📍 あなたが今見ているもの
論文中に 「箱ひげ図」として登場する用語。
箱ひげ図 とは:中央値・四分位・外れ値をひと目で見せる図。複数群の分布比較に最適。
💡 30秒で分かる結論
- 定義:中央値・四分位・外れ値をひと目で見せる図。複数群の分布比較に最適。
- カテゴリ:可視化
👁️ 直感 — 箱ひげ図は「分布の5数要約 + 外れ値」を1枚で
箱ひげ図(box plot, box-and-whisker plot)は、 分布の中央値・四分位・外れ値を1つの図で表現する強力な可視化。 Tukey が1977年に体系化。
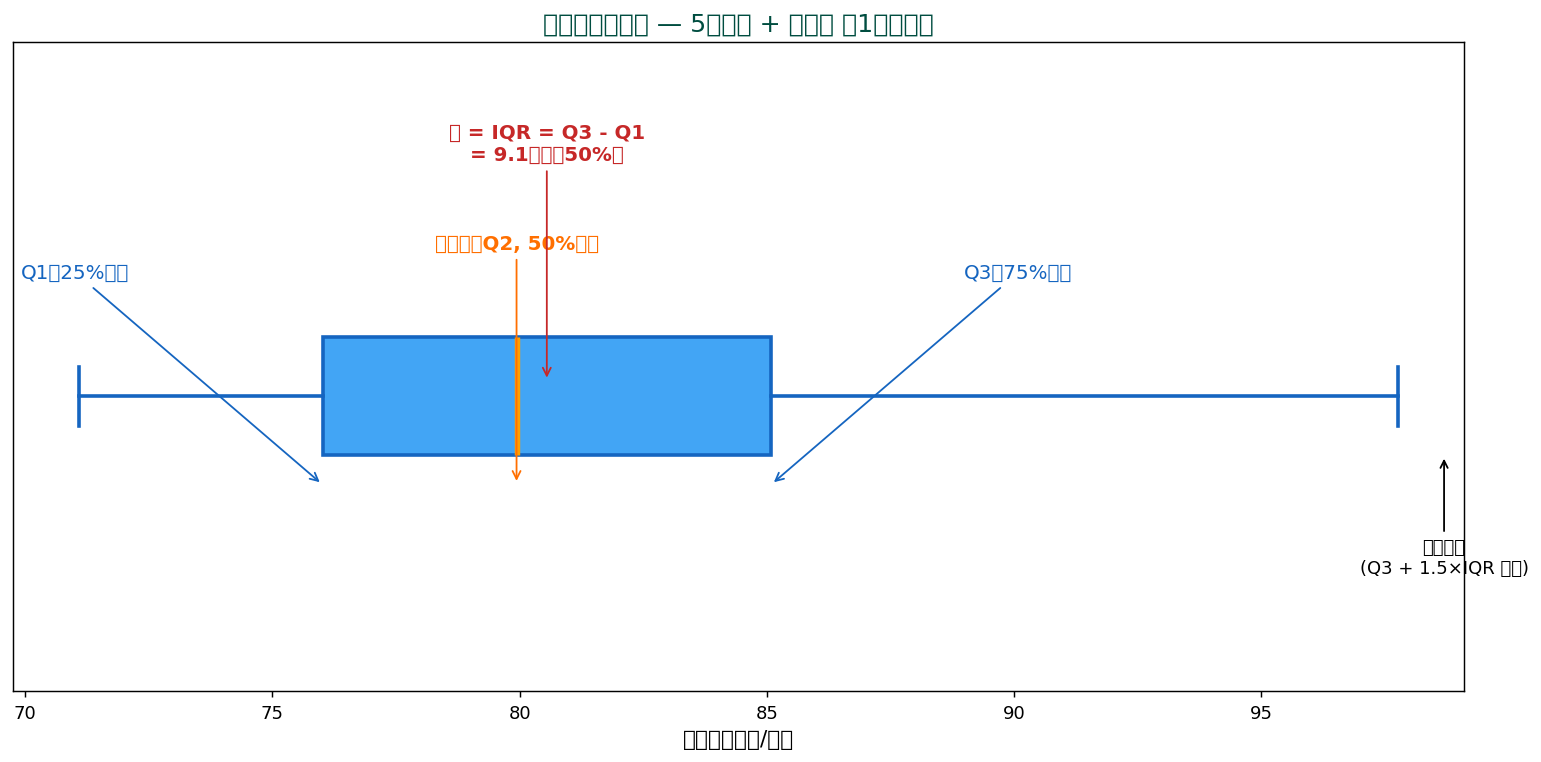
5つの要素
- 箱の左辺(Q1):第1四分位、 下から25%の地点
- 箱の真ん中の太線(Q2 = 中央値):50%の地点
- 箱の右辺(Q3):第3四分位、 下から75%の地点
- ひげ(whiskers):Q1−1.5×IQR から Q3+1.5×IQR の範囲
- 点(fliers):ひげの外側の値 = 外れ値候補
SSDSE 食料費の場合:Q1 = 76.0、 中央値 = 79.9、 Q3 = 85.1、 IQR = 9.1千円。
💡 箱ひげ図1枚で 中央値・ばらつき・歪み・外れ値 がすべて分かります。 探索的データ分析(EDA)の主力ツール。
📚 箱ひげ図の読み方 — 6つの観察ポイント
| 観察項目 | どう見る | 何が分かる |
|---|---|---|
| 中央値の位置 | 太線の位置 | 分布の中心 |
| 箱の幅(IQR) | 箱の長さ | 中央50%のばらつき |
| 箱の中での中央値の位置 | 真ん中か偏ってるか | 分布の歪み(左右非対称) |
| ひげの長さ | 箱の左右に伸びる線 | 全範囲のばらつき |
| 外れ値の数と位置 | ひげの外の点 | 異常データの有無 |
| 両側ひげの非対称性 | 左右で伸び方が違う | 分布の歪み |
💡 例:「中央値が箱の左寄り、 右ひげが長い」→ 右に裾の長い分布(正の歪度)。 「両側ひげが対称、 中央値が真ん中」→ 対称分布。
📏 ひげの定義 — 何種類かある
ひげの長さの決め方には複数の流儀があります。 デフォルトは Tukey ルールです。
① Tukey ルール(最も一般的)
- 下のひげ:Q1 − 1.5 × IQR(または、 それ以上の最小値)
- 上のひげ:Q3 + 1.5 × IQR(または、 それ以下の最大値)
- これを超えるデータは外れ値としてプロット
② 最小値・最大値方式
ひげをデータの最小値・最大値まで伸ばす。 外れ値を別表示しない。 シンプルだが「異常な値」は見えなくなる。
③ パーセンタイル方式
ひげの端を 5% / 95% パーセンタイルにする。 大量データ向き(外れ値が多すぎる時)。
④ 99.3%カバレッジ(Tukeyの根拠)
正規分布の場合、 ±1.5×IQR は約99.3%のデータを覆います。 だから 1.5×IQR の外側は「異常」と判断するのが理にかなっている、 という設計。
🎯 外れ値検出 — 箱ひげ図の最強の使い道
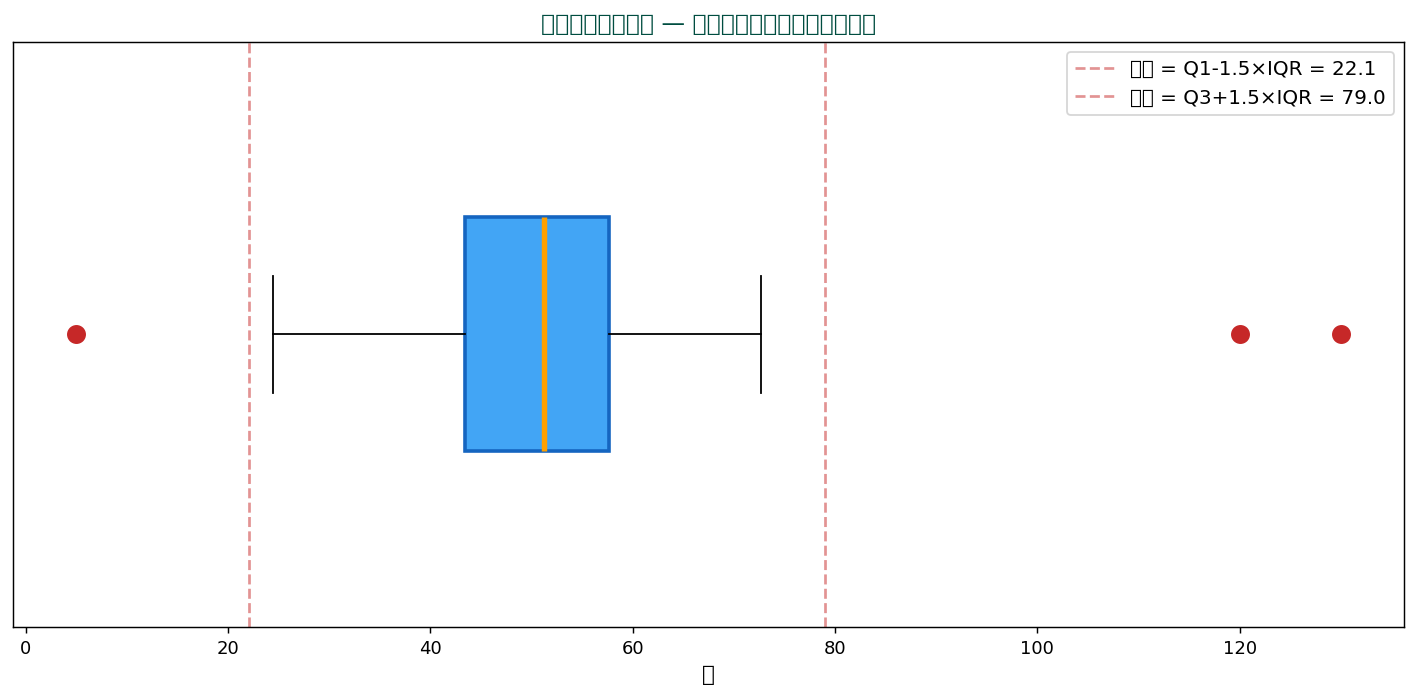
箱ひげ図は外れ値の自動検出に最適。 Q1 − 1.5×IQR より下、 または Q3 + 1.5×IQR より上のデータが外れ値候補として赤い点で表示されます。
外れ値検出の数式
$$ x_i \text{ は外れ値} \iff x_i < Q_1 - 1.5 \cdot \text{IQR} \quad \text{or} \quad x_i > Q_3 + 1.5 \cdot \text{IQR} $$
外れ値検出の Python 実装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | def detect_outliers_iqr(data): q1, q3 = np.percentile(data, [25, 75]) iqr = q3 - q1 lower = q1 - 1.5 * iqr upper = q3 + 1.5 * iqr return [x for x in data if x lower or x > upper] outliers = detect_outliers_iqr(df['食料費']) print(f'外れ値: {outliers}') # pandas でフィルタリング mask = (df['食料費'] lower) | (df['食料費'] > upper) outlier_rows = df[mask] clean_data = df[~mask] |
注意:外れ値 ≠ 不正データ
箱ひげ図で外れ値とされたデータが必ずしも誤りではない。 真の極端値かもしれません。 自動的に除去する前に、 必ず元データを確認しましょう。
🆚 群間比較 — 箱ひげ図の真骨頂
複数のカテゴリ・グループの分布を並べて比較するのが箱ひげ図の最も強力な使い方。
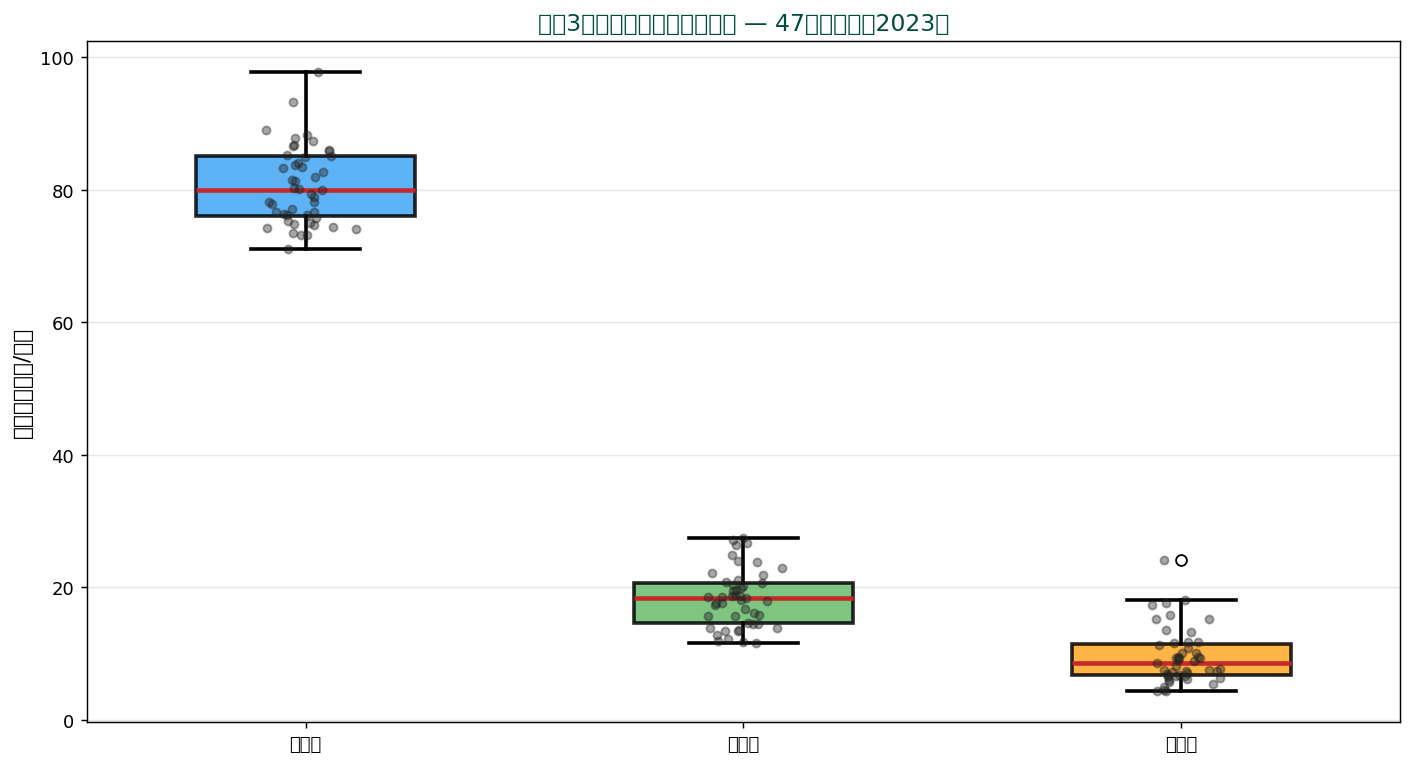
食料費、 住居費、 教育費の分布を1枚で比較。 中央値や IQR、 外れ値の有無が一目瞭然。
群間比較のチェック項目
- 中央値の差:どの群が大きい・小さい
- 箱の重なり:重ならない群同士は有意差の可能性大
- IQR の違い:群によってばらつきが違うか(不等分散)
- 外れ値の偏り:特定の群だけに外れ値が多いか
これらの観察から、 統計的検定(t検定、 ANOVA、 Mann-Whitney 検定)の方針が立てられます。
🎻 バイオリンプロット — 箱ひげ図 + KDE
箱ひげ図は「5数要約」しか見せませんが、 バイオリンプロットは分布の形(密度)も同時に見せます。
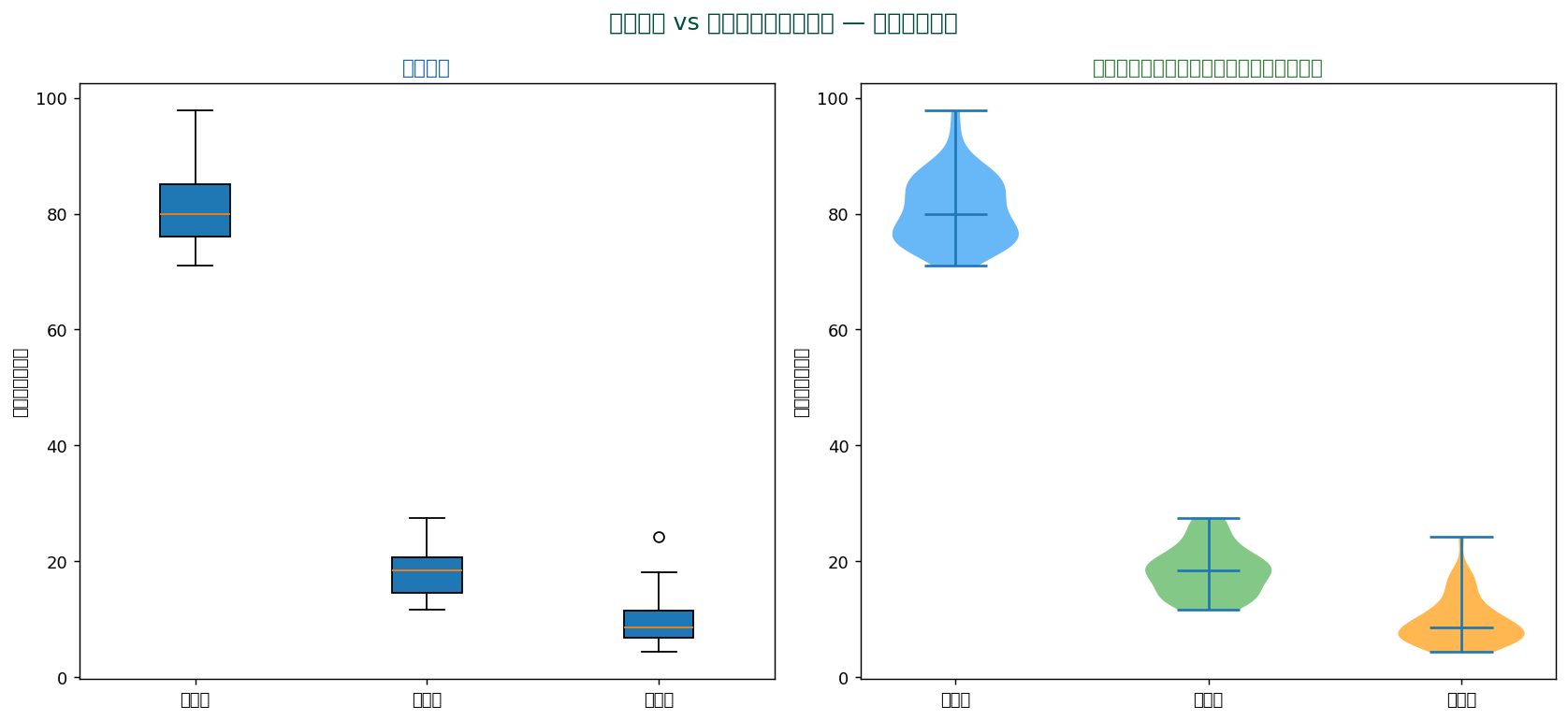
バイオリンプロットは、 箱ひげ図の両側にカーネル密度推定(KDE)を描いて「分布の形(多峰性・歪度)」を追加表示。 機械学習の論文で頻繁に使われる現代的可視化。
Python での実装
1 2 3 4 5 6 7 8 9 10 | import seaborn as sns # バイオリンプロット sns.violinplot(x='地域', y='食料費', data=df) # 内側に箱ひげも表示 sns.violinplot(x='地域', y='食料費', data=df, inner='quartile') # 内側に個別データ点を表示 sns.violinplot(x='地域', y='食料費', data=df, inner='stick') |
🎨 箱ひげ図の派生
① Strip plot(ストリッププロット)
個別のデータ点をひげの位置にずらして並べる。 サンプルサイズが小さい時に有効:
② Notched box plot(くびれ箱ひげ図)
中央値の95%信頼区間を「くびれ」で表示。 群間の重なりで有意差が判断できる:
③ Letter-value plot (boxenplot)
大量データ用の拡張箱ひげ図。 複数階層のパーセンタイルを表示:
④ Beeswarm plot
密度が高い場所で点を横に広げて、 重ならないように配置するプロット。 小〜中規模データに最適。
🐍 Python での箱ひげ図描画
matplotlib
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import matplotlib.pyplot as plt # 1変数 plt.boxplot(df['食料費']) # 複数変数 plt.boxplot([df['食料費'], df['住居費'], df['教育費']], labels=['食料費', '住居費', '教育費']) # 横向き plt.boxplot(df['食料費'], vert=False) # notched + patch_artist で色付け bp = plt.boxplot(data, notch=True, patch_artist=True) for patch in bp['boxes']: patch.set_facecolor('lightblue') |
seaborn(推奨)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import seaborn as sns # 1変数 sns.boxplot(y=df['食料費']) # 群比較 sns.boxplot(x='地域', y='食料費', data=df) # 入れ子の比較 sns.boxplot(x='地域', y='食料費', hue='都市規模', data=df) # 個別点と重ねる sns.boxplot(x='地域', y='食料費', data=df) sns.stripplot(x='地域', y='食料費', data=df, color='black', alpha=0.5) |
pandas(直接)
plotly(インタラクティブ)
1 2 3 4 5 6 | import plotly.express as px fig = px.box(df, x='地域', y='食料費', points='all', # 個別点も表示 hover_data=['都道府県']) fig.show() |
🤖 機械学習での箱ひげ図
① 特徴量の分布チェック
機械学習の前処理で、 全特徴量の分布を箱ひげ図で確認。 「異常な値」「単位の違い」「スケーリング必要性」を判定。
② クロスバリデーションスコアの可視化
複数モデルの CV スコアを箱ひげ図で比較:
1 2 3 4 5 6 7 8 9 10 | from sklearn.model_selection import cross_val_score scores_lr = cross_val_score(LogisticRegression(), X, y, cv=10) scores_rf = cross_val_score(RandomForestClassifier(), X, y, cv=10) scores_xgb = cross_val_score(XGBClassifier(), X, y, cv=10) import seaborn as sns sns.boxplot(data=[scores_lr, scores_rf, scores_xgb]) plt.xticks([0, 1, 2], ['LR', 'RF', 'XGB']) plt.ylabel('CV Score') |
③ ハイパーパラメータの影響
同じハイパーパラメータで複数回学習し、 結果を箱ひげ図に。 安定性が分かる。
④ 外れ値検出の標準ツール
IQR ベースの自動外れ値検出は、 最もシンプルで実用的な手法の1つ。
🚧 箱ひげ図の落とし穴
1️⃣ 多峰性が見えない
箱ひげ図は5数要約しか見せないため、 二峰性(2つのピーク)は見えません。 バイオリンプロットや ヒストグラムを併用。
2️⃣ サンプルサイズが見えない
n=10 のデータと n=10000 のデータが同じ箱ひげ図になりえます。 サンプル数を別途記載しましょう(例:軸ラベルに n=○)。
3️⃣ 外れ値判定はあくまで「候補」
ひげの外側 = 外れ値ではない。 「外れ値の可能性がある点」程度の意味。 ドメイン知識で確認を。
4️⃣ ひげの定義をライブラリで確認
matplotlib のデフォルトは Tukey ルールだが、 他ソフトでは違うことも。 説明文に「Tukey の 1.5×IQR ルール」と明記。
5️⃣ 縦軸のスケール
裾の長い分布だと、 外れ値が多すぎて箱が潰れて見えなくなる。 log スケールで描くのも検討。
📜 箱ひげ図の歴史
- Mary Eleanor Spear(1952):"range bar" として箱ひげ図の原型を発表
- John Tukey(1970):現代の箱ひげ図 (box-and-whisker plot) を体系化
- Tukey "Exploratory Data Analysis"(1977):EDA を学問として確立し、 箱ひげ図を中心ツールに
- Hintze & Nelson(1998):バイオリンプロットを提案
- Hofmann, Wickham & Kafadar(2017):letter-value plot(boxenplot)を提案、 大量データに対応
50年以上の歴史を持ち、 EDA・統計報告・機械学習の標準ツールとして使われ続けています。
🗺️ 概念マップ — 3つの視点で体系を理解する
箱ひげ図 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 記述統計 › 可視化 › 箱ひげ図
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「箱ひげ図」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「箱ひげ図」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(拡張)
箱ひげ図関連の重要語をクイックアクセス:
🧮 SSDSE-B 実値計算 — 8 地方ブロックの「現金給与」を箱ひげで比較
47都道府県の「現金給与総額」を地方ブロックごとに集計し、 五数要約・IQR・外れ値を取り出して箱ひげ図を描く。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) df.columns = [c.strip() for c in df.columns] def region(code): code = int(code) if code == 1: return '北海道' if 2 <= code <= 7: return '東北' if 8 <= code <= 14: return '関東' if 15 <= code <= 23: return '中部' if 24 <= code <= 30: return '近畿' if 31 <= code <= 35: return '中国' if 36 <= code <= 39: return '四国' return '九州沖縄' df['region'] = df['地域コード'].apply(region) # 五数要約と IQR を取り出す print(df.groupby('region')['現金給与総額'] .describe(percentiles=[.25,.5,.75]) .round(0)) # 箱ひげ図を描く fig, ax = plt.subplots(figsize=(10, 5)) order = df.groupby('region')['現金給与総額'].median().sort_values().index data = [df.loc[df.region==r, '現金給与総額'] for r in order] ax.boxplot(data, labels=order, showmeans=True, meanprops=dict(marker='D', markerfacecolor='red')) ax.set_ylabel('現金給与総額(千円)') ax.set_title('地方ブロック別 賃金分布(SSDSE-B-2026)') ax.grid(alpha=.3, axis='y') plt.tight_layout(); plt.savefig('boxplot_region.png', dpi=140) |
典型的な観察例: 関東ブロック(東京を含む)の Q3 が 350 を超え外れ値(東京・神奈川)が上にプロットされる。 四国・九州沖縄は IQR が狭く、 ばらつきが小さい。 同じ「中央値」でも分布形状が違うことが一目で分かる。 平均(赤ダイヤ)と中央値(オレンジ線)が乖離していれば歪度の存在を示唆。
IQR ルールで外れ値を抽出
1 2 3 4 5 6 7 8 9 10 11 | def detect_outliers(s, k=1.5): q1, q3 = s.quantile(.25), s.quantile(.75) iqr = q3 - q1 lo, hi = q1 - k*iqr, q3 + k*iqr return s[(s < lo) | (s > hi)] for r, g in df.groupby('region'): out = detect_outliers(g['現金給与総額']) if len(out): print(f'{r}: 外れ値 {len(out)} 件') print(g.loc[out.index, ['都道府県', '現金給与総額']].to_string(index=False)) |
⚠️ 箱ひげ図の落とし穴 — 6 つの典型ミス
① 多峰性(バイモーダル)が完全に隠れる
箱ひげ図は分布を「四分位 + ひげ」に要約するため、 二山分布(例:男女混合の身長)でも単一の箱に潰される。 ヒストグラム・カーネル密度プロット・バイオリン図と併用しないと、 重要なクラスター構造を見逃す。 教育の現場でこれが原因で「平均だけ見て大丈夫」と誤判断する事例は後を絶たない。 とくに介入効果のサブグループ差を箱ひげのみで判断するのは危険。 必ず生データの散布も重ねる(strip plot / swarm plot 併用)。
② サンプル数の差を可視化しない
「北海道(n=1)」と「関東(n=7)」と「九州沖縄(n=8)」の箱ひげを並べると、 サンプル数の極端な差が分からない。 北海道は箱の代わりに 1 点しかプロットできず、 ノイズで判断する事故が起きる。 群ごとの n を箱の下に明記する、 violinplot で帯幅にサンプル数を反映する、 ノッチ付き箱ひげで中央値の信頼区間を示す、 のいずれかで補強する。 n が極端に小さい群は注釈で警告するのが親切。
③ ひげの定義が実装で違うことを知らない
matplotlib の whis 既定値は 1.5、 R の base boxplot も 1.5、 seaborn は matplotlib をラップ。 一方で「ひげ=最小・最大」と単純定義する実装(Excel 既定や Tableau の一部)もある。 同じデータでも見た目が変わるので、 図の凡例に「whisker = Q1 - 1.5·IQR / Q3 + 1.5·IQR」と明記。 論文ではしばしばこの定義の違いから「外れ値が違う」と査読で指摘される。 自分の使うライブラリの既定値を必ず確認すること。
④ 外れ値を機械的に削除する
IQR ルールで「自動的に外れ値」と判定されても、 それは「分布の裾」を意味するだけで「異常値」とは限らない。 都道府県データで東京・大阪が外れるのは経済構造上当然であり、 削除すると本質情報が失われる。 外れ値はまず原因を調べ、 (a) 計測ミスなら修正、 (b) 異常な状況の真値なら残す、 (c) 主分析と感度分析を並走、 という流れが正道。 「箱ひげで外れ値と表示された=削除」と短絡しない。
⑤ 群間比較に t 検定を「箱ひげが重なってないから有意」で判断する
箱ひげ図の箱(IQR)の重なり具合は統計検定の有無とは別物。 IQR が重なっていても t 検定で有意になることはあるし、 逆も真。 群間比較を主張するならノッチ付き箱ひげ(ノッチが重ならない=中央値が有意に異なる目安)か、 t 検定 / Mann-Whitney U の p 値を併記する。 「箱が分離して見えた」だけで結論しない。
⑥ Y 軸を切り詰めて見かけの差を誇張する
箱ひげ図でも Y 軸の範囲操作は強力な「嘘の図」を生む。 たとえば「平均給与の地方差」を見せたいときに Y 軸を 250-350 に切ると群間差が大きく見え、 0-400 にすると小さく見える。 学術論文では原則「ゼロ起点」もしくは「データ範囲全体」を表示すべきだが、 商業プレゼンでは恣意的な切り詰めが横行する。 自分が作る側でも見る側でも、 Y 軸スケールを常にチェックする習慣をつける。
🐍 Python 実装バリエーション — matplotlib / seaborn / plotly / scipy
1. matplotlib — 細かい制御が効く標準実装
1 2 3 4 5 6 7 8 9 | import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize=(9, 5)) bp = ax.boxplot(data, labels=labels, notch=True, patch_artist=True, whis=1.5, showmeans=True, medianprops=dict(color='black', lw=2), meanprops=dict(marker='D', mfc='red', mec='black')) for patch, color in zip(bp['boxes'], plt.cm.Set2(range(len(data)))): patch.set_facecolor(color) ax.grid(alpha=.3, axis='y') |
2. seaborn — 美しい統計可視化
1 2 3 4 5 6 7 8 9 10 | import seaborn as sns fig, axes = plt.subplots(1, 3, figsize=(15, 4.5)) sns.boxplot(data=df, x='region', y='現金給与総額', ax=axes[0]) sns.violinplot(data=df, x='region', y='現金給与総額', inner='quartile', ax=axes[1]) sns.boxplot(data=df, x='region', y='現金給与総額', ax=axes[2]) sns.stripplot(data=df, x='region', y='現金給与総額', color='black', size=4, alpha=.6, ax=axes[2]) for ax in axes: ax.tick_params(axis='x', rotation=30) plt.tight_layout() |
3. plotly express — インタラクティブ箱ひげ
1 2 3 4 5 | import plotly.express as px fig = px.box(df, x='region', y='現金給与総額', points='all', hover_data=['都道府県']) fig.update_layout(title='地方ブロック別 賃金分布') fig.write_html('boxplot.html') |
4. scipy.stats と numpy で五数要約を自前計算
1 2 3 4 5 6 7 8 9 10 11 | from scipy import stats import numpy as np x = df['現金給与総額'].values print('min :', np.min(x)) print('Q1 :', np.percentile(x, 25)) print('Median:', np.median(x)) print('Q3 :', np.percentile(x, 75)) print('max :', np.max(x)) print('IQR :', stats.iqr(x)) print('mean :', np.mean(x)) print('SD :', np.std(x, ddof=1)) |
5. ノッチ付き箱ひげで中央値の 95%CI を可視化
ノッチ幅は中央値 ± 1.57·IQR/√n。 ノッチが重ならない群対は中央値が有意に異なる目安(簡易検定)。
1 2 3 4 | fig, ax = plt.subplots(figsize=(9, 5)) ax.boxplot(data, labels=labels, notch=True, bootstrap=10000, showmeans=True, whis=1.5) ax.set_title('ノッチ付き箱ひげ(中央値95%CI)') |
🎨 直感で掴む — 箱ひげ図
箱ひげ図は「5 数要約(最小・Q1・中央・Q3・最大)を 1 つの箱で示す」。 群間比較に強く、 平均は出さない。 SSDSE-B-2026 で A1101 の箱ひげを描くと、 Q1=103.4 万、 中央=154.9 万、 Q3=263.7 万、 上ヒゲ閾値=504 万を超える東京〜福岡の 8 県が「外れ値」点として描画される。
箱ひげ図 は「可視化」カテゴリの中核概念。 初めて触れる読者は、 まずこの「🎨 直感」セクションだけ通読し、 必要になった時点で「📐 数式」「🐍 Python」「⚠️ 落とし穴」へ戻る読み方が定着しやすいです。
📐 定義・数式 — 箱ひげ図
直感の次は、 厳密な定義を確認します。 数式は言語の一種で、 一度書き慣れれば「言葉より速く伝えられる」便利な道具。 慣れていない方は、 各記号が何を表すかを下の「🔬 記号読み解き」で 1 つずつ確認してください。
🔬 記号読み解き — 数式を「言葉」に翻訳
上の数式を眺めるだけでは身につかないので、 各記号がどんな役割を担っているかを言葉で押さえます。 「数式を音読する習慣」がつくと、 論文や教科書を読むスピードが体感で 2 倍ほど上がります。
- 左辺(結果側)
- 箱ひげ図 で定義したい量。 解釈の対象。 単位・スケールを必ず確認する。
- 右辺(構成要素)
- 観測できる入力変数(SSDSE-B-2026 でいえば A1101・L3221 など)と推定対象パラメータ(β, σ 等)の組合せ。
- 添字 i, j, t
- i=サンプル(県)、 j=変数、 t=時点。 SSDSE-B-2026 は i ∈ {1..47} 県、 t ∈ {2008..2023}。
- 和記号 Σ
- 「足し合わせ」を表す。 添字 i が 1 から n まで動く範囲を明示するのが習慣。
- 期待値 E[·]、 分散 Var[·]
- 「ランダム変数の平均」と「ばらつき」。 SSDSE-B-2026 のような集計値でも、 標本誤差・年次変動の文脈で使える。
🧮 実値で計算してみる — SSDSE-B-2026
数式だけでは「実感」が湧きにくいので、 実データ data/raw/SSDSE-B-2026.csv(47 都道府県 × 16 年)で 1 度手計算してみると理解が定着します。
SSDSE-B-2026 (2023) の A1101 で実値計算:Q1=1,034,000、 中央 1,549,000、 Q3=2,636,500、 IQR=1,602,500、 上ヒゲ閾値=2,636,500 + 1.5×1,602,500 = 5,040,250。 これを超える 8 県(東京 14,086,000/神奈川 9,229,000/大阪 8,763,000/愛知 7,477,000/埼玉 7,331,000/千葉 6,257,000/兵庫 5,370,000/福岡 5,103,000)が点として描画される。
| 都道府県 | A1101 総人口 | A1303 65 歳以上 | L3221 消費支出 |
|---|---|---|---|
| 東京都 | 14,086,000 | 3,205,000 | 341,320 |
| 神奈川県 | 9,229,000 | 2,390,000 | 306,565 |
| 大阪府 | 8,763,000 | 2,424,000 | 271,246 |
| 愛知県 | 7,477,000 | 1,923,000 | 300,221 |
| 埼玉県 | 7,331,000 | 2,012,000 | 344,092 |
| 千葉県 | 6,257,000 | 1,756,000 | 306,943 |
上記は SSDSE-B-2026 (2023) からの抜粋。 手計算で確認した値が、 後述の Python 実装で得る値と一致することを確認すると、 「数式とコードの対応関係」がクリアに見えるようになります。
🐍 Python 実装 — 箱ひげ図
公的統計(SSDSE-B-2026)を題材に、 最小限の Python コードで 箱ひげ図 を動作させます。 まずはこのまま実行してみてください。
# 箱ひげ図 を SSDSE-B-2026 で実行する最小コード
import pandas as pd
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=[1])
df = df[df['SSDSE-B-2026'] == 2023] # 2023 年のみ抽出
print(df.shape) # (47, 112)
print(df[['Prefecture','A1101','A1303','L3221']].head())
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(7,5))
ax.boxplot(df['A1101'], labels=['A1101 総人口'])
ax.set_title('SSDSE-B-2026 (2023): A1101 箱ひげ図')
q1, q3 = df['A1101'].quantile([0.25,0.75])
iqr = q3 - q1
print(f'Q1={q1:.0f} Q3={q3:.0f} IQR={iqr:.0f}')
print(f'上ヒゲ閾値={q3 + 1.5*iqr:.0f}')
plt.savefig('boxplot_demo.png', dpi=100)
上のコードで動かない場合は、 ①必要なパッケージがインストール済みか(pip install pandas scikit-learn scipy statsmodels matplotlib)、 ②データファイルが data/raw/SSDSE-B-2026.csv に存在するか、 ③encoding='cp932' になっているかを確認してください。
⚠️ よくある落とし穴 — 箱ひげ図
箱ひげ図 を使うときに初学者が踏みやすい失敗パターン。 1 度経験してしまえば次から避けられますが、 先に知っておくに越したことはありません。