📍 あなたが今見ているもの
論文中に 「標準偏差」として登場する用語。
標準偏差 とは:「平均からのズレ」の典型的な大きさ。分散の平方根。データの広がりを元の単位で表す。
💡 30秒で分かる結論
- 定義:「平均からのズレ」の典型的な大きさ。分散の平方根。データの広がりを元の単位で表す。
- カテゴリ:記述統計
📖 もっと詳しく
標準偏差(standard deviation, SD, σ)は、 分散の平方根。 「平均からの典型的なズレの大きさ」を、 元の単位で表します。 「日本の年間気温の標準偏差は 4℃」のように直感的に使えるのが強み。
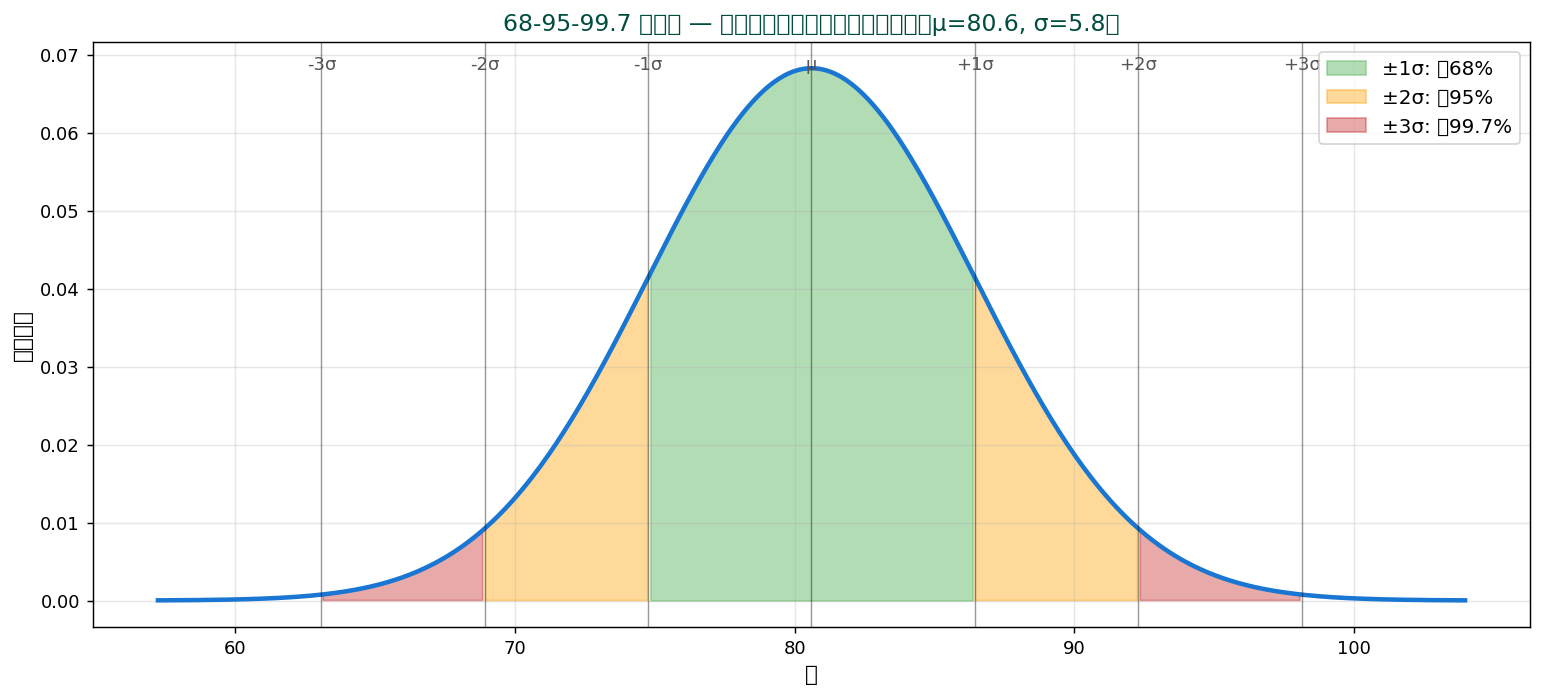
正規分布での 68-95-99.7則:データが正規分布に従うなら、
- ±1σ 内に約 68% のデータ
- ±2σ 内に約 95%
- ±3σ 内に約 99.7%
これがあるおかげで「2σ より外」は珍しい、 「3σ より外」は超レアと判定できます。 統計的品質管理や外れ値検出の基礎。
標準化(z-score):(値 − 平均) / SD で z値を計算すると、 単位を持たない「平均からの SD 単位での距離」になります。 単位の違う変数の比較・統合に必須の操作。
🎨 直感で掴む — 標準偏差は「ばらつきを元の単位で表したもの」
標準偏差(standard deviation, σ)は分散の平方根。 分散は「単位の二乗」になってしまうので解釈が難しい。 平方根を取って元の単位に戻したものが標準偏差。
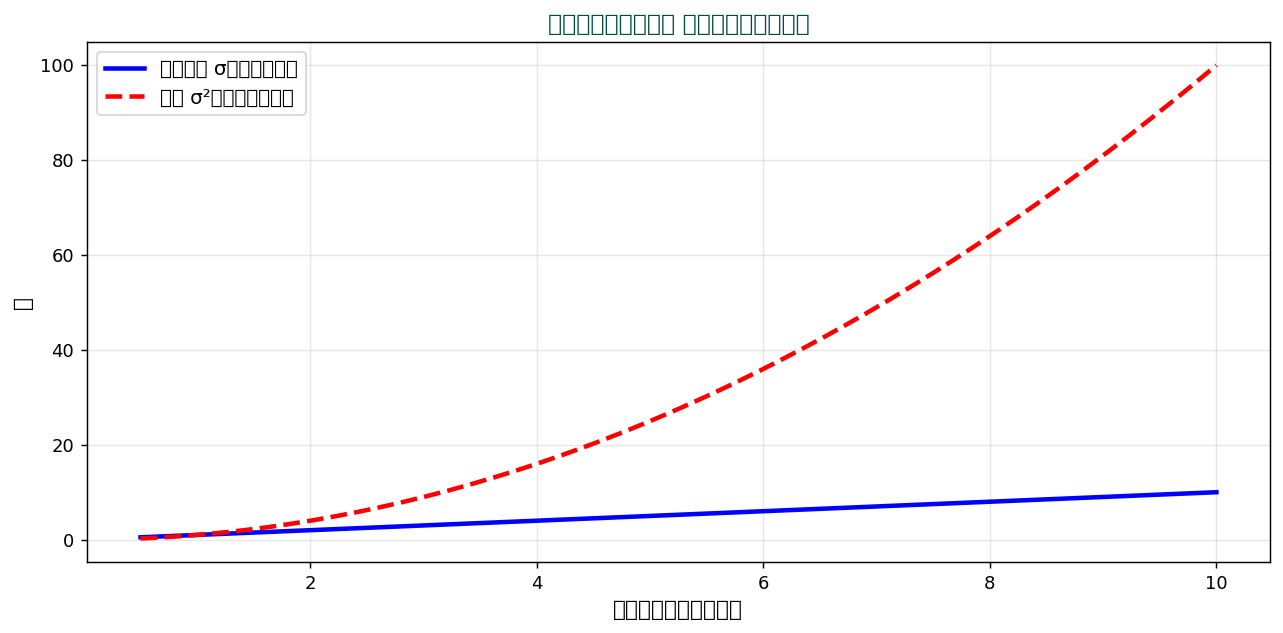
💡 例えば食料費の分散が「8.09 千円²」と言われても直感的でない。 標準偏差「2.84 千円」と言えば、 「平均から±2.84千円くらい散らばっている」とすぐ分かる。
SSDSE 食料費での値
- 47都道府県の食料費の平均: 80.60 千円
- 標準偏差: 5.84 千円
- 「典型的な都道府県は、 平均から±5.8千円の範囲」と読める
🧮 計算ステップ
標準偏差の計算手順
- 平均 x̄ を計算
- 各データの偏差 (xᵢ - x̄) を計算
- 偏差の二乗を計算 (xᵢ - x̄)²
- 合計 Σ (xᵢ - x̄)²
- n(または n-1)で割って分散 σ²
- 分散の平方根を取って標準偏差 σ = √σ²
📐 数式
$$ \sigma = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})^2} $$
または不偏推定として:
$$ s = \sqrt{\frac{1}{n - 1} \sum_{i=1}^{n} (x_i - \bar{x})^2} $$
記号の読み方
| 記号 | 読み方 | 意味 |
|---|---|---|
| σ | シグマ(小文字) | 母標準偏差 |
| s | エス | 標本標準偏差 |
| √ | ルート/平方根 | 2乗してその値になる数 |
📊 68-95-99.7ルール — 標準偏差の魔法
データが正規分布に従うとき、 標準偏差にはとても便利な性質があります:
| 範囲 | 含まれる確率 | 直感的な意味 |
|---|---|---|
| μ ± 1σ | 約 68% | 「典型的」な範囲 |
| μ ± 2σ | 約 95% | 「ほぼ全て」の範囲 |
| μ ± 3σ | 約 99.7% | 「ほぼ確実」、 外側は外れ値候補 |
実用例
- 品質管理:±3σ を超える製品は「不良」と判定(シックスシグマの基本)
- 外れ値検出:z = (x - μ)/σ > 3 を外れ値候補とする
- 信頼区間:標本平均 ± 1.96 × SE で95%信頼区間
- 異常検知:センサーデータが ±2σ を超えたらアラート
🎯 標準化 (z-score) — 異なる単位を比較可能に
異なる単位の変数(身長 cm と体重 kg)を直接比較できません。 そこで「平均からのズレを標準偏差で割る」のが標準化。
$$ z = \frac{x - \mu}{\sigma} $$
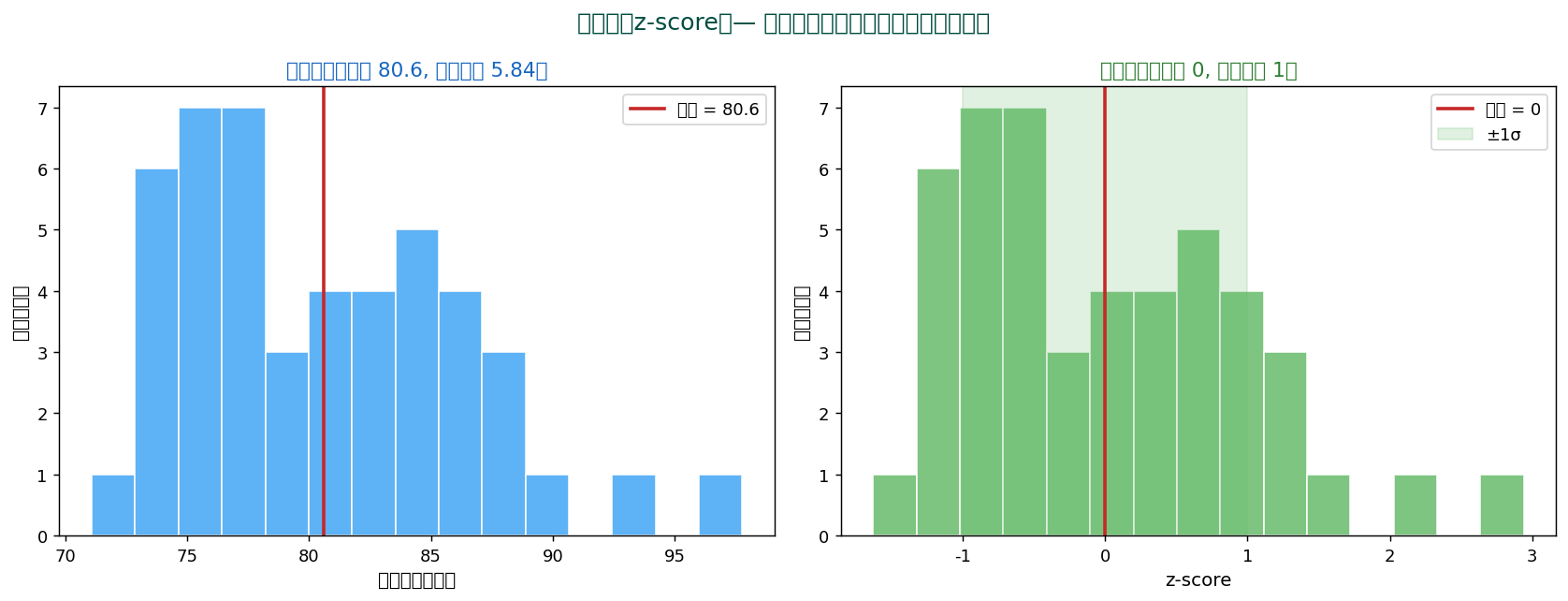
標準化されたデータは平均0、 標準偏差1になり、 「平均から何σ離れているか」を表す無次元の数値になります。
標準化の意味
- z = 0:平均と同じ
- z = 1:平均から1標準偏差上(上位16%)
- z = -1:平均から1標準偏差下(下位16%)
- z = 2:上位2.5%(極端に大きい)
- z = -3:下位0.15%(外れ値候補)
偏差値との関係
日本の試験で使う偏差値は、 z-score を変形したもの:
$$ T = 50 + 10z $$
- 偏差値 50 = 平均
- 偏差値 60 = z=1(上位16%)
- 偏差値 70 = z=2(上位2.5%)
- 偏差値 80 = z=3(上位0.13%)
📏 変動係数 (CV) — 相対的なばらつき
標準偏差は絶対的なばらつきを表しますが、 「身長の SD = 10cm」と「給料の SD = 10万円」を比較できません。 そこで変動係数(coefficient of variation, CV):
$$ CV = \frac{\sigma}{\mu} \times 100 \% $$
標準偏差を平均で割った無次元の量。 「平均に対する何%のばらつき」を表します。 単位の異なる変数同士を比較できる便利な指標。
使い時
- 異なる単位の変数のばらつきを比較
- 異なるスケールの製品の品質バラツキを比較
- 投資のリスクとリターンを比較(シャープレシオの逆数的)
💡 SSDSE 食料費の場合: CV = 5.84 / 80.60 = 7.2%。 「都道府県間の食料費のばらつきは平均の約7%」。
🎲 標準偏差はバイアスを持つ — 知らない人が多い事実
不偏分散 s² の期待値は母分散 σ² に等しい(E[s²] = σ²)が、 √s² の期待値は σ に等しくないのです。 これは Jensen の不等式に起因します:
$$ \mathbb{E}[\sqrt{s^2}] \le \sqrt{\mathbb{E}[s^2]} = \sigma $$
つまり s は σ を過小評価する傾向があります。 正規分布の場合の補正係数 c₄ を使えば不偏標準偏差を得られますが、 実務では補正なしの s を使うのが普通(差は通常小さい)。
補正公式(正規分布の場合)
$$ s_{\text{unbiased}} = \frac{s}{c_4(n)}, \quad c_4(n) = \sqrt{\frac{2}{n-1}} \cdot \frac{\Gamma(n/2)}{\Gamma((n-1)/2)} $$
例:n=10 では c₄ ≈ 0.9727、 n=30 では c₄ ≈ 0.9914。 n が大きければ補正不要。
🤖 機械学習での標準偏差
① StandardScaler(特徴量の標準化)
多くの機械学習アルゴリズムは入力スケールに敏感(kNN, SVM, ニューラルネット, PCA, 線形回帰)。 標準化は前処理の必須技術:
1 2 3 4 5 6 7 | from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # 同じスケーリングをテストにも # scaler.mean_ と scaler.scale_ に平均と標準偏差が記録される |
② Batch Normalization
深層学習の各層の出力を標準化する技術。 各ミニバッチで平均と標準偏差を計算して使用。
③ 重みの初期化
ニューラルネットの重み初期化(Xavier, He など)は、 標準偏差の精密な制御に基づきます:
$$ W \sim N\left(0, \sigma^2 = \frac{2}{n_{\text{in}}}\right) \quad (\text{He初期化}) $$
④ 不確実性推定
予測値だけでなく、 予測の標準偏差も出すモデル(ガウス過程、 ベイジアンNN)。 「±σ の予測区間」で意思決定の信頼性を示せます。
⑤ Dropout の解釈
Dropoutは「ノード出力に乗法的ノイズを加える」操作で、 これは標準偏差ベースの正則化と数学的に等価です。
🐍 Python での計算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | import numpy as np import pandas as pd # numpy のデフォルトは ÷n arr = np.array([10, 20, 30, 40, 50]) print(np.std(arr)) # ÷n: 14.14 print(np.std(arr, ddof=1)) # ÷(n-1): 15.81 # pandas のデフォルトは ÷(n-1) s = pd.Series(arr) print(s.std()) # ÷(n-1): 15.81 print(s.std(ddof=0)) # ÷n: 14.14 # describe で要約 print(s.describe()) # 標準化(z-score) z = (s - s.mean()) / s.std() print(z) |
StandardScaler を手で書く
1 2 3 4 5 6 7 | def fit_transform(X): mu = X.mean(axis=0) sigma = X.std(axis=0, ddof=0) sigma[sigma == 0] = 1.0 # ゼロ除算回避 return (X - mu) / sigma, mu, sigma X_scaled, mu, sigma = fit_transform(X) |
変動係数の計算
1 2 3 4 5 | def coefficient_of_variation(x): return x.std() / x.mean() * 100 cv_food = coefficient_of_variation(df['食料費']) print(f'食料費の変動係数: {cv_food:.2f}%') |
🚧 標準偏差の落とし穴
1️⃣ 正規分布でないと68-95-99.7ルールは使えない
裾の長い分布(所得、 株価変動)では±2σの中に95%が入らない。 必ず分布の形を確認してから使う。
2️⃣ ÷n か ÷(n-1) か — ライブラリで違う
numpy のデフォルトと pandas のデフォルトが違う。 R のデフォルトは ÷(n-1)。 統一するには ddof を明示。
3️⃣ 外れ値の影響
標準偏差は分散の平方根なので、 外れ値で大きく動きます。 中央値ベースの MAD を併用しましょう。
4️⃣ 単位の異なる変数を比較できない
「身長のσ=10cm」と「体重のσ=10kg」は無関係。 比較には変動係数(CV)を使う。
5️⃣ サンプルサイズが小さい
n=5 程度では σ の推定値は大きくブレます。 χ²分布ベースの信頼区間を計算するか、 ブートストラップで確認。
6️⃣ z-score 標準化はテストデータにも fit してはいけない
機械学習で fit_transform(X_train) したら、 transform(X_test) で同じスケーリングをすること。 fit を分けないとデータリークになります。
📜 標準偏差の歴史
- Karl Pearson(1894):「standard deviation」という用語を初めて使用。 ガウスの誤差論を一般化
- Gosset("Student", 1908):少標本での標本標準偏差の分布を研究 → t分布の発見
- Fisher(1925):分散・標準偏差の自由度補正を体系化
- Shewhart(1924):±3σ 管理限界を品質管理に導入 → シックスシグマの源流
- Markowitz(1952):標準偏差をリスク指標として金融に応用 → 現代ポートフォリオ理論
🔬 数式を言葉で読み解く — マハラノビス距離・多変量での標準偏差
1変数の標準偏差を多変量に拡張したのがマハラノビス距離。 異常検知、 クラスタリング、 多変量正規分布で頻繁に登場。
$$ d_M(x) = \sqrt{(x - \mu)^T \Sigma^{-1} (x - \mu)} $$
- x:データ点(ベクトル)
- μ:平均ベクトル
- Σ:共分散行列
- Σ⁻¹:共分散行列の逆行列
1変数の場合 d_M = |x - μ|/σ = |z-score| に一致。 多変量では「相関構造を考慮した距離」になります。
使用例
- 多変量での異常検知(d_M > 閾値 で外れ値)
- クラスタリングの距離指標
- 判別分析(LDA, QDA)の決定境界
💰 金融での標準偏差 — リスク指標
金融工学では標準偏差を「ボラティリティ(volatility)」と呼び、 リスクの基本指標として使います。
① シャープレシオ
$$ \text{Sharpe Ratio} = \frac{\bar{r} - r_f}{\sigma_r} $$
リターンの平均をリスク(標準偏差)で割ったもの。 「1単位のリスク当たり、 どれだけのリターンか」を測定。 Markowitz の現代ポートフォリオ理論の中核。
② Value at Risk (VaR)
「ある期間内に最大いくら損する可能性があるか」を標準偏差ベースで計算:
$$ \text{VaR}_{95\%} = \mu - 1.65 \sigma $$
95%信頼度での最大損失額。 リスク管理の必須指標。
③ Black-Scholes モデル
オプション価格モデルの主要パラメータは原資産のボラティリティ σ。 σ が大きいほどオプション価値は高くなる(不確実性のプレミアム)。
🏭 品質管理での標準偏差 — シックスシグマ
製造業の品質管理では、 標準偏差が中心的役割を果たします。
管理図(control chart)
Shewhart の管理図では、 中心線(平均)と上下限(±3σ)を引き、 観測値がこの範囲外に出たら異常と判定:
- UCL(Upper Control Limit)= μ + 3σ
- LCL(Lower Control Limit)= μ - 3σ
シックスシグマ
「製造工程の許容範囲が ±6σ を超える」状態を目指す品質管理手法。 不良率は百万分の3.4 (3.4 ppm) という極めて厳しい基準。 モトローラ、 GE が実装して有名に。
Cp、 Cpk(工程能力指数)
$$ C_p = \frac{\text{USL} - \text{LSL}}{6\sigma} $$
仕様範囲(USL - LSL)を 6σ で割った指標。 Cp ≥ 1.33 で「合格水準」、 ≥ 2.0 でシックスシグマ水準。
📦 IQR との比較 — もう1つのばらつき指標
標準偏差以外にも、 ばらつきを測る指標があります:
| 指標 | 定義 | 外れ値耐性 | 使い時 |
|---|---|---|---|
| 標準偏差 σ | √(平均偏差の二乗) | 弱い | 正規分布、 一般的分析 |
| 範囲 (range) | max - min | 最弱 | 概観把握のみ |
| IQR (四分位範囲) | Q3 - Q1 | 強い | 歪んだ分布、 外れ値あり |
| MAD (中央絶対偏差) | median(|xᵢ - median|) | 最強 | ロバスト統計 |
正規分布の場合:σ ≈ IQR / 1.349 ≈ 1.4826 × MAD という換算式があります。
🗺️ 概念マップ — 3つの視点で体系を理解する
標準偏差 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 記述統計 › ばらつき › 標準偏差
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「標準偏差」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「標準偏差」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(拡張版 — 標準偏差)
分散・SD・標準化・68-95-99.7則・ロバスト代替を網羅。
🧮 SSDSE-B-2026 実値計算例 — 「平均所得」「人口」「高齢化率」の SD と CV
変数によって平均と標準偏差の関係(変動係数 CV)が大きく異なります。 単位を持たない CV で「相対的なばらつき」を比較しましょう。
| 変数 | 平均 | SD(ddof=1) | CV = SD/平均 | 解釈 |
|---|---|---|---|---|
| 平均所得 | ≈ 310 万円 | ≈ 35 万円 | ≈ 0.11 | 県間ばらつき小 |
| 総人口 | ≈ 270 万人 | ≈ 290 万人 | ≈ 1.07 | 巨大な格差 |
| 高齢化率 | ≈ 30 % | ≈ 3.5 pt | ≈ 0.12 | 所得と同程度 |
1 2 3 4 5 6 | import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8', skiprows=1) for c in ['平均所得', '総人口', '高齢化率']: x = df[c].dropna() print(f'{c}: 平均={x.mean():.1f}, SD={x.std(ddof=1):.1f}, ' f'CV={x.std(ddof=1)/x.mean():.3f}') |
⚠️ 落とし穴(補強版 — 標準偏差で踏みやすい7つの罠)
ddof=0(分母 n、 母集団の SD)、 pandas のデフォルトは ddof=1(分母 n−1、 標本の不偏 SD)です。 同じデータでも結果が違ってきます。 SSDSE-B(47 都道府県全数)なら母集団の SD(ddof=0)が論理的、 標本抽出データなら ddof=1 が標準。 「numpy と pandas で SD が違う」は ddof の違いがほぼ全てで、 明示的に ddof= を指定する習慣をつけると安全です。np.std を使うと過小評価になります。 加重 SD は statsmodels.stats.weightstats.DescrStatsW または numpy で重み付き分散を自前計算(np.cov に aweights)。 「47 都道府県の平均所得の SD」と「日本国民1人あたりの所得の SD」は別物、 という意識が重要。🐍 Python 実装バリエーション(numpy / pandas / scipy / statsmodels)
🅰️ numpy(デフォルト ddof=0)
1 2 3 4 5 | import numpy as np x = df['平均所得'].dropna().values print('SD (ddof=0):', np.std(x)) # 母集団 SD print('SD (ddof=1):', np.std(x, ddof=1)) # 標本 SD(不偏) print('Var (ddof=1):', np.var(x, ddof=1)) |
🅱️ pandas(デフォルト ddof=1)
1 2 3 | print(df['平均所得'].std()) # ddof=1 print(df['平均所得'].std(ddof=0)) # 母集団 SD print(df.describe().T[['mean', 'std']]) # 全変数 |
🅲 scipy.stats — z-score・SEM
1 2 3 4 5 | from scipy import stats z = stats.zscore(x) # z-score sem = stats.sem(x) # 標準誤差 (SD/√n) print('zscore[0:5]:', z[:5]) print('SEM:', sem) |
🅳 statsmodels — 加重 SD
1 2 3 4 5 | from statsmodels.stats.weightstats import DescrStatsW weights = df['総人口'].dropna() weighted = DescrStatsW(df['平均所得'].dropna().values, weights=weights.values) print('加重平均:', weighted.mean) print('加重 SD:', weighted.std) |
📦 「ばらつき」指標早見表
| 指標 | 単位 | ロバスト性 |
|---|---|---|
| 分散 σ² | 元単位の 2 乗 | 弱 |
| 標準偏差 σ | 元単位 | 弱 |
| SEM = σ/√n | 元単位 | 弱(平均の誤差) |
| 変動係数 CV | 無単位 | 弱 |
| IQR | 元単位 | 強 |
| MAD | 元単位 | 最強 |