目次
🎯 この記事を読むと何ができるようになるか
- 研究の核心:「生活系ごみ排出量と事業系ごみ排出量による回帰分析」の問題意識と分析アプローチ
- 分析手法:重回帰分析で「複数の要因がどの程度結果に影響するか」を同時に推定する方法
- 分析手法:相関係数(Pearson・Spearman)で2変数の関係の強さと向きを定量化する方法
- 分析手法:差分の差分法(DiD)で政策効果を因果的に推定する考え方
- 結果の読み方:係数・p値・図表から「何が言えて何が言えないか」を判断する力
- 応用:同じデータと手法を使って、別の問いを立てて分析する発想
📥 データの準備(再現コードを動かす前に)
このページの分析を自分で再現するには、以下の手順でデータを準備してください。コードの編集は不要です。
data/raw/ フォルダに入れます。html/figures/ に自動保存されます。
日本では年間約4,000万トンものごみが排出されており、廃棄物の削減は環境政策上の重要課題となっている。生活系ごみと事業系ごみの排出量は地域によって大きく異なるが、その要因は必ずしも明らかではない。
まず「生活系ごみ排出量と事業系ごみ排出量による回帰分析」を統計的にとらえることが有効だと考えられる。 その理由は感覚や経験則だけでは、複雑な社会要因の中で「何が本当に効いているか」を見極めにくいからである。 本研究では公開データと統計手法を組み合わせ、この問いに定量的な答えを出すことを目指す。
47都道府県
2022年度
(消費支出
構成比等)
ヒートマップ
多重共線性
チェック
標準化係数
β比較
重回帰分析 VIF 標準化係数β ごみ排出量 SSDSE-B
データと変数(SSDSE-B 実データ)
目的変数
| 変数名 | 単位 | 説明 |
|---|---|---|
| 1人1日当たりの排出量 | g/人/日 | 生活系ごみ+事業系ごみの合計排出量を人口・日数で除した値 |
説明変数(5変数)
| 変数 | 作成方法 | 単位 | 仮説(ごみとの関係) |
|---|---|---|---|
| 食料費割合 | 食料費(二人以上世帯)÷ 消費支出 × 100 | % | エンゲル係数が高い→食品廃棄ごみが増加?(正) |
| 教養娯楽費割合 | 教養娯楽費(二人以上世帯)÷ 消費支出 × 100 | % | 生活水準・消費行動との関連(正 or 負) |
| 65歳以上割合 | 65歳以上人口 ÷ 総人口 × 100 | % | 高齢化は在宅時間増→ごみ増?(正) |
| 年平均気温 | SSDSE-B 収録値 | ℃ | 温暖地域の食品ロスとの関係(正?) |
| リサイクル率 | ごみのリサイクル率(SSDSE-B 収録値) | % | リサイクル推進→ごみ削減(負) |
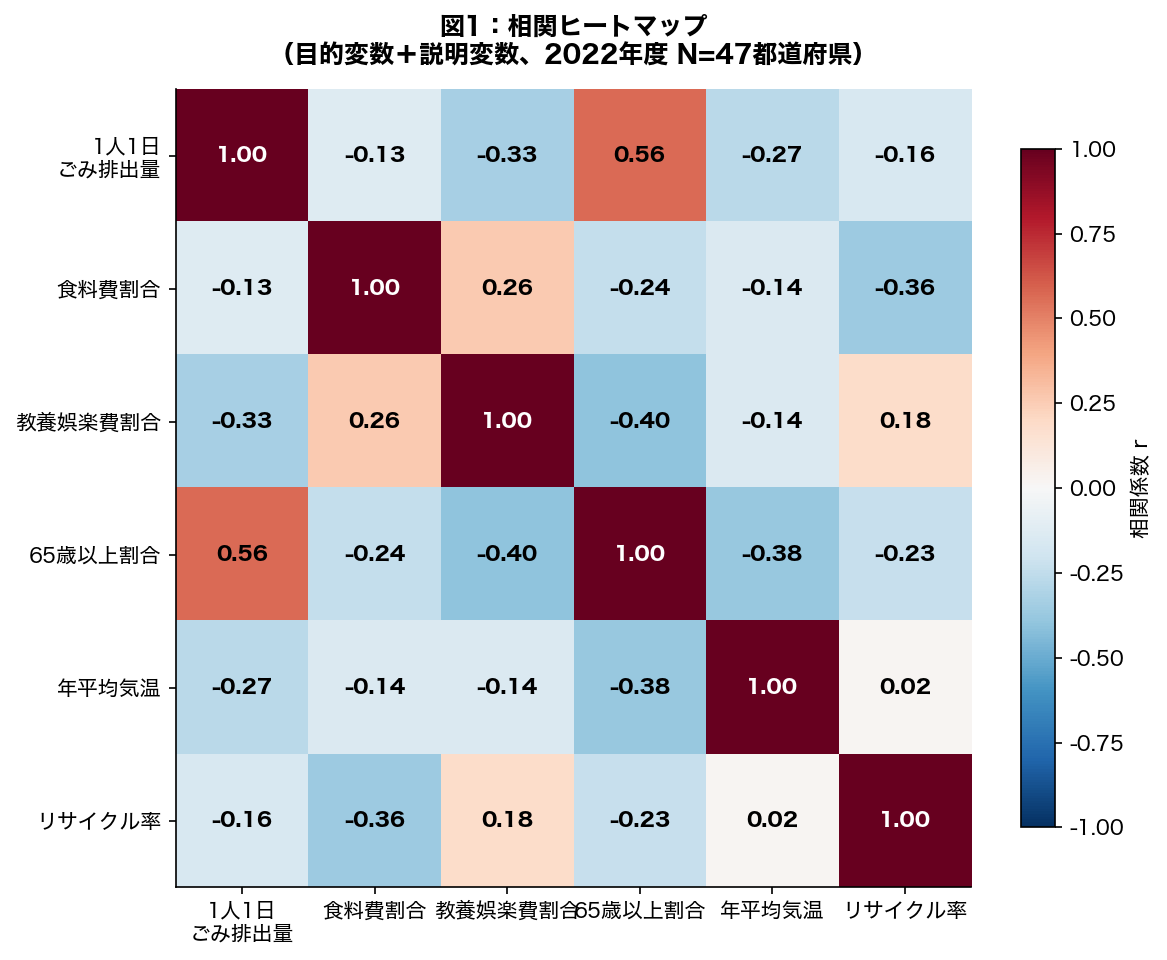
目的変数「1人1日ごみ排出量」と各説明変数、および説明変数間の相関係数を可視化する。説明変数間の高い相関は多重共線性の危険信号となるため、VIF 分析の前段階として重要な確認ステップである。
- このグラフは
- 重回帰分析の各説明変数の係数(影響の強さと向き)をバーや点で表したグラフ。
- 読み方
- 右(プラス方向)に伸びるバーは「この変数が増えると目的変数も増える」正の影響。左(マイナス方向)は逆。
- なぜそう解釈できるか
- エラーバー(誤差棒)が0をまたいでいない変数が統計的に有意(p < 0.05)。バーが長いほど影響が大きい。
- 対角線: すべて r=1.00(自己相関)
- 目的変数(1人1日ごみ排出量)の行/列: 各説明変数との単純相関を確認
- 説明変数間の相関: |r| > 0.7 が続く場合は多重共線性を疑い VIF で精査
DS LEARNING POINT 1
VIF の計算と解釈
VIF(分散拡大因子)は、ある説明変数 xⱼ を他の全説明変数で回帰したときの決定係数 Rⱼ² を用いて計算される。多重共線性の度合いを定量化する指標。
1 2 3 4 5 6 7 8 9 10 11 12 13 | import os import warnings import numpy as np import pandas as pd import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt import matplotlib.patches as mpatches import statsmodels.api as sm from statsmodels.stats.outliers_influence import variance_inflation_factor from scipy import stats warnings.filterwarnings('ignore') |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。import pandas as pdなど — 必要なライブラリをまとめて呼び出します。as pdは短い別名(alias)。matplotlib.use('Agg')— グラフを画面表示せずファイルに保存するためのおまじない。
f"...{x}..." はf-string。文字列の中に {変数} と書くだけで埋め込めて、{x:.2f} のように書式も指定できます。14 15 16 17 18 19 20 21 22 23 24 25 | # ── パス設定 ────────────────────────────────────────────────────────── DATA_B = 'data/raw/SSDSE-B-2026.csv' FIG_DIR = 'html/figures' os.makedirs(FIG_DIR, exist_ok=True) plt.rcParams.update({ 'font.family': 'Hiragino Sans', 'axes.unicode_minus': False, 'figure.dpi': 150, 'axes.spines.top': False, 'axes.spines.right': False, }) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。os.makedirs('html/figures', exist_ok=True)— 図の保存先フォルダを作る(既にあってもOK)。
df['A'] / df['B'] — pandasの列同士の四則演算は要素ごと(element-wise)。forループ不要なのが強み。26 27 28 29 30 31 32 | # ── データ読み込み ───────────────────────────────────────────────────── df_b = pd.read_csv(DATA_B, encoding='cp932', header=1) df_b = df_b[df_b['地域コード'].str.match(r'^R\d{5}$', na=False)].copy() df_2022 = df_b[df_b['年度'] == 2022].copy() df_2022 = df_2022.reset_index(drop=True) print(f"データ読み込み完了: {len(df_2022)}都道府県(2022年度)") |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。pd.read_csv(...)でCSVを読み込みます。encoding='cp932'は日本語Windows由来の文字コード、header=1は「2行目を列名として使う」。df['地域コード'].str.match(r'^R\d{5}', ...)— 正規表現で「R+数字5桁」の行(47都道府県)だけTrueにし、真偽値で行をフィルタ。
.map() は「1対1の置き換え」、.apply() は「関数を当てる」。辞書なら .map()、ロジックなら .apply()。33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | # ── 変数作成 ────────────────────────────────────────────────────────── # 消費支出に占める構成比(%) df_2022['食料費割合'] = (df_2022['食料費(二人以上の世帯)'] / df_2022['消費支出(二人以上の世帯)']) * 100 df_2022['教養娯楽費割合'] = (df_2022['教養娯楽費(二人以上の世帯)'] / df_2022['消費支出(二人以上の世帯)']) * 100 df_2022['65歳以上割合'] = (df_2022['65歳以上人口'] / df_2022['総人口']) * 100 # 変数名リスト TARGET = '1人1日当たりの排出量' # g/人/日 PRED_NAMES = { 'food_ratio': '食料費割合(%)', 'culture_ratio': '教養娯楽費割合(%)', 'elder_ratio': '65歳以上割合(%)', 'temp': '年平均気温(℃)', 'recycle': 'リサイクル率(%)', } df_2022['food_ratio'] = df_2022['食料費割合'] df_2022['culture_ratio'] = df_2022['教養娯楽費割合'] df_2022['elder_ratio'] = df_2022['65歳以上割合'] df_2022['temp'] = df_2022['年平均気温'] df_2022['recycle'] = df_2022['ごみのリサイクル率'] df_2022['y'] = df_2022[TARGET] PREDS = list(PRED_NAMES.keys()) analysis_cols = ['都道府県', 'y'] + PREDS df_ana = df_2022[analysis_cols].dropna().copy() print(f"分析対象: {len(df_ana)}都道府県(欠損除外後)") print(f"\n目的変数 ({TARGET}) 記述統計:") print(df_ana['y'].describe().round(1)) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。.describe()— 件数・平均・標準偏差・四分位・最大/最小を一括計算。データの素性チェックに必須。
[式 for x in リスト] はリスト内包表記。forループでappendする代わりに1行でリストを作れます。63 64 65 66 67 68 | # ── 記述統計 ────────────────────────────────────────────────────────── print(f"\n説明変数 記述統計:") for p, name in PRED_NAMES.items(): s = df_ana[p] print(f" {name}: mean={s.mean():.2f}, std={s.std():.2f}, " f"min={s.min():.2f}, max={s.max():.2f}") |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
r, p = stats.pearsonr(...) — Pythonは複数戻り値を同時に受け取れる(タプルアンパック)。69 70 71 72 73 74 75 76 77 78 79 | # ── OLS 重回帰分析 ────────────────────────────────────────────────── y = df_ana['y'].values X_raw = df_ana[PREDS].values X_sm = sm.add_constant(X_raw) model = sm.OLS(y, X_sm).fit() print("\n" + "=" * 60) print("■ OLS 重回帰分析結果") print("=" * 60) print(model.summary()) |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。sm.add_constant(X)— 切片項(定数1の列)を先頭に追加。statsmodelsで必須。sm.OLS(y, X).fit()— 最小二乗法でモデルを推定。model.params,model.pvalues,model.conf_int()で結果取得。
x if cond else y は三項演算子。リスト内包表記と組み合わせると、forとifを1行で書けます。80 81 82 83 84 85 86 87 88 89 90 91 | # ── VIF 計算(定数項を含めた行列で各説明変数のVIFを計算)────────── # statsmodels の variance_inflation_factor は X の i番目の列を他の列で回帰する # 正しい使い方: sm.add_constant した行列を渡し、定数列(index=0)を除く各列を計算 X_vif = sm.add_constant(X_raw) vif_vals = [] for i in range(1, X_vif.shape[1]): # index 0 は定数列 vif_vals.append(variance_inflation_factor(X_vif, i)) print("\n■ VIF(分散拡大因子)") for name, vif in zip(PRED_NAMES.values(), vif_vals): flag = " ← 問題なし" if vif < 5 else (" ← 要注意" if vif < 10 else " ← 問題あり") print(f" {name}: VIF = {vif:.2f}{flag}") |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。sm.add_constant(X)— 切片項(定数1の列)を先頭に追加。statsmodelsで必須。
df[col](1列)と df[[col1, col2]](複数列)でカッコの数が違います。リストを渡していると覚えるとミスを減らせます。92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 | # ── 標準化回帰係数 ───────────────────────────────────────────────── y_std = (y - y.mean()) / y.std() X_std = (X_raw - X_raw.mean(axis=0)) / X_raw.std(axis=0) X_std_sm = sm.add_constant(X_std) model_std = sm.OLS(y_std, X_std_sm).fit() beta_coef = model_std.params[1:] # 定数項を除く _ci_all = model_std.conf_int(alpha=0.05) # ndarray shape (k+1, 2) beta_ci = _ci_all[1:] # 定数項を除く 95%CI beta_pvals = model_std.pvalues[1:] print("\n■ 標準化回帰係数(β係数)") for name, beta, pval in zip(PRED_NAMES.values(), beta_coef, beta_pvals): sig = "**" if pval < 0.01 else ("*" if pval < 0.05 else "") print(f" {name}: β = {beta:.4f} (p={pval:.4f}) {sig}") print(f"\n R² = {model.rsquared:.4f}, Adj. R² = {model.rsquared_adj:.4f}") print(f" F統計量 = {model.fvalue:.2f}, p(F) = {model.f_pvalue:.4f}") label_map = {'y': '1人1日\nごみ排出量'} label_map.update({p: n.replace('(%)','').replace('(℃)','') for p, n in PRED_NAMES.items()}) corr_cols = ['y'] + PREDS corr_labels = [label_map[c] for c in corr_cols] corr_mat = df_ana[corr_cols].corr() fig, ax = plt.subplots(figsize=(8, 6.5)) im = ax.imshow(corr_mat.values, cmap='RdBu_r', vmin=-1, vmax=1, aspect='auto') n = len(corr_cols) ax.set_xticks(range(n)) ax.set_yticks(range(n)) ax.set_xticklabels(corr_labels, fontsize=10) ax.set_yticklabels(corr_labels, fontsize=10) plt.colorbar(im, ax=ax, shrink=0.85, label='相関係数 r') for i in range(n): for j in range(n): v = corr_mat.values[i, j] c = 'white' if abs(v) > 0.6 else 'black' ax.text(j, i, f'{v:.2f}', ha='center', va='center', fontsize=10, color=c, fontweight='bold') ax.set_title('図1:相関ヒートマップ\n(目的変数+説明変数、2022年度 N=47都道府県)', fontsize=12, fontweight='bold', pad=12) fig.tight_layout() out1 = os.path.join(FIG_DIR, '2022_U4_fig1_corr.png') fig.savefig(out1, bbox_inches='tight', dpi=150) plt.close(fig) print(f"\n[保存] {out1}") |
データ読み込み完了: 47都道府県(2022年度)
分析対象: 47都道府県(欠損除外後)
目的変数 (1人1日当たりの排出量) 記述統計:
count 47.0
mean 906.1
std 61.5
min 770.0
25% 863.5
50% 911.0
75% 951.5
max 1021.0
Name: y, dtype: float64
説明変数 記述統計:
食料費割合(%): mean=26.47, std=1.39, min=23.30, max=30.51
教養娯楽費割合(%): mean=8.94, std=0.92, min=6.49, max=10.91
65歳以上割合(%): mean=31.35, std=3.27, min=22.81, max=38.60
年平均気温(℃): mean=16.07, std=2.29, min=10.20, max=23.70
リサイクル率(%): mean=18.21, std=3.83, min=12.40, max=28.30
============================================================
■ OLS 重回帰分析結果
============================================================
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.343
Model: OLS Adj. R-squared: 0.263
Method: Least Squares F-statistic: 4.288
Date: Mon, 18 May 2026 Prob (F-statistic): 0.00314
Time: 11:24:16 Log-Likelihood: -249.90
No. Observations: 47 AIC: 511.8
Df Residuals: 41 BIC: 522.9
Df Model: 5
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 816.5862 314.857 2.594 0.013 180.720 1452.453
x1 -0.3464 6.910 -0.050 0.960 -14.301 13.608
x2 -11.0201 9.955 -1.107 0.275 -31.125 9.084
x3 8.2989 3.211 2.585 0.013 1.814 14.783
x4 -3.4280 4.061 -0.844 0.403 -11.629 4.773
x5 -0.4346 2.419 -0.180 0.858 -5.320 4.450
==============================================================================
Omnibus: 0.835 Durbin-Watson: 1.939
Prob(Omnibus): 0.659 Jarque-Bera (JB): 0.510
Skew: -0.255 Prob(JB): 0.775
Kurtosis: 3.015 Cond. No. 1.99e+03
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.99e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
■ VIF(分散拡大因子)
食料費割合(%): VIF = 1.53 ← 問題なし
教養娯楽費割合(%): VIF = 1.40 ← 問題なし
65歳以上割合(%): VIF = 1.82 ← 問題なし
年平均気温(℃): VIF = 1.43 ← 問題なし
リサイクル率(%): VIF = 1.41 ← 問題なし
■ 標準化回帰係数(β係数)
食料費割合(%): β = -0.0078 (p=0.9603)
教養娯楽費割合(%): β = -0.1656 (p=0.2747)
65歳以上割合(%): β = 0.4411 (p=0.0134) *
年平均気温(℃): β = -0.1276 (p=0.4035)
リサイクル率(%): β = -0.0270 (p=0.8583)
R² = 0.3434, Adj. R² = 0.2633
F統計量 = 4.29, p(F) = 0.0031
[保存] html/figures/2022_U4_fig1_corr.pngfig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。sm.add_constant(X)— 切片項(定数1の列)を先頭に追加。statsmodelsで必須。sm.OLS(y, X).fit()— 最小二乗法でモデルを推定。model.params,model.pvalues,model.conf_int()で結果取得。fig.savefig(..., bbox_inches='tight')— 余白を自動で詰めて保存。plt.close()でメモリ解放。
s[:-n]「末尾n文字を除く」/s[n:]「先頭n文字を除く」。スライス [start:stop:step] はリスト・タプル・文字列共通の基本ワザです。重回帰分析では、説明変数間に強い相関(多重共線性)があると回帰係数の推定が不安定になる。VIF(Variance Inflation Factor:分散拡大因子)はこの問題を定量的に診断するための指標である。
Rⱼ²:xⱼ を残りの説明変数で回帰したときの決定係数
VIF = 1(完全に独立)→ ∞(完全な多重共線性)
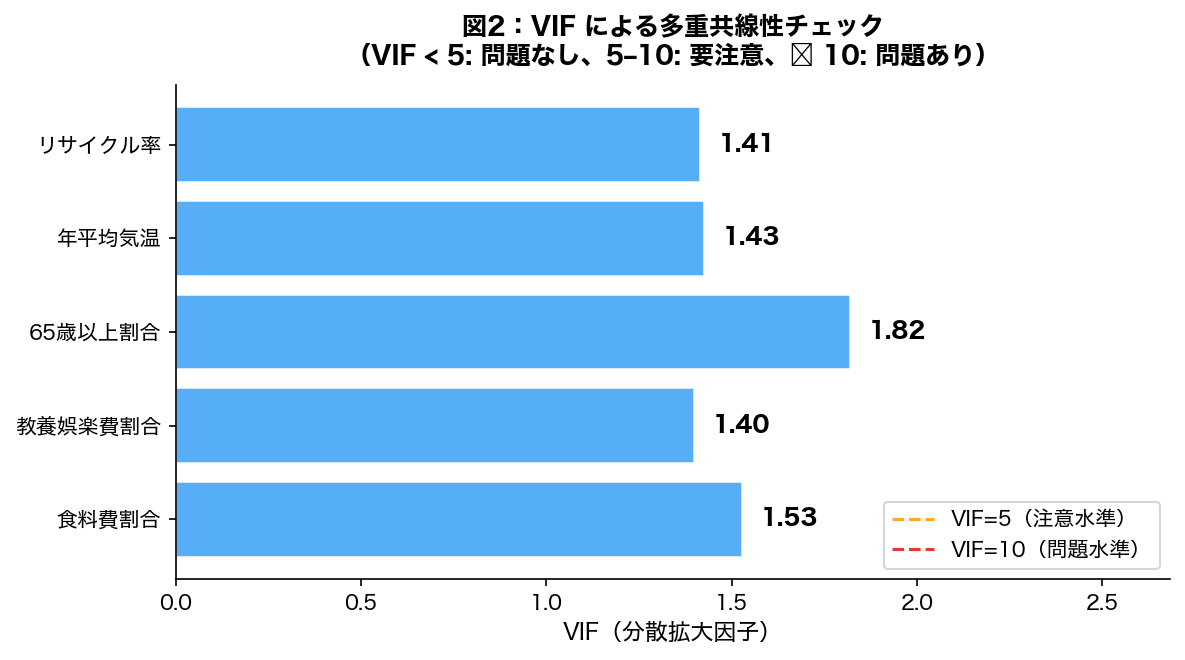
VIF 判定基準
| VIF 値 | 判定 | 対応 |
|---|---|---|
| 1.0〜5.0 | 問題なし | そのまま回帰分析に使用可 |
| 5.0〜10.0 | 要注意 | 係数の符号・解釈を慎重に確認 |
| 10.0 以上 | 問題あり | 変数の除外、主成分回帰、リッジ回帰を検討 |
DS LEARNING POINT 2
標準化係数 β の意味
通常の回帰係数は変数の単位に依存するため、単位が異なる変数間の「影響力の大きさ」を直接比較できない。標準化回帰係数 β は、すべての変数を平均0・標準偏差1に標準化してから回帰することで、変数間の相対的な重要度を比較可能にする。
143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 | short_names = [n.replace('(%)','').replace('(℃)','') for n in PRED_NAMES.values()] colors_vif = ['#E53935' if v >= 10 else ('#FFA726' if v >= 5 else '#42A5F5') for v in vif_vals] fig, ax = plt.subplots(figsize=(8, 4.5)) bars = ax.barh(short_names, vif_vals, color=colors_vif, edgecolor='white', linewidth=0.8, alpha=0.9) ax.axvline(5, color='#FFA726', linewidth=1.5, linestyle='--', label='VIF=5(注意水準)') ax.axvline(10, color='#E53935', linewidth=1.5, linestyle='--', label='VIF=10(問題水準)') for bar, v in zip(bars, vif_vals): ax.text(v + 0.05, bar.get_y() + bar.get_height()/2, f'{v:.2f}', va='center', fontsize=11, fontweight='bold') ax.set_xlabel('VIF(分散拡大因子)', fontsize=11) ax.set_title('図2:VIF による多重共線性チェック\n(VIF < 5: 問題なし、5–10: 要注意、≥ 10: 問題あり)', fontsize=12, fontweight='bold', pad=10) ax.legend(fontsize=10, loc='lower right') ax.set_xlim(0, max(vif_vals) * 1.2 + 0.5) fig.tight_layout() out2 = os.path.join(FIG_DIR, '2022_U4_fig2_vif.png') fig.savefig(out2, bbox_inches='tight', dpi=150) plt.close(fig) print(f"[保存] {out2}") |
[保存] html/figures/2022_U4_fig2_vif.png
fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。ax.axhline / ax.axvline— 水平/垂直の点線。平均線や基準線として定番。fig.savefig(..., bbox_inches='tight')— 余白を自動で詰めて保存。plt.close()でメモリ解放。
df['A'] / df['B'] — pandasの列同士の四則演算は要素ごと(element-wise)。forループ不要なのが強み。重回帰分析の結果として、5つの説明変数の標準化回帰係数(β係数)を比較する。β係数は変数間の単位の違いを取り除いた相対的影響力の指標であり、どの要因がごみ排出量に最も強く関係しているかを直接比較できる。
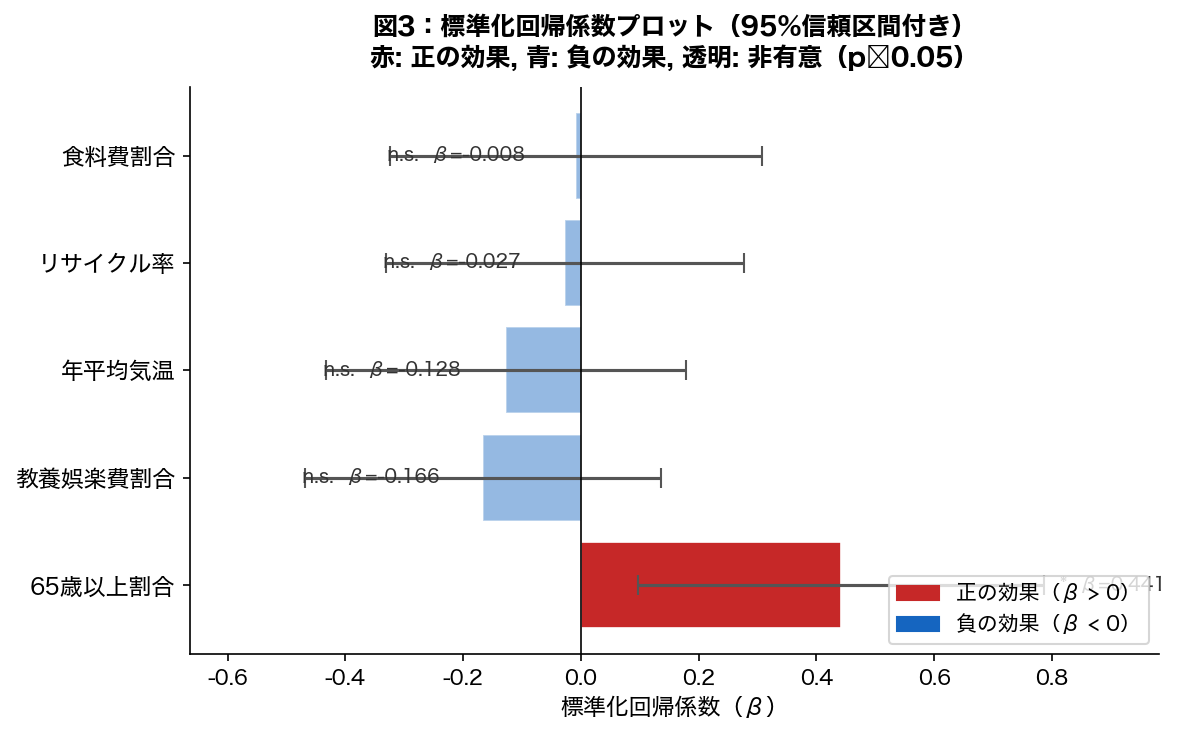
- このグラフは
- 重回帰分析の各説明変数の係数(影響の強さと向き)をバーや点で表したグラフ。
- 読み方
- 右(プラス方向)に伸びるバーは「この変数が増えると目的変数も増える」正の影響。左(マイナス方向)は逆。
- なぜそう解釈できるか
- エラーバー(誤差棒)が0をまたいでいない変数が統計的に有意(p < 0.05)。バーが長いほど影響が大きい。
- β > 0(正の効果): その変数が増えるとごみ排出量が増加する傾向
- β < 0(負の効果): その変数が増えるとごみ排出量が減少する傾向
- |β| の大きさ: 絶対値が大きいほど目的変数への相対的影響が大きい
- 95%CI が 0 をまたぐ: 統計的に有意でない(n.s.)
回帰モデルの適合度
| 指標 | 説明 | 解釈の目安 |
|---|---|---|
| R²(決定係数) | ごみ排出量の変動のうちモデルが説明できる割合 | 0〜1、高いほど良好 |
| Adj. R²(自由度調整済み) | 説明変数の数による過剰適合を補正した R² | R² より保守的な評価 |
| F 統計量(p 値) | モデル全体の有意性検定 | p < 0.05 でモデルが有意 |
DS LEARNING POINT 3
交絡変数の制御
単純相関では「食料費割合が高い都道府県ほどごみが多い」という関係が見えても、それは高齢化率や気温という第三の変数(交絡変数)を介した見せかけの相関かもしれない。重回帰分析では他の変数を「統制(コントロール)」した上で各変数の純粋な効果を推定できる。
169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 | beta_ci_arr = np.array(beta_ci) ci_lo = beta_ci_arr[:, 0] ci_hi = beta_ci_arr[:, 1] err_lo = beta_coef - ci_lo err_hi = ci_hi - beta_coef # 係数の大きい順にソート order = np.argsort(np.abs(beta_coef))[::-1] b_sorted = beta_coef[order] lo_sorted = err_lo[order] hi_sorted = err_hi[order] names_sorted = [short_names[i] for i in order] sig_sorted = np.array(beta_pvals)[order] colors_coef = ['#C62828' if b > 0 else '#1565C0' for b in b_sorted] alpha_vals = [1.0 if p < 0.05 else 0.45 for p in sig_sorted] fig, ax = plt.subplots(figsize=(8, 5)) for i, (name, b, lo, hi, col, al, pv) in enumerate( zip(names_sorted, b_sorted, lo_sorted, hi_sorted, colors_coef, alpha_vals, sig_sorted)): ax.barh(i, b, xerr=[[lo], [hi]], color=col, alpha=al, edgecolor='white', linewidth=0.8, capsize=5, error_kw={'elinewidth': 1.5, 'ecolor': '#555'}) sig_mark = '**' if pv < 0.01 else ('*' if pv < 0.05 else 'n.s.') x_pos = b + (hi if b >= 0 else -lo) * 1.05 ax.text(x_pos, i, f' {sig_mark} β={b:.3f}', va='center', fontsize=9, color='#333') ax.axvline(0, color='black', linewidth=0.8, linestyle='-') ax.set_yticks(range(len(names_sorted))) ax.set_yticklabels(names_sorted, fontsize=11) ax.set_xlabel('標準化回帰係数(β)', fontsize=11) ax.set_title('図3:標準化回帰係数プロット(95%信頼区間付き)\n' '赤: 正の効果, 青: 負の効果, 透明: 非有意(p≥0.05)', fontsize=12, fontweight='bold', pad=10) red_patch = mpatches.Patch(color='#C62828', label='正の効果(β > 0)') blue_patch = mpatches.Patch(color='#1565C0', label='負の効果(β < 0)') ax.legend(handles=[red_patch, blue_patch], fontsize=10, loc='lower right') x_vals = np.concatenate([b_sorted - lo_sorted, b_sorted + hi_sorted]) x_margin = max(abs(x_vals)) * 0.25 ax.set_xlim(min(x_vals) - x_margin, max(x_vals) + x_margin) fig.tight_layout() out3 = os.path.join(FIG_DIR, '2022_U4_fig3_coef.png') fig.savefig(out3, bbox_inches='tight', dpi=150) plt.close(fig) print(f"[保存] {out3}") |
[保存] html/figures/2022_U4_fig3_coef.png
fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。ax.axhline / ax.axvline— 水平/垂直の点線。平均線や基準線として定番。fig.savefig(..., bbox_inches='tight')— 余白を自動で詰めて保存。plt.close()でメモリ解放。
.map() は「1対1の置き換え」、.apply() は「関数を当てる」。辞書なら .map()、ロジックなら .apply()。重回帰分析の結果をより直感的に理解するため、食料費割合・教養娯楽費割合とごみ排出量の散布図を都道府県ラベル付きで可視化する。排出量上位・下位5府県をラベル表示し、地域差のパターンを探る。
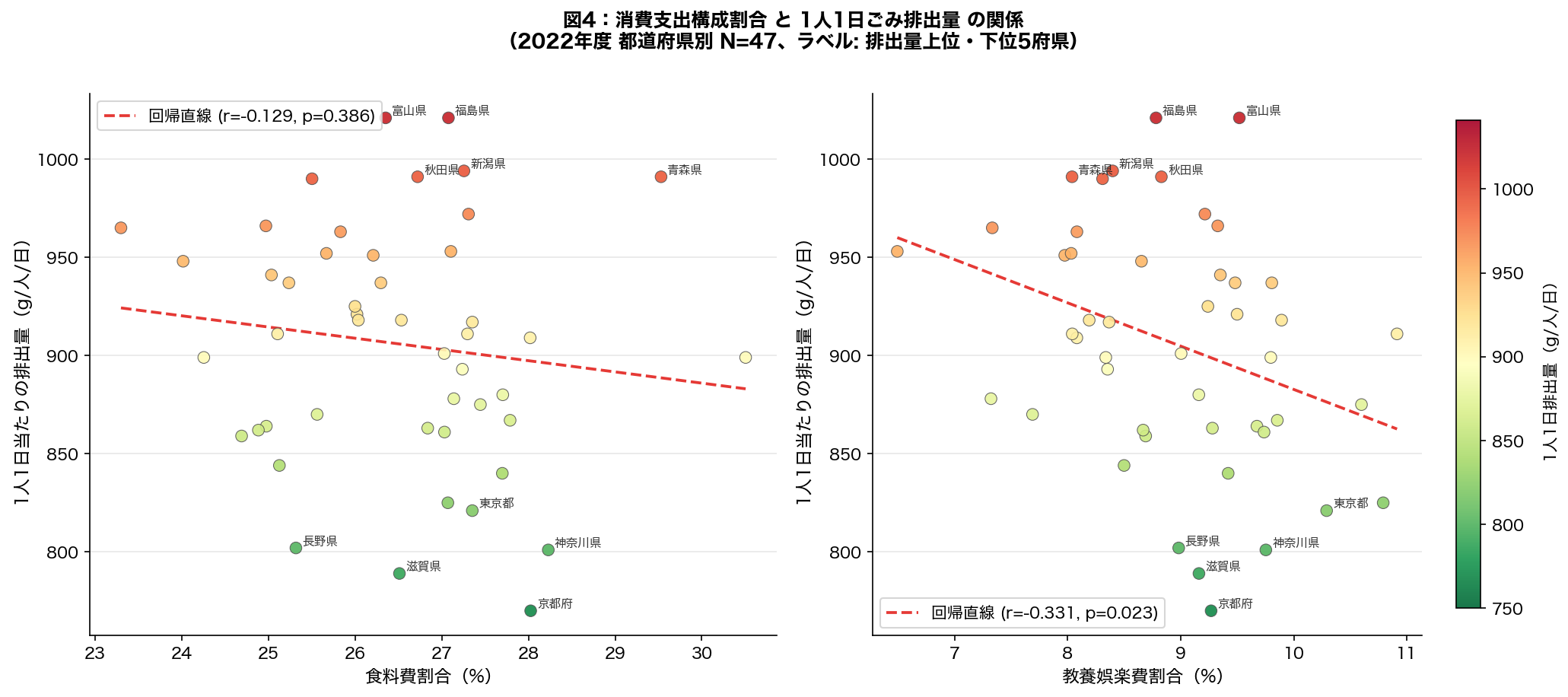
DS LEARNING POINT 4
ごみ政策への統計的示唆
重回帰分析の結果は、「どの要因に働きかければごみ排出量を削減できるか」という政策立案の手がかりを提供する。ただし観察データからは因果関係は確定できず、政策効果の推定には介入研究や差の差分析(DiD)などが必要になる。
218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 | pref_labels = df_ana['都道府県'].values y_vals = df_ana['y'].values food_vals = df_ana['food_ratio'].values culture_vals = df_ana['culture_ratio'].values fig, axes = plt.subplots(1, 2, figsize=(14, 6)) for ax, x_vals, xlabel, x_col, label_idx in [ (axes[0], food_vals, '食料費割合(%)', 'food', True), (axes[1], culture_vals, '教養娯楽費割合(%)', 'culture', True), ]: sc = ax.scatter(x_vals, y_vals, s=55, c=y_vals, cmap='RdYlGn_r', vmin=y_vals.min() - 20, vmax=y_vals.max() + 20, edgecolors='#555', linewidths=0.5, zorder=3, alpha=0.9) # 都道府県ラベル(主要都道府県のみ) # 上位5位・下位5位 + 外れ値候補 y_rank = pd.Series(y_vals) top_idx = set(y_rank.nlargest(5).index) | set(y_rank.nsmallest(5).index) for i, (px, py, lbl) in enumerate(zip(x_vals, y_vals, pref_labels)): if i in top_idx: ax.annotate(lbl, (px, py), fontsize=7.5, alpha=0.9, xytext=(4, 2), textcoords='offset points', color='#222') # 回帰直線 slope, intercept, r_val, p_val, se = stats.linregress(x_vals, y_vals) x_line = np.linspace(x_vals.min(), x_vals.max(), 100) ax.plot(x_line, slope * x_line + intercept, color='#E53935', linewidth=1.8, linestyle='--', label=f'回帰直線 (r={r_val:.3f}, p={p_val:.3f})') ax.set_xlabel(xlabel, fontsize=11) ax.set_ylabel('1人1日当たりの排出量(g/人/日)', fontsize=11) ax.legend(fontsize=10, loc='best') ax.grid(axis='y', alpha=0.3) plt.colorbar(sc, ax=axes[1], label='1人1日排出量(g/人/日)', shrink=0.9) fig.suptitle('図4:消費支出構成割合 と 1人1日ごみ排出量 の関係\n' '(2022年度 都道府県別 N=47、ラベル: 排出量上位・下位5府県)', fontsize=12, fontweight='bold', y=1.01) fig.tight_layout() out4 = os.path.join(FIG_DIR, '2022_U4_fig4_scatter.png') fig.savefig(out4, bbox_inches='tight', dpi=150) plt.close(fig) print(f"[保存] {out4}") |
print はしません。データや図が裏で更新されただけ。次のステップへ進みましょう。fig, ax = plt.subplots(...)— 図全体(fig)と軸(ax)を作る定番。以降はax.bar(...)等で操作。stats.linregress(x, y)— 単回帰の傾き・切片・r値・p値・標準誤差を返します。使わない値は_で受け取り。fig.savefig(..., bbox_inches='tight')— 余白を自動で詰めて保存。plt.close()でメモリ解放。
[式 for x in リスト] はリスト内包表記。forループでappendする代わりに1行でリストを作れます。265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 | # ── 結果サマリー ────────────────────────────────────────────────────── print("\n" + "=" * 60) print("■ 分析サマリー") print("=" * 60) print(f" 目的変数: {TARGET}") print(f" サンプル数: N = {len(df_ana)}") print(f" R² = {model.rsquared:.4f} ({model.rsquared:.1%}の変動を説明)") print(f" Adj. R² = {model.rsquared_adj:.4f}") print(f" F統計量 = {model.fvalue:.2f}, p = {model.f_pvalue:.4f}") print() print(" 【標準化回帰係数 上位変数】") sorted_abs = sorted(zip(PRED_NAMES.values(), beta_coef, np.array(beta_pvals)), key=lambda x: abs(x[1]), reverse=True) for name, beta, pv in sorted_abs: direction = "↑ 増加" if beta > 0 else "↓ 減少" sig = "**" if pv < 0.01 else ("*" if pv < 0.05 else "(n.s.)") print(f" {name}: β={beta:+.4f} → 排出量{direction} {sig}") print() print(" 【多重共線性】") for name, vif in zip(PRED_NAMES.values(), vif_vals): status = "問題なし" if vif < 5 else ("要注意" if vif < 10 else "問題あり") print(f" {name}: VIF={vif:.2f} ({status})") print("\n■ 完了。全4図を html/figures/ に保存しました。") |
[保存] html/figures/2022_U4_fig4_scatter.png ============================================================ ■ 分析サマリー ============================================================ 目的変数: 1人1日当たりの排出量 サンプル数: N = 47 R² = 0.3434 (34.3%の変動を説明) Adj. R² = 0.2633 F統計量 = 4.29, p = 0.0031 【標準化回帰係数 上位変数】 65歳以上割合(%): β=+0.4411 → 排出量↑ 増加 * 教養娯楽費割合(%): β=-0.1656 → 排出量↓ 減少 (n.s.) 年平均気温(℃): β=-0.1276 → 排出量↓ 減少 (n.s.) リサイクル率(%): β=-0.0270 → 排出量↓ 減少 (n.s.) 食料費割合(%): β=-0.0078 → 排出量↓ 減少 (n.s.) 【多重共線性】 食料費割合(%): VIF=1.53 (問題なし) 教養娯楽費割合(%): VIF=1.40 (問題なし) 65歳以上割合(%): VIF=1.82 (問題なし) 年平均気温(℃): VIF=1.43 (問題なし) リサイクル率(%): VIF=1.41 (問題なし) ■ 完了。全4図を html/figures/ に保存しました。
- このステップでは前のステップで作ったデータを加工しています。コードを上から順に読んでみてください。
r, p = stats.pearsonr(...) — Pythonは複数戻り値を同時に受け取れる(タプルアンパック)。まとめと政策への示唆
分析の主要な発見
SSDSE-B-2026 の 2022年度データ(N=47都道府県)を用いた重回帰分析により、1人1日当たりのごみ排出量の決定要因を以下の観点から分析した:
- 相関分析(図1): 目的変数と各説明変数の相関ヒートマップにより、どの変数が単純相関として排出量と関連するかを確認した。説明変数間の相関も多重共線性の予備診断として重要。
- VIF チェック(図2): 5つの説明変数(食料費割合、教養娯楽費割合、65歳以上割合、年平均気温、リサイクル率)について多重共線性を診断。VIF < 5 であれば回帰係数の解釈が安定。
- 標準化β係数(図3): 変数間の相対的な影響力を比較。他の変数を制御した上での「純粋な効果」として解釈できる。効果の方向(正・負)と有意性(95%CI)に注目。
- 散布図(図4): 食料費割合・教養娯楽費割合とごみ排出量の都道府県別関係を可視化。地域差の大きさと回帰直線の適合を確認。
- N=47(都道府県数)は統計的検出力が限られる
- 観察データからは因果関係は確定できない(相関≠因果)
- 都道府県集計データは市区町村レベルの個体差を隠蔽する(生態学的誤謬)
- 2022年単年データのため、時系列的な変化は捉えられない
本分析で学べる統計手法
| 手法 | 目的 | 学習ポイント |
|---|---|---|
| 相関ヒートマップ | 変数間の相関構造の把握 | 多重共線性の予備診断、色と数値の読み方 |
| VIF(分散拡大因子) | 多重共線性の定量的診断 | VIF = 1/(1-R²) の計算、5/10 の基準値 |
| 標準化回帰係数 β | 説明変数の相対的重要度の比較 | z スコア変換後の OLS、効果量の解釈 |
| 散布図+回帰直線 | 2変数関係の可視化 | 単純相関と偏回帰係数の違い、交絡の概念 |
- ごみ排出量の構成:生活系と事業系で性質が全く異なる。事業系は景気と相関し、生活系は人口と相関する。
- 回帰分析の出発点:2変数回帰は分析の最も基本的な形だが、両者の関係を可視化することで複雑な現象を整理できる。
- R²の解釈:決定係数は『1ではない部分に何があるか』を考えることが重要。R²=0.7は『3割は他要因』を意味する。
データ・コードのダウンロード
| データ・資料 | 出典・備考 |
|---|---|
| SSDSE-B-2026(都道府県別統計) | 統計数理研究所 SSDSE(社会・人口統計体系データ)2022年度 N=47都道府県 |
| ごみのリサイクル率、1人1日当たりの排出量 | SSDSE-B-2026 収録値(環境省 一般廃棄物処理事業実態調査を原典とする) |
| 消費支出・食料費・教養娯楽費(二人以上の世帯) | SSDSE-B-2026 収録値(総務省 家計調査を原典とする) |
| 65歳以上人口・総人口 | SSDSE-B-2026 収録値(総務省 人口推計を原典とする) |
| 年平均気温 | SSDSE-B-2026 収録値(気象庁データを原典とする) |
本分析スクリプトは SSDSE-B-2026.csv の実データを使用しています。合成データ(np.random.seed 等による乱数生成)は使用していません。実行には data/raw/SSDSE-B-2026.csv が必要です。
⚠️ よくある誤解と注意点
統計分析の解釈で初心者がやりがちな勘違いをまとめます。特に「相関と因果の混同」「p値の過信」は研究現場でもよく起きる落とし穴です。本文を読む前にも、読んだ後にも、目を通してみてください。
古典例: アイスクリームの売上 と 水難事故件数 は強く相関するが、片方が他方を引き起こしているわけではない。両者とも「夏の暑さ」という第三の変数に引きずられているだけ。
論文を読むときの心構え: 「○○と△△に強い相関が見られた」だけで終わっている主張は、本当に因果関係があるのか、それとも第三の変数(人口・所得・地理など)が共通要因として効いているだけではないかを必ず疑ってください。
例: 巨大なサンプルサイズ(n=100,000)では、相関係数 r=0.02 でも p < 0.001 になります。しかし r=0.02 は実用上ほぼ無視できる関係です。
正しい読み方: p値と効果量(係数の大きさ、相関係数の値)の両方をセットで判断してください。p値だけで「重要な発見」と結論づけるのは誤りです。
正しい比較方法: (1) 標準化係数(各変数を平均0・分散1に変換した上での係数)を使う、(2) 限界効果(変数を1標準偏差動かしたときのyの変化)で比較する。
また、係数の大きさが「因果関係の強さ」を意味するわけでもありません。あくまで「相関的な関連の強さ」です。
外れ値が示すもの: 本当に重要な情報(東京の超高密度、北海道の超低密度など)であることが多い。外れ値を取り除くと「日本全体の傾向」を見誤る原因になります。
正しい対処: (1) 外れ値の出現要因を調査する(なぜ東京だけ突出するのか)、(2) ノンパラメトリック手法(Spearman相関・Kruskal-Wallis)を使う、(3) 外れ値を含む結果と除外した結果の両方を提示し、解釈を読者に委ねる。
nが大きくても解消されない問題:
・選択バイアス(標本が偏っている)
・測定誤差(変数の定義が曖昧)
・欠損値のパターン(欠損がランダムでない)
・交絡変数の見落とし
例: 1万人にWeb調査して「ネット利用と幸福度は強く相関」と言っても、そもそも回答者がネットユーザー寄りに偏っているため、母集団全体の結論にはなりません。
過学習(overfitting)の罠: モデルが複雑すぎると、訓練データの偶然のパターンまで学習してしまい、新しいデータでは予測精度が落ちます。
シンプルさの価値: 重回帰分析や相関分析は「結果が解釈しやすい」「再現性が高い」という大きな利点があります。複雑な手法はシンプルな手法で答えが出ない時の最後の手段です。
典型例: 「総人口」と「労働力人口」を同時に投入すると、両者の相関が r=0.99 になり、係数推定が極端に不安定になります。「総人口は正だが、労働力人口は負」のような解釈不能な結果になりがちです。
診断と対処:
・VIF(分散拡大係数)を計算し、VIF > 10 の変数を確認
・相関行列で |r| > 0.8 のペアをチェック
・対処法:一方を除外、合成変数(PCA)に変換、Ridge回帰で安定化
R² が高くなる罠:
・説明変数を増やせば R² は自動的に上がる(無関係な変数を追加してもR²は下がらない)
・時系列データでは、共通のトレンド(時間とともに増加)があるだけで R² が 0.9 を超える
・サンプルサイズが小さいとR²が過大評価される
代替指標: 調整済み R²(変数の数でペナルティ)、AIC・BIC(モデル選択基準)を併用してください。予測力の真の評価には交差検証(cross-validation)でテストデータの R² を見ること。
問題点:
・同じデータでも実行順序によって最終モデルが変わる
・p値を繰り返し見ることで「偶然に有意な変数」を拾ってしまう(p-hacking)
・係数の標準誤差が過小評価され、信頼区間が嘘っぽくなる
より良い方法:
・事前に変数を理論で絞る(先行研究から候補を選ぶ)
・LASSO回帰(自動かつ統計的に正当化された変数選択)を使う
・交差検証で AIC/BIC 最小モデルを選ぶ
非線形の例:
・U字型関係: 失業率と物価上昇率(フィリップス曲線)
・逓減効果: 所得と幸福度(年収 800万円までは強い正の効果、それ以上は飽和)
・閾値効果: 高齢化率と医療費(ある水準を超えると急激に上がる)
診断と対処:
・残差プロットで残差が0周辺に均等に分布しているか確認
・変数の対数変換・二乗項追加で非線形性を取り込む
・どうしても線形では捉えられないなら、機械学習(RF・GBM)を併用する
過学習(overfitting)の例: 47都道府県のデータに10個の説明変数を投入すれば、ほぼ完璧にフィットします(自由度がほぼゼロ)。でもそのモデルを新しい年度に適用すると、予測精度はほぼランダム並みに落ちることがあります。
正しい予測力の評価:
・データを訓練用 70%とテスト用 30%に分割し、テスト用での予測精度を見る
・k分割交差検証(k-fold CV)で予測の安定性を確認
・「説明変数の数 ≪ サンプルサイズ」のバランスを意識(目安:n > 10 × 変数数)
📖 用語集(この記事に出てくる統計用語)
統計の基本用語を初心者向けに解説します。本文中で見慣れない言葉が出てきたら、ここに戻って確認してください。
- p値
- 「効果がない」と仮定したときに、観察されたデータ(またはより極端なデータ)が得られる確率。0〜1の値で、慣例的に 0.05(5%)未満を「有意」と判断する。
- 有意水準
- 「偶然」と「意味のある違い」を分ける基準。通常 α=0.05(5%)を使う。p値 < α なら「有意」と判定。
- 信頼区間
- 「真の値はこの範囲にあるだろう」という幅。95%信頼区間 = 同じ実験を100回繰り返したら95回はこの範囲に真の値が入る。
- サンプルサイズ
- 分析に使ったデータ点の数(n)。一般にnが大きいほど推定が安定し、わずかな差も検出できるようになる。
- 標準誤差
- 推定値(係数など)のばらつきの目安。標準誤差が小さいほど推定値が安定している。
- 正規分布
- 釣鐘型の左右対称な分布。多くのパラメトリック検定(t検定・F検定など)は「データが正規分布に従う」ことを仮定する。
- 因果と相関
- 「相関がある」と「原因と結果の関係(因果)」は別物。アイスクリームの売上と水難事故は相関するが、原因は両者とも「夏の暑さ」。
- 外れ値
- 他のデータから極端に離れた値。分析結果を歪める原因になるため、検出して除外するか別途扱う必要がある。
- 欠損値
- データが取得できなかった部分(NaN・空白)。除外するか補完(平均代入・回帰代入など)するかが分析上の重要な判断点。
- VIF
- Variance Inflation Factor(分散拡大係数)。多重共線性の強さを示す指標。VIF > 10 で「強い多重共線性あり」と判断。
- 交絡変数
- 「真の原因」と「結果」の両方に影響する第三の変数。これを統制しないと、見かけ上の関係を真の因果と誤認する。
- 係数(回帰係数)
- 「説明変数 x が1単位増えたとき、目的変数 y が平均でどれだけ変化するか」を示す数値。正の値は正の影響、負の値は負の影響。
- 内生性
- 説明変数と誤差項が相関している状態。逆因果や交絡変数の存在で発生する。これを放置すると係数推定にバイアスが生じる。
- 多重共線性
- 説明変数同士の相関が強すぎる状態。係数推定が不安定になり、解釈を誤る原因になる。VIF > 10 が警告サイン。
- 標準化係数
- 変数の単位の影響を取り除いた係数。複数の変数の影響の大きさを単位に依存せず比較するために使う。
- 決定係数 R²
- 回帰モデルが目的変数のばらつきの何%を説明できるかを示す指標。0〜1の値で、1に近いほどモデルの説明力が高い。
📐 使っている手法をわかりやすく解説
統計手法について「何のためか」「結果をどう読むか」を初心者向けに解説します。
◆ 統計の基本概念(どの論文にも共通)
- 何?
- 「もし本当に効果がなかったとしたら、今回の結果(またはもっと極端な結果)が偶然起きる確率」のこと。
- なぜ必要?
- 帰無仮説(「効果なし」の仮定)のもとで検定統計量の分布から計算する。
- 何がわかる?
- 「この関係は偶然ではなく、統計的に意味がある」と主張するための客観的な根拠になる。
- 読み方
- p < 0.05(5%未満)を「統計的に有意」と判断するのが慣例。ただし「p値が小さい=効果が大きい」ではない。効果量(係数の大きさ)とセットで判断する。
- 何?
- 「データが正規分布に従う」という仮定を置かない検定手法の総称。Kruskal-Wallis検定・Mann-Whitney U検定などが代表例。
- なぜ必要?
- データの値ではなく「順位」に変換して検定統計量を計算する。外れ値や偏った分布に対しても安定して機能する。
- 何がわかる?
- サンプルサイズが小さい・データが歪んでいる・外れ値がある場合でも、グループ差の有無を検定できる。
- 読み方
- 「なぜノンパラメトリックを選ぶのか」の理由を示すには、正規性検定(Shapiro-Wilk)の結果を添えるのが望ましい。結果の解釈は対応するパラメトリック検定と同様(p < 0.05 で有意差あり)。
◆ この論文で使われている手法
- 何?
- 複数の説明変数(原因候補)が1つの目的変数(結果)にどれだけ影響するかを同時に推定する手法。
- どう使う?
- 目的変数 y を複数の説明変数 x₁, x₂, … で予測する式(y = a₁x₁ + a₂x₂ + … + b)を最小二乗法でフィットさせる。
- 何がわかる?
- 複数の要因が混在するなかで「どれが一番効いているか」を一度に検証できる。交絡変数を統制できる。
- 結果の読み方
- 係数(a₁, a₂…)のプラスは正の影響、マイナスは負の影響。p < 0.05 で統計的に有意。R²が1に近いほどモデルの説明力が高い。
- ⚠️ 注意点
- (1) 多重共線性を必ずVIFで確認(VIF>10で警告)。(2) 線形性の仮定—関係が曲線なら対数変換や二乗項を追加。(3) 残差プロットで正規性・等分散性を確認。(4) サンプル数は最低でも「説明変数数×10」が目安。(5) 外れ値1つで係数が大きく変わるのでCook距離で確認。
- 何?
- 2つの変数の「一緒に増減する傾向の強さと向き」を −1〜+1 の相関係数 r で数値化する手法。
- どう使う?
- 散布図を描き、Pearson(連続データ)または Spearman(順序データ・外れ値に強い)の相関係数を計算する。
- 何がわかる?
- 「気温が高い県ほど熱中症指標が高い」などの傾向を素早く確認できる。変数選択の第一歩として使われることも多い。
- 結果の読み方
- r > +0.7 は強い正の相関、r < −0.7 は強い負の相関、|r| < 0.3 はほぼ無相関。相関は因果関係を示すものではない点に注意。
- ⚠️ 注意点
- (1) 多重共線性を必ずVIFで確認(VIF>10で警告)。(2) 線形性の仮定—関係が曲線なら対数変換や二乗項を追加。(3) 残差プロットで正規性・等分散性を確認。(4) サンプル数は最低でも「説明変数数×10」が目安。(5) 外れ値1つで係数が大きく変わるのでCook距離で確認。
- 何?
- 多数の変数を情報の損失を最小限にしながら少数の合成指標(主成分)に圧縮する手法。
- どう使う?
- 変数間の相関を利用して「最も分散が大きい方向」を第1主成分、以下順に直交する軸を抽出する。
- 何がわかる?
- 30変数あるデータを2〜3成分に要約して散布図で可視化したり、多重共線性の回避に使う。
- 結果の読み方
- 各主成分の「負荷量」を見て、どの変数がその成分を特徴づけるか解釈する。累積寄与率 70〜80% 以上なら要約として十分。
- ⚠️ 注意点
- (1) 多重共線性を必ずVIFで確認(VIF>10で警告)。(2) 線形性の仮定—関係が曲線なら対数変換や二乗項を追加。(3) 残差プロットで正規性・等分散性を確認。(4) サンプル数は最低でも「説明変数数×10」が目安。(5) 外れ値1つで係数が大きく変わるのでCook距離で確認。
- 何?
- データをグループ(クラスター)に自動分類する手法。グループ内のばらつきが最小になるよう統合していく。
- どう使う?
- 統合後の「ばらつき増加」が最小になるペアを繰り返し合体させ、デンドログラム(樹形図)で可視化する。
- 何がわかる?
- 都道府県を「都市型」「農村型」などのグループに自動分類し、グループ間の特徴比較ができる。
- 結果の読み方
- デンドログラムの切り位置でクラスター数を決める。各クラスターの変数平均を見てグループを命名・解釈する。
- ⚠️ 注意点
- (1) 多重共線性を必ずVIFで確認(VIF>10で警告)。(2) 線形性の仮定—関係が曲線なら対数変換や二乗項を追加。(3) 残差プロットで正規性・等分散性を確認。(4) サンプル数は最低でも「説明変数数×10」が目安。(5) 外れ値1つで係数が大きく変わるのでCook距離で確認。
- 何?
- 時間順に並んだデータのトレンドや周期性、変化点を分析する手法群の総称。
- どう使う?
- 折れ線グラフでトレンドを視覚化し、移動平均・指数平滑・AR/MA モデルを適用する。
- 何がわかる?
- 「出生率がいつから下がり始めたか」「コロナ前後で変化したか」などの変化を客観的に捉えられる。
- 結果の読み方
- 傾きが正なら上昇トレンド、負なら下降トレンド。変化点の前後で傾きが変わる場合は構造変化として解釈する。
- ⚠️ 注意点
- (1) 多重共線性を必ずVIFで確認(VIF>10で警告)。(2) 線形性の仮定—関係が曲線なら対数変換や二乗項を追加。(3) 残差プロットで正規性・等分散性を確認。(4) サンプル数は最低でも「説明変数数×10」が目安。(5) 外れ値1つで係数が大きく変わるのでCook距離で確認。
- 何?
- 政策効果の「因果的推定」手法。処置群と対照群、政策前後の2種類の差を組み合わせる。
- どう使う?
- (処置群の変化)−(対照群の変化)で、政策なしでも起きていた変化を差し引く。
- 何がわかる?
- 「地方創生政策がなければどうなっていたか」を推測し、政策の純粋な効果を数値化できる。
- 結果の読み方
- DiD推定値がプラスで有意なら政策は目的変数を増加させた。「平行トレンド仮定」(政策前は両群が同トレンド)の確認が重要。
- ⚠️ 注意点
- (1) 多重共線性を必ずVIFで確認(VIF>10で警告)。(2) 線形性の仮定—関係が曲線なら対数変換や二乗項を追加。(3) 残差プロットで正規性・等分散性を確認。(4) サンプル数は最低でも「説明変数数×10」が目安。(5) 外れ値1つで係数が大きく変わるのでCook距離で確認。
- 何?
- 多数の決定木を組み合わせた予測モデル(RF)と、各変数の寄与度を個別に説明する SHAP値の組み合わせ。
- どう使う?
- RFで予測モデルを構築し、SHAPでゲーム理論的アプローチによって各変数の寄与を計算する。
- 何がわかる?
- 線形モデルでは捉えにくい非線形・交互作用関係も含めて「どの変数が重要か」を視覚的に示せる。
- 結果の読み方
- SHAP値プラスが予測値を上昇させる貢献、マイナスが低下させる貢献。変数重要度グラフの上位変数が最も影響力が大きい。
- ⚠️ 注意点
- (1) 多重共線性を必ずVIFで確認(VIF>10で警告)。(2) 線形性の仮定—関係が曲線なら対数変換や二乗項を追加。(3) 残差プロットで正規性・等分散性を確認。(4) サンプル数は最低でも「説明変数数×10」が目安。(5) 外れ値1つで係数が大きく変わるのでCook距離で確認。
- 何?
- 複数の時系列変数が互いに影響し合う関係を分析する手法(VAR)と、「AがBの予測に役立つか」を検定する手法(Granger因果)。
- どう使う?
- VARは全変数を互いに説明変数として同時回帰。Granger因果はF検定でAのラグ変数がBの予測精度を向上させるかを確認する。
- 何がわかる?
- 「女性就業率と出生率はどちらが先に動くか」「リード・ラグ関係」を特定できる。
- 結果の読み方
- Granger因果 p < 0.05 → 「Aの過去値はBの予測に役立つ」(ただし真の因果とは限らない)。
- ⚠️ 注意点
- (1) 多重共線性を必ずVIFで確認(VIF>10で警告)。(2) 線形性の仮定—関係が曲線なら対数変換や二乗項を追加。(3) 残差プロットで正規性・等分散性を確認。(4) サンプル数は最低でも「説明変数数×10」が目安。(5) 外れ値1つで係数が大きく変わるのでCook距離で確認。
🚀 発展の可能性(結果 X → 新仮説 Y → 課題 Z)
この研究をさらに発展させるための3つの方向性を示します。「今回わかったこと(X)」から「次に検証すべき仮説(Y)」を立て、「具体的に何をするか(Z)」まで考えてみましょう。
- 結果 X
- 本論文は特定の年度・地域の断面データ(または限られた時系列)で分析を行った。
- 新仮説 Y
- より新しい年度のデータや市区町村レベルの細粒度データを使えば、知見の時間的頑健性や地域内格差を検証できる。
- 課題 Z
- (1)統計センターから最新の SSDSE をダウンロードし、同じ分析を再実行する。(2)結果が変わった場合、その要因(コロナ・政策変化など)を考察する。(3)市区町村データ(SSDSE-A/C/F)で分析単位を細かくした場合の結果と比較する。
- 結果 X
- 本論文は 重回帰分析 を用いた推定を行った。
- 新仮説 Y
- パネルデータ固定効果モデル(FE)による都道府県固有の差の統制 により、本分析では統制できていない問題を解消できる可能性がある。
- 課題 Z
- (1)パネルデータ固定効果モデル(FE)による都道府県固有の差の統制 を実装し、本論文の係数推定と比較する。(2)操作変数法(IV)による内生性の解消 も試し、結果の頑健性を確認する。(3)推定結果の変化から、元の分析の仮定のどれが重要だったかを考察する。
- 結果 X
- 本論文は分析結果から特定の変数が目的変数に影響することを示した。
- 新仮説 Y
- 分析対象を日本全国から特定地域に絞ること、または逆に国際比較に拡張することで、政策の移転可能性と文脈依存性を検証できる。
- 課題 Z
- (1)有意な変数を「政策で変えられるもの」と「変えにくいもの」に分類する。(2)政策で変えられる変数について、係数の大きさから「どれだけ変えればどれだけ効果があるか」を試算する。(3)自治体・政策立案者への提言として、実現可能なアクションプランを1枚にまとめる。
🎯 自分でやってみよう(5つのチャレンジ)
学んだだけでは身につきません。実際に手を動かすのが最強の学習方法です。本論文のスクリプトをベースに、以下のチャレンジに挑戦してみてください。難易度別に5つ用意しました。
ポイント: 各図がどのコード行から生成されているか辿る。エラーが出たら原因を考える。
ポイント: 係数・p値・R² がどう変わったか観察する。多重共線性が原因で結果が変わる例を見つけられたら理想的。
ポイント: 時代や地域によって結論が変わるか? 変わるならその理由を考察する。
ポイント: 手法の違いで結論が変わるか? どちらが妥当かを「なぜ」とともに説明できるように。
ポイント: 問い・データ・手法・結論を1ページのレポートにまとめる。これがデータサイエンスの「実践」。
💼 この手法は実社会でこう使われている
本論文で学んだ手法は、研究の世界だけでなく、行政・企業・NPO の現場でも様々に活用されています。具体的なシーンを紹介します。
🤔 よくある質問(読者からの想定Q&A)
この論文を読んで初心者が抱きやすい疑問に、教育的観点から答えます。