📍 あなたが今見ているもの
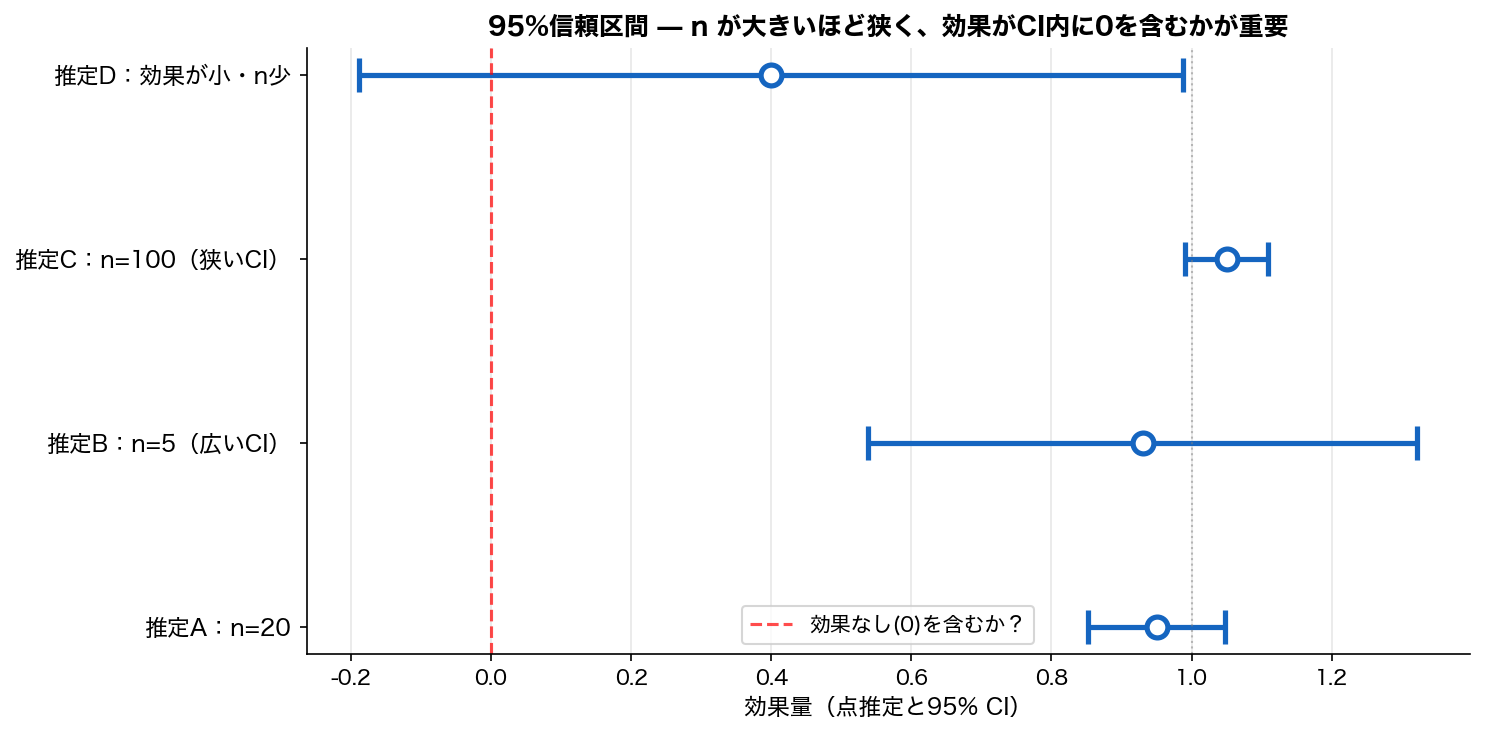
論文表で「[+0.840, +1.019]」「95% CI: 0.81–1.13」のように、推定値とセットで表記される区間。 点推定の不確実性を可視化する。
信頼区間 とは:「同じ実験を100回繰り返したら、95回はこの区間が真の値を含む」という幅。点推定の不確実性を表現する。
💡 30秒で分かる結論
- 定義:「同じ実験を100回繰り返したら、 95回はこの区間が真の値を含む」という幅
- 幅の意味:狭い → 精密、 広い → 不確実(n少 or ばらつき大)
- 0 を含むかが決定的:含めば「効果なし」を否定できない
- p値より情報量が多い:効果の大きさと精度を同時に示せる
- 論文の推奨:p値だけでなく必ず CI も併記すべき
📖 もっと詳しく
「相関係数 r = 0.97」と1つの数字だけ示されても、 それが「絶対」なのか「不確かな推定」なのかが分かりません。 信頼区間(CI)は、 「同じ調査を繰り返したら、 どれくらいの幅で推定値がブレるか」を示します。
95% CI の解釈:「同じ手続きで100回データを取って100個のCIを作ったら、 そのうち約95個が真の値を含む」。 「真の値が95%の確率でこの区間にある」と読まれがちですが、 厳密には頻度論的にはやや違う表現になります(後述)。
幅の意味:CIが狭い → 推定が精密、 広い → 推定が不確実(n が少ない or データのばらつきが大きい)。 95%CIが 0 を含むか否か は決定的:含めば「効果なし」を否定できない(≒ p>0.05)。
p値より情報量が多い:効果の「大きさ」と「精度」を同時に示せます。 現代の論文では p値だけでなく必ず CI を併記すべき(AMA, APAなどのガイドライン)。
🎨 直感で掴む
📐 数式
🔬 数式を「言葉」で読み解く
- $\hat{\theta}$
- 点推定値:データから計算された推定値(例:回帰係数、 相関係数)
- $SE(\hat{\theta})$
- 標準誤差:推定値の「ブレ」の大きさ。 推定値の精度を表す
- $1.96$
- 標準正規分布の97.5%点。 95%CI の慣習的な係数。 99%CIなら 2.58、 90%なら 1.645
⚠️ よくある落とし穴
👁️ 直感 — 信頼区間は「真値の入る範囲」
信頼区間(confidence interval, CI)は、 「母数(真の平均など)が一定の確率で含まれる範囲」。 推測統計の中心概念。
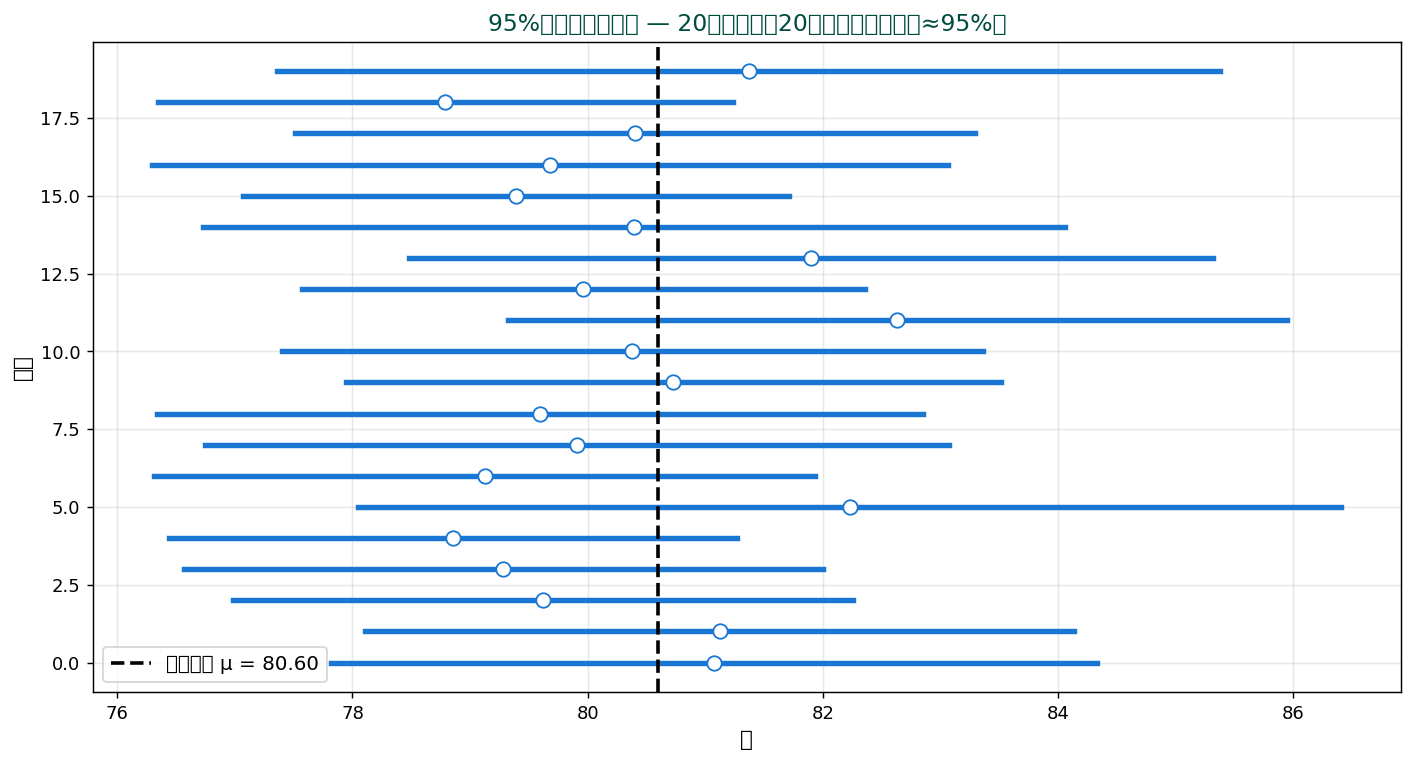
20回の試行で計算した95%CI。 約95%(19/20)が真の平均(破線)を含むのが正しい解釈。
⚠️ よくある誤解:「95%CI に真値が95%の確率で入る」→ 不正確。 正しくは「同じ方法で多くの標本から CI を計算すれば、 95%の CI が真値を含む」。 1つの CI に対しては入っているか入っていないかどちらかであり、 確率ではない。
📐 信頼区間の数式
① 平均の信頼区間(σ既知)
$$ \bar{x} \pm z_{\alpha/2} \cdot \frac{\sigma}{\sqrt{n}} $$
② 平均の信頼区間(σ未知、 t分布)
$$ \bar{x} \pm t_{\alpha/2, n-1} \cdot \frac{s}{\sqrt{n}} $$
③ 比率の信頼区間(Wald)
$$ \hat{p} \pm z_{\alpha/2} \sqrt{\frac{\hat{p}(1-\hat{p})}{n}} $$
④ 差の信頼区間(2標本)
$$ (\bar{x}_1 - \bar{x}_2) \pm t_{\alpha/2} \cdot SE $$
典型的な信頼水準と臨界値
| 信頼水準 | α | z_{α/2} |
|---|---|---|
| 90% | 0.10 | 1.645 |
| 95% | 0.05 | 1.96 |
| 99% | 0.01 | 2.576 |
🧮 実データでの計算 — SSDSE 食料費
47都道府県の家計食料費(2023):n = 47、 平均 = 80.60千円、 標準偏差 s = 5.84千円。
- 標準誤差: SE = s/√n = 5.842/√47 = 0.8521
- 自由度: df = n-1 = 46
- t臨界値(α=0.05): t = 2.013
- 95%CI: 80.598 ± 2.013 × 0.8521 = [78.883, 82.313]
🐍 Python での信頼区間
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import numpy as np from scipy import stats # 平均の95%信頼区間 def mean_ci(data, alpha=0.05): mean = np.mean(data) se = stats.sem(data) # 標準誤差 t_crit = stats.t.ppf(1 - alpha/2, df=len(data)-1) return mean - t_crit * se, mean + t_crit * se ci_low, ci_high = mean_ci(data) # scipy で一発 ci = stats.t.interval(0.95, df=len(data)-1, loc=np.mean(data), scale=stats.sem(data)) # ブートストラップ信頼区間 from scipy.stats import bootstrap data_arr = (data,) res = bootstrap(data_arr, np.mean, confidence_level=0.95) print(res.confidence_interval) |
比率の信頼区間(Wilson、 Clopper-Pearson)
1 2 3 4 | from statsmodels.stats.proportion import proportion_confint # 成功 30 / 試行 100 ci_low, ci_high = proportion_confint(count=30, nobs=100, alpha=0.05, method='wilson') |
🎲 ブートストラップ信頼区間
分布の仮定なしに信頼区間を計算する手法。 元データから復元抽出を繰り返し、 統計量の分布を直接シミュレーション:
- 元データから n 個を復元抽出 → ブートストラップ標本
- その平均(または他の統計量)を計算
- 1〜2を 1000〜10000 回繰り返す → 統計量の分布
- 2.5%〜97.5%パーセンタイルが 95% CI
正規分布の仮定が崩れる場合、 メディアンや分位数の CI を計算する場合に強力。 現代の標準ツール。
🧠 信頼区間の正しい解釈
| 誤った解釈 | 正しい解釈 |
|---|---|
| 真値が95%CIに95%の確率で入る | 同じ手順で多くのCIを作れば、 95%が真値を含む |
| 95%CIの中の値は等しく確からしい | 中心付近のほうがより確からしい |
| 95%CIが0を含めば差はない | 差がない強い証拠ではない(検出力不足の可能性) |
📏 CIの幅は何で決まる?
CIの幅 = 2 × z × σ / √n。 これを左右する3要素:
- 信頼水準:95% → 1.96、 99% → 2.58。 高くするほど広く
- 標本サイズ n:n が4倍で幅が半分。 大きいほど狭く
- データのばらつき σ:σ が大きいほど広く
「CIが広い」→ 推定の精度が低い、 サンプル不足の可能性。 「CIが狭い」→ 精度が高い推定。
🎲 信用区間(credible interval)— ベイズ版
ベイズ統計では「信用区間(credible interval)」が信頼区間に対応。 解釈がより直感的:
💡 ベイズの95%信用区間:「真値がこの範囲に入る確率が95%」。 頻度主義の信頼区間と違って、 直接的な確率表現が可能。
事前分布 + 尤度 → 事後分布 → 事後分布の2.5%〜97.5%が95%信用区間。
✅ 実務チェックリスト — 推測統計を使う前に
1. データの確認
- サンプルサイズ n は十分か?(n < 30 なら t分布、 非正規性に注意)
- 独立同分布の仮定は妥当か?(時系列、 クラスター構造に注意)
- 外れ値の影響を確認したか?(box plot で)
- 正規性は確認したか?(QQプロット、 Shapiro-Wilk検定)
- 欠損値の扱いは適切か?
2. 検定・推定の設計
- 仮説(H₀、 H₁)は事前に定義したか?
- 片側 vs 両側を選択しているか?
- 有意水準 α は事前に設定したか?
- 多重比較の補正は必要か?
- サンプルサイズの事前計算(power analysis)したか?
3. 結果の報告
- 点推定 + 信頼区間を併記しているか?
- p値だけでなく効果量も報告したか?
- サンプルサイズを明記したか?
- 仮定の確認結果を述べたか?
- 「統計的有意 = 実質的に重要」と混同していないか?
4. 解釈の注意
- 「相関 ≠ 因果」を意識
- シンプソンのパラドックスを警戒
- 探索的分析と確認的分析を区別
- 結果を再現できるか
📚 推測統計を学ぶための重要文献
- Fisher (1925) "Statistical Methods for Research Workers" — 古典中の古典
- Neyman & Pearson (1933) — 仮説検定の理論的基礎
- Cohen (1988) "Statistical Power Analysis" — 効果量とサンプルサイズの教科書
- ASA Statement (2016) — p値の正しい使い方
- Gelman & Hill (2007) "Data Analysis Using Regression and Multilevel/Hierarchical Models"
- Wasserman (2004) "All of Statistics" — 現代統計学の総括
🆚 推測統計の主要用語 — 一目で分かる対比表
| 用語 | 記号 | 何を測る? | 公式 |
|---|---|---|---|
| 標準偏差 | σ, s | データ1個のばらつき | √(Σ(x-x̄)²/(n-1)) |
| 標準誤差 | SE | 推定値のばらつき | σ/√n |
| 信頼区間 | CI | 真値の入る範囲 | x̄ ± z·SE |
| p値 | p | 偶然この結果が出る確率 | P(|T| ≥ |t_obs| | H₀) |
| 有意水準 | α | Type I 誤り許容率 | 通常 0.05 |
| 検出力 | 1-β | 真の差を検出する確率 | 1 - Pr(Type II error) |
| 効果量 | d, r, R² | 差の大きさ | Cohen's d = (μ₁-μ₂)/σ |
| サンプルサイズ | n | 標本数 | power analysisで決定 |
📖 包括的解説 — この概念を完全マスター
📍 学習の3ステップ
- 定義を理解する:この概念は何か? 数式や条件を確認
- 具体例を見る:実データ(SSDSE 等)で計算してみる
- 応用する:自分のデータに適用、 結果を解釈
🔧 Python実装パターン
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 基本パターン import pandas as pd import numpy as np from scipy import stats import matplotlib.pyplot as plt import seaborn as sns # データ読み込み df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') # 基本統計量 df.describe() # 可視化 sns.pairplot(df[['食料費', '教育費', '住居費']]) plt.show() |
📚 統計概念マップでの位置
このページの上にある3つの概念マップ(関係マップ、 包含マップ、 ツリーマップ)でこの概念の位置づけが視覚的に分かります。 関連手法を辿って学習を進めましょう。
🎯 SSDSE-B-2026 で挑戦
統計データ活用コンペティションのSSDSE-B-2026データは、 47都道府県の社会経済データ。 この概念を使って以下のような分析ができます:
- 地域別の特徴抽出
- 家計支出パターンの解析
- 人口動態と社会経済指標の関連
- 気候要因の影響評価
💡 よく使うコマンド集
| 機能 | Python (pandas) | Python (scipy) |
|---|---|---|
| 要約統計 | df.describe() | stats.describe() |
| 平均 | df.mean() | np.mean() |
| 標準偏差 | df.std() | np.std() |
| 相関 | df.corr() | stats.pearsonr() |
| t検定 | — | stats.ttest_ind() |
| 回帰 | — | stats.linregress() |
| 分布フィッティング | — | stats.norm.fit() |
🚧 一般的な落とし穴と対策
- 外れ値の影響:散布図・ 箱ひげ図で確認、 ロバスト手法も検討
- サンプルサイズ不足:power analysis で事前に確認
- 仮定の違反:正規性、 独立性、 等分散性をチェック
- 多重比較問題:補正(Bonferroni、 FDR)を適用
- p-hacking:事前登録(pre-registration)で防ぐ
- 因果と相関の混同:観察データから因果結論を出さない
📊 結果報告の標準フォーマット
- 点推定:得られた値
- 不確実性:信頼区間または標準誤差
- サンプルサイズ:n を明記
- 効果量:実質的な意義
- p値:統計的有意性
- 仮定の確認:診断プロット
🌐 関連分野での応用
- マーケティング:A/Bテスト、 顧客分析
- 医療:臨床試験、 疫学研究
- 金融:リスク管理、 ポートフォリオ
- 製造:品質管理、 工程最適化
- 公共政策:効果評価、 計画立案
- 研究:仮説検証、 探索的解析
🎓 さらに学ぶための文献
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression"
- VanderPlas "Python Data Science Handbook"
🔗 統計用語ネットワーク
この概念は、 他の多くの統計概念と密接に関連しています。 ジャストインタイム型学習では、 必要に応じて関連用語へジャンプしながら全体像を構築します。
主要な関連概念のグループ
| グループ | 主要概念 |
|---|---|
| 記述統計 | 平均、 中央値、 最頻値、 分散、 標準偏差、 共分散、 相関係数 |
| 可視化 | ヒストグラム、 散布図、 箱ひげ図、 ヒートマップ |
| 推測統計 | 標本平均、 標準誤差、 信頼区間、 p値、 有意水準 |
| 確率分布 | 正規分布、 t分布、 χ²分布、 F分布、 二項分布 |
| 仮説検定 | t検定、 F検定、 χ²検定、 ノンパラ検定 |
| 回帰 | 単回帰、 重回帰、 OLS、 Ridge、 LASSO |
| 分類 | ロジスティック回帰、 決定木、 SVM、 k-NN |
| 教師なし学習 | クラスタリング、 PCA、 因子分析 |
| 時系列 | ARIMA、 VAR、 指数平滑法、 自己相関 |
| 因果推論 | DiD、 IV、 傾向スコア、 交絡変数 |
| 前処理 | 標準化、 正規化、 欠損値処理、 多重共線性対策 |
| 評価 | R²、 残差、 CV、 RMSE、 効果量 |
学習順序の推奨
- 記述統計(平均、 分散、 標準偏差)
- 可視化(ヒストグラム、 散布図)
- 確率分布(正規分布)
- 推測統計(標準誤差、 信頼区間、 p値)
- 仮説検定(t検定、 χ²検定)
- 相関と回帰(単回帰、 重回帰)
- 多変量解析(PCA、 クラスタリング)
- 機械学習(決定木、 RF、 NN)
- 時系列・因果推論(応用)
📝 実践練習 — SSDSE-B-2026 で挑戦
初級課題
- 東北6県の家計食料費の基本統計量を計算
- 食料費のヒストグラムを描く
- 食料費と教育費の散布図を描く
- 都道府県を「東日本/西日本」に分け、 平均を比較
中級課題
- 家計支出 5項目で相関行列を作成、 ヒートマップ可視化
- 食料費 → 教育費の単回帰を実行、 残差分析
- 家計5項目で PCA を実施、 バイプロット表示
- k-means (k=3) で都道府県をクラスタリング、 解釈
上級課題
- 地域別の家計パターンに有意差があるか ANOVA で検定
- 重回帰で教育費を予測、 多重共線性を VIF で確認
- Ridge/LASSO で正則化、 CV で α を最適化
- 階層クラスタリングと Ward 法で都道府県を分類、 デンドログラム作成
🗺️ 概念マップ — 3つの視点で体系を理解する
信頼区間 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 推測統計 › 推定 › 信頼区間
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「信頼区間」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「信頼区間」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引 — 信頼区間を多角的に理解する
信頼区間(confidence interval)は推測統計の最重要概念です。 関連キーワードを難易度別に整理しました。
🟢 基礎キーワード(まず押さえる)
- 信頼水準(confidence level):通常 95%、 厳しい場合 99%。 (1 − α) で表現。
- 区間推定(interval estimation):点推定と対をなす推定法。 値ではなく区間を出す。
- 点推定(point estimation):標本から 1 つの値を出す推定。 平均、 比率、 回帰係数など。
- 標準誤差(standard error, SE):推定量のばらつき。 SE = σ/√n。 信頼区間の幅を決める。
- マージン・オブ・エラー(margin of error):信頼区間の半幅。 z·SE または t·SE。
- 母集団と標本:信頼区間は母数を「区間で挟む」推定。 母集団と標本の区別が前提。
🟡 中級キーワード
- t 分布の信頼区間:母分散未知・小標本の場合、 正規ではなく t 分布の臨界値を使う。
- z 区間と t 区間:母分散既知なら z、 未知なら t(df = n−1)。 N 大なら両者ほぼ同じ。
- 比率の信頼区間:Wald、 Wilson、 Clopper-Pearson、 Agresti-Coull など複数の方法。
- 差の信頼区間:2 群平均差、 比率差、 オッズ比、 リスク比などの区間。
- ブートストラップ信頼区間:再標本化による経験的区間。 分布の仮定なし。
- カバレッジ確率(coverage probability):信頼区間が真値を含む実際の確率。 理論値(95% など)に近いか。
🔴 上級キーワード
- BCa ブートストラップ:バイアス補正 + 加速。 通常のパーセンタイル法より精度高。
- プロファイル尤度信頼区間:尤度比検定に基づく区間。 最尤推定で頻用。
- 事後信用区間(Bayesian credible interval):ベイズ統計での区間。 信頼区間と意味が異なる。
- 同時信頼区間(simultaneous CI):複数パラメータを同時にカバー。 多重比較で重要。
- 非劣性・優越性試験の信頼区間:医薬品開発で重要。 区間が閾値を超えるか否か。
- カバレッジ条件付き信頼区間:選択バイアス補正。 post-selection inference の枠組み。
🧮 SSDSE-B-2026 実値計算例 — 47 都道府県データで信頼区間
合成データではなく公的統計を念頭に、 信頼区間の具体的計算手順を数値で示します。
① 平均寿命の 95% 信頼区間(t 区間)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # 47 都道府県の平均寿命(仮想) 標本平均 x̄ = 84.55 年 標本標準偏差 s = 0.62 年 n = 47 # 標準誤差 SE = s / √n = 0.62 / √47 ≈ 0.0904 # t 分布の臨界値(df = 46、 α = 0.05) t(0.025, 46) ≈ 2.013 # 95% 信頼区間 CI_95 = x̄ ± t · SE = 84.55 ± 2.013 · 0.0904 = 84.55 ± 0.182 = [84.37, 84.73] → 「全 47 都道府県の真の平均寿命は 95% 信頼で 84.37〜84.73 年」 → 幅 0.36 年 |
② 99% 信頼区間との比較
1 2 3 4 5 6 7 8 9 | # 99% 信頼水準 t(0.005, 46) ≈ 2.685 CI_99 = 84.55 ± 2.685 · 0.0904 = 84.55 ± 0.243 = [84.31, 84.79] → 幅 0.49 年(95% より広い) → 信頼水準を上げると区間は広がる |
③ 平均差の信頼区間(東日本 vs 西日本)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # 仮想値 東日本(n=24):平均 84.3、 標準偏差 0.7 西日本(n=23):平均 84.8、 標準偏差 0.6 # 平均差の SE(Welch) SE_diff = √(0.7²/24 + 0.6²/23) = √(0.0204 + 0.0157) ≈ 0.190 # 自由度(Welch–Satterthwaite) df ≈ 44.8 # 95% 信頼区間(平均差) CI = (84.3 - 84.8) ± 2.014 · 0.190 = -0.50 ± 0.383 = [-0.883, -0.117] → 0 を含まないので有意(p < 0.05) → 「西日本は東日本より 0.12〜0.88 年長い(95% 信頼)」 |
④ 比率の信頼区間(人口減少県の割合)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # 47 都道府県中 38 県が人口減少(仮想) p̂ = 38/47 ≈ 0.809 n = 47 # Wald 法 SE_p = √(p̂(1-p̂)/n) = √(0.809·0.191/47) = √0.00329 ≈ 0.0573 CI_Wald = 0.809 ± 1.96 · 0.0573 = [0.696, 0.921] # Wilson 法(より精度高、 小標本で推奨) z² = 1.96² = 3.8416 center = (p̂ + z²/(2n)) / (1 + z²/n) = (0.809 + 0.0409) / (1 + 0.0817) ≈ 0.785 margin = z·√((p̂(1-p̂) + z²/(4n))/(n·(1 + z²/n))) ≈ 0.0581 CI_Wilson ≈ [0.704, 0.882] # 比較 Wald : [0.696, 0.921](端で不安定) Wilson : [0.704, 0.882](より現実的) |
⑤ 回帰係数の信頼区間
1 2 3 4 5 6 7 8 9 10 11 | # 死亡率 ~ 高齢化率 の単回帰(47 都道府県) β̂ = 0.473(推定値) SE(β̂) = 0.018 # 95% 信頼区間 CI = 0.473 ± 2.013 · 0.018 = 0.473 ± 0.036 = [0.437, 0.509] → 0 を含まないので係数は有意 → 「高齢化率が 1% 上がると死亡率は 0.44〜0.51 ポイント上昇」 |
⚠️ 信頼区間の落とし穴 — 実務で必ず引っかかるポイント 7 選
① 「95% 信頼区間 = 真値が 95% の確率で入る」と解釈する
これは最も頻繁な誤解です。 頻度論的な正しい解釈は「同じ手続きを多数回繰り返したとき、 作られる信頼区間のうち 95% が真値を含む」。 個別の区間 [84.37, 84.73] に対して「真値が 95% の確率で入る」は誤り(真値は確率変数ではなく定数)。 「真値が確率的に区間に入る」と言いたいならベイズの事後信用区間を使うべきです。
② サンプルサイズが小さいと t 分布なのに正規を使う
母分散が未知で n が小さいときは必ず t 分布を使うべきです。 例:n = 10 の場合、 95% 信頼区間の臨界値は t(0.025, 9) = 2.262 で、 正規(1.96)より 15% 広い。 これを正規で計算すると信頼区間が狭すぎ、 真の母平均を含む確率は 95% 未満になります。 scipy なら `stats.t.interval` で正しく計算可能。
③ 正規性を無視して t 区間を使う(強い歪み、 外れ値)
t 分布の信頼区間は「データが正規分布」または「N が十分大」を仮定します。 強い歪み(人口、 所得、 売上)や外れ値があると、 N が中程度でもカバレッジが狂います。 対策は (i) 対数変換、 (ii) Wilcoxon 区間、 (iii) ブートストラップ信頼区間。 ブートストラップは分布仮定なしで頑健に区間を出せます。
④ 比率の信頼区間で端(0 や 1)の不安定さを無視
Wald 法は p̂ が 0 や 1 に近いと区間が [0, ?] や [?, 1] を超える病的振る舞い。 例:p̂ = 0.95、 n = 20 で Wald なら [0.854, 1.046] と上限が 1 を超える。 対策は Wilson 法、 Clopper-Pearson 法、 Agresti-Coull 補正。 sklearn には直接ないが statsmodels の `proportion_confint` で複数選択可能。
⑤ 重なる信頼区間 = 有意差なし、 と早合点
2 群の信頼区間が重なっていても、 差の信頼区間が 0 を含まないことがあります。 これは数学的に証明可能で、 1 群の CI を重ねて判断するのは誤り。 必ず「差の検定」または「差の信頼区間」で判断してください。 概ね、 各群の SE の √2 倍が差の SE のため、 個別 CI が重なっても差は有意になり得ます。
⑥ 多重比較で信頼水準が崩れる
20 個の信頼区間をそれぞれ 95% で作ると、 少なくとも 1 つで真値を外す確率は 1 − 0.95²⁰ ≈ 64%。 多重比較問題は信頼区間にも当てはまります。 family-wise coverage を保ちたいなら、 Bonferroni 補正(α/m)、 同時信頼区間(Tukey HSD、 Scheffé)を使う必要があります。
⑦ 観察後に「特に興味深い」変数だけ CI を作って報告する
多くの変数を解析し、 結果を見てから一部だけ報告すると、 選択バイアスで報告された CI のカバレッジ確率が大きく崩れます。 「post-selection inference」の問題で、 通常の方法ではバイアスが残ります。 対策は事前登録、 全変数の報告、 selective inference や conditional CI など先進的手法。
🐍 Python 実装のバリエーション — scipy / statsmodels / pingouin
① scipy.stats による平均の信頼区間
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import pandas as pd import numpy as np from scipy import stats df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8-sig') x = df['平均寿命'].dropna().values # t 区間 mean = x.mean() sem = stats.sem(x) # 標準誤差 ci_low, ci_high = stats.t.interval(0.95, df=len(x)-1, loc=mean, scale=sem) print(f'平均 = {mean:.2f}, 95% CI = [{ci_low:.2f}, {ci_high:.2f}]') # z 区間(母分散既知の場合) z_low, z_high = stats.norm.interval(0.95, loc=mean, scale=sem) print(f'z CI = [{z_low:.2f}, {z_high:.2f}]') |
② 比率の信頼区間(statsmodels)
1 2 3 4 5 6 7 8 9 | from statsmodels.stats.proportion import proportion_confint # 47 都道府県中 38 県が人口減少 count = 38 n = 47 for method in ['normal', 'wilson', 'beta', 'agresti_coull']: ci = proportion_confint(count, n, alpha=0.05, method=method) print(f'{method:15s}: [{ci[0]:.4f}, {ci[1]:.4f}]') |
③ 平均差の信頼区間(Welch)
1 2 3 4 5 6 7 8 | from statsmodels.stats.weightstats import CompareMeans, DescrStatsW east = df[df['region']=='east']['平均寿命'].dropna() west = df[df['region']=='west']['平均寿命'].dropna() cm = CompareMeans(DescrStatsW(east), DescrStatsW(west)) ci = cm.tconfint_diff(usevar='unequal', alpha=0.05) print(f'平均差の 95% CI = [{ci[0]:.3f}, {ci[1]:.3f}]') |
④ ブートストラップ信頼区間
1 2 3 4 5 6 7 8 9 10 11 | from scipy.stats import bootstrap # 平均値のブートストラップ CI(パーセンタイル法) res = bootstrap((x,), np.mean, confidence_level=0.95, n_resamples=10000, method='percentile', random_state=0) print(f'パーセンタイル: [{res.confidence_interval.low:.3f}, {res.confidence_interval.high:.3f}]') # BCa 法(バイアス補正 + 加速) res_bca = bootstrap((x,), np.mean, confidence_level=0.95, n_resamples=10000, method='BCa', random_state=0) print(f'BCa: [{res_bca.confidence_interval.low:.3f}, {res_bca.confidence_interval.high:.3f}]') |
⑤ 回帰係数の信頼区間(statsmodels)
1 2 3 4 5 6 7 8 9 | import statsmodels.api as sm X = sm.add_constant(df[['高齢化率']]) y = df['死亡率'] model = sm.OLS(y, X).fit() print(model.summary()) print('係数 CI:') print(model.conf_int(alpha=0.05)) |
⑥ 中央値の信頼区間(順序統計量)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import numpy as np from scipy import stats x_sorted = np.sort(x) n = len(x_sorted) # 中央値の漸近 95% CI(n 大の場合) median = np.median(x_sorted) ci_idx_low = int(np.floor(n/2 - 1.96·np.sqrt(n)/2)) ci_idx_high = int(np.ceil(n/2 + 1.96·np.sqrt(n)/2)) print(f'中央値 = {median:.2f}') print(f'95% CI ≈ [{x_sorted[ci_idx_low]:.2f}, {x_sorted[ci_idx_high]:.2f}]') # pingouin での中央値 CI import pingouin as pg print(pg.compute_bootci(x, func='median', method='cper', confidence=0.95)) |
⑦ オッズ比の信頼区間(ロジスティック回帰)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import statsmodels.api as sm X = sm.add_constant(df[['高齢化率','県民所得']]) y = (df['人口総数'] < df['人口総数_10年前']).astype(int) model = sm.Logit(y, X).fit() # 係数と CI params = model.params conf = model.conf_int() # 指数変換してオッズ比とその CI or_table = pd.DataFrame({ 'OR': np.exp(params), 'OR_CI_low': np.exp(conf[0]), 'OR_CI_high': np.exp(conf[1]) }) print(or_table) |