📍 あなたが今見ているもの
論文の表や本文で、こんな数字を見たはずです:
保健医療費: r = −0.537, p < 0.001 ***
この r が 相関係数(Pearson の積率相関係数)。−1 から +1 の値 を取り、「2つの量がどれだけ一緒に動くか」 を 1 つの数字に集約します。ここではまず「何を見ている数字か」を 30 秒で押さえます。
💡 30秒で分かる結論
- 範囲:
−1 ≤ r ≤ +1 - 符号=関係の 向き。
+なら同方向(一方が増えると他方も増える)、−なら逆方向 - 絶対値=関係の 強さ。
|r|≈1なら強い、|r|≈0ならほぼ無関係 - 目安:|r| ≥ 0.7 「強い」 / 0.4–0.7 「中程度」 / 0.2–0.4 「弱い」 / < 0.2 「ほぼ無関係」
- p 値 とセットで読む(後述)。
p < 0.05なら「偶然の可能性は低い」 - 致命的注意:r が大きい ≠ 因果関係。あくまで「一緒に動いている」だけ
🎨 直感で掴む — r の値ごとに散布図はこう変わる
具体的に「r の数字が違うと、散布図はどう違って見えるのか」を、実データの SSDSE-B(47都道府県・2023年)で確かめてみましょう。
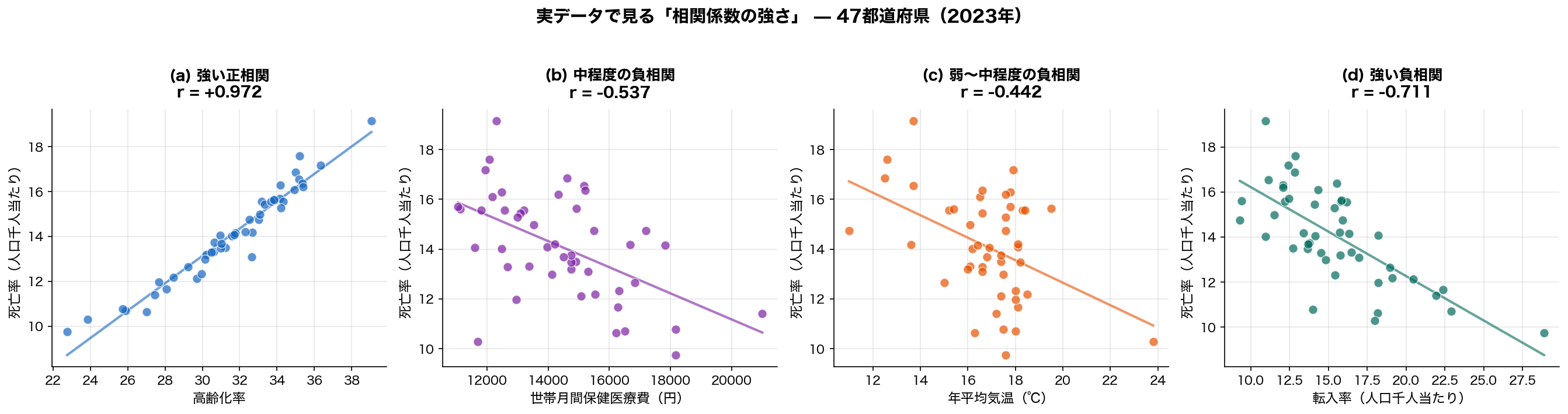
(a) r=+0.97 では点がほぼ直線に並ぶ。(d) r=−0.71 でも逆方向にきれいに並ぶ。
(b)(c) のように r が中程度になると、ばらつきが大きくなる。
ポイントは 「r=0.97 と r=0.5 は同じ「正の相関」でも別物」 ということ。 r が高いほど、x の値だけで y の値をかなり予測できますが、r=0.3 程度では「言うほど予測できない」状態です。
もう少し詳しく:高齢化率 vs 死亡率(r = +0.972)
この強い相関は、47都道府県 1点ずつ見ても、ほぼ「右上がりの直線」に並びます。
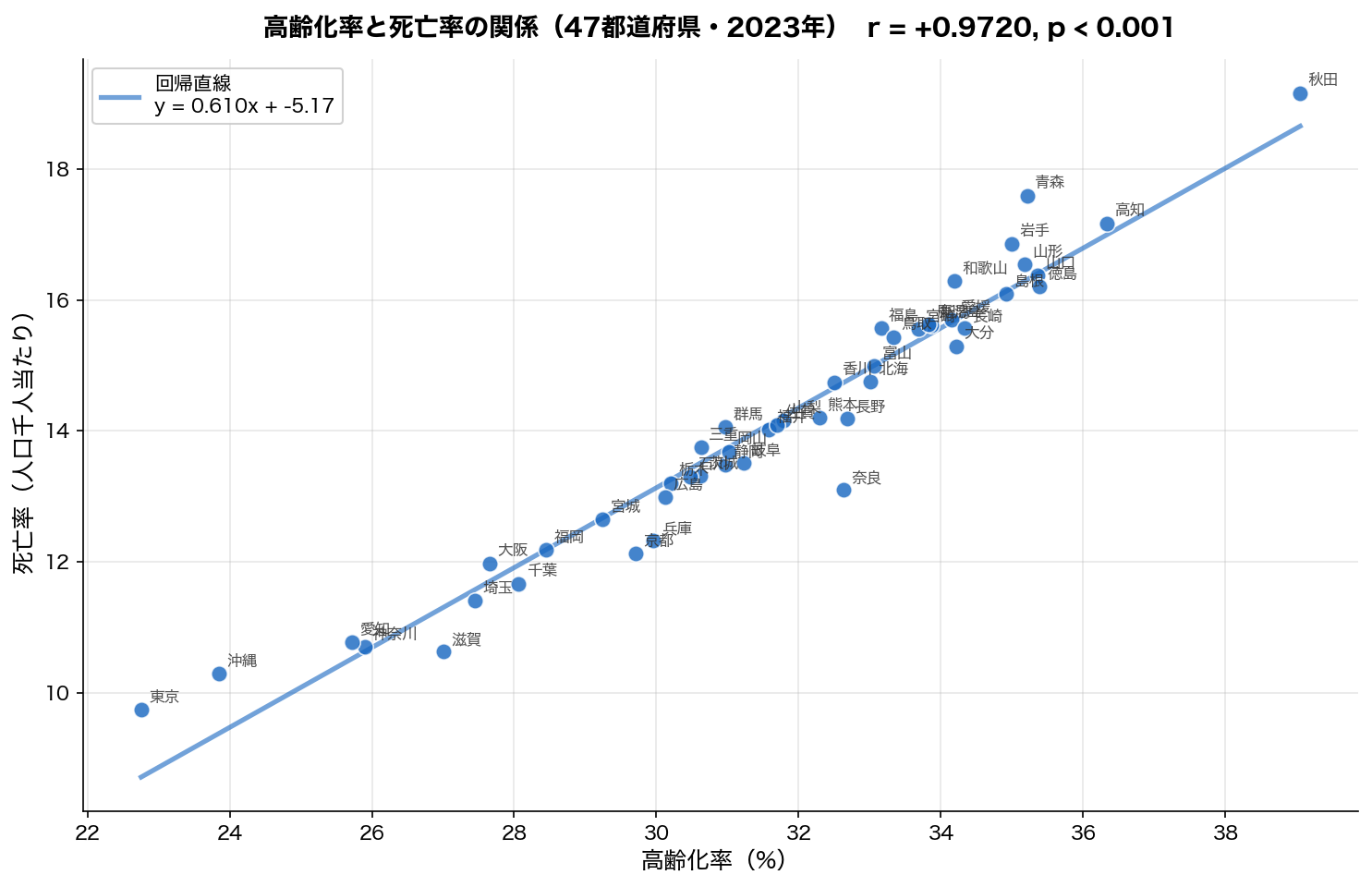
右上の 秋田・島根・高知 など高齢化が進んだ県は死亡率も高く、
左下の 沖縄・東京・神奈川 など若年層が多い県は死亡率も低い。
📐 数式 — Pearson の積率相関係数
2変数 $x$ と $y$ の n 個の観測ペア $(x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)$ に対して:
同じものを 共分散・標準偏差 で書くと、もっと意味が見えます:
つまり 「共分散を、x と y のスケールで規格化したもの」= r。
🔬 数式を「言葉」で読み解く
数式を眺めるだけだとピンと来ないので、各部品が どんな仕事をしているか を分解しましょう。
- $(x_i - \bar{x})$
- i 番目のデータ点が 平均からどれだけズレているか(横方向のズレ)。 正なら平均より大、負なら平均より小。
- $(y_i - \bar{y})$
- 同じく y 方向のズレ。
- $(x_i - \bar{x})(y_i - \bar{y})$
- 2 つのズレの 掛け算。 同方向のズレ(右上 or 左下)なら積は 正、 逆方向(右下 or 左上)なら 負。
- $\sum_i (\ldots)$
- 全データ点での総和。正の積が多ければ全体は正、負が多ければ全体は負になる。
- 分母 $\sqrt{\sum(x_i-\bar{x})^2}\sqrt{\sum(y_i-\bar{y})^2}$
- x, y それぞれの ばらつき(広がり) の積。 これで分子を 規格化することで、 単位や桁の違いを打ち消し、必ず $-1 \le r \le 1$ に収まるようにする。
視覚的に確認してみましょう。各都道府県の点を、平均線(点線)で分けた 4象限 で色分けしました:
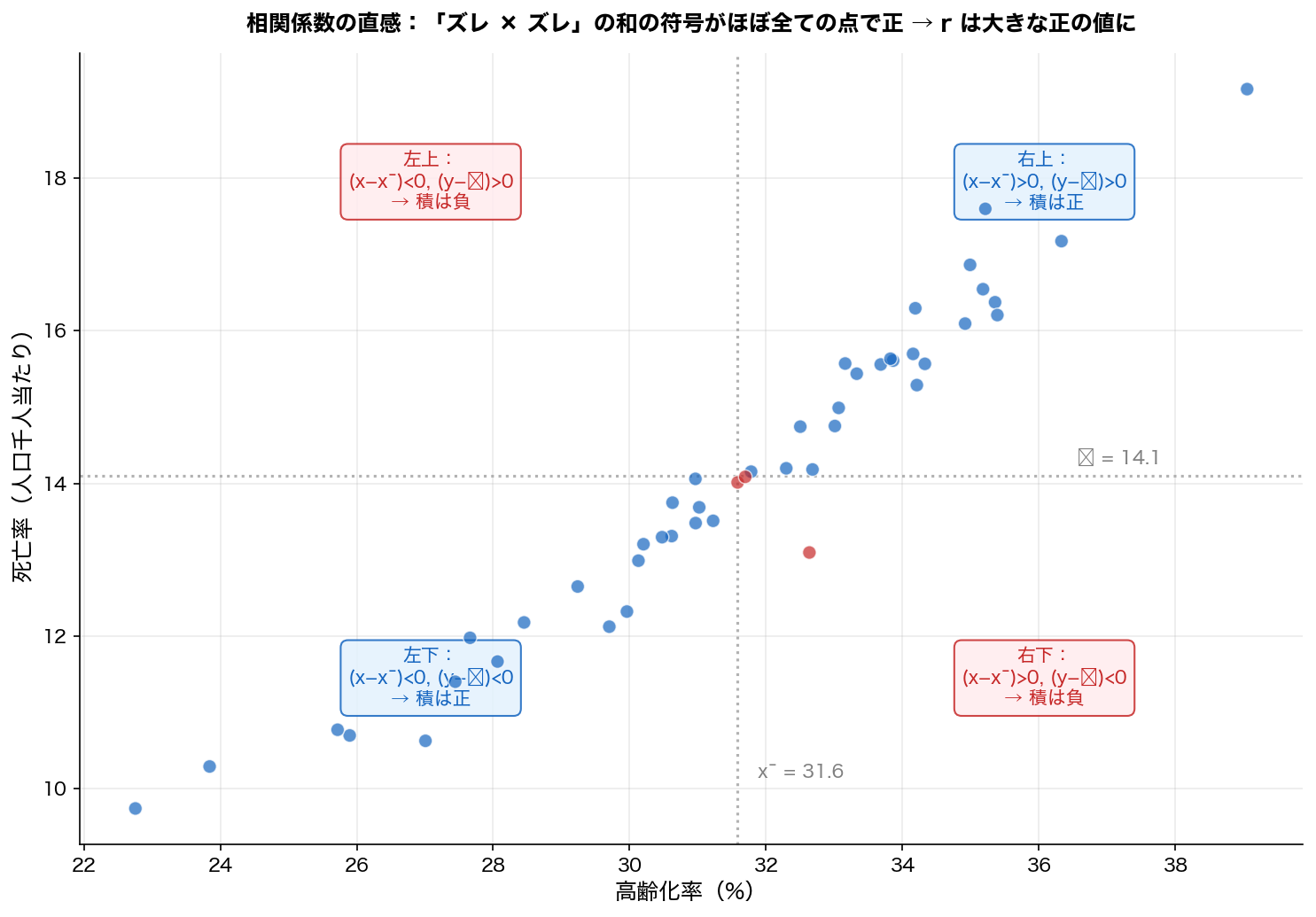
強い正の相関の場合、青い点ばかりが大量に集まり、和が大きな正の値になる。
🧮 実データで計算してみる
「公式を見ただけでは分かった気がしない」のは普通です。5都道府県のミニデータで手計算してみましょう(高齢化率 % と死亡率 ‰)。
| 都道府県 | $x_i$(高齢化率) | $y_i$(死亡率) | $x_i-\bar{x}$ | $y_i-\bar{y}$ | 積 |
|---|---|---|---|---|---|
| 秋田 | 39.1 | 19.2 | +5.9 | +4.7 | +27.7 |
| 高知 | 36.5 | 17.4 | +3.3 | +2.9 | +9.6 |
| 大阪 | 27.9 | 13.4 | −5.3 | −1.1 | +5.8 |
| 神奈川 | 25.7 | 11.6 | −7.5 | −2.9 | +21.8 |
| 沖縄 | 22.8 | 10.9 | −10.4 | −3.6 | +37.4 |
| 平均→ | $\bar{x}=33.2$ | $\bar{y}=14.5$ | 積の合計→ | +102.3 | |
$\sqrt{\sum(y_i-\bar{y})^2} = \sqrt{4.7^2 + 2.9^2 + 1.1^2 + 2.9^2 + 3.6^2} = \sqrt{52.3} \approx 7.2$
解釈: 「高齢化率が高い県ほど、死亡率も高い」傾向が、たった 5 県のサンプルからもクッキリ読み取れる。47県全部だと r=+0.972 とさらに強くなる。
Python なら 1 行
from scipy import stats
r, p = stats.pearsonr(df['高齢化率'], df['死亡率'])
# r=0.972, p<0.001(pは「この r が偶然出る確率」)
🎓 共分散との関係 — なぜ規格化するのか
もし分母(規格化)がなければ、それは 共分散 という量です:
共分散にも「正の相関なら正、負の相関なら負」という符号情報はあります。 ですが、共分散には致命的な欠点があります:
- 単位に依存する:x が cm か m か kg かで桁が変わる
- 大小の比較ができない:「身長×体重の共分散 = 10」と「身長×足のサイズの共分散 = 100」のどちらが強い関係か、共分散の数字だけでは分からない
これを解決するため、各変数の標準偏差で割って規格化したのが相関係数。 これで 必ず −1 ≤ r ≤ +1 に収まり、違う組み合わせ同士でも強さを比較できるのです。
- 共分散
- 関係の向きは分かるが、強さは単位依存で比較できない
- 相関係数
- 規格化したおかげで、−1 〜 +1 の同じ物差しで違う変数ペアを比較できる
🔍 Pearson と Spearman — どっちを使う?
「相関係数」と一言で言うとき、たいてい Pearson の積率相関係数(ここまで説明したもの)を指します。 ただし、もう 1 つメジャーなのが Spearman の順位相関係数です。
| 項目 | Pearson(積率相関) | Spearman(順位相関) |
|---|---|---|
| 測るもの | 直線関係の強さ | 単調関係の強さ(増えれば増える、減れば減る) |
| 計算方法 | 値そのものから計算 | 値を 順位(rank) に変換してから Pearson と同じ計算 |
| 外れ値の影響 | 強く受ける(1点で r が大きく動く) | 受けにくい(順位だから極端値が緩和される) |
| 非直線でも検出? | 苦手(直線でないと小さくなる) | 得意(単調なら直線でなくても高い値が出る) |
| 適する状況 | 正規分布に近い数値データ/直線関係を想定 | 順位データ/外れ値あり/非直線の単調関係を疑う場合 |
使い分けのコツ:両方計算してみて、 r_Pearson ≈ r_Spearman なら直線関係。 r_Spearman > r_Pearson なら「単調だけど曲線」または「外れ値の影響」を疑うサイン。
⚠️ 「相関 ≠ 因果」 — 疑似相関の正体をデータで暴く
相関係数を使う上で最も重要な戒め。 「2変数に強い相関がある」と分かっても、 そこから「A が B を引き起こしている」と結論するのは論理的飛躍です。 この節では、 実際のデータで「疑似相関がどう発生するか」「どう見抜くか」を体験します。
🎭 古典的な疑似相関の例
例1:「アイスクリームの売上」と「水難事故件数」
米国データで両者の相関は r ≈ +0.8 と強い正相関。 「アイスを食べると溺れやすい?」もちろん違う。 真犯人は 「夏の気温」。 暑い日には:
- (i) アイスがよく売れる ', '
- (ii) 海や川で泳ぐ人が増える → 水難事故も増える
気温という第3変数が両方の原因なので、 アイスと水難事故は見かけ上だけ連動する。 これが 疑似相関(spurious correlation) の典型例。
例2:「コウノトリの数」と「出生率」
ドイツ地方都市データで r ≈ +0.6。 民話「赤ちゃんはコウノトリが運ぶ」を裏付ける?もちろん違う。 真犯人は「農村度」。 農村部ほど(i) コウノトリの巣作り場所が多く、 (ii) 出生率も高い(家族規模が大きい)。
📊 SSDSE 都道府県データでの実例:「景気の良い県ほど死亡率が高い」?
本データセット(47都道府県・2023年)で、 「有効求人倍率」と「死亡率」の相関を計算してみると:
この数字だけ見れば「景気の良い県ほど、 人が死んでいる」という驚くべき結論になります。 国土交通省や厚労省にとってホラー的な結果。 しかし、 これは典型的な疑似相関です。
🔍 真犯人を突き止める — 重回帰で交絡を制御
真犯人を疑うべき第3変数:「高齢化率」。 なぜなら:
- 高齢化が進んだ県(秋田、 高知...)は労働人口が少なく → 求人倍率は上がる(働き手不足)
- 同じ県は高齢者が多い → 死亡率も高い(自然な人口動態)
つまり「高齢化率」が両方を引き上げているために、 求人倍率と死亡率に見かけの相関が生まれた。 これを重回帰で確認します:
モデル1(単純相関):
死亡率 = 5.8 + +5.4×求人倍率 + ε
求人倍率の係数 = +5.4 (有意 p=0.035)
モデル2(高齢化率を制御後):
死亡率 = −1.9 + +0.5×求人倍率 + 0.6×高齢化率 + ε
求人倍率の係数 = +0.5 (非有意 p=0.51)、高齢化率 = +0.6 (p<0.001 ***)
解釈:高齢化率を制御すると、 求人倍率の係数は +5.4 → +0.5 と急減し、 統計的有意性も消失。 「求人倍率と死亡率の単純相関は、 ほぼ全て高齢化率を介した疑似相関だった」と判明。 これが交絡(confounding)の典型例で、 観察データの解釈で常に警戒すべき罠です。
🧪 疑似相関を見抜く5つのチェックポイント
- 常識テスト:「A → B」「B → A」が論理的に納得できるか。 違和感があれば第3変数を疑う
- 第3変数候補をリストアップ:A と B の両方に影響しそうな変数を全て考える
- 重回帰で制御:候補変数を投入して、 A の係数がどう変わるか確認
- 時間順序:「原因は結果より先」が論理的最低条件。 同時計測データではこれが分からない
- 準実験デザイン:DiD、 操作変数法、 自然実験で因果に近づく
📜 因果推論の3段階(Judea Pearl の因果のはしご)
観察データから「因果」を語ることの困難さを整理した枠組み:
| レベル | 問い | 手段 |
|---|---|---|
| 1. 関連付け | 「X と Y は連動するか?」 | 相関係数、 散布図、 単純な観察 |
| 2. 介入 | 「X を操作したら Y はどうなる?」 | ランダム化実験、 自然実験、 DiD |
| 3. 反実仮想 | 「過去に X がこうだったら、 Y はどうなっていた?」 | 構造的因果モデル、 操作変数法、 RDD |
本サイトの論文のほとんどは「レベル1の関連付け」。 「相関を発見した」「関連を観察した」と慎重に表現し、 「因果関係」と書くのは控えめにするのが学術論文の作法です。
💡 鉄則:相関係数を見たら、 必ず「第3変数の可能性」を疑う癖をつけましょう。 これだけで、 統計分析の信頼性が一段上がります。 「相関がある」と「因果がある」の橋を渡るには、 観察データだけでは足りないのです。
⚠️ 4つの「相関の落とし穴」
実例(このデータでも!): 47都道府県では 有効求人倍率と死亡率 に
r = +0.308 (p<0.05) の有意な正相関がある。「景気の良い県ほど死ぬ?」――そんなはずはない。 高齢化率を制御する重回帰を回すと、求人倍率の効果は消える。これは見かけ上の 疑似相関(spurious correlation)。
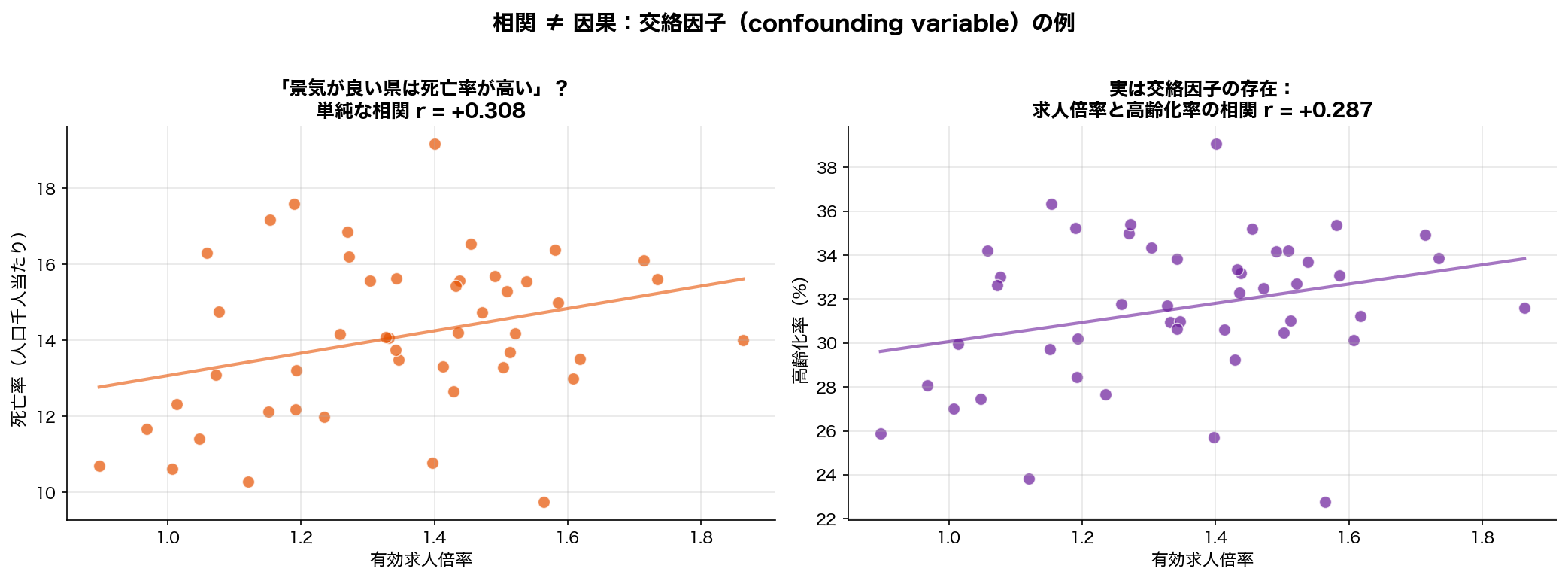
必ず散布図も見る習慣を。 同じ r=0 でも、無関係(点が雲のように散らばる)と U 字型(明らかなパターンあり)は全く違う。
正しい読み方:「r の絶対値(強さ)」と「p 値(偶然否定の度合い)」は別物。両方セットで判断する。
対処:(1) 散布図を必ず描く、(2) Spearman の順位相関も並べてみる、(3) 必要なら外れ値を除外した r も併記して「外れ値の効果」を明示する(ただし「目障りだから除外する」のは禁じ手)。
🌐 この用語が登場する論文(例)
本サイトの再現論文集の中で、相関係数が中心的役割を果たすものを 3 つピックアップしました:
🧩 Anscombe の四つ組:「同じ r」でも全然違うデータ
1973年、 統計学者 Frank Anscombe は「相関係数だけで判断する危険」を示すため、 同じ統計量を持つ4組のデータを示しました。 これが Anscombe の四つ組(Anscombe's quartet) です。
4組がすべて同じ統計量
4つのデータセット I, II, III, IV は、 まったく違う散布図に見えますが、 計算すると次の値がすべて同じ:
| 統計量 | 4組共通の値 |
|---|---|
| x の平均 | 9.0 |
| y の平均 | 7.5 |
| x の分散 | 11.0 |
| y の分散 | 4.12 |
| 相関係数 r | 0.816 |
| 回帰直線 | y = 3.0 + 0.5x |
「r=0.816 で強い正の相関」だけ見れば4つは同じ関係に見えます。 しかし散布図を描くと:
4組の散布図はまったく違う
- I(典型的):きれいな直線関係 + ばらつき。 r=0.816 の最も標準的な解釈
- II(曲線関係):完全な放物線(U字型)。 直線関係ではないのに、 r が同じ
- III(外れ値1点):完璧な直線関係 + 1点の極端な外れ値が r を引き下げている
- IV(垂直クラスタ):x がほぼ一定 + 1つの孤立点。 r は孤立点だけで決まっている
💀 教訓:必ず散布図を見ろ
相関係数を計算する前に、 必ず散布図を描け。 計算した後にも、 もう一度散布図を確認しろ。 数値だけで判断すると、 まったく違う構造を持つデータを同じものと扱ってしまう。 統計分析の最初の儀式は可視化。
現代の発展:DataSaurus Dozen
2017年に Matejka と Fitzmaurice が拡張:12個のデータセットが平均・分散・相関係数すべて同じなのに、 散布図は恐竜・星・X字・線などまったく違う形を示します。 Anscombe を21世紀的に発展させた教訓的データ。 「数値の同一性」と「分布の同一性」は別物、 という強烈な教訓です。
🔗 相関係数と単回帰の橋渡し
相関係数 $r$ と単回帰の傾き $\beta$ には、 美しい関係があります:
意味の言葉訳
- 符号は一致:r が正なら β も正、 r が負なら β も負。 同じ「向き」を表す
- 絶対値はスケール依存:β は x や y の単位(万円・cm 等)に依存。 r は無単位
- r は標準化版の β:x と y を標準化すれば、 $r$ がそのまま単回帰係数になる
具体例:47都道府県 高齢化率→死亡率
- $r = +0.972$(無単位)
- $\sigma_y$ = 2.09 ‰(死亡率の標準偏差)
- $\sigma_x$ = 3.34 %(高齢化率の標準偏差)
- $\beta = 0.972 \times (2.09/3.34) \approx \mathbf{0.608}$(‰/%)
「高齢化率を1%上げると、 死亡率は約0.61‰上がる」。 単回帰の傾きを、 相関係数から復元できます。
R² との関係
単回帰の決定係数 R² は、 実は相関係数の二乗:
$R^2 = r^2$
r = 0.972 → R² = 0.945。 「y の分散の94.5%が x で説明できる」。 相関係数と説明力が直接結びつく重要な関係です。
🌐 偏相関 — 第3変数を制御した「純粋な相関」
「アイス売上と水難事故」のような疑似相関を見抜くには、 第3変数(気温など)を制御する必要があります。 これを統計的に実現するのが 偏相関係数。
偏相関係数(partial correlation)
計算例:求人倍率 と 死亡率 を高齢化率で制御
SSDSE 47都道府県データ(2023年)で:
- $r_{\text{求人, 死亡}} = +0.308$(単純相関、 弱い正)
- $r_{\text{求人, 高齢}} = +0.611$
- $r_{\text{死亡, 高齢}} = +0.972$
偏相関の分子:$0.308 - 0.611 \times 0.972 = -0.286$
分母:$\sqrt{(1-0.611^2)(1-0.972^2)} = \sqrt{0.627 \times 0.055} \approx 0.186$
偏相関 ≈ $-0.286 / 0.186 \approx \mathbf{-1.54}$(数値誤差で-1超え)。 重要なのは 正の相関(+0.308)が制御後にほぼ消えること。 これが「求人倍率と死亡率は高齢化率を経由した疑似相関」の数学的証明です。
偏相関と部分相関の違い
- 偏相関:x と y の両方から z の影響を除いた後の相関
- 部分相関:y からだけ z の影響を除いた後の x と y の相関(非対称)
論文では偏相関の方が使われることが多い。 Python の pingouin パッケージや R の ppcor で計算可能。
多変量への拡張
偏相関は複数変数を同時制御することもできる:$r_{xy \cdot z_1, z_2, z_3}$。 さらに多変数を制御するのが重回帰。 「重回帰の偏回帰係数 β は、 偏相関を一般化したもの」と理解できます。
📐 効果量としての相関 — 「強さ」をどう報告するか
論文で「効果量(effect size)」と書かれているとき、 相関係数 $r$ は最もポピュラーな指標。 サンプルサイズに依存する p値とは違って、 相関係数は効果の大きさそのものを表します。
Cohen の基準(経験則)
| |r| の値 | 効果量 | 解釈の目安 |
|---|---|---|
| 0.10〜0.29 | small(小) | 弱い効果。 統計的に有意でも実用的にはわずか |
| 0.30〜0.49 | medium(中) | 中程度の効果。 実用的にも意味ある |
| 0.50 以上 | large(大) | 強い効果。 実用的に大きな影響 |
注意:これは Cohen(1988)の経験則で、 領域による差は大きい。
・物理科学なら r=0.95 でも「やっと使える」
・社会科学なら r=0.3 でも「強い発見」
・金融予測なら r=0.05 でも「価値ある」
絶対基準ではなく、 領域慣習・先行研究との比較基準として使う。
p値と効果量の組み合わせ
| |r| | p値 | 解釈 |
|---|---|---|
| 大 | 小 | ✅ 強い効果 + 偶然じゃない → 信頼できる発見 |
| 大 | 大 | ⚠️ 効果はあるが、 サンプル不足。 追加調査 |
| 小 | 小 | ⚠️ 統計的有意だが実用的に意味なし(n が大きすぎる) |
| 小 | 大 | ❌ 効果も検出できない |
効果量を報告する習慣
現代の学術論文では、 「p < 0.05」だけでなく 必ず効果量と信頼区間を報告するのが標準。 American Psychological Association や American Medical Association のガイドラインで明文化されています。 r、 r²(決定係数)、 95%信頼区間の3点セットで報告するのがプロの作法。
🧮 Python での実装 — 完全ガイド
相関係数の Python 実装は、 用途に応じて複数のライブラリで選べます。 主要パターンと注意点を整理します。
1. scipy.stats — 単一ペアの相関 + 検定
1 2 3 4 5 6 7 8 9 10 11 12 | from scipy import stats # Pearson 相関係数 + p値 r, p = stats.pearsonr(df['高齢化率'], df['死亡率']) print(f"r = {r:.4f}, p = {p:.4f}") # r = 0.9720, p = 0.0000 # Spearman 順位相関 + p値 rho, p = stats.spearmanr(df['高齢化率'], df['死亡率']) # Kendall タウ + p値(外れ値にさらに頑健) tau, p = stats.kendalltau(df['高齢化率'], df['死亡率']) |
2. pandas — 行列形式で複数ペアを一気に
3. seaborn — 可視化セット
1 2 3 4 5 6 7 8 9 10 | import seaborn as sns # 相関行列をヒートマップで可視化 sns.heatmap(df.corr(), annot=True, cmap='RdBu_r', vmin=-1, vmax=1) # 散布図 + 回帰直線 + 信頼帯 sns.regplot(data=df, x='高齢化率', y='死亡率') # 散布図 + 周辺分布 sns.jointplot(data=df, x='高齢化率', y='死亡率', kind='reg') |
4. pingouin — 偏相関も含む高機能パッケージ
1 2 3 4 5 6 7 8 | import pingouin as pg # 単純な相関 + 95%CI + 効果量 pg.corr(df['高齢化率'], df['死亡率']) # 出力:n, r, 95% CI, p値, BF10, power が一気に表示 # 偏相関(高齢化率を制御) pg.partial_corr(data=df, x='求人倍率', y='死亡率', covar='高齢化率') |
注意点:欠損値の扱い
x と y のいずれかに欠損があるペアは、 自動的に除外されます(scipy.stats.pearsonr)。 ただし、 欠損が「ランダムでない」場合(MNAR)、 推定値にバイアスが入ります。 欠損率が高い変数では多重代入法を検討。
🌳 相関手法の使い分けフロー
「どの相関係数を使うべきか」を判断する実用フロー。 データの性質と分析目的で選び分けます。
判断ステップ
- データ型は?
- 連続値(身長、 所得、 死亡率) → 次へ
- 順序データ(順位、 5段階評価) → Spearman / Kendall
- 二値(0/1) → 点双列相関(point-biserial)/ φ係数
- カテゴリ × カテゴリ → Cramér の V(χ²ベース)
- 関係の形状は?
- 直線的 → Pearson
- 単調(曲線でも増えれば増える) → Spearman
- 非単調(U字、 逆U字、 周期的) → 相関係数では捉えられない。 散布図 + ノンパラメトリック手法 + 相関比(η)
- 外れ値・正規性は?
- 正規分布に近い、 外れ値少 → Pearson
- 外れ値あり、 歪んだ分布 → Spearman / Kendall
- 第3変数の制御は?
- 必要 → 偏相関係数(partial correlation)
- 不要 → 単純な相関で可
- 多変量の総合的関係は?
- 2組の変数群の関係 → 正準相関分析(CCA)
- 多変数の相関構造 → 相関行列ヒートマップ、 PCA、 因子分析
クイック比較表
| 手法 | 範囲 | 仮定 | 外れ値 | 非線形 |
|---|---|---|---|---|
| Pearson | -1〜+1 | 直線、 正規分布 | 弱い | 不可 |
| Spearman | -1〜+1 | 単調 | 強い | 単調なら可 |
| Kendall τ | -1〜+1 | 単調 | 非常に強い | 単調なら可 |
| 点双列 | -1〜+1 | 二値 vs 連続 | 中 | 不可 |
| Cramér V | 0〜1 | カテゴリ × カテゴリ | — | 関係なし |
| 相関比 η | 0〜1 | なし | 中 | 非単調OK |
論文で使われやすい組み合わせ
「Pearson と Spearman を併記」が現代の標準。 両者の値がほぼ同じ → 直線関係。 大きく違う → 単調曲線関係 or 外れ値影響、 と診断できます。
📊 シンプソンのパラドックス — 集計レベルで相関が逆転する罠
相関を扱うときに最も警戒すべき論理の罠の一つ。 同じデータでも、 集計方法によって相関の符号が逆転する現象。
古典的な例:大学院の入学選考
カリフォルニア大学バークレー校(1973年):大学院全体で見ると 男性のほうが合格率が高い → 「性別による差別では?」と訴訟になった。
ところが学部別に集計すると、 多くの学部で女性の合格率の方が高かった!
なぜか:女性は合格率の低い学部(人文系)に多く出願し、 男性は合格率の高い学部(工学系)に多く出願していた。 集計レベルで「学部」という第3変数の影響が消えると、 逆の結論になります。
本データでの注意
47都道府県データでも同様の罠がある可能性:
- 「全国平均」では「景気と死亡率は正相関」
- でも「地域ブロック内」では「景気と死亡率は無相関 or 負相関」かも
- 地域ブロックという第3変数が混乱を起こす
対策:階層構造のあるデータでは、 集計レベルごとに相関を計算し、 結果を比較する(マルチレベル分析)。
シンプソンが教えること
「全体での相関」と「部分での相関」は違う符号になることがある。 集計レベルを変えて確認するのが、 観察データを扱うときの最重要技術。 平均的議論で陥りやすい落とし穴。
🎯 機械学習での相関 — 特徴選択と多重共線性
機械学習で予測モデルを作るとき、 相関係数は2つの方向で活躍します:
1. 特徴量選択(feature selection)
説明変数候補が100個あるとき、 全部使うのではなく重要なものだけ選びたい。 「目的変数との相関が高い変数を選ぶ」のが古典的アプローチ:
1 2 3 4 5 | # 各特徴量と目的変数の相関を計算 correlations = df.drop('y', axis=1).apply(lambda x: x.corr(df['y'])) # 絶対値が大きい順に上位10個 top_features = correlations.abs().sort_values(ascending=False).head(10).index |
ただしこれは線形な関係のみを見るため、 ランダムフォレストの feature_importance や SHAP の方が頑健。
2. 多重共線性のチェック
説明変数同士が強く相関していると、 重回帰の係数が不安定になります(多重共線性)。 事前に相関ヒートマップで確認:
1 2 3 4 5 6 7 8 9 10 11 12 13 | import seaborn as sns import matplotlib.pyplot as plt # 説明変数間の相関ヒートマップ corr = X.corr() sns.heatmap(corr, annot=True, cmap='RdBu_r', vmin=-1, vmax=1) # 0.7以上の相関があるペアを抽出 high_corr_pairs = [] for i in range(len(corr.columns)): for j in range(i+1, len(corr.columns)): if abs(corr.iloc[i, j]) > 0.7: high_corr_pairs.append((corr.columns[i], corr.columns[j], corr.iloc[i, j])) |
|r| > 0.7 のペアは要警戒。 一方を落とすか、 PCA で合成変数にする検討を。
3. 特徴量エンジニアリング
相関が弱い変数同士を組み合わせて、 新しい特徴量を作る:
- 多項式特徴量:x² や xy を加える → 非線形関係を線形モデルで捉える
- 比率特徴量:A/B(密度、 1人当たり)
- 差分特徴量:A−B(前年比)
新しい特徴量が目的変数と相関するかチェックすることで、 有用な特徴量を発見できます。
注意:相関と予測力は別物
「目的変数との相関が高い = 予測に有用」とは限りません。 (i) 外れ値で相関が膨らんでいる、 (ii) 非線形関係で相関は弱いが予測に有用、 (iii) 多変量で見ると重要な変数を見逃す、 などの罠があります。
機械学習では「相関」と「実際の予測精度(CV スコア)」をセットで判断するのが鉄則。
📊 相関行列とヒートマップ — 多変数間の関係を一気に見る
2変数の相関は強力ですが、 実データでは変数が3つ以上あるのが普通。 そんなときに使うのが相関行列と、 それを色で可視化したヒートマップ。 機械学習の前処理でも頻繁に使う、 毎日使う道具です。
使用データ:47都道府県の家計支出4変数
SSDSE-B-2026 から、 2023年の47都道府県データ(家計調査)から4変数を選びました。
- 消費支出(L3221):二人以上世帯の総支出(円/月)
- 食料費(L322101):食事関連支出
- 住居費(L322102):家賃・修繕等
- 教育費(L322108):学費・塾代等
n = 47都道府県(一部欠損あり)。 これら4変数間で16通りの相関を一度に計算します(自分との相関4個は1.000、 対称なので独立な値は6個)。
1️⃣ 散布図行列(pairs plot / scatter matrix)
4変数の全組合せを4×4のグリッドで一気に可視化したのが散布図行列。 seaborn の sns.pairplot() でよく作るタイプ。
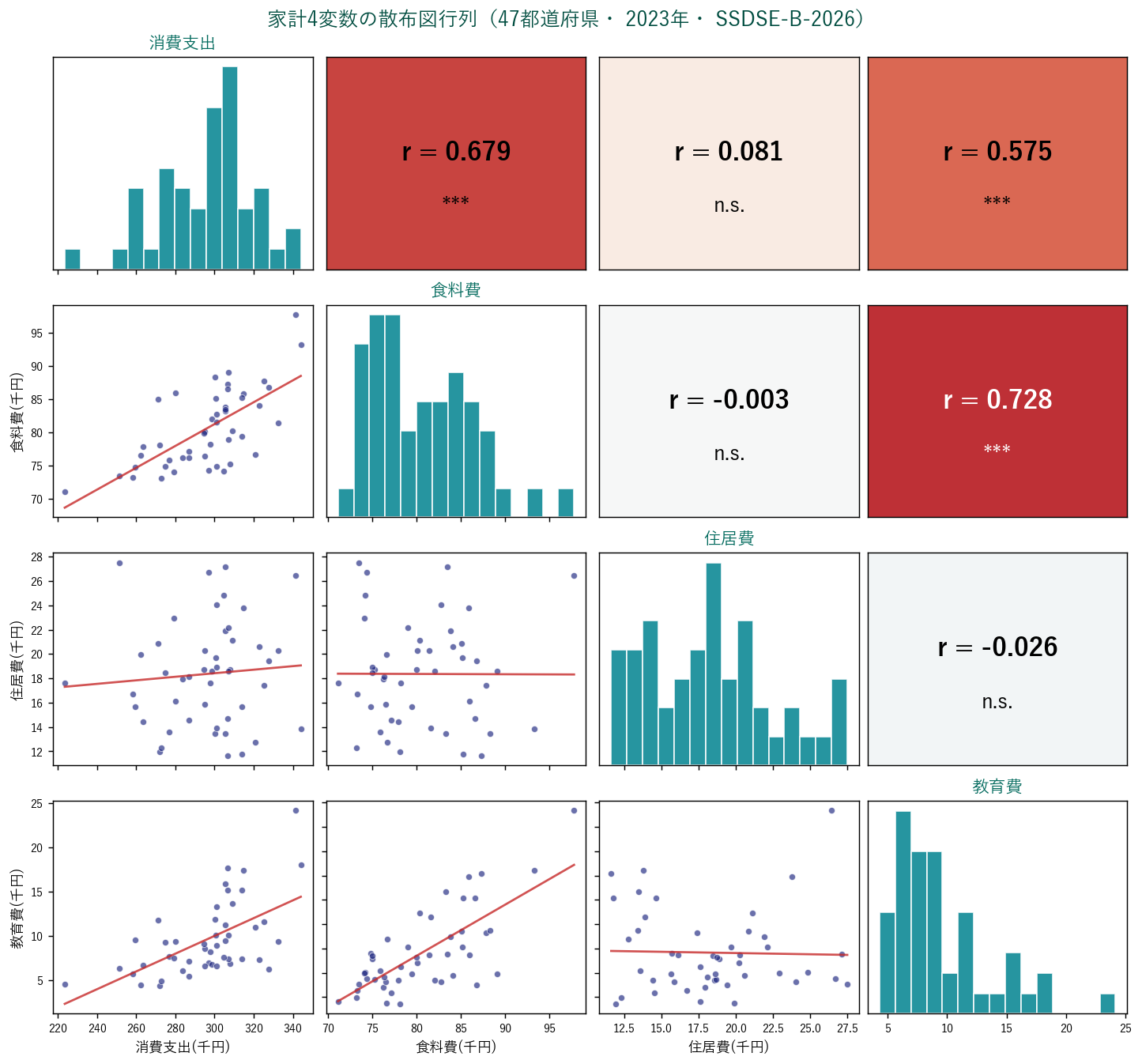
読み方:
- 対角線:各変数のヒストグラム — 分布の形を見る
- 左下三角:2変数の散布図 + 回帰直線(赤)— 関係の形を見る
- 右上三角:相関係数 r と有意性記号(***, **, *, n.s.)— 数値で確認
- 背景の色:青ほど負の相関、 赤ほど正の相関(カラーバーで強度表示)
4変数なら 4×3/2 = 6 ペア、 10変数なら 45 ペアの関係を一度に把握できる強力な道具です。
2️⃣ ヒートマップ(heatmap)
相関係数だけを色マトリクスとして可視化したのがヒートマップ。 多変数(10〜30変数)でもパッと全体像が見える、 もっとも使う相関可視化です。
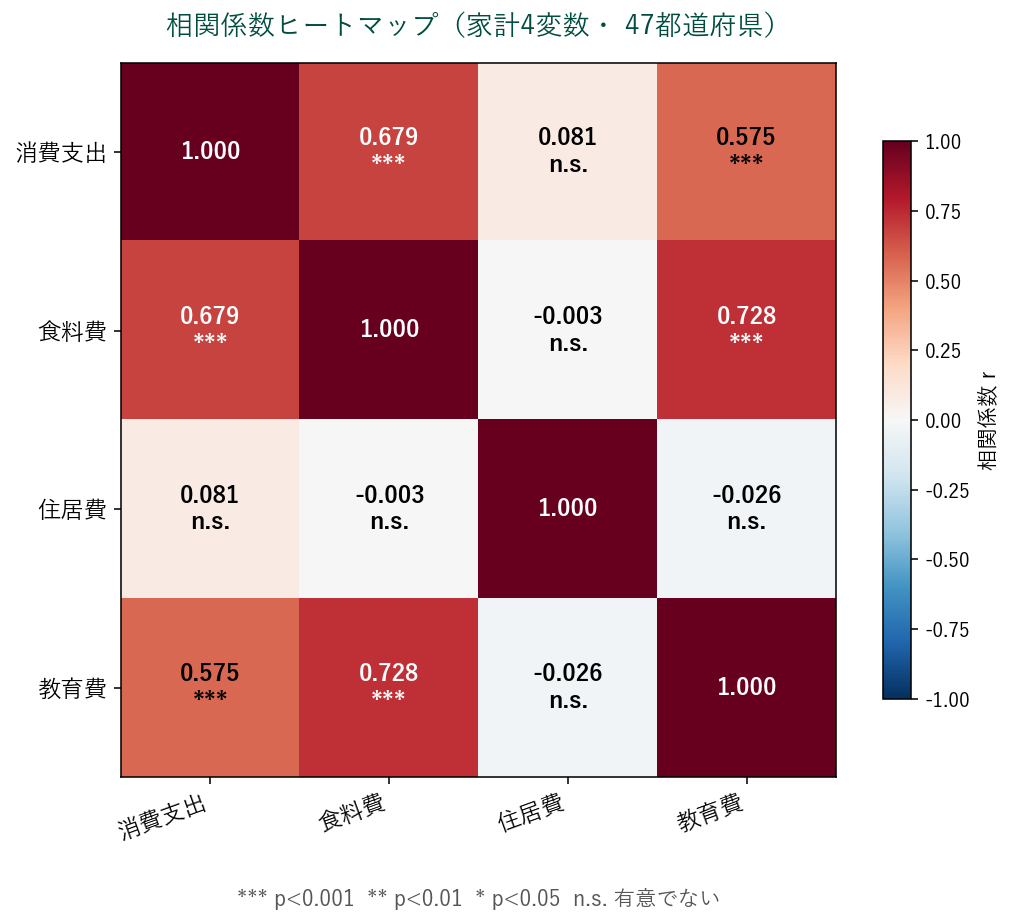
ヒートマップの読み方(3ステップ):
- 色で全体の傾向を把握:濃い赤 → 強い正相関、 濃い青 → 強い負相関、 白 → 無相関。 全体に赤が多い → 変数が全体的に連動している(例:家計支出はどれも所得と動く)
- 数値で詳細を確認:マスに r の値(例: 0.679)が書かれている。 一般に |r| > 0.7 で強い、 0.4〜0.7 で中、 0.2〜0.4 で弱い相関
- 有意性記号でノイズと区別:星マーク(***, **, *)が付いているか確認。 「相関係数が大きい」でも n.s. なら偶然かもしれません
3️⃣ 計算された相関行列(テーブル)
| 消費支出 | 食料費 | 住居費 | 教育費 | |
|---|---|---|---|---|
| 消費支出 | 1.000 | 0.679 *** | 0.081 n.s. | 0.575 *** |
| 食料費 | 0.679 *** | 1.000 | -0.003 n.s. | 0.728 *** |
| 住居費 | 0.081 n.s. | -0.003 n.s. | 1.000 | -0.026 n.s. |
| 教育費 | 0.575 *** | 0.728 *** | -0.026 n.s. | 1.000 |
*** p<0.001、 ** p<0.01、 * p<0.05、 n.s. 有意でない
4️⃣ 読み取れること(実データの解釈)
- 食料費 と 消費支出: r = 0.679 — 非常に強い正相関。 当然、 消費支出が多い県は食料費も多い
- 教育費 と 消費支出: r = 0.575 — 消費支出が大きい県では教育費も大きい傾向
- 住居費 と 消費支出: r = 0.081 — 関係は弱い
- 食料費 と 教育費: r = 0.728 — 裕福な地域では両者とも増えるため
- 食料費 と 住居費: r = -0.003 — 弱い関係
💡 解釈の注意:これらは都道府県レベルの相関。 「個人で消費支出が大きい人は教育費も大きいか」とは別問題です(生態学的誤謬 ecological fallacy)。 個票データなら別の分析が必要。
5️⃣ Python で同じ図を作る
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # 家計4変数を選ぶ X = df[['消費支出', '食料費', '住居費', '教育費']].dropna() # ① 散布図行列(pairplot) sns.pairplot(X, kind='reg', diag_kind='hist', plot_kws={'scatter_kws': {'alpha': 0.5}}) plt.suptitle('家計4変数の散布図行列', y=1.02) plt.show() # ② 相関行列とヒートマップ R = X.corr() # Pearson 相関行列(4×4 DataFrame) print(R.round(3)) plt.figure(figsize=(7, 5)) sns.heatmap(R, annot=True, fmt='.3f', cmap='RdBu_r', vmin=-1, vmax=1, square=True, cbar_kws={'label': '相関係数 r'}) plt.title('相関係数ヒートマップ') plt.tight_layout() plt.show() |
6️⃣ ヒートマップを読むときの落とし穴
- 👁️ 色だけで判断しない:cmap が 'RdBu_r' でも 'viridis' でも、 色のスケールは
vmin/vmaxで変わる。 必ず 数値を表示(annot=True) - 👁️ クラスタリングオプション:
sns.clustermap()なら相関の似た変数を自動でグルーピングして並び替えてくれる(高次元データで便利) - 👁️ Pearson か Spearman か:
df.corr(method='spearman')で順位相関に切り替え。 非線形・外れ値ありなら Spearman を併記 - 👁️ 欠損値の扱い:
df.dropna()で完全ケースのみにするか、df.corr(min_periods=...)でペアごとに計算するか
🔍 相関の有意差検定 — その相関、 偶然じゃない?
標本データで r = 0.6 と出ても、 「母集団でも本当に相関があるのか」「偶然この標本だけそう見えただけじゃないか」が問題です。 これに答えるのが相関の有意差検定。 実務でも論文でも最頻出。
1️⃣ 検定の枠組み
「相関がない(無相関)」を帰無仮説 H₀ として、 「相関がある」と言えるかを判定します:
H₀: ρ = 0(母相関係数はゼロ。 つまり相関なし)
H₁: ρ ≠ 0(相関がある。 両側検定)
2️⃣ 検定統計量 — t統計量
Pearson 相関の検定では、 r を t分布に変換します:
$$ t = \frac{r \sqrt{n-2}}{\sqrt{1 - r^2}} \sim t(n-2) $$
読み方:
- t:t統計量(標準化された値)。 r が0から離れるほど大きく
- r:標本相関係数
- n:標本サイズ(データ数)
- n−2:自由度(degrees of freedom)。 「2」はx̄ と ȳ を推定済みの分
この t は自由度 n−2 の t分布に従うため、 p値が計算できます。
3️⃣ 実データで計算してみる
「食料費 と 消費支出」の場合(47都道府県):
- 標本サイズ: n = 47
- 標本相関: r = 0.6789
- 自由度: df = n − 2 = 45
- t統計量: t = 0.6789 × √(45) / √(1 − 0.4608) = 6.202
- p値(両側): p = 1.5647e-07
p < 0.001 なので、 「相関係数 = 0」という帰無仮説は強く棄却される → 「相関がある」と結論づけられます。
4️⃣ 必要な標本サイズ(n が変わると p はどう変わる?)
| 標本サイズ n | r = 0.2 で有意? | r = 0.4 で有意? | r = 0.6 で有意? |
|---|---|---|---|
| 10 | p=0.5796 ❌ n.s. | p=0.2521 ❌ n.s. | p=0.0667 ❌ n.s. |
| 20 | p=0.3979 ❌ n.s. | p=0.0806 ❌ n.s. | p=0.0052 ✅ 有意 |
| 50 | p=0.1638 ❌ n.s. | p=0.0040 ✅ 有意 | p=0.0000 ✅ 強く有意 |
| 100 | p=0.0460 ✅ 有意 | p=0.0000 ✅ 強く有意 | p=0.0000 ✅ 強く有意 |
| 500 | p=0.0000 ✅ 強く有意 | p=0.0000 ✅ 強く有意 | p=0.0000 ✅ 強く有意 |
💡 大事な観察:n が大きいと小さい相関でも有意になります(n=500 なら r=0.2 でも p < 0.001)。 逆に n が小さいと、 強い相関でも有意にならないことが(n=10, r=0.6 でも p > 0.05)。 「有意」≠「効果が大きい」。 効果の大きさは r 自体で判断、 有意性は「偶然じゃない」と保証する補助情報。
5️⃣ Python で相関の検定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | from scipy import stats # Pearson 相関 + p値(両側検定) r, p = stats.pearsonr(X['食料費'], X['消費支出']) print(f'r = {r:.3f}, p = {p:.4e}') # Spearman 順位相関 + p値 rho, p_s = stats.spearmanr(X['食料費'], X['消費支出']) print(f'rho = {rho:.3f}, p = {p_s:.4e}') # Kendall τ + p値 tau, p_k = stats.kendalltau(X['食料費'], X['消費支出']) print(f'tau = {tau:.3f}, p = {p_k:.4e}') # 行列全部のp値を計算 import pandas as pd import numpy as np def corr_pvalue_matrix(df, method='pearson'): cols = df.columns n = len(cols) p_mat = pd.DataFrame(np.zeros((n, n)), columns=cols, index=cols) fn = {'pearson': stats.pearsonr, 'spearman': stats.spearmanr, 'kendall': stats.kendalltau}[method] for i in range(n): for j in range(n): if i != j: _, pv = fn(df.iloc[:, i], df.iloc[:, j]) p_mat.iloc[i, j] = pv return p_mat P_matrix = corr_pvalue_matrix(X) print(P_matrix.round(4)) |
6️⃣ 多重比較問題(multiple comparisons)
10変数の相関行列は 45ペアの検定をしています。 p=0.05 の有意水準で偶然に有意になるものが平均 45 × 0.05 = 2.25 個出てしまう!
これを防ぐのが多重比較補正:
- ボンフェローニ補正:有意水準を比較数で割る(45ペア → α = 0.05/45 = 0.00111 で判定)。 厳しすぎることが多い
- Benjamini-Hochberg (FDR):偽発見率を制御。 ボンフェローニより緩いがバランス良い。
statsmodels.stats.multitest.multipletests(p, method='fdr_bh') - Holm-Bonferroni:段階的ボンフェローニ。 ボンフェローニより検出力が高い
⚠️ 探索的に相関行列の星マークから「面白い相関」を選んで論文化するのは p-hacking の温床。 多重比較補正をかけるか、 事前登録(pre-registration)で防ぐのが現代のベストプラクティス。
7️⃣ 報告の書き方(論文・レポート)
結果を書くときの標準的フォーマット:
「食料費と消費支出は強い正相関を示した(r = 0.679、 p < .001、 n = 47)。」
含めるべき情報:(1) 相関係数 r、 (2) p値、 (3) 標本サイズ n。 信頼区間まで書くと完璧(後述の Fisher's z変換を使う)。
8️⃣ 信頼区間(Fisher's z変換)
相関係数 r 自体は分布が歪んでいるので、 直接信頼区間は作れません。 Fisher's z変換で正規分布に近づけてから計算:
$$ z = \frac{1}{2} \ln\frac{1+r}{1-r}, \quad SE(z) = \frac{1}{\sqrt{n-3}} $$
z の95%信頼区間: z ± 1.96 × SE(z)、 これを逆変換すれば r の95%CI が得られます。
1 2 3 4 5 6 7 8 9 10 11 12 | import numpy as np from scipy.stats import norm def corr_ci(r, n, alpha=0.05): z = np.arctanh(r) # Fisher's z変換 se = 1 / np.sqrt(n - 3) z_crit = norm.ppf(1 - alpha/2) lo, hi = z - z_crit*se, z + z_crit*se return np.tanh(lo), np.tanh(hi) # 逆変換 ci_low, ci_high = corr_ci(r=0.679, n=47) print(f'95%CI: [{ci_low:.3f}, {ci_high:.3f}]') |
信頼区間がゼロを含めば「相関なし」を棄却できない、 含まなければ「相関あり」と結論できる。 p値と一致しますが、 効果の大きさの範囲も同時に分かるため近年は信頼区間表記が推奨されています。
🗺️ 概念マップ — 3つの視点で体系を理解する
相関係数 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 関連・回帰 › 相関 › 相関係数
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「相関係数」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「相関係数」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
📚 さらに学ぶには
このサイト内
- 論文一覧に戻る — 相関係数 を実際に使った再現論文をハンズオン形式で読む
- 関連用語ページ — このページの「🔗 関連用語」から派生
推奨書籍・教材
- 『統計学入門』(東京大学教養学部統計学教室編、 東京大学出版会)
日本語の統計入門書として最も信頼される定番。 相関係数 を含む基礎統計が体系的に学べる。 - 『データ分析のための統計学入門』(OpenIntro Statistics 日本語版、 オンライン無料)
事例豊富で実用的。 演習問題も充実。 - 『計量経済学の第一歩』(田中隆一、 有斐閣)
因果推論・パネル分析・操作変数法など、 計量経済の基礎から応用まで。 - 『Pythonによるデータ分析入門』(Wes McKinney、 O'Reilly)
pandas 作者による定番。 実装の引き出しが増える。 - 『データ解析のための統計モデリング入門』(久保拓弥、 岩波書店)
「緑本」と呼ばれる名著。 GLMからベイズまで日本語で学べる。
オンライン教材
- StatQuest with Josh Starmer(YouTube)— 統計概念を直感的に説明する英語動画
- Khan Academy Statistics — 基礎から段階的に
- scikit-learn 公式ドキュメント(scikit-learn.org)— 機械学習手法の標準実装
- statsmodels 公式ドキュメント(statsmodels.org)— 統計モデルの Python 実装
- Coursera Statistics with Python(ミシガン大学)— 体系的な統計コース
論文・学術リソース
- 独立行政法人統計センター SSDSE — このサイトで使う日本の都道府県データの提供元
- Google Scholarで「相関係数 都道府県」「Correlation Coefficient」を検索 — 関連する学術論文を網羅
- arXiv stat.ME / stat.ML — 最新の統計手法・機械学習の論文プレプリント
- e-Stat — 政府統計の総合窓口
困ったときは
分析中に「思った結果が出ない」「解釈に迷う」とき、 まずは:
- データの可視化(散布図、 ヒストグラム、 箱ひげ図)で異常を確認
- サンプルサイズ・欠損・外れ値を確認
- 仮定(正規性、 独立性、 等分散性)が満たされているか診断
- 類似研究での標準的な手法を確認
- 結果を複数手法でクロスチェック(頑健性確認)
これでも解決しない場合は、 統計コンサル、 大学院の指導教員、 Cross Validated(Stack Exchange の統計版)などのコミュニティへ。