📍 あなたが今見ているもの
論文表で各係数の隣に出てくる「std err」「SE」の列。 p値や信頼区間の計算の出発点。
標準誤差 とは:「標本平均がどれくらいブレるか」を測る量。標準偏差をサンプルサイズの平方根で割ったもの。
💡 30秒で分かる結論
- 定義:「同じ実験を繰り返したときの推定値のばらつき」
- SD との違い:SD はデータ自体、 SE は統計量(推定値)のばらつき
- 計算:標本平均なら $SE = \sigma/\sqrt{n}$、 n大で SE は小さく
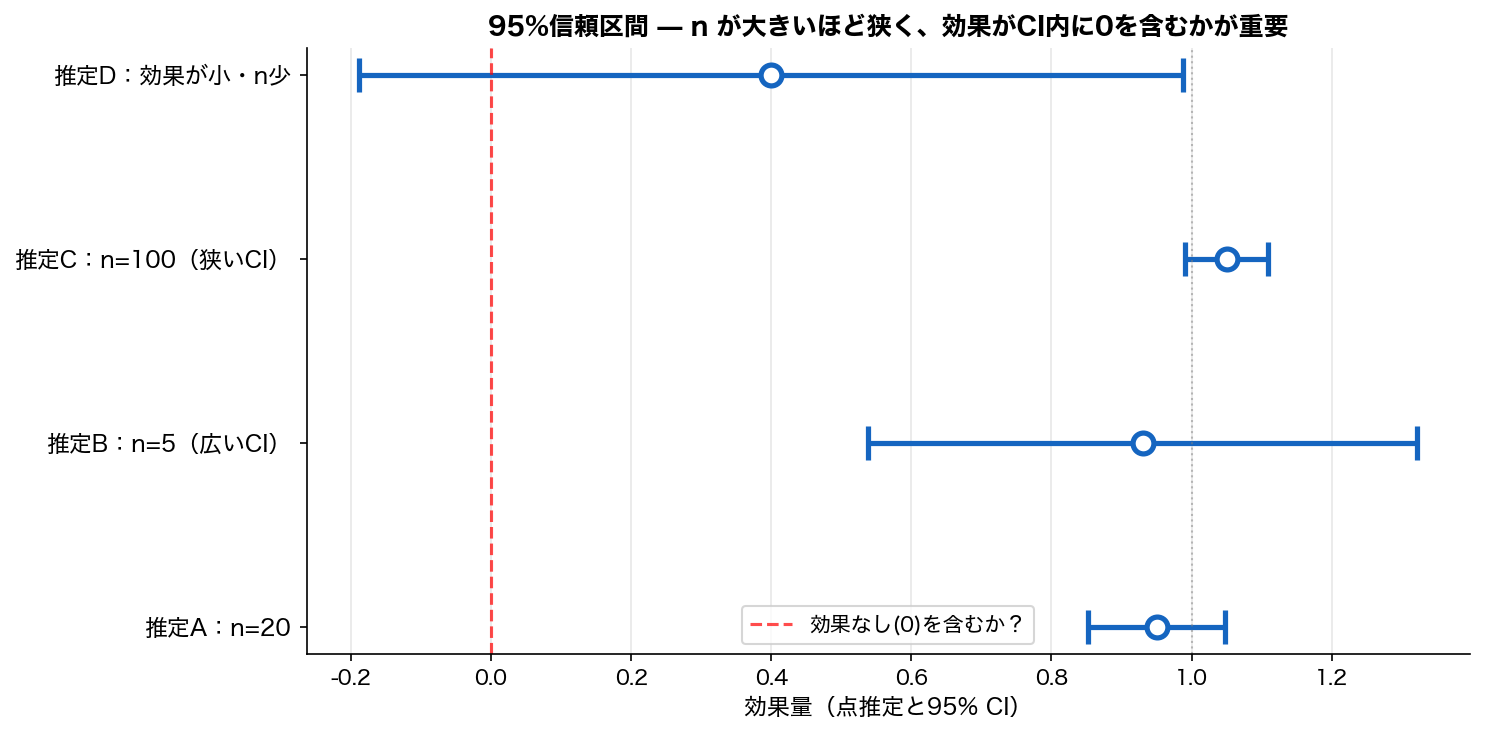
- 用途:CI の幅は SE で決まる。 t統計量は「推定値 ÷ SE」
- 正規誤差項仮定下:CI = 推定値 ± 1.96·SE(95%)
📖 もっと詳しく
標準誤差(Standard Error, SE)は「もし同じ調査を何度も繰り返したら、 推定値はどれくらいブレるか」を測る量です。 標準偏差(SD)と紛らわしいですが、 別物です。
SD vs SE:
- SD(標準偏差):データ自体の広がり。 47都道府県の死亡率がどれだけ違うか
- SE(標準誤差):統計量(平均値などの推定値)のブレ。 別のサンプル47県を取り直したら、 平均はどれくらい違うか
標本平均の SE は $\sigma/\sqrt{n}$ で計算され、 n が大きいほど小さくなります。 SD は n が変わっても変わりません(データの本質的な広がりだから)。
SE の用途:(i) 信頼区間 = 推定値 ± 1.96·SE、 (ii) t統計量 = 推定値 / SE、 (iii) Wald 検定の分母。 ほぼ全ての推測統計の中核です。
🎨 直感で掴む
📐 数式
🔬 数式を「言葉」で読み解く
- $\widehat{\mathrm{Var}}(\hat{\theta})$
- 推定量 $\hat{\theta}$ の分散の推定値
- $\sigma$
- 母標準偏差(不明なので標本標準偏差 s で代用)
- $n$
- サンプルサイズ
⚠️ よくある落とし穴
SE:平均値という統計量がどれだけブレるか
n が大きいと SE は 0 に近づくが、 SD はそうではない。 グラフで誤差棒を出すときも、 SD と SE のどちらかを明示すべき。
cov_type='HC1')を使うのが安全。👁️ 直感 — 標準誤差は「標本平均のばらつき」
標準誤差(standard error, SE)は、 「同じ母集団から何度も標本を取り、 標本平均を計算したときのばらつき」を表します。
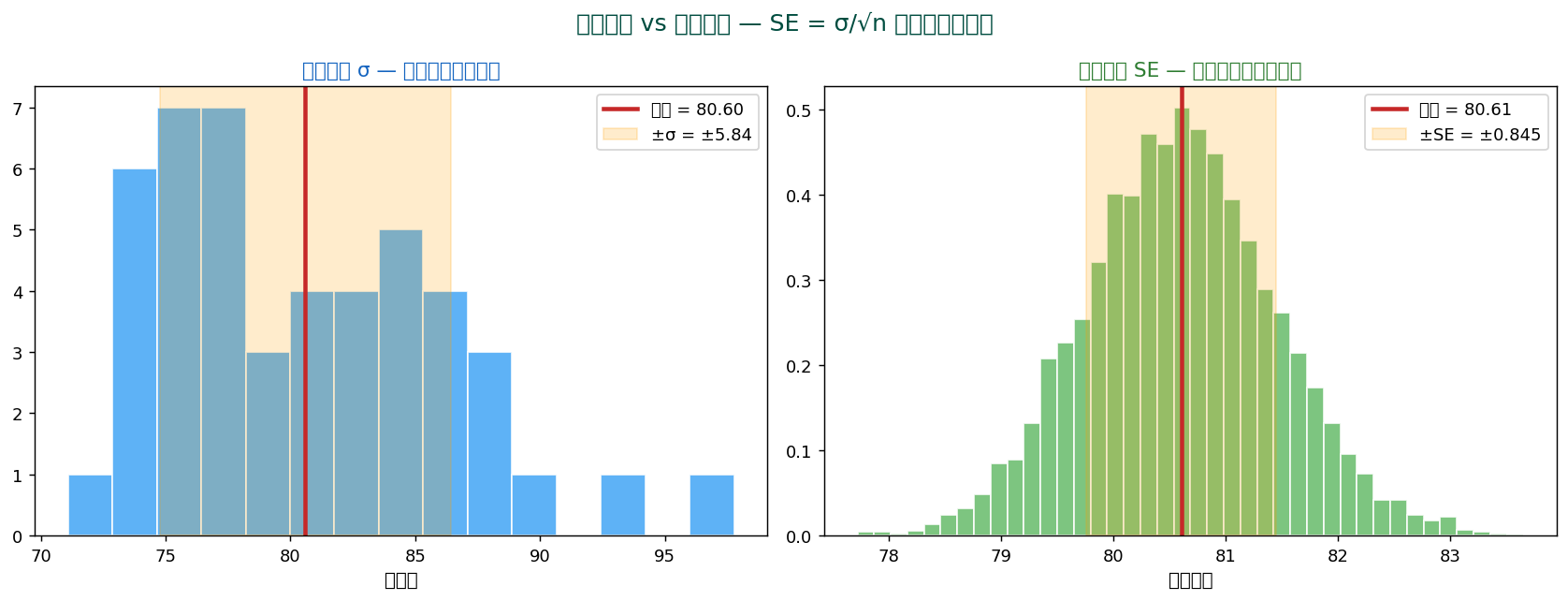
左:データそのもののばらつき(標準偏差 σ)。
右:標本平均のばらつき(標準誤差 SE)— ずっと小さい。
💡 SE と SD は別物。 SD は「データ1個のばらつき」、 SE は「平均のばらつき」。 SE は SD より√n 倍小さい。
📐 標準誤差の数式
標本平均の標準誤差
$$ SE_{\bar{x}} = \frac{\sigma}{\sqrt{n}} \approx \frac{s}{\sqrt{n}} $$
- σ:母標準偏差(未知)
- s:標本標準偏差(σ の推定値)
- n:標本サイズ
- √n:標本サイズの平方根 — n が4倍になれば SE は半分
SSDSE 食料費の例
- n = 47
- s = 5.842 千円
- SE = s/√n = 5.842/√47 = 0.8521 千円
「47都道府県データから推定した母平均は、 ±0.852千円程度のばらつきで信頼できる」と読めます。
🎯 なぜ √n で割るのか?
中心極限定理(CLT)から、 標本平均の分散は σ²/n に等しい:
$$ \text{Var}(\bar{X}) = \frac{\sigma^2}{n} \Rightarrow SE = \sqrt{\text{Var}(\bar{X})} = \frac{\sigma}{\sqrt{n}} $$
実用的含意
- n = 100 → SE = σ / 10
- n = 400 → SE = σ / 20(n を4倍にして SE が半分)
- n = 10000 → SE = σ / 100(精度100倍にしたければ n は10000倍必要)
💡 「精度を上げるには標本を大きくしろ」が常識だが、 √n でしか改善しないため、 巨大なコスト増加。 設計時に SE の目標値とサンプルサイズを慎重に決めるべき。
📚 様々な統計量の標準誤差
| 統計量 | 標準誤差の公式 |
|---|---|
| 標本平均 | σ/√n |
| 比率 | √(p(1-p)/n) |
| 2標本の平均差 | √(σ₁²/n₁ + σ₂²/n₂) |
| 回帰係数 | σ_ε / (√n × σ_x) |
| 相関係数 | √((1-r²)/(n-2)) |
| 分散 | σ² √(2/(n-1)) |
🐍 Python での標準誤差
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | import numpy as np from scipy import stats # 標本平均のSE data = np.array([45, 50, 55, 60, 65]) se = stats.sem(data) # scipy のヘルパー se_manual = data.std(ddof=1) / np.sqrt(len(data)) print(f'SE = {se:.4f}') # 比率のSE p_hat = 30 / 100 # 成功割合 n = 100 se_prop = np.sqrt(p_hat * (1 - p_hat) / n) # 回帰係数のSE(statsmodels) import statsmodels.api as sm X = sm.add_constant(x) model = sm.OLS(y, X).fit() print(model.bse) # 各係数のSE |
🤖 機械学習での標準誤差
① 回帰係数のSE
線形回帰でも、 各係数 β_j の標準誤差が計算されます。 これを使って t統計量と p値が出ます:
$$ t_j = \frac{\hat{\beta}_j}{SE(\hat{\beta}_j)} $$
② アンサンブルの予測SE
ランダムフォレストでは、 N本の木の予測の標準偏差が予測の不確実性(SE)として使えます。
③ ブートストラップによるSE
任意のモデルで、 ブートストラップサンプルから繰り返し学習・予測し、 その分散から SE を推定。
🚧 SE の落とし穴
1️⃣ SD と SE を混同しない
SD はデータの散らばり、 SE は推定値のばらつき。 グラフのエラーバーが SD か SE かは必ず明記。
2️⃣ サンプリングが独立か
σ/√n は独立同分布のサンプリングを前提。 時系列、 クラスター内データでは違う SE 公式が必要。
3️⃣ 小標本ではSEも不安定
n=5〜10 では、 s 自体がぶれるため SE もぶれます。 ブートストラップでより堅実な推定を。
📜 標準誤差の歴史
- Gauss(1809):天体観測の精度を 1/√n で改善する公式を確立
- Gosset (Student, 1908):少標本での SE と t分布を発見
- Fisher(1925):標準誤差を統計推論の中核に
- Efron(1979):ブートストラップで分布の仮定を不要に
✅ 実務チェックリスト — 推測統計を使う前に
1. データの確認
- サンプルサイズ n は十分か?(n < 30 なら t分布、 非正規性に注意)
- 独立同分布の仮定は妥当か?(時系列、 クラスター構造に注意)
- 外れ値の影響を確認したか?(box plot で)
- 正規性は確認したか?(QQプロット、 Shapiro-Wilk検定)
- 欠損値の扱いは適切か?
2. 検定・推定の設計
- 仮説(H₀、 H₁)は事前に定義したか?
- 片側 vs 両側を選択しているか?
- 有意水準 α は事前に設定したか?
- 多重比較の補正は必要か?
- サンプルサイズの事前計算(power analysis)したか?
3. 結果の報告
- 点推定 + 信頼区間を併記しているか?
- p値だけでなく効果量も報告したか?
- サンプルサイズを明記したか?
- 仮定の確認結果を述べたか?
- 「統計的有意 = 実質的に重要」と混同していないか?
4. 解釈の注意
- 「相関 ≠ 因果」を意識
- シンプソンのパラドックスを警戒
- 探索的分析と確認的分析を区別
- 結果を再現できるか
📚 推測統計を学ぶための重要文献
- Fisher (1925) "Statistical Methods for Research Workers" — 古典中の古典
- Neyman & Pearson (1933) — 仮説検定の理論的基礎
- Cohen (1988) "Statistical Power Analysis" — 効果量とサンプルサイズの教科書
- ASA Statement (2016) — p値の正しい使い方
- Gelman & Hill (2007) "Data Analysis Using Regression and Multilevel/Hierarchical Models"
- Wasserman (2004) "All of Statistics" — 現代統計学の総括
🆚 推測統計の主要用語 — 一目で分かる対比表
| 用語 | 記号 | 何を測る? | 公式 |
|---|---|---|---|
| 標準偏差 | σ, s | データ1個のばらつき | √(Σ(x-x̄)²/(n-1)) |
| 標準誤差 | SE | 推定値のばらつき | σ/√n |
| 信頼区間 | CI | 真値の入る範囲 | x̄ ± z·SE |
| p値 | p | 偶然この結果が出る確率 | P(|T| ≥ |t_obs| | H₀) |
| 有意水準 | α | Type I 誤り許容率 | 通常 0.05 |
| 検出力 | 1-β | 真の差を検出する確率 | 1 - Pr(Type II error) |
| 効果量 | d, r, R² | 差の大きさ | Cohen's d = (μ₁-μ₂)/σ |
| サンプルサイズ | n | 標本数 | power analysisで決定 |
🎲 ブートストラップで SE を計算
分布の仮定なしで SE を推定する強力な方法。 任意の統計量(中央値、 四分位、 機械学習の予測など)に適用可能:
1 2 3 4 5 6 7 8 9 10 11 12 13 | import numpy as np def bootstrap_se(data, statistic=np.mean, n_bootstrap=1000): n = len(data) boot_stats = [] for _ in range(n_bootstrap): sample = np.random.choice(data, size=n, replace=True) boot_stats.append(statistic(sample)) return np.std(boot_stats, ddof=1) se_mean = bootstrap_se(data, np.mean) se_median = bootstrap_se(data, np.median) # 中央値のSEも! se_q90 = bootstrap_se(data, lambda x: np.percentile(x, 90)) |
scipy のブートストラップ機能
1 2 3 4 | from scipy.stats import bootstrap result = bootstrap((data,), np.mean, n_resamples=10000, confidence_level=0.95) print(f'SE: {result.standard_error:.4f}') print(f'95%CI: {result.confidence_interval}') |
📐 クラスター・階層構造での SE
独立性が崩れる場合、 通常の σ/√n では SE を過小評価。 例:
- 同じ学校の生徒は似ている → クラスタリング
- 同じ家族の人は似ている → 家族効果
- 同じ都市の住民は似ている → 地域効果
クラスター ロバスト標準誤差(CR-SE)や混合効果モデルで対処。
1 2 3 4 5 | import statsmodels.api as sm # クラスター ロバストSE model = sm.OLS(y, X).fit(cov_type='cluster', cov_kwds={'groups': cluster_id}) print(model.bse) # クラスター調整後のSE |
🗺️ 概念マップ — 3つの視点で体系を理解する
標準誤差 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 推測統計 › 推定 › 標準誤差
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「標準誤差」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「標準誤差」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引 — 拡張版
標準誤差(standard error, SE)に関する用語を、 標本統計量別・推定法・関連概念 別に索引化します。
| カテゴリ | キーワード(日本語) | キーワード(英語) |
|---|---|---|
| 基本概念 | 標準誤差、 標準偏差、 標本分布、 推定量の精度 | standard error, sampling distribution, precision |
| 標本統計量別 SE | 平均のSE、 比率のSE、 回帰係数のSE、 差のSE | SE of mean, proportion, regression coef |
| 推定法 | 解析的SE、 ブートストラップ、 ジャックナイフ、 デルタ法 | analytical SE, bootstrap, jackknife, delta method |
| 頑健な SE | ロバスト標準誤差、 クラスター頑健、 ニューウェイ-ウェスト | robust SE, HC0-HC3, cluster, Newey-West |
| 関連指標 | 信頼区間、 t統計量、 z統計量、 p値、 検出力 | CI, t/z statistic, p-value, power |
| 実装 | scipy.stats.sem、 statsmodels、 pingouin、 bootstrap | scipy.stats.sem, statsmodels, pingouin, bootstrap |
🧮 SSDSE-B での標準誤差 — 実値計算例
SSDSE-B から「47都道府県の平均所得」を1つの標本とみなし、 母平均の標準誤差を計算します。
① 基本統計量
| 統計量 | 値 | 説明 |
|---|---|---|
| n | 47 | 標本サイズ |
| x̄ | 304 万円 | 標本平均 |
| SD | 59 万円 | 標本標準偏差 |
| SE = SD/√n | 59/√47 ≈ 8.6 万円 | 平均の標準誤差 |
② 95%信頼区間
自由度 df = n − 1 = 46、 t₀.₀₂₅,₄₆ ≈ 2.013
CI = x̄ ± t · SE = 304 ± 2.013 × 8.6 = (286.7, 321.3)
母平均は95%の確率で この区間に含まれると解釈。
③ サンプルサイズと SE の関係
| n | SE | 95% CI 幅 |
|---|---|---|
| 10 | 18.7 | ±37.4 |
| 47 | 8.6 | ±17.3 |
| 100 | 5.9 | ±11.8 |
| 1000 | 1.87 | ±3.74 |
💡 n を4倍にしないと SE は半分にならない(SE は √n に反比例)。 精度を上げるコストは 非線形に増大 する。
⚠️ 標準誤差の落とし穴 — 拡張版(実務で本当に困る5+件)
- 標準偏差(SD)と標準誤差(SE)の混同:SD はデータのばらつきを表し、 標本サイズに依存しない。 SE は推定量(多くは標本平均)のばらつきを表し、 標本サイズが大きくなるほど小さくなる。 論文の表で「Mean ± SD」と「Mean ± SE」を混同すると、 ばらつきの見え方が10倍以上違うことも。 グラフのエラーバーがどちらかを必ず明記する。
- 独立性を満たさないデータでの誤計算:クラスター化されたデータ(同一学校の生徒、 同一地域の都市、 同一被験者からの繰り返し測定)に通常の SE 公式を使うと、 SE が 過小評価 される。 クラスター頑健標準誤差や階層モデルが必要。 ICC(クラス内相関)が0でない場合は標準のSEは信用できない。
- 不均一分散下での誤った推定:回帰係数の SE は誤差分散が一定(等分散)を仮定。 不均一分散(heteroscedasticity)があると SE が偏って計算される。 ロバスト標準誤差(HC0、 HC1、 HC2、 HC3)に切り替えるか、 加重最小二乗法(WLS)を使う。 statsmodels では cov_type='HC3' で指定。
- 時系列データでの自己相関無視:時系列で SE を計算する際、 残差の自己相関を無視すると過小評価される。 Newey-West 標準誤差や HAC(Heteroskedasticity and Autocorrelation Consistent)標準誤差を使う。 株価リターンや GDP データではほぼ必須の補正。
- 小標本での t 分布の自由度誤り:n が小さいとき正規近似ではなく t 分布を使うべき。 信頼区間の幅は自由度に依存。 自由度を計算ミスすると SE 自体は正しくても CI が不正確になる。 Welch の t 検定では Satterthwaite の自由度近似が必要。
- ブートストラップの誤用:時系列や階層データに通常のブートストラップを適用すると、 構造を壊して SE が誤って小さく出る。 ブロックブートストラップ、 階層ブートストラップなど構造に応じた方法を使う。
- SE を「真の値からの距離」と勘違い:SE は 推定値が標本ごとにどれだけ変動するか を表すもので、 「真の値から x ± SE の範囲にある」とは厳密には言えない。 95% CI を計算してこそ意味がある。 「推定値±SE」だけでは34%(≈ ±1σ)程度の信頼度しかない。
🐍 Python 実装バリエーション — scipy / statsmodels / pingouin / bootstrap
① scipy.stats.sem(最も簡単)
1 2 3 4 5 6 7 8 9 10 11 12 13 | import pandas as pd from scipy.stats import sem, t df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) x = df['平均所得'] se = sem(x) # ddof=1 がデフォルト print(f'SE = {se:.3f}') # 95% 信頼区間 n = len(x) ci_half = t.ppf(0.975, df=n-1) * se print(f'95% CI: ({x.mean()-ci_half:.2f}, {x.mean()+ci_half:.2f})') |
② numpy で手動計算(教育目的)
1 2 3 4 5 6 7 8 9 10 | import numpy as np import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) x = df['平均所得'].to_numpy() n = len(x) sd = x.std(ddof=1) # 標本SD se = sd / np.sqrt(n) print(f'SD={sd:.2f}, n={n}, SE={se:.3f}') |
③ statsmodels(回帰係数のSE)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | import statsmodels.api as sm import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) X = sm.add_constant(df[['教育支出']]) y = df['平均所得'] # 通常のSE ols = sm.OLS(y, X).fit() print(ols.bse) # 係数のSE # ロバストSE(HC3) robust = sm.OLS(y, X).fit(cov_type='HC3') print('HC3:', robust.bse) # クラスター頑健SE cluster = sm.OLS(y, X).fit(cov_type='cluster', cov_kwds={'groups': df['地域']}) print('cluster:', cluster.bse) |
④ ブートストラップ標準誤差
1 2 3 4 5 6 7 8 9 10 11 | from scipy.stats import bootstrap import numpy as np import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) x = df['平均所得'].to_numpy() res = bootstrap((x,), np.mean, n_resamples=10000, confidence_level=0.95, random_state=0) print(f'ブートストラップSE: {res.standard_error:.3f}') print(f'CI: {res.confidence_interval}') |
⑤ pingouin(効果量・CI付き)
1 2 3 4 | import pingouin as pg res = pg.compute_bootci(x, func='mean', n_boot=10000, confidence=0.95, seed=0) print(f'95% CI (bootstrap): {res}') |
⑥ エラーバー付きプロット
1 2 3 4 5 6 7 | import seaborn as sns import matplotlib.pyplot as plt # 群ごとの平均±SE をプロット sns.barplot(data=df, x='地域', y='平均所得', estimator='mean', errorbar=('ci', 95)) # 自動で SE→CI plt.show() |