📍 あなたが今見ているもの
論文や記事中に 「分散」「標準偏差」「共分散」「MAD」「範囲」 として登場する用語群です。 代表値(平均・中央値)が「中心の位置」を示すのに対し、 ばらつき指標は「そこからどれだけ散らばっているか」を示します。
代表値とばらつきはセットで初めて分布を要約できます(例:平均 $\bar{x}$ ± 標準偏差 $s$)。
🔖 キーワード索引
論文記事から各用語のリンクをクリックすると、 該当箇所が開きます:
💡 30秒で分かる結論
🗂️ 章俯瞰 — 5つのばらつき指標
| 指標 | 記号 | 式 | 単位 | 外れ値耐性 |
|---|---|---|---|---|
| 分散 | $\sigma^2$ | $\frac{1}{n}\sum(x_i-\bar{x})^2$ | 元の単位² | ❌ 弱い |
| 標準偏差 | $\sigma$ | $\sqrt{\sigma^2}$ | 元の単位 | ❌ 弱い |
| 共分散 | $\sigma_{xy}$ | $\frac{1}{n}\sum(x_i-\bar{x})(y_i-\bar{y})$ | X単位×Y単位 | ❌ 弱い |
| 範囲 | R | max - min | 元の単位 | ❌❌ 最弱 |
| MAD | MAD | $\mathrm{median}(|x_i - \tilde{x}|)$ | 元の単位 | ✅ 強い |
📐 分散(Variance, $\sigma^2$)
分散は、 データの散らばり具合を1つの数字で表す最も基本的な指標。 各データから平均までの距離(偏差)の2乗を平均したもの。 平均が「重心」だったのに対し、 分散は「重心からどれだけ離れているか」を測ります。
母分散の定義は
$$ \sigma^2 = \mathbb{E}[(X - \mu)^2] = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 $$
記号:$\sigma^2$ は「シグマの二乗」(母分散)、 $\mu$ は「ミュー」(母平均)、 $\mathbb{E}[\cdot]$ は「期待値」、 $(x_i - \mu)^2$ は「偏差の2乗」。
なぜ2乗するのか
偏差 $(x_i - \mu)$ を素朴に足すと、 正の偏差と負の偏差が打ち消し合って必ずゼロになります(これが「平均は重心」の意味)。 2乗すれば全て非負になり「散らばりの大きさ」を測れます。
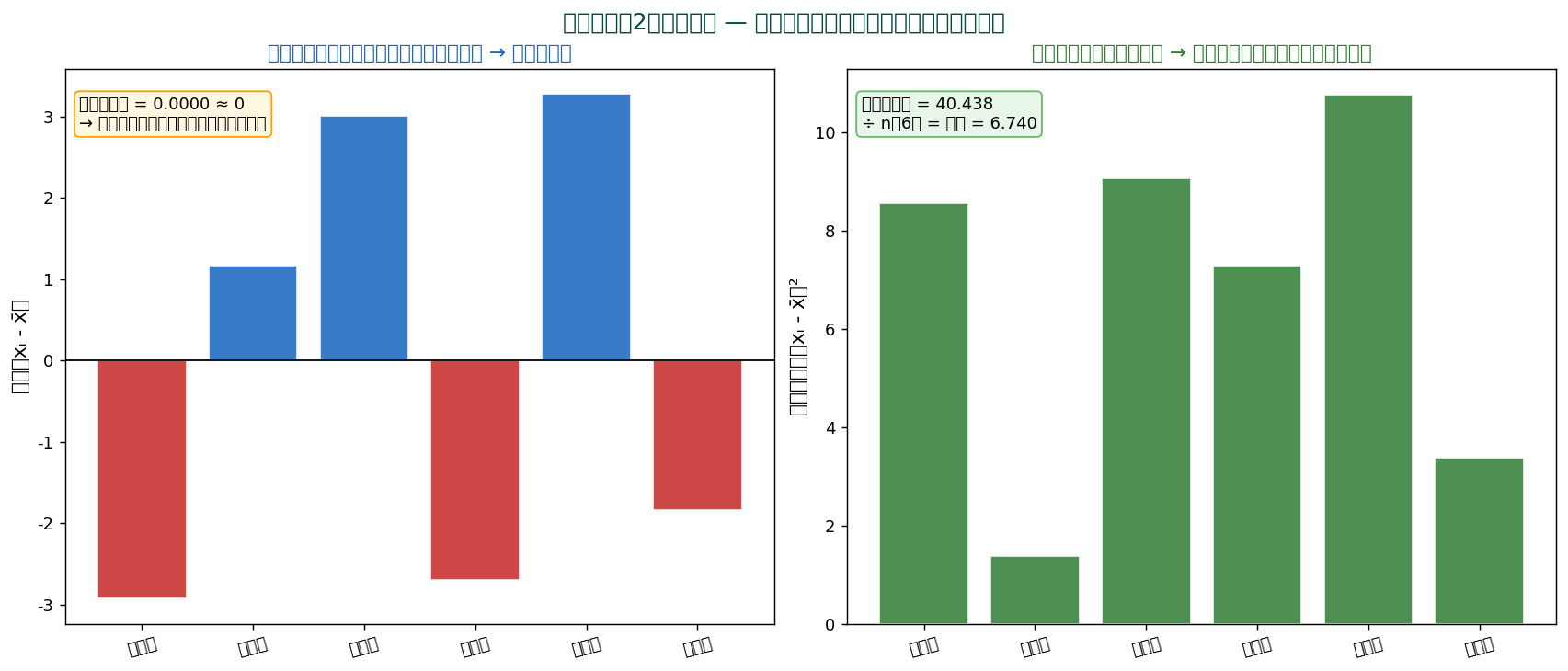
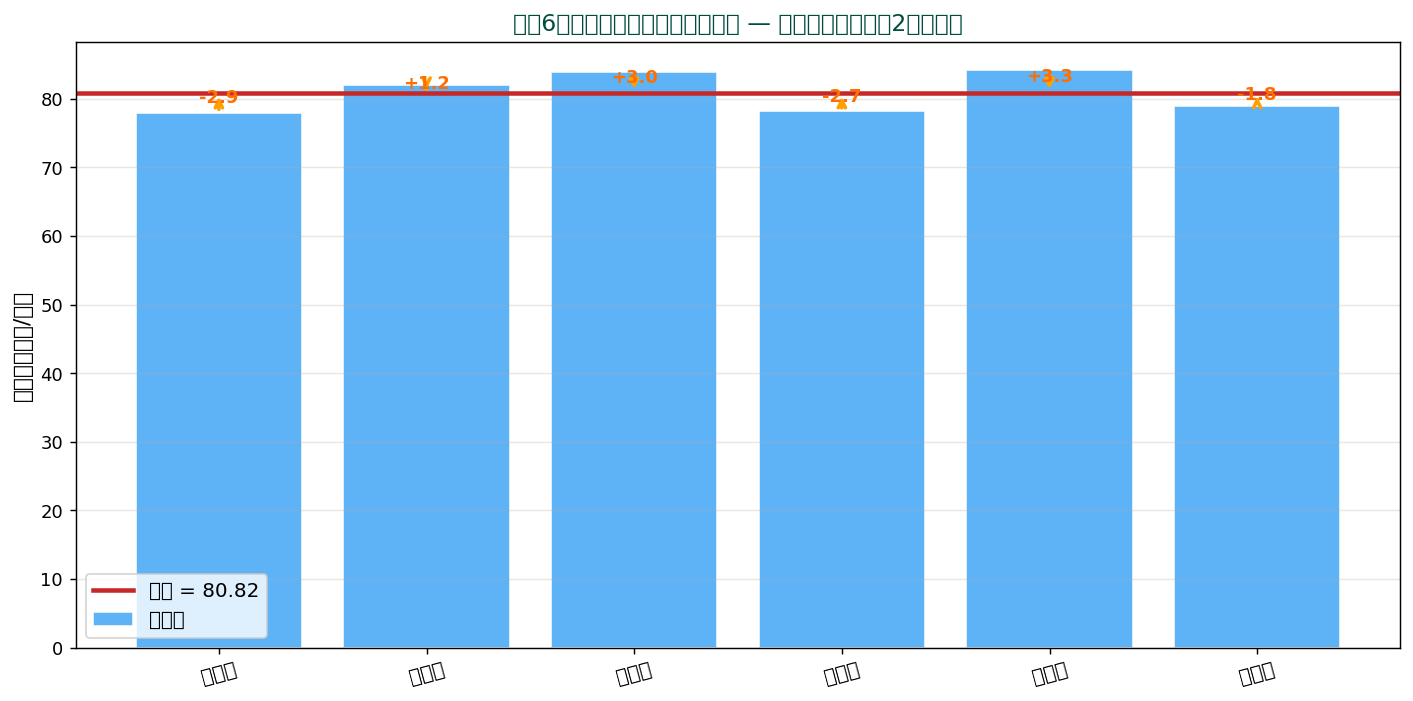
🧮 SSDSE 実値で計算 — 東北6県の食料費
| 都道府県 | $x_i$ | $x_i - \bar{x}$ | $(x_i - \bar{x})^2$ |
|---|---|---|---|
| 青森県 | 77.899 | -2.925 | 8.5556 |
| 岩手県 | 81.997 | +1.173 | 1.3759 |
| 宮城県 | 83.835 | +3.011 | 9.0661 |
| 秋田県 | 78.124 | -2.700 | 7.2900 |
| 山形県 | 84.105 | +3.281 | 10.7650 |
| 福島県 | 78.984 | -1.840 | 3.3856 |
| 合計 | ≈ 0 | 40.4382 |
平均 $\bar{x} = 80.824$、 $n = 6$。 標本分散(÷n)= $40.4382/6 = \mathbf{6.7397}$ (千円²)、 不偏分散(÷(n-1))= $40.4382/5 = \mathbf{8.0876}$ (千円²)。
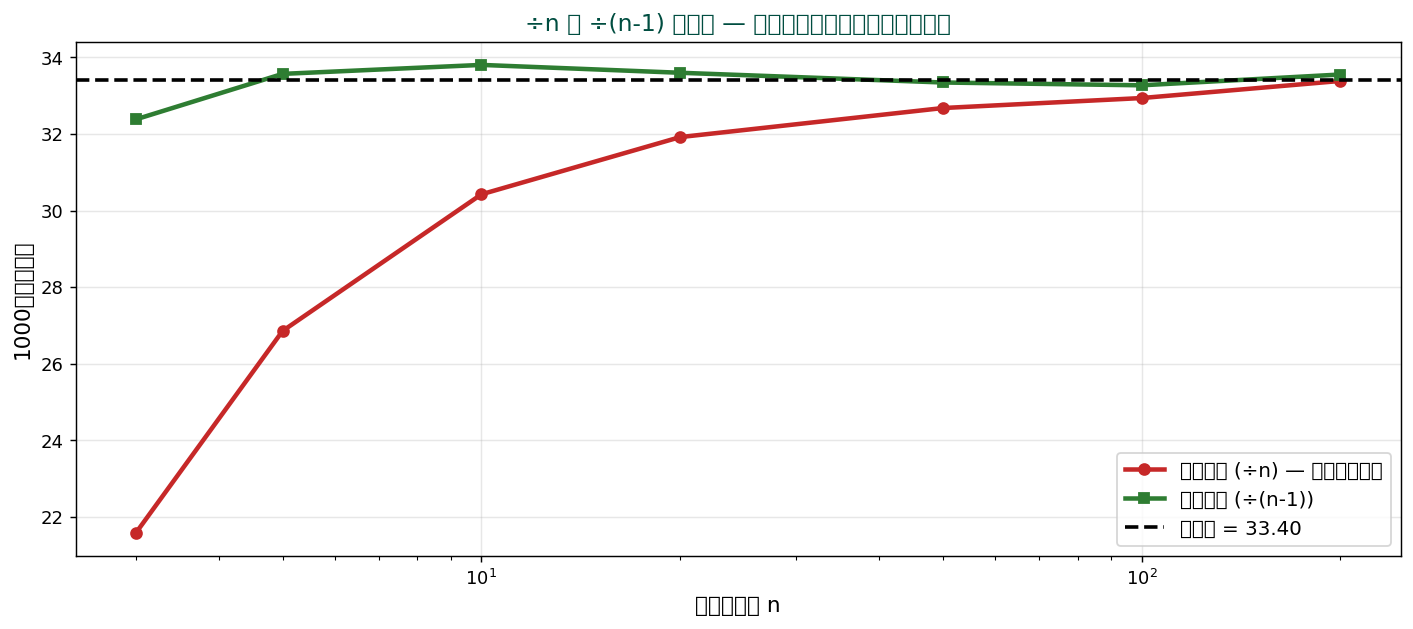
🎲 ÷n か ÷(n-1) か — Bessel 補正
「÷n」だと標本分散は母分散を過小評価します($\mathbb{E}[s_n^2] = \frac{n-1}{n}\sigma^2$)。 そこで $\frac{n}{n-1}$ を掛けて補正したものが不偏分散:
$$ s^2 = \frac{1}{n - 1} \sum_{i=1}^{n} (x_i - \bar{x})^2 $$
直感的説明:n 個のデータから $\bar{x}$ を計算した時点で、 偏差の合計がゼロになるという「1つの制約」が生じる。 残りの自由な情報は n − 1 個 → これが自由度。
🔢 ベクトル表記
$\boldsymbol{x} \in \mathbb{R}^n$ について、 中心化ベクトル $\tilde{\boldsymbol{x}} = \boldsymbol{x} - \bar{x}\mathbf{1}$ を使うと:
$$ s_n^2 = \frac{1}{n} \|\tilde{\boldsymbol{x}}\|^2 = \frac{1}{n} \tilde{\boldsymbol{x}}^\top \tilde{\boldsymbol{x}} $$
「中心化ベクトルのノルムの2乗 ÷ n」。 標準偏差はそのノルムを $\sqrt{n}$ で割ったもの。 多次元行列 $X \in \mathbb{R}^{n \times d}$ なら列ごとの分散ベクトル $\boldsymbol{s}^2 \in \mathbb{R}^d$、 これが共分散行列の対角成分に。
🐍 Python で確認
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | import numpy as np import pandas as pd x = np.array([78.124, 78.984, 81.997, 83.835, 84.105, 80.700]) # 標本分散(÷n)と不偏分散(÷(n-1)) print(np.var(x)) # 標本分散 (NumPy デフォルト) print(np.var(x, ddof=1)) # 不偏分散 # Pandas(÷(n-1) がデフォルト) s = pd.Series(x) print(s.var()) # 不偏 print(s.var(ddof=0)) # 標本 # 行列の列ごと分散 X = np.array([[1, 10], [3, 30], [5, 50], [7, 70], [9, 90]]) print(np.var(X, axis=0, ddof=1)) # [10.0, 1000.0] # ベクトル表記での確認 mean = x.mean() print(np.linalg.norm(x - mean) ** 2 / len(x)) # 標本分散と一致 |
📐 分散の重要な性質
- 定数の足し算:$\mathrm{Var}(X + c) = \mathrm{Var}(X)$(平行移動では変わらない)
- 定数倍:$\mathrm{Var}(aX) = a^2 \mathrm{Var}(X)$(2倍すると4倍に)
- 独立な変数の和:$\mathrm{Var}(X+Y) = \mathrm{Var}(X) + \mathrm{Var}(Y)$
- 一般の場合:$\mathrm{Var}(X+Y) = \mathrm{Var}(X) + \mathrm{Var}(Y) + 2\mathrm{Cov}(X,Y)$
- 標本平均の分散:$\mathrm{Var}(\bar{X}) = \sigma^2 / n$(サンプル増で減る)
📏 標準偏差(Standard Deviation, $\sigma$)
標準偏差は分散の平方根。 分散は単位が「元の単位の2乗」(食料費なら千円²)で解釈しにくいので、 平方根を取って元の単位に戻したものです。
$$ \sigma = \sqrt{\sigma^2} = \sqrt{\frac{1}{N} \sum (x_i - \mu)^2} $$
東北6県の食料費の例では、 標本標準偏差 $s_n = \sqrt{6.7397} ≈ 2.596$ 千円、 不偏標準偏差 $s = \sqrt{8.0876} ≈ 2.844$ 千円。 「東北6県の食料費は平均 80.8 千円から平均的に ±2.8 千円ずれる」と解釈できます。
📊 68-95-99.7 ルール — 正規分布での意味
データが正規分布に従うとき、 標準偏差で「データが含まれる範囲」を予測できます:
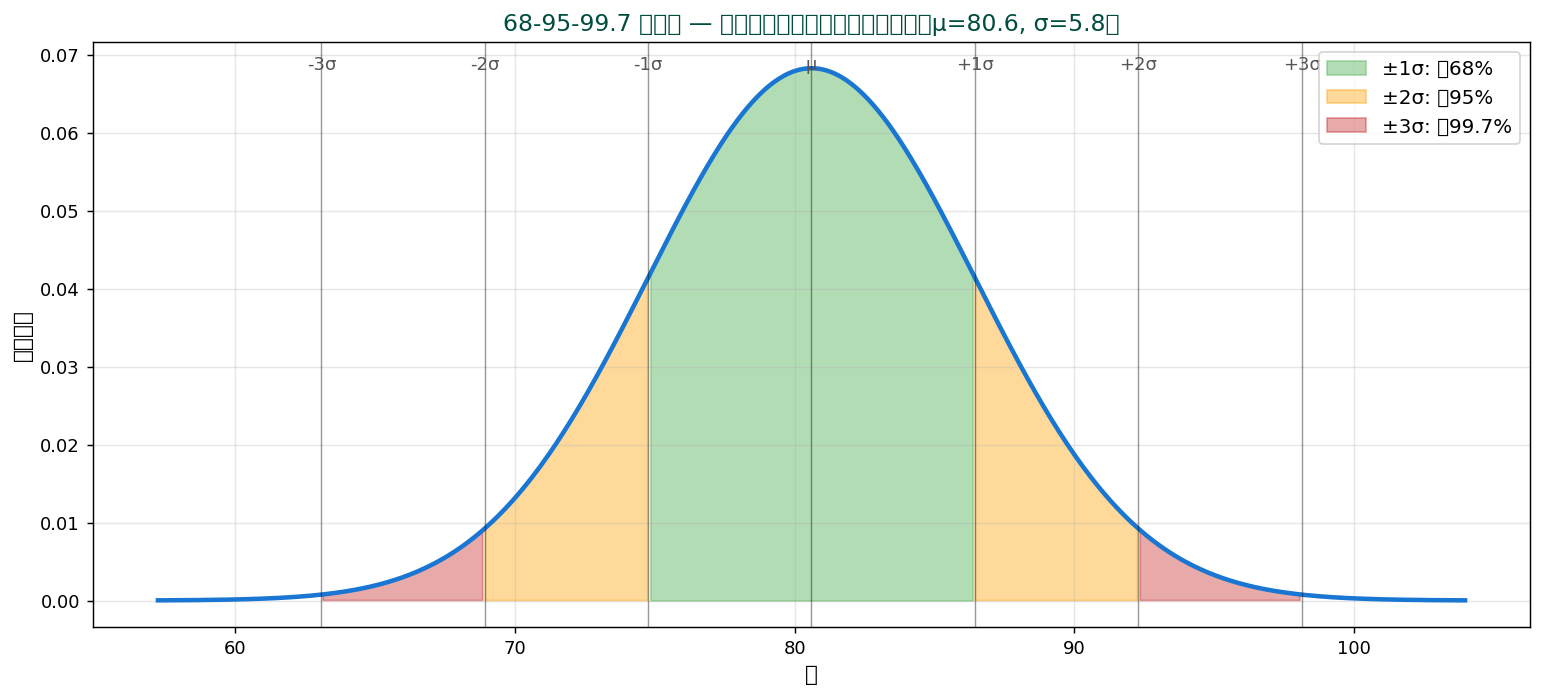
- $\mu \pm 1\sigma$ — 約 68% のデータが含まれる
- $\mu \pm 2\sigma$ — 約 95%(厳密には $\pm 1.96\sigma$)
- $\mu \pm 3\sigma$ — 約 99.7%(外側は外れ値候補)
これは「品質管理」「異常検知」「信頼区間」の基礎。 シックスシグマ品質管理の $\pm 6\sigma$ は 99.9999998% カバレッジを意味します。
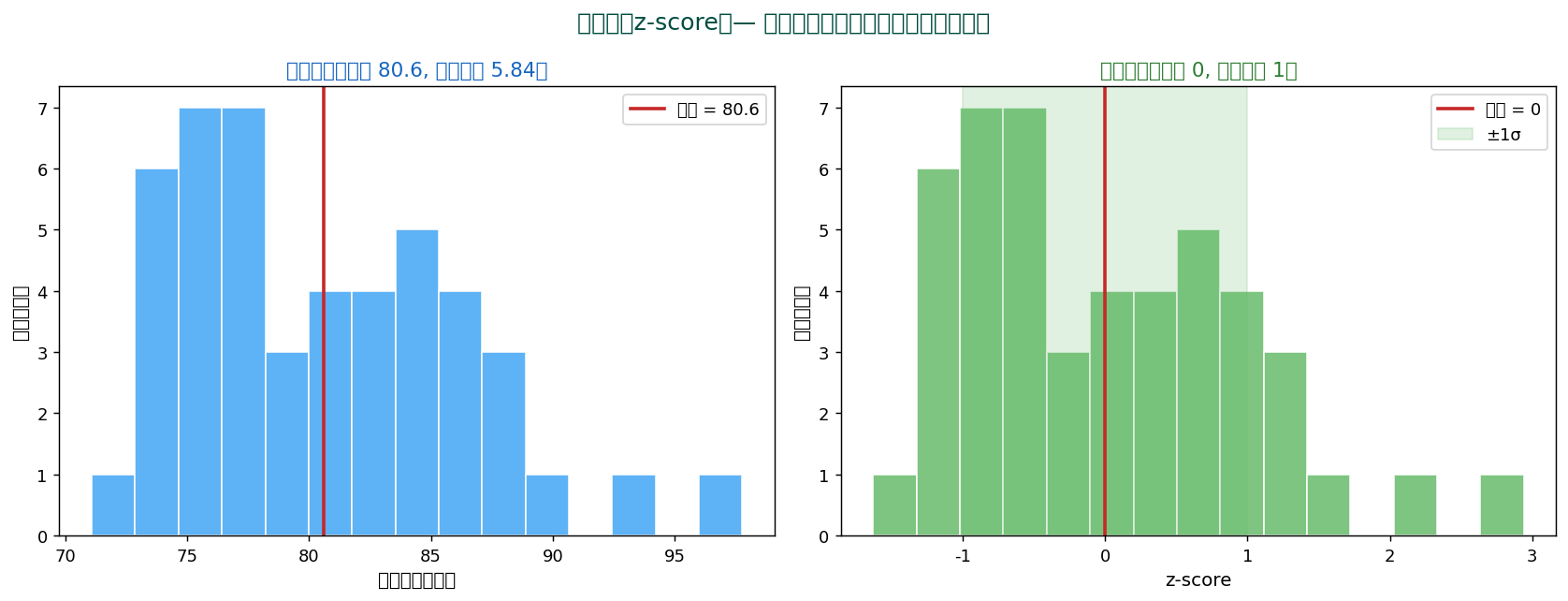
🎯 標準化(z-score)— 単位を消す
異なる単位の変数を比較するには、 「平均からのズレを標準偏差で割る」標準化:
$$ z = \frac{x - \mu}{\sigma} $$
$z$ は無次元で「平均から何標準偏差離れているか」。 偏差値はこれを変形した $T = 50 + 10z$。
🐍 Python で標準化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import numpy as np from sklearn.preprocessing import StandardScaler x = np.array([78.124, 78.984, 81.997, 83.835, 84.105, 80.700]) print(np.std(x)) # 標本SD: 2.59 print(np.std(x, ddof=1)) # 不偏SD: 2.84 # z-score 標準化 z = (x - x.mean()) / x.std(ddof=1) print(z) # 平均 0, SD 1 # sklearn の StandardScaler(機械学習で多用) X = np.array([[1, 10], [3, 30], [5, 50]]) scaler = StandardScaler() X_scaled = scaler.fit_transform(X) print(X_scaled.mean(axis=0)) # ≈ 0 print(X_scaled.std(axis=0)) # ≈ 1 |
🔗 共分散(Covariance, $\sigma_{xy}$)
共分散は「2つの変数が一緒に動くか」を測る指標。 分散の2変数版とも言えます。 平均からの偏差を 2変数で掛け合わせたものの平均。
$$ \sigma_{xy} = \mathbb{E}[(X - \mu_X)(Y - \mu_Y)] = \frac{1}{N} \sum (x_i - \mu_X)(y_i - \mu_Y) $$
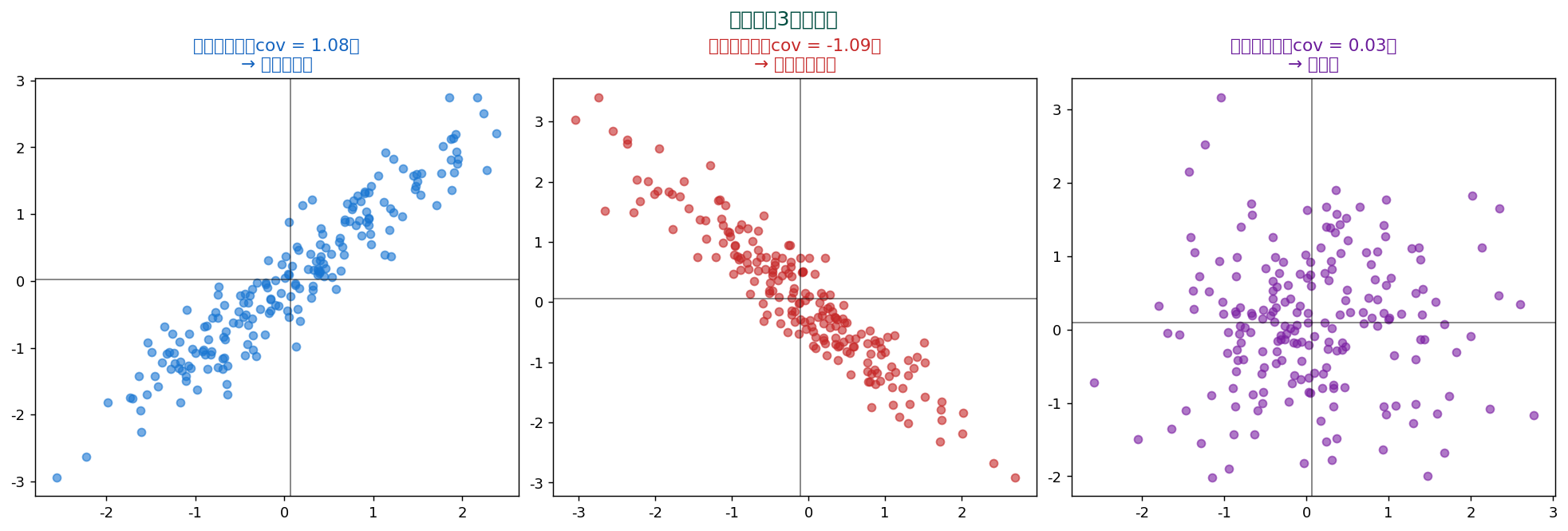
幾何学的意味 — 4象限の積
散布図上で平均 $(\bar{x}, \bar{y})$ を原点として4象限に分けると:
- 第1象限(両方+)→ $(+)(+) = $ 正
- 第3象限(両方-)→ $(-)(-) = $ 正(負×負=正)
- 第2・4象限(一方+、 一方-)→ 負
これらを全部足して n で割ると共分散。 第1・第3象限に多ければ正の共分散、 第2・第4 に多ければ負。
🧮 SSDSE 実値で計算 — 東北6県の食料費 × 教育費
| 都道府県 | 食料費 $x$ | 教育費 $y$ | $x - \bar{x}$ | $y - \bar{y}$ | $(x-\bar{x})(y-\bar{y})$ |
|---|---|---|---|---|---|
| 青森県 | 77.90 | 6.71 | -2.925 | -1.021 | +2.9864 |
| 岩手県 | 82.00 | 6.75 | +1.173 | -0.986 | -1.1566 |
| 宮城県 | 83.83 | 11.24 | +3.011 | +3.511 | +10.5716 |
| 秋田県 | 78.12 | 4.32 | -2.700 | -3.418 | +9.2286 |
| 山形県 | 84.11 | 7.27 | +3.281 | -0.467 | -1.5322 |
| 福島県 | 78.98 | 10.12 | -1.840 | +2.381 | -4.3810 |
| 合計 | +15.7168 | ||||
不偏共分散 $s_{xy} = 15.7168 / (6 - 1) = \mathbf{3.1434}$。 正の値なので「食料費が高い県は教育費も高い」傾向。
🔢 ベクトル表記と共分散行列
2つの中心化ベクトル $\tilde{\boldsymbol{x}}, \tilde{\boldsymbol{y}}$ について:
$$ s_{xy} = \frac{1}{n-1} \tilde{\boldsymbol{x}}^\top \tilde{\boldsymbol{y}} $$
$d$ 変数のデータ行列 $X \in \mathbb{R}^{n \times d}$ について、 中心化行列 $\tilde{X}$ から共分散行列:
$$ \Sigma = \frac{1}{n-1} \tilde{X}^\top \tilde{X} \in \mathbb{R}^{d \times d} $$
$d \times d$ の対称・半正定値行列。 対角は各変数の分散、 非対角がペアの共分散。 これを固有値分解すればPCA になります。
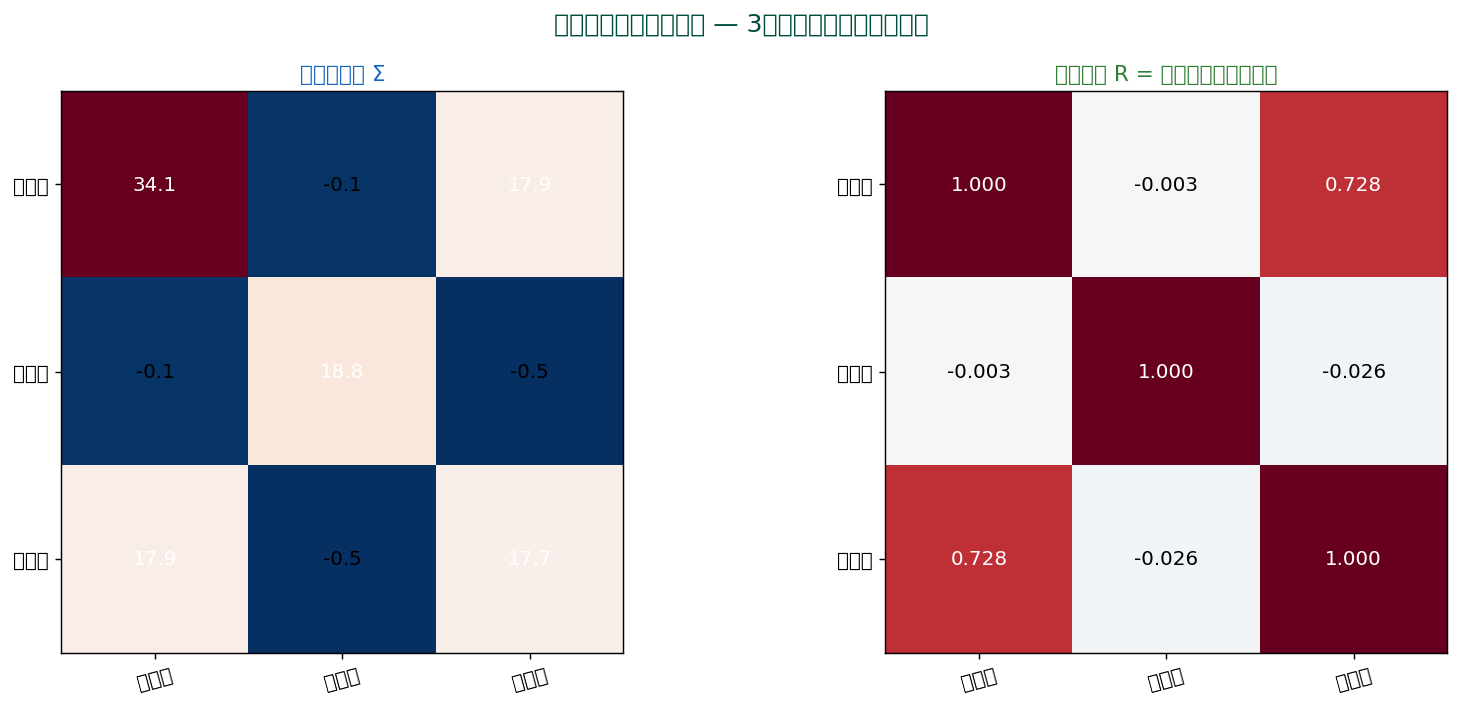
⚠️ 共分散の問題点と相関への展開
共分散は単位に依存するため、 大小比較が困難です。 同じデータでも単位を変えれば共分散が変わってしまいます:
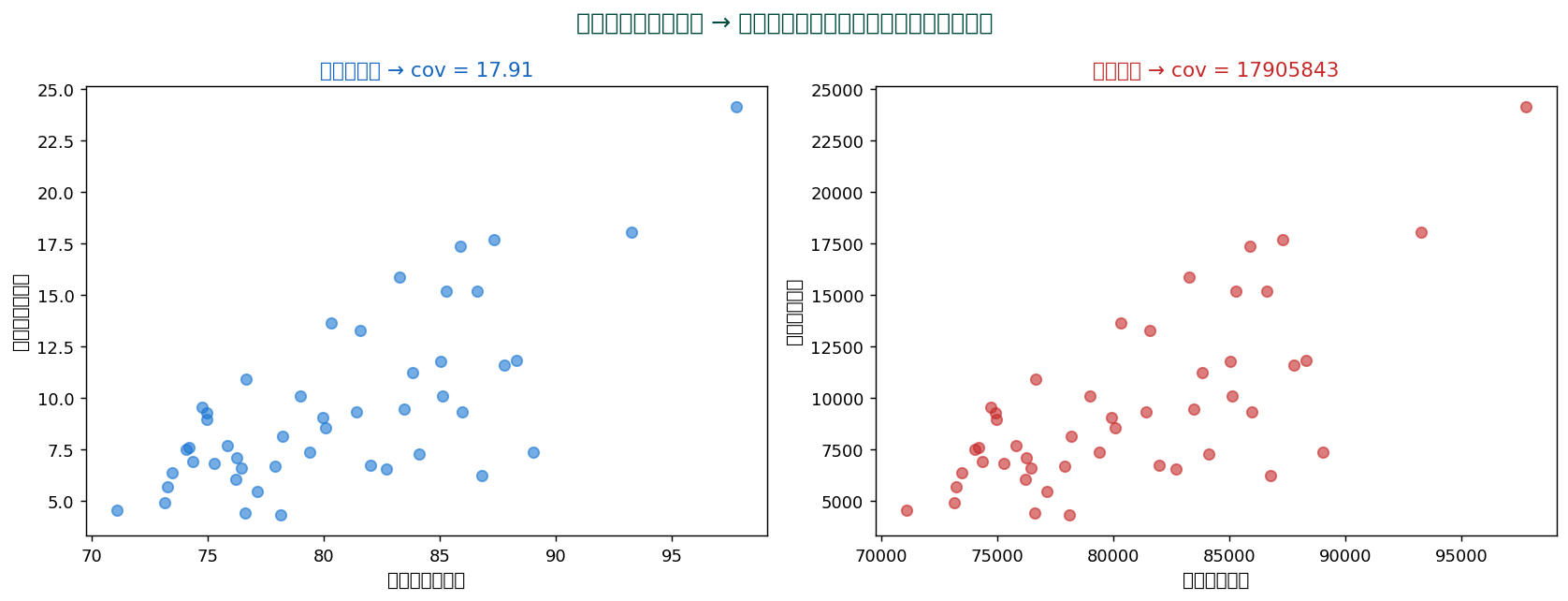
これを解消するため、 標準偏差で正規化したのが 相関係数:$r = \sigma_{xy} / (\sigma_x \sigma_y)$。 $r \in [-1, +1]$ で単位フリー。
🐍 Python で共分散
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import numpy as np import pandas as pd x = np.array([78.124, 78.984, 81.997, 83.835, 84.105, 80.700]) y = np.array([8.5, 9.2, 10.1, 11.0, 10.8, 9.5]) # NumPy の cov(デフォルトは不偏、 ddof=1) print(np.cov(x, y)) # 2x2 共分散行列 print(np.cov(x, y)[0, 1]) # x と y の共分散 # Pandas df = pd.DataFrame({'x': x, 'y': y}) print(df.cov()) print(df['x'].cov(df['y'])) # 多変数の共分散行列 X = np.random.randn(100, 5) Sigma = np.cov(X, rowvar=False) print(Sigma.shape) # (5, 5) diag = np.diag(Sigma) # 各列の分散 |
📏 範囲(Range)
範囲は最も単純なばらつき指標:$\mathrm{Range} = \max(x) - \min(x)$。 「データの広がる幅」。
長所:計算が極めて簡単、 直感的。
短所:外れ値に最も弱い(1点で値が変わる)、 中央のデータ分布の情報を失う。
実務では「最低・最高」を併記して提示するか、 四分位範囲(IQR)に置き換えることが多い。
🛡️ MAD(中央絶対偏差)
標準偏差は平均と分散をベースとするため外れ値に弱い。 そのロバスト版がMAD(Median Absolute Deviation):
$$ \mathrm{MAD} = \mathrm{median}(|x_i - \mathrm{median}(x)|) $$
「中央値からの絶対距離の中央値」。 平均と標準偏差が外れ値で歪むのに対し、 MAD は50% 崩壊点(半分のデータが壊れても影響なし)。
正規分布での換算
正規分布の場合、 $\sigma \approx 1.4826 \times \mathrm{MAD}$。 つまり MAD を 1.4826 倍すれば「ロバストな標準偏差」になります。
1 2 3 4 5 6 7 8 9 | from scipy import stats import numpy as np # 外れ値を含むデータ data = np.array([1, 2, 3, 4, 5, 6, 7, 100]) print(np.std(data, ddof=1)) # 33.8(外れ値で歪む) print(stats.median_abs_deviation(data)) # 2.5(ロバスト) print(stats.median_abs_deviation(data, scale='normal')) # 3.7(正規分布換算) |
🌳 使い分け — どの指標を選ぶか
分布の形・状況での選び方
| 状況 | 推奨指標 | 理由 |
|---|---|---|
| 対称分布(正規分布)、 外れ値少 | 分散・標準偏差 | CLT・信頼区間の前提 |
| 外れ値・歪んだ分布 | MAD、 IQR | ロバスト性 |
| 2変数の関係 | 共分散(→ 相関で正規化) | 単位フリーは相関 |
| 多変数の関係 | 共分散行列・ 相関行列 | PCA の前提 |
| 単位の異なる変数の比較 | 変動係数 (CV) = $\sigma/\mu$ | 無次元化 |
| 概観把握のみ | 範囲(min/max) | 計算容易だが情報少 |
🤖 機械学習でのばらつき指標
- バイアス-バリアンス分解:予測誤差 = $\text{Bias}^2 + \text{Variance} + \sigma^2_\varepsilon$。 過学習はバリアンス大、 過小学習はバイアス大
- PCA:共分散行列の固有値分解。 「分散を最大化する方向」を主成分軸に
- Batch Normalization:各層出力の平均と分散で標準化、 深層学習の必須技術
- Variance Threshold:分散がほぼゼロの特徴量を除外する前処理
- StandardScaler / RobustScaler:平均・SD(または中央値・IQR)で標準化
- 分散分析(ANOVA):全分散を「群間分散 + 群内分散」に分解
- マハラノビス距離:$\Sigma^{-1}$ を使った多変量距離、 異常検知の基本
- ポートフォリオ理論:共分散行列でリスク最小化(Markowitz)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from sklearn.preprocessing import StandardScaler, RobustScaler from sklearn.feature_selection import VarianceThreshold from sklearn.decomposition import PCA # 標準化(学習用) scaler = StandardScaler() X_train_std = scaler.fit_transform(X_train) X_test_std = scaler.transform(X_test) # 訓練でfit、 テストはtransform # ロバスト版(外れ値に強い) scaler = RobustScaler() # 中央値と IQR ベース # 分散ほぼゼロの特徴量を除外 selector = VarianceThreshold(threshold=0.01) X_filtered = selector.fit_transform(X) # PCA(共分散行列を分解) pca = PCA(n_components=2) X_pca = pca.fit_transform(X_std) print(pca.explained_variance_ratio_) # 主成分の寄与率 |
🚧 よくある誤解 — チェックリスト
| ❌ よくある誤解 | ✅ 正しい理解 |
|---|---|
| 「÷n」も「÷(n-1)」も同じ | 推測には ÷(n-1)(不偏)、 記述には ÷n。 ライブラリのデフォルトを確認 |
| 標準偏差と標準誤差は同じ | SD はデータのばらつき、 SE は推定値のばらつき($\sigma/\sqrt{n}$) |
| 分散の単位は元と同じ | 分散は単位の2乗。 解釈には標準偏差を使う |
| 共分散の大きさで関係の強さが分かる | 単位依存で比較不可。 相関係数(正規化済み)を使う |
| 外れ値があっても標準偏差で十分 | 2乗で外れ値の影響が増幅。 MAD・IQR を併用 |
| 共分散ゼロ ⇒ 独立 | 線形関係がないだけ。 非線形(U字など)はあり得る |
| 68-95-99.7 ルールはどんな分布でも使える | 正規分布の話。 歪んだ分布では成り立たない |
| 変動係数(CV)で全部比較可能 | 平均がゼロに近い/負の場合は意味を失う |
📝 練習問題 — 理解度チェック
問1:データ $(10, 20, 30, 40, 50)$ の標本分散・不偏分散・標準偏差を手計算せよ。
解答:$\bar{x} = 30$、 偏差: $(-20, -10, 0, 10, 20)$、 二乗和 $= 400 + 100 + 0 + 100 + 400 = 1000$。
標本分散 $= 1000/5 = 200$。 不偏分散 $= 1000/4 = 250$。 標本標準偏差 $= \sqrt{200} \approx 14.14$、 不偏標準偏差 $= \sqrt{250} \approx 15.81$。
問2:データに $1$ つの外れ値(極端な値)が含まれている。 標準偏差と MAD のどちらを使うべきか?
解答:MAD。 標準偏差は偏差を2乗するため、 外れ値の影響が大きく増幅されてしまう。 MAD は中央値ベースで 50% 崩壊点を持つロバスト指標。 正規分布なら $\sigma \approx 1.4826 \times \mathrm{MAD}$ で標準偏差相当の値も得られる。
問3:「÷n」と「÷(n-1)」の使い分けを説明せよ。 NumPy と Pandas のデフォルトはどちら?
解答:「÷n」は標本分散(最尤推定)、 「÷(n-1)」は不偏分散。 母集団の分散を推定したい場合は ÷(n-1)(バイアス補正)、 標本そのものの記述には ÷n。 NumPy の np.var はデフォルトで ddof=0(÷n)、 Pandas の df.var() はデフォルトで ddof=1(÷(n-1))。 違いに注意。
問4:データを 2 倍したら、 平均・分散・標準偏差はそれぞれ何倍になるか?
解答:平均 → 2倍、 分散 → 4倍($\mathrm{Var}(aX) = a^2 \mathrm{Var}(X)$)、 標準偏差 → 2倍。 これが「分散は2乗で動くが、 標準偏差は元の単位で動く」の意味。
問5:共分散が 100、 $\sigma_x = 5$、 $\sigma_y = 8$ のとき、 相関係数は?
解答:$r = \sigma_{xy} / (\sigma_x \sigma_y) = 100 / (5 \times 8) = 100/40 = 2.5$。 …これは $|r| \le 1$ の制約に違反しているので、 与えられた値が矛盾している(共分散の絶対値は $\sigma_x \sigma_y$ を超えない)。 「共分散が標準偏差の積より大きいことは数学的にあり得ない」(コーシー・シュワルツの不等式)。
問6:SSDSE-B-2026 から食料費・教育費・住居費の共分散行列を Python で計算し、 PCA の前処理として標準化が必要な理由を説明せよ。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import pandas as pd import numpy as np from sklearn.preprocessing import StandardScaler df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') data = df.iloc[1:].copy() data['年度'] = data['SSDSE-B-2026'] df23 = data[data['年度'] == '2023'] cols = ['L322101', 'L322108', 'L322102'] # 食料・教育・住居 X = df23[cols].apply(pd.to_numeric, errors='coerce').dropna() / 1000 # 共分散行列 print(np.cov(X.values, rowvar=False)) # PCA の前に標準化(必須) X_std = StandardScaler().fit_transform(X) |
PCA は分散最大方向を見つけるので、 単位が大きい変数(住居費)が支配的になってしまう。 標準化すると全変数が等しいスケールになり、 真の構造が捉えられる。 つまり「単位の違いを取り除いてから分散構造を見る」が標準化の目的。
📋 報告フォーマット
ばらつき指標を報告するときは、 必ず代表値(平均または中央値)とセットで示します。 単に「分散 = X」では意味を成しません。
「47都道府県の食料費(2023年・ SSDSE-B-2026)は、 平均 80.6 千円 ± 標準偏差 3.0 千円(不偏推定)、 範囲は 71.1〜97.8 千円。 分布は概ね対称だが、 一部の都市県が右側に長い裾を作る。 MAD ベースのロバスト標準偏差は 2.6 千円とほぼ同等で、 外れ値の影響は限定的。 (n=47)」
- 代表値(平均または中央値) + ばらつき指標を併記
- SD / SE / IQR / MAD のうちどれを示しているか明示
- サンプルサイズ $n$ を必ず記す
- 分布の形(対称・歪み)にも触れる
🔖 キーワード索引 — 拡張版
散らばり(dispersion)に関連する用語を、 計算量・スケール・代表値との関係 別に整理しました。
| カテゴリ | キーワード(日本語) | キーワード(英語) |
|---|---|---|
| 基本量 | 分散、 標準偏差、 範囲、 四分位範囲、 平均絶対偏差 | variance, standard deviation, range, IQR, MAD |
| 無次元化指標 | 変動係数、 ジニ係数、 エントロピー | CV, Gini coefficient, entropy |
| 理論基盤 | 期待値、 モーメント、 自由度、 不偏推定量 | expectation, moment, degrees of freedom, unbiased |
| 関連手法 | 分散分析、 F検定、 主成分分析、 共分散行列 | ANOVA, F-test, PCA, covariance matrix |
| 外れ値耐性 | ロバスト、 中央絶対偏差、 トリム平均 | robust, MAD (median absolute deviation), trimmed mean |
| 実装関数 | np.var、 np.std、 pd.Series.var、 scipy.stats.iqr、 statsmodels | numpy.var, ddof, pandas describe, scipy.stats.iqr |
🧮 SSDSE-B による散らばり指標 — 実値計算例
SSDSE-B から「47都道府県の平均所得(万円)」を取り出して、 各種の散らばり指標を計算します。
① データの概要
平均所得の最小値:約 240(沖縄県)、 最大値:約 540(東京都)、 中央値:約 295
② 各指標の値(イメージ値)
| 指標 | 値 | 解釈 |
|---|---|---|
| 範囲 (Range) | 300 | 最大と最小の差。 東京と沖縄で約 300 万円差。 |
| 分散 (Variance, ddof=1) | ≈ 3500 | 単位は「万円²」で直感的に解釈しにくい。 |
| 標準偏差 (SD) | ≈ 59 | 平均からの典型的なズレが 59 万円。 直感的に分かる。 |
| IQR | ≈ 35 | 真ん中50%の幅。 外れ値(東京)の影響を受けない。 |
| 変動係数 CV | ≈ 0.19 | SD / 平均。 単位なし。 他県・他項目との比較が可能。 |
| MAD(中央絶対偏差) | ≈ 22 | 外れ値の影響を最も受けない。 ロバスト統計の基礎。 |
💡 SD と IQR が大きく異なるのは、 東京都が外れ値として SD を引っ張っているためです。 外れ値の影響を避けたい場合は IQR や MAD を使います。
⚠️ 散らばり指標の落とし穴 — 拡張版(実務で本当に困る5+件)
- 自由度の混乱(n vs n−1):分散の分母を n とすると母集団の分散(最尤推定量)、 n−1 とすると不偏推定量になる。 numpy.var はデフォルト ddof=0(n割り)、 pandas .var() はデフォルト ddof=1(n−1割り)。 同じデータでも値が異なる原因になるため、 ddof を必ず明示することが事故防止の基本。
- 外れ値による分散の爆発:分散・標準偏差は二乗を含むため、 1個の極端な値で値が大きく膨らむ。 例えば所得分布の上位1%を含めるかどうかで SD が 2 倍以上変わることも珍しくない。 外れ値の検討なしに SD を報告するのは危険で、 IQR や MAD など robust な指標を併用する。
- 単位の異なる変数間で SD を直接比較:身長(cm)と体重(kg)の SD を比べても意味がない。 比較したい場合は 変動係数 CV = SD / 平均 のような無次元化指標を使うか、 標準化(z変換)してから比較する。 単位を意識しない比較は誤った結論を生む典型例。
- 非対称分布での平均±SD の誤解:「平均±SD」が68%区間を示すのは正規分布の場合のみ。 所得分布や待機時間のように右に裾が長い分布で平均±SD を使うと、 平均−SD が負になり「マイナスの所得」を含むという奇妙な記述になる。 中央値と四分位数(boxplot)を使うか、 対数変換を検討する。
- 少標本でのIQR・範囲の不安定さ:n=10 程度の小標本では、 IQR や範囲は標本ごとに大きく変動する。 信頼区間とセットで報告するか、 ブートストラップで再標本化する。 単一の値で「ばらつきはこれだけ」と断定しない姿勢が重要。
- 分散と相関の混同:分散は単一変数のばらつき、 共分散・相関は2変数の連動の度合い。 「分散が大きい=相関がある」とは言えない。 別の概念として整理して使い分ける。
- 離散値・カテゴリ変数への適用:性別や血液型などの名義尺度に分散を計算しても意味がない。 多様性の尺度としては エントロピー や ジニ不純度 を使う。
🐍 Python 実装バリエーション — numpy / scipy / pandas / statsmodels
① numpy(基本、 軽量)
1 2 3 4 5 6 7 8 9 10 11 | import numpy as np import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) x = df['平均所得'].to_numpy() print('範囲 :', x.max() - x.min()) print('分散 (ddof=0):', np.var(x, ddof=0)) # 母分散 print('分散 (ddof=1):', np.var(x, ddof=1)) # 標本分散 print('標準偏差(ddof=1):', np.std(x, ddof=1)) print('CV :', np.std(x, ddof=1) / np.mean(x)) |
② pandas(DataFrame向け、 describe()で一括)
1 2 3 4 5 6 7 8 9 | import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) print(df[['人口', '平均所得', '完全失業率']].describe()) # mean, std, min, 25%, 50%, 75%, max # IQR q1 = df['平均所得'].quantile(0.25) q3 = df['平均所得'].quantile(0.75) print('IQR:', q3 - q1) |
③ scipy.stats(IQR、 トリム分散、 ロバスト指標)
1 2 3 4 5 6 7 8 9 10 11 12 | from scipy import stats import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) x = df['平均所得'] print('IQR :', stats.iqr(x)) print('MAD :', stats.median_abs_deviation(x)) print('歪度 :', stats.skew(x)) print('尖度 :', stats.kurtosis(x)) print('5%トリム平均:', stats.trim_mean(x, 0.05)) print('20%trimVar:', stats.tvar(x, limits=(x.quantile(0.1), x.quantile(0.9)))) |
④ statsmodels(記述統計まとめ)
1 2 3 4 5 6 7 8 9 | import statsmodels.api as sm import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) desc = sm.stats.DescrStatsW(df['平均所得']) print('mean:', desc.mean) print('std :', desc.std) print('var :', desc.var) print('95% CI:', desc.tconfint_mean()) |
⑤ 可視化(boxplot / violin)
1 2 3 4 5 6 7 8 9 10 | import matplotlib.pyplot as plt import seaborn as sns import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) fig, ax = plt.subplots(1, 2, figsize=(10, 4)) sns.boxplot(y=df['平均所得'], ax=ax[0]) sns.violinplot(y=df['平均所得'], ax=ax[1]) plt.tight_layout() plt.show() |