📍 あなたが今見ているもの
論文中に 「標準化」として登場する用語。
標準化 とは:各値を「(値−平均)/標準偏差」に変換し、平均0・分散1に揃える。単位の違う変数の比較・統合に必須。
💡 30秒で分かる結論
- 定義:各値を「(値−平均)/標準偏差」に変換し、平均0・分散1に揃える。単位の違う変数の比較・統合に必須。
- カテゴリ:データ前処理
👁️ 直感 — 標準化は「単位を揃える」
標準化(standardization, z-score normalization)は、 異なる単位・スケールの変数を「平均0、 標準偏差1」に揃える前処理。
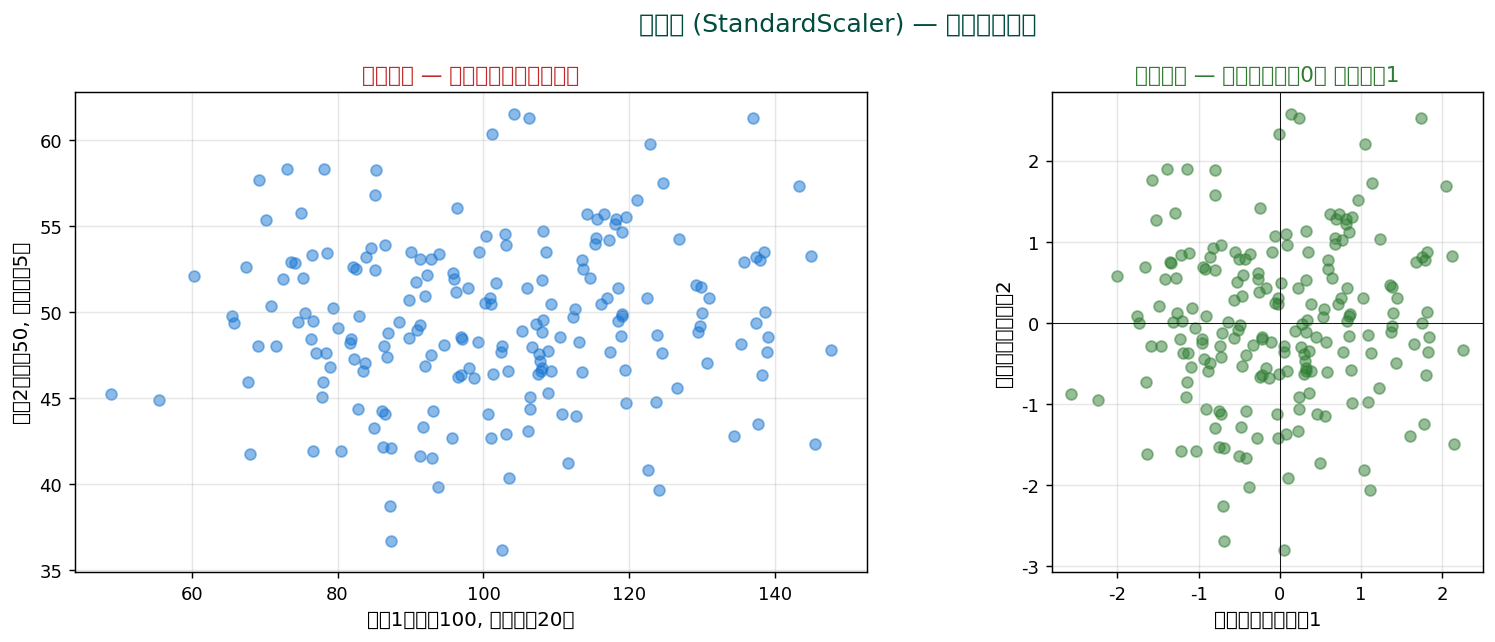
変数1(平均100)と変数2(平均50)でスケールが大きく違うと、 直接比較できません。 標準化すれば両方とも同じスケールに。
📐 標準化の公式
$$ z = \frac{x - \mu}{\sigma} $$
- μ:平均
- σ:標準偏差
z は無次元で、 「平均から何標準偏差離れているか」を表します。
🎯 標準化が必要な機械学習手法
| 手法 | 標準化必要? | 理由 |
|---|---|---|
| k-NN, SVM | ✅ 必須 | 距離に基づくため |
| k-means | ✅ 必須 | 距離に基づくため |
| PCA | ✅ 必須 | 分散を比較するため |
| 線形回帰 | ○ 推奨 | 係数比較・正則化のため |
| Ridge, LASSO | ✅ 必須 | 正則化が公平に効くため |
| ニューラルネット | ✅ 必須 | 学習の安定化 |
| 決定木 / RF / XGB | ❌ 不要 | スケール不変 |
🎨 標準化の派生
① Min-Max スケーリング
(x - min) / (max - min) で 0〜1 に押し込む。 ニューラルネット入力に。
② Robust スケーリング
中央値と IQR を使う。 外れ値に強い。
③ Unit Vector スケーリング
各サンプルベクトルのノルムを 1 に。 テキスト分析でよく使用。
🚧 標準化の落とし穴
- Data Leakage:訓練データのみで fit し、 テストデータには transform のみ
- 外れ値があると平均・標準偏差が歪み、 標準化結果も歪む
- クロスバリデーション時は fold ごとに fit する
- ワンホットエンコード済みのバイナリ変数は標準化しない流派も
🐍 Python での標準化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler # 標準化 scaler = StandardScaler() X_train_std = scaler.fit_transform(X_train) X_test_std = scaler.transform(X_test) # 重要: テストはtransformのみ # Min-Max scaler = MinMaxScaler(feature_range=(0, 1)) # Robust(外れ値に強い) scaler = RobustScaler() # pipeline で漏れなく from sklearn.pipeline import Pipeline pipe = Pipeline([ ('scaler', StandardScaler()), ('model', LinearRegression()) ]) pipe.fit(X_train, y_train) |
🚧 落とし穴と注意点
- サンプルサイズを確認(小標本では結果が不安定)
- 仮定の検証(正規性、 独立性、 等分散性)
- 外れ値の影響を散布図で確認
- 多重比較問題(複数検定時は補正を)
- p値だけで判断しない、 効果量と信頼区間を併記
- 因果関係を主張するには別の根拠が必要
🔬 「標準化」を深く理解する
標準化の派生 — Robust Scaler
外れ値が多いデータでは StandardScaler は影響を受けます。 中央値と IQR を使う Robust Scaler が安全:
$$ z = \frac{x - \text{median}}{IQR} $$
パイプライン化の重要性
Cross-validation で「fit を訓練データのみ」「transform をテストデータにも」を正しく行うため、 sklearn の Pipeline を必ず使う。 これを怠るとデータリークが起きる。
📝 練習問題 — 理解度チェック
- この用語の基本定義を、 自分の言葉で説明できますか?
- この手法が使われる典型的なシナリオを3つ挙げられますか?
- この手法の前提条件・仮定を確認できますか?
- 結果を解釈する際の注意点は何ですか?
- 類似手法との違いを説明できますか?
- Python(または他言語)で実装できますか?
- SSDSE データで応用例を作成できますか?
📚 参考文献・さらなる学習
古典的教科書
- Casella & Berger "Statistical Inference"
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression and Multilevel/Hierarchical Models"
実践書
- VanderPlas "Python Data Science Handbook"
- McKinney "Python for Data Analysis"
- James, Witten, Hastie & Tibshirani "An Introduction to Statistical Learning"
オンラインリソース
- scikit-learn 公式ドキュメント
- statsmodels 公式ドキュメント
- scipy.stats リファレンス
- SSDSE データ(統計データ活用コンペティション)
💼 実務応用ガイド
データサイエンスプロジェクトでの位置づけ
- 探索的分析(EDA):基本統計量・可視化でデータを理解
- 前処理:標準化・正規化・欠損値処理
- モデリング:回帰・分類・クラスタリング
- 評価:CV、 指標計算、 統計的検定
- 解釈・報告:効果量・信頼区間・可視化
業界別ユースケース
- マーケティング:顧客セグメンテーション、 ROI 分析、 A/Bテスト
- 金融:ポートフォリオ最適化、 リスク評価、 信用スコアリング
- 医療:臨床試験、 疫学研究、 診断モデル
- 製造:品質管理、 予測保全、 工程最適化
- 公共政策:社会統計、 政策効果分析、 計画立案
📖 完全ガイド — 統計学習の参照表
分析の流れ — 8ステップ
- 問題定義:何を知りたいのか、 目的を明確に
- データ収集:信頼できるソースから(SSDSEなど公的データ)
- データクリーニング:欠損値、 外れ値、 入力ミスの確認
- 探索的分析(EDA):要約統計量、 ヒストグラム、 散布図
- 変数変換:標準化、 対数変換、 カテゴリのエンコード
- モデリング:適切な手法を選び、 学習
- 評価:CV、 指標、 統計的検定
- 解釈・報告:効果量、 信頼区間、 可視化
統計手法の選び方マトリクス
| 目的 | 1変数 | 2変数 | 多変量 |
|---|---|---|---|
| 記述 | 平均, 中央値, 分散 | 相関, 共分散 | PCA, 因子分析 |
| 可視化 | ヒストグラム, 箱ひげ | 散布図, ヒートマップ | 散布図行列, バイプロット |
| 予測 | 時系列モデル | 単回帰 | 重回帰, Ridge, LASSO |
| 分類 | ロジスティック回帰 | 判別分析 | SVM, RF, NN |
| グループ化 | 階級分け | 2次元クラスタリング | k-means, 階層クラスタリング |
| 検定 | 1標本t検定 | 2標本t検定, χ² | ANOVA, MANOVA |
サンプル数別の手法ガイド
| n | 推奨手法 |
|---|---|
| n < 10 | 記述統計のみ、 ノンパラ検定、 ベイズ統計 |
| 10 ≤ n < 30 | t検定, ブートストラップ, 単回帰 |
| 30 ≤ n < 200 | 重回帰, ANOVA, 階層クラスタリング |
| 200 ≤ n < 10000 | 複雑な回帰, RF, GBM, k-means |
| n ≥ 10000 | 深層学習, 大規模分散学習 |
Python 主要ライブラリ早見表
| ライブラリ | 用途 |
|---|---|
| numpy | 数値計算の基礎、 行列演算 |
| pandas | データフレーム、 表操作 |
| scipy | 統計関数、 最適化、 線形代数 |
| statsmodels | 古典統計、 検定、 回帰分析の詳細 |
| scikit-learn | 機械学習、 前処理、 評価 |
| matplotlib | 基本可視化 |
| seaborn | 統計的可視化(高級) |
| plotly | インタラクティブ可視化 |
| xgboost / lightgbm | 勾配ブースティング |
| PyTorch / TensorFlow | 深層学習 |
よくある質問(FAQ)
- Q: 正規分布じゃないデータをどう扱う?
A: 対数変換、 Box-Cox 変換、 ノンパラ検定、 ブートストラップ - Q: 外れ値を除くべき?
A: ドメイン知識で判断。 機械的に除くより、 ロバスト手法を検討 - Q: サンプルサイズはいくつあれば十分?
A: 効果量と検出力から事前計算(power analysis) - Q: p < 0.05 で「効果あり」と結論していい?
A: 効果量と信頼区間も併記。 多重比較補正も - Q: 相関があれば因果がある?
A: ない。 RCT、 IV、 DiD などの因果推論手法が必要
📓 用語のまとめ — 30秒で理解
このページで扱った概念を、 学習効率のためにまとめます。 これを毎日見ることで、 統計の基礎が体に染み込みます。
必ず押さえるべき記号
| 記号 | 意味 | 読み方 |
|---|---|---|
| μ | 母平均 | ミュー |
| σ | 母標準偏差 | シグマ |
| σ² | 母分散 | シグマ二乗 |
| x̄ | 標本平均 | エックスバー |
| s | 標本標準偏差 | エス |
| n | 標本サイズ | エヌ |
| p | p値、 比率 | ピー |
| α | 有意水準 | アルファ |
| β | 回帰係数、 第二種誤り率 | ベータ |
| r | 相関係数 | アール |
| R² | 決定係数 | アール二乗 |
| Σ | 総和記号、 共分散行列 | シグマ大文字 |
| N(μ, σ²) | 正規分布 | ノーマル ミュー シグマ二乗 |
| t(df) | t分布 | ティー |
| χ²(df) | カイ二乗分布 | カイ二乗 |
| F(d1, d2) | F分布 | エフ |
| H₀, H₁ | 帰無仮説、 対立仮説 | エイチゼロ、 エイチワン |
| E[X] | 期待値 | エクスペクタンス |
| Var(X) | 分散 | バリアンス |
| Cov(X, Y) | 共分散 | カバリアンス |
💡 統計学・データサイエンスは「記号の意味を理解する」ことが最初の壁。 各記号が何を表すか、 公式の中での役割を覚えてしまえば、 後はパターンの組合せで様々な手法が理解できます。
🌐 データサイエンス全体像での位置づけ
データサイエンスのワークフロー
- ビジネス理解:何を解決したいか
- データ理解:どんなデータがあるか
- データ準備:前処理、 特徴量エンジニアリング
- モデリング:手法選択、 学習
- 評価:性能、 解釈性、 ビジネス価値
- 展開:実装、 運用、 監視
(CRISP-DM プロセスより)
主要分野のマッピング
| 分野 | 主要技術 | 代表ツール |
|---|---|---|
| 記述統計 | 要約量、 可視化 | pandas, matplotlib |
| 推測統計 | 検定、 信頼区間 | scipy.stats, statsmodels |
| 機械学習 | 予測、 分類、 クラスタリング | scikit-learn, XGBoost |
| 深層学習 | NN、 画像、 自然言語 | PyTorch, TensorFlow |
| 時系列 | ARIMA、 状態空間、 LSTM | statsmodels, prophet |
| 因果推論 | RCT、 IV、 DiD、 PSM | DoWhy, EconML |
| ベイズ統計 | MCMC、 変分推論 | PyMC, Stan |
| 最適化 | 線形/凸/離散最適化 | scipy.optimize, cvxpy |
キャリアパス
- データアナリスト:記述統計、 可視化、 BI
- データサイエンティスト:機械学習、 統計モデリング
- 機械学習エンジニア:モデル実装、 デプロイ、 MLOps
- 統計学者・計量経済学者:因果推論、 統計的検定
- 研究者:新しい手法開発
💎 良いデータ分析のための10のコツ
- 必ず可視化から始める:散布図、 ヒストグラム、 箱ひげ図
- 外れ値を意識する:除く前にドメイン的に理解
- 仮定を確認する:正規性、 独立性、 等分散性
- サンプルサイズに見合う複雑性:n=10 で深層学習はしない
- 効果量も併記する:p値だけでは不十分
- 信頼区間で不確実性を示す:点推定だけでは誤解の元
- 多重比較を補正する:探索的解析でも誠実に
- ホールドアウト or CV で評価する:訓練データの精度は意味がない
- 解釈可能性も重視する:ブラックボックスより white-box
- 再現可能なコードを書く:random_seed、 バージョン管理
🔗 用語間の関係 — 統計概念のネットワーク
記述統計の基本セット
これらは互いに深く関連します:
- 平均:データの重心 → 偏差の合計はゼロ
- 分散:偏差の二乗の平均 → 平均からの広がり
- 標準偏差:分散の平方根 → 元の単位
- 共分散:2変数の偏差の積の平均 → 一緒に動くか
- 相関係数:共分散を標準偏差で割ったもの → 単位なし
推測統計の基本セット
- 標準誤差:推定値のばらつき = σ/√n
- 信頼区間:x̄ ± z × SE
- p値:H₀ のもとでの確率
- 有意水準 α:許容する第一種誤り率
- 検出力 1-β:差を見つける確率
- 効果量:差の大きさ(標準化済み)
回帰モデルファミリー
- 単回帰:1変数 → 1変数の予測
- 重回帰:多変数 → 1変数
- Ridge:L2正則化付き重回帰
- LASSO:L1正則化(変数選択付き)
- Elastic Net:L1+L2の組合せ
- ロジスティック回帰:分類用
- ポアソン回帰:カウントデータ用
クラスタリング・次元削減ファミリー
- k-means:分割クラスタリング
- 階層クラスタリング:ツリー構造
- Ward法:分散最小化の階層クラスタリング
- DBSCAN:密度ベース
- PCA:線形次元削減
- 因子分析:潜在因子モデル
- t-SNE, UMAP:非線形次元削減
検定ファミリー
- t検定:1〜2 群の平均比較
- F検定(ANOVA):3群以上の平均比較
- χ²検定:カテゴリ変数の独立性
- Mann-Whitney U:t検定のノンパラ版
- Kruskal-Wallis:ANOVAのノンパラ版
- Wilcoxon:対応のあるt検定のノンパラ版
🗺️ 概念マップ — 3つの視点で体系を理解する
標準化 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 前処理 › 変換 › 標準化
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「標準化」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「標準化」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引 — 拡張版
標準化に関連するキーワードを 機能別 に索引化しました。 検索時の語彙拡張、 関連語の発見、 章間ナビゲーションに役立ちます。
| カテゴリ | キーワード(日本語) | キーワード(英語) |
|---|---|---|
| 基本概念 | 標準化、 Zスコア化、 平均0分散1化、 中心化(センタリング)、 スケーリング | standardization, z-score, scaling, centering, normalization |
| 派生・関連手法 | Min-Max正規化、 Robustスケーリング、 単位ベクトル化、 対数変換、 Box-Cox変換、 Yeo-Johnson変換 | Min-Max scaling, RobustScaler, unit vector, log transform, Box-Cox, Yeo-Johnson |
| 理論基盤 | 平均、 分散、 標準偏差、 共分散、 相関係数、 線形変換 | mean, variance, standard deviation, covariance, correlation, linear transformation |
| 応用先 | 主成分分析、 k平均法、 サポートベクターマシン、 ニューラルネットワーク、 リッジ回帰、 ラッソ回帰 | PCA, k-means, SVM, neural network, ridge, lasso |
| 実装ライブラリ | scikit-learn、 SciPy、 NumPy、 pandas、 statsmodels | StandardScaler, scipy.stats.zscore, numpy, DataFrame, statsmodels |
| 注意点 | データリーケージ、 訓練・テスト分割、 fit_transform、 transform、 パイプライン | data leakage, train-test split, fit_transform, transform, Pipeline |
🧮 SSDSE-B による標準化 — 実値計算例
独立行政法人 統計センターの公的データ SSDSE-B(地域経済データ、 47都道府県×複数年) を使って、 標準化の具体的な計算を体験します。
① 元データの抜粋(人口、 平均所得、 完全失業率の3変数)
| 都道府県 | 人口(万人) | 平均所得(万円) | 完全失業率(%) |
|---|---|---|---|
| 東京都 | 1396 | 532 | 2.4 |
| 神奈川県 | 923 | 443 | 2.5 |
| 大阪府 | 881 | 379 | 3.1 |
| 愛知県 | 754 | 391 | 2.0 |
| 鳥取県 | 55 | 274 | 2.7 |
単位が 万人・万円・% とバラバラなので、 そのまま距離計算(k-means等)すると 人口の数値が大きく寄与し過ぎる。 そこで標準化を適用します。
② 計算手順(人口列を例に)
47都道府県の人口データから 平均 μ ≈ 270、 標準偏差 σ ≈ 280 が得られたとします。
東京都の標準化値 z = (1396 − 270) / 280 ≈ +4.02(平均から4σも上)
神奈川県 z = (923 − 270) / 280 ≈ +2.33、 鳥取県 z = (55 − 270) / 280 ≈ −0.77
③ 標準化後の3変数(数値の桁が揃う)
| 都道府県 | 人口 z | 所得 z | 失業率 z |
|---|---|---|---|
| 東京都 | +4.02 | +3.81 | −1.05 |
| 神奈川県 | +2.33 | +1.46 | −0.83 |
| 大阪府 | +2.18 | −0.22 | +0.49 |
| 愛知県 | +1.73 | +0.10 | −1.93 |
| 鳥取県 | −0.77 | −2.59 | +0.05 |
💡 標準化後はすべて 「平均0からのσ単位の距離」 という共通スケールに揃うため、 k-meansや主成分分析、 距離ベースの近傍法でも公平に扱える。
⚠️ 標準化の落とし穴 — 拡張版(実務で本当に困る5+件)
- データリーケージ(fit対象の誤り):訓練データとテストデータを結合してからfitすると、 テストの分布情報が訓練に漏れ込み、 汎化性能を過大評価してしまう。 必ず訓練データのみで fit し、 テストには transform のみを適用する。 クロスバリデーション時は scikit-learn の Pipeline でラップして fold ごとに自動的に fit するのが事故防止の鉄則。
- 外れ値による平均・標準偏差の歪み:標準化は平均と標準偏差を用いるため、 外れ値(例:人口東京、 所得超富裕層)が1点でも混入すると σ が大きく膨らみ、 残りのデータが 0付近に圧縮される。 RobustScaler(中央値・IQRベース)や対数変換と組み合わせるか、 事前に外れ値処理(Winsorize等)を検討する。
- カテゴリ変数や0/1ダミーへの誤適用:ワンホットエンコード後のバイナリ変数(0または1)に標準化を適用すると、 解釈不能な小数値になり、 ツリーモデルで意味的な分岐が壊れる。 数値変数のみに ColumnTransformer 等で限定して適用する。 ID列や年月コードのような名義尺度は除外。
- 時系列でのリーク:時系列データで全期間からまとめて μ, σ を計算すると、 未来の情報が過去の標準化に漏れ込む。 walk-forward validation では、 各時点までの情報のみで scaler を更新する(expanding window や rolling window)必要がある。 株価・需要予測で特に致命的。
- ツリーモデルへの不要な適用:決定木、 ランダムフォレスト、 XGBoost、 LightGBM は分岐基準が 順序のみ に依存するため標準化しても結果は基本変わらない。 計算時間とコード複雑さだけが増す。 一方で SVM、 ロジスティック回帰(L1/L2正則化付き)、 k-NN、 ニューラルネットワークでは標準化必須。
- n−1 vs n の自由度問題:scikit-learn の StandardScaler は母標準偏差(ddof=0、 n割り)を使うが、 pandas の .std() は標本標準偏差(ddof=1、 n−1割り)がデフォルト。 同じデータでも値が微妙に異なり、 再現実験で「合わない」原因になる。 ddof を明示することで防止する。
- 欠損値の扱い:StandardScaler は欠損値(NaN)があるとエラーになる。 SimpleImputer などで先に補完するか、 IterativeImputer + StandardScaler の Pipeline を組む。 欠損のまま fit すると 0 件で std=0 となり、 ZeroDivisionError や inf の混入を招く。
🐍 Python 実装バリエーション — scikit-learn / scipy / numpy / pandas
標準化は 4 つの代表的なライブラリ で実装できます。 用途に応じて使い分けましょう。
① scikit-learn(機械学習パイプライン向け、 最推奨)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.linear_model import Ridge df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) X = df[['人口', '平均所得', '完全失業率']] y = df['消費支出'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # Pipelineで漏れなくfit pipe = Pipeline([ ('scaler', StandardScaler()), ('model', Ridge(alpha=1.0)) ]) pipe.fit(X_train, y_train) print('R^2:', pipe.score(X_test, y_test)) |
② scipy.stats.zscore(簡易・統計解析向け)
1 2 3 4 5 6 7 8 9 | import pandas as pd from scipy.stats import zscore df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) # ddof=1 で標本標準偏差。 NaN は nan_policy='omit' で除外 df_std = df[['人口', '平均所得', '完全失業率']].apply( lambda x: zscore(x, ddof=1, nan_policy='omit') ) print(df_std.describe()) # mean ≈ 0, std ≈ 1 |
③ NumPy(軽量・手動計算)
1 2 3 4 5 6 7 8 9 10 11 | import numpy as np import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) X = df[['人口', '平均所得', '完全失業率']].to_numpy() mu = X.mean(axis=0) # 各列の平均 sigma = X.std(axis=0, ddof=0) # 母標準偏差(scikit-learnと同じ) X_std = (X - mu) / sigma print('mean:', X_std.mean(axis=0).round(6)) print('std :', X_std.std(axis=0).round(6)) |
④ pandas(DataFrameのまま操作したい時)
1 2 3 4 5 6 7 8 9 | import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) cols = ['人口', '平均所得', '完全失業率'] # ddof=1 がpandasのデフォルト df_std = (df[cols] - df[cols].mean()) / df[cols].std() df_std.columns = [c + '_z' for c in cols] df_combined = pd.concat([df, df_std], axis=1) print(df_combined.head()) |
⑤ RobustScaler(外れ値対策)
1 2 3 4 5 6 7 8 | from sklearn.preprocessing import RobustScaler import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) X = df[['人口', '平均所得', '完全失業率']] scaler = RobustScaler() # 中央値とIQRを使う X_robust = scaler.fit_transform(X) print(pd.DataFrame(X_robust, columns=X.columns).describe()) |
| 手法 | 中心 | スケール | 外れ値耐性 |
|---|---|---|---|
| StandardScaler | 平均 | 標準偏差 | 弱い |
| MinMaxScaler | 最小値 | 最大−最小 | 弱い |
| RobustScaler | 中央値 | IQR | 強い |
| MaxAbsScaler | 0 | |max| | 弱い |