📍 あなたが今見ているもの
論文や記事中に 「平均」「中央値」「最頻値」 として登場する用語群です。 47都道府県や時系列データを要約するとき必ず使う、 統計学の最も基本的な道具。
このページの構成:説明 → 数式 → 実値計算 → ベクトル例 → Python が一体化されています。 「数式だけ独立して見せる」のではなく、 流れの中で身につけられるよう編まれています。
🔖 キーワード索引
論文記事から各用語のリンクをクリックすると、 該当箇所が開きます:
💡 30秒で分かる結論
🎨 直感で掴む — 3つの代表値を一望する
データの真ん中を「ひとつの数で表せ」と言われたら、 答えは 3通りあります。 それぞれ得意な場面と苦手な場面が違うので、 「分布を見てから選ぶ」のが大切です。
| 代表値 | 記号 | 直感 | 最適な場面 | 弱点 |
|---|---|---|---|---|
| 平均 | $\bar{x}$, $\mu$ | シーソーの支点 | 対称分布、 合計が意味を持つ場合 | 外れ値に弱い |
| 中央値 | $\tilde{x}$, ME | 並べて真ん中 | 歪んだ分布、 外れ値あり | 情報量を全部使わない |
| 最頻値 | Mo | 分布のピーク | カテゴリ変数、 多峰性の診断 | 連続値で定義困難 |
📊 平均(Mean, $\bar{x}$)
平均は、 すべての値を足してデータ数で割った代表値です。 物理的には、 各データ点に同じ重さの「玉」を置いたとき、 シーソーが釣り合う支点が平均。 つまり「データ全体の重心」。
📐 数式
数学的に表現すると、 $n$個のデータ $x_1, x_2, \ldots, x_n$ の平均は次式:
$$ \bar{x} = \frac{1}{n}\sum_{i=1}^{n} x_i = \frac{x_1 + x_2 + \cdots + x_n}{n} $$
🔬 数式を言葉で読み解く
記号を1つずつ読みほどくと:$\bar{x}$ は「エックスバー」(標本平均)、 $\sum_{i=1}^{n}$ は「$i$ を 1 から $n$ まで動かしながら全部足す」、 $\frac{1}{n}$ で個数で割る。 母集団全体の平均は $\mu$(ミュー)と書いて区別します。
🌐 関連手法・派生:中央値・最頻値・分散と並んで、 代表値は分布の土台です。
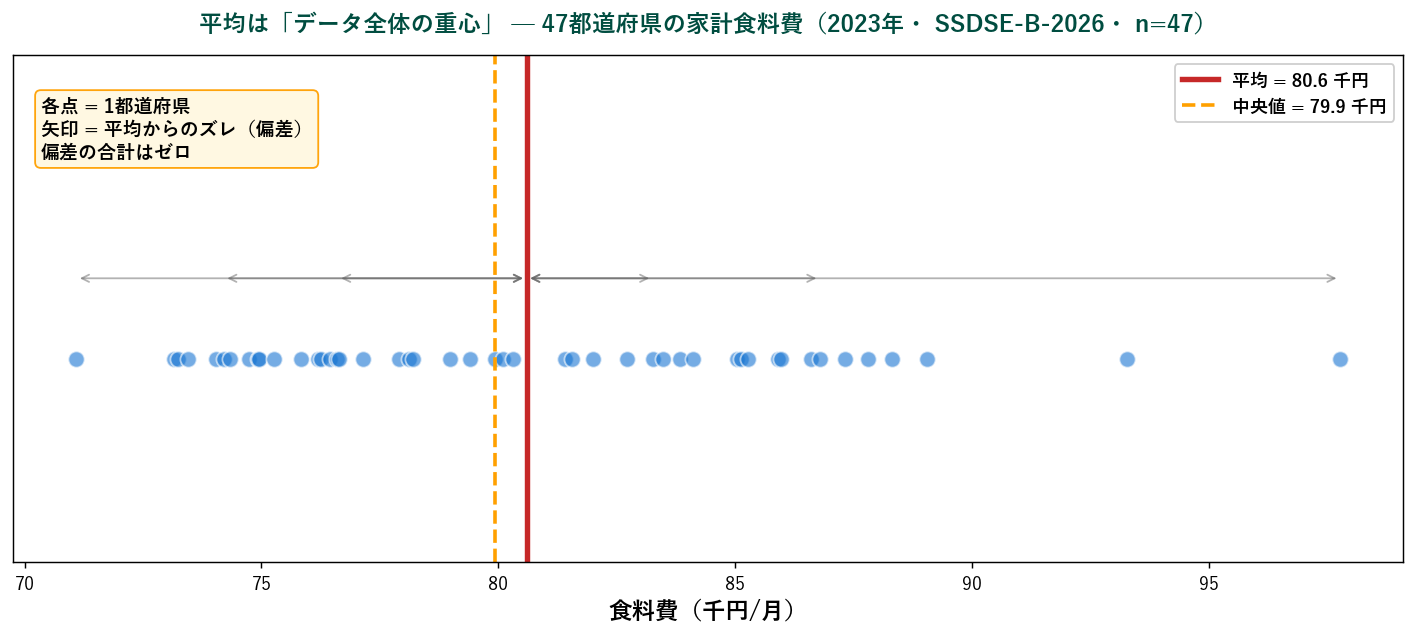
🧮 SSDSE 実値で計算 — 東北6県の食料費
具体的な数値で確認しましょう。 47都道府県データから東北6県の食料費(千円/月、 2023年)を取り出します:
| 都道府県 | 食料費 $x_i$ | 偏差 $x_i - \bar{x}$ |
|---|---|---|
| 青森県 | 77.899 | -2.925 |
| 岩手県 | 81.997 | +1.173 |
| 宮城県 | 83.835 | +3.011 |
| 秋田県 | 78.124 | -2.700 |
| 山形県 | 84.105 | +3.281 |
| 福島県 | 78.984 | -1.840 |
| 合計 | 484.944 | ≈ 0 |
公式に代入:$\bar{x} = (484.944) / 6 = \mathbf{80.824}$ 千円。
偏差の合計が(丸め誤差を除き)ゼロになるのが重要な性質で、 これが「平均は重心」と呼ばれる所以です。 正と負の偏差がちょうど釣り合う点が平均。
🔢 ベクトル表記で見直す
1次元ベクトル例:上のデータを列ベクトルにすると
$$ \boldsymbol{x} = (78.124, 78.984, 81.997, 83.835, 84.105, 80.700)^\top \in \mathbb{R}^6 $$
全要素1のベクトル $\mathbf{1} = (1,1,\ldots,1)^\top$ を使えば、 平均は内積で書けます:
$$ \bar{x} = \frac{1}{n} \mathbf{1}^\top \boldsymbol{x} $$
2次元(行列)例:3地域×2項目のデータ行列
$$ X = \begin{pmatrix} 78 & 9 \\ 81 & 11 \\ 84 & 10 \end{pmatrix} \in \mathbb{R}^{3 \times 2} $$
各列の平均(列平均ベクトル)は $\bar{\boldsymbol{x}} = \frac{1}{n}\mathbf{1}^\top X = (81.0, 10.0) \in \mathbb{R}^2$。 これは「各変数の平均ベクトル」と呼ばれ、 PCA や標準化の基礎になります。
🐍 Python で確認
同じ計算を NumPy/Pandas でやります:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import numpy as np import pandas as pd # 1次元データ(東北6県の食料費) x = np.array([78.124, 78.984, 81.997, 83.835, 84.105, 80.700]) print(np.mean(x)) # 80.824 print(x.mean()) # 同じ # 全要素1のベクトルとの内積で平均を表現 n = len(x) print((np.ones(n) @ x) / n) # 80.824 # 2次元行列(3地域×2項目)の列平均 X = np.array([[78, 9], [81, 11], [84, 10]]) print(X.mean(axis=0)) # [81.0, 10.0] # Pandas で SSDSE データ読み込み df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') print(df['食料費'].mean()) # 全国47都道府県の平均 print(df.groupby('地域')['食料費'].mean()) # 地域別平均 |
⚠️ 平均の弱点 — 外れ値で崩れる
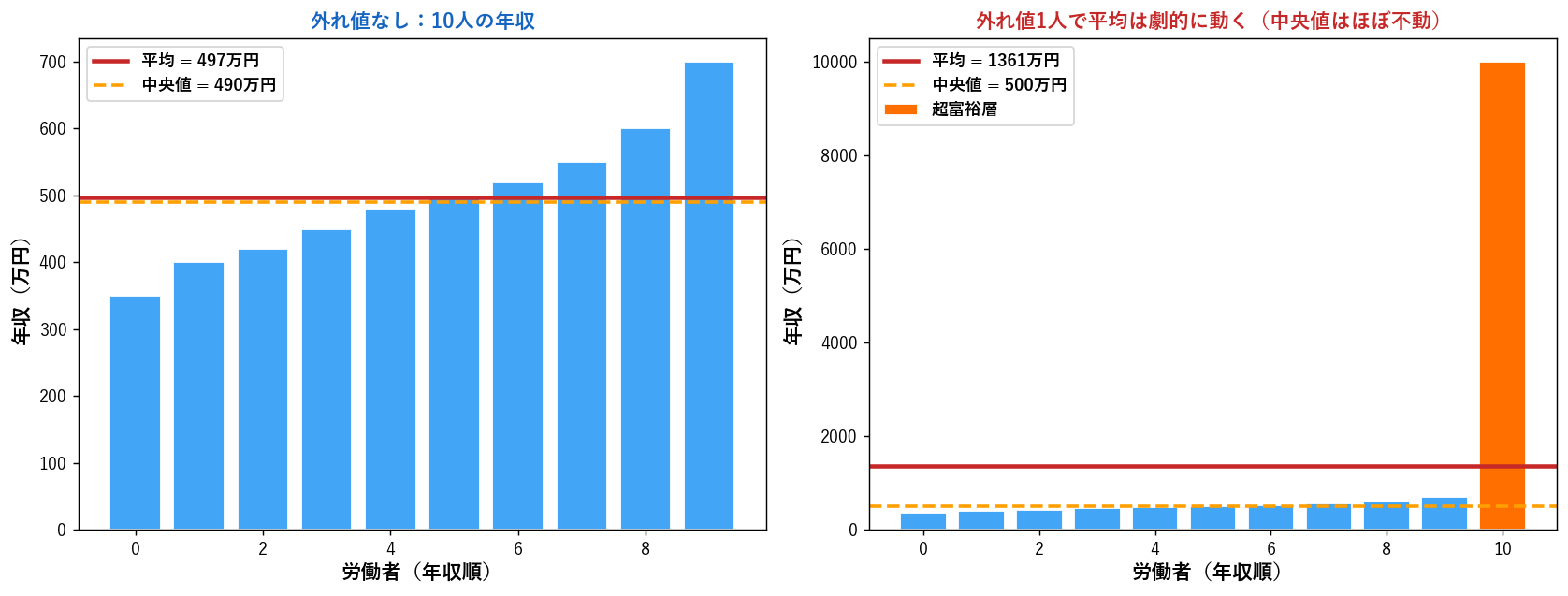
平均はすべてのデータを使うので情報量は最大ですが、 1個の極端な値で大きく動きます。 例えば10人の年収が全員 400万円で1人だけ10億円なら、 平均は約 1億400万円。 「平均的な人」を全く表しません。
🔢 平均の家族 — 算術・幾何・調和・加重
「平均」と言っても実は4種類あります。 同じデータでも目的により値が変わります。
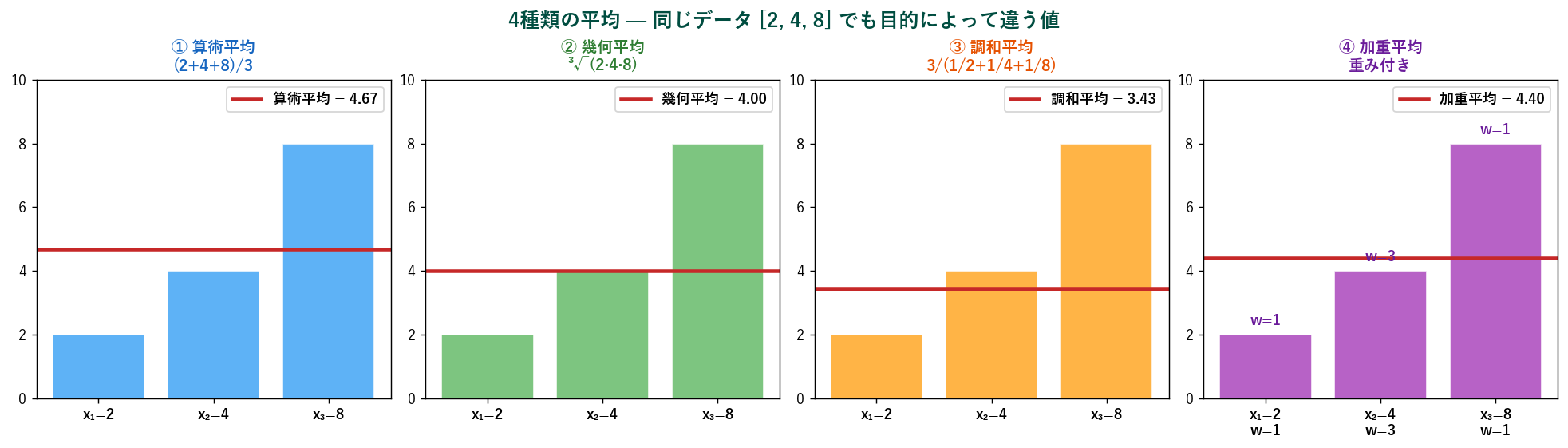
① 算術平均(普段「平均」と呼ぶもの):$\bar{x}_A = \frac{1}{n}\sum x_i$
② 幾何平均(成長率・複利):$\bar{x}_G = \sqrt[n]{x_1 \cdot x_2 \cdots x_n} = \left(\prod x_i\right)^{1/n}$
例:年率 +50% → −50% の2年で投資は $\sqrt{1.5 \times 0.5} \approx 0.866$ → 年率 −13.4%(算術平均では誤って 0% と判定する)。 Python:scipy.stats.gmean([1.5, 0.5])。
③ 調和平均(速度・並列処理):$\bar{x}_H = \dfrac{n}{\sum 1/x_i}$
例:行き60 km/h、 帰り40 km/h の往復平均速度は調和平均で $2/(1/60+1/40) = 48$ km/h。 機械学習の F1 スコアもこの形(precision と recall の調和平均)。
④ 加重平均(重要度に差がある時):$\bar{x}_W = \dfrac{\sum w_i x_i}{\sum w_i}$
例:47都道府県の食料費の人口加重平均。 単純平均だと人口の少ない県と多い県を同等に扱うが、 全国の実態は加重平均が示す。
1 2 3 4 5 6 7 8 | from scipy import stats import numpy as np x = np.array([2.0, 4.0, 8.0]) print(np.mean(x)) # 算術平均: 4.667 print(stats.gmean(x)) # 幾何平均: 4.000 print(stats.hmean(x)) # 調和平均: 3.429 print(np.average(x, weights=[1, 3, 1])) # 加重平均: 4.4 |
大小関係:非負の値では常に AM ≥ GM ≥ HM(イェンセンの不等式)。
📉 移動平均 — 時系列の平滑化
時系列データのノイズを取り除く基本手法。 単純移動平均(SMA):$\text{SMA}_t = \frac{1}{N} \sum_{i=t-N+1}^{t} x_i$。 指数移動平均(EMA):$\text{EMA}_t = \alpha x_t + (1-\alpha)\text{EMA}_{t-1}$(新しいデータに大きな重み)。
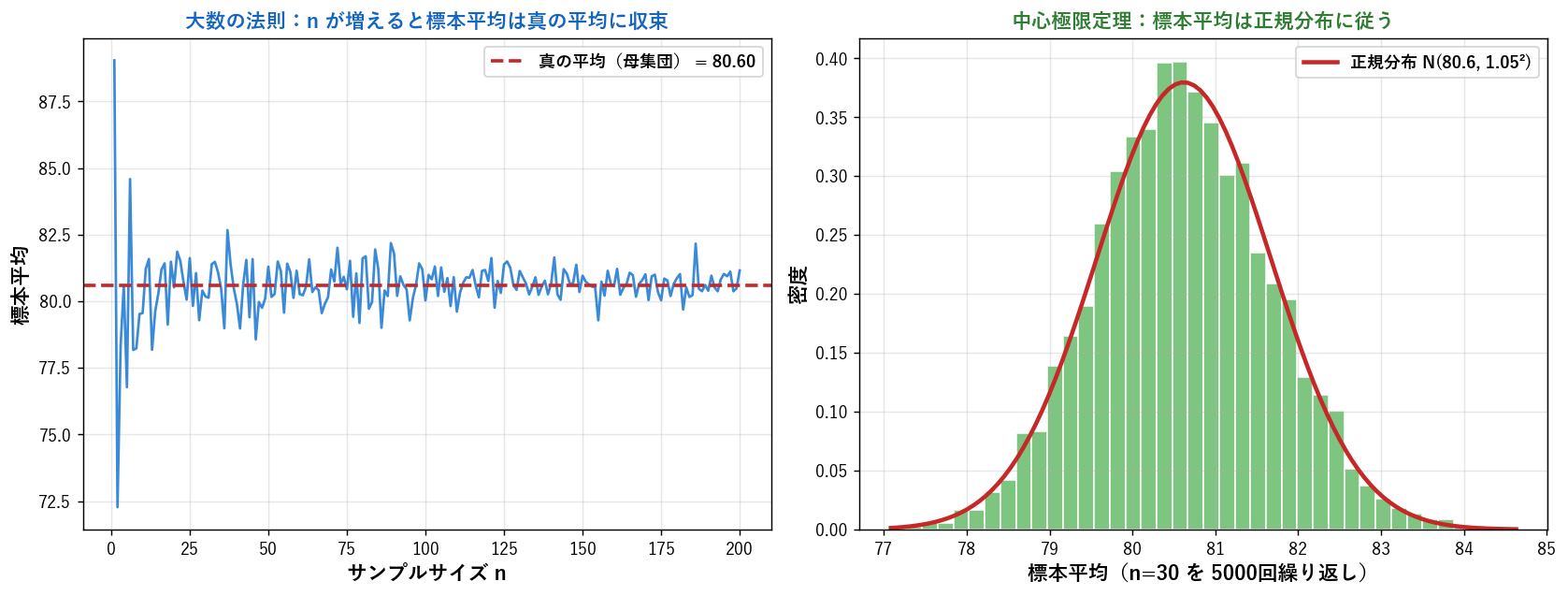
🎯 大数の法則と中心極限定理
平均が統計学の中核を担う理由は、 2つの強力な定理があるから。 大数の法則: $\bar{X}_n \to \mu$(標本サイズ大で標本平均は母平均に収束)。 中心極限定理: $\bar{X}_n \sim N(\mu, \sigma^2/n)$(元の分布が何であれ標本平均は正規分布に近づく)。 これにより信頼区間や仮説検定が可能になります。
📍 中央値(Median, $\tilde{x}$)
中央値は、 データを小さい順に並べたときの真ん中の値。 平均が「重心」だったのに対し、 中央値は 順位の中心 を表します。 値そのものではなく「順位」を使うので、 両端にどれだけ巨大な値があっても中央値はびくともしません。
データを昇順に並べて $x_{(1)} \le x_{(2)} \le \cdots \le x_{(n)}$ としたとき、 中央値は
$$ \tilde{x} = \begin{cases} x_{((n+1)/2)} & (n \text{ が奇数}) \\ \dfrac{x_{(n/2)} + x_{(n/2+1)}}{2} & (n \text{ が偶数}) \end{cases} $$
連続分布の場合は累積分布関数 $F$ の 0.5 になる点:$F(\tilde{x}) = 0.5$。 数学的にはL1 損失(絶対値和)を最小化する点でもあります:$\tilde{x} = \arg\min_m \sum_i |x_i - m|$。 これは平均が「二乗和(L2)」を最小化することと対をなします。
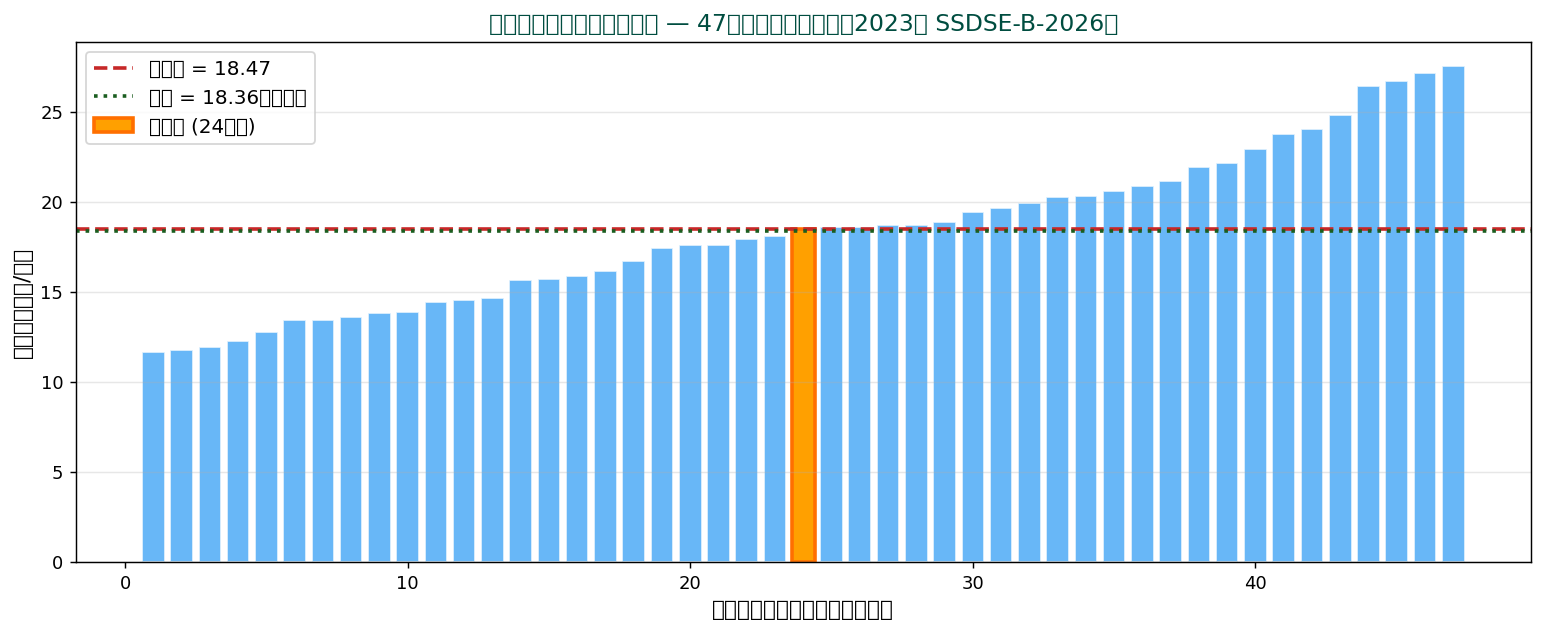
🧮 SSDSE 実値で計算 — 47都道府県の住居費から7点抽出
住居費から等間隔で7県を抜き出します(千円/月):
元データ(順不同): 11.64, 13.60, 15.88, 18.47, 19.93, 22.96, 27.52
これを昇順に並べて真ん中の4番目を取ります:
| 順位 | 都道府県 | 住居費 |
|---|---|---|
| 1 | 神奈川県 | 11.64 |
| 2 | 福井県 | 13.60 |
| 3 | 島根県 | 15.88 |
| 4 | 佐賀県 | 18.47 |
| 5 | 長崎県 | 19.93 |
| 6 | 鹿児島県 | 22.96 |
| 7 | 沖縄県 | 27.52 |
$n=7$(奇数)なので、 真ん中は $(7+1)/2 = 4$ 番目。 中央値 = 18.47 千円。
同じデータを偶数(6個に減らす)と、 真ん中の2つの平均を取ります:例えば3番目と4番目が $a, b$ なら中央値 $= (a+b)/2$。
🔢 ベクトル表記
1次元ベクトル $\boldsymbol{x} \in \mathbb{R}^n$ について、 ソート後の順序統計量 $x_{(i)}$ を使えば中央値は順位 $(n+1)/2$ の要素。 2次元行列 $X \in \mathbb{R}^{n \times d}$ なら列ごとに計算した中央値ベクトル $\tilde{\boldsymbol{x}} \in \mathbb{R}^d$ を作れます。
🐍 Python で確認
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | import numpy as np import pandas as pd # 1次元 x = np.array([50, 70, 80, 90, 90]) print(np.median(x)) # 80.0 # 偶数個(真ん中2つの平均) x6 = np.array([1, 3, 5, 7, 9, 11]) print(np.median(x6)) # 6.0 = (5+7)/2 # 2次元(行列の列ごと) X = np.array([[1, 10], [3, 30], [5, 50], [7, 70], [9, 90]]) print(np.median(X, axis=0)) # [5, 50] # 欠損値を無視 print(np.nanmedian([1, 2, np.nan, 4])) # 2.0 # Pandas df['住居費'].median() df['住居費'].describe() # min/25%/50%(中央値)/75%/max |
🛡️ ロバスト性 — 中央値の最強の武器
「順位だけ」を使うため、 データの両端にどれほど巨大・極小な値があっても中央値は動きません。 これを崩壊点(breakdown point)と呼び、 平均は0%(1点で壊れる)、 中央値は50%(理論的最大)です。
所得分布や住宅価格、 地震被害額のように右に裾の長い分布では、 平均は裾に引っ張られて「典型的でない」値になり、 中央値の方が「典型的な値」を表します。 厚労省の調査では、 ある年の世帯平均所得 約552万円に対し中央値 約437万円。 「平均以下」の世帯が62%にもなるのはこのため。
📏 中央絶対偏差(MAD)— 中央値のばらつき指標
平均にペアの「標準偏差」があるように、 中央値のロバスト版が MAD (Median Absolute Deviation):$\text{MAD} = \text{median}(|x_i - \text{median}(x)|)$。 正規分布なら $\sigma \approx 1.4826 \times \text{MAD}$ という換算式。
1 2 3 4 5 | from scipy import stats data = np.array([1, 2, 3, 4, 5, 6, 7, 100]) # 外れ値あり print(np.median(data)) # 4.5 print(stats.median_abs_deviation(data)) # 2.5(ロバスト) print(stats.median_abs_deviation(data, scale='normal')) # 正規分布換算 |
🔝 最頻値(Mode, Mo)
最頻値は、 データの中でもっとも多く現れる値。 アンケートのようなカテゴリ変数(血液型、 購入色、 好きなフレーバー)には平均も中央値も計算できないので、 最頻値が唯一意味を持つ代表値です。
離散分布での定義は $\text{Mode} = \arg\max_x P(X=x)$、 連続分布なら密度関数 $f(x)$ のピーク $\arg\max_x f(x)$。
🧮 計算例 — カテゴリ・離散・連続の3パターン
① カテゴリデータ:「好きな果物」アンケート
| 果物 | 回答数 |
|---|---|
| リンゴ | 25 |
| バナナ | 42 |
| オレンジ | 18 |
| ぶどう | 15 |
最頻値 = バナナ(最大頻度 42)。 ここで「平均=ミカン的な何か」「中央値=順位の真ん中」と計算しても無意味です。
② 離散数値データ:あるクラスの兄弟姉妹の数 $\boldsymbol{x} = (0, 1, 1, 1, 2, 2, 3, 0, 1, 2, 1, 4)^\top$
頻度カウント:0→2回、 1→5回(最多!)、 2→3回、 3→1回、 4→1回。 最頻値 = 1。
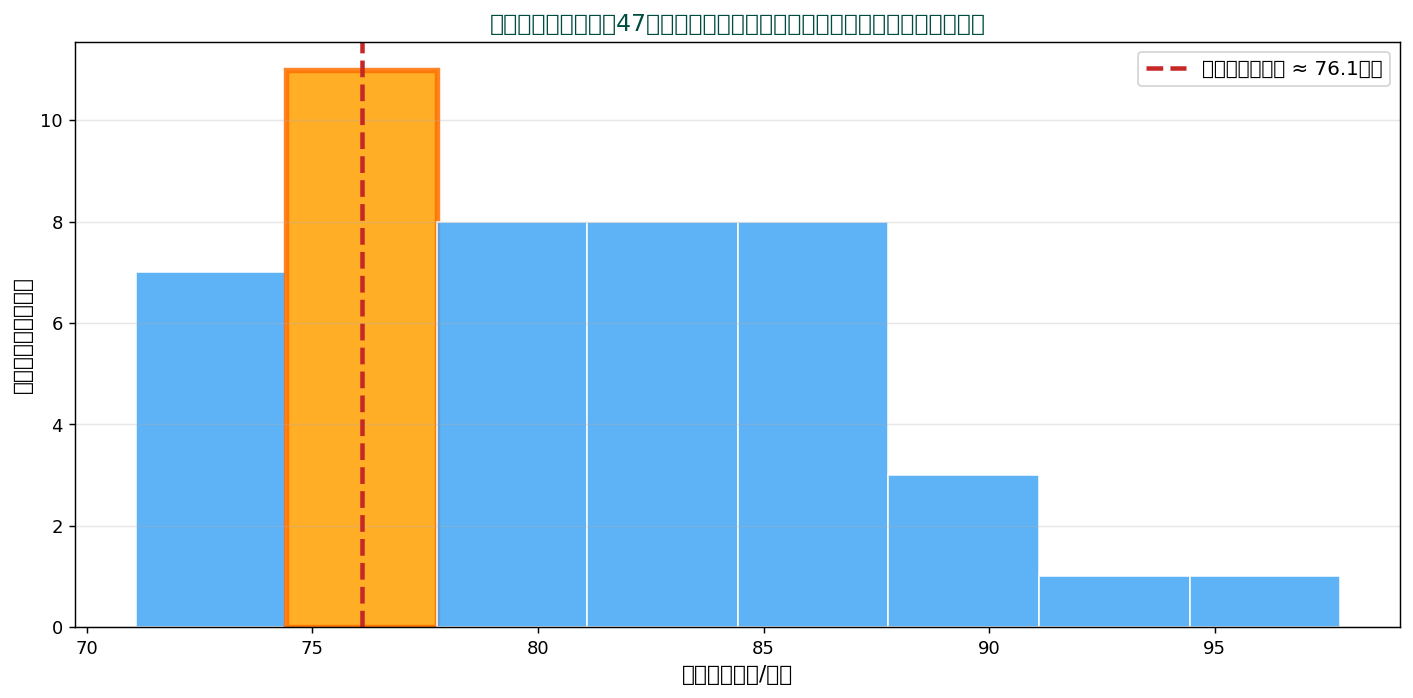
③ 連続データ:47都道府県の食料費を8階級に区切ると、 74.4〜77.8 千円 の階級が 11都道府県を含み最多。 階級の中点 ≈ 76.1 千円が最頻値の代表。
🔢 ベクトル例 + Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from scipy import stats import pandas as pd import numpy as np # 1次元(離散) x = np.array([1, 2, 2, 3, 3, 3, 4, 5]) result = stats.mode(x, keepdims=False) print(result.mode, result.count) # 3, 3 # Pandas(複数最頻値なら全部返す) df['果物'].mode() df['果物'].value_counts().head() # 頻度トップ5 # 連続データの最頻値 → KDE で密度のピーク def continuous_mode(data, grid=1000): kde = stats.gaussian_kde(data) xx = np.linspace(data.min(), data.max(), grid) return xx[np.argmax(kde(xx))] print(continuous_mode(df['食料費'].values)) |
📊 単峰性・ 二峰性 — 集団の混在を診断
最頻値の数は、 データに何種類の集団が混ざっているかのヒントになります:
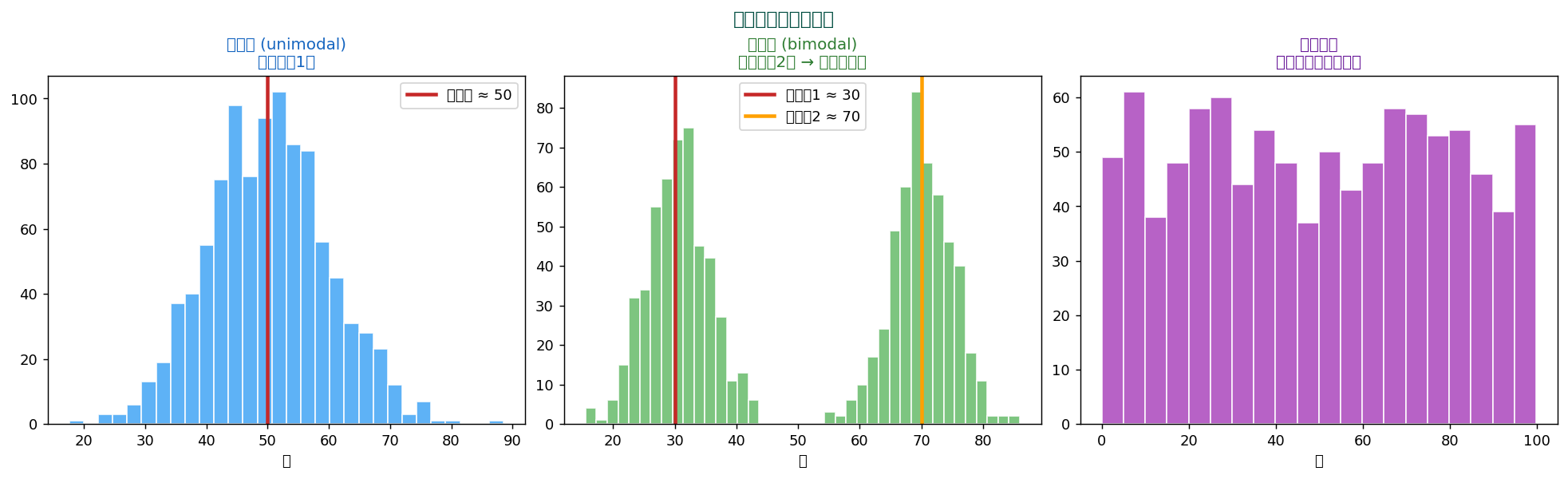
単峰性(山1つ)→ 1集団、 二峰性(山2つ)→ 2集団が混在している可能性(例:男女、 新旧モデル)、 多峰性→ 複数集団、 一様→ 最頻値が定まらない。
🎯 連続データの最頻値 — KDE で滑らかに推定
連続値は同じ値が複数現れることが稀。 ヒストグラムでビン幅を変えると最頻値も変わってしまうため、 カーネル密度推定(KDE)で滑らかな密度関数を作り、 そのピークを最頻値とします。
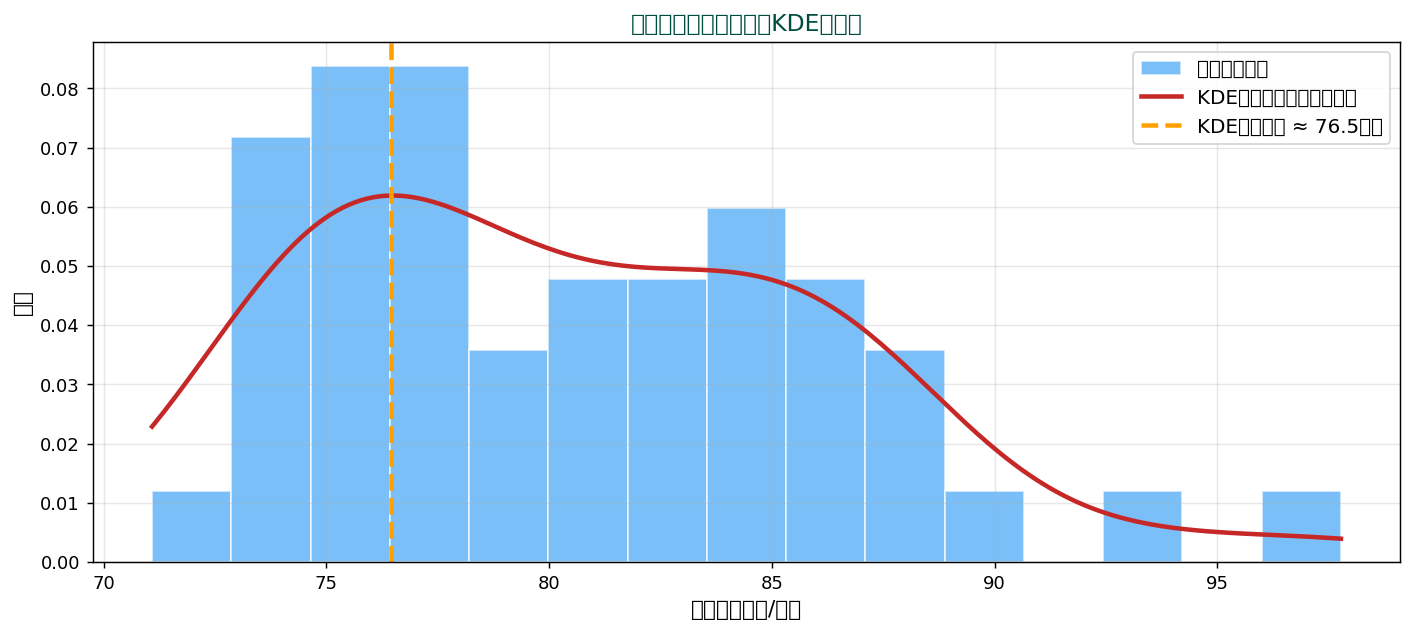
🌳 三者の使い分け — 分布の形で選ぶ
分布が左右対称(正規分布など)なら、 3つの代表値はほぼ一致します。 しかし右に裾を引く分布(所得、 株価、 都市人口)では3つがバラバラになり、 「最頻値 < 中央値 < 平均」の順に右にずれます。
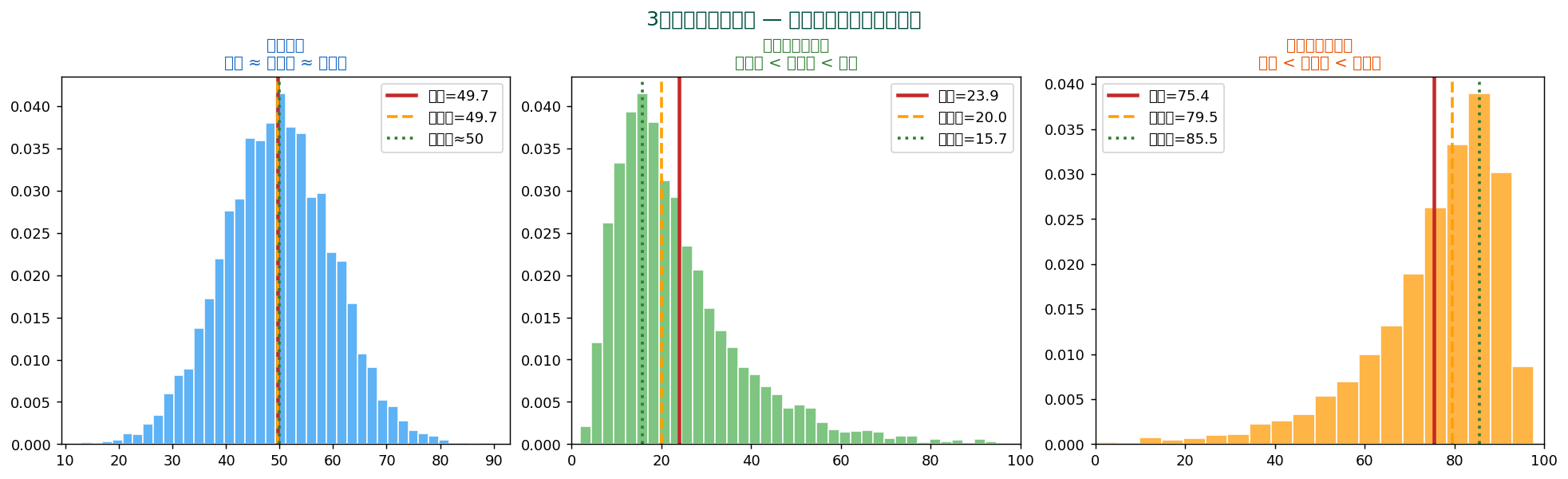
| 分布の形 | 代表値の並び | 実例 |
|---|---|---|
| 左右対称 | 平均 ≒ 中央値 ≒ 最頻値 | 身長、 IQ、 体重 |
| 右に裾 | 最頻値 < 中央値 < 平均 | 所得、 株価、 都市人口 |
| 左に裾 | 平均 < 中央値 < 最頻値 | テスト点数(簡単な問題) |
ピアソンの経験式:歪んだ単峰分布で次がほぼ成立 — $\text{Mean} - \text{Mode} \approx 3(\text{Mean} - \text{Median})$。
🆚 似た概念との違い — 一目で分かる比較表
| 比較項目 | 平均 | 中央値 | 最頻値 |
|---|---|---|---|
| 最小化する損失 | L2 (二乗) | L1 (絶対値) | 0-1 (一致) |
| 外れ値耐性 | ❌ 弱い | ✅ 強い (50%) | ⭕ 中 |
| 情報量 | 全部 | 順位のみ | 頻度のみ |
| 名義尺度で使える? | ❌ | ❌ | ✅ |
| 順序尺度で使える? | ⚠️ 注意 | ✅ | ✅ |
| 微分可能 | ✅ | ❌ | ❌ |
| 線形性 | ✅ | ❌ | ❌ |
💡 報告では3つを併記するのが最も誠実。 「平均500万円、 中央値450万円、 最頻値380万円」と書けば、 読者は分布の歪みを把握できます。
🤖 機械学習での代表値
- 損失関数の中核:MSE = $\frac{1}{n}\sum (y_i - \hat{y}_i)^2$ は誤差の平均。 MAE = $\frac{1}{n}\sum |y_i - \hat{y}_i|$ は中央値と相性が良い。
- 欠損値補完:
SimpleImputer(strategy='mean')/'median'/'most_frequent'。 連続値で外れ値あれば median、 カテゴリは most_frequent。 - 分類器のベースライン:
DummyClassifier(strategy='most_frequent')。 最頻クラスを常に予測する単純モデル。 他モデルが超えるべき下限。 - 決定木の葉ノード:回帰木は葉の平均、 分類木は葉の最頻クラスを予測値とする。
- アンサンブル投票:複数モデルの予測を平均(回帰)or 最頻値(分類, majority vote)で集約。
- Batch Normalization:各層出力の平均と分散で標準化(深層学習の必須技術)。
- Robust Scaling:中央値と IQR を使うスケーリング。 外れ値に強い前処理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from sklearn.impute import SimpleImputer from sklearn.preprocessing import RobustScaler from sklearn.dummy import DummyClassifier # 欠損値補完 imp_mean = SimpleImputer(strategy='mean') # 連続値、 外れ値少 imp_median = SimpleImputer(strategy='median') # 連続値、 外れ値多 imp_mode = SimpleImputer(strategy='most_frequent') # カテゴリ # ロバストスケーリング(中央値と IQR ベース) scaler = RobustScaler() X_scaled = scaler.fit_transform(X) # 最頻クラスのダミー分類器(ベースライン) dummy = DummyClassifier(strategy='most_frequent') dummy.fit(X_train, y_train) print(dummy.score(X_test, y_test)) # 機械学習モデルが超えるべき下限 |
📝 練習問題 — 理解度チェック
問1:年収データ [300, 350, 400, 450, 500, 9000] の代表値3つを計算し、 どれを「典型的な値」として報告すべきか?
解答:
- 平均 = (300+350+400+450+500+9000)/6 = 1833 万円
- 中央値 = (400+450)/2 = 425 万円(n=6なので3,4番目の平均)
- 最頻値 = 連続値で全部1回ずつ → 厳密には定義困難
9000という外れ値が平均を歪めているので、 中央値の425万円を「典型的な値」として報告すべき。 平均だけ示すと誤解を招く。
問2:ベクトル $\boldsymbol{x} = (1, 2, 3, 4, 5)$ の平均と中央値が一致する条件は?
解答:平均 = 中央値 = 3。 このように左右対称な分布(または等差数列)では平均と中央値が一致する。 一般に、 データが中央値を軸として対称に分布していれば両者は一致する。
問3:ある商品の月次売上にヒストグラムを描いたら二峰性(山が2つ)が見えた。 何を疑うべきか?
解答:「2つの異なる集団が混在している」可能性。 例えば、 平日と週末、 セール期間と通常期間、 オンラインと店舗、 新製品と旧製品。 別変数で層別すると2つの単峰分布に分解できることが多い。
問4:年率変化が +50%, -50% の2年で、 投資の平均成長率は? 算術平均と幾何平均のどちらが正しい?
解答:算術平均では (+50% − 50%)/2 = 0%(「変わらない」と誤判定)。 幾何平均では $\sqrt{1.5 \times 0.5} \approx 0.866$ → 年率 -13.4%。 実際 100万円が 1年目で 150万円、 2年目で 75万円になっているので幾何平均が正しい。 成長率・複利・収益率の平均には常に幾何平均を使う。
問5:SSDSE-B-2026 で 47都道府県の食料費を取得し、 平均・ 中央値・ 最頻階級の中点を Python で計算せよ。 分布の歪みはどの方向か?
1 2 3 4 5 6 7 8 9 10 11 12 | import pandas as pd import numpy as np df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') # 2行目以降がデータ、 食料費は L322101 列 food = pd.to_numeric(df['L322101'].iloc[1:], errors='coerce').dropna() / 1000 print('平均:', food.mean()) # ≈ 80.60 print('中央値:', food.median()) # ≈ 79.94 counts, edges = np.histogram(food, bins=8) mid = (edges[np.argmax(counts)] + edges[np.argmax(counts)+1]) / 2 print('最頻階級中点:', mid) # ≈ 76.1 |
結果は 平均 ≈ 80.60、 中央値 ≈ 79.94、 最頻階級中点 ≈ 76.1。 平均 > 中央値 > 最頻値 の順なので右にやや裾を引いた分布。 これは食料費の高い都市県(東京、 神奈川など)が分布の右端を伸ばしているため。
問6:行き 60 km/h、 帰り 30 km/h で同じ距離を往復したとき、 平均速度は?
解答:算術平均では 45 km/h だが、 これは誤り。 距離が同じでかかった時間が違う(行き $d/60$、 帰り $d/30$)ので、 平均速度 = 全距離/全時間 = $2d / (d/60 + d/30) = 2/(1/60+1/30) = 40$ km/h。 これは調和平均。
問7:機械学習で「目的変数の欠損を最頻値で補完したい」場面はどんなとき? 「平均」「中央値」での補完が向くのはそれぞれどんな変数?
解答:
- 最頻値補完:カテゴリ変数(性別、 血液型)、 順序が大きく偏った離散変数。 ラベルとして自然な値を維持できる。
- 平均補完:対称分布の連続変数(身長、 IQ)。 外れ値が少ない場合。
- 中央値補完:歪んだ分布の連続変数(収入、 価格、 反応時間)。 外れ値があっても安定。 sklearn の
SimpleImputer(strategy='median')。
🚧 よくある誤解 — チェックリスト
代表値の解釈・使い方で初学者がつまずきやすいポイントを、 誤解 → 正しい理解の形でまとめます。 自分の分析を点検するチェックリストとして活用してください。
| ❌ よくある誤解 | ✅ 正しい理解 |
|---|---|
| 平均は「典型的な値」 | 対称分布のときだけ。 歪んだ分布では中央値の方が「典型」を表す |
| 外れ値は機械的に除外してよい | ドメイン知識で判断。 真のデータかノイズかを切り分ける |
| 最頻値は1つに決まる | 複数あり得る(二峰性)。 「2つの集団が混在」のサインかも |
| 幾何平均と算術平均は同じ | 成長率・複利には幾何平均。 算術平均では誤った結論に |
| 中央値は順位だから外れ値を完全に無視する | 中央値は「位置」を保証するが、 外れ値の存在自体は箱ひげ図等で別途確認すべき |
| カテゴリ変数に平均を計算してよい | 不可。 名義尺度では最頻値のみ意味を持つ |
| 3人のテスト点数の代表値も意味がある | n が小さいと代表値は不安定。 n ≥ 30 が CLT の目安 |
| 「全国平均」は単純平均でよい | 人口の違う地域を等重みで扱うのは誤り。 人口加重平均が正解 |
| 最頻階級の中点を「最頻値」とすればOK | ビン幅で値が変わる。 KDE で滑らかに推定するのが現代流 |
| 平均が一致すれば分布も同じ | 違う。 ばらつき(分散)と形(歪度・尖度)も見るべき。 アンスコムの四重奏が好例 |
💡 セルフチェック:分析を始める前に「ヒストグラムを描いたか?」「3つの代表値を計算したか?」「外れ値を確認したか?」「サンプルサイズは十分か?」を必ず確認しましょう。
📋 報告フォーマット — 論文・レポートでの書き方
分析結果を報告するときの、 現代的・誠実なフォーマットです。 単に「平均は◯」だけでなく、 分布の文脈ごと示すのがプロの作法。
記述形式の例
「47都道府県の家計食料費(2023年・ SSDSE-B-2026)の中央値は約 80.0 千円/月、 四分位範囲は約 4.0 千円。 分布は右にやや裾を引いており、 平均(80.6 千円)が中央値より高い。 最頻階級は 78.0〜80.0 千円。 (n = 47)」
含めるべき情報
| 項目 | 記述例 | 必須度 |
|---|---|---|
| 中央値(または平均) | $\tilde{x}$ = 437 万円 | ★★★ |
| サンプルサイズ | n = 5,000 | ★★★ |
| ばらつき(IQR/SD) | IQR = [325, 612] / SD = 280 | ★★★ |
| 分布の形 | 右裾を引く(歪度 +2.3) | ★★ |
| 3つの代表値の併記 | 平均 552、 中央値 437、 最頻 380 | ★★ |
| 外れ値の有無 | 上位3件が IQR×1.5 を超えた | ★★ |
| 出典・データ年月 | SSDSE-B-2026、 2023年 | ★★★ |
悪い報告 vs 良い報告
「平均所得は552万円でした。」
問題点:分布の形、 サンプルサイズ、 ばらつき、 中央値が不明。 「552」が代表値として適切かも判断できない。
「世帯所得は右に裾を引く分布で、 中央値は437万円(IQR: 280–680)。 平均は552万円と中央値より高く、 高所得世帯が分布の上端を伸ばしている影響を示唆。 (n=4,500、 厚労省2023)」
改善点:分布の形・中央値・IQR・平均との比較・サンプル・出典がすべて含まれる。
📚 さらに学ぶ — 参考文献とリソース
古典・基本書
- John W. Tukey "Exploratory Data Analysis" (1977) — 中央値・箱ひげ図・ロバスト統計の原典
- Casella & Berger "Statistical Inference" — 推定論の教科書
- Wasserman "All of Statistics" — 現代統計の総論
- 東京大学教養学部統計学教室編 『統計学入門』 — 日本の標準教科書
実装・実務
- Jake VanderPlas "Python Data Science Handbook" — NumPy/Pandas/Matplotlib の総合
- Wes McKinney "Python for Data Analysis" — Pandas の決定版
- scipy.stats 公式ドキュメント — 統計関数のリファレンス
Web リソース
- SSDSE 統計データ活用コンペティション — 47都道府県の社会経済データ
- 政府統計の総合窓口(e-Stat)— 一次データ
- scipy.stats / pandas / NumPy 公式ドキュメント
このページで使ったデータ
- SSDSE-B-2026:47都道府県×112指標のパネルデータ(2023年データを使用)
- 主な変数:食料費 (L322101)、 住居費 (L322102)、 教育費 (L322108)
🐍 Python 実装バリエーション
A. numpy・pandas(最頻出)
1 2 3 4 5 | import numpy as np, pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8', skiprows=1) x = df['食料費'] print(x.mean(), x.median(), x.mode().iloc[0]) print(np.mean(x), np.median(x)) |
B. scipy.stats(mode 厳密版・幾何/調和平均)
1 2 3 4 5 | from scipy import stats print(stats.mode(x, keepdims=False)) # 最頻値 print(stats.gmean(x)) # 幾何平均 print(stats.hmean(x)) # 調和平均 print(stats.trim_mean(x, proportiontocut=0.1)) # 10% トリム平均 |
C. statistics(標準ライブラリ・教育用)
1 2 3 4 | import statistics as st print(st.mean(x), st.median(x), st.mode(x)) print(st.fmean(x)) # float 高速版(Python 3.8+) print(st.geometric_mean(x)) |
D. 加重平均と移動平均
1 2 3 4 5 6 | weights = df['人口'] weighted = np.average(x, weights=weights) print('人口加重平均 =', weighted) # 時系列の移動平均 ma = x.rolling(window=5, center=True).mean() |
E. ロバスト推定(Huber / 中央値ブートストラップ)
1 2 3 4 | from scipy.stats import bootstrap rng = np.random.default_rng(42) res = bootstrap((x.values,), np.median, n_resamples=5000, random_state=rng) print('中央値の 95% CI:', res.confidence_interval) |
⚠️ 代表値の落とし穴 7 連発
1. 外れ値の影響を無視して平均だけ報告する。所得や売上は右に裾が長い(log-normal 系)。 平均と中央値が 1.3〜1.5 倍も乖離することがあります。 「平均年収 600 万」と「中央値年収 440 万」では市場像が全く異なるため、 両方併記するのが鉄則です。
2. 名義尺度に平均を計算してしまう。血液型・職業区分・色などのカテゴリは順序を持たないため、 平均は意味を持ちません(最頻値のみ可)。 ラベルを 0,1,2 に数値化したからといって平均値を出すと、 数学的には計算できても解釈不能な数字になります。
3. 加重平均と単純平均を混同する。「全国平均」と称して 47 都道府県の単純平均を取ると、 人口の少ない島嶼県と東京都が等しい重みになり、 全国民の平均像から大きくずれます。 人口加重平均(np.average(x, weights=人口))を使う場面を見極めましょう。
4. 幾何平均が必要な場面で算術平均を使う。年率成長率の合成、 価格指数(GDP デフレータ)、 比率の平均には幾何平均が正解です。 「年率 +20%・−10%」の平均は (1.2 × 0.9)^0.5 − 1 = +3.9%(算術平均 +5% は誤り)。
5. 多峰分布(multimodal)で代表値を 1 個だけ報告する。2 つのサブ集団が混在しているデータ(男女の身長、 都市/地方の所得)では、 平均も中央値もどちらの集団も代表しません。 ヒストグラム・KDE で多峰性を確認し、 必要なら層別に分けて報告しましょう。
6. 「中央値だから外れ値に強い」を過信する。中央値は確かに頑健ですが、 N が小さい(< 10)と少数の値の入れ替えで大きく動きます。 ブートストラップ CI で中央値の不確実性を可視化することが重要です。
7. 移動平均で「未来からのリーク」を作る。時系列の rolling(window=5, center=True).mean() は対称窓なので、 t 時点の値が「t+2 時点のデータ」を含みます。 予測モデルの特徴量に使うと未来情報が漏れて致命的なので、 必ず center=False(過去のみ)を使いましょう。
📜 歴史 — 4000年の知恵
- 古代バビロニア(紀元前2000年頃):天体観測の誤差を補正するため、 算術平均が使われた
- ピタゴラス学派(紀元前500年頃):算術・幾何・調和の3平均を「音楽の調和」と結びつけた
- Edward Wright(1599):航海術で複数方位観測の中央値を提案
- Gauss(1809):最小二乗法を発明、 平均が正規分布の最尤推定量
- Galton(1869):「median」という用語を導入
- Karl Pearson(1895):「mode」という用語を提唱、 ピアソンの経験式
- Tukey(1977):トリム平均などロバスト統計を体系化