📍 あなたが今見ているもの
論文中に 「ヒストグラム」として登場する用語。
ヒストグラム とは:1変数の分布を区間(bin)に分けて棒グラフで表す。データの「形」(対称か偏りか)を一目で把握。
💡 30秒で分かる結論
- 定義:1変数の分布を区間(bin)に分けて棒グラフで表す。データの「形」(対称か偏りか)を一目で把握。
- カテゴリ:可視化
📖 もっと詳しく
ヒストグラム(histogram)は、 1変数の分布を視覚化する基本ツール。 データを区間(ビン)に分けて、 各区間に入る個数を棒の高さで示します。 分析の前に「データの形」を把握する ための必須ステップ。
読み取りポイント:
- 分布の形:左右対称(正規分布的)/ 右に裾長(所得分布的)/ 双峰(2つの山)
- 中心位置:山の頂点はどこか(平均・中央値)
- 広がり:横幅が標準偏差を反映
- 外れ値:本体から大きく離れた棒
- 欠損や打ち切り:端での不自然な集積
ビン幅の選び方が重要:細すぎるとノイズが見え、 粗すぎると構造が消えます。 Sturges、 Scott、 Freedman-Diaconis などの自動ルールがあり、 matplotlib のデフォルトは Auto。 不安なら複数のビン幅で確認するか、 カーネル密度推定(KDE)を並べて見るのが安全。
👁️ 直感 — ヒストグラムは「分布の形が見える」
ヒストグラム(histogram)は、 数値データの分布の形を視覚化する最も基本的なグラフ。 データを階級(ビン)に分け、 各ビンに入る件数(頻度)を棒の高さで表します。
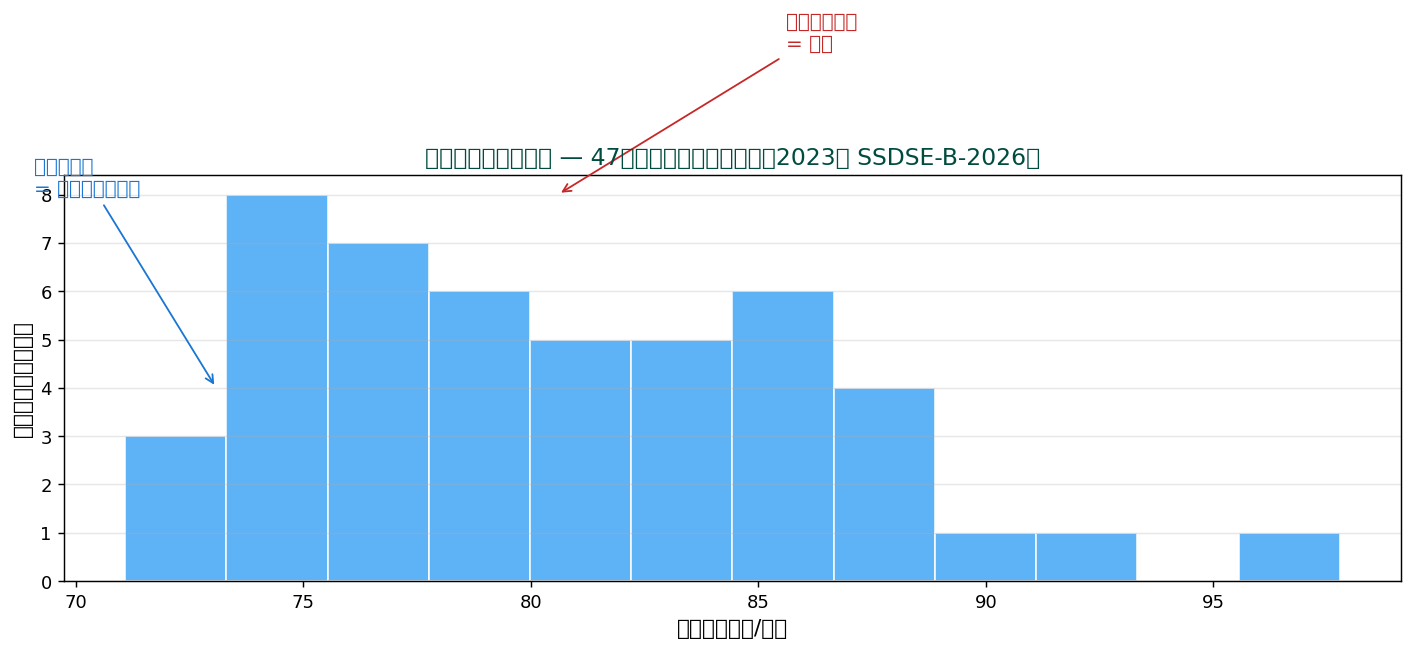
47都道府県の家計食料費を例に。 横軸が食料費の値、 縦軸が「その値の範囲に何県あるか」。 山型の分布が一目で分かります。
💡 ヒストグラムを描けば、 分布の中心、 ばらつき、 歪み、 外れ値、 多峰性のすべてが一目で見えます。 データ分析の最初に必ず描くべき図。
🧮 ヒストグラムの作り方 — 4ステップ
- データの範囲を決める:最小値〜最大値
- ビン(階級)に分ける:通常 5〜30 個
- 各ビンの頻度を数える:そのビンに入るデータの個数
- 棒で描画:横軸=ビン、 縦軸=頻度
具体例:東北6県の食料費
仮にデータが [78.1, 79.0, 82.0, 83.8, 84.1, 76.0] とする:
- 範囲:76.0〜84.1(幅 8.1)
- ビン幅:3.0 とする → ビン: [76, 79), [79, 82), [82, 85)
- 頻度カウント:[76,79) → 2件、 [79,82) → 1件、 [82,85) → 3件
- 棒の高さ:2, 1, 3
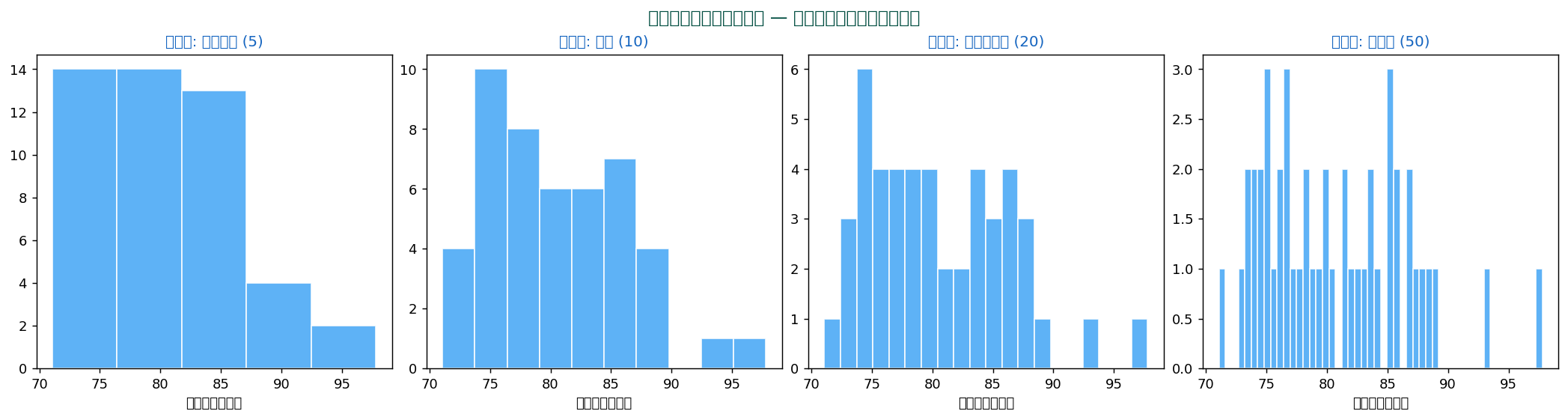
📏 ビン数の選び方 — 適切な「粒度」を決める
ヒストグラムで最も重要な選択がビン数(または階級幅)。 多すぎても少なすぎても分布の形を見誤ります。
古典的ルール
| ルール | 公式 | 特徴 |
|---|---|---|
| Sturges | k = log₂(n) + 1 | n が小さい時向き。 n=47 → k=7 |
| Rice | k = 2·n^(1/3) | Sturges の代替。 n=47 → k=7 |
| Scott | 幅 = 3.5σ / n^(1/3) | 正規分布前提 |
| Freedman-Diaconis | 幅 = 2·IQR / n^(1/3) | 外れ値に強い。 推奨 |
| √n | k = √n | 簡便な経験則 |
実用的判断
- n < 50:5〜10 個のビン
- 50 ≤ n < 500:10〜25 個
- n ≥ 500:25〜50 個
- 外れ値や歪みがある場合:Freedman-Diaconis を試す
Python では
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import numpy as np import matplotlib.pyplot as plt # matplotlib: bins='auto' で Sturges + Freedman-Diaconis の組合せ plt.hist(data, bins='auto') # 個別指定 plt.hist(data, bins=20) plt.hist(data, bins='sturges') plt.hist(data, bins='fd') # Freedman-Diaconis plt.hist(data, bins='scott') # numpy.histogram_bin_edges で値の境界だけ取得 edges = np.histogram_bin_edges(data, bins='fd') |
📈 ヒストグラムで見える分布の形
ヒストグラムは分布の「形」を読み取るための強力なツール。 形から多くの情報が分かります。
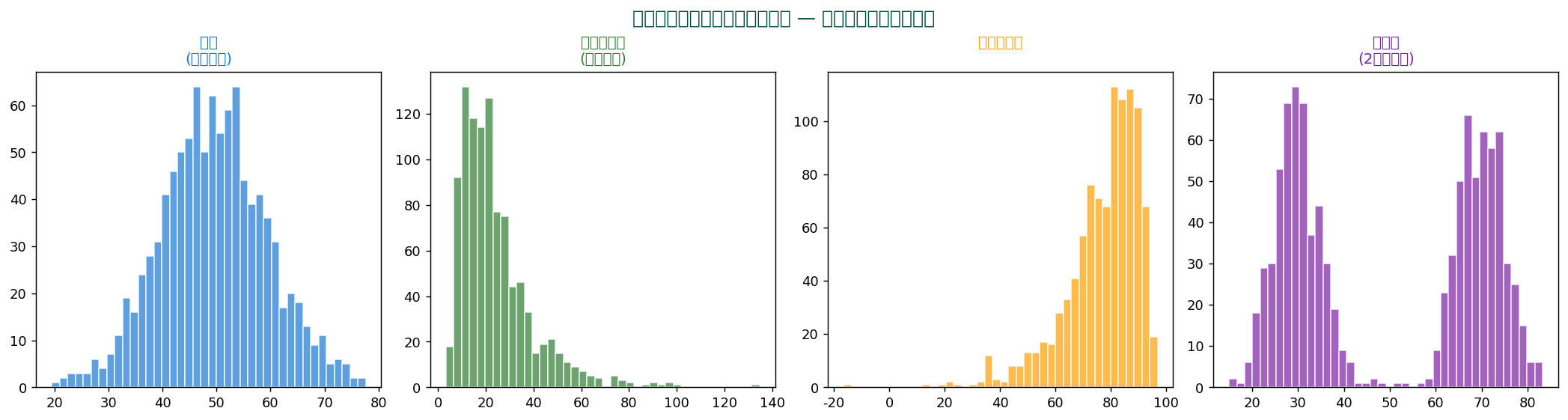
診断チェックリスト
- 対称か? → 正規分布に近い → 平均・標準偏差が代表値として有効
- 右に裾(正の歪度)→ 所得分布、 株価変動 → 中央値が安全
- 左に裾(負の歪度)→ 簡単なテスト点数など → 中央値が安全
- 山が複数(多峰性)→ 集団が混在している可能性
- 端に偏り→ 上限・下限が存在(censoring)
- 飛び地(gap)→ 2つの異なる過程が混在
🎯 頻度 vs 密度 vs KDE
ヒストグラムには「頻度」と「密度」の2種類の表記があります。
頻度 (frequency)
縦軸 = そのビンに入るデータの個数(整数)。 一番直感的。
密度 (density)
縦軸 = 頻度 ÷ (n × ビン幅)。 全体の面積が1になるよう正規化。 異なるビン幅やサンプルサイズのヒストグラムを比較するときに使用。
KDE(カーネル密度推定)
ヒストグラムを「滑らかに」したもの。 ビン幅の影響を受けにくく、 連続的な分布が見える。
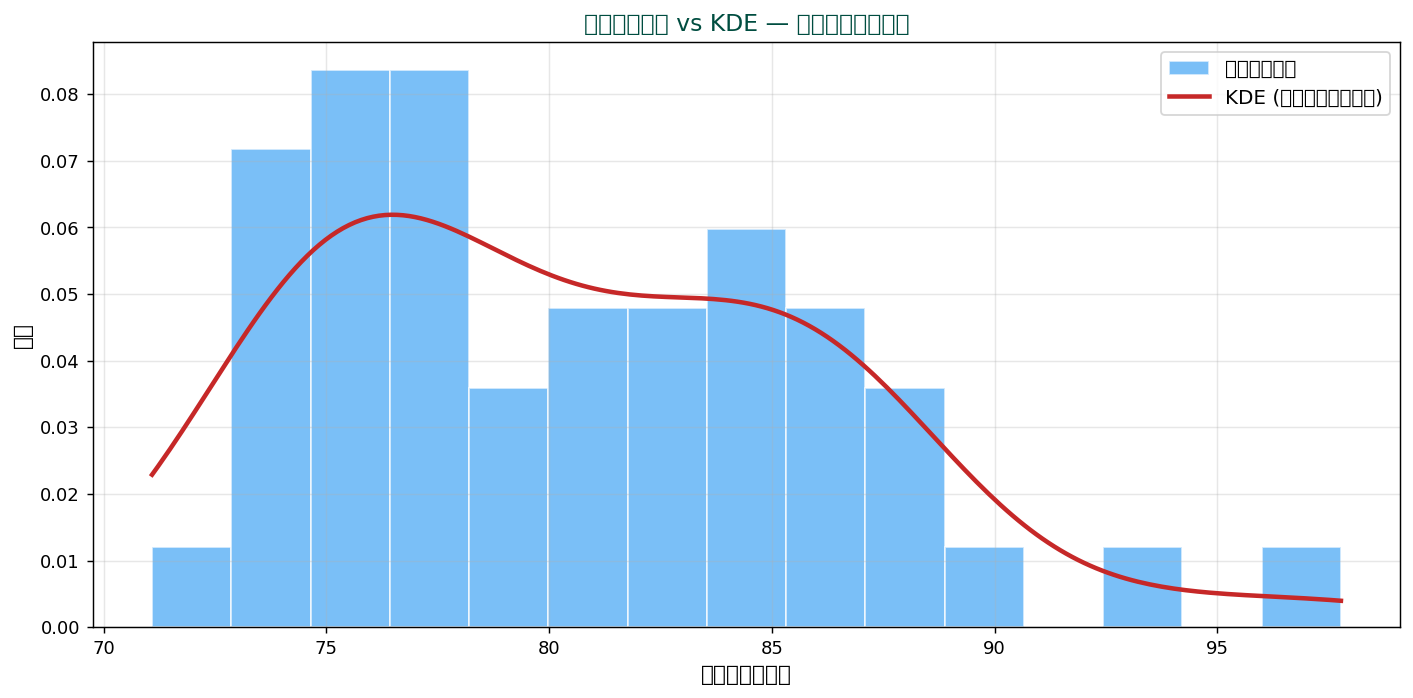
KDE は scipy.stats.gaussian_kde や seaborn.kdeplot で簡単に描けます。 ヒストグラムと併用するとさらに情報量が増えます。
🆚 群間比較ヒストグラム
2つ以上のグループの分布を重ねて比較できます。 「東日本と西日本では食料費の分布が違うか?」など。
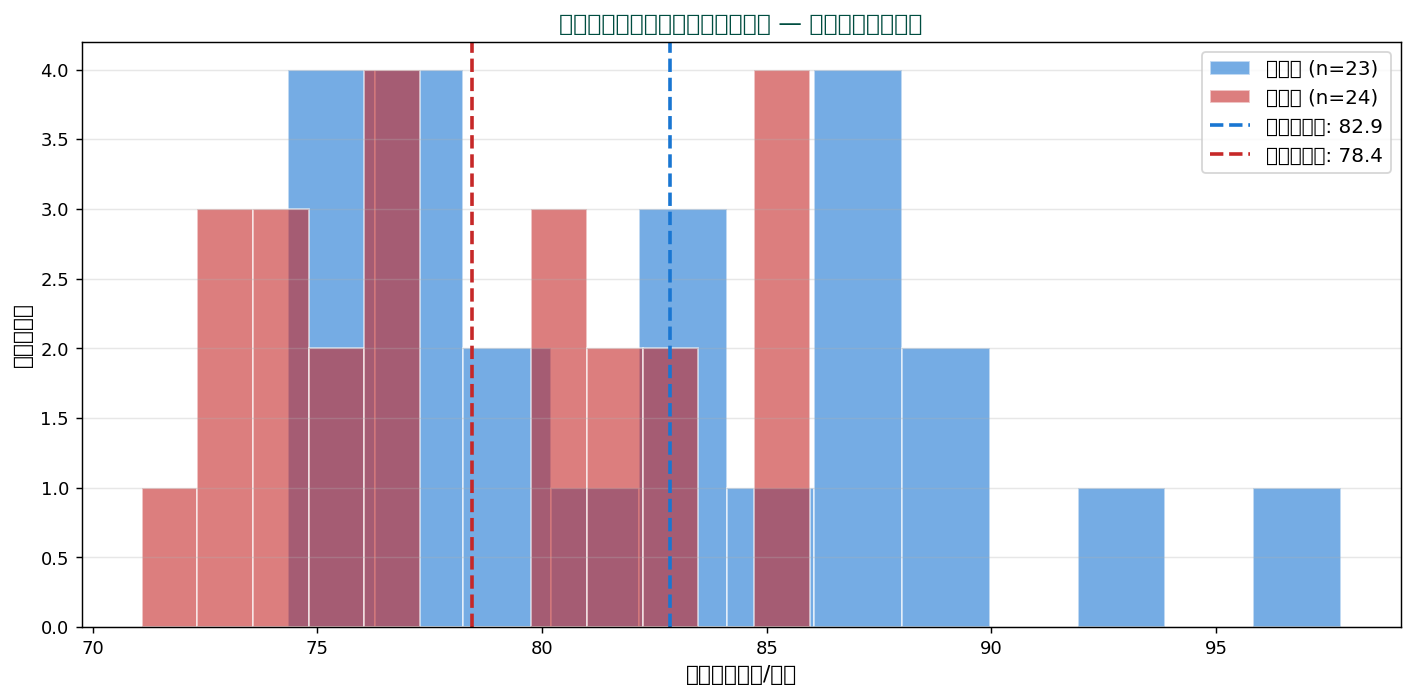
東日本と西日本でほぼ同じ分布。 平均にも大きな違いはなさそうです。 仮説検定(t検定)で違いの有意性を確認するのが次のステップ。
seaborn での群間比較
1 2 3 4 5 6 7 8 9 10 11 12 13 | import seaborn as sns # 重ね合わせ sns.histplot(data=df, x='食料費', hue='地域', alpha=0.5, kde=True) # 並べる sns.histplot(data=df, x='食料費', hue='地域', multiple='dodge') # 積み上げ sns.histplot(data=df, x='食料費', hue='地域', multiple='stack') # 確率密度として正規化(群間サイズが違っても比較可) sns.histplot(data=df, x='食料費', hue='地域', stat='density', common_norm=False) |
🎨 ヒストグラムの派生
① 2次元ヒストグラム(ヒートマップ)
2変数の関係を見るとき、 散布図ではデータが重なりすぎることがある。 そんなときは2Dヒストグラム:
② 累積ヒストグラム
「ある値以下のデータの累計」を示す:
③ Ridgeline plot(リッジラインプロット)
多くのグループのKDEを縦に並べる。 月ごとの売上分布、 業界ごとの給料分布などに有効。 seaborn や joypy ライブラリ。
④ 帯ヒストグラム(rug plot)
ヒストグラムの下に個々のデータ点を「縦棒」で表示。 サンプルサイズが少ない時に各点を可視化:
1 | sns.histplot(data, kde=True, rug=True) |
🐍 Python での描画
matplotlib(基本)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') # 基本ヒストグラム plt.figure(figsize=(10, 5)) plt.hist(df['食料費'], bins=15, color='steelblue', edgecolor='white') plt.xlabel('食料費') plt.ylabel('頻度') plt.title('食料費の分布') plt.show() # pandas の直接機能 df['食料費'].hist(bins=15, color='steelblue', edgecolor='white') # 平均と中央値を線で plt.axvline(df['食料費'].mean(), color='red', linewidth=2, label='平均') plt.axvline(df['食料費'].median(), color='orange', linestyle='--', label='中央値') plt.legend() |
seaborn(高機能)
1 2 3 4 5 6 7 8 9 10 11 12 13 | import seaborn as sns # 1変数 + KDE sns.histplot(df['食料費'], kde=True, color='steelblue') # 群別 sns.histplot(data=df, x='食料費', hue='地域', element='step') # 密度プロット sns.kdeplot(df['食料費'], fill=True) # 結合プロット sns.jointplot(x='食料費', y='教育費', data=df, kind='hist') |
plotly(インタラクティブ)
1 2 3 4 5 6 7 | import plotly.express as px fig = px.histogram(df, x='食料費', nbins=15, marginal='box') fig.show() # 群別 fig = px.histogram(df, x='食料費', color='地域', barmode='overlay') |
🤖 機械学習でのヒストグラム
① EDA(探索的データ分析)の第一歩
機械学習プロジェクトの最初に、 各特徴量のヒストグラムを描く。 分布の形から:
- 外れ値があるか → 除去・変換が必要
- 歪んでいるか → log 変換、 Box-Cox 変換が必要
- カテゴリが偏っていないか → クラス不均衡対策が必要
② Histogram-based Gradient Boosting
LightGBM や XGBoost は、 連続値を高速処理するためにヒストグラムベースのアルゴリズム(Hist GBDT)を採用。 ビン化が高速化の鍵。
③ 画像処理(色のヒストグラム)
画像の RGB 各チャンネルの分布を見る。 ヒストグラム均等化(histogram equalization)は古典的なコントラスト向上手法。
④ オートエンコーダの入力分布
生成モデルの学習時、 入力データの分布と再構成データの分布をヒストグラムで比較。 ずれていれば学習不足。
🚧 ヒストグラムの落とし穴
1️⃣ ビン数で印象が変わる
同じデータでもビン数を変えると分布の見え方が変わる。 複数のビン数で確認、 KDE を併用するのが安全。
2️⃣ サンプルサイズが小さいと不安定
n=10 程度ではヒストグラムの形は安定しません。 KDE や箱ひげ図のほうが情報損失が少ない。
3️⃣ 軸のスケールを忘れない
裾の長い分布(所得、 株価)では対数軸が見やすい:plt.xscale('log')
4️⃣ 縦軸の頻度 vs 密度を混同しない
群間比較する時、 サイズが違うグループは「密度」で描く必要があります(生の頻度だと比較不能)。
5️⃣ 0からの軸を保つ
棒グラフ・ヒストグラムは縦軸を 0 から始めるのが原則。 切り取ると差が誇張されます。
6️⃣ 名義変数には使わない
「血液型」「性別」のようなカテゴリ変数には棒グラフ(bar chart)を使う。 ヒストグラムは連続値用。
📜 ヒストグラムの歴史
- John Graunt(1662):死亡記録の最初の頻度表(ヒストグラム的可視化)
- William Playfair(1786):棒グラフの発明
- Karl Pearson(1891):「histogram」という用語を提唱
- Rosenblatt(1956)、 Parzen(1962):KDE の発明 → ヒストグラムの理論的後継
- Sturges(1926)、 Scott(1979)、 Freedman & Diaconis(1981):ビン数選択の数学的ルールを次々と提案
🗺️ 概念マップ — 3つの視点で体系を理解する
ヒストグラム がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 記述統計 › 可視化 › ヒストグラム
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「ヒストグラム」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「ヒストグラム」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引 — 拡張版
ヒストグラムに関する用語を、 ビン幅・分布形状・関連可視化 別に索引化します。
| カテゴリ | キーワード(日本語) | キーワード(英語) |
|---|---|---|
| 基本構成 | ビン(階級)、 度数、 階級値、 階級幅、 累積度数 | bin, frequency, class width, cumulative |
| ビン幅選択則 | スタージェスの公式、 スコット、 フリードマン・ダイアコニス | Sturges, Scott, Freedman-Diaconis, Doane, Rice |
| 分布形状 | 対称、 右に裾が長い(正の歪度)、 左に裾が長い、 双峰、 一様 | symmetric, right-skewed, left-skewed, bimodal, uniform |
| 統計量 | 最頻値、 歪度、 尖度、 中央値、 四分位数 | mode, skewness, kurtosis, median, quartile |
| 関連可視化 | 密度プロット(KDE)、 箱ひげ図、 バイオリンプロット、 累積分布 | KDE, boxplot, violin plot, ECDF |
| 実装関数 | matplotlib.hist、 seaborn.histplot、 pandas.DataFrame.hist、 numpy.histogram | plt.hist, sns.histplot, df.hist, np.histogram |
🧮 SSDSE-B での平均所得ヒストグラム — 実値計算例
SSDSE-B から「47都道府県の平均所得(万円)」を取り出し、 ヒストグラムを実際に作成します。
① 度数分布表(ビン幅50万円)
| 階級(万円) | 度数 | 相対度数 | 累積度数 |
|---|---|---|---|
| 240–280 | 18 | 38.3% | 18 |
| 280–320 | 19 | 40.4% | 37 |
| 320–360 | 5 | 10.6% | 42 |
| 360–400 | 3 | 6.4% | 45 |
| 400–440 | 1 | 2.1% | 46 |
| 440–540 | 1 | 2.1% | 47(東京) |
② ビン幅選択則の比較
n = 47 の場合:
Sturges:⌈log₂(47)+1⌉ = 7 ビン → 幅 ≈ 42 万円
Scott:3.5σ/n^(1/3) ≈ 56 万円
Freedman-Diaconis:2·IQR/n^(1/3) ≈ 19 万円(外れ値に頑健)
Rice:2·n^(1/3) ≈ 7 ビン
③ 分布の特徴
所得分布は 右に裾が長い(正の歪度)。 東京都が外れ値で、 ピークは 280 万円付近。 中央値(≈295)が平均(≈304)より小さい典型的な右歪み分布。 対数変換すると対称に近づく。
⚠️ ヒストグラムの落とし穴 — 拡張版(実務で本当に困る5+件)
- ビン幅選択による印象操作:ビン数を 5 にすると分布が滑らかに見え、 50 にするとデコボコに見える。 同じデータでもビン幅で「形」が変わる。 単一のビン幅で結論を出さず、 複数のビン幅で確認するか、 KDE(密度推定)と併用するのが賢明。 Sturges は古典的だが大標本でビン数不足になりがちなので、 Scott や Freedman-Diaconis を使うと良い。
- 連続データと離散データの混同:離散値(評価点1〜5など)にビン幅を勝手に決めると、 2ポイント以上が同じビンに入って意味が崩れる。 離散データには棒グラフ(bar chart)を使う。 ヒストグラムは連続変数、 棒グラフはカテゴリ、 という使い分けを明確に。
- 累積度数と確率密度の混同:plt.hist の density=True は 面積が1 になるように規格化された確率密度を出す。 縦軸を「確率」と勘違いしないこと。 ビン幅 × 高さの面積がその範囲に入る割合。 累積分布関数(ECDF)とは別物。
- 対数スケールの誤用:所得や売上のような右に裾の長いデータをそのままヒストグラムにすると、 ピークが左に偏って詳細が見えない。 横軸を対数スケール(log)にするか、 対数変換後の値でヒストグラムを描く。 ただし負値や0には対数が取れないので log(x+1) などの工夫が必要。
- 2群の比較で重ね合わせを誤る:男女別ヒストグラムを単純に重ねると見えにくい。 alpha=0.5 で半透明にする、 stacked=True で積み上げる、 step型で輪郭のみ表示、 など状況に応じた選択を。 違いを際立たせたいなら正規化(density=True)して同じスケールに揃える。
- 小標本でのギザギザ問題:n が小さい(<30)と、 たまたまそのビンに値が入るかどうかでヒストグラムが不安定になる。 KDE のような滑らかな推定を使うか、 ジッタープロット(rugplot)併用で生データも見せる。
- 3D・派手な装飾の罠:3D棒グラフや影付きヒストグラムは「印象的」だが、 比較が困難で誤読を招く。 シンプルな2D棒で、 グリッド線・色合いを抑えるのが優れたヒストグラムの基本。
🐍 Python 実装バリエーション — matplotlib / seaborn / pandas / plotly
① matplotlib(基本、 細かい制御)
1 2 3 4 5 6 7 8 9 10 11 12 13 | import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) plt.hist(df['平均所得'], bins=10, edgecolor='black', alpha=0.7) plt.xlabel('平均所得(万円)') plt.ylabel('度数') plt.title('都道府県別 平均所得分布') plt.grid(axis='y', alpha=0.3) plt.show() # ビン幅自動選択 plt.hist(df['平均所得'], bins='fd') # Freedman-Diaconis |
② seaborn(KDEと組み合わせ、 美しい統計可視化)
1 2 3 4 5 6 7 | import seaborn as sns import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) sns.histplot(df['平均所得'], kde=True, bins=15, color='skyblue') # rugplotで生データ位置を表示 sns.rugplot(df['平均所得'], color='red', height=0.05) |
③ pandas(DataFrameで全数値列を一括)
1 2 3 4 5 6 | import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) df[['人口', '平均所得', '完全失業率']].hist(bins=10, figsize=(12, 4), layout=(1, 3)) # Series単独で hist df['平均所得'].plot(kind='hist', bins=15) |
④ numpy(数値計算用、 度数表だけ欲しい時)
1 2 3 4 5 6 7 8 9 10 | import numpy as np import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) counts, bin_edges = np.histogram(df['平均所得'], bins=10) print('度数:', counts) print('境界:', bin_edges) # 累積分布 cum = np.cumsum(counts) / counts.sum() print('累積相対度数:', cum) |
⑤ plotly(インタラクティブ)
1 2 3 4 5 6 7 | import plotly.express as px import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) fig = px.histogram(df, x='平均所得', nbins=15, marginal='box', title='都道府県別 平均所得分布') fig.show() |
⑥ 2群比較(男女・地域別)
1 2 3 4 | import seaborn as sns sns.histplot(data=df, x='平均所得', hue='地域', element='step', stat='density', common_norm=False) # stat='density'で確率密度に正規化、 common_norm=Falseで群ごとに正規化 |