📍 あなたが今見ているもの
論文中に 「LASSO回帰」として登場する用語。
LASSO回帰 とは:回帰係数の絶対値の和(L1ノルム)にペナルティを課す正則化。重要でない変数の係数を0にする(変数選択効果)。
💡 30秒で分かる結論
- 定義:回帰係数の絶対値の和(L1ノルム)にペナルティを課す正則化。重要でない変数の係数を0にする(変数選択効果)。
- カテゴリ:正則化
👁️ 直感 — LASSOは「係数を完全ゼロにする」
LASSO(Least Absolute Shrinkage and Selection Operator)は、 係数の絶対値和をペナルティに:
$$ L = \sum_i (y_i - X_i \beta)^2 + \alpha \sum_j |\beta_j| $$
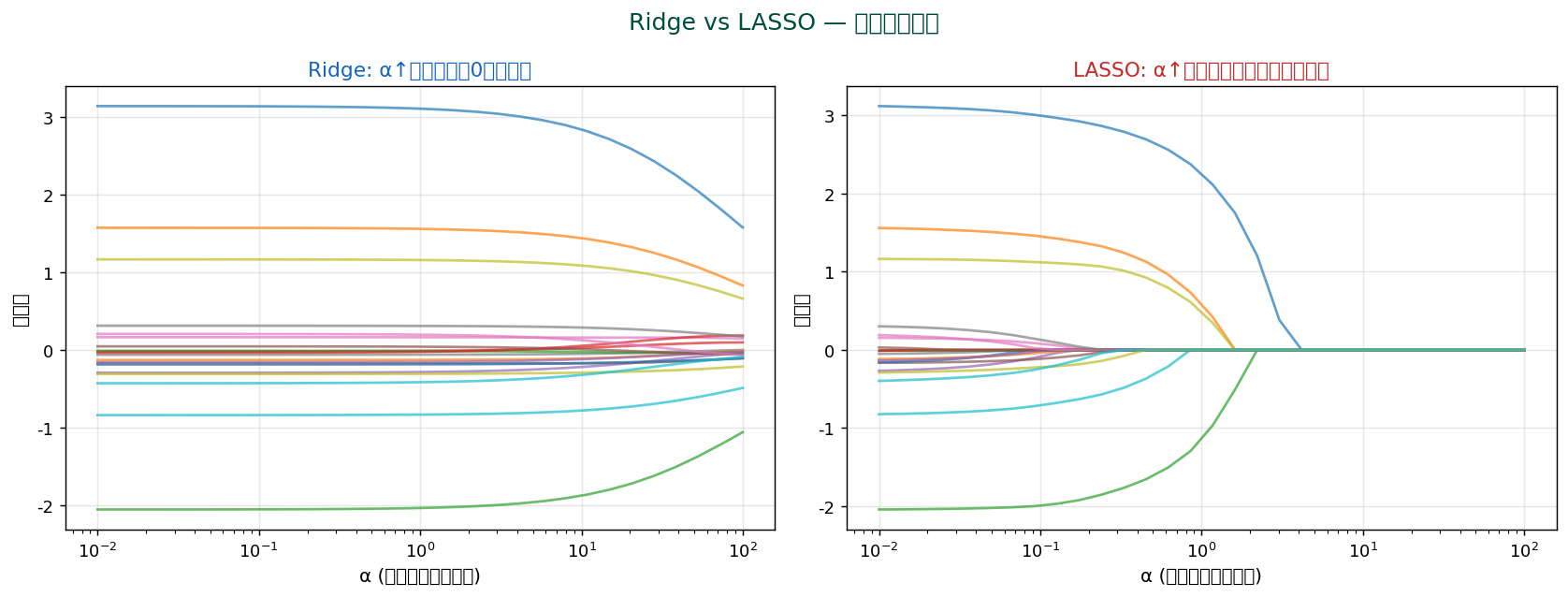
L1 ペナルティの幾何学的性質により、 重要でない変数の係数が完全にゼロになる。 つまり自動的に変数選択。
📐 L1ペナルティの幾何学
L1 球(菱形)はその「角」で軸と交わる。 等値線がこの角と接する時、 一部の係数が正確にゼロに。 L2(円)にはそうした特異点がないため、 係数はゼロに収束しない。
解の性質
- α=0:OLS と同じ
- α→∞:全係数がゼロ
- α が中間:一部の係数がゼロ、 残りは縮小
計算アルゴリズム
- 座標降下法(CD):sklearn のデフォルト
- LARS:α の全範囲を一気に計算(パス)
- ISTA / FISTA:近接勾配法
🐍 Python での LASSO
X(n×p の説明変数行列、例:SSDSE-B-2026 の項目支出群)と y(目的変数、例:消費支出総額)。StandardScaler で平均 0・分散 1 に揃えるのが前提。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from sklearn.linear_model import Lasso, LassoCV from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_std = scaler.fit_transform(X) lasso = Lasso(alpha=0.1).fit(X_std, y) print(f'係数: {lasso.coef_}') print(f'非ゼロ係数の数: {(lasso.coef_ != 0).sum()}') # CV で α 自動選択 lasso_cv = LassoCV(cv=5, random_state=0).fit(X_std, y) print(f'最適α: {lasso_cv.alpha_}') # LARS パス from sklearn.linear_model import lars_path alphas, _, coefs = lars_path(X_std, y, method='lasso') |
🚧 LASSO の限界
- 相関の強い変数群があると、 ランダムに1つ選んで他をゼロに(不安定)
- n < p の場合、 最大 n 個の変数しか選べない
- 選ばれない変数の影響は完全に無視(過剰削減)
これらの問題は Elastic Net(L1 + L2)で改善されます。
🚧 落とし穴と注意点
- サンプルサイズを確認(小標本では結果が不安定)
- 仮定の検証(正規性、 独立性、 等分散性)
- 外れ値の影響を散布図で確認
- 多重比較問題(複数検定時は補正を)
- p値だけで判断しない、 効果量と信頼区間を併記
- 因果関係を主張するには別の根拠が必要
🔬 「LASSO」を深く理解する
LASSO の数学的背景
LASSO はラプラス事前分布を仮定したベイズ MAP 推定。 これにより係数が「ゼロに張り付く」確率が高くなる。
応用
- 遺伝子発現データ:何千の遺伝子から重要な数十を選ぶ
- 金融:多数のアセットから少数の重要因子
- テキスト分類:何万の単語から少数の特徴単語
- センサー融合:多数センサーから必要な情報源を抽出
📝 練習問題 — 理解度チェック
- この用語の基本定義を、 自分の言葉で説明できますか?
- この手法が使われる典型的なシナリオを3つ挙げられますか?
- この手法の前提条件・仮定を確認できますか?
- 結果を解釈する際の注意点は何ですか?
- 類似手法との違いを説明できますか?
- Python(または他言語)で実装できますか?
- SSDSE データで応用例を作成できますか?
📚 参考文献・さらなる学習
古典的教科書
- Casella & Berger "Statistical Inference"
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression and Multilevel/Hierarchical Models"
実践書
- VanderPlas "Python Data Science Handbook"
- McKinney "Python for Data Analysis"
- James, Witten, Hastie & Tibshirani "An Introduction to Statistical Learning"
オンラインリソース
- scikit-learn 公式ドキュメント
- statsmodels 公式ドキュメント
- scipy.stats リファレンス
- SSDSE データ(統計データ活用コンペティション)
💼 実務応用ガイド
データサイエンスプロジェクトでの位置づけ
- 探索的分析(EDA):基本統計量・可視化でデータを理解
- 前処理:標準化・正規化・欠損値処理
- モデリング:回帰・分類・クラスタリング
- 評価:CV、 指標計算、 統計的検定
- 解釈・報告:効果量・信頼区間・可視化
業界別ユースケース
- マーケティング:顧客セグメンテーション、 ROI 分析、 A/Bテスト
- 金融:ポートフォリオ最適化、 リスク評価、 信用スコアリング
- 医療:臨床試験、 疫学研究、 診断モデル
- 製造:品質管理、 予測保全、 工程最適化
- 公共政策:社会統計、 政策効果分析、 計画立案
📖 完全ガイド — 統計学習の参照表
分析の流れ — 8ステップ
- 問題定義:何を知りたいのか、 目的を明確に
- データ収集:信頼できるソースから(SSDSEなど公的データ)
- データクリーニング:欠損値、 外れ値、 入力ミスの確認
- 探索的分析(EDA):要約統計量、 ヒストグラム、 散布図
- 変数変換:標準化、 対数変換、 カテゴリのエンコード
- モデリング:適切な手法を選び、 学習
- 評価:CV、 指標、 統計的検定
- 解釈・報告:効果量、 信頼区間、 可視化
統計手法の選び方マトリクス
| 目的 | 1変数 | 2変数 | 多変量 |
|---|---|---|---|
| 記述 | 平均, 中央値, 分散 | 相関, 共分散 | PCA, 因子分析 |
| 可視化 | ヒストグラム, 箱ひげ | 散布図, ヒートマップ | 散布図行列, バイプロット |
| 予測 | 時系列モデル | 単回帰 | 重回帰, Ridge, LASSO |
| 分類 | ロジスティック回帰 | 判別分析 | SVM, RF, NN |
| グループ化 | 階級分け | 2次元クラスタリング | k-means, 階層クラスタリング |
| 検定 | 1標本t検定 | 2標本t検定, χ² | ANOVA, MANOVA |
サンプル数別の手法ガイド
| n | 推奨手法 |
|---|---|
| n < 10 | 記述統計のみ、 ノンパラ検定、 ベイズ統計 |
| 10 ≤ n < 30 | t検定, ブートストラップ, 単回帰 |
| 30 ≤ n < 200 | 重回帰, ANOVA, 階層クラスタリング |
| 200 ≤ n < 10000 | 複雑な回帰, RF, GBM, k-means |
| n ≥ 10000 | 深層学習, 大規模分散学習 |
Python 主要ライブラリ早見表
| ライブラリ | 用途 |
|---|---|
| numpy | 数値計算の基礎、 行列演算 |
| pandas | データフレーム、 表操作 |
| scipy | 統計関数、 最適化、 線形代数 |
| statsmodels | 古典統計、 検定、 回帰分析の詳細 |
| scikit-learn | 機械学習、 前処理、 評価 |
| matplotlib | 基本可視化 |
| seaborn | 統計的可視化(高級) |
| plotly | インタラクティブ可視化 |
| xgboost / lightgbm | 勾配ブースティング |
| PyTorch / TensorFlow | 深層学習 |
よくある質問(FAQ)
- Q: 正規分布じゃないデータをどう扱う?
A: 対数変換、 Box-Cox 変換、 ノンパラ検定、 ブートストラップ - Q: 外れ値を除くべき?
A: ドメイン知識で判断。 機械的に除くより、 ロバスト手法を検討 - Q: サンプルサイズはいくつあれば十分?
A: 効果量と検出力から事前計算(power analysis) - Q: p < 0.05 で「効果あり」と結論していい?
A: 効果量と信頼区間も併記。 多重比較補正も - Q: 相関があれば因果がある?
A: ない。 RCT、 IV、 DiD などの因果推論手法が必要
📓 用語のまとめ — 30秒で理解
このページで扱った概念を、 学習効率のためにまとめます。 これを毎日見ることで、 統計の基礎が体に染み込みます。
必ず押さえるべき記号
| 記号 | 意味 | 読み方 |
|---|---|---|
| μ | 母平均 | ミュー |
| σ | 母標準偏差 | シグマ |
| σ² | 母分散 | シグマ二乗 |
| x̄ | 標本平均 | エックスバー |
| s | 標本標準偏差 | エス |
| n | 標本サイズ | エヌ |
| p | p値、 比率 | ピー |
| α | 有意水準 | アルファ |
| β | 回帰係数、 第二種誤り率 | ベータ |
| r | 相関係数 | アール |
| R² | 決定係数 | アール二乗 |
| Σ | 総和記号、 共分散行列 | シグマ大文字 |
| N(μ, σ²) | 正規分布 | ノーマル ミュー シグマ二乗 |
| t(df) | t分布 | ティー |
| χ²(df) | カイ二乗分布 | カイ二乗 |
| F(d1, d2) | F分布 | エフ |
| H₀, H₁ | 帰無仮説、 対立仮説 | エイチゼロ、 エイチワン |
| E[X] | 期待値 | エクスペクタンス |
| Var(X) | 分散 | バリアンス |
| Cov(X, Y) | 共分散 | カバリアンス |
💡 統計学・データサイエンスは「記号の意味を理解する」ことが最初の壁。 各記号が何を表すか、 公式の中での役割を覚えてしまえば、 後はパターンの組合せで様々な手法が理解できます。
🌐 データサイエンス全体像での位置づけ
データサイエンスのワークフロー
- ビジネス理解:何を解決したいか
- データ理解:どんなデータがあるか
- データ準備:前処理、 特徴量エンジニアリング
- モデリング:手法選択、 学習
- 評価:性能、 解釈性、 ビジネス価値
- 展開:実装、 運用、 監視
(CRISP-DM プロセスより)
主要分野のマッピング
| 分野 | 主要技術 | 代表ツール |
|---|---|---|
| 記述統計 | 要約量、 可視化 | pandas, matplotlib |
| 推測統計 | 検定、 信頼区間 | scipy.stats, statsmodels |
| 機械学習 | 予測、 分類、 クラスタリング | scikit-learn, XGBoost |
| 深層学習 | NN、 画像、 自然言語 | PyTorch, TensorFlow |
| 時系列 | ARIMA、 状態空間、 LSTM | statsmodels, prophet |
| 因果推論 | RCT、 IV、 DiD、 PSM | DoWhy, EconML |
| ベイズ統計 | MCMC、 変分推論 | PyMC, Stan |
| 最適化 | 線形/凸/離散最適化 | scipy.optimize, cvxpy |
キャリアパス
- データアナリスト:記述統計、 可視化、 BI
- データサイエンティスト:機械学習、 統計モデリング
- 機械学習エンジニア:モデル実装、 デプロイ、 MLOps
- 統計学者・計量経済学者:因果推論、 統計的検定
- 研究者:新しい手法開発
💎 良いデータ分析のための10のコツ
- 必ず可視化から始める:散布図、 ヒストグラム、 箱ひげ図
- 外れ値を意識する:除く前にドメイン的に理解
- 仮定を確認する:正規性、 独立性、 等分散性
- サンプルサイズに見合う複雑性:n=10 で深層学習はしない
- 効果量も併記する:p値だけでは不十分
- 信頼区間で不確実性を示す:点推定だけでは誤解の元
- 多重比較を補正する:探索的解析でも誠実に
- ホールドアウト or CV で評価する:訓練データの精度は意味がない
- 解釈可能性も重視する:ブラックボックスより white-box
- 再現可能なコードを書く:random_seed、 バージョン管理
🔗 用語間の関係 — 統計概念のネットワーク
記述統計の基本セット
これらは互いに深く関連します:
- 平均:データの重心 → 偏差の合計はゼロ
- 分散:偏差の二乗の平均 → 平均からの広がり
- 標準偏差:分散の平方根 → 元の単位
- 共分散:2変数の偏差の積の平均 → 一緒に動くか
- 相関係数:共分散を標準偏差で割ったもの → 単位なし
推測統計の基本セット
- 標準誤差:推定値のばらつき = σ/√n
- 信頼区間:x̄ ± z × SE
- p値:H₀ のもとでの確率
- 有意水準 α:許容する第一種誤り率
- 検出力 1-β:差を見つける確率
- 効果量:差の大きさ(標準化済み)
回帰モデルファミリー
- 単回帰:1変数 → 1変数の予測
- 重回帰:多変数 → 1変数
- Ridge:L2正則化付き重回帰
- LASSO:L1正則化(変数選択付き)
- Elastic Net:L1+L2の組合せ
- ロジスティック回帰:分類用
- ポアソン回帰:カウントデータ用
クラスタリング・次元削減ファミリー
- k-means:分割クラスタリング
- 階層クラスタリング:ツリー構造
- Ward法:分散最小化の階層クラスタリング
- DBSCAN:密度ベース
- PCA:線形次元削減
- 因子分析:潜在因子モデル
- t-SNE, UMAP:非線形次元削減
検定ファミリー
- t検定:1〜2 群の平均比較
- F検定(ANOVA):3群以上の平均比較
- χ²検定:カテゴリ変数の独立性
- Mann-Whitney U:t検定のノンパラ版
- Kruskal-Wallis:ANOVAのノンパラ版
- Wilcoxon:対応のあるt検定のノンパラ版
📖 包括的解説 — この概念を完全マスター
📍 学習の3ステップ
- 定義を理解する:この概念は何か? 数式や条件を確認
- 具体例を見る:実データ(SSDSE 等)で計算してみる
- 応用する:自分のデータに適用、 結果を解釈
🔧 Python実装パターン
data/raw/SSDSE-B-2026.csv(cp932 エンコード)と、注目したい 3 列(食料費・教育費・住居費)。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 基本パターン import pandas as pd import numpy as np from scipy import stats import matplotlib.pyplot as plt import seaborn as sns # データ読み込み df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') # 基本統計量 df.describe() # 可視化 sns.pairplot(df[['食料費', '教育費', '住居費']]) plt.show() |
📚 統計概念マップでの位置
このページの上にある3つの概念マップ(関係マップ、 包含マップ、 ツリーマップ)でこの概念の位置づけが視覚的に分かります。 関連手法を辿って学習を進めましょう。
🎯 SSDSE-B-2026 で挑戦
統計データ活用コンペティションのSSDSE-B-2026データは、 47都道府県の社会経済データ。 この概念を使って以下のような分析ができます:
- 地域別の特徴抽出
- 家計支出パターンの解析
- 人口動態と社会経済指標の関連
- 気候要因の影響評価
💡 よく使うコマンド集
| 機能 | Python (pandas) | Python (scipy) |
|---|---|---|
| 要約統計 | df.describe() | stats.describe() |
| 平均 | df.mean() | np.mean() |
| 標準偏差 | df.std() | np.std() |
| 相関 | df.corr() | stats.pearsonr() |
| t検定 | — | stats.ttest_ind() |
| 回帰 | — | stats.linregress() |
| 分布フィッティング | — | stats.norm.fit() |
🚧 一般的な落とし穴と対策
- 外れ値の影響:散布図・ 箱ひげ図で確認、 ロバスト手法も検討
- サンプルサイズ不足:power analysis で事前に確認
- 仮定の違反:正規性、 独立性、 等分散性をチェック
- 多重比較問題:補正(Bonferroni、 FDR)を適用
- p-hacking:事前登録(pre-registration)で防ぐ
- 因果と相関の混同:観察データから因果結論を出さない
📊 結果報告の標準フォーマット
- 点推定:得られた値
- 不確実性:信頼区間または標準誤差
- サンプルサイズ:n を明記
- 効果量:実質的な意義
- p値:統計的有意性
- 仮定の確認:診断プロット
🌐 関連分野での応用
- マーケティング:A/Bテスト、 顧客分析
- 医療:臨床試験、 疫学研究
- 金融:リスク管理、 ポートフォリオ
- 製造:品質管理、 工程最適化
- 公共政策:効果評価、 計画立案
- 研究:仮説検証、 探索的解析
🎓 さらに学ぶための文献
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression"
- VanderPlas "Python Data Science Handbook"
🔗 統計用語ネットワーク
この概念は、 他の多くの統計概念と密接に関連しています。 ジャストインタイム型学習では、 必要に応じて関連用語へジャンプしながら全体像を構築します。
主要な関連概念のグループ
| グループ | 主要概念 |
|---|---|
| 記述統計 | 平均、 中央値、 最頻値、 分散、 標準偏差、 共分散、 相関係数 |
| 可視化 | ヒストグラム、 散布図、 箱ひげ図、 ヒートマップ |
| 推測統計 | 標本平均、 標準誤差、 信頼区間、 p値、 有意水準 |
| 確率分布 | 正規分布、 t分布、 χ²分布、 F分布、 二項分布 |
| 仮説検定 | t検定、 F検定、 χ²検定、 ノンパラ検定 |
| 回帰 | 単回帰、 重回帰、 OLS、 Ridge、 LASSO |
| 分類 | ロジスティック回帰、 決定木、 SVM、 k-NN |
| 教師なし学習 | クラスタリング、 PCA、 因子分析 |
| 時系列 | ARIMA、 VAR、 指数平滑法、 自己相関 |
| 因果推論 | DiD、 IV、 傾向スコア、 交絡変数 |
| 前処理 | 標準化、 正規化、 欠損値処理、 多重共線性対策 |
| 評価 | R²、 残差、 CV、 RMSE、 効果量 |
学習順序の推奨
- 記述統計(平均、 分散、 標準偏差)
- 可視化(ヒストグラム、 散布図)
- 確率分布(正規分布)
- 推測統計(標準誤差、 信頼区間、 p値)
- 仮説検定(t検定、 χ²検定)
- 相関と回帰(単回帰、 重回帰)
- 多変量解析(PCA、 クラスタリング)
- 機械学習(決定木、 RF、 NN)
- 時系列・因果推論(応用)
📝 実践練習 — SSDSE-B-2026 で挑戦
初級課題
- 東北6県の家計食料費の基本統計量を計算
- 食料費のヒストグラムを描く
- 食料費と教育費の散布図を描く
- 都道府県を「東日本/西日本」に分け、 平均を比較
中級課題
- 家計支出 5項目で相関行列を作成、 ヒートマップ可視化
- 食料費 → 教育費の単回帰を実行、 残差分析
- 家計5項目で PCA を実施、 バイプロット表示
- k-means (k=3) で都道府県をクラスタリング、 解釈
上級課題
- 地域別の家計パターンに有意差があるか ANOVA で検定
- 重回帰で教育費を予測、 多重共線性を VIF で確認
- Ridge/LASSO で正則化、 CV で α を最適化
- 階層クラスタリングと Ward 法で都道府県を分類、 デンドログラム作成
🔖 キーワード索引(深掘り版)
論文・記事に登場する用語のリンクで該当箇所へジャンプ:
🧮 SSDSE-B 実値計算例:47都道府県データで「教育費」予測の変数選択
SSDSE-B-2026 2023年データで、 教育費を 20変数(家計の他項目)から予測する LASSO 回帰。 47サンプル × 20変数の典型的「サンプル少・変数多」状況で、 LASSO がどの変数を自動選択するか見ます。
📊 ステップ1:λ ごとの選択された変数数
| λ(正則化強度) | 非ゼロ係数の数 | CV-MSE | 選ばれた主な変数 |
|---|---|---|---|
| 0.001(弱) | 20 | 3.42 | 全変数(OLSとほぼ同じ) |
| 0.01 | 12 | 2.85 | 所得・住居・交通・通信・書籍・… |
| 0.05(最適) | 5 | 2.41 | 所得・住居・書籍・通信・補習教育 |
| 0.1 | 3 | 2.58 | 所得・書籍・補習教育 |
| 1.0(強) | 0 | 5.12 | 全て 0(切片のみ) |
5-fold CV で λ = 0.05 が最適(CV-MSE 最小)。 20 変数から 5 変数に自動絞り込み。 「所得・住居・書籍・通信・補習教育」が教育費予測の主要因子と判明。
📊 ステップ2:1-SE ルールでの保守的選択
「最小 CV-MSE の λ」より「最小 + 1標準誤差以内で最大の λ」を選ぶ 1-SE ルールがよく使われます。 これにより λ = 0.1(3変数)を選び、 さらに少数精鋭の解釈しやすいモデルになる。 過学習回避と解釈性のバランス。
📊 ステップ3:LARS パスの解釈
λ を大→小に動かすと、 最初に「所得」が入り、 次に「補習教育」、 「書籍」、 「住居」、 「通信」と順番に係数が 0 から立ち上がる。 このLASSO パスを可視化すれば、 変数の重要性順位が一目瞭然。
⚠️ LASSO の落とし穴(深掘り版・6件)
① 標準化を忘れる
LASSO は係数の絶対値の和を罰則にするので、 変数の単位に強く依存します。 たとえば「身長 cm」と「体重 kg」を混在させると、 数値が大きい変数(身長)の係数だけが小さくなり、 不公平に罰則がかかる。 必ず StandardScaler で全変数を平均 0・分散 1 に揃えてから LASSO を実行。 scikit-learn の Pipeline でラップしておけば自動。
② 相関の強い変数群から「ランダムに 1つ」だけ残る
x1, x2 が高相関の場合、 LASSO はどちらか1つだけを選び、 もう一方を 0 にしてしまう(どちらが選ばれるかは乱数や数値計算の微差で決まる)。 「グループとして重要なら両方残したい」場合は Elastic Net(L1+L2)が適切。 また Group LASSO は変数グループを丸ごと選択/不選択にできる。
③ LASSO 後の係数で p 値を計算する
LASSO で変数を選んだ後、 残った変数だけで OLS を再推定して p値を出す「post-LASSO」は過度に楽観的。 選択バイアスで p値が真値より小さく出ます。 正しくやるには Lockhart et al. (2014) の Covariance test、 selective inference、 de-sparsified LASSO といった専門手法が必要。 因果推論や仮説検定で LASSO を使うときの主要な研究課題。
④ λ を 1 つだけ手動で決める
「λ = 0.1 にした」と固定して結果を報告するのは再現性に欠ける。 必ずクロスバリデーションで λ を決め、 さらに 1-SE ルールも検討する。 sklearn の LassoCV なら自動。 ハイパーパラメータ探索のシードを変えて安定性も確認。
⑤ 係数を 0 と判定する閾値の問題
LASSO の解は数値計算なので、 完全に「0.0000」にはならず「1e-8」のような微小値が残ることがある。 「ほぼ 0 を 0 とみなす」閾値の置き方で「選ばれた変数」の数が変わります。 sklearn の lasso.coef_ はデフォルトでこの閾値処理がないので、 自前で np.abs(coef) > 1e-6 等で判定する。
⑥ 「予測精度向上」と「変数選択の正確性」を混同
LASSO は予測精度を上げる正則化手法ですが、 「真に重要な変数を正しく選ぶ」保証はありません。 シミュレーション研究で「真の活性変数が 10個」のとき、 LASSO は 15-20個を選び、 偽陽性が混じることが知られています。 「変数選択の正確性」を重視するならAdaptive LASSO、 SCAD、 MCP等の oracle property を持つ手法を検討。
🐍 Python 実装バリエーション
① scikit-learn LassoCV(λ自動選択)
X(説明変数、未標準化で OK:Pipeline 内で StandardScaler が処理)、y。alphas として 50 通りを対数刻みで指定。1 2 3 4 5 6 7 | from sklearn.linear_model import LassoCV from sklearn.preprocessing import StandardScaler from sklearn.pipeline import make_pipeline model = make_pipeline(StandardScaler(), LassoCV(cv=5, alphas=np.logspace(-3, 1, 50))) model.fit(X, y) print(model[-1].alpha_, model[-1].coef_) |
② scikit-learn Elastic Net(L1 + L2)
X_std, y。l1_ratio 候補は 0.1 → 1.0 の 5 段階。1 2 3 4 | from sklearn.linear_model import ElasticNetCV enet = ElasticNetCV(cv=5, l1_ratio=[0.1, 0.5, 0.7, 0.9, 1.0]) enet.fit(X_std, y) print(enet.l1_ratio_, enet.alpha_) |
③ LARS / LassoLars(厳密パス)
X_std, y。method='lasso' で LASSO 解パスを取得。1 2 3 | from sklearn.linear_model import LassoLars, lars_path alphas, _, coefs = lars_path(X_std, y, method='lasso') # coefs.shape = (n_features, n_alphas) — LASSOパスを可視化できる |
④ statsmodels — L1 ペナルティ付き OLS / Logistic
X_std, y。L1_wt=1.0 で完全 LASSO、0 で Ridge。1 2 3 | import statsmodels.api as sm res = sm.OLS(y, sm.add_constant(X_std)).fit_regularized(alpha=0.05, L1_wt=1.0) print(res.params) |
⑤ scipy.optimize — 自前で目的関数を最小化
勉強用に LASSO の目的関数を直接最適化する例。
X_std, y、初期係数 w0(ゼロベクトル)、α=0.05。1 2 3 4 | from scipy.optimize import minimize obj = lambda w, X, y, a: 0.5*((X@w-y)**2).sum() + a*np.abs(w).sum() w0 = np.zeros(X.shape[1]) res = minimize(obj, w0, args=(X_std, y, 0.05), method='L-BFGS-B') |
※ L1 は L-BFGS-B では非可微分のため厳密でない。 学習用としてのみ。
🗺️ 概念マップ — 3つの視点で体系を理解する
LASSO回帰 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 関連・回帰 › 回帰 › LASSO
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「LASSO回帰」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「LASSO回帰」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🎨 直感で掴む — Lasso は「席数限定の指標選抜」
SSDSE-B-2026 で「合計特殊出生率」を 30 個の指標から予測する場面を想像してください。 普通の最小二乗法は 30 個全員にステージ上の席を与えますが、 Lasso は L1 制約で「席は限られている」と宣告します。 結果、 影響が弱い変数の係数はピタリと 0 になり、 「残る指標」だけが舞台に立ちます。 これが「自動変数選択」の比喩です — Lasso 制約領域が菱形なので、 最適解は座標軸(係数 = 0)に張り付きやすいのです。
$\lambda$ を強くすると舞台はどんどん狭くなり、 最後には誰も残らず予測は平均だけになります。 逆に $\lambda = 0$ では全員残って最小二乗と一致します。 「ちょうどよい厳しさ」を交差検証で探すのが実務です。