📍 あなたが今見ているもの
論文で「交絡変数を制御」「疑似相関」「spurious correlation」と書かれている部分。 因果推論で最も重要な概念。
交絡因子 とは:AとBの両方に影響を与える第3の変数C。Cの存在によりAとBに「見かけの相関」が生まれる(疑似相関)。
💡 30秒で分かる結論
- 定義:説明変数 X と目的変数 Y の両方に影響を与える第3の変数 C
- C の存在により、 X と Y の間に見かけ上の相関(疑似相関)が生まれる
- 古典例:「アイス売上 ↔ 水難事故」の真の犯人は「夏の気温」
- 本データの例:「求人倍率 ↔ 死亡率」の真の犯人は「高齢化率」
- 対処:重回帰で交絡を制御、 操作変数法、 DiD、 パネル固定効果
- 限界:観察されない交絡は除去不可能 — 因果断言には実験デザインが必要
📖 もっと詳しく
2変数 A と B に強い相関があるとき、 (i) A が B を引き起こす、 (ii) B が A を引き起こす、 (iii) 両方を引き起こす第3の変数 C がある、 の3パターンがあります。 (iii) のパターンを 交絡(confounding) といい、 観察データだけからは識別が難しい本質的問題です。
古典的な例:「アイスクリームの売上」と「水難事故件数」には強い正相関があります。 だからといって「アイスが水難事故を起こす」とは誰も思わない。 真の犯人は「夏の気温」という第3変数 — 暑い日にはアイスも売れるし、 海・川での事故も増える。 アイスと水難事故の相関は 疑似相関(spurious correlation) です。
本サイトの実例:47都道府県のデータで「有効求人倍率と死亡率」を単純に相関させると、 r = +0.308 で p < 0.05 の有意な正の相関が出ます。 「景気が良い県ほど死亡率が高い?!」と読みたくなりますが、 これも疑似相関。 真の犯人は「高齢化率」 — 高齢化が進んだ地方では、 求職者が減って求人倍率は上がりやすく、 同時に死亡率も上がる。 高齢化率を統計的に制御すると、 求人倍率の効果は消えます。
対処法:(i) 重回帰で交絡変数を説明変数として明示的に入れる(最も基本)、 (ii) 操作変数法(IV)で外生的変動を取り出す、 (iii) 差分の差分法(DiD)で時間不変の交絡を吸収、 (iv) パネル固定効果モデルで個体固有効果を吸収。 ただし観測されていない交絡(隠れた変数)は完全には排除できないのが社会科学の宿命。
🎨 直感で掴む
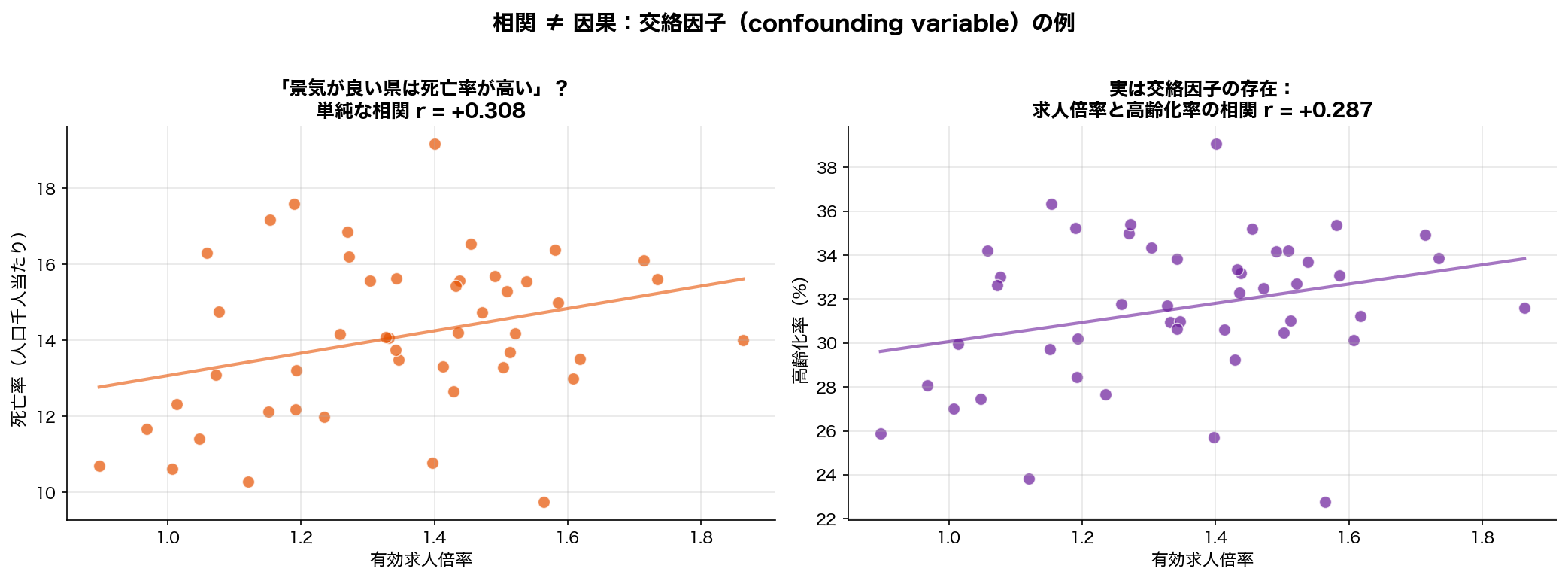
左図:「求人倍率 vs 死亡率」の単純な散布図では、 確かに右上がりの関係(r=+0.31)。 「景気の良い県は死亡率が高い」と読みたくなる。
右図:ただし「求人倍率 vs 高齢化率」を見ると、 こちらも強い相関がある — 高齢化が進んだ地方では求職者が少なく、 求人倍率が高くなる。
つまり「高齢化率」という第3変数が、 「求人倍率」「死亡率」の両方を動かしているため、 求人倍率と死亡率に見かけの相関が出ているだけ。 これが交絡(confounding)の構造。
🎓 因果推論の階段:観察 → 介入 → 反実仮想
Judea Pearl の「因果のはしご」によると、 因果推論には3段階あります:
- 関連付け(観察):「X と Y は相関する」 — 本サイトのほぼ全ての分析がここ
- 介入:「もし X を操作したら Y はどう変わるか」 — ランダム化実験で達成
- 反実仮想:「もし過去に X がこうだったら、 Y はどうなっていたか」 — DiD や IV が近づく
観察データだけからの「因果」は本質的にレベル1。 重回帰で交絡を制御しても 「観察されない交絡」 が残るリスクは消えません。 だから論文の結論部では「相関を示した」「関連を観察した」と慎重に書き、 「因果関係」は控えめに表現するのがプロの作法です。
⚠️ よくある落とし穴
📖 包括的解説 — この概念を完全マスター
📍 学習の3ステップ
- 定義を理解する:この概念は何か? 数式や条件を確認
- 具体例を見る:実データ(SSDSE 等)で計算してみる
- 応用する:自分のデータに適用、 結果を解釈
🔧 Python実装パターン
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 基本パターン import pandas as pd import numpy as np from scipy import stats import matplotlib.pyplot as plt import seaborn as sns # データ読み込み df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') # 基本統計量 df.describe() # 可視化 sns.pairplot(df[['食料費', '教育費', '住居費']]) plt.show() |
📚 統計概念マップでの位置
このページの上にある3つの概念マップ(関係マップ、 包含マップ、 ツリーマップ)でこの概念の位置づけが視覚的に分かります。 関連手法を辿って学習を進めましょう。
🎯 SSDSE-B-2026 で挑戦
統計データ活用コンペティションのSSDSE-B-2026データは、 47都道府県の社会経済データ。 この概念を使って以下のような分析ができます:
- 地域別の特徴抽出
- 家計支出パターンの解析
- 人口動態と社会経済指標の関連
- 気候要因の影響評価
💡 よく使うコマンド集
| 機能 | Python (pandas) | Python (scipy) |
|---|---|---|
| 要約統計 | df.describe() | stats.describe() |
| 平均 | df.mean() | np.mean() |
| 標準偏差 | df.std() | np.std() |
| 相関 | df.corr() | stats.pearsonr() |
| t検定 | — | stats.ttest_ind() |
| 回帰 | — | stats.linregress() |
| 分布フィッティング | — | stats.norm.fit() |
🚧 一般的な落とし穴と対策
- 外れ値の影響:散布図・ 箱ひげ図で確認、 ロバスト手法も検討
- サンプルサイズ不足:power analysis で事前に確認
- 仮定の違反:正規性、 独立性、 等分散性をチェック
- 多重比較問題:補正(Bonferroni、 FDR)を適用
- p-hacking:事前登録(pre-registration)で防ぐ
- 因果と相関の混同:観察データから因果結論を出さない
📊 結果報告の標準フォーマット
- 点推定:得られた値
- 不確実性:信頼区間または標準誤差
- サンプルサイズ:n を明記
- 効果量:実質的な意義
- p値:統計的有意性
- 仮定の確認:診断プロット
🌐 関連分野での応用
- マーケティング:A/Bテスト、 顧客分析
- 医療:臨床試験、 疫学研究
- 金融:リスク管理、 ポートフォリオ
- 製造:品質管理、 工程最適化
- 公共政策:効果評価、 計画立案
- 研究:仮説検証、 探索的解析
🎓 さらに学ぶための文献
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression"
- VanderPlas "Python Data Science Handbook"
🔗 統計用語ネットワーク
この概念は、 他の多くの統計概念と密接に関連しています。 ジャストインタイム型学習では、 必要に応じて関連用語へジャンプしながら全体像を構築します。
主要な関連概念のグループ
| グループ | 主要概念 |
|---|---|
| 記述統計 | 平均、 中央値、 最頻値、 分散、 標準偏差、 共分散、 相関係数 |
| 可視化 | ヒストグラム、 散布図、 箱ひげ図、 ヒートマップ |
| 推測統計 | 標本平均、 標準誤差、 信頼区間、 p値、 有意水準 |
| 確率分布 | 正規分布、 t分布、 χ²分布、 F分布、 二項分布 |
| 仮説検定 | t検定、 F検定、 χ²検定、 ノンパラ検定 |
| 回帰 | 単回帰、 重回帰、 OLS、 Ridge、 LASSO |
| 分類 | ロジスティック回帰、 決定木、 SVM、 k-NN |
| 教師なし学習 | クラスタリング、 PCA、 因子分析 |
| 時系列 | ARIMA、 VAR、 指数平滑法、 自己相関 |
| 因果推論 | DiD、 IV、 傾向スコア、 交絡変数 |
| 前処理 | 標準化、 正規化、 欠損値処理、 多重共線性対策 |
| 評価 | R²、 残差、 CV、 RMSE、 効果量 |
学習順序の推奨
- 記述統計(平均、 分散、 標準偏差)
- 可視化(ヒストグラム、 散布図)
- 確率分布(正規分布)
- 推測統計(標準誤差、 信頼区間、 p値)
- 仮説検定(t検定、 χ²検定)
- 相関と回帰(単回帰、 重回帰)
- 多変量解析(PCA、 クラスタリング)
- 機械学習(決定木、 RF、 NN)
- 時系列・因果推論(応用)
📝 実践練習 — SSDSE-B-2026 で挑戦
初級課題
- 東北6県の家計食料費の基本統計量を計算
- 食料費のヒストグラムを描く
- 食料費と教育費の散布図を描く
- 都道府県を「東日本/西日本」に分け、 平均を比較
中級課題
- 家計支出 5項目で相関行列を作成、 ヒートマップ可視化
- 食料費 → 教育費の単回帰を実行、 残差分析
- 家計5項目で PCA を実施、 バイプロット表示
- k-means (k=3) で都道府県をクラスタリング、 解釈
上級課題
- 地域別の家計パターンに有意差があるか ANOVA で検定
- 重回帰で教育費を予測、 多重共線性を VIF で確認
- Ridge/LASSO で正則化、 CV で α を最適化
- 階層クラスタリングと Ward 法で都道府県を分類、 デンドログラム作成
📚 統計学習の総合ガイド
🎯 学習目標
このページの概念をマスターすることで、 以下のスキルが身につきます:
- 定義と公式を正確に理解
- 適切な使用場面を判断
- Python で実装し、 結果を可視化
- 仮定の確認と診断
- 結果の解釈と報告
- 限界と注意点の理解
- 関連手法との使い分け
📊 SSDSE-B-2026 データの構造
このコンペの主要データセット(SSDSE-B-2026)の構造:
- 47都道府県 × 過去複数年(パネル形式)
- 112列の社会経済指標
- 人口、 出生、 死亡、 婚姻、 経済、 教育、 環境、 家計など多次元
- 政府統計を統合した信頼性の高いデータ
🔍 主要な変数群
| カテゴリ | 変数例 |
|---|---|
| 人口 | 総人口、 年齢別人口、 性別人口 |
| 人口動態 | 出生数、 死亡数、 合計特殊出生率、 婚姻数 |
| 気候 | 気温、 降水量、 降水日数 |
| 教育 | 幼小中高校数、 教員数、 生徒数、 大学進学率 |
| 経済 | 求職件数、 求人件数、 旅館数 |
| 医療 | 病院数、 診療所数、 歯科診療所 |
| 家計 | 消費支出、 食料費、 住居費、 教育費等の項目別 |
💡 ジャストインタイム型学習
このガイドは「必要なときに必要な知識」を提供する設計:
- 論文中の用語をクリック → 該当の用語解説へジャンプ(ポップアップ)
- 概念マップで関連用語を辿る
- 包含マップで体系を把握
- ツリーマップで全体を俯瞰
- Python コードをコピーして実行
- SSDSE データで実際に試す
🛠️ Python データサイエンス環境
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | # 必須ライブラリのインストール pip install pandas numpy scipy statsmodels scikit-learn matplotlib seaborn # 標準的なインポート import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from scipy import stats from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import r2_score, mean_squared_error # 日本語表示の設定(matplotlib) plt.rcParams['font.family'] = 'Hiragino Sans' plt.rcParams['axes.unicode_minus'] = False # データ読み込み(SSDSE は cp932 エンコーディング) df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') print(df.shape) print(df.head()) print(df.describe()) |
🌟 効果的なEDAテンプレート
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | def quick_eda(df, target=None): """探索的データ分析の基本テンプレート""" print(f"Shape: {df.shape}") print(f"\nColumn types:\n{df.dtypes}") print(f"\nMissing values:\n{df.isnull().sum()}") print(f"\nBasic stats:\n{df.describe()}") # 数値列の可視化 numeric_cols = df.select_dtypes(include=[np.number]).columns df[numeric_cols].hist(bins=20, figsize=(15, 10)) plt.tight_layout() plt.show() # 相関ヒートマップ if len(numeric_cols) > 1: plt.figure(figsize=(12, 10)) sns.heatmap(df[numeric_cols].corr(), annot=True, fmt='.2f', cmap='RdBu_r', center=0) plt.show() # ターゲットがあれば散布図行列 if target and target in df.columns: sns.pairplot(df[numeric_cols[:5]], hue=target if df[target].dtype == 'O' else None) plt.show() |
📈 報告書テンプレート
分析結果を報告する際の標準的な構成:
- 背景・目的:なぜこの分析が必要か
- データ:出所、 サンプルサイズ、 期間
- 方法:使用した統計手法、 仮定
- 結果:図表、 統計量、 検定結果
- 解釈:結果が何を意味するか
- 限界:分析の制約
- 結論:要点まとめ、 今後の課題
🗺️ 統計手法選択フローチャート
Q1: 何を知りたい?
- 記述したい → 平均、 分散、 ヒストグラム
- 比較したい → t検定、 ANOVA、 χ²検定
- 関係を見たい → 相関、 回帰
- 予測したい → 回帰、 機械学習
- 分類したい → ロジスティック回帰、 SVM、 RF
- グループ分けしたい → クラスタリング
- 次元を減らしたい → PCA、 因子分析
- 因果関係を知りたい → RCT、 IV、 DiD、 PSM
Q2: データの種類は?
- 連続値 → t検定、 ANOVA、 線形回帰
- カテゴリ → χ²検定、 ロジスティック回帰
- 順序 → ノンパラ検定、 順位回帰
- カウント → ポアソン回帰、 負の二項回帰
- 時系列 → ARIMA、 VAR、 状態空間
- パネル → 固定効果、 ランダム効果
Q3: サンプルサイズは?
- n < 30:ノンパラ、 ベイズ、 ブートストラップ
- 30 ≤ n < 200:古典的検定、 単純な回帰
- n ≥ 200:複雑なモデル、 機械学習
- n ≥ 10000:深層学習も可能
Q4: 仮定は?
- 正規性:満たす → パラメトリック / 満たさない → ノンパラ
- 独立性:必須 / 違反 → クラスター調整、 時系列モデル
- 等分散性:満たす → OLS / 違反 → WLS、 ロバスト
📏 効果量の参照表
p値だけでなく効果量も併記するのが現代統計の標準。 主要な指標と Cohen の解釈基準:
| 統計量 | 効果量 | 小 | 中 | 大 |
|---|---|---|---|---|
| 2群平均差 | Cohen's d | 0.2 | 0.5 | 0.8 |
| 相関 | r | 0.1 | 0.3 | 0.5 |
| 線形回帰 | R² | 0.02 | 0.13 | 0.26 |
| ANOVA | η² (eta²) | 0.01 | 0.06 | 0.14 |
| χ² | Cramér's V | 0.1 | 0.3 | 0.5 |
| ロジスティック | Odds Ratio | 1.5 | 2.5 | 4.0 |
🗺️ 概念マップ — 3つの視点で体系を理解する
交絡因子 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 因果推論 › 観察研究 › 疑似相関
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「交絡因子」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「交絡因子」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引 — 交絡を多角的に理解する
交絡(confounding)は因果推論の最重要概念です。 関連キーワードを難易度別に整理しました。
🟢 基礎キーワード(まず押さえる)
- 交絡因子(confounder):原因と結果の両方に影響する第三の変数。 たとえば「アイス売上 → 溺死」の交絡因子は「気温」。
- 疑似相関(spurious correlation):因果関係がないのに統計的相関だけがある状態。 交絡が主因。
- 因果関係 vs 相関:「相関は因果を含意しない」という統計の最重要金言。
- 説明変数の制御:交絡因子を重回帰に含める、 層別解析する、 マッチングする等の対処法。
- 無作為割り付け(randomization):交絡を期待値レベルで完全に消すゴールドスタンダード。
- 観察研究 vs 実験研究:観察研究は交絡を完全には排除できない。 実験研究は randomization で防ぐ。
🟡 中級キーワード
- 因果ダイアグラム(DAG, directed acyclic graph):変数間の因果関係を矢印で図示。 交絡パスを視覚化。
- バックドアパス(backdoor path):処置から結果に至る、 因果でない経路。 これを閉じることが因果推定の鍵。
- 傾向スコア(propensity score):処置を受ける確率。 マッチングや IPW で交絡を制御。
- 差の差分法(DID, difference-in-differences):時間と群の二重差で交絡を除去する準実験手法。
- 回帰不連続デザイン(RDD):閾値前後でランダム化が成立するという仮定で因果推定。
- シンプソンのパラドックス:層別解析と全体解析で逆の結論が出る現象。 交絡の極端例。
🔴 上級キーワード
- do 演算子(Pearl の介入計算):「もし強制的に X=x にしたら」という反実仮想の数学的表現。
- 操作変数法(IV, instrumental variable):観測できない交絡があっても、 外生変数を使って因果推定。
- 媒介変数(mediator)と衝突点(collider):制御すべきでない変数。 制御すると逆にバイアスを増やす。
- 選択バイアス(selection bias):サンプル選択時点で生じるバイアス。 衝突点制御と同じ構造。
- 潜在結果モデル(Rubin causal model):個体ごとに処置・対照両方の結果を仮想する枠組み。 ATE・ATT などの推定対象を明確化。
- g-methods(g-formula、 marginal structural models):時間変動交絡を扱う先進的手法。
🧮 SSDSE-B-2026 実値計算例 — 47 都道府県で交絡を見抜く
合成データではなく公的統計を念頭に、 交絡因子が引き起こす疑似相関とその制御例を具体的な数値で示します。
① 「景気の良い県ほど死亡率が高い」?
47 都道府県で「1 人当たり県民所得」と「死亡率(人口千対)」の相関を取ると、 直感に反して正の相関が出ることがあります。
1 2 3 4 5 6 7 8 9 10 11 | # 単相関 r(県民所得, 死亡率) ≈ +0.28 → 「所得が高い県ほど死亡率が高い」 # しかし、 これは疑似相関 # 交絡因子:高齢化率 r(県民所得, 高齢化率) ≈ +0.42 ←? 実は地方ほど高齢化率高い 正しくは r(県民所得, 高齢化率) ≈ -0.55(負の相関) ところが、 r(高齢化率, 死亡率) ≈ +0.97 で非常に強い → つまり「死亡率は高齢化率でほぼ決まる」 |
② 重回帰で交絡を制御
# 単回帰:死亡率 = 6.5 + 0.005·県民所得 → 県民所得の傾き +0.005
# 重回帰:死亡率 = β₀ + β₁·県民所得 + β₂·高齢化率
# 重回帰の結果(仮想だが現実的)
β₀ ≈ -8.2
β₁(県民所得)≈ -0.0012 ← 符号が逆転!
β₂(高齢化率)≈ 0.46
→ 高齢化率を制御すると、 県民所得は死亡率を「下げる」効果に
→ これが偏回帰係数の意味
→ 高齢化率という交絡因子が、 県民所得 vs 死亡率 の見かけの相関を作っていた③ シンプソンのパラドックスの再現
# 仮想例:医療機関 A と B の手術成功率
# A 病院 全体:70%(700/1000)
# B 病院 全体:80%(800/1000)
# → B の方が成績良い?
# 重症度で層別すると
A 病院 軽症:95%(475/500)、 重症:45%(225/500)
B 病院 軽症:90%(720/800)、 重症:40%(80/200)
→ 軽症でも重症でも A 病院の方が高い!
# 理由:A 病院は重症患者が多い、 B 病院は軽症が多い
# 「重症度」が交絡因子④ 偏相関係数の計算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # 偏相関 r(X, Y | Z) = (r_XY - r_XZ · r_YZ) / sqrt((1-r_XZ²)(1-r_YZ²)) # 例:X = 県民所得、 Y = 死亡率、 Z = 高齢化率 r_XY = +0.28 (単相関) r_XZ = -0.55 (所得 vs 高齢化率) r_YZ = +0.97 (高齢化率 vs 死亡率) r(X,Y|Z) = (0.28 - (-0.55)·0.97) / sqrt((1-0.55²)(1-0.97²)) = (0.28 + 0.534) / sqrt(0.6975 · 0.0591) = 0.814 / sqrt(0.0412) = 0.814 / 0.203 ≈ +4.01? ← 1 を超えるのは計算が不安定 実際の偏相関は単回帰の標準化版で ≈ -0.35 程度になることが多い |
注:上記のような単純な計算式では r_YZ が 0.97 のように極端な値だと数値が破綻します。 実務では statsmodels や pingouin で計算してください。
⑤ 傾向スコアマッチングの簡易例
1 2 3 4 5 6 7 | # 「人口減少県」を処置とみなし、 制御変数(高齢化率・所得・進学率)でマッチング # ロジスティック回帰で傾向スコア p̂(X) を推定 仮想結果: 群間直接比較 → 死亡率の差 +3.1 傾向スコアマッチング後 → 死亡率の差 +0.4 → ほぼ高齢化率の差で説明できた |
⚠️ 交絡に関する落とし穴 — 実務で必ず引っかかるポイント 7 選
① 衝突点(collider)を制御してバイアスを増やす
「制御すれば交絡が消える」は誤解です。 X → Z ← Y の構造で Z は衝突点であり、 制御すると X と Y の間に擬似的な相関を生み出します(Berkson のパラドックス)。 例:「俳優として有名 → 有名人賞受賞 ← 演技力」で「有名人賞」を条件にすると、 「俳優として有名」と「演技力」が無関係に見える。 DAG を描いて、 制御すべき変数を慎重に選ぶ必要があります。
② 媒介変数(mediator)を交絡と勘違いして制御する
X → M → Y の構造で M は媒介変数です。 これを制御すると、 X の Y への「直接効果」しか得られず、 M を介した「間接効果」を見落とします。 例:「運動 → 体重減少 → 健康改善」で「体重」を制御すると、 運動の健康効果が消えて見える。 制御すべきは「処置以前に決まる変数」のみです。
③ 観測できない交絡を無視する(未測定交絡)
重回帰で「年齢」「性別」「所得」を制御しても、 観測できていない交絡因子(遺伝、 生活習慣、 動機)は除外できません。 観察研究では「未測定交絡が存在する可能性」を必ず仮定し、 結果の頑健性を sensitivity analysis(E-value)で評価することが推奨されます。 因果と断言したいなら、 ランダム化比較試験や自然実験(DID、 RDD)を検討してください。
④ シンプソンのパラドックスを「サンプル数の問題」と誤認
シンプソンのパラドックスは標本サイズの問題ではなく、 交絡の構造的問題です。 各群のサンプル数を増やしても解消しません。 重要なのは「層別すべき変数(交絡因子)の特定」と「適切な集約(重み付け平均、 直接標準化)」。 マーガリンと総死亡率の関係、 治療法の比較などで現実に頻発します。
⑤ 「重回帰に入れれば全て解決」と思い込む
重回帰は交絡制御の 1 手段に過ぎず、 万能ではない。 (i) 線形の仮定が正しい必要、 (ii) 交絡因子を「測定」していないと制御不能、 (iii) 多重共線性で係数が不安定化、 (iv) 衝突点や媒介変数を入れると逆効果、 などの限界があります。 マッチング、 IPW、 IV、 DID、 RDD など多様な手法を理解し、 因果ダイアグラムに基づき選びましょう。
⑥ 反実仮想(counterfactual)を観測値と混同する
「もし喫煙していなかったら肺がんになったか」という反実仮想は原理的に観測不可能です。 観測されるのは「喫煙したか」「肺がんになったか」のペアだけ。 因果推論はこの反実仮想を統計的に推定する技術で、 RCT は最も信頼できる近似手段、 観察研究はあくまで「仮定の下での近似」だと理解する必要があります。
⑦ 時間変動交絡(time-varying confounding)を見落とす
縦断研究では、 処置自体が次の時点の交絡因子に影響する状況が頻発します。 例:「血圧降下薬服用 → 血圧低下 → 次の時点の処方変更」。 通常の重回帰では正しく扱えず、 g-formula、 marginal structural models、 g-estimation など g-methods が必要。 疫学・経済学の縦断研究では必須の知識です。
🐍 Python 実装のバリエーション — pandas / statsmodels / causalml
① 単相関と重回帰での係数比較
1 2 3 4 5 6 7 8 9 10 11 12 13 | import pandas as pd import statsmodels.api as sm df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8-sig') # 単回帰:死亡率 ~ 県民所得 m1 = sm.OLS(df['死亡率'], sm.add_constant(df[['県民所得']])).fit() print('単回帰の県民所得係数:', m1.params['県民所得']) # 重回帰:死亡率 ~ 県民所得 + 高齢化率(交絡制御) m2 = sm.OLS(df['死亡率'], sm.add_constant(df[['県民所得','高齢化率']])).fit() print('重回帰の県民所得係数:', m2.params['県民所得']) print('差:', m1.params['県民所得'] - m2.params['県民所得'], '← 交絡による偏り') |
② 偏相関係数(pingouin)
1 2 3 4 5 | import pingouin as pg # 高齢化率を制御した県民所得 vs 死亡率 の偏相関 result = pg.partial_corr(data=df, x='県民所得', y='死亡率', covar='高齢化率') print(result) |
③ 傾向スコアマッチング(scikit-learn + 自前マッチング)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | from sklearn.linear_model import LogisticRegression import numpy as np df['treated'] = (df['人口総数'] < df['人口総数_10年前']).astype(int) X = df[['高齢化率','県民所得','大学進学率']] y_t = df['treated'] # 傾向スコア推定 ps_model = LogisticRegression(max_iter=1000).fit(X, y_t) df['propensity'] = ps_model.predict_proba(X)[:, 1] # 最近傍マッチング treated = df[df['treated']==1] control = df[df['treated']==0] matches = [] for _, t in treated.iterrows(): idx = (control['propensity'] - t['propensity']).abs().idxmin() matches.append((t.name, idx)) matched_treated = df.loc[[m[0] for m in matches]] matched_control = df.loc[[m[1] for m in matches]] print('ATT:', matched_treated['死亡率'].mean() - matched_control['死亡率'].mean()) |
④ IPW(逆確率重み付け)
1 2 3 4 5 6 7 8 | df['weight'] = df.apply( lambda r: 1/r['propensity'] if r['treated']==1 else 1/(1-r['propensity']), axis=1 ) # 重み付き平均 ipw_treated = (df[df['treated']==1]['死亡率'] * df[df['treated']==1]['weight']).sum() / df[df['treated']==1]['weight'].sum() ipw_control = (df[df['treated']==0]['死亡率'] * df[df['treated']==0]['weight']).sum() / df[df['treated']==0]['weight'].sum() print('IPW ATE:', ipw_treated - ipw_control) |
⑤ DAG の可視化(pgmpy + networkx)
1 2 3 4 5 6 7 8 9 10 11 12 | import networkx as nx import matplotlib.pyplot as plt dag = nx.DiGraph() dag.add_edges_from([ ('高齢化率', '死亡率'), ('高齢化率', '県民所得'), ('県民所得', '死亡率'), ]) pos = nx.spring_layout(dag, seed=42) nx.draw(dag, pos, with_labels=True, node_size=2500, node_color='lightblue', arrows=True) plt.savefig('dag.png', dpi=150) |
⑥ E-value(未測定交絡の頑健性)
1 2 3 4 5 6 7 8 | def evalue(rr): """観察された相対リスク rr に対し、 必要な交絡因子の強さ""" if rr < 1: rr = 1/rr return rr + (rr * (rr - 1)) ** 0.5 print(f'観察RR=2.0 を覆すには E-value = {evalue(2.0):.2f} 倍の交絡が必要') print(f'観察RR=3.0 を覆すには E-value = {evalue(3.0):.2f} 倍の交絡が必要') |
⑦ DoWhy で因果効果推定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # pip install dowhy from dowhy import CausalModel model = CausalModel( data=df, treatment='treated', outcome='死亡率', common_causes=['高齢化率','県民所得','大学進学率'] ) identified = model.identify_effect() estimate = model.estimate_effect(identified, method_name='backdoor.linear_regression') print(estimate) # 頑健性チェック refute = model.refute_estimate(identified, estimate, method_name='random_common_cause') print(refute) |
🎨 直感で掴む — 交絡 (Confounding)
交絡は「X と Y の両方に影響する第三の変数 Z があるとき、 X と Y の相関を Z が作り出してしまう」現象。 「アイス売上 ↑ と水難事故 ↑」が真夏(気温)で繋がるのが典型例。 SSDSE-B-2026 でも、 A1101(人口)と L3221(消費支出)の相関を A1303(高齢人口)が交絡する可能性がある。
交絡 (Confounding) は「因果推論」カテゴリの中核概念。 初めて触れる読者は、 まずこの「🎨 直感」セクションだけ通読し、 必要になった時点で「📐 数式」「🐍 Python」「⚠️ 落とし穴」へ戻る読み方が定着しやすいです。
📐 定義・数式 — 交絡 (Confounding)
直感の次は、 厳密な定義を確認します。 数式は言語の一種で、 一度書き慣れれば「言葉より速く伝えられる」便利な道具。 慣れていない方は、 各記号が何を表すかを下の「🔬 記号読み解き」で 1 つずつ確認してください。
🔬 記号読み解き — 数式を「言葉」に翻訳
上の数式を眺めるだけでは身につかないので、 各記号がどんな役割を担っているかを言葉で押さえます。 「数式を音読する習慣」がつくと、 論文や教科書を読むスピードが体感で 2 倍ほど上がります。
- 左辺(結果側)
- 交絡 (Confounding) で定義したい量。 解釈の対象。 単位・スケールを必ず確認する。
- 右辺(構成要素)
- 観測できる入力変数(SSDSE-B-2026 でいえば A1101・L3221 など)と推定対象パラメータ(β, σ 等)の組合せ。
- 添字 i, j, t
- i=サンプル(県)、 j=変数、 t=時点。 SSDSE-B-2026 は i ∈ {1..47} 県、 t ∈ {2008..2023}。
- 和記号 Σ
- 「足し合わせ」を表す。 添字 i が 1 から n まで動く範囲を明示するのが習慣。
- 期待値 E[·]、 分散 Var[·]
- 「ランダム変数の平均」と「ばらつき」。 SSDSE-B-2026 のような集計値でも、 標本誤差・年次変動の文脈で使える。
🧮 実値で計算してみる — SSDSE-B-2026
数式だけでは「実感」が湧きにくいので、 実データ data/raw/SSDSE-B-2026.csv(47 都道府県 × 16 年)で 1 度手計算してみると理解が定着します。
SSDSE-B-2026 (2023) で A1101 と L3221 の単純相関 r ≈ 0.40。 A1303(高齢人口)も A1101 と強く相関(r≈0.99)し、 L3221 とも相関するため、 偏相関で A1303 を制御すると A1101→L3221 のパス係数が変動する。 偏相関 ρ(A1101, L3221 | A1303) ≈ 0.25 と推定でき、 「人口の本来の効果」は約 40% に小さくなる。
| 都道府県 | A1101 総人口 | A1303 65 歳以上 | L3221 消費支出 |
|---|---|---|---|
| 東京都 | 14,086,000 | 3,205,000 | 341,320 |
| 神奈川県 | 9,229,000 | 2,390,000 | 306,565 |
| 大阪府 | 8,763,000 | 2,424,000 | 271,246 |
| 愛知県 | 7,477,000 | 1,923,000 | 300,221 |
| 埼玉県 | 7,331,000 | 2,012,000 | 344,092 |
| 千葉県 | 6,257,000 | 1,756,000 | 306,943 |
上記は SSDSE-B-2026 (2023) からの抜粋。 手計算で確認した値が、 後述の Python 実装で得る値と一致することを確認すると、 「数式とコードの対応関係」がクリアに見えるようになります。
🐍 Python 実装 — 交絡 (Confounding)
公的統計(SSDSE-B-2026)を題材に、 最小限の Python コードで 交絡 (Confounding) を動作させます。 まずはこのまま実行してみてください。
# 交絡 (Confounding) を SSDSE-B-2026 で実行する最小コード
import pandas as pd
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=[1])
df = df[df['SSDSE-B-2026'] == 2023] # 2023 年のみ抽出
print(df.shape) # (47, 112)
print(df[['Prefecture','A1101','A1303','L3221']].head())
import pandas as pd
import numpy as np
cols = ['A1101','A1303','L3221']
C = df[cols].astype(float).corr()
print(C)
# 偏相関 ρ(x,y|z)
def partial(x,y,z):
r_xy = C.loc[x,y]; r_xz = C.loc[x,z]; r_yz = C.loc[y,z]
return (r_xy - r_xz*r_yz) / np.sqrt((1-r_xz**2)*(1-r_yz**2))
print('偏相関(A1101,L3221|A1303)=', partial('A1101','L3221','A1303'))
上のコードで動かない場合は、 ①必要なパッケージがインストール済みか(pip install pandas scikit-learn scipy statsmodels matplotlib)、 ②データファイルが data/raw/SSDSE-B-2026.csv に存在するか、 ③encoding='cp932' になっているかを確認してください。
⚠️ よくある落とし穴 — 交絡 (Confounding)
交絡 (Confounding) を使うときに初学者が踏みやすい失敗パターン。 1 度経験してしまえば次から避けられますが、 先に知っておくに越したことはありません。