📍 あなたが今見ているもの
論文中に 「平均」として登場する用語。
平均 とは:全データの合計 ÷ 個数。データの「中心」を表す代表値だが、外れ値の影響を受けやすい。
💡 30秒で分かる結論
- 定義:全データの合計 ÷ 個数。データの「中心」を表す代表値だが、外れ値の影響を受けやすい。
- カテゴリ:記述統計
📖 もっと詳しく
平均(mean)は、 全データの合計を個数で割った最も基本的な代表値です。 df.mean() で一発計算。
意味:「データの中心」を1点で表現する代表値。 全データ点の重心に対応します。
強み:(i) 数学的に扱いやすい(微分・線形性)、 (ii) 全データを使うので情報量が多い、 (iii) 回帰モデルの中核(平均からのズレ=偏差が分散・回帰係数を作る)。
弱点:外れ値の影響を強く受ける。 1個の極端な値で平均は大きく動きます。 例えば年収の平均は、 ごく少数の超富裕層によって押し上げられるため、 「平均的な人」を表しません。 そういうときは中央値が適切。
分布が歪んでいる場合(所得分布、 株価、 地震被害額など)、 平均より中央値が代表値として優れます。
🎨 直感で掴む — 平均は「データの重心」
下の図は、 47都道府県の家計食料費(2023年・ SSDSE-B-2026)を1次元の数直線上にプロットしたものです。 各点が1つの都道府県。 赤い縦線が平均、 オレンジ点線が中央値。
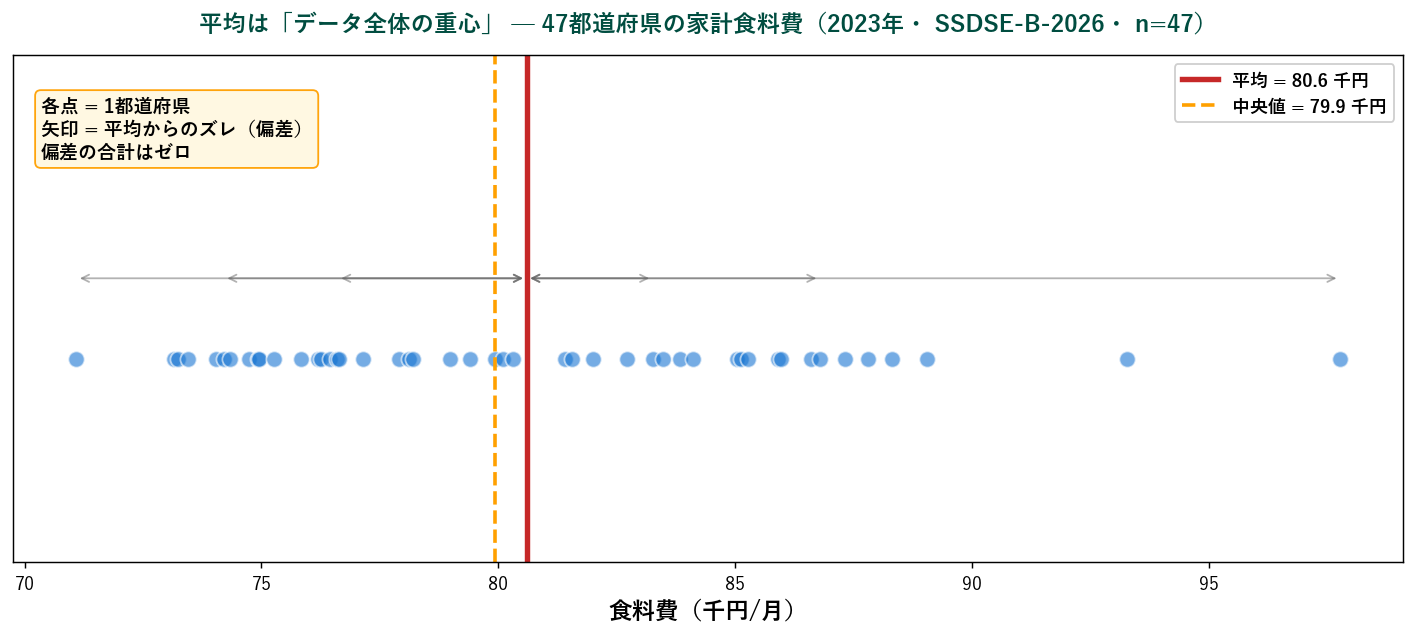
🪨 物理的な意味:シーソーのバランス点
各データ点に同じ重さの「玉」を置いたとき、 シーソーが釣り合う支点こそが平均です。 これを数式で表すと:
$$ \sum_{i=1}^{n} (x_i - \bar{x}) = 0 $$
「各データから平均までの距離(偏差)を全部足すと、 ぴったりゼロになる」という意味。 上向きの引っ張りと下向きの引っ張りが釣り合っているからです。 これが「重心」と呼ばれる所以。
💡 平均は幾何学的には「重心」、 数学的には「偏差の総和をゼロにする点」、 確率論的には「期待値」、 機械学習的には「最小二乗推定量」。 同じものを多角的に見ることで深く理解できます。
🧮 計算ステップ — 東北6県の食料費で手計算
47都道府県データの中から、 東北6県を抜き出して手で平均を計算します。 SSDSE-B-2026 の家計食料費(2023年、 単位:千円/月)です。
1️⃣ データを並べる(n = 6)
| 都道府県 | 食料費(千円/月) |
|---|---|
| 青森県 | 77.90 |
| 秋田県 | 78.12 |
| 福島県 | 78.98 |
| 岩手県 | 82.00 |
| 宮城県 | 83.83 |
| 山形県 | 84.11 |
| 合計 | 484.94 |
2️⃣ 公式に当てはめる
$$ \bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i = \frac{x_1 + x_2 + \cdots + x_n}{n} $$
3️⃣ 数値を代入
- 合計: x₁ + x₂ + ... + x₆ = 484.94 千円
- 個数: n = 6
- 平均: x̄ = 484.94 ÷ 6 = 80.824 千円
東北6県の家計食料費の平均は約80.8千円。 全国平均(80.6千円)と比較するとやや多いことが分かります。
4️⃣ 偏差の検証(重心の性質)
各データから平均を引いた「偏差」を求めます:
| 都道府県 | 食料費 xᵢ | 偏差 (xᵢ - x̄) |
|---|---|---|
| 青森県 | 77.90 | -2.925 |
| 秋田県 | 78.12 | -2.700 |
| 福島県 | 78.98 | -1.840 |
| 岩手県 | 82.00 | +1.173 |
| 宮城県 | 83.83 | +3.011 |
| 山形県 | 84.11 | +3.281 |
| 偏差の合計 | 0.000000 ≈ 0 |
偏差の合計が(丸め誤差を除き)ゼロになることが確認できます。 これが「平均は重心」と呼ばれる所以。 正の偏差と負の偏差が互いに打ち消し合う点が平均。
📐 数式と読み方ガイド — 記号の意味をすべて解説
平均の定義式は教科書で必ず見るものですが、 記号の意味を1つずつ丁寧に読み解きます。
① 標本平均(sample mean)
$$ \bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i $$
| 記号 | 読み方 | 意味 |
|---|---|---|
| x̄ | エックスバー | 標本平均。 観測したデータから計算された平均値 |
| n | エヌ | 標本サイズ(データの個数) |
| xᵢ | エックスサブアイ/エックスアイ | i番目のデータ点。 i は 1, 2, ..., n まで動く |
| Σ | シグマ(大文字)/総和記号 | 「全部足す」を意味する。 「∑」の下に開始、 上に終了が書かれる |
| ∑ᵢ₌₁ⁿ xᵢ | シグマ アイ イコール 1 から エヌまで エックスアイ | x₁ + x₂ + ... + xₙ の略記 |
| 1/n | エヌぶんのいち | 合計を個数で割る → 1個あたりの値 |
② 母平均(population mean)
$$ \mu = \frac{1}{N} \sum_{i=1}^{N} x_i = \mathbb{E}[X] $$
- μ(ミュー): 母集団全体の平均。 ふつう未知(推定対象)
- N: 母集団の大きさ。 全数(しばしば無限大)
- E[X]: 期待値(expected value)。 確率変数 X の重み付き平均
標本平均 x̄ は母平均 μ の不偏推定量:何度もサンプリングして平均を取れば、 期待値は μ に一致します(E[x̄] = μ)。
🔬 数式を言葉で読み解く — ③ なぜ「÷ n」なのか?
合計だけでは「データが多ければ多いほど大きくなる」だけで、 中心の位置情報になりません。 個数で割ることで「1個あたりの代表値」になります。 これが平均が個体の比較に使える理由。
④ 線形性という強力な性質
$$ \bar{a x + b y} = a \bar{x} + b \bar{y}, \quad \bar{c} = c $$
これが「平均の線形性」。 a, b, c は定数。 この性質のおかげで、 平均は計算が簡単で、 回帰モデルの中核に使えます。 例:年収を1.1倍して10万円足したものの平均は、 元の平均を1.1倍して10万円足したものと同じ。
🔢 4種類の平均 — 目的によって使い分ける
「平均」と一口に言っても、 実は4つの主要な種類があります。 同じデータでも目的によって値が変わります。
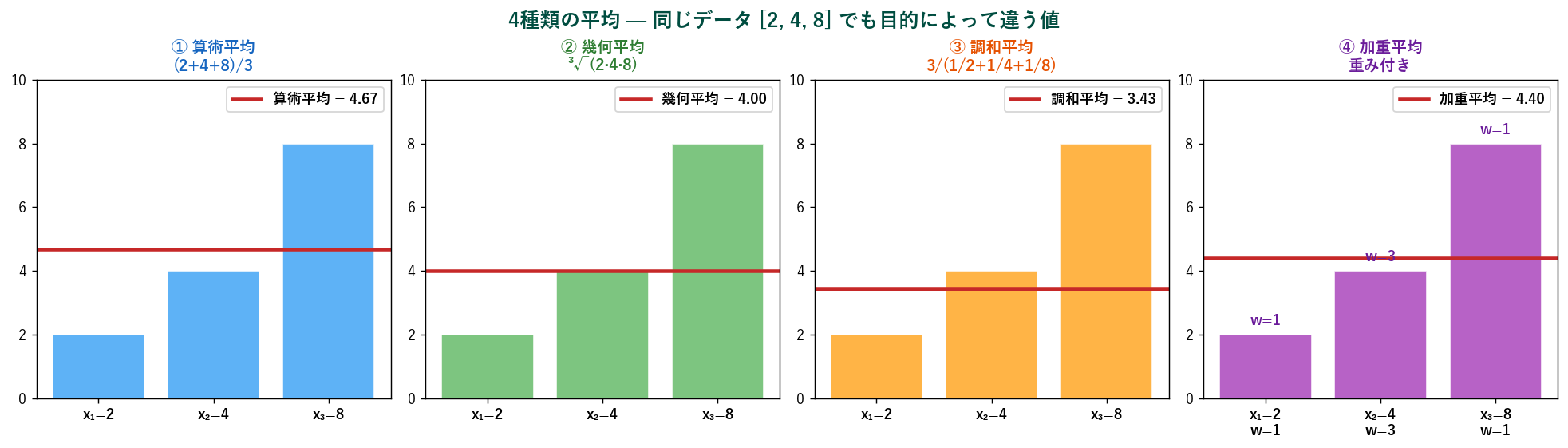
① 算術平均(arithmetic mean) — 最も一般的
$$ \bar{x}_A = \frac{1}{n} \sum x_i $$
普段「平均」と言えばこれ。 単純な代表値、 線形性を持ち、 微分可能。 全データを足して個数で割る。
② 幾何平均(geometric mean) — 成長率・複利
$$ \bar{x}_G = \sqrt[n]{x_1 \cdot x_2 \cdots x_n} = \left( \prod_{i=1}^{n} x_i \right)^{1/n} $$
「掛け算ベース」の平均。 使い時:成長率(毎年110%, 90%, 105% の平均成長率)、 複利、 比率の平均、 GDP 成長率、 株価収益率、 ジャズの売上倍率。 算術平均より小さいか等しい(AM ≥ GM)。
例:年率 +50%, -50% の2年で投資はどうなる? 算術平均 → (50-50)/2 = 0%(変わらない?)。 幾何平均 → √(1.5×0.5) = 0.866 → 年率 -13.4%(実際は損!)。 こういう時は幾何平均が正解。
③ 調和平均(harmonic mean) — 速度・並列処理
$$ \bar{x}_H = \frac{n}{\sum_{i=1}^{n} \frac{1}{x_i}} $$
逆数の平均の逆数。 使い時:往復速度の平均(行き60km/h、 帰り40km/hの平均は調和平均で48km/h)、 並列処理の合算スループット、 F1スコア(精度と再現率の調和平均)。 算術平均よりもっと小さい(HM ≤ GM ≤ AM)。
④ 加重平均(weighted mean) — 重要度に差がある時
$$ \bar{x}_W = \frac{\sum w_i x_i}{\sum w_i} $$
各データに「重み w」を付けた平均。 使い時:成績の加重平均(単位数×評点)、 ポートフォリオのリターン(資産比率×収益率)、 全国平均(県別人口×値)の集計。 各値の重要度が異なるときに必須。
大小関係:AM ≥ GM ≥ HM
非負の値については、 算術平均 ≥ 幾何平均 ≥ 調和平均 が常に成立(イェンセンの不等式の特殊例)。 等しくなるのは全データが同じ時だけ。
📊 大数の法則と中心極限定理 — 平均の魔法
平均が統計学の中核である理由は、 2つの偉大な定理があるから。 サンプル数が多いほど標本平均は「真の値」に収束し、 「正規分布」に近づきます。
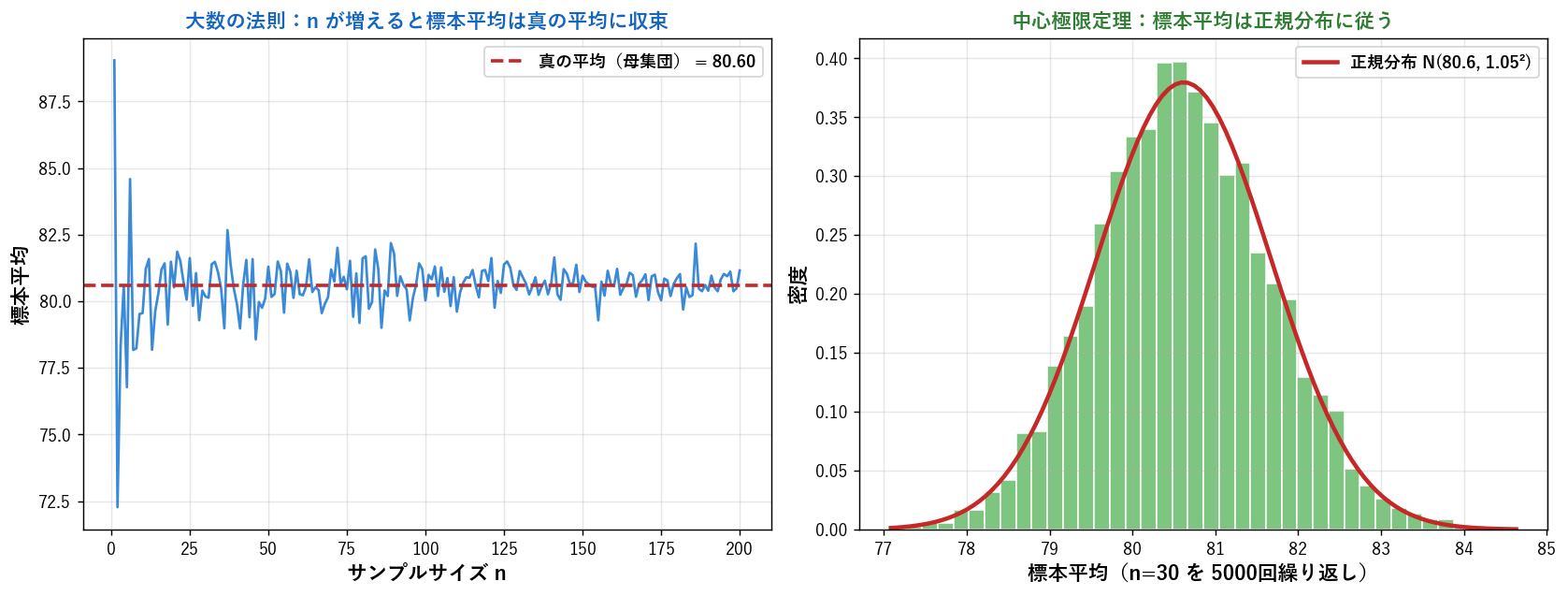
① 大数の法則(Law of Large Numbers, LLN)
「サンプルサイズが大きくなるほど、 標本平均は母平均に収束する」
$$ \bar{X}_n \xrightarrow{n \to \infty} \mu $$
読み方:「ノットサンクラスのバーエックス サブ エヌ は n が無限大に向かう時、 ミューに収束する」。 上の図の左を見ると、 n が小さい時は標本平均は揺れますが、 n が大きくなるほど赤い破線(真の平均 = 80.60)に収束していくのが分かります。
② 中心極限定理(Central Limit Theorem, CLT)
「標本平均の分布は、 元の分布が何であれ、 n が大きいと正規分布に近づく」
$$ \bar{X}_n \sim N\left(\mu, \frac{\sigma^2}{n}\right) \quad (n \to \infty) $$
- μ:母平均(標本平均の期待値)
- σ²/n:標本平均の分散(n が大きいほど小さい)
- σ/√n:標準誤差(standard error)。 標本平均のばらつき
上の図の右を見ると、 元のデータ(食料費)の分布がどんな形でも、 標本平均を5000回計算した分布はきれいな釣り鐘形(正規分布)になっています。 これがCLTの威力。
CLTがなぜ重要か
CLTのおかげで:
- 標本平均の信頼区間を計算できる(正規分布なので)
- 仮説検定(t検定、 z検定)の前提が成立する
- サンプルサイズ計算ができる
多くの統計分析が「平均を扱う」ことに集中している理由はここにあります。 CLTにより平均は予測可能になるからです。
🎯 平均の信頼区間 — どこまで信用できる?
標本平均 x̄ が出ても、 「母平均 μ はどこにあるか」は分かりません。 そこで「95%の確率で μ が含まれる範囲」を計算するのが信頼区間。
公式(σ未知、 n小、 t分布)
$$ \bar{x} \pm t_{\alpha/2, n-1} \cdot \frac{s}{\sqrt{n}} $$
- x̄:標本平均
- s:標本標準偏差
- n:標本サイズ
- s/√n:標準誤差。 平均のばらつき
- t_{α/2, n-1}:自由度 n-1 のt分布の臨界値(α=0.05 なら2.045前後)
実データでの計算(東北6県の食料費)
- 標本平均: x̄ = 80.824 千円
- 標本標準偏差: s = 2.844 千円
- 標本サイズ: n = 6
- 標準誤差: SE = s/√n = 2.844/√6 = 1.1610
- 自由度: df = n - 1 = 5
- t臨界値(α=0.05): t = 2.571
- 95%信頼区間: x̄ ± t·SE = 80.824 ± 2.984 = [77.84, 83.81] 千円
💡 結論:「東北6県の母平均食料費は、 95%の信頼度で[77.8, 83.8]千円の範囲にある」。 区間が広いほど不確実、 狭いほど精度が高い推定。
⚠️ 外れ値の影響 — 平均は崩壊しやすい
平均の最大の弱点は外れ値に弱いこと。 1つの極端な値が代表値を大きく歪めます。
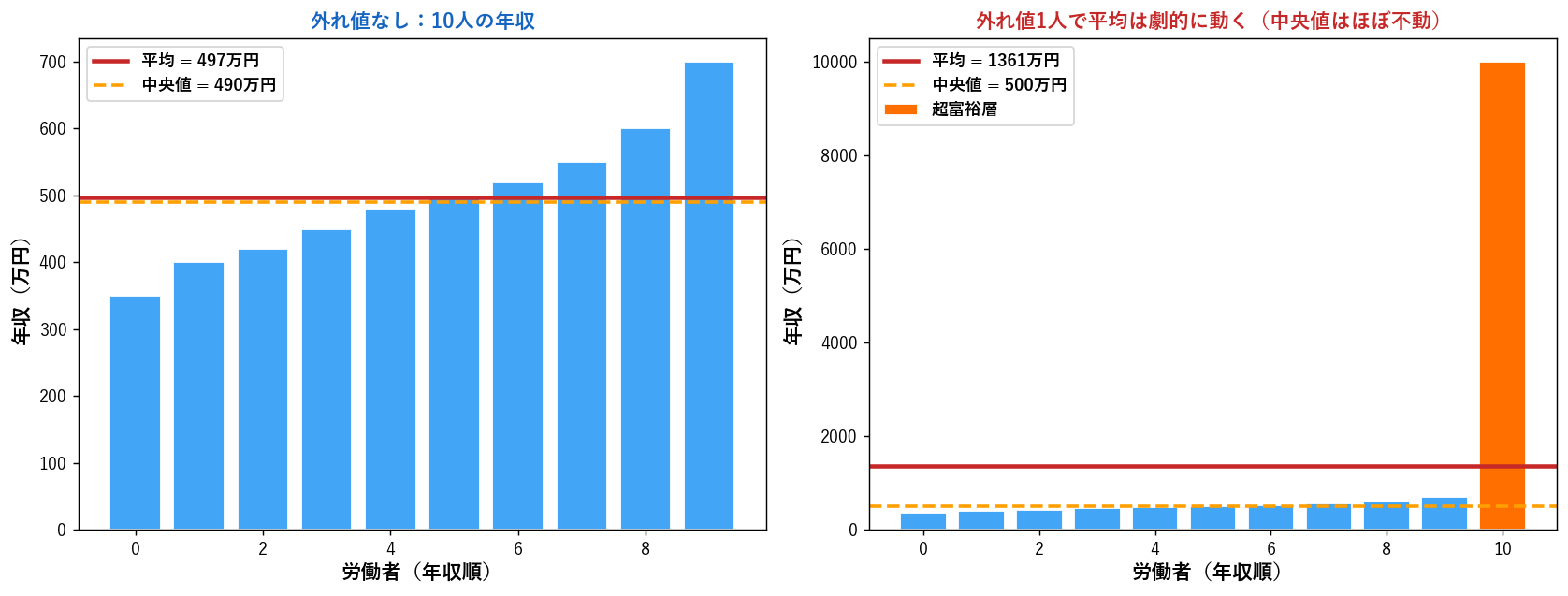
左:通常の10人の年収(350〜700万円)。 平均と中央値は近い(500万円前後)。
右:そこに「年収1億円の人」を1人足しただけ。 平均は劇的に上がるのに、 中央値はほぼ動かない。
ロバスト推定 — 外れ値に強い代表値
| 手法 | 説明 | 外れ値耐性 |
|---|---|---|
| 算術平均 | 全データの平均 | ❌ 弱い |
| 中央値 | 並べた真ん中の値 | ✅ 強い(崩壊点50%) |
| トリム平均 (trimmed mean) | 上下10%を捨てた残りの平均 | ⭕ 中程度 |
| ウィンザー化平均 (winsorized mean) | 上下10%を境界値に置換した平均 | ⭕ 中程度 |
| M推定 | 外れ値の影響を減らす重み付け | ✅ 強い |
判断フロー
- 分布の確認:ヒストグラムを描く。 対称か、 歪んでいるか
- 分布が対称(正規分布など):平均が最適
- 分布が歪んでいる or 外れ値あり:中央値 or トリム平均が代表値として優れる
- 所得分布のような対数正規:幾何平均 or 対数変換後の平均が直感的
🐍 Python での計算 — pandas, numpy, statistics の使い分け
Pythonでは複数のライブラリで平均を計算できます。 状況によって使い分けます。
① pandas(データフレーム)— 最も多用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import pandas as pd # SSDSE データを読み込む df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') # 1変数の平均 mean_food = df['食料費'].mean() print(f'食料費の平均: {mean_food:.2f} 千円') # 全数値列の平均を一気に all_means = df.mean(numeric_only=True) print(all_means.head()) # グループ別平均(地域別など) by_region = df.groupby('地域')['食料費'].mean() print(by_region) # 加重平均(人口で重み付け) weighted_mean = (df['食料費'] * df['人口']).sum() / df['人口'].sum() print(f'人口加重平均: {weighted_mean:.2f}') |
② numpy(数値計算)— 配列処理に最適
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import numpy as np # 配列からの平均 arr = np.array([2.0, 4.0, 8.0]) print(np.mean(arr)) # 4.667 print(arr.mean()) # 同じ # 軸指定(多次元配列) mat = np.array([[1, 2, 3], [4, 5, 6]]) print(np.mean(mat, axis=0)) # [2.5, 3.5, 4.5] - 列ごと print(np.mean(mat, axis=1)) # [2.0, 5.0] - 行ごと # 加重平均 np.average(arr, weights=[1, 3, 1]) # 重み付き # 欠損値を含む場合 arr_nan = np.array([1, 2, np.nan, 4]) print(np.nanmean(arr_nan)) # 2.333 - NaN を無視 |
③ scipy — 幾何平均・調和平均・トリム平均
1 2 3 4 5 6 7 8 9 | from scipy import stats arr = [2.0, 4.0, 8.0] print(stats.gmean(arr)) # 4.0 - 幾何平均 print(stats.hmean(arr)) # 3.429 - 調和平均 # トリム平均(上下10%をカット) data_with_outlier = [1, 2, 3, 4, 5, 100] print(stats.trim_mean(data_with_outlier, proportiontocut=0.1)) |
④ statistics(標準ライブラリ)— シンプル
1 2 3 4 5 6 7 | import statistics arr = [2.0, 4.0, 8.0] print(statistics.mean(arr)) # 4.667 print(statistics.geometric_mean(arr)) # 4.0 print(statistics.harmonic_mean(arr)) # 3.429 print(statistics.fmean(arr)) # 4.667(高速版、 float のみ) |
⑤ 信頼区間の計算
1 2 3 4 5 6 7 8 9 10 11 | import numpy as np from scipy import stats data = np.array([77.90, 78.12, 78.98, 82.00, 83.83, 84.11]) mean = data.mean() se = data.std(ddof=1) / np.sqrt(len(data)) t_crit = stats.t.ppf(0.975, df=len(data)-1) ci_low = mean - t_crit * se ci_high = mean + t_crit * se print(f'95%CI: [{ci_low:.2f}, {ci_high:.2f}]') |
🌳 平均の使い分けフロー
状況によって適切な平均は異なります。 以下のフローに従って選びます:
- データの性質は?
- 絶対値(収入、 身長など) → 算術平均が基本
- 比率・倍率(成長率、 収益率) → 幾何平均
- 速度・スループット → 調和平均
- 各値の重要度が違う → 加重平均
- 分布の形は?
- 対称・正規分布 → 算術平均
- 歪んでいる、 裾が長い → 中央値(または対数変換)
- 外れ値あり → 中央値 or トリム平均
- 目的は?
- 1個あたりの代表値 → 算術平均
- 中央的な「典型値」 → 中央値
- 分布の頂点 → 最頻値
- 不確実性の評価 → 信頼区間
🚧 平均の落とし穴 — よくある誤用と対策
1️⃣ 外れ値の影響を見落とす
所得分布や被害額のような歪んだ分布では、 平均は「典型的な値」を表しません。 必ずヒストグラムや箱ひげ図で分布を確認。 「日本人の平均貯蓄額」が高く出るのも、 富裕層の影響です。
2️⃣ シンプソンのパラドックス
全体での平均と、 部分での平均が逆になることがあります。 集計レベルが違うと、 結論が変わる。 必ず複数のレベルで確認。
3️⃣ 加重なしの平均(生態学的誤謬)
「都道府県の平均所得」を単純平均すると、 人口の多い都市県の影響が過小評価されます。 全国全体を語るなら人口で加重すべき。
4️⃣ 比率の平均
「3社の利益率(10%, 20%, 30%)の平均は20%」は、 売上規模が同じならOKだが、 普通は加重平均すべき。 単純平均は誤解の元。
5️⃣ 成長率の平均
「3年で +10%, +20%, -10% の成長」の平均成長率を算術平均で出すと(10+20-10)/3 = 6.67%だが、 これは誤り。 正しくは幾何平均:³√(1.1×1.2×0.9) = 1.058 → 5.8%。
6️⃣ サンプルサイズが小さい
n=3 の平均は信頼性が低い。 必ず信頼区間を併記、 または最低 n≥30 で計算。 CLTが成立するサンプルサイズが目安。
📈 47都道府県の家計食料費の分布
SSDSE-B-2026 のデータをヒストグラムで可視化。 平均(赤線)と中央値(オレンジ点線)の位置関係も確認できます。
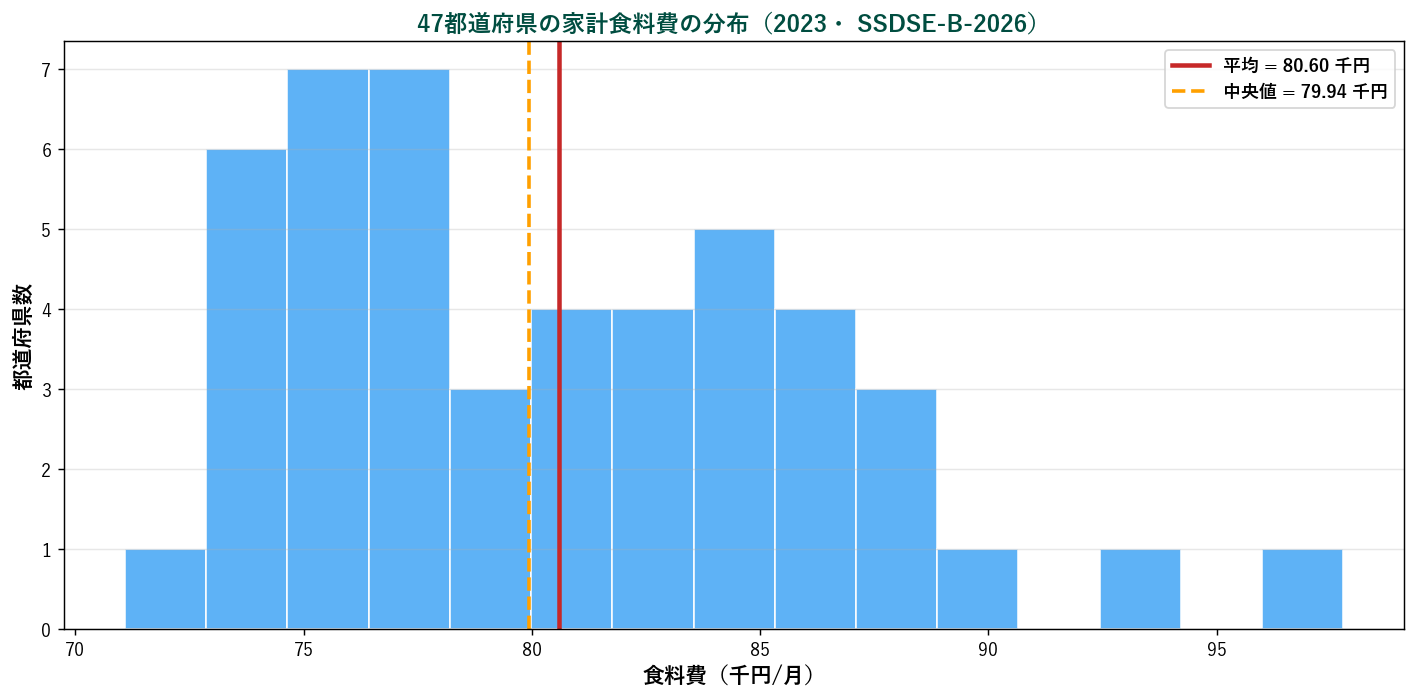
分布は概ね右に裾を引いており(少数の高額県あり)、 平均は中央値よりやや右にあります。 これは「平均は外れ値に引っ張られる」典型例。 分布が歪んでいる場合の代表値は中央値の方が安全です。
📉 移動平均 — 時系列データの平滑化
時系列データ(株価、 売上、 気温)のノイズを取り除く最も基本的な平滑化が移動平均。 直近 N 個のデータの平均を窓を動かしながら計算します。
① 単純移動平均(SMA: Simple Moving Average)
$$ \text{SMA}_t = \frac{1}{N} \sum_{i=t-N+1}^{t} x_i $$
「最後の N 個の単純平均」。 窓を1ステップずつスライドさせて計算。 N が大きいほど平滑化が強くなる。
② 指数移動平均(EMA: Exponential Moving Average)
$$ \text{EMA}_t = \alpha \cdot x_t + (1 - \alpha) \cdot \text{EMA}_{t-1} $$
「新しいデータほど重みを大きく」。 α(0〜1)は平滑化係数。 機械学習のAdam optimizer、 株式のテクニカル分析、 IoT センサーのノイズ除去で頻繁に使われます。
Python 実装
1 2 3 4 5 6 7 8 9 10 11 12 13 | import pandas as pd # pandas で時系列移動平均 df['SMA_7'] = df['売上'].rolling(window=7).mean() # 7日 SMA df['EMA_7'] = df['売上'].ewm(span=7, adjust=False).mean() # 7日 EMA # 中心化移動平均(過去+未来の窓) df['CMA_7'] = df['売上'].rolling(window=7, center=True).mean() # 加重移動平均 weights = [1, 2, 3, 4, 5] df['WMA_5'] = df['売上'].rolling(window=5).apply( lambda x: (x * weights).sum() / sum(weights), raw=True) |
🤖 機械学習での平均の役割
① 損失関数の中核:平均二乗誤差(MSE)
線形回帰など多くの教師あり学習は、 予測誤差の平均を最小化します:
$$ \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 $$
「予測 ŷ と真値 y のズレを2乗して平均」。 「平均」を最小化するから、 結果は「予測誤差ゼロの中心」 = 条件付き平均 E[Y|X] になります。
② バイアス-バリアンス分解
機械学習モデルの誤差は3つに分解できます:
$$ \text{誤差} = \text{バイアス}^2 + \text{バリアンス} + \text{ノイズ} $$
- バイアス:予測の平均と真の関数のズレ(モデルが単純すぎる→大)
- バリアンス:データセット間での予測のばらつき(モデルが複雑すぎる→大)
両方とも平均が基本になっています。
③ Batch Normalization
深層学習で各層の出力を平均0・分散1に標準化する手法。 ミニバッチ内の平均と分散を計算して使う。 訓練の安定性と速度が劇的に改善する画期的技術(Ioffe & Szegedy, 2015)。
④ アンサンブル学習
複数の予測モデル(決定木、 ニューラルネット)の予測結果を平均することで精度を上げる手法(バギング、 ランダムフォレスト、 アベレージング)。 「3人寄れば文殊の知恵」を平均で実現。
⑤ 勾配降下法での Adam / RMSProp
これらの最適化アルゴリズムは、 過去の勾配の指数移動平均を使って学習率を適応的に調整。 「最近の勾配ほど重視」する平均化が学習を加速。
📜 平均の歴史 — 4000年の知恵
「平均」という考え方は驚くほど古くから存在しました。 統計学の歴史を簡単に俯瞰します。
古代(〜紀元前500年)
- 古代バビロニア:紀元前2000年頃、 算術平均の概念がすでに使われていた(天体観測の誤差を補正するため)
- ピタゴラス学派:紀元前500年頃、 算術平均・幾何平均・調和平均の3つを「音楽の調和」と結びつけた
近代(16〜19世紀)
- Tycho Brahe(1546-1601):天体観測で複数の測定値の平均を取って精度を上げた
- Gauss(1777-1855):「最小二乗法」を発明(1809年)。 平均が最尤推定量である正規分布を提案
- Quetelet(1796-1874):「平均人(l'homme moyen)」の概念を提唱、 社会統計学の祖
現代
- Tukey(1977):トリム平均、 中央値などのロバスト統計を体系化
- 機械学習:平均は損失関数、 バッチ正規化、 アンサンブルなど至るところに登場
💡 「平均」という素朴な概念が、 4000年かけて確率論・統計学・機械学習・物理学の中核に発展してきました。 一見単純なものほど、 深く理解する価値があります。
🎲 ベイズ的視点での平均
ベイズ統計学では、 平均は「事前分布と尤度を組み合わせた事後分布の期待値」として登場します。
事後平均(posterior mean)
$$ \mathbb{E}[\mu | x_1, \ldots, x_n] = \frac{\tau_0^2}{\tau_0^2 + \sigma^2/n} \bar{x} + \frac{\sigma^2/n}{\tau_0^2 + \sigma^2/n} \mu_0 $$
事後平均は「標本平均」と「事前平均 μ₀」の加重平均。 サンプルが多いほど標本平均が優勢、 サンプルが少ないほど事前情報が優勢。 これは正則化と本質的に同じ仕組み(Ridge 回帰の原型)。
Stein のパラドックス
独立した複数の平均を推定する時、 「すべての平均を全体平均に向けて引き寄せる」推定量(James-Stein 推定量)の方が、 個別の標本平均より必ず精度が高いという驚くべき結果(James & Stein, 1961)。 ベイズ的シュリンケージの原型。
🗺️ 概念マップ — 3つの視点で体系を理解する
平均 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 記述統計 › 中心傾向 › 平均
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「平均」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「平均」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(拡張)
「平均」周辺の重要用語:
🧮 SSDSE-B 実値計算 — 5 種類の「平均」を 47 都道府県で比較
SSDSE-B-2026 の現金給与総額に対し、 算術平均・幾何平均・調和平均・トリム平均・加重平均を計算し、 値の差を観察する。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import numpy as np import pandas as pd from scipy import stats df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) df.columns = [c.strip() for c in df.columns] x = df['現金給与総額'].astype(float).values w = df['総人口'].astype(float).values am = np.mean(x) gm = stats.gmean(x) hm = stats.hmean(x) tm = stats.trim_mean(x, proportiontocut=0.1) wm = np.average(x, weights=w) med = np.median(x) print(f'算術平均 : {am:8.2f}') print(f'幾何平均 : {gm:8.2f} (AM-GM 不等式: AM >= GM)') print(f'調和平均 : {hm:8.2f} (HM <= GM <= AM)') print(f'10%トリム平均: {tm:8.2f}') print(f'人口加重平均 : {wm:8.2f} (大都市寄り)') print(f'中央値 : {med:8.2f}') |
典型的な観察例: 47 都道府県の現金給与は AM ≈ HM ≈ GM ≈ 310 千円程度で、 ほぼ一致する(分布が対数正規からそれほど外れていない)。 一方、 人口加重平均は東京・神奈川・大阪のウェイトが効いて約 340 千円と上方シフト。 「47 都道府県の単純平均」と「日本国民 1 人当たり」が違うものを測っている点が重要。
平均値の標準誤差と 95%CI
1 2 3 4 5 6 7 8 9 10 11 | n = len(x) sd = np.std(x, ddof=1) se = sd / np.sqrt(n) t = stats.t.ppf(0.975, df=n-1) ci_lo, ci_hi = am - t*se, am + t*se print(f'AM = {am:.2f} SE = {se:.2f} 95%CI = [{ci_lo:.2f}, {ci_hi:.2f}]') # ブートストラップ CI(分布仮定不要) from scipy.stats import bootstrap res = bootstrap((x,), np.mean, n_resamples=10000, confidence_level=0.95) print(f'Bootstrap 95%CI = {res.confidence_interval}') |
移動平均で時系列の平滑化(参考)
1 2 3 4 5 6 | # 都道府県別データは時系列ではないが、 47県を「人口順」に並べて移動平均でデモ s = df.sort_values('総人口')['現金給与総額'].reset_index(drop=True) print('移動平均 (window=5) :') print(s.rolling(window=5).mean().round(1)) print('指数加重移動平均 :') print(s.ewm(span=5).mean().round(1)) |
⚠️ 平均の落とし穴 — 6 つの典型ミス
① 外れ値で平均が「実態と乖離」する
平均は全データを等しく扱うため、 外れ値 1 個で大きく動く。 「日本人の平均年収」では一握りの超高所得者が平均を引き上げ、 過半数の人より高い値が出る。 こうした「右に裾を引く分布」では中央値の方が「典型的な人」を表す。 報告時には平均と中央値の両方を併記、 さらにヒストグラムや箱ひげ図で分布形状を示すのが標準的なベストプラクティス。 「平均年収 600 万」の見出しに騙されないリテラシーが必須。
② 比率の平均は算術平均では計算できない
「投資 A: +10%, B: -10% を平均すると 0%」と思いがちだが、 実際には複利で (1.10 × 0.90) - 1 = -1% の損失。 比率や成長率の平均には幾何平均を使うのが正しい。 「年率 5% × 3% → 平均 4%」ではなく、 √(1.05 × 1.03) - 1 ≈ 4.0% と幾何平均で算出。 速度の平均(距離一定で往復)は調和平均、 と平均の種類は使い分ける必要がある。 算術平均を機械的に使うと数値が嘘になる。
③ シンプソンのパラドックス
「グループごとの平均」が「全体の平均」と矛盾する現象。 例:男女別の合格率は男女ともに学部 A > B でも、 全体で集計すると女性の合格率が高くなる、 など。 これは集計レベルが変わると重みが変わるため。 平均だけで「グループ間に差がある」と結論する前に、 重要な変数(学部・年齢・地域)で層別化したサブグループ平均も確認する。 因果推論の文脈では交絡変数の存在を疑う。
④ 平均と標準誤差を区別しない
「平均 ± SD」と「平均 ± SE」は別物。 SD はデータのばらつきを表し、 SE は平均推定量の精度(= SD/√n)を表す。 サンプルが大きくなると SE は小さくなるが SD は変わらない。 多くの論文で混同が見られるので、 必ず「mean ± SE (n=N)」もしくは「mean ± SD」と明記する。 グラフのエラーバーが何を意味するか(SD / SE / 95%CI)を凡例に書かないと読者に正確に伝わらない。
⑤ 加重平均の重みを間違える
「47 都道府県の単純平均」と「国民 1 人当たりの加重平均(人口加重)」は別の数値。 政策議論で「県民平均」を引いて議論すると、 人口の少ない県が過大評価される。 GDP の地域差なら GDP 加重、 個人レベルの分析なら個人加重と、 目的によって重みを正しく選ぶ。 sklearn の sample_weight、 statsmodels の weights、 numpy.average の weights を使い分ける。
⑥ 欠損値の扱いで平均が変わる
numpy.mean は NaN があると NaN を返す。 pandas Series.mean() は既定で NaN をスキップし「観測値だけの平均」を返す。 この違いが落とし穴で、 同じデータでもライブラリで結果が変わる。 さらに、 欠損が完全ランダムでない場合(MNAR/MAR)は NaN をスキップした平均が偏る。 多重代入(MICE)や Inverse Probability Weighting で対処するのが現代的なアプローチ。
🐍 Python 実装バリエーション — numpy / scipy / pandas / statsmodels
1. numpy — 算術平均と欠損対応
1 2 3 4 5 6 7 | import numpy as np x = np.array([1, 2, 3, np.nan, 5]) print('mean :', np.mean(x)) # NaN print('nanmean :', np.nanmean(x)) # 2.75 print('average :', np.average(x[~np.isnan(x)])) # 加重平均 print('weighted :', np.average([1,2,3], weights=[1,2,3])) # 2.333 |
2. scipy.stats の各種平均
1 2 3 4 5 6 7 | from scipy import stats x = np.array([100, 200, 300, 400, 500]) print('gmean :', stats.gmean(x)) # 幾何平均 print('hmean :', stats.hmean(x)) # 調和平均 print('pmean(p=2) :', stats.pmean(x, 2)) # 二次平均 / RMS print('trim_mean :', stats.trim_mean(x, 0.2)) # 両端20%トリム print('mode :', stats.mode(x, keepdims=True)) |
3. pandas — 移動平均・指数加重平均
1 2 3 4 5 6 7 | import pandas as pd s = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) print(s.mean()) # 5.5 print(s.rolling(window=3).mean()) # 単純移動平均 print(s.rolling(window=3).mean().dropna().tolist()) print(s.ewm(span=3).mean().tolist()) # 指数加重 print(s.expanding().mean().tolist()) # 累積平均 |
4. statsmodels — 重み付き記述統計と平均差検定
1 2 3 4 5 6 7 8 | from statsmodels.stats.weightstats import DescrStatsW, ttest_ind d = DescrStatsW(df['現金給与総額'], weights=df['総人口'], ddof=1) print(f'重み付き平均: {d.mean:.2f}, CI={d.tconfint_mean()}') # 2群平均差検定(不等分散 / Welch t) a = df.loc[df['地域コード']<=23, '現金給与総額'] b = df.loc[df['地域コード']> 23, '現金給与総額'] t, p, _ = ttest_ind(a, b, usevar='unequal') print(f'東日本 vs 西日本: t={t:.2f}, p={p:.4f}') |
5. ブートストラップで平均の信頼区間
1 2 3 4 | from scipy.stats import bootstrap res = bootstrap((df['現金給与総額'].values,), np.mean, method='BCa', n_resamples=10000) print('BCa 95%CI =', res.confidence_interval) |
6. ロバスト中心傾向(M-estimator)
1 2 3 4 5 6 | import statsmodels.api as sm # Huber の M-estimator huber = sm.robust.scale.Huber() x = df['現金給与総額'].astype(float).values mu_huber, sigma_huber = huber(x) print(f'Huber 中心 = {mu_huber:.2f}, スケール = {sigma_huber:.2f}') |