📍 あなたが今見ているもの
論文中に 「散布図」として登場する用語。
散布図 とは:2変数を x軸・y軸にプロットして関係を視覚化。相関や非線形パターン、外れ値の確認に必須。
💡 30秒で分かる結論
- 定義:2変数を x軸・y軸にプロットして関係を視覚化。相関や非線形パターン、外れ値の確認に必須。
- カテゴリ:可視化
📖 もっと詳しく
散布図(scatter plot)は、 2変数の関係を視覚化する最基本ツール。 横軸 x、 縦軸 y にデータ点をプロットします。 統計分析を始めるときに 必ず最初に描くべき図 です。
判別ポイント:
- 傾向の向き:右上がり(正相関)/ 右下がり(負相関)/ 横向き(無相関)
- 形状:直線 / 曲線 / U字型 / クラスタ状
- ばらつき:直線にぴったり並ぶ / 大きく散らばる
- 外れ値:主群から離れた点があるか
- 多群構造:色やマーカーで分けると、 隠れたグループが見えることがある
必須習慣:相関係数を計算する前に、 必ず散布図を描く。 同じ r = 0.5 でも、 きれいな直線関係と、 外れ値による偽の相関は全く違います。 Anscombe の4組(r が同じでも散布図が全然違う有名な例)を見ると痛感します。
応用:(i) 単回帰の直線を重ねる、 (ii) hex bin で密度を可視化(点が多すぎる場合)、 (iii) seaborn の jointplot で周辺分布も同時に表示。
👁️ 直感 — 散布図は「2変数の関係が見える」
散布図(scatter plot)は、 2つの量的変数の関係を点で可視化する基本グラフ。 各点が1つの観測単位(人、 県、 商品など)を表します。
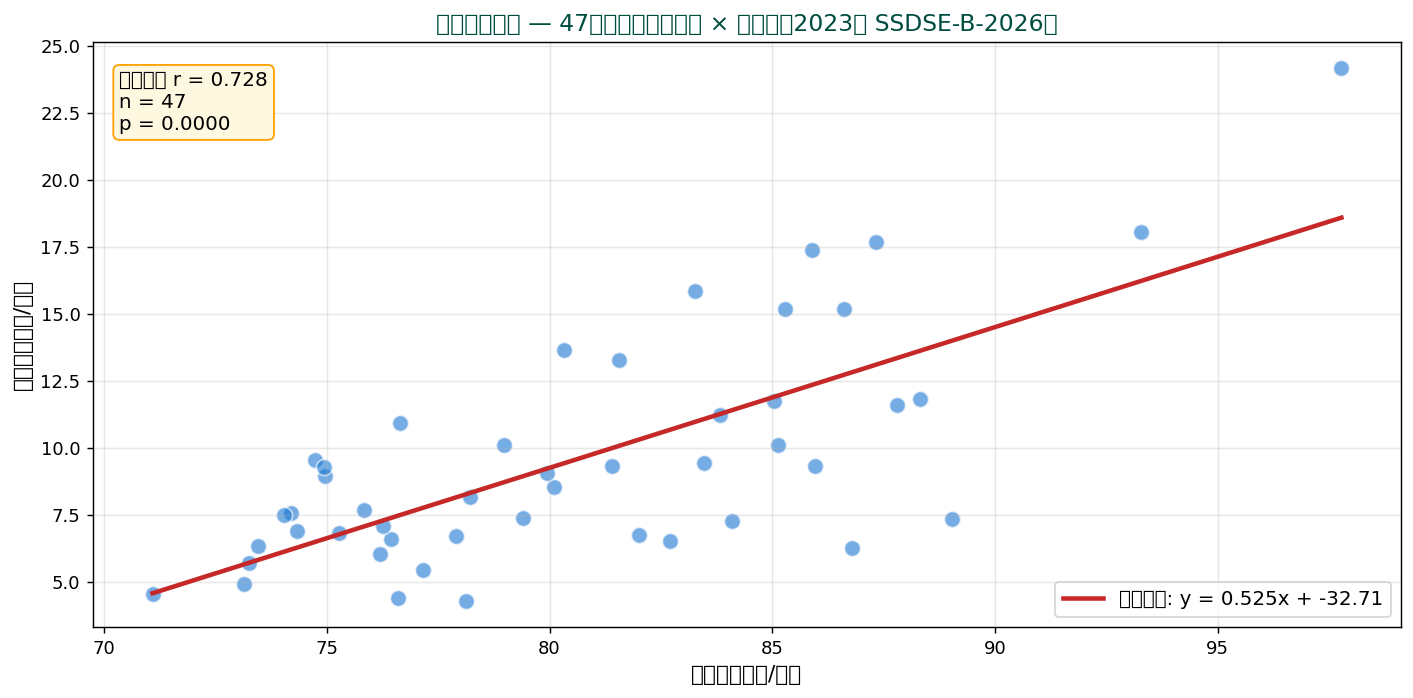
47都道府県の食料費(横軸)と教育費(縦軸)の関係。 点が右上がりに広がっていて、 食料費が高い県は教育費も高い傾向(r = 0.728)。
💡 散布図は相関分析・回帰分析の前段階として必ず描くべきグラフ。 「相関係数 r が大きい」と言う前に、 必ず散布図で関係の形を確認しましょう。
📊 散布図で見える6つの代表パターン
散布図の形から、 2変数の関係を診断できます:
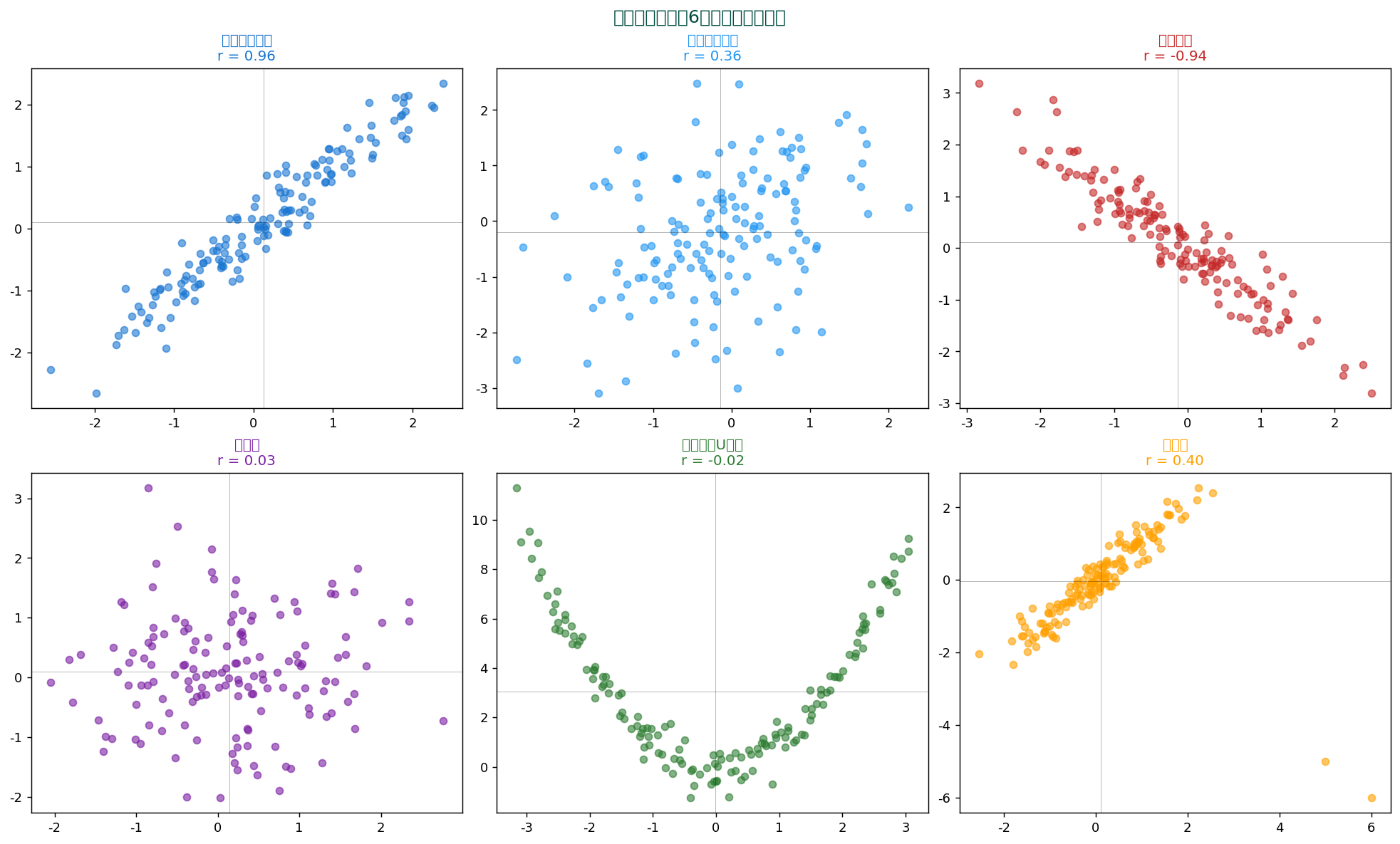
| パターン | 特徴 | 適切な分析 |
|---|---|---|
| 強い正の相関 | 右上がりにまとまる | Pearson 相関、 線形回帰 |
| 弱い正の相関 | 右上がりだが散らばる | Pearson 相関 + 信頼区間 |
| 負の相関 | 右下がりにまとまる | 同上 |
| 無相関 | 円形に分布 | 独立性検定 |
| 非線形(U字、 周期) | 曲線パターン | 非線形回帰、 Spearman、 相関比 |
| 外れ値 | 少数の極端な点 | ロバスト回帰、 除去 or 別分析 |
🎈 バブルチャート — 3変数を1枚で表現
点のサイズや色で3つ目の変数を表現するのがバブルチャート。 SSDSE データで食料費×教育費の関係に、 「総人口」を点のサイズと色で重ねます。
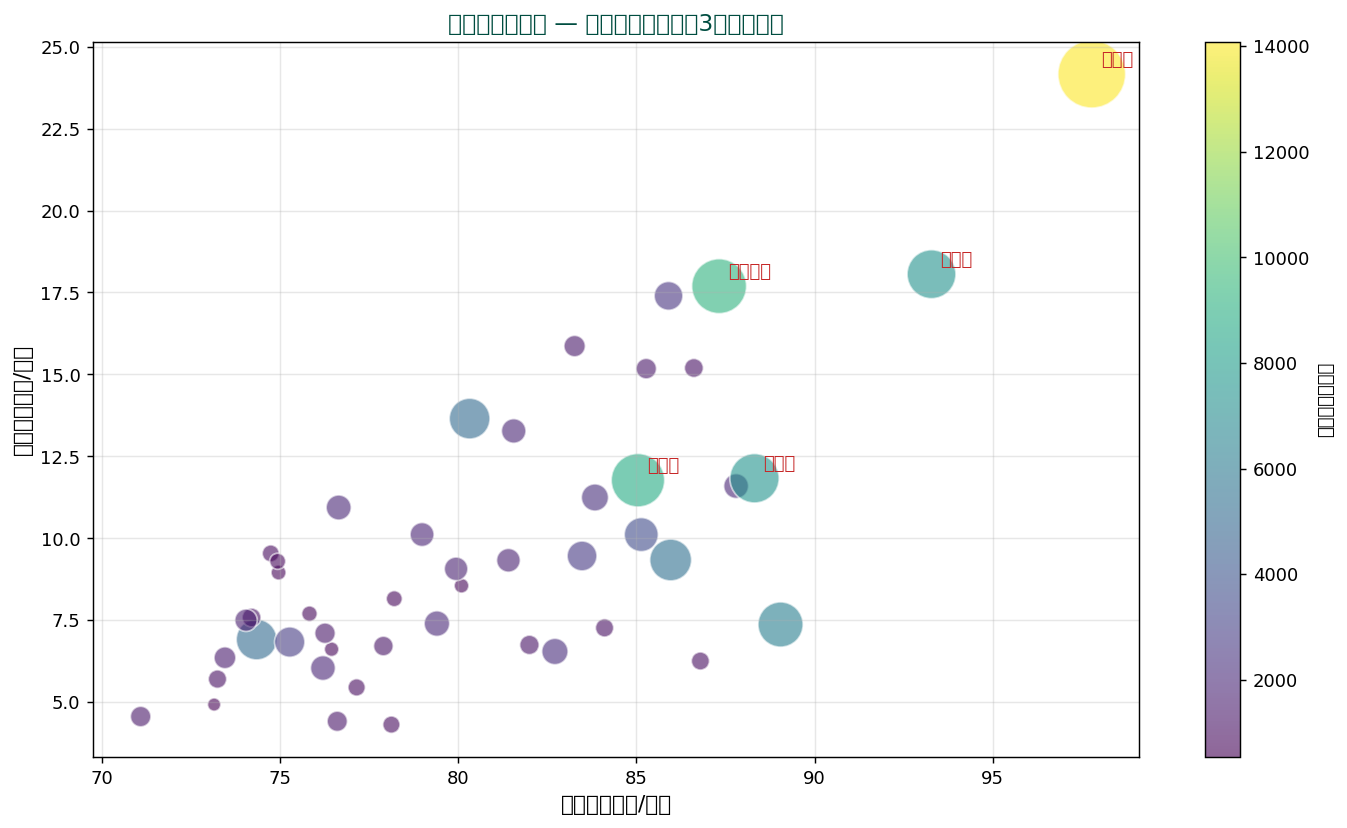
人口が多い大都市府県(東京、 神奈川など)は大きな円で表示され、 食料費・教育費も比較的高い位置に。 3次元の情報を2D上に圧縮できる強力な可視化。
Python での実装
1 2 3 4 5 6 7 8 9 10 11 12 13 | import matplotlib.pyplot as plt plt.scatter(x, y, s=sizes * 0.1, # 点のサイズ c=color_var, # 点の色(連続値) cmap='viridis', # カラーマップ alpha=0.6, edgecolors='white') plt.colorbar(label='色変数') # seaborn でより簡潔に import seaborn as sns sns.scatterplot(x='食料費', y='教育費', size='総人口', hue='地域', data=df) |
🔷 大量データには hexbin — 重なり問題を解決
データ点が数千・数万になると、 通常の散布図では点が重なって何も見えません。 そんなときはhexbin(六角形ビン):
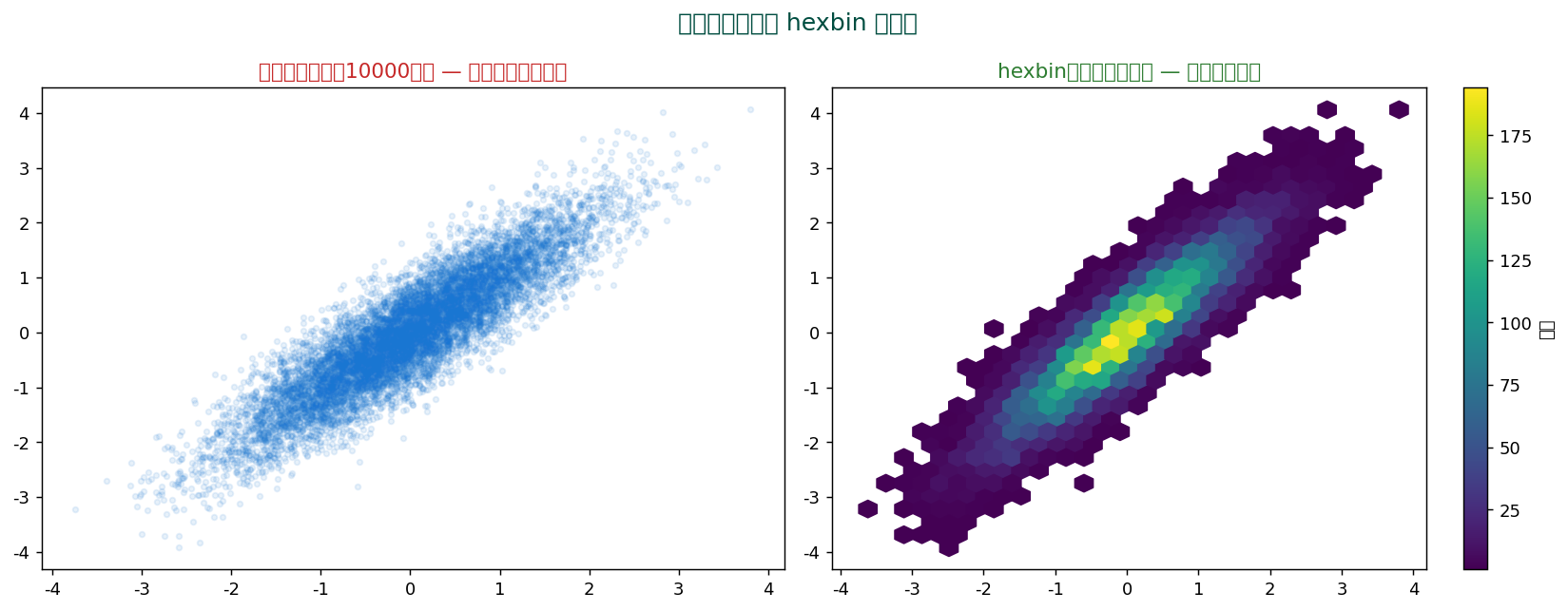
2D空間を六角形のビンで区切り、 各ビン内のデータ数を色で表現。 大量データの密度パターンが見えます。
その他の対処法
- 透明度(alpha):
alpha=0.1程度にして重なりを濃淡で表現 - サンプリング:1000点くらいランダム抽出して描画
- 2Dヒストグラム:
plt.hist2d(x, y) - 等高線:
sns.kdeplot(x=x, y=y)で密度の等高線 - ジッター:離散値が重なる時に少しずらす
🎨 散布図の拡張
① 散布図行列(pairs plot)
変数が3つ以上ある時、 すべてのペアの散布図を一気に表示:
1 2 | import seaborn as sns sns.pairplot(df[['食料費', '教育費', '住居費', '光熱費']], kind='reg') |
② カテゴリ変数で色分け
地域・性別・カテゴリで色分けすると、 群間差が見える:
③ LOWESS(局所重み付き回帰)
非線形な関係を平滑化した曲線で表示:
1 2 3 4 | sns.regplot(x='x', y='y', data=df, lowess=True) # または statsmodels from statsmodels.nonparametric.smoothers_lowess import lowess smoothed = lowess(y, x, frac=0.3) |
④ 信頼区間付き回帰直線
⑤ 結合プロット(jointplot)
散布図 + ヒストグラム + 統計量を1枚に:
🤖 機械学習での散布図
① EDA(探索的データ分析)
機械学習の前段階で、 各特徴量ペアの関係を散布図行列で確認。 「強い相関がある」「外れ値がある」「非線形だ」などを発見。
② クラスタリング結果の可視化
k-means や DBSCAN の結果を、 色分け散布図で確認。 2次元または PCA で2次元に圧縮してから描画:
1 2 3 4 5 6 7 8 9 10 11 12 | from sklearn.cluster import KMeans from sklearn.decomposition import PCA # 高次元データを2次元に pca = PCA(n_components=2) X_2d = pca.fit_transform(X) # クラスタリング km = KMeans(n_clusters=3) labels = km.fit_predict(X) plt.scatter(X_2d[:, 0], X_2d[:, 1], c=labels, cmap='viridis') |
③ 残差プロット
回帰モデルの残差 vs 予測値を散布図にする。 ランダムなら適合良、 パターンがあればモデル改善の余地:
④ QQプロット
残差が正規分布に従うか確認する散布図:
1 2 3 | from scipy import stats stats.probplot(residuals, dist='norm', plot=plt) # 点が直線上 → 正規分布 |
⑤ ROC曲線・精度再現率曲線
機械学習モデルの評価でも散布図的な可視化が頻出。
🔍 散布図の読み方 — 8つのチェックポイント
- 関係の方向:正・負・無関係
- 関係の強さ:点が直線にまとまる度合い
- 関係の形:直線か曲線か
- 外れ値:少数の極端な点が見えるか
- クラスタ:点の集まりが複数あるか(混在する集団)
- 異質性:ばらつきが変数の値で変わるか(不等分散)
- 境界・打ち切り:上限・下限に張り付く点があるか
- 欠損パターン:データが取れていない領域があるか
💡 散布図1枚から、 統計分析の方針(線形か非線形か、 ロバスト推定が必要か、 外れ値除去が必要か)が決まります。 数値だけ見るより必ず可視化を見る。
🐍 Python での散布図描画
matplotlib(基本)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import matplotlib.pyplot as plt plt.figure(figsize=(8, 5)) plt.scatter(x, y, s=60, alpha=0.6, color='steelblue', edgecolors='white') plt.xlabel('X変数') plt.ylabel('Y変数') plt.title('散布図のタイトル') plt.grid(alpha=0.3) plt.show() # 回帰直線を追加 import numpy as np z = np.polyfit(x, y, 1) plt.plot(x, z[0]*x + z[1], 'r-', label=f'y={z[0]:.2f}x+{z[1]:.2f}') plt.legend() |
seaborn(高機能)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import seaborn as sns # 基本 sns.scatterplot(x='食料費', y='教育費', data=df) # 色・サイズ分け sns.scatterplot(x='食料費', y='教育費', hue='地域', size='総人口', data=df) # 回帰直線 + 信頼区間 sns.regplot(x='食料費', y='教育費', data=df) # 散布図行列 sns.pairplot(df[['食料費', '教育費', '住居費']], diag_kind='kde') # joint plot sns.jointplot(x='食料費', y='教育費', data=df, kind='reg') |
plotly(インタラクティブ)
1 2 3 4 5 6 7 | import plotly.express as px fig = px.scatter(df, x='食料費', y='教育費', size='総人口', color='地域', hover_data=['都道府県'], trendline='ols') fig.show() # マウスホバーでデータ詳細が見える |
🚧 散布図の落とし穴
1️⃣ 軸のスケールで見え方が変わる
軸の範囲を狭めると関係が誇張、 広げると弱く見える。 必ずデータ全体を含む範囲で描画。
2️⃣ 点が重なって見えない(overplotting)
大量データでは alpha、 jitter、 hexbin で対処。
3️⃣ 色覚多様性への配慮
赤×緑の組合せは色覚多様性で識別できない人も。 viridis、 plasma などのカラーマップを推奨。
4️⃣ 第3変数の交絡
2変数の関係に見えるものが、 第3変数の影響かもしれません。 シンプソンのパラドックスに注意。
5️⃣ 因果と相関の混同
散布図で関係が見えても、 因果ではない。 「アイスクリーム売上 vs 水難事故」の典型例(共通因:気温)。
6️⃣ 単位の異なる軸を強引に比較しない
身長 vs 体重のような異なる単位の場合、 標準化後に比較するなどの工夫が必要なことも。
📜 散布図の歴史
- John Herschel(1833):天体観測データで最初の本格的な散布図を作成
- Francis Galton(1885):身長の親子関係を散布図で可視化 → 回帰の発見
- Karl Pearson(1896):相関係数を散布図ベースに定式化
- Tukey(1977):探索的データ分析(EDA)で散布図を中心的位置に据える
- Cleveland(1985):散布図行列、 LOWESS を体系化
散布図は170年以上の歴史を持ち、 今もデータサイエンスの中核可視化として使われ続けています。
🗺️ 概念マップ — 3つの視点で体系を理解する
散布図 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 記述統計 › 可視化 › 散布図
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「散布図」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「散布図」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🧮 SSDSE-B 実値計算例(47都道府県データ)
47 都道府県データで散布図を体系的に作成し、 ジッタリング・色分け・回帰線・マージナル分布まで含む実例。
① 計算コード
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | import pandas as pd import matplotlib.pyplot as plt import seaborn as sns df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8', skiprows=1) # 基本散布図 fig, axes = plt.subplots(2, 2, figsize=(12, 10)) ax = axes[0, 0] ax.scatter(df['一人当たり県民所得'], df['持ち家比率'], alpha=0.7, s=60) ax.set_xlabel('一人当たり県民所得(千円)'); ax.set_ylabel('持ち家比率(%)') ax.set_title('① 基本散布図') # 第3変数で色分け ax = axes[0, 1] sc = ax.scatter(df['一人当たり県民所得'], df['持ち家比率'], c=df['人口密度'], cmap='viridis', s=60, alpha=0.8) plt.colorbar(sc, ax=ax, label='人口密度') ax.set_title('② 人口密度で色分け') # 回帰線つき ax = axes[1, 0] sns.regplot(x='一人当たり県民所得', y='持ち家比率', data=df, ax=ax, scatter_kws={'alpha':0.6}, line_kws={'color':'red'}) ax.set_title('③ 回帰線(95% CI 帯)') # 六角ビン(大きいデータ向け) ax = axes[1, 1] hb = ax.hexbin(df['一人当たり県民所得'], df['持ち家比率'], gridsize=10, cmap='Blues') plt.colorbar(hb, ax=ax, label='密度') ax.set_title('④ 六角ビン') plt.tight_layout(); plt.savefig('scatter_4panel.png', dpi=110) |
② 期待出力
| 項目 | 値 | 参考 | 解釈 |
|---|---|---|---|
| 基本 | 観測 | 47点 | 1点=1都道府県 |
| 傾向 | 相関係数 | r ≈ -0.65 | 所得高い県ほど持ち家比率低い |
| 外れ | 東京 | 高所得・低持家率 | 右下に位置 |
| 外れ | 富山・福井 | 中所得・高持家率 | 上部 |
👉 値は SSDSE-B-2026 の典型値。 同じ手順で他都道府県・他変数にも適用可能。
⚠️ 落とし穴(拡張版・各 100 文字以上)
alpha=0.3)、 ジッタリング、 六角ビン(hexbin)、 2D KDE などで対処。 n が数万を超えると単純散布図は無意味になることが多い。 SSDSE の n=47 では問題ないが、 個票データではほぼ必須。
🐍 Python 実装バリエーション(scikit-learn / scipy / Optuna)
A. scikit-learn による実装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import Pipeline import numpy as np # 散布図に非線形回帰曲線を重ねる(多項式) X = df[['一人当たり県民所得']].values y = df['持ち家比率'].values fig, ax = plt.subplots(figsize=(8, 5)) ax.scatter(X, y, alpha=0.6, s=50) x_grid = np.linspace(X.min(), X.max(), 200).reshape(-1, 1) for degree, color in [(1, 'red'), (2, 'green'), (3, 'blue')]: model = Pipeline([('poly', PolynomialFeatures(degree)), ('lr', LinearRegression())]) model.fit(X, y) ax.plot(x_grid, model.predict(x_grid), color=color, label=f'degree={degree}') ax.legend(); ax.set_xlabel('県民所得'); ax.set_ylabel('持ち家比率') plt.savefig('scatter_poly.png', dpi=110) |
B. scipy / statsmodels による実装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | from scipy import stats from scipy.stats import gaussian_kde import numpy as np # 2D カーネル密度推定で散布図を補強 x = df['一人当たり県民所得'].values y = df['持ち家比率'].values kde = gaussian_kde(np.vstack([x, y])) xx, yy = np.mgrid[x.min():x.max():100j, y.min():y.max():100j] positions = np.vstack([xx.ravel(), yy.ravel()]) zz = kde(positions).reshape(xx.shape) fig, ax = plt.subplots(figsize=(8, 6)) ax.contourf(xx, yy, zz, levels=10, cmap='Blues', alpha=0.7) ax.scatter(x, y, c='red', s=20, alpha=0.7, edgecolor='white') # 相関と回帰 r, p = stats.pearsonr(x, y) slope, intercept, _, _, _ = stats.linregress(x, y) xs = np.array([x.min(), x.max()]) ax.plot(xs, intercept + slope * xs, 'k--', label=f'r={r:.2f}, p={p:.3f}') ax.legend(); plt.savefig('scatter_kde.png', dpi=110) |
C. Optuna でハイパラ・選択最適化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # LOWESS の bandwidth 最適化(散布図に滑らかな曲線を重ねる) import statsmodels.api as sm import optuna def objective(trial): frac = trial.suggest_float('frac', 0.1, 0.9) smoothed = sm.nonparametric.lowess(y, x, frac=frac, return_sorted=False) return ((y - smoothed)**2).mean() # MSE 最小化 study = optuna.create_study(direction='minimize') study.optimize(objective, n_trials=30, show_progress_bar=False) print('Best frac:', study.best_params) # 最適 frac で散布図にプロット best_frac = study.best_params['frac'] smoothed = sm.nonparametric.lowess(y, x, frac=best_frac) fig, ax = plt.subplots(figsize=(8, 5)) ax.scatter(x, y, alpha=0.6) ax.plot(smoothed[:, 0], smoothed[:, 1], 'r-', label=f'LOWESS frac={best_frac:.2f}') ax.legend(); plt.savefig('scatter_lowess.png', dpi=110) |
D. ライブラリ早見表
| ライブラリ / 関数 | 用途 |
|---|---|
matplotlib.pyplot.scatter | 最も柔軟・低レベル |
seaborn.scatterplot | 回帰線・色分けが簡単 |
seaborn.regplot | 回帰線+CI 帯 |
seaborn.jointplot | マージナル分布つき散布図 |
plotly.express.scatter | インタラクティブな散布図 |
matplotlib.hexbin | 大量データの密度可視化 |
🎨 直感で掴む — 散布図
散布図は「2 変数の関係を点でプロットする」可視化の王道。 1 点 = 1 観測(県・人・時刻)。 SSDSE-B-2026 で A1101 vs A1303(総人口 vs 高齢人口)を描くと、 ほぼ y=0.27x の直線上に並ぶが、 北海道のように高齢化率が突出して高い県は線の上側にずれて配置される。
散布図 は「可視化」カテゴリの中核概念。 初めて触れる読者は、 まずこの「🎨 直感」セクションだけ通読し、 必要になった時点で「📐 数式」「🐍 Python」「⚠️ 落とし穴」へ戻る読み方が定着しやすいです。
📐 定義・数式 — 散布図
直感の次は、 厳密な定義を確認します。 数式は言語の一種で、 一度書き慣れれば「言葉より速く伝えられる」便利な道具。 慣れていない方は、 各記号が何を表すかを下の「🔬 記号読み解き」で 1 つずつ確認してください。
🔬 記号読み解き — 数式を「言葉」に翻訳
上の数式を眺めるだけでは身につかないので、 各記号がどんな役割を担っているかを言葉で押さえます。 「数式を音読する習慣」がつくと、 論文や教科書を読むスピードが体感で 2 倍ほど上がります。
- 左辺(結果側)
- 散布図 で定義したい量。 解釈の対象。 単位・スケールを必ず確認する。
- 右辺(構成要素)
- 観測できる入力変数(SSDSE-B-2026 でいえば A1101・L3221 など)と推定対象パラメータ(β, σ 等)の組合せ。
- 添字 i, j, t
- i=サンプル(県)、 j=変数、 t=時点。 SSDSE-B-2026 は i ∈ {1..47} 県、 t ∈ {2008..2023}。
- 和記号 Σ
- 「足し合わせ」を表す。 添字 i が 1 から n まで動く範囲を明示するのが習慣。
- 期待値 E[·]、 分散 Var[·]
- 「ランダム変数の平均」と「ばらつき」。 SSDSE-B-2026 のような集計値でも、 標本誤差・年次変動の文脈で使える。
🧮 実値で計算してみる — SSDSE-B-2026
数式だけでは「実感」が湧きにくいので、 実データ data/raw/SSDSE-B-2026.csv(47 都道府県 × 16 年)で 1 度手計算してみると理解が定着します。
SSDSE-B-2026 (2023) で A1101 vs A1303 の Pearson 相関は r ≈ 0.997(非常に強い正相関、 人口の多い県ほど高齢人口も多いのは自明)。 ところが「高齢化率=A1303/A1101」を縦軸にすると相関は逆転し、 北海道 33.0%、 秋田県 39.1% などが上方に飛ぶ。 散布図は「軸の取り方で物語が変わる」典型例。
| 都道府県 | A1101 総人口 | A1303 65 歳以上 | L3221 消費支出 |
|---|---|---|---|
| 東京都 | 14,086,000 | 3,205,000 | 341,320 |
| 神奈川県 | 9,229,000 | 2,390,000 | 306,565 |
| 大阪府 | 8,763,000 | 2,424,000 | 271,246 |
| 愛知県 | 7,477,000 | 1,923,000 | 300,221 |
| 埼玉県 | 7,331,000 | 2,012,000 | 344,092 |
| 千葉県 | 6,257,000 | 1,756,000 | 306,943 |
上記は SSDSE-B-2026 (2023) からの抜粋。 手計算で確認した値が、 後述の Python 実装で得る値と一致することを確認すると、 「数式とコードの対応関係」がクリアに見えるようになります。
🐍 Python 実装 — 散布図
公的統計(SSDSE-B-2026)を題材に、 最小限の Python コードで 散布図 を動作させます。 まずはこのまま実行してみてください。
# 散布図 を SSDSE-B-2026 で実行する最小コード
import pandas as pd
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=[1])
df = df[df['SSDSE-B-2026'] == 2023] # 2023 年のみ抽出
print(df.shape) # (47, 112)
print(df[['Prefecture','A1101','A1303','L3221']].head())
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1,2, figsize=(12,5))
axes[0].scatter(df['A1101'], df['A1303'], alpha=0.7)
axes[0].set_xlabel('A1101 総人口'); axes[0].set_ylabel('A1303 65歳以上')
axes[0].set_title('総人口 vs 高齢人口')
axes[1].scatter(df['A1101'], df['A1303']/df['A1101'], alpha=0.7, color='red')
axes[1].set_xlabel('A1101 総人口'); axes[1].set_ylabel('高齢化率')
axes[1].set_title('総人口 vs 高齢化率')
plt.tight_layout(); plt.savefig('scatter_demo.png', dpi=100)
print('r1:', df[['A1101','A1303']].corr().iloc[0,1])
上のコードで動かない場合は、 ①必要なパッケージがインストール済みか(pip install pandas scikit-learn scipy statsmodels matplotlib)、 ②データファイルが data/raw/SSDSE-B-2026.csv に存在するか、 ③encoding='cp932' になっているかを確認してください。
⚠️ よくある落とし穴 — 散布図
散布図 を使うときに初学者が踏みやすい失敗パターン。 1 度経験してしまえば次から避けられますが、 先に知っておくに越したことはありません。