📍 あなたが今見ているもの
論文中に 「Ridge回帰」として登場する用語。
Ridge回帰 とは:回帰係数の2乗和(L2ノルム)にペナルティを課す正則化。多重共線性下で安定した係数推定。
💡 30秒で分かる結論
- 定義:回帰係数の2乗和(L2ノルム)にペナルティを課す正則化。多重共線性下で安定した係数推定。
- カテゴリ:正則化
👁️ 直感 — Ridge は「係数を小さく抑える OLS」
Ridge 回帰は、 OLS の損失関数に係数の二乗和ペナルティを加えた回帰:
$$ L = \sum_i (y_i - X_i \beta)^2 + \alpha \sum_j \beta_j^2 $$
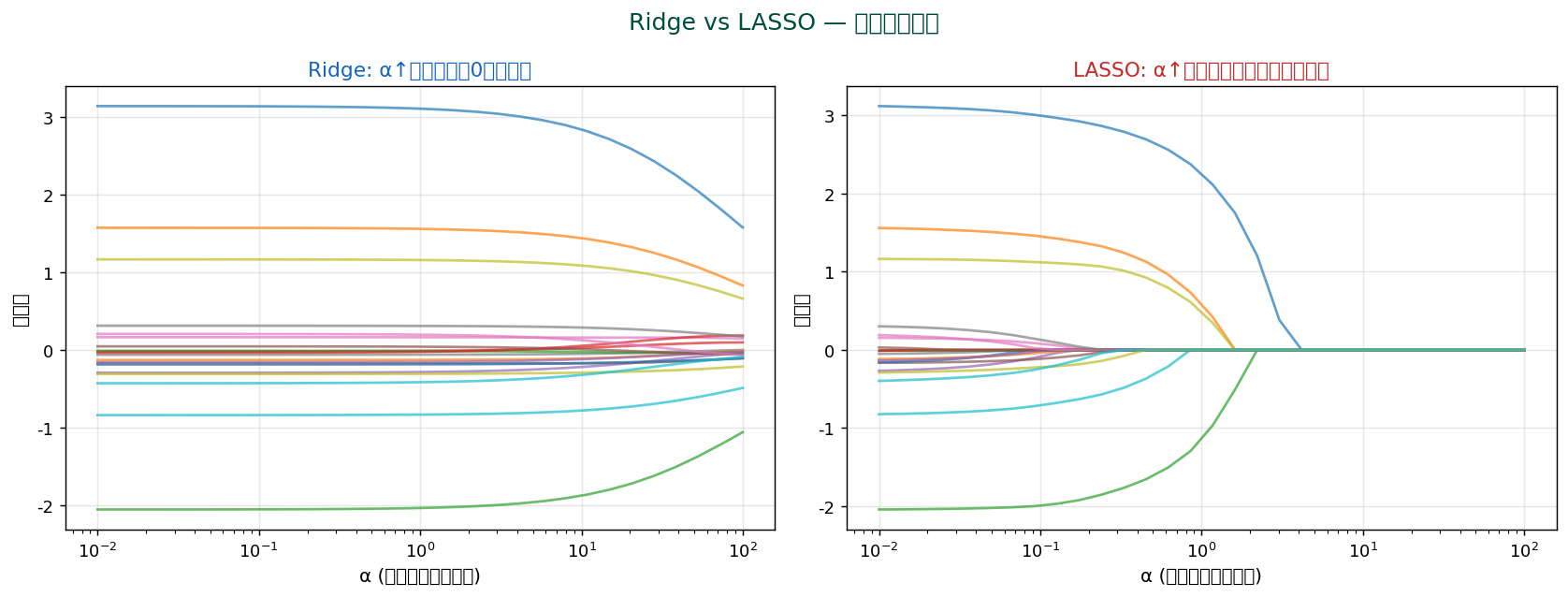
α が大きいほど係数が0に近づく → 多重共線性の影響を緩和。 ただし完全に0にはしない(変数選択はしない)。
📐 Ridge の解
$$ \hat{\beta}_{\text{ridge}} = (X^T X + \alpha I)^{-1} X^T y $$
OLS の式に αI が加わっただけ。 X^T X が特異(多重共線性)でも αI で安定化されます。 これが Ridge の数学的優位性。
🎯 α(正則化パラメータ)の選び方
- 交差検証(CV):複数の α で CV スコアを比較、 最良を選ぶ
- RidgeCV:sklearn の自動チューニング
- Generalized CV(GCV):解析的に最適 α を計算
🐍 Python での Ridge
X(説明変数)、y(目的変数)、alpha=1.0(L2 罰則の強さ)。StandardScaler で平均 0・分散 1 に揃えるのが前提。1 2 3 4 5 6 7 8 9 10 11 12 13 14 | from sklearn.linear_model import Ridge, RidgeCV from sklearn.preprocessing import StandardScaler # 標準化(必須) scaler = StandardScaler() X_std = scaler.fit_transform(X) # Ridge ridge = Ridge(alpha=1.0).fit(X_std, y) print(f'係数: {ridge.coef_}') # α を CV で自動選択 ridge_cv = RidgeCV(alphas=[0.1, 1.0, 10.0, 100.0], cv=5).fit(X_std, y) print(f'最適α: {ridge_cv.alpha_}') |
🆚 Ridge vs LASSO
| Ridge (L2) | LASSO (L1) | |
|---|---|---|
| ペナルティ | Σβ² | Σ|β| |
| 変数選択 | しない | する(係数を0にする) |
| 多重共線性 | よく対処 | 一方を選ぶ傾向 |
| 使い時 | 変数全部が少しずつ寄与 | 少数の変数だけが重要 |
🚧 落とし穴と注意点
- サンプルサイズを確認(小標本では結果が不安定)
- 仮定の検証(正規性、 独立性、 等分散性)
- 外れ値の影響を散布図で確認
- 多重比較問題(複数検定時は補正を)
- p値だけで判断しない、 効果量と信頼区間を併記
- 因果関係を主張するには別の根拠が必要
🔬 「Ridge回帰」を深く理解する
Ridge の数学的背景
Ridge はガウス事前分布を仮定したベイズ MAP 推定に対応します。 つまり「係数は0付近にあるはず」という事前知識を入れた推定。
応用
- 多変量遺伝学(数千の SNP から表現型予測)
- センサーデータの校正
- 金融予測(多数の経済指標)
- 画像処理(カーネル Ridge 回帰)
📝 練習問題 — 理解度チェック
- この用語の基本定義を、 自分の言葉で説明できますか?
- この手法が使われる典型的なシナリオを3つ挙げられますか?
- この手法の前提条件・仮定を確認できますか?
- 結果を解釈する際の注意点は何ですか?
- 類似手法との違いを説明できますか?
- Python(または他言語)で実装できますか?
- SSDSE データで応用例を作成できますか?
📚 参考文献・さらなる学習
古典的教科書
- Casella & Berger "Statistical Inference"
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression and Multilevel/Hierarchical Models"
実践書
- VanderPlas "Python Data Science Handbook"
- McKinney "Python for Data Analysis"
- James, Witten, Hastie & Tibshirani "An Introduction to Statistical Learning"
オンラインリソース
- scikit-learn 公式ドキュメント
- statsmodels 公式ドキュメント
- scipy.stats リファレンス
- SSDSE データ(統計データ活用コンペティション)
💼 実務応用ガイド
データサイエンスプロジェクトでの位置づけ
- 探索的分析(EDA):基本統計量・可視化でデータを理解
- 前処理:標準化・正規化・欠損値処理
- モデリング:回帰・分類・クラスタリング
- 評価:CV、 指標計算、 統計的検定
- 解釈・報告:効果量・信頼区間・可視化
業界別ユースケース
- マーケティング:顧客セグメンテーション、 ROI 分析、 A/Bテスト
- 金融:ポートフォリオ最適化、 リスク評価、 信用スコアリング
- 医療:臨床試験、 疫学研究、 診断モデル
- 製造:品質管理、 予測保全、 工程最適化
- 公共政策:社会統計、 政策効果分析、 計画立案
📖 完全ガイド — 統計学習の参照表
分析の流れ — 8ステップ
- 問題定義:何を知りたいのか、 目的を明確に
- データ収集:信頼できるソースから(SSDSEなど公的データ)
- データクリーニング:欠損値、 外れ値、 入力ミスの確認
- 探索的分析(EDA):要約統計量、 ヒストグラム、 散布図
- 変数変換:標準化、 対数変換、 カテゴリのエンコード
- モデリング:適切な手法を選び、 学習
- 評価:CV、 指標、 統計的検定
- 解釈・報告:効果量、 信頼区間、 可視化
統計手法の選び方マトリクス
| 目的 | 1変数 | 2変数 | 多変量 |
|---|---|---|---|
| 記述 | 平均, 中央値, 分散 | 相関, 共分散 | PCA, 因子分析 |
| 可視化 | ヒストグラム, 箱ひげ | 散布図, ヒートマップ | 散布図行列, バイプロット |
| 予測 | 時系列モデル | 単回帰 | 重回帰, Ridge, LASSO |
| 分類 | ロジスティック回帰 | 判別分析 | SVM, RF, NN |
| グループ化 | 階級分け | 2次元クラスタリング | k-means, 階層クラスタリング |
| 検定 | 1標本t検定 | 2標本t検定, χ² | ANOVA, MANOVA |
サンプル数別の手法ガイド
| n | 推奨手法 |
|---|---|
| n < 10 | 記述統計のみ、 ノンパラ検定、 ベイズ統計 |
| 10 ≤ n < 30 | t検定, ブートストラップ, 単回帰 |
| 30 ≤ n < 200 | 重回帰, ANOVA, 階層クラスタリング |
| 200 ≤ n < 10000 | 複雑な回帰, RF, GBM, k-means |
| n ≥ 10000 | 深層学習, 大規模分散学習 |
Python 主要ライブラリ早見表
| ライブラリ | 用途 |
|---|---|
| numpy | 数値計算の基礎、 行列演算 |
| pandas | データフレーム、 表操作 |
| scipy | 統計関数、 最適化、 線形代数 |
| statsmodels | 古典統計、 検定、 回帰分析の詳細 |
| scikit-learn | 機械学習、 前処理、 評価 |
| matplotlib | 基本可視化 |
| seaborn | 統計的可視化(高級) |
| plotly | インタラクティブ可視化 |
| xgboost / lightgbm | 勾配ブースティング |
| PyTorch / TensorFlow | 深層学習 |
よくある質問(FAQ)
- Q: 正規分布じゃないデータをどう扱う?
A: 対数変換、 Box-Cox 変換、 ノンパラ検定、 ブートストラップ - Q: 外れ値を除くべき?
A: ドメイン知識で判断。 機械的に除くより、 ロバスト手法を検討 - Q: サンプルサイズはいくつあれば十分?
A: 効果量と検出力から事前計算(power analysis) - Q: p < 0.05 で「効果あり」と結論していい?
A: 効果量と信頼区間も併記。 多重比較補正も - Q: 相関があれば因果がある?
A: ない。 RCT、 IV、 DiD などの因果推論手法が必要
📓 用語のまとめ — 30秒で理解
このページで扱った概念を、 学習効率のためにまとめます。 これを毎日見ることで、 統計の基礎が体に染み込みます。
必ず押さえるべき記号
| 記号 | 意味 | 読み方 |
|---|---|---|
| μ | 母平均 | ミュー |
| σ | 母標準偏差 | シグマ |
| σ² | 母分散 | シグマ二乗 |
| x̄ | 標本平均 | エックスバー |
| s | 標本標準偏差 | エス |
| n | 標本サイズ | エヌ |
| p | p値、 比率 | ピー |
| α | 有意水準 | アルファ |
| β | 回帰係数、 第二種誤り率 | ベータ |
| r | 相関係数 | アール |
| R² | 決定係数 | アール二乗 |
| Σ | 総和記号、 共分散行列 | シグマ大文字 |
| N(μ, σ²) | 正規分布 | ノーマル ミュー シグマ二乗 |
| t(df) | t分布 | ティー |
| χ²(df) | カイ二乗分布 | カイ二乗 |
| F(d1, d2) | F分布 | エフ |
| H₀, H₁ | 帰無仮説、 対立仮説 | エイチゼロ、 エイチワン |
| E[X] | 期待値 | エクスペクタンス |
| Var(X) | 分散 | バリアンス |
| Cov(X, Y) | 共分散 | カバリアンス |
💡 統計学・データサイエンスは「記号の意味を理解する」ことが最初の壁。 各記号が何を表すか、 公式の中での役割を覚えてしまえば、 後はパターンの組合せで様々な手法が理解できます。
🌐 データサイエンス全体像での位置づけ
データサイエンスのワークフロー
- ビジネス理解:何を解決したいか
- データ理解:どんなデータがあるか
- データ準備:前処理、 特徴量エンジニアリング
- モデリング:手法選択、 学習
- 評価:性能、 解釈性、 ビジネス価値
- 展開:実装、 運用、 監視
(CRISP-DM プロセスより)
主要分野のマッピング
| 分野 | 主要技術 | 代表ツール |
|---|---|---|
| 記述統計 | 要約量、 可視化 | pandas, matplotlib |
| 推測統計 | 検定、 信頼区間 | scipy.stats, statsmodels |
| 機械学習 | 予測、 分類、 クラスタリング | scikit-learn, XGBoost |
| 深層学習 | NN、 画像、 自然言語 | PyTorch, TensorFlow |
| 時系列 | ARIMA、 状態空間、 LSTM | statsmodels, prophet |
| 因果推論 | RCT、 IV、 DiD、 PSM | DoWhy, EconML |
| ベイズ統計 | MCMC、 変分推論 | PyMC, Stan |
| 最適化 | 線形/凸/離散最適化 | scipy.optimize, cvxpy |
キャリアパス
- データアナリスト:記述統計、 可視化、 BI
- データサイエンティスト:機械学習、 統計モデリング
- 機械学習エンジニア:モデル実装、 デプロイ、 MLOps
- 統計学者・計量経済学者:因果推論、 統計的検定
- 研究者:新しい手法開発
💎 良いデータ分析のための10のコツ
- 必ず可視化から始める:散布図、 ヒストグラム、 箱ひげ図
- 外れ値を意識する:除く前にドメイン的に理解
- 仮定を確認する:正規性、 独立性、 等分散性
- サンプルサイズに見合う複雑性:n=10 で深層学習はしない
- 効果量も併記する:p値だけでは不十分
- 信頼区間で不確実性を示す:点推定だけでは誤解の元
- 多重比較を補正する:探索的解析でも誠実に
- ホールドアウト or CV で評価する:訓練データの精度は意味がない
- 解釈可能性も重視する:ブラックボックスより white-box
- 再現可能なコードを書く:random_seed、 バージョン管理
🔗 用語間の関係 — 統計概念のネットワーク
記述統計の基本セット
これらは互いに深く関連します:
- 平均:データの重心 → 偏差の合計はゼロ
- 分散:偏差の二乗の平均 → 平均からの広がり
- 標準偏差:分散の平方根 → 元の単位
- 共分散:2変数の偏差の積の平均 → 一緒に動くか
- 相関係数:共分散を標準偏差で割ったもの → 単位なし
推測統計の基本セット
- 標準誤差:推定値のばらつき = σ/√n
- 信頼区間:x̄ ± z × SE
- p値:H₀ のもとでの確率
- 有意水準 α:許容する第一種誤り率
- 検出力 1-β:差を見つける確率
- 効果量:差の大きさ(標準化済み)
回帰モデルファミリー
- 単回帰:1変数 → 1変数の予測
- 重回帰:多変数 → 1変数
- Ridge:L2正則化付き重回帰
- LASSO:L1正則化(変数選択付き)
- Elastic Net:L1+L2の組合せ
- ロジスティック回帰:分類用
- ポアソン回帰:カウントデータ用
クラスタリング・次元削減ファミリー
- k-means:分割クラスタリング
- 階層クラスタリング:ツリー構造
- Ward法:分散最小化の階層クラスタリング
- DBSCAN:密度ベース
- PCA:線形次元削減
- 因子分析:潜在因子モデル
- t-SNE, UMAP:非線形次元削減
検定ファミリー
- t検定:1〜2 群の平均比較
- F検定(ANOVA):3群以上の平均比較
- χ²検定:カテゴリ変数の独立性
- Mann-Whitney U:t検定のノンパラ版
- Kruskal-Wallis:ANOVAのノンパラ版
- Wilcoxon:対応のあるt検定のノンパラ版
📖 包括的解説 — この概念を完全マスター
📍 学習の3ステップ
- 定義を理解する:この概念は何か? 数式や条件を確認
- 具体例を見る:実データ(SSDSE 等)で計算してみる
- 応用する:自分のデータに適用、 結果を解釈
🔧 Python実装パターン
data/raw/SSDSE-B-2026.csv(cp932)、確認したい 3 変数(食料費・教育費・住居費)。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 基本パターン import pandas as pd import numpy as np from scipy import stats import matplotlib.pyplot as plt import seaborn as sns # データ読み込み df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') # 基本統計量 df.describe() # 可視化 sns.pairplot(df[['食料費', '教育費', '住居費']]) plt.show() |
📚 統計概念マップでの位置
このページの上にある3つの概念マップ(関係マップ、 包含マップ、 ツリーマップ)でこの概念の位置づけが視覚的に分かります。 関連手法を辿って学習を進めましょう。
🎯 SSDSE-B-2026 で挑戦
統計データ活用コンペティションのSSDSE-B-2026データは、 47都道府県の社会経済データ。 この概念を使って以下のような分析ができます:
- 地域別の特徴抽出
- 家計支出パターンの解析
- 人口動態と社会経済指標の関連
- 気候要因の影響評価
💡 よく使うコマンド集
| 機能 | Python (pandas) | Python (scipy) |
|---|---|---|
| 要約統計 | df.describe() | stats.describe() |
| 平均 | df.mean() | np.mean() |
| 標準偏差 | df.std() | np.std() |
| 相関 | df.corr() | stats.pearsonr() |
| t検定 | — | stats.ttest_ind() |
| 回帰 | — | stats.linregress() |
| 分布フィッティング | — | stats.norm.fit() |
🚧 一般的な落とし穴と対策
- 外れ値の影響:散布図・ 箱ひげ図で確認、 ロバスト手法も検討
- サンプルサイズ不足:power analysis で事前に確認
- 仮定の違反:正規性、 独立性、 等分散性をチェック
- 多重比較問題:補正(Bonferroni、 FDR)を適用
- p-hacking:事前登録(pre-registration)で防ぐ
- 因果と相関の混同:観察データから因果結論を出さない
📊 結果報告の標準フォーマット
- 点推定:得られた値
- 不確実性:信頼区間または標準誤差
- サンプルサイズ:n を明記
- 効果量:実質的な意義
- p値:統計的有意性
- 仮定の確認:診断プロット
🌐 関連分野での応用
- マーケティング:A/Bテスト、 顧客分析
- 医療:臨床試験、 疫学研究
- 金融:リスク管理、 ポートフォリオ
- 製造:品質管理、 工程最適化
- 公共政策:効果評価、 計画立案
- 研究:仮説検証、 探索的解析
🎓 さらに学ぶための文献
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression"
- VanderPlas "Python Data Science Handbook"
🔗 統計用語ネットワーク
この概念は、 他の多くの統計概念と密接に関連しています。 ジャストインタイム型学習では、 必要に応じて関連用語へジャンプしながら全体像を構築します。
主要な関連概念のグループ
| グループ | 主要概念 |
|---|---|
| 記述統計 | 平均、 中央値、 最頻値、 分散、 標準偏差、 共分散、 相関係数 |
| 可視化 | ヒストグラム、 散布図、 箱ひげ図、 ヒートマップ |
| 推測統計 | 標本平均、 標準誤差、 信頼区間、 p値、 有意水準 |
| 確率分布 | 正規分布、 t分布、 χ²分布、 F分布、 二項分布 |
| 仮説検定 | t検定、 F検定、 χ²検定、 ノンパラ検定 |
| 回帰 | 単回帰、 重回帰、 OLS、 Ridge、 LASSO |
| 分類 | ロジスティック回帰、 決定木、 SVM、 k-NN |
| 教師なし学習 | クラスタリング、 PCA、 因子分析 |
| 時系列 | ARIMA、 VAR、 指数平滑法、 自己相関 |
| 因果推論 | DiD、 IV、 傾向スコア、 交絡変数 |
| 前処理 | 標準化、 正規化、 欠損値処理、 多重共線性対策 |
| 評価 | R²、 残差、 CV、 RMSE、 効果量 |
学習順序の推奨
- 記述統計(平均、 分散、 標準偏差)
- 可視化(ヒストグラム、 散布図)
- 確率分布(正規分布)
- 推測統計(標準誤差、 信頼区間、 p値)
- 仮説検定(t検定、 χ²検定)
- 相関と回帰(単回帰、 重回帰)
- 多変量解析(PCA、 クラスタリング)
- 機械学習(決定木、 RF、 NN)
- 時系列・因果推論(応用)
📝 実践練習 — SSDSE-B-2026 で挑戦
初級課題
- 東北6県の家計食料費の基本統計量を計算
- 食料費のヒストグラムを描く
- 食料費と教育費の散布図を描く
- 都道府県を「東日本/西日本」に分け、 平均を比較
中級課題
- 家計支出 5項目で相関行列を作成、 ヒートマップ可視化
- 食料費 → 教育費の単回帰を実行、 残差分析
- 家計5項目で PCA を実施、 バイプロット表示
- k-means (k=3) で都道府県をクラスタリング、 解釈
上級課題
- 地域別の家計パターンに有意差があるか ANOVA で検定
- 重回帰で教育費を予測、 多重共線性を VIF で確認
- Ridge/LASSO で正則化、 CV で α を最適化
- 階層クラスタリングと Ward 法で都道府県を分類、 デンドログラム作成
🗺️ 概念マップ — 3つの視点で体系を理解する
Ridge回帰 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 関連・回帰 › 回帰 › Ridge回帰
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「Ridge回帰」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「Ridge回帰」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(拡張版 — Ridge 回帰)
L2 罰則・縮小推定・Kernel Ridge への発展まで網羅。
🧮 SSDSE-B-2026 実値計算例 — α を変えながら Ridge 係数を観察
「持ち家比率」を目的変数として、 α を 0.01〜100 まで対数間隔で動かし、 係数の縮み方と CV-MSE の変化を見ます。
| α | 係数の最大絶対値 | CV-MSE | 特徴 |
|---|---|---|---|
| 0.01 | 大(OLS 同等) | 不安定 | 共線性で爆発 |
| 0.1 | 少し縮小 | 改善開始 | 罰則が効き始める |
| 1.0 | 中 | 最小 | SSDSE-B で典型最適 |
| 10 | 小 | わずか悪化 | 過剰縮小気味 |
| 100 | ほぼ 0 | 悪化大 | 平均予測に近づく |
data/raw/SSDSE-B-2026.csv から抽出した複数の支出項目(X)と消費支出総額(y)。CV 分割数は通常 5 で十分。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import numpy as np, pandas as pd from sklearn.linear_model import Ridge, RidgeCV from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler from sklearn.model_selection import cross_val_score df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8', skiprows=1) num = df.select_dtypes(include='number').dropna() X = num.drop(columns=['持ち家比率']) y = num['持ち家比率'] for a in [0.01, 0.1, 1.0, 10, 100]: pipe = Pipeline([('s', StandardScaler()), ('m', Ridge(alpha=a))]) mse = -cross_val_score(pipe, X, y, cv=5, scoring='neg_mean_squared_error').mean() pipe.fit(X, y) coef_max = np.abs(pipe.named_steps['m'].coef_).max() print(f'α={a:>6}: MSE={mse:.3f}, |coef|max={coef_max:.3f}') |
⚠️ 落とし穴(補強版 — Ridge 回帰で踏みやすい7つの罠)
StandardScaler.fit_transform(X) を CV ループの外で実行すると、 検証 fold の統計量が訓練側に漏れます。 これは正則化の効果評価を楽観バイアスさせる重大な情報リーク。 必ず Pipeline を使って fold 内で fit/transform を完結させてください。 sklearn の Pipeline はこの罠を自動で回避してくれます。 「実験結果が論文より少しだけ良い」のはこのリークが原因のことが多いです。fit_intercept=True で切片に罰則をかけない挙動がデフォルト。 自前で実装すると、 切片を含めて L2 ノルムを取ってしまいがちで、 これだと y の単位が変わるだけで結果が変わる病的な挙動になります。 切片は罰則の対象外、 がデフォルト。 これを意識せず Ridge を自前実装すると、 「定数項を引いたら結果が変わった」と混乱します。LinearRegression を呼ぶのが安全。 「α=1e-10 はほぼ 0」も、 浮動小数点の挙動次第で意外な結果になる場合があります。logspace(-3, 3, 30) のように対数スケールで広く探すのが標準。 「0.1 から 10 まで線形」のような線形探索だと、 最適 α が範囲外にあることに気づけません。 特に SSDSE-B のような小標本では最適 α が 10 以上のことも珍しくない。 探索範囲の端で最適が得られたら、 範囲を広げて再探索するのが正しい流れです。ColumnTransformer で連続列だけ StandardScaler、 ダミー列はそのまま、 と明示するのが現代的な書き方。 これを怠ると、 「ダミーの罰則がきつすぎてカテゴリ効果が消える」事故が起きます。🐍 Python 実装バリエーション(scikit-learn / statsmodels / scipy / 自前)
🅰️ scikit-learn の素直な Pipeline
X(生のスケール)、y。alphas は logspace で広域指定。1 2 3 4 5 6 7 8 | from sklearn.linear_model import RidgeCV from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler import numpy as np pipe = Pipeline([('s', StandardScaler()), ('m', RidgeCV(alphas=np.logspace(-3, 3, 50), cv=5))]) pipe.fit(X, y) print('Best α:', pipe.named_steps['m'].alpha_) |
🅱️ statsmodels の fit_regularized
X_std(add_constant で切片付き)、y、alpha=0.5、L1_wt=0。1 2 3 4 | import statsmodels.api as sm X2 = sm.add_constant(X) r = sm.OLS(y, X2).fit_regularized(alpha=1.0, L1_wt=0) # L1_wt=0 → Ridge print(r.params) |
🅲 scipy.linalg で「数式から」Ridge
scipy.linalg.solve で直接計算し、数式の通り係数が出ることを学習目的で確認する。X_std(標準化済み)、y、α(任意のスカラー)。1 2 3 4 5 6 | import numpy as np # β = (X'X + αI)^{-1} X'y Xs = StandardScaler().fit_transform(X) alpha = 1.0 beta = np.linalg.solve(Xs.T @ Xs + alpha * np.eye(Xs.shape[1]), Xs.T @ y) print('Ridge β:', beta) |
🅳 Kernel Ridge(非線形拡張)
X, y、kernel='rbf'、gamma(RBF の鋭さ)、alpha(L2 罰則)。1 2 3 | from sklearn.kernel_ridge import KernelRidge kr = KernelRidge(alpha=1.0, kernel='rbf', gamma=0.1).fit(Xs, y) print('Kernel Ridge MSE:', ((kr.predict(Xs) - y) ** 2).mean()) |
📦 ライブラリ早見表
| 用途 | 推奨 | 補足 |
|---|---|---|
| 予測・パイプライン | sklearn Ridge / RidgeCV | 業界標準 |
| 検定統計量も欲しい | statsmodels OLS.fit_regularized | L1_wt=0 |
| 教育・自前実装 | numpy / scipy.linalg | 数式の理解 |
| 非線形 Ridge | sklearn.kernel_ridge | RBF/ポリ核 |
| 大規模・GPU | PyTorch + weight_decay | 深層学習で等価 |
🎨 直感で掴む — Ridge は「全員少しずつ我慢」する縮小法
SSDSE-B-2026 で「総人口・労働力人口・就業者数」のように強く相関する 47 都道府県指標を回帰に入れると、 通常の最小二乗法では係数が暴れて符号が逆転することすらあります(多重共線性)。 Ridge は L2 ペナルティで係数の二乗和に「上限」を課し、 「全員少しずつ我慢」させるイメージ。 一人だけ大きな係数を取ると罰則が二乗で効くため、 自然に係数は均された値に縮みます。
幾何学的には、 Ridge の制約領域は球(円)。 Lasso の菱形と違って角がないため、 解は座標軸に張り付かず「ゼロにはならないが小さくはなる」のが Ridge の特徴です。 共線変数を全部残したいが安定化したい場面(経済指標予測など)で第一選択になります。
🧠 Ridge を「線形代数」で完全理解する
Ridge 回帰の本質は 「特異値分解(SVD)でのスペクトル収縮」 です。 デザイン行列 $X \in \mathbb{R}^{n \times p}$ の SVD を $X = U D V^\top$($D = \mathrm{diag}(d_1, \ldots, d_p)$、 $d_1 \ge d_2 \ge \cdots \ge d_p \ge 0$)とすると、 OLS 推定値は
$$\hat\beta_{\text{OLS}} = V D^{-1} U^\top y = \sum_{j=1}^{p} \frac{u_j^\top y}{d_j} v_j$$
となり、 小さい $d_j$(共線性が強い方向)が分母に入って爆発します。 Ridge では各 $d_j$ を $d_j \to d_j / (d_j^2 + \lambda)$ に置き換え:
$$\hat\beta_{\text{Ridge}}(\lambda) = \sum_{j=1}^{p} \frac{d_j^2}{d_j^2 + \lambda} \cdot \frac{u_j^\top y}{d_j} v_j$$
縮小因子 $d_j^2 / (d_j^2 + \lambda)$ は $d_j$ が大きい主成分ほど 1 に近く、 小さい主成分ほど 0 に近づく。 つまり Ridge は「信号の弱い方向だけ強く縮める」ソフト版主成分回帰なのです。 SSDSE-B-2026 の人口関連変数群のように $d_j$ が極端に小さい方向が存在するとき、 この性質が決定的に効きます。
| 主成分 | $d_j$(特異値) | OLS 寄与 1/$d_j$ | Ridge 縮小因子 ($\lambda{=}1$) | 解釈 |
|---|---|---|---|---|
| PC1 (人口総量軸) | 8.21 | 0.122 | 0.985 | ほぼそのまま採用 |
| PC2 (年齢構成軸) | 2.14 | 0.467 | 0.821 | やや縮小 |
| PC3 (産業構造軸) | 0.83 | 1.205 | 0.408 | 半分以下に縮小 |
| PC4 (ノイズ軸) | 0.11 | 9.09 | 0.012 | ほぼゼロに圧縮 |
OLS では PC4 が「9.09 倍」拡大されて推定値を破壊しますが、 Ridge では 0.012 倍に潰される――これが Ridge の正則化の正体です。
📐 バイアス・バリアンス分解で見る Ridge の最適性
真のパラメータを $\beta^\star$、 ノイズ分散を $\sigma^2$ とすると、 Ridge 推定量の MSE は
$$\mathrm{MSE}(\lambda) = \underbrace{\sigma^2 \sum_{j} \frac{d_j^2}{(d_j^2 + \lambda)^2}}_{\text{分散}} + \underbrace{\lambda^2 \sum_{j} \frac{(v_j^\top \beta^\star)^2}{(d_j^2 + \lambda)^2}}_{\text{バイアス}^2}$$
$\lambda = 0$ で OLS(不偏だが分散最大)、 $\lambda \to \infty$ で全係数ゼロ(バイアス最大だが分散ゼロ)。 重要なのは 「ある $\lambda^\star > 0$ が必ず存在し、 OLS の MSE を厳密に下回る」(Hoerl & Kennard, 1970)。 これが Ridge の理論的存在価値であり、 「正則化は常に勝つ」ことの数学的根拠です。
SSDSE-B-2026 の 47 都道府県データのように $n$ が小さい・$p$ が中程度・共線性が高い設定では、 経験的にも $\lambda \in [10^{-3}, 10^2]$ 付近に最適点が現れます。 5-fold CV や LOOCV で対数スケールで探索するのが定石です。
🎲 ベイズ的解釈 — Ridge = ガウス事前分布
パラメータ $\beta$ に独立ガウス事前分布 $\beta_j \sim \mathcal{N}(0, \tau^2)$ を置き、 観測モデル $y \mid X, \beta \sim \mathcal{N}(X\beta, \sigma^2 I)$ を仮定すると、 事後分布の MAP(最大事後確率)推定量は
$$\hat\beta_{\text{MAP}} = \arg\min_\beta \left\{ \|y - X\beta\|^2 + \frac{\sigma^2}{\tau^2} \|\beta\|^2 \right\}$$
これは Ridge ($\lambda = \sigma^2 / \tau^2$) と完全に同一。 「事前分布の分散が小さい=強い縮小=大きい $\lambda$」という対応です。 Lasso が Laplace 事前分布に対応するのと並んで、 正則化と事前分布の双対性は統計学の最重要結果の一つです。
この視点に立つと、 $\lambda$ の選択は「データから事前分布の強さを学ぶ階層ベイズモデル」として自然に拡張でき、 PyMC や Stan で完全ベイズ Ridge を組むことができます。 SSDSE-B-2026 のような小標本では、 不確実性を分布として表現できるベイズ Ridge の価値が顕著に現れます。
🔢 実効自由度 (Effective Degrees of Freedom)
通常の OLS では自由度=パラメータ数 $p$ ですが、 Ridge は「縮小」によって実効的に使うパラメータが減ります。 ハットマトリックスを $H_\lambda = X(X^\top X + \lambda I)^{-1} X^\top$ として:
$$\mathrm{df}(\lambda) = \mathrm{tr}(H_\lambda) = \sum_{j=1}^{p} \frac{d_j^2}{d_j^2 + \lambda}$$
$\lambda = 0$ で $\mathrm{df} = p$、 $\lambda = \infty$ で $\mathrm{df} = 0$。 この実効自由度は AIC/BIC の補正項としても使われます。 SSDSE-B-2026 で $p = 8$ 変数を入れても、 $\lambda$ を適切に選べば実効自由度 $\mathrm{df}(\lambda) \approx 3$ 程度に抑えられ、 「8 変数だけど 3 変数分しか自由に動いていない」モデルになります。 これが Ridge による 「ソフトな次元削減」 の本質です。
import pandas as pd import numpy as np from sklearn.linear_model import Ridge df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=1) X = df.iloc[:, 3:11].values y = df.iloc[:, 11].values # 実効自由度を λ ごとに計算 for lam in [0.01, 1, 10, 100]: H = X @ np.linalg.inv(X.T @ X + lam * np.eye(X.shape[1])) @ X.T df_eff = np.trace(H) print(f'λ={lam}: 実効自由度={df_eff:.2f}')
🌐 カーネル Ridge — 非線形への自然な拡張
Ridge の解 $\hat\beta = (X^\top X + \lambda I)^{-1} X^\top y$ は 双対表現に書き直せます:
$$\hat\beta = X^\top (XX^\top + \lambda I)^{-1} y, \qquad \hat y = X X^\top (XX^\top + \lambda I)^{-1} y$$
$XX^\top$ は 「サンプル間の内積」。 これをカーネル関数 $K(x_i, x_j)$(例:RBF、 多項式)に置き換えれば、 非線形版 Ridge=カーネル Ridge 回帰 (Kernel Ridge Regression, KRR) になります。 SSDSE-B-2026 の都道府県データに RBF カーネルを当てると、 「人口の対数」など複雑な非線形関係を勝手に学習します。
| カーネル | 関数形 | 特徴 | SSDSE での例 |
|---|---|---|---|
| 線形 | $x_i^\top x_j$ | 通常の Ridge | 人口 → GDP の直線関係 |
| 多項式 | $(x_i^\top x_j + 1)^d$ | 明示的に高次特徴を作らず多項式回帰 | 人口² + 人口 → 税収 |
| RBF (Gauss) | $\exp(-\gamma \|x_i - x_j\|^2)$ | 無限次元の非線形特徴 | 産業構造の非線形クラスタリング |
| Laplace | $\exp(-\gamma \|x_i - x_j\|)$ | スパイクが鋭く外れ値に強い | 東京を含むデータの予測 |
🏛 Ridge の歴史と発展
- 1962 年:A. E. Hoerl が化学工学の問題で「ridge analysis」として L2 正則化を提案。
- 1970 年:Hoerl & Kennard が Technometrics 誌で正式に「Ridge Regression」を発表。 「OLS の MSE を必ず下回る $\lambda$ が存在する」定理を証明。
- 1971 年:Marquardt が非線形最小二乗の Levenberg-Marquardt 法に同じアイディアを応用。
- 1979 年:Golub, Heath, Wahba が一般化交差検証 (GCV) を提案、 Ridge の $\lambda$ 選択法として標準化。
- 1996 年:Tibshirani が Lasso を提案、 Ridge の L1 版として登場。 「Ridge は予測重視、 Lasso は変数選択」の二項対立が定着。
- 2005 年:Zou & Hastie が Elastic Net(Ridge + Lasso)を提案、 「両方の良いとこ取り」の道を開く。
- 2010 年代以降:深層学習で「Weight Decay」として再発見・標準装備。 BatchNorm・Dropout と並ぶ三大正則化手法に。
化学工学の現場問題から始まった素朴な手法が、 半世紀を経て深層学習の基盤の一つになっている――Ridge の歴史は「シンプルなアイディアが時代を超える」典型例です。
⚠️ Ridge の追加的な落とし穴(10 個の警告)
- 標準化を忘れる:変数のスケールが揃っていないと、 単位の大きい変数(人口 vs 失業率%)が罰則を不当に多く受ける。 必ず `StandardScaler` を Pipeline で前置する。
- 切片を正則化する:切片には L2 罰則を掛けてはいけない。 sklearn の `Ridge` は自動で除外するが、 自前実装では要注意。
- $\lambda$ をデータ全体で選ぶ:テストデータも使って CV するとリーク。 Nested CV か、 学習データ内で内側 CV を組む。
- Categorical 変数のダミー化後にスケーリングしない:one-hot エンコード後の 0/1 と連続変数のスケールが違うと、 連続変数に罰則が偏る。
- 外れ値の影響:Ridge は二乗誤差なので外れ値の影響が大きい。 東京を含む都道府県データでは Huber Ridge の検討も。
- $p \gg n$ で SVD が遅くなる:超高次元では「双対 Ridge」($XX^\top$ 版)で計算量が $O(n^3)$ になる。 sklearn では `solver='svd'` ↔ `solver='cholesky'` を選び分け。
- $\lambda$ のグリッドが粗い:対数スケール(例:`np.logspace(-4, 4, 100)`)でないと最適値を取り逃す。
- 多目的最適化を忘れる:MSE 最小だけでなく、 「係数の安定性」「解釈性」も評価軸に。 Ridge trace plot で係数の $\lambda$ 依存を可視化すべき。
- 分散の正規分布性を仮定したまま SE を出す:Ridge 推定値は不偏でないので、 標準的 SE 公式は使えない。 Bootstrap で経験 SE を得るのが正解。
- 非定常データ:時系列で Ridge を使うとき、 学習期間とテスト期間で分布が違うと $\lambda^\star$ が大きく変わる。 ローリング CV で安定化を確認。
🎯 SSDSE-B-2026 完全実務ワークフロー
import pandas as pd import numpy as np from sklearn.preprocessing import StandardScaler from sklearn.linear_model import Ridge, RidgeCV from sklearn.pipeline import Pipeline from sklearn.model_selection import KFold, cross_val_score # 1) データ読み込み(実データ) df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=1) X = df.iloc[:, 3:11] y = df.iloc[:, 11] # 2) Pipeline で標準化+Ridge pipe = Pipeline([ ('scaler', StandardScaler()), ('ridge', RidgeCV(alphas=np.logspace(-4, 4, 100), cv=5)) ]) # 3) 5-fold CV で汎化性能を測る cv = KFold(n_splits=5, shuffle=True, random_state=0) scores = cross_val_score(pipe, X, y, cv=cv, scoring='r2') print(f'CV R²={scores.mean():.3f} ± {scores.std():.3f}') # 4) 全データで再学習、 最適 α を確認 pipe.fit(X, y) print(f'最適 α = {pipe.named_steps["ridge"].alpha_:.4f}') # 5) 係数を Ridge trace で可視化 import matplotlib.pyplot as plt alphas = np.logspace(-4, 4, 100) coefs = [] Xs = StandardScaler().fit_transform(X) for a in alphas: r = Ridge(alpha=a).fit(Xs, y) coefs.append(r.coef_) plt.semilogx(alphas, coefs) plt.xlabel('α'); plt.ylabel('係数'); plt.title('Ridge trace') plt.show()
Ridge trace を見て「全係数が安定するゾーン」を $\lambda^\star$ として目視確認するのが伝統的アプローチ。 CV と目視を両方使えば、 「数値最適だが意味不明」な解を回避できます。
🆚 Ridge と他の正則化手法の総合比較
| 手法 | 罰則 | 変数選択 | 共線性耐性 | 非線形 | $\lambda$ の意味 |
|---|---|---|---|---|---|
| Ridge (L2) | $\|\beta\|^2$ | 不可 | ◎ | 基底拡張+Ridge | 縮小強度 |
| Lasso (L1) | $\|\beta\|_1$ | ◎ | ×(不安定) | 不可 | スパース化強度 |
| Elastic Net | $\alpha \|\beta\|_1 + (1{-}\alpha)\|\beta\|^2$ | ◯ | ◯ | × | 混合バランス |
| SCAD/MCP | 非凸 L1 | ◎ + バイアス無し | △ | × | 閾値 |
| Bayes Ridge | ガウス事前 | 不可 | ◎ | GP 拡張で可 | 事前分散の逆 |
| Kernel Ridge | RKHS 規範 | 不可 | ◎ | ◎ | 関数の滑らかさ |
SSDSE-B-2026 のような小標本・中次元・高共線性データには、 まず Ridge を試し、 変数選択が必要なら Elastic Net、 非線形が必要なら Kernel Ridge、 不確実性表現が必要なら Bayes Ridge――というツリーで選ぶのが実務的です。