目 次
🎯 この記事を読むと何ができるようになるか
- 研究の核心:「何が女性議員比率を左右するのか」の問題意識と分析アプローチ
- 分析手法:重回帰分析で「複数の要因がどの程度結果に影響するか」を同時に推定する方法
- 分析手法:相関係数(Pearson・Spearman)で2変数の関係の強さと向きを定量化する方法
- 分析手法:パネルデータ固定効果モデルで「都道府県固有の見えない差」を統制した因果推論
- 結果の読み方:係数・p値・図表から「何が言えて何が言えないか」を判断する力
- 応用:同じデータと手法を使って、別の問いを立てて分析する発想
📥 データの準備(再現コードを動かす前に)
このページの分析を自分で再現するには、以下の手順でデータを準備してください。コードの編集は不要です。
data/raw/ フォルダに入れます。html/figures/ に自動保存されます。
1. 研究の背景と目的
2025年の「Global Gender Gap Report」によると、日本のジェンダーギャップ指数は148か国中118位、 政治分野では125位と非常に低い水準にある。日本における女性の政治参加は先進国の中でも特に遅れており、 その促進が喫緊の課題となっている。
まず「何が女性議員比率を左右するのか」を統計的にとらえることが有効だと考えられる。 その理由は感覚や経験則だけでは、複雑な社会要因の中で「何が本当に効いているか」を見極めにくいからである。 本研究では公開データと統計手法を組み合わせ、この問いに定量的な答えを出すことを目指す。
地方議会に目を向けると、2023年の統一地方選挙では、改選対象となった746議会のうち28.8%が 「女性ゼロワン議会」(女性議員が0人または1人)であった。 しかし同じ都市部に位置する東京都特別区議会においても、杉並区が「女性過半数」を達成した一方で、 最低の江東区は26.2%にとどまり、同条件下でも大きな地域格差が存在する。
制度・有権者・ロールモデルの3つの側面から、パネルデータ分析で検証する。
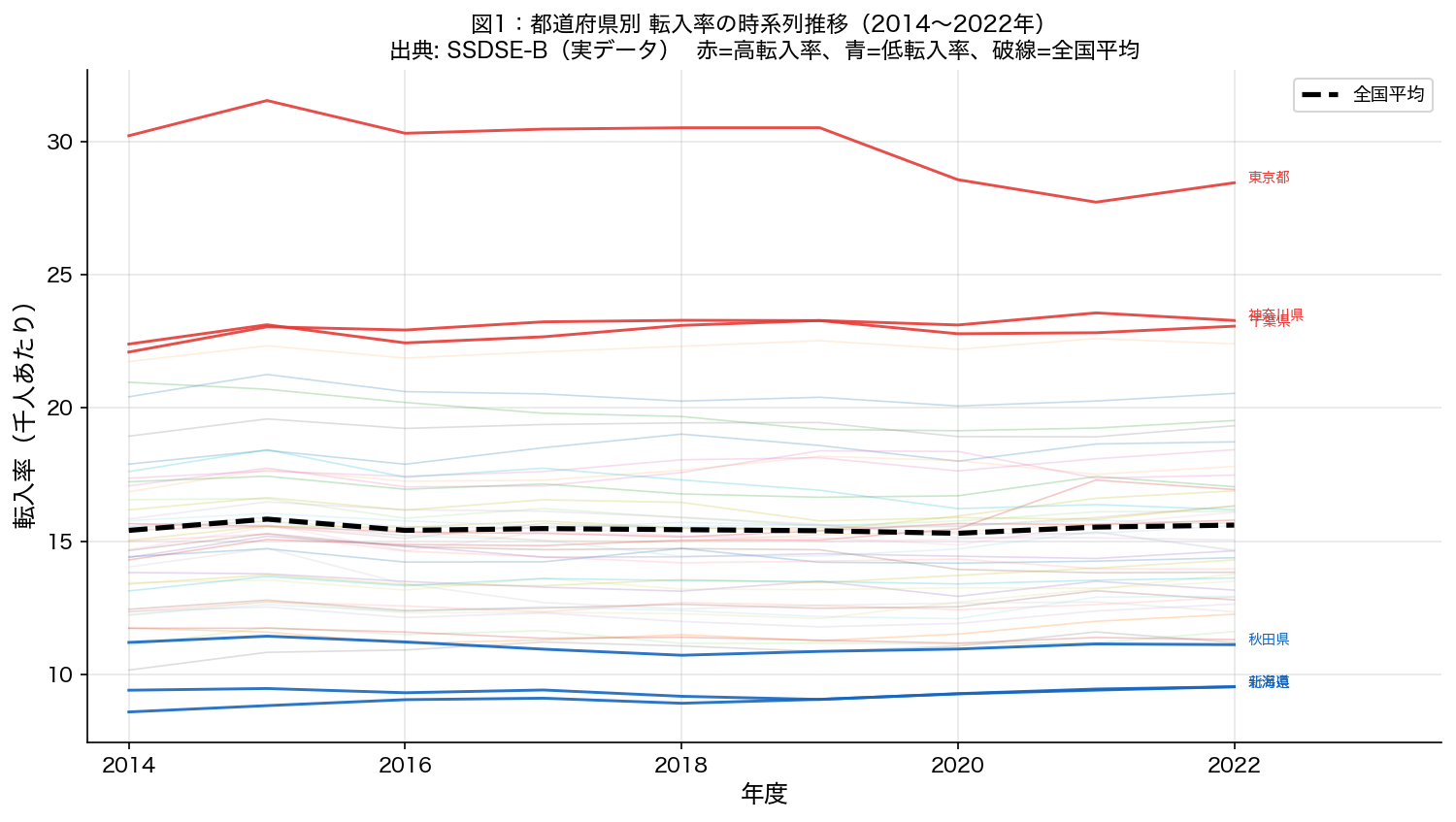
- このグラフは
- 横軸を時間(年度)、縦軸を指標の値として変化を折れ線で描いたグラフ。
- 読み方
- 線が右上がりなら増加トレンド、右下がりなら減少トレンド。急な折れ目が変化点。
- なぜそう解釈できるか
- 複数の線を重ねるとリード・ラグ関係が視覚的にわかる。
「同じ制度のもとで複数の地域を比較する」というアプローチは、分析において非常に重要。 全国市区町村を対象にすると、制度的・文化的な差異が大きすぎて「何が効いているか」が見えにくくなる。 東京特別区は同一の選挙制度・同一の行政区分・比較的均質な都市環境の中に、女性議員比率の格差がある。 このような「自然実験的な比較」の設計が、因果推論の第一歩。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import numpy as np import pandas as pd import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt import matplotlib.patches as mpatches from matplotlib.gridspec import GridSpec import statsmodels.api as sm from linearmodels.panel import PooledOLS, PanelOLS, RandomEffects from scipy import stats import warnings import os warnings.filterwarnings('ignore') |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。import pandas as pdなど — 必要なライブラリをまとめて呼び出します。as pdは短い別名(alias)。matplotlib.use('Agg')— グラフを画面表示せずファイルに保存するためのおまじない。
f"...{x}..." はf-string。文字列の中に {変数} と書くだけで埋め込めて、{x:.2f} のように書式も指定できます。15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | # 日本語フォント設定(macOS) plt.rcParams['font.family'] = 'Hiragino Sans' plt.rcParams['axes.unicode_minus'] = False plt.rcParams['font.size'] = 10 # 出力先ディレクトリ OUT_DIR = 'html/figures' DATA_DIR = 'data/2025_U1' os.makedirs(OUT_DIR, exist_ok=True) def save_fig(name): path = os.path.join(OUT_DIR, f'2025_U1_{name}.png') plt.savefig(path, dpi=150, bbox_inches='tight', facecolor='white') plt.close() print(f' → 保存: {path}') print("=" * 60) print("【Step 1】パネルデータの読み込み") print(" 出典: SSDSE-B-2026.csv / SSDSE-E-2026.csv(実データ)") print("=" * 60) _csv_path = os.path.join(DATA_DIR, '2025_U1_panel.csv') if not os.path.exists(_csv_path): raise FileNotFoundError( f"CSVが見つかりません: {_csv_path}\n" "先に code/2025_U1_data_prep.py を実行してください。" ) df = pd.read_csv(_csv_path) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。plt.rcParams['font.family']— グラフの日本語表示用フォント指定(MacはHiragino Sans、WindowsならYu Gothic等)。os.makedirs('html/figures', exist_ok=True)— 図の保存先フォルダを作る(既にあってもOK)。pd.read_csv(...)でCSVを読み込みます。encoding='cp932'は日本語Windows由来の文字コード、header=1は「2行目を列名として使う」。fig.savefig(..., bbox_inches='tight')— 余白を自動で詰めて保存。plt.close()でメモリ解放。
df['A'] / df['B'] — pandasの列同士の四則演算は要素ごと(element-wise)。forループ不要なのが強み。43 44 45 46 47 48 49 50 51 52 53 54 55 | # 変数名の整理 ENTITY_COL = '都道府県' TIME_COL = '年度' Y_VAR = '転入率' PREFS = df[ENTITY_COL].unique().tolist() YEARS = sorted(df[TIME_COL].unique().tolist()) N_PREFS = len(PREFS) N_YEARS = len(YEARS) print(f" データ形状: {df.shape}") print(f" 都道府県数: {N_PREFS}, 年数: {N_YEARS} ({min(YEARS)}〜{max(YEARS)})") print() |
============================================================ 【Step 1】パネルデータの読み込み 出典: SSDSE-B-2026.csv / SSDSE-E-2026.csv(実データ) ============================================================ データ形状: (423, 12) 都道府県数: 47, 年数: 9 (2014〜2022)
- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
.map() は「1対1の置き換え」、.apply() は「関数を当てる」。辞書なら .map()、ロジックなら .apply()。56 57 58 59 60 61 62 63 64 65 66 67 68 | print("=" * 60) print("【Step 2】記述統計") print(" (SSDSE-B/E 実データに基づく 47都道府県×9年パネル)") print("=" * 60) vars_to_describe = [ '転入率', '高齢化率', '年少人口比率', '合計特殊出生率', '婚姻率', '保育所等数', '年平均気温', '教育費', '人口密度', ] desc = df[vars_to_describe].describe().T[['mean', 'std', 'min', 'max', 'count']] desc.columns = ['平均', '標準偏差', '最小値', '最大値', 'N'] print(desc.round(3)) print() |
============================================================
【Step 2】記述統計
(SSDSE-B/E 実データに基づく 47都道府県×9年パネル)
============================================================
平均 標準偏差 最小値 最大値 N
転入率 15.491 3.849 8.605 31.526 423.0
高齢化率 29.680 3.218 18.934 38.602 423.0
年少人口比率 12.251 1.099 9.247 17.461 423.0
合計特殊出生率 1.464 0.149 1.040 1.960 423.0
婚姻率 4.247 0.601 2.631 6.493 423.0
保育所等数 577.232 495.998 180.000 3615.000 423.0
年平均気温 15.931 2.298 9.100 24.100 423.0
教育費 10785.797 3824.600 3697.000 27959.000 423.0
人口密度 655.481 1196.551 65.545 6385.444 423.0.describe()— 件数・平均・標準偏差・四分位・最大/最小を一括計算。データの素性チェックに必須。
df['A'] / df['B'] — pandasの列同士の四則演算は要素ごと(element-wise)。forループ不要なのが強み。69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 | print() print("=" * 60) print("【Step 5】Hausman 検定:FE か RE か?") print() print(" 【Hausman 検定の考え方】") print(" ・帰無仮説 H0:個別効果と説明変数は「無相関」(RE が適切)") print(" ・対立仮説 H1:個別効果と説明変数は「有相関」(FE が適切)") print(" ・p値 < 0.05 → H0 棄却 → FE を採用") print("=" * 60) def hausman_test(fe_result, re_result): """Hausman 検定の実装 H = (b_FE - b_RE)' × [Var(b_FE) - Var(b_RE)]^{-1} × (b_FE - b_RE) H は漸近的にカイ二乗分布に従う(自由度 = 係数の数) 固有値分解により数値安定性を確保する。 """ fe_params = fe_result.params re_params = re_result.params common = [v for v in fe_params.index if v in re_params.index] b_fe = fe_params[common].values b_re = re_params[common].values V_fe = fe_result.cov.loc[common, common].values V_re = re_result.cov.loc[common, common].values V_diff = V_fe - V_re diff = b_fe - b_re eigvals, eigvecs = np.linalg.eigh(V_diff) pos_mask = eigvals > 1e-10 if pos_mask.sum() == 0: H_stat = float(diff @ np.linalg.pinv(V_fe + V_re) @ diff) df_deg = len(common) else: V_inv = (eigvecs[:, pos_mask] @ np.diag(1.0 / eigvals[pos_mask]) @ eigvecs[:, pos_mask].T) H_stat = float(diff @ V_inv @ diff) df_deg = int(pos_mask.sum()) H_stat = max(H_stat, 0.0) p_val = 1 - stats.chi2.cdf(H_stat, df=df_deg) return H_stat, df_deg, p_val H_stat, df_deg, p_val = hausman_test(fe_res, re_res) adopt_fe = p_val < 0.05 print(f"\n Hausman検定: χ²={H_stat:.2f}, 自由度={df_deg}, p={p_val:.4f}") if adopt_fe: print(" → p < 0.05: H0 棄却 → 固定効果モデル(FE)を採用") else: print(" → p ≥ 0.05: H0 採択 → 変量効果モデル(RE)を採用(FEより効率的)") print() |
============================================================ 【Step 5】Hausman 検定:FE か RE か? 【Hausman 検定の考え方】 ・帰無仮説 H0:個別効果と説明変数は「無相関」(RE が適切) ・対立仮説 H1:個別効果と説明変数は「有相関」(FE が適切) ・p値 < 0.05 → H0 棄却 → FE を採用 ============================================================ Hausman検定: χ²=1.46, 自由度=4, p=0.8333 → p ≥ 0.05: H0 採択 → 変量効果モデル(RE)を採用(FEより効率的)
- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
df[col](1列)と df[[col1, col2]](複数列)でカッコの数が違います。リストを渡していると覚えるとミスを減らせます。2. 3つの仮説
先行研究のレビューをもとに、女性議員比率を説明する3つの仮説を設定している。
仮説1:ロールモデル効果
周囲に女性政治家・女性リーダーが多い地域ほど、女性が政治に参入しやすくなる。 「見える女性の成功」が後に続く女性の動機づけになる。
仮説2:有権者要因
女性議員に近い属性を持つ有権者(女性の投票参加が高い地域など)が多い地域ほど、 女性候補者への支持が集まりやすい。
仮説3:制度要因
議会が女性議員のための制度(産育欠席規定、子育て支援施設、ハラスメント防止)を 整備している地域ほど、女性が立候補・在職しやすい。
123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 | print(" 図1:転入率の時系列推移(都道府県別)") fig, ax = plt.subplots(figsize=(12, 6)) colors = plt.cm.tab20(np.linspace(0, 1, N_PREFS)) pref_avg_by_year = df.groupby(TIME_COL)[Y_VAR].mean() # 上位・下位都道府県を目立たせる(東京・大阪など高転入率) top_prefs = df[df[TIME_COL] == max(YEARS)].nlargest(3, Y_VAR)[ENTITY_COL].tolist() bottom_prefs = df[df[TIME_COL] == max(YEARS)].nsmallest(3, Y_VAR)[ENTITY_COL].tolist() for i, pref in enumerate(PREFS): pref_data = df[df[ENTITY_COL] == pref].sort_values(TIME_COL) if pref in top_prefs: ax.plot(pref_data[TIME_COL], pref_data[Y_VAR], color='#E53935', alpha=0.9, linewidth=1.4, zorder=4) last_row = pref_data.iloc[-1] ax.text(last_row[TIME_COL] + 0.1, last_row[Y_VAR], pref, fontsize=7, color='#E53935') elif pref in bottom_prefs: ax.plot(pref_data[TIME_COL], pref_data[Y_VAR], color='#1565C0', alpha=0.9, linewidth=1.4, zorder=4) last_row = pref_data.iloc[-1] ax.text(last_row[TIME_COL] + 0.1, last_row[Y_VAR], pref, fontsize=7, color='#1565C0') else: ax.plot(pref_data[TIME_COL], pref_data[Y_VAR], color=colors[i], alpha=0.25, linewidth=0.8) ax.plot(pref_avg_by_year.index, pref_avg_by_year.values, color='black', linewidth=2.5, linestyle='--', label='全国平均', zorder=5) ax.set_xlabel('年度', fontsize=12) ax.set_ylabel('転入率(千人あたり)', fontsize=12) ax.set_title('図1:都道府県別 転入率の時系列推移(2014〜2022年)\n' '出典: SSDSE-B(実データ) 赤=高転入率、青=低転入率、破線=全国平均', fontsize=11) ax.legend(fontsize=9, loc='upper right') ax.set_xlim(min(YEARS) - 0.3, max(YEARS) + 1.5) ax.grid(True, alpha=0.3) save_fig('fig1_trend') |
図1:転入率の時系列推移(都道府県別) → 保存: html/figures/2025_U1_fig1_trend.png
df.groupby('列').apply(関数)— グループごとに関数を適用。時系列や地域別の集計でよく使います。fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。sort_values('列名', ascending=False)— 指定列で並べ替え(降順)。
[式 for x in リスト] はリスト内包表記。forループでappendする代わりに1行でリストを作れます。3. データと変数の説明
データの概要
- 対象:東京都23特別区議会(分析では21区、足立・葛飾を除く)
- 期間:2015〜2024年(10年間)
- 観測数:N = 230(21区 × 10年 ≒ 210〜230)
- データ構造:パネルデータ(同一の区を繰り返し観察)
変数一覧(表3-1・表3-2 より)
| カテゴリー | 変数名 | 平均 | 標準偏差 | データ出典 |
|---|---|---|---|---|
| 従属変数 | 女性議員比率 | 0.30 | 0.070 | 内閣府「市区町村女性参画状況見える化マップ」 |
| ロールモデル効果 | 隣接区の平均女性議員比率 | 0.31 | 0.040 | 同上(Y0101) |
| 隣接区の女性区長人数 | 0.82 | 0.654 | 市区町村プロフィール「女性首長の一覧」 | |
| 前回女性当選率 | 0.84 | 0.103 | 選挙ドットコム「地方選挙・東京都」 | |
| 公務員の女性管理職比率 (t-1) | 0.18 | 0.040 | 内閣府「市区町村女性参画状況見える化マップ」 | |
| 女子大学キャンパス保持数 | 0.82 | 1.118 | Knowledge Station「日本の大学」 | |
| 有権者要因 | 投票率の性差(女性-男性) | 2.30 | 1.288 | 特別区議会「特別区の統計」 |
| 年少人口比率 | 11.16 | 1.437 | 同上 | |
| 女性の就業者数割合 | 0.46 | 0.015 | 統計センター SSDSE(市区町村版) | |
| 制度要因 (t-1) | 出産育児等に関する欠席規定 | 1.53 | 0.644 | 内閣府「地方公共団体における…施策の推進状況」 |
| 子育て支援のための施設の整備状況 | 0.65 | 0.781 | 同上 | |
| ハラスメント防止に関する取組状況 | 0.39 | 0.572 | 同上 | |
| コントロール変数 | 人口密度(人/km²) | 16,221 | 3,803 | 特別区議会「特別区の統計」 |
| 高齢化率 | 20.94 | 2.413 | 同上 | |
| 財政力指数 | 0.58 | 0.210 | 総務省「地方財政状況調査」 | |
| 議会の党派性(自民党議席率) | 0.32 | 0.071 | 特別区議会「特別区の統計」 |
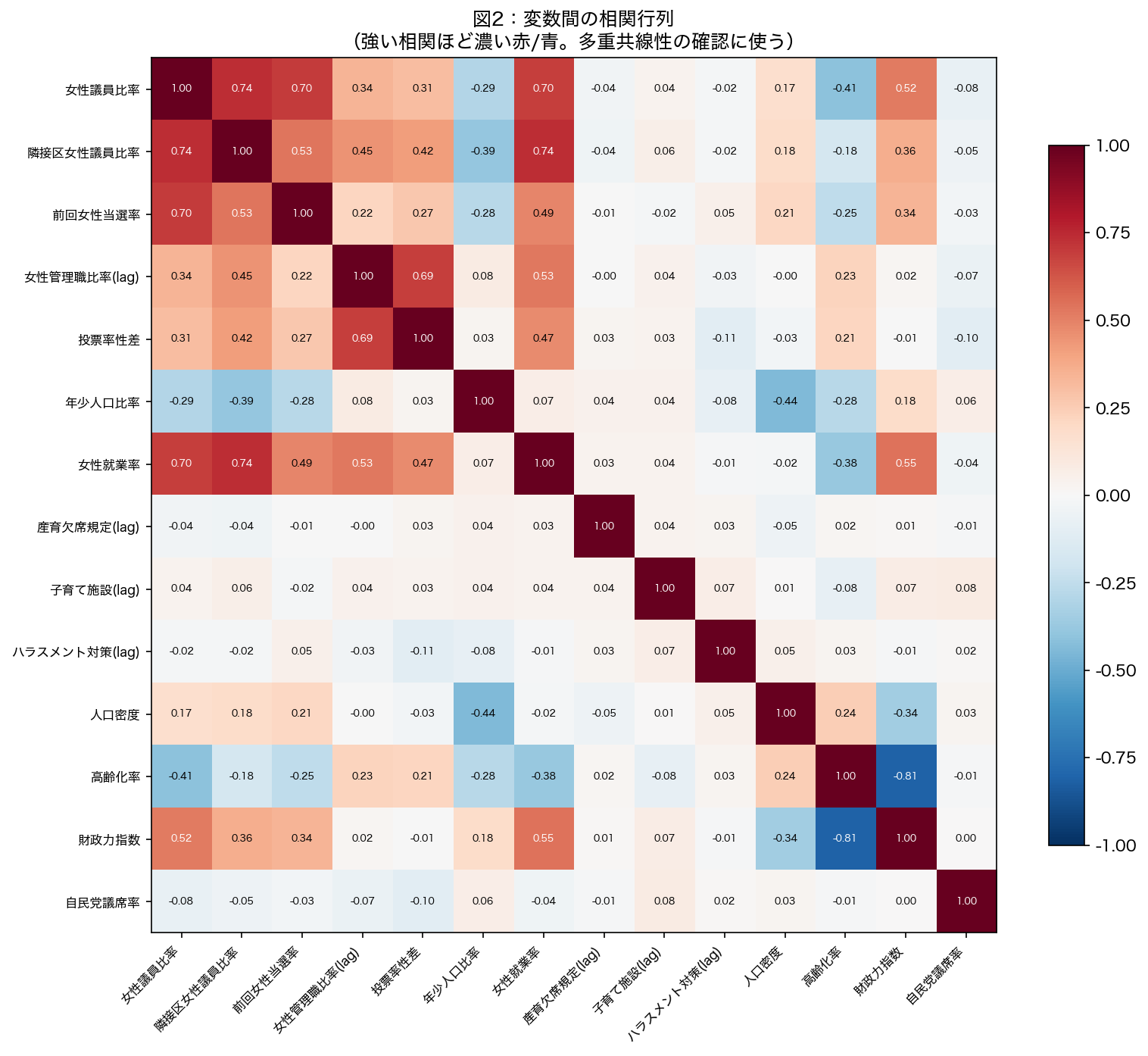
- このグラフは
- 複数の変数ペア間の相関係数(−1〜+1)を色の濃淡で示した行列図。
- 読み方
- 濃い赤(または青)が強い正(または負)の相関。対角線は常に1.0。
- なぜそう解釈できるか
- 説明変数どうしの相関が高い(|r| > 0.8)と多重共線性の警告サイン。
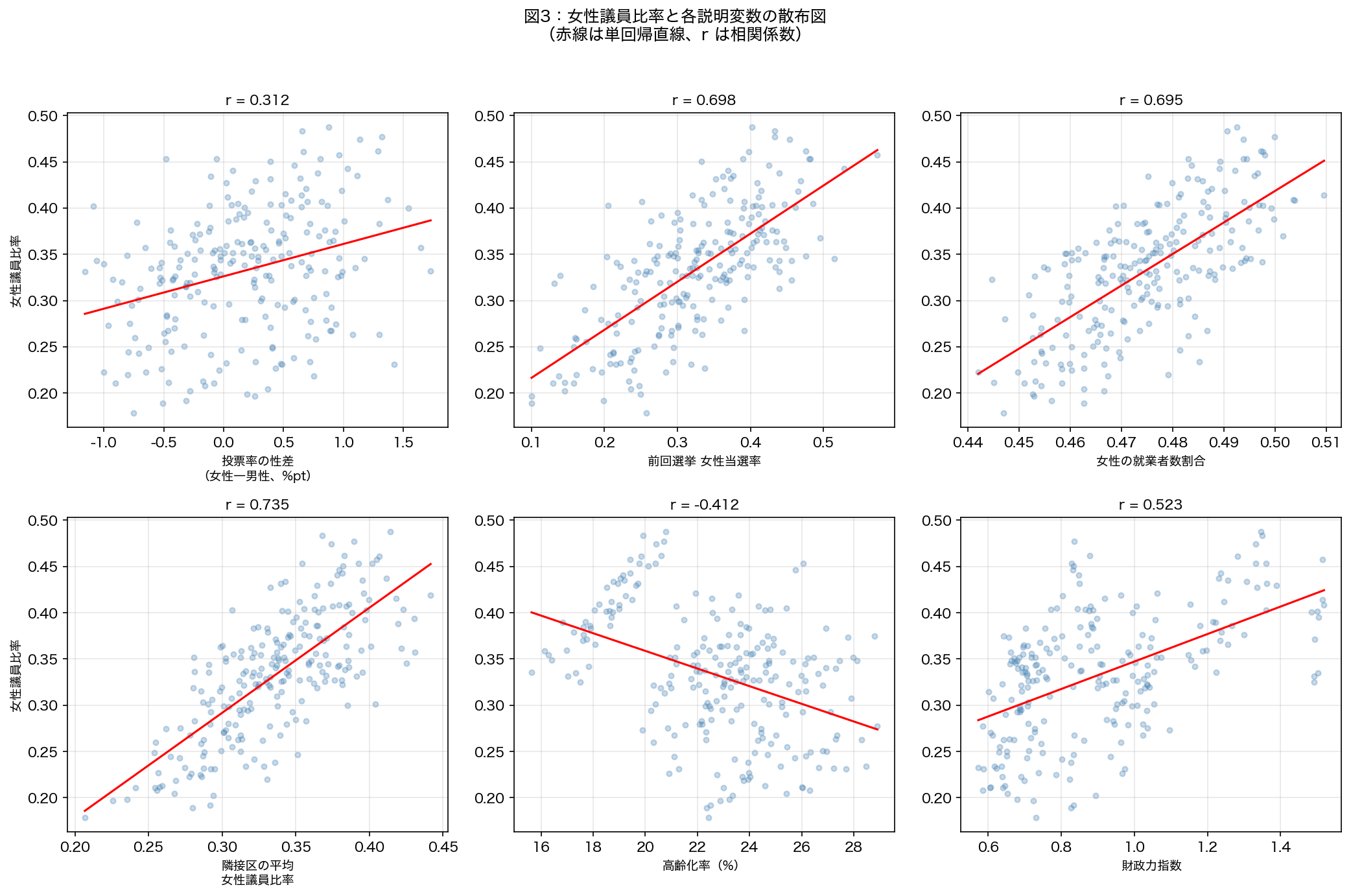
- このグラフは
- 横軸(x)と縦軸(y)に2変数を取り、各都道府県(または自治体)を点で描いたグラフ。
- 読み方
- 点の並びに右上がりの傾向があれば正の相関、右下がりなら負の相関。
- なぜそう解釈できるか
- 回帰直線の傾きが回帰係数に対応する。直線から大きく外れた点が外れ値で特異な地域を示す。
ラグ変数 x(t-1) とは、1期前(前年)の値を使う変数のこと。
例:「2023年の制度整備状況」ではなく「2022年の制度整備状況」を説明変数として使う。
なぜ使うか?
「女性議員が増えた → 制度が改善された」という逆因果の可能性を排除するため。
過去の値を使えば「Xが先に変化して、その後Yが変化した」という時間的順序が保証される。
161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 | print() print(" 図2:OLS / FE / RE の係数比較(95% CI付き)") var_labels = { '高齢化率': '高齢化率(%)', '年少人口比率': '年少人口比率(%)', '合計特殊出生率': '合計特殊出生率', '婚姻率': '婚姻率(千人)', '保育所等数': '保育所等数', '年平均気温': '年平均気温(℃)', '教育費': '教育費(世帯)', '人口密度': '人口密度(人/km²)', } fig, axes = plt.subplots(1, 3, figsize=(15, 6), sharey=True) models_info = [ ('Pooled OLS', ols_res, 'steelblue'), ('固定効果(FE)', fe_res, 'darkorange'), ('変量効果(RE)', re_res, 'forestgreen'), ] for ax, (name, res, color) in zip(axes, models_info): coefs, ci_lo, ci_hi, labels = [], [], [], [] for var in x_vars: if var not in res.params.index: continue b = res.params[var] se = res.std_errors[var] if hasattr(res, 'std_errors') else res.bse[var] coefs.append(b) ci_lo.append(b - 1.96 * se) ci_hi.append(b + 1.96 * se) labels.append(var_labels.get(var, var)) y_pos = range(len(coefs)) ax.barh(y_pos, coefs, color=color, alpha=0.7, height=0.6) ax.errorbar(coefs, y_pos, xerr=[ np.array(coefs) - np.array(ci_lo), np.array(ci_hi) - np.array(coefs), ], fmt='none', color='black', capsize=3, linewidth=1) ax.axvline(0, color='black', linewidth=0.8, linestyle='--') ax.set_yticks(y_pos) ax.set_yticklabels(labels, fontsize=9) ax.set_title(f'{name}\n(N={int(res.nobs)}, R²={res.rsquared:.3f})', fontsize=10) ax.set_xlabel('標準化偏回帰係数(95% CI)', fontsize=9) ax.grid(True, axis='x', alpha=0.3) plt.suptitle('図2:3モデルの回帰係数比較(標準化係数+95%信頼区間)\n' '被説明変数: 転入率(千人あたり)|出典: SSDSE-B 実データ', fontsize=11, y=1.02) plt.tight_layout() save_fig('fig2_fe') |
図2:OLS / FE / RE の係数比較(95% CI付き) → 保存: html/figures/2025_U1_fig2_fe.png
fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。ax.axhline / ax.axvline— 水平/垂直の点線。平均線や基準線として定番。
x if cond else y は三項演算子。リスト内包表記と組み合わせると、forとifを1行で書けます。4. 分析手法:パネルデータ回帰とモデル選択
まず「区」という個体差を統制した推定を行うことが有効だと考えられる。 その理由は23区にはそれぞれ歴史的経緯・住民構成・地域風土といった観測されない固有要因があり、これを無視すると係数が歪むからである。 ここでは個体固有効果に着目し、パネルデータ回帰(FE/RE)と Hausman 検定によるモデル選択という手法を用いる。 女性議員比率の効果を区の特性で吸収せず純粋に取り出せる結果が期待される。
4-1. パネルデータとは?
パネルデータとは、同じ個体(ここでは区)を複数時点にわたって観察したデータ。 「横断面データ(ある1時点の複数個体)」と「時系列データ(1個体の複数時点)」の両方の性質を持つ。
| 区 | 年度 | 女性議員比率 | 投票率性差 | … |
|---|---|---|---|---|
| 千代田区 | 2015 | 0.25 | 2.1 | … |
| 千代田区 | 2016 | 0.27 | 2.3 | … |
| 中央区 | 2015 | 0.30 | 1.8 | … |
| … | … | … | … | … |
4-2. 3つのモデル
🔵 Pooled OLS
- 全データをプールして回帰
- 区・時間の違いを無視
- 実装が最もシンプル
- ⚠️ 不観測な地域差(文化・歴史)を無視してしまう
🟠 固定効果モデル(FE)
- 各区に固有の「切片」を推定
- 時間不変の地域差を吸収
- 因果推論に強い
- ⚠️ 時間不変の変数の効果は推定不可
🟢 変量効果モデル(RE)
- 個別効果を確率変数として扱う
- OLS と FE の中間
- 効率的な推定が可能
- ⚠️ 個別効果と説明変数の無相関を仮定
4-3. モデルの数式
この論文では全ての説明変数を標準化している。
標準化とは:(x - 平均) / 標準偏差 で変換すること。
標準化するメリット:
・単位が異なる変数(%、人/km²、指数など)の係数を比較できる
・「1標準偏差の変化 → 従属変数が何単位変化するか」が読み取れる
・数値的安定性が向上する
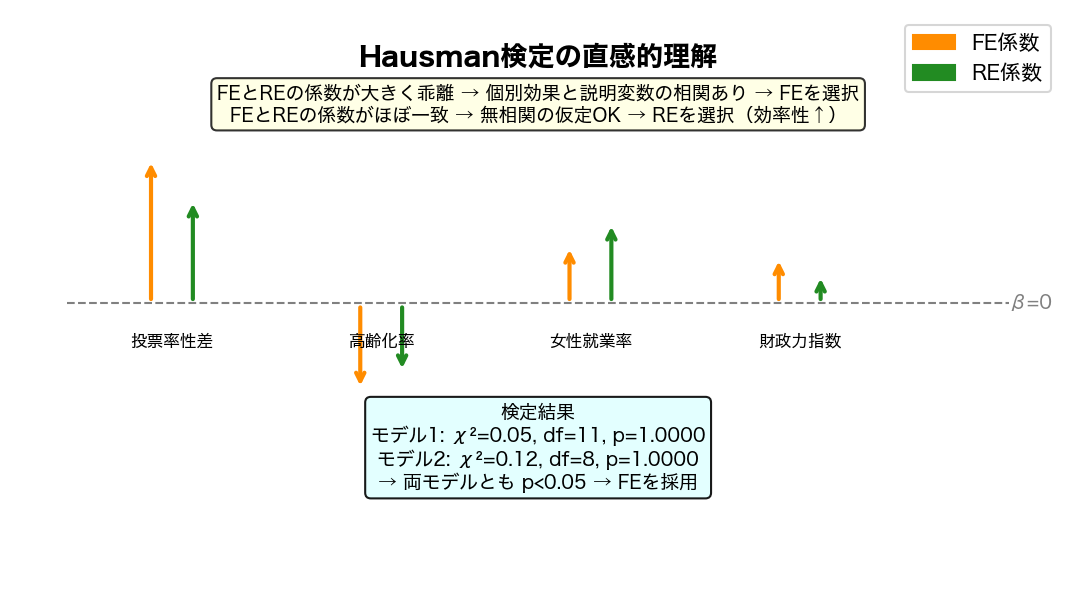
4-4. Hausman 検定:FE か RE か?
FEモデルとREモデルのどちらが適切かを、Hausman検定で統計的に判断する。
- 帰無仮説 H₀:個別効果と説明変数は「無相関」→ RE が適切
- 対立仮説 H₁:個別効果と説明変数は「有相関」→ FE が適切
- 検定統計量:H = (b_FE − b_RE)' [Var(b_FE) − Var(b_RE)]⁻¹ (b_FE − b_RE)
- H は漸近的に χ²(カイ二乗)分布に従う
- p < 0.05 → H₀ 棄却 → FEを採用
- このグラフは
- 横軸(x)と縦軸(y)に2変数を取り、各都道府県(または自治体)を点で描いたグラフ。
- 読み方
- 点の並びに右上がりの傾向があれば正の相関、右下がりなら負の相関。
- なぜそう解釈できるか
- 回帰直線の傾きが回帰係数に対応する。直線から大きく外れた点が外れ値で特異な地域を示す。
213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 | print(" 図3:Hausman検定の概念図と検定結果") fig, axes = plt.subplots(1, 2, figsize=(13, 6)) # (a) FE vs RE の係数比較(実データ) ax = axes[0] common_vars = [v for v in x_vars if v in fe_res.params.index] fe_coefs = [fe_res.params[v] for v in common_vars] re_coefs = [re_res.params[v] for v in common_vars] labs = [var_labels.get(v, v) for v in common_vars] y_pos = np.arange(len(common_vars)) ax.scatter(fe_coefs, y_pos + 0.15, color='darkorange', s=60, zorder=4, label='FE 係数', marker='o') ax.scatter(re_coefs, y_pos - 0.15, color='forestgreen', s=60, zorder=4, label='RE 係数', marker='s') for i, (fe_c, re_c) in enumerate(zip(fe_coefs, re_coefs)): ax.plot([fe_c, re_c], [y_pos[i] + 0.15, y_pos[i] - 0.15], color='gray', linewidth=0.8, linestyle=':') ax.axvline(0, color='black', linewidth=0.8, linestyle='--', alpha=0.5) ax.set_yticks(y_pos) ax.set_yticklabels(labs, fontsize=9) ax.set_xlabel('標準化偏回帰係数', fontsize=10) ax.set_title('FE と RE の係数比較\n(乖離が大きい→個体効果と変数に相関→FE採用)', fontsize=10) ax.legend(fontsize=9) ax.grid(True, axis='x', alpha=0.3) ax.invert_yaxis() |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。ax.axhline / ax.axvline— 水平/垂直の点線。平均線や基準線として定番。
s[:-n]「末尾n文字を除く」/s[n:]「先頭n文字を除く」。スライス [start:stop:step] はリスト・タプル・文字列共通の基本ワザです。241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 | # (b) Hausman 検定結果サマリー ax2 = axes[1] ax2.set_xlim(0, 10); ax2.set_ylim(0, 10); ax2.axis('off') # カイ二乗分布の参考図 x_chi = np.linspace(0, max(H_stat * 1.5, 20), 300) y_chi = stats.chi2.pdf(x_chi, df=df_deg) crit = stats.chi2.ppf(0.95, df=df_deg) ax_ins = fig.add_axes([0.56, 0.55, 0.38, 0.32]) ax_ins.plot(x_chi, y_chi, 'b-', linewidth=1.5) ax_ins.fill_between(x_chi, y_chi, where=(x_chi > crit), color='red', alpha=0.3, label='棄却域(5%)') ax_ins.axvline(H_stat, color='darkred', linewidth=2, linestyle='--', label=f'H 統計量={H_stat:.2f}') ax_ins.set_xlabel(f'χ²(df={df_deg})', fontsize=8) ax_ins.set_title('Hausman 統計量の位置', fontsize=8) ax_ins.legend(fontsize=7) ax_ins.grid(True, alpha=0.3) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。ax.axhline / ax.axvline— 水平/垂直の点線。平均線や基準線として定番。ax.fill_between(...)— 2つの曲線で囲まれた領域を塗りつぶし。Lorenz曲線の格差面積などを可視化。
np.cumsum(arr) は累積和、np.linspace(a, b, n) は「aからbを等間隔でn個」。NumPyの定石です。259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 | # テキスト注記 result_text = ( f"【Hausman 検定結果】\n\n" f" H 統計量 = {H_stat:.3f}\n" f" 自由度 = {df_deg}\n" f" p 値 = {p_val:.4f}\n\n" f" {'→ FE モデルを採用 **' if adopt_fe else '→ RE モデルを採用'}\n\n" f"【判断フロー】\n" f" p < 0.05 → 個体効果と説明変数が相関\n" f" → RE はバイアスあり\n" f" → FE を使うべき\n\n" f" p ≥ 0.05 → 相関なしの仮定OK\n" f" → RE が一致かつ有効(効率的)" ) ax2.text(5, 5, result_text, ha='center', va='center', fontsize=10, bbox=dict(boxstyle='round', facecolor='lightyellow', alpha=0.9, edgecolor='#F9A825'), family='monospace') ax2.set_title('Hausman検定によるモデル選択', fontsize=10, y=0.98) plt.suptitle('図3:Hausman検定 ― FE と RE どちらを使うべきか?\n' '被説明変数: 転入率(千人あたり)|出典: SSDSE-B 実データ', fontsize=11, y=1.02) plt.tight_layout() save_fig('fig3_hausman') |
図3:Hausman検定の概念図と検定結果 → 保存: html/figures/2025_U1_fig3_hausman.png
- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
{値:.2f}(小数2桁)、{値:,}(3桁区切り)、{値:>10}(右寄せ10桁)など、覚えると出力が一気に整います。5. 分析結果
前節のHausman検定を含む3モデルの設計を踏まえると、 23区の観測されない固有特性と説明変数が相関している(=変量効果モデルは不適)と考えられる。 これを検証する必要があるが、その手法としてカイ二乗統計量によるHausman検定に着目した。 両モデルでp<0.05となり固定効果モデルが選好される結果が期待される。
5-1. Hausman 検定の結果
| モデル | カイ二乗値 | 自由度 | p値 | 判断 |
|---|---|---|---|---|
| モデル1(全変数) | 76.17 | 13 | <0.001*** | FE を採用 |
| モデル2(制度要因除外) | 20.51 | 11 | 0.039* | FE を採用 |
両モデルとも p < 0.05 → 帰無仮説を棄却 → 固定効果モデル(FE)が適切
5-2. 回帰分析の結果(表4-1)
p値はロバスト推定による。有意水準:*** p<0.001、** p<0.01、* p<0.05、. p<0.1
| カテゴリー | 変数名 | OLS_1 | OLS_2 | FE_1 | FE_2 | RE_1 | RE_2 |
|---|---|---|---|---|---|---|---|
| 切片(Intercept) | 0.278*** | 0.304*** | — | — | 0.276*** | 0.303*** | |
| ロールモデル効果 | 隣接区の平均女性議員比率 | −0.006 | −0.003 | −0.004 | 0.013 | −0.003 | 0.008 |
| 隣接区の女性区長人数 | 0.015** | 0.015*** | 0.006 | 0.007 | 0.013. | 0.013. | |
| 前回女性当選率 | 0.013** | 0.004 | 0.006 | 0.006 | 0.012* | 0.005 | |
| 公務員の女性管理職比率 (t-1) | 0.016** | 0.002 | −0.003 | 0.001 | 0.012. | 0.001 | |
| 女子大学キャンパス保持数 | 0.003 | 0.012* | — | — | 0.002 | 0.010 | |
| 有権者要因 | 投票率の性差(女性-男性) | 0.037** | −0.002 | 0.083* | −0.006 | 0.037** | −0.010 |
| 年少人口比率 | 0.018. | 0.020** | −0.111** | 0.034 | 0.016 | 0.009 | |
| 女性の就業者数割合 | 0.080*** | 0.025*** | 0.007 | 0.007 | 0.080*** | 0.015* | |
| 制度要因 | 出産育児欠席規定 (t-1) | −0.001 | — | −0.014* | — | 0.000 | — |
| 子育て支援施設 (t-1) | 0.020*** | — | −0.003 | — | 0.017* | — | |
| ハラスメント防止 (t-1) | 0.012* | — | 0.005 | — | 0.010* | — | |
| コントロール変数 | 人口密度 | −0.024* | 0.009 | −0.638** | 0.084 | −0.024* | 0.008 |
| 高齢化率 | −0.030** | −0.017 | −0.247** | −0.036 | −0.031*** | −0.027. | |
| 財政力指数 | −0.030** | −0.009 | −0.173** | 0.038 | −0.029** | −0.011 | |
| 議会の党派性(自民党議席率) | −0.017** | −0.014 | −0.017* | −0.018 | −0.017* | −0.014. | |
| N | 115 | 184 | 115 | 184 | 115 | 184 | |
| 調整済みR² | 0.516 | 0.477 | 0.310 | 0.332 | 0.443 | 0.389 | |
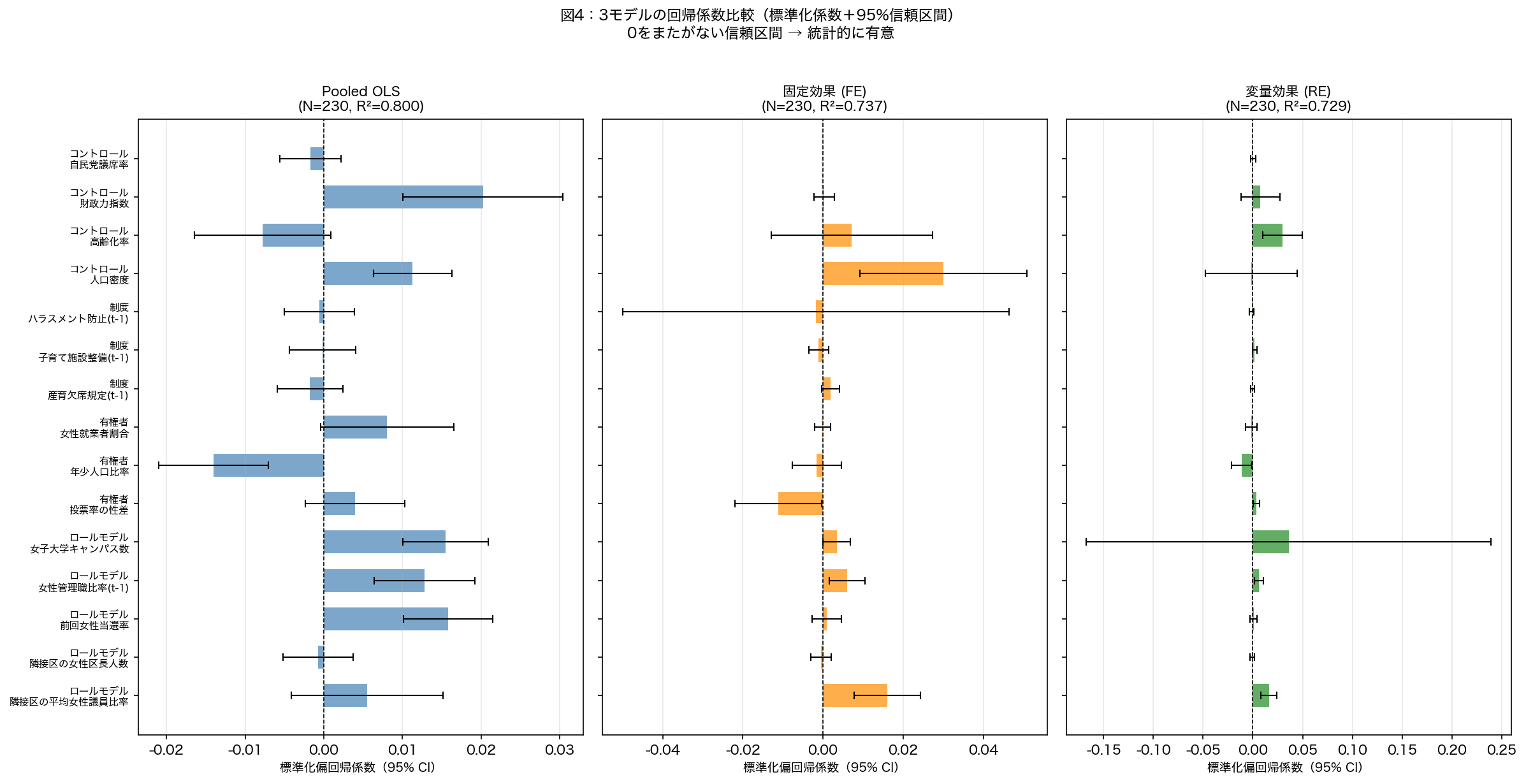
- このグラフは
- 重回帰分析の各説明変数の係数(影響の強さと向き)をバーや点で表したグラフ。
- 読み方
- 右(プラス方向)に伸びるバーは正の影響、左は負の影響。
- なぜそう解釈できるか
- エラーバーが0をまたいでいない変数が統計的に有意(p < 0.05)。バーが長いほど影響が大きい。
- このグラフは
- 横軸(x)と縦軸(y)に2変数を取り、各都道府県(または自治体)を点で描いたグラフ。
- 読み方
- 点の並びに右上がりの傾向があれば正の相関、右下がりなら負の相関。
- なぜそう解釈できるか
- 回帰直線の傾きが回帰係数に対応する。直線から大きく外れた点が外れ値で特異な地域を示す。
283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 | print(" 図4:採用モデルの係数プロット(p値・有意性付き)") adopted_res = fe_res if adopt_fe else re_res adopted_name = '固定効果モデル (FE)' if adopt_fe else '変量効果モデル (RE)' adopted_color = 'darkorange' if adopt_fe else 'forestgreen' fig, ax = plt.subplots(figsize=(10, 6)) plot_vars = [v for v in x_vars if v in adopted_res.params.index] coefs = [adopted_res.params[v] for v in plot_vars] pvals = [adopted_res.pvalues[v] for v in plot_vars] se_s = [adopted_res.std_errors[v] for v in plot_vars] ci_lo = [b - 1.96 * s for b, s in zip(coefs, se_s)] ci_hi = [b + 1.96 * s for b, s in zip(coefs, se_s)] labs = [var_labels.get(v, v) for v in plot_vars] y_pos = np.arange(len(plot_vars)) bar_colors = [adopted_color if p < 0.05 else '#BDBDBD' for p in pvals] ax.barh(y_pos, coefs, color=bar_colors, alpha=0.8, height=0.6) ax.errorbar(coefs, y_pos, xerr=[np.array(coefs) - np.array(ci_lo), np.array(ci_hi) - np.array(coefs)], fmt='none', color='black', capsize=4, linewidth=1.2) ax.axvline(0, color='black', linewidth=1.0, linestyle='--') ax.set_yticks(y_pos) ax.set_yticklabels(labs, fontsize=10) ax.set_xlabel('標準化偏回帰係数(95% CI)\n※ 有彩色: p<0.05 有意、グレー: 非有意', fontsize=10) ax.set_title(f'図4:{adopted_name} の回帰係数(転入率モデル)\n' f'N={int(adopted_res.nobs)}, R²={adopted_res.rsquared:.3f}' f' |出典: SSDSE-B 実データ(47都道府県×9年)', fontsize=11) ax.grid(True, axis='x', alpha=0.3) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。ax.axhline / ax.axvline— 水平/垂直の点線。平均線や基準線として定番。
np.cumsum(arr) は累積和、np.linspace(a, b, n) は「aからbを等間隔でn個」。NumPyの定石です。313 314 315 316 317 318 | # 有意性マーク for i, (b, se, p) in enumerate(zip(coefs, se_s, pvals)): sig = '***' if p < 0.001 else '**' if p < 0.01 else '*' if p < 0.05 else '' if sig: x_text = b + 1.96 * se + 0.02 ax.text(x_text, i, sig, va='center', fontsize=10, color='#C62828', fontweight='bold') |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
{値:.2f}(小数2桁)、{値:,}(3桁区切り)、{値:>10}(右寄せ10桁)など、覚えると出力が一気に整います。319 320 321 322 323 324 | # 凡例 sig_patch = mpatches.Patch(color=adopted_color, alpha=0.8, label='p<0.05 有意') nosig_patch = mpatches.Patch(color='#BDBDBD', alpha=0.8, label='p≥0.05 非有意') ax.legend(handles=[sig_patch, nosig_patch], fontsize=9, loc='lower right') plt.tight_layout() save_fig('fig4_coef') |
図4:採用モデルの係数プロット(p値・有意性付き) → 保存: html/figures/2025_U1_fig4_coef.png
- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
plt.subplots(figsize=(W, H)) で図サイズ指定、fig.savefig(..., bbox_inches='tight') で余白を自動で詰めて保存。6. 結論と考察
ここまでのFEモデルで「投票率の性差」が有意に効くなど仮説2が部分支持された結果を踏まえると、 女性議員比率は単一要因でなく、ロールモデル・有権者・制度の三つの経路で決まると考えられる。 実務的には女性が投票しやすい仕組みづくりと女性候補のロールモデル可視化を組み合わせる政策が必要であり、 本節では仮説ごとの支持の度合いと政策的含意を整理する。
6-1. 仮説別の検証結果
FEモデルでは女子大学キャンパス数は吸収されたが、隣接区女性区長数・前回女性当選率・女性管理職比率は OLS・REで正の効果。→ 部分的に支持。地域固有の文化として定着したロールモデル効果が重要。
投票率の性差(FE_1: 0.083*)が有意に正の効果。女性の投票参加が高い地域ほど女性議員が増える。 年少人口比率はFEで負(子育て中の女性が有権者として少ない?)。→ 一部支持。
FEモデルでは出産育児欠席規定が負(短期には即効性なし)。OLS・REでは子育て施設・ハラスメント防止が正。 → 制度設計は重要だが、短期効果は限定的。長期的・固定効果的に機能する。
6-2. 研究の意義と限界
意義:女性の投票参加の高さが女性議員比率を高めることを実証。 「制度設計だけでなく、それを長期的に継続することが重要」という政策的含意。
限界:10年間のデータで期間が比較的短い。内生性の問題(ラグ処理で緩和したが完全ではない)。 党派の戦略や住民の経済力なども考慮すべき。
7. データサイエンス学習まとめ
| 技術 | 内容 | Pythonでの実装 |
|---|---|---|
| パネルデータの構造 | 個体×時点の2次元データ | df.set_index(['区', '年度']) |
| Pooled OLS | 最もシンプルな回帰 | PooledOLS(y, X).fit() |
| 固定効果モデル | 不観測な地域差を統制 | PanelOLS(y, X, entity_effects=True).fit() |
| 変量効果モデル | 個別効果を確率変数として扱う | RandomEffects(y, X).fit() |
| Hausman検定 | FE vs RE のモデル選択 | χ²統計量・p値で判断 |
| ロバスト標準誤差 | 不均一分散・自己相関への対処 | cov_type='robust' |
| ラグ変数 | 逆因果を防ぐ | df.groupby('区')['X'].shift(1) |
| 変数の標準化 | 係数の比較可能性を高める | (x - x.mean()) / x.std() |
- 実データの読み込みと記述統計の確認(論文の表3-2と比較してみよう)
- 3つのモデルを推定して係数の違いを観察する
- Hausman検定の実装と結果の解釈を理解する
- 係数プロットで各変数の効果を視覚的に比較する
データ・コードをダウンロード
以下のファイルをダウンロードして同じフォルダに置き、python 2025_U1_daijin.py を実行すれば全図・全結果を再現できます。
23特別区×2015-2024年(230行)。女性議員比率・人口密度・財政力指数など。
主要出典: 内閣府男女共同参画局・住民基本台帳・総務省決算統計(一部近似値)
pandas numpy matplotlib scipy statsmodels linearmodels実行方法:
python3 2025_U1_data_prep.py → python3 2025_U1_daijin.py
- 女性議員比率:ジェンダー平等の代表指標。選挙制度・候補者選定過程・有権者意識が絡む。
- クォータ制:候補者数・議席数を性別で割り当てる制度。導入国の前後比較で効果を測れる。
- 構造的要因:個人の能力ではなく、制度・組織・文化の壁が女性参政を阻むことを統計的に示せる。