📍 あなたが今見ているもの
論文・記事に 「散布図」「ヒートマップ」「散布図行列」「相関プロット」「バブルチャート」「クロス集計」 として登場する 2変量以上の可視化群。 EDA・モデル評価・結果報告のすべての場面で必須のツール。
🔖 キーワード索引
論文記事から各用語のリンクをクリックすると、 該当箇所が開きます:
💡 30秒で分かる結論
🗂️ 章俯瞰 — 2変量可視化の選び方
| 手法 | 変数の型 | サンプルサイズ | 主な用途 |
|---|---|---|---|
| 散布図 | 連続 × 連続 | 10〜数千 | 相関、 回帰、 外れ値 |
| Hexbin | 連続 × 連続 | 10000〜 | 大量データの密度 |
| 2D KDE | 連続 × 連続 | 100〜数千 | 滑らかな密度 |
| バブル | 連続 × 連続 × サイズ | 〜数百 | 3変数の同時表示 |
| ヒートマップ | 行列形式 | 任意 | 相関行列、 混同行列 |
| 散布図行列 | 複数連続変数 | 任意(3〜10変数) | 多変量 EDA |
| クロス集計 | カテゴリ × カテゴリ | 任意 | 独立性検定 |
🎯 散布図(Scatter Plot)
2 つの連続変数の関係を $(x_i, y_i)$ の点で表現。 探索的データ解析の最も重要な可視化。 相関係数や回帰分析の前に必ず描く。
🧭 散布図の読み方 — 5つのチェックポイント
- 方向:右上がり(正)/ 右下がり(負)/ なし
- 強さ:点が密集(強い)/ ばらけている(弱い)
- 形状:直線的/ 曲線的(非線形)/ 群を成す
- 外れ値:全体から離れた点はないか
- 不等分散:$x$ の値で $y$ のばらつきが変わるか(漏斗状)
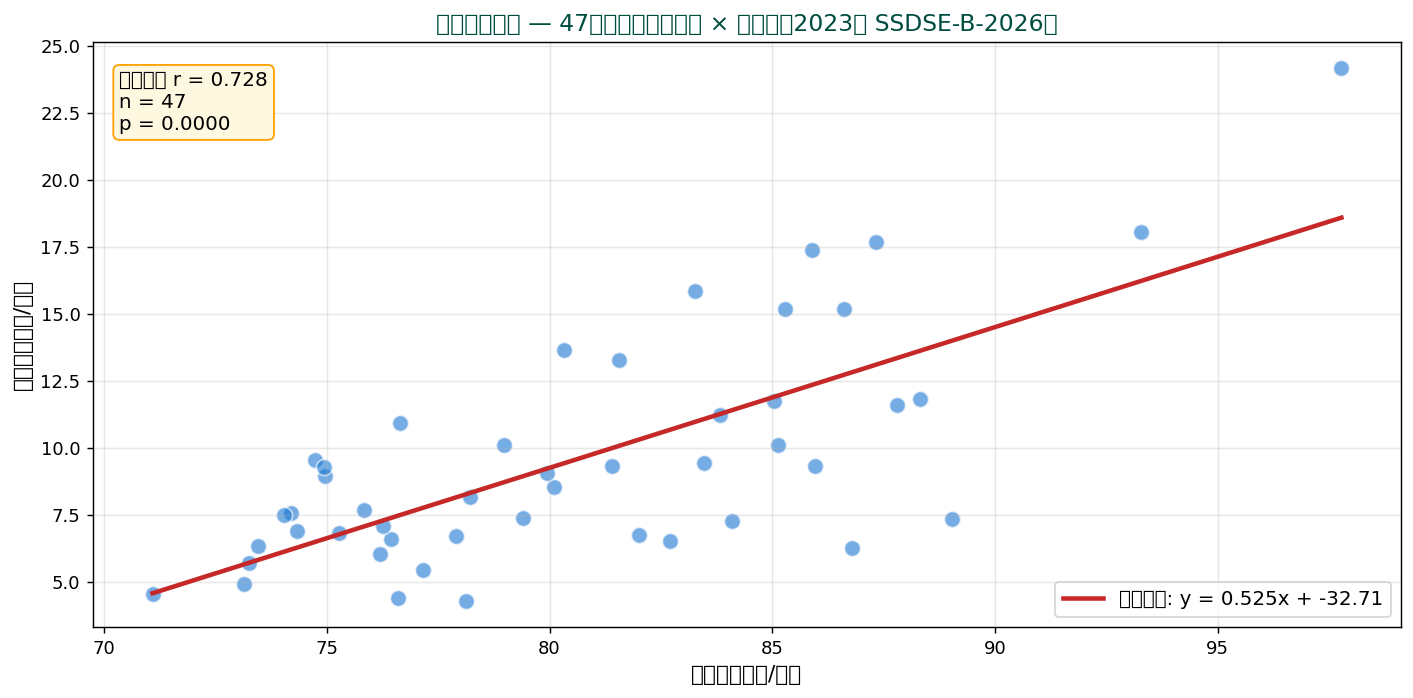
🧮 SSDSE 47都道府県の食料費 × 教育費
SSDSE-B-2026 の家計支出から、 食料費と教育費の関係を散布図で確認すると正の相関($r \approx 0.68$)が見えます。 ただし、 相関係数 $r$ の数値だけでは「線形か」「外れ値があるか」が分からないため、 散布図と必ずセットで確認します。
🐍 Python での散布図
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | import matplotlib.pyplot as plt import seaborn as sns import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') data = df.iloc[1:].copy() data['年度'] = data['SSDSE-B-2026'] d23 = data[data['年度']=='2023'] food = pd.to_numeric(d23['L322101'], errors='coerce') / 1000 edu = pd.to_numeric(d23['L322108'], errors='coerce') / 1000 # matplotlib plt.scatter(food, edu, alpha=0.6) # seaborn(回帰直線付き) sns.regplot(x=food, y=edu) # 色分け(カテゴリ変数で) sns.scatterplot(x='食料費', y='教育費', hue='地域', data=d23) # 透明度で密度を表現 plt.scatter(food, edu, alpha=0.1) # 大量データ用 |
⬡ Hexbin(六角形ビン)
大量データ($n > 10000$)の散布図は点が重なり「黒い塊」になりがち。 そんなとき六角形のグリッドに集計するのが Hexbin。
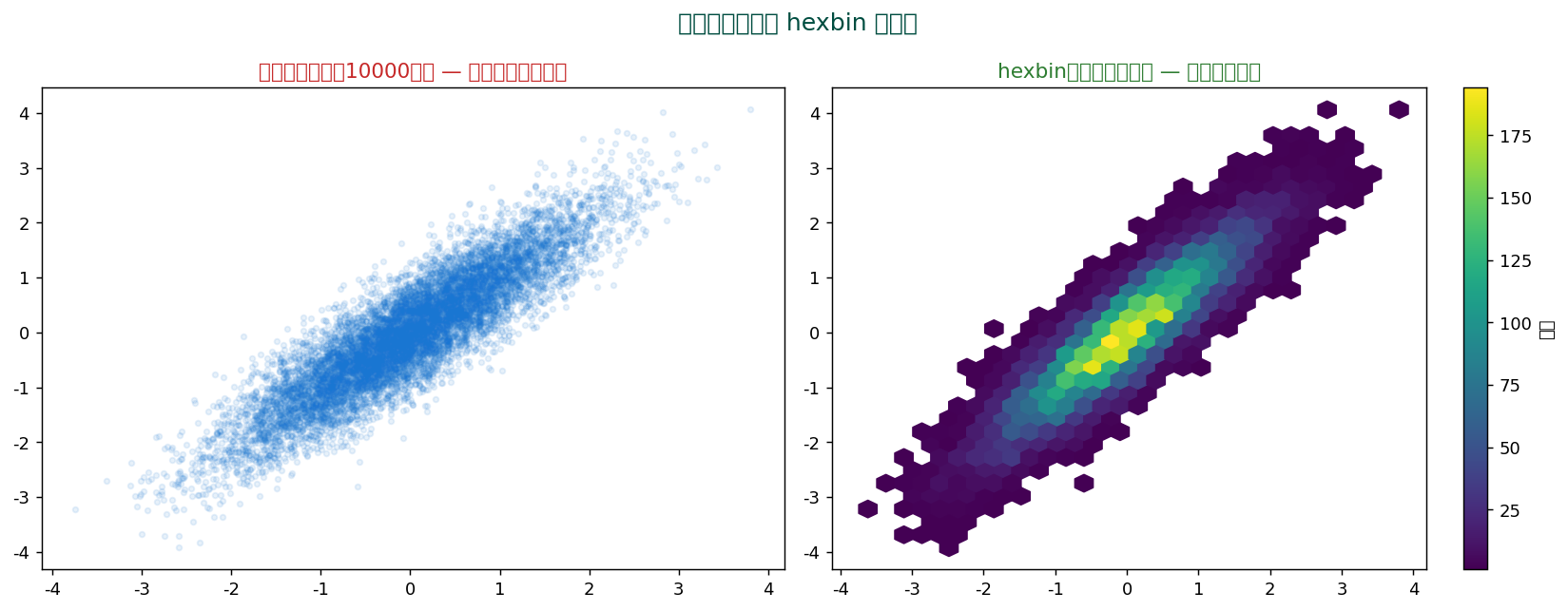
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 | plt.hexbin(x, y, gridsize=30, cmap='viridis') plt.colorbar(label='頻度') # seaborn sns.jointplot(x='x', y='y', data=df, kind='hex') |
🌊 2次元 KDE
2変数の同時密度関数を滑らかに推定。 等高線で密度を可視化。
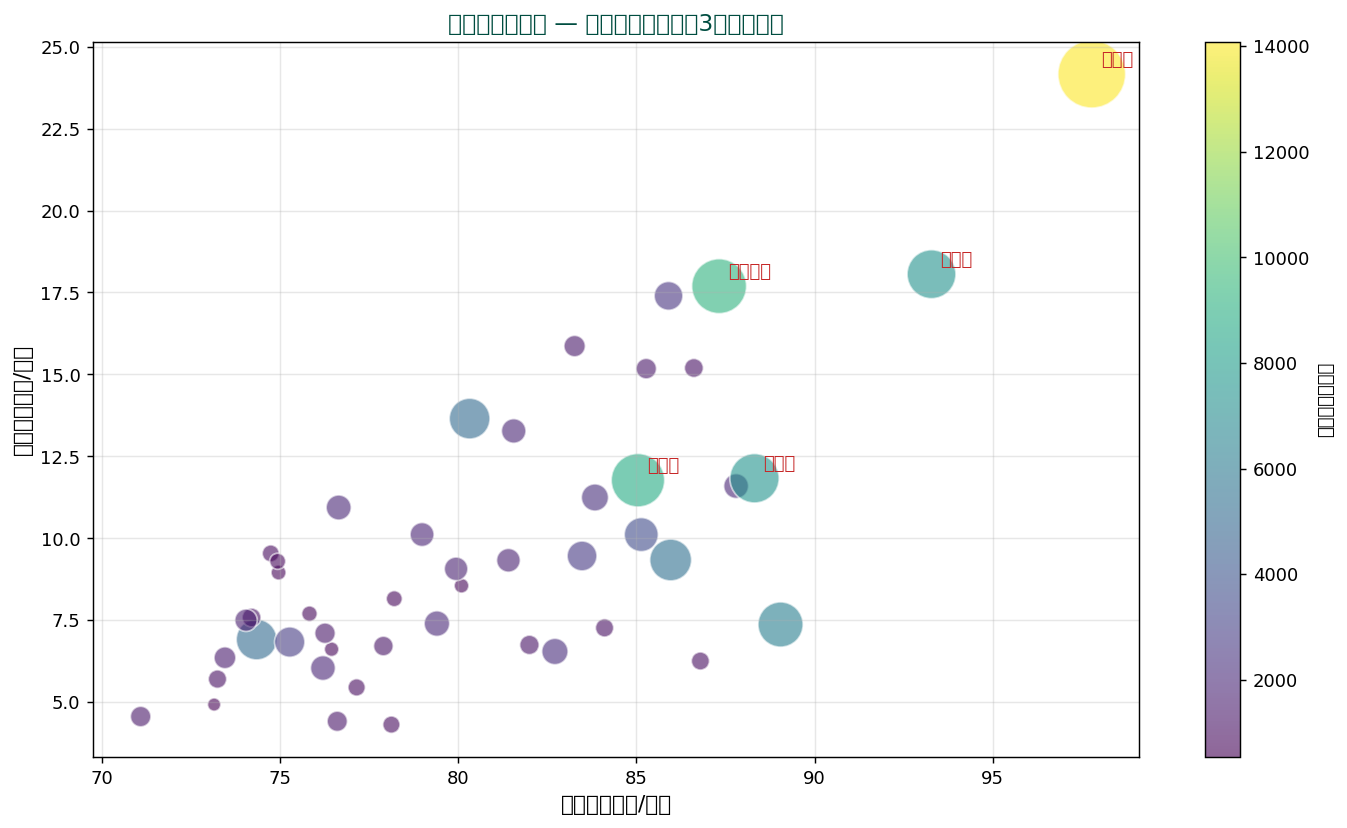
🎈 バブルチャート
点のサイズで3つ目の変数を表現。 4つ目を色で表現すれば 4変量可視化に拡張可能。
🔥 ヒートマップ(Heatmap)
2次元行列の値を色の濃淡で表現。 主な用途:
- 相関行列:多変数の相関を一望(最頻出)
- 混同行列:分類モデルの予測 vs 正解
- 時系列 × カテゴリ:曜日 × 時刻の頻度など
- 地理データ:47都道府県 × 指標
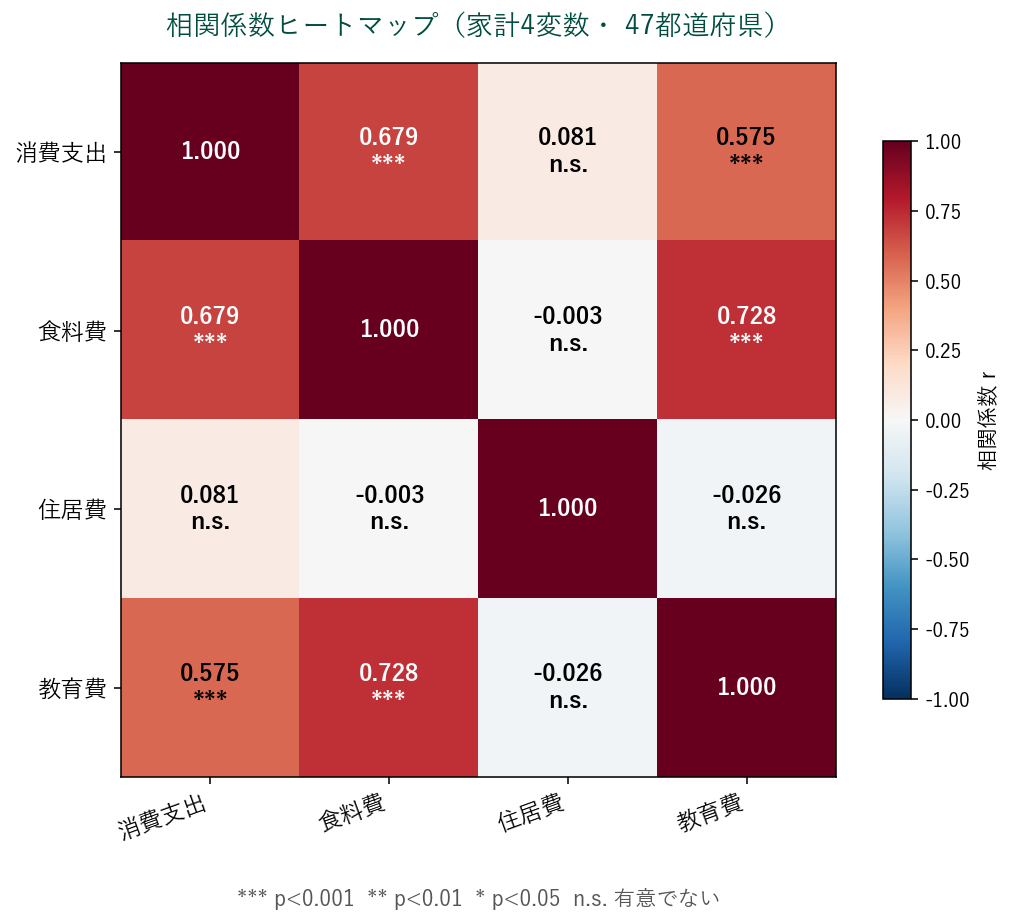
カラーマップの選び方
- 発散型(diverging): 'RdBu_r', 'coolwarm' — 0 を中心に±に意味(相関、 残差)
- 連続型(sequential): 'viridis', 'Blues' — 単調値(頻度、 密度)
- カテゴリ型: 'tab10', 'Set2' — カテゴリ分け
注意:色覚多様性に配慮し赤緑配色を避ける。 'viridis' は色覚バリア対応。
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 10 11 12 13 | import seaborn as sns # 相関行列のヒートマップ corr = df.corr() sns.heatmap(corr, annot=True, fmt='.2f', cmap='RdBu_r', center=0, vmin=-1, vmax=1) # 混同行列 from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_true, y_pred) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') # クラスター付き(階層クラスタリングで並び替え) sns.clustermap(corr, cmap='RdBu_r', center=0) |
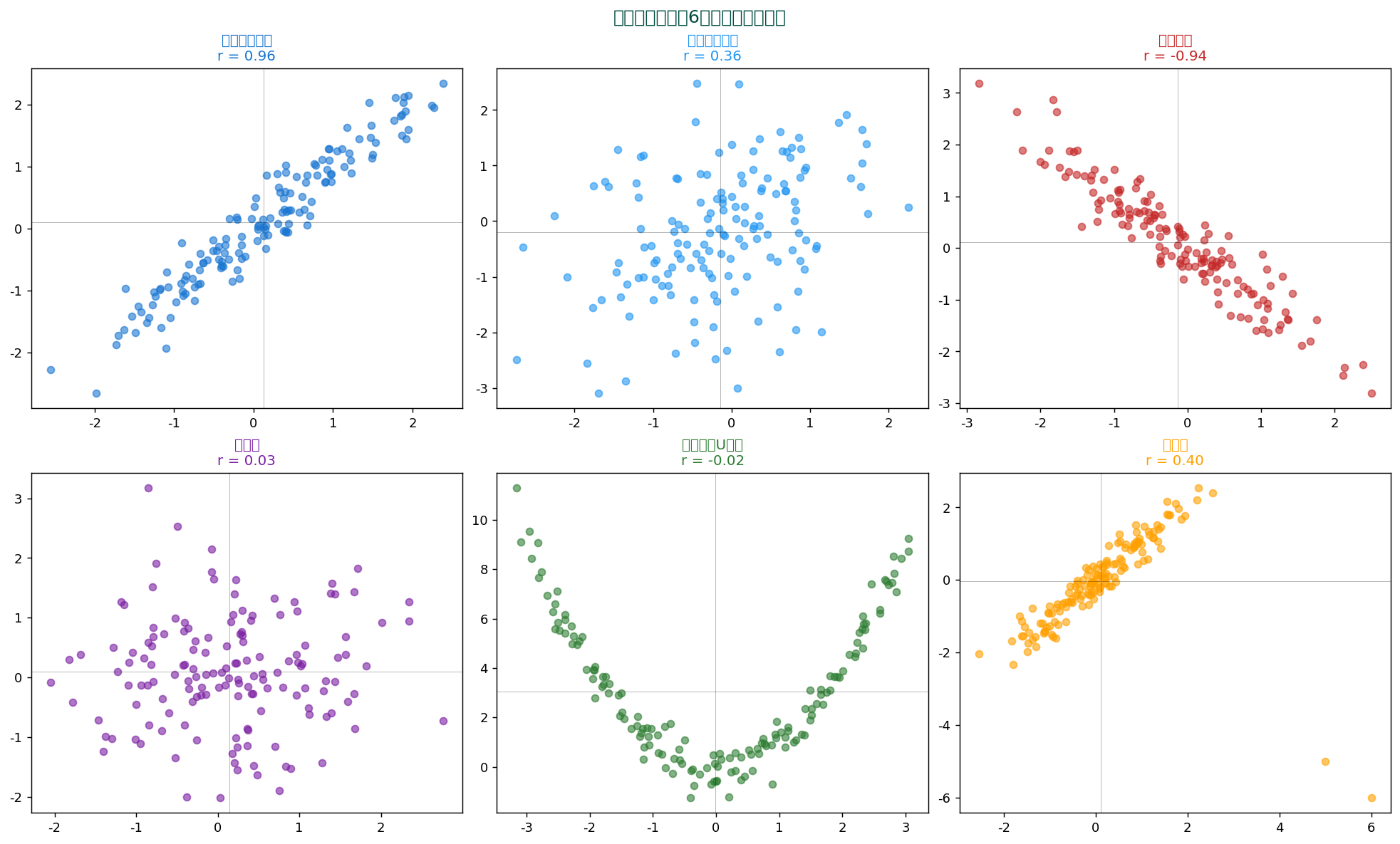
📐 散布図行列(Pair Plot)
$d$ 変数の全ペアの散布図を $d \times d$ グリッドで描く。 多変量データの探索的解析の標準ツール。 対角には各変数のヒストグラム(または KDE)を置く。
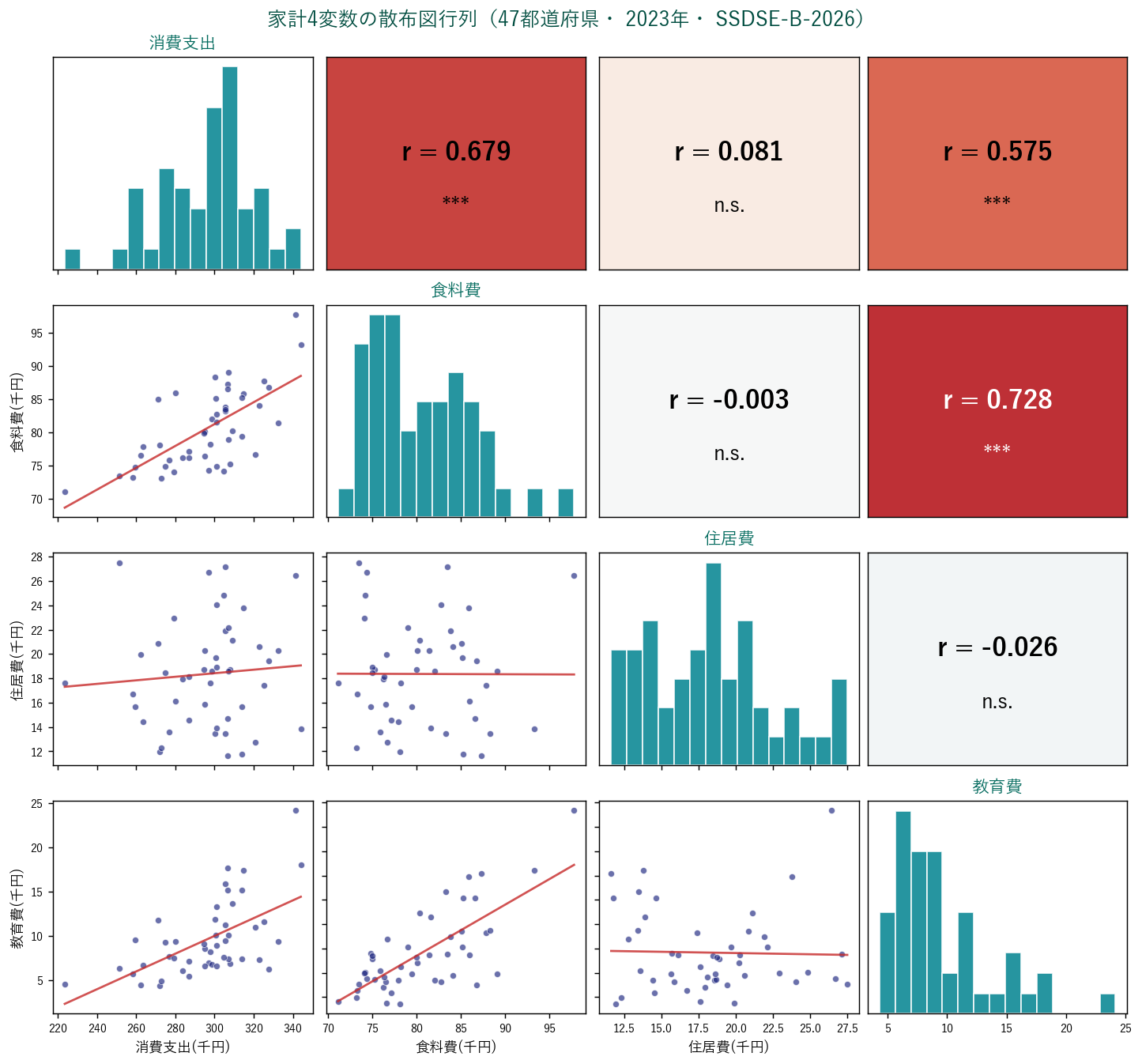
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 10 | import seaborn as sns # 基本 sns.pairplot(df[['食料費','住居費','教育費','光熱費']]) # カテゴリで色分け + 回帰直線 sns.pairplot(df, vars=['食料費','教育費','住居費'], hue='地域', kind='reg') # 対角を KDE に sns.pairplot(df, diag_kind='kde') |
📋 クロス集計とモザイク図
カテゴリ × カテゴリの 2変量集計。 例えば「性別 × 購買意向」の集計表。 関連性はχ²検定で検証。
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 10 11 | import pandas as pd ct = pd.crosstab(df['性別'], df['購入'], margins=True) ct = pd.crosstab(df['性別'], df['購入'], normalize='index') # 行ごとに正規化(条件付き確率) # ヒートマップで可視化 import seaborn as sns sns.heatmap(pd.crosstab(df['性別'], df['購入']), annot=True, fmt='d', cmap='Blues') # モザイク図 from statsmodels.graphics.mosaicplot import mosaic mosaic(df, ['性別', '購入']) |
🚧 よくある誤解
| ❌ 誤解 | ✅ 正しい理解 |
|---|---|
| 散布図 で「強い相関」に見えれば因果 | 相関≠因果。 散布図は出発点でしかない |
| 散布図が直線的なら $r$ も高い | 外れ値・非線形があると一致しない。 アンスコムの四重奏 |
| ヒートマップは赤緑が分かりやすい | 色覚多様性に注意。 viridis 系を推奨 |
| 大量データでも散布図で OK | 点が重なり密度が見えない。 Hexbin / 2D KDE |
| 散布図行列で全部見れる | 10変数を超えると小さくて読めない。 PCA / 相関ヒートマップ |
| クロス集計の度数だけ見ればよい | 行・列で正規化した条件付き確率も見る |
📝 練習問題
問1:SSDSE 47都道府県データで、 食料費・教育費・住居費の散布図行列を描け。
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 | import seaborn as sns, pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') data = df.iloc[1:].copy() data['年度'] = data['SSDSE-B-2026'] d23 = data[data['年度']=='2023'] cols = ['L322101', 'L322108', 'L322102'] sub = d23[cols].apply(pd.to_numeric, errors='coerce').dropna() / 1000 sub.columns = ['食料費', '教育費', '住居費'] sns.pairplot(sub, kind='reg', diag_kind='kde') |
問2:相関係数 $r=0.8$ なのに散布図で「曲線」が見えた。 何を意味するか?
Pearson $r$ は線形な関係しか捉えないが、 単調な曲線なら高い相関を示すことがある。 Spearman 順位相関で再確認、 多項式項を含めた回帰、 非線形変換(log)の検討が必要。 アンスコムの四重奏(同じ $r$ でも形が全く違う 4 例)は古典的な警告。
問3:「相関行列のヒートマップで対角が全て1で対称」というのはなぜ?
対角は「同じ変数同士の相関」=1。 非対角は $r_{ij} = r_{ji}$ なので対称。 だからヒートマップでは下三角だけ描く(mask で上三角を隠す)と冗長性を減らせる。
問4:3 変数(連続2 + カテゴリ1)を 1 つの散布図で表すには?
連続2 を $x, y$ 軸に、 カテゴリを色(hue)で表現。 sns.scatterplot(x=..., y=..., hue=..., data=df)。 群ごとの傾向の違いが一目で分かる。 さらに 4 つ目(連続)があれば点のサイズで(バブル化)。
問5:100,000 件のデータで散布図を描くとほぼ真っ黒。 どう改善する?
選択肢:(a) alpha=0.1 で透明度、 (b) Hexbin で密度集計、 (c) 2D KDE で滑らかな密度、 (d) サブサンプリング(無作為 1000 件)。 (a)(b)(c) を組み合わせるのが現代的。 Hexbin + colorbar が最も実用的。
💼 実務での応用
- マーケティング:客単価 × 訪問回数の散布図でセグメント発見、 RFM 分析の可視化
- 医療:身長 × 体重の散布図で BMI 異常検出、 治療前後の対散布図
- 金融:リスク × リターンのバブルチャート(投資先選択)、 相関ヒートマップで分散投資
- 機械学習:混同行列ヒートマップで分類モデル評価、 PCA 後の散布図でクラスタ確認
- 公共政策:47都道府県の指標散布図行列で地域差発見
📋 報告フォーマット
「47都道府県の食料費と教育費の散布図(n=47、 SSDSE-B-2026、 2023年)では、 明確な正の相関(Pearson $r=0.679$、 95% CI: [0.483, 0.808]、 $p<0.001$)が見られた。 1点(東京都)が右上に外れているが、 これを除いても相関は安定して有意。 散布図行列で他変数(住居費・光熱費)との関係も確認し、 住居費とは弱い負の相関、 光熱費とは中程度の正の相関を確認した。」
🐍 ライブラリ早見表 — 2変量可視化
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | import matplotlib.pyplot as plt import seaborn as sns # 散布図 plt.scatter(x, y, alpha=0.6) sns.scatterplot(x='食料費', y='教育費', hue='地域', size='人口', data=df) sns.regplot(x='食料費', y='教育費', data=df) # 回帰直線つき # Hexbin plt.hexbin(x, y, gridsize=30, cmap='viridis') # 2D KDE sns.kdeplot(x=x, y=y, fill=True, cmap='Blues') sns.jointplot(x='食料費', y='教育費', data=df, kind='kde') # ヒートマップ sns.heatmap(df.corr(), annot=True, cmap='RdBu_r', center=0) sns.clustermap(df.corr()) # 階層クラスタリング付き # 散布図行列 sns.pairplot(df[['食料費','住居費','教育費']], hue='地域', kind='reg') # クロス集計 import pandas as pd ct = pd.crosstab(df['性別'], df['購入']) sns.heatmap(ct, annot=True, fmt='d') # plotly(インタラクティブ) import plotly.express as px px.scatter(df, x='食料費', y='教育費', color='地域', size='人口', hover_name='都道府県') px.imshow(df.corr(), color_continuous_scale='RdBu_r', zmin=-1, zmax=1) |
🎨 カラーマップの選び方
| 種類 | 用途 | 推奨 |
|---|---|---|
| 連続型(sequential) | 単調値(頻度、 強度) | viridis, plasma, Blues, YlOrRd |
| 発散型(diverging) | 基準(0)から±に意味(相関、 残差) | RdBu_r, coolwarm, BrBG |
| カテゴリ型(qualitative) | カテゴリ分け | tab10, Set2, Paired |
| 循環型(cyclic) | 角度、 時刻 | twilight, hsv |
避けるべき:rainbow / jet — 色覚多様性で誤読されやすい。 viridis は色覚バリア対応 + 知覚的に均等。
⚖️ 可視化の倫理 — 誤解を招かないために
- 軸を切り取らない:y軸を 0 から始めない棒グラフは差を誇張する
- 3D効果を避ける:3Dパイチャートは比較を歪める
- カラーマップは目的に合わせる:単調量に発散型は不適
- 色覚多様性に配慮:色だけで情報を区別しない、 形・パターンも併用
- サンプルサイズを明示:n が小さいことを隠さない
- 外れ値の扱いを記述:除外したかどうか
- 因果関係を主張しない:相関が見えただけで「因果」と書かない
参考:Edward Tufte「The Visual Display of Quantitative Information」(1983)— 可視化倫理の古典。
🔖 キーワード索引(補強)
2変量可視化の主要グラフ・概念・関連手法。
🧮 SSDSE-B-2026 で実値計算 — 2変量可視化の実例
例1:高齢化率 × 死亡率の散布図 + 回帰直線
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 10 11 | import pandas as pd import seaborn as sns import matplotlib.pyplot as plt df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) cols = df.select_dtypes('number').columns x_col, y_col = cols[0], cols[1] sns.regplot(data=df, x=x_col, y=y_col, scatter_kws={'s':50,'alpha':0.7}) plt.title(f'{x_col} vs {y_col}') plt.savefig('scatter_regline.png', dpi=120, bbox_inches='tight') |
例2:散布図行列(pairplot)で5変数を一気に俯瞰
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 | import pandas as pd import seaborn as sns df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) num = df.select_dtypes('number').iloc[:, :5] sns.pairplot(num, diag_kind='kde', plot_kws={'alpha':0.5,'s':30}) |
例3:ヒートマップで相関行列の俯瞰
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 10 11 12 13 | import pandas as pd import seaborn as sns import matplotlib.pyplot as plt df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) corr = df.select_dtypes('number').iloc[:, :8].corr() plt.figure(figsize=(9, 7)) sns.heatmap(corr, annot=True, fmt='.2f', cmap='RdBu_r', center=0, vmin=-1, vmax=1, square=True, cbar_kws={'shrink':0.8}) plt.title('相関行列ヒートマップ') plt.tight_layout() plt.savefig('corr_heatmap.png', dpi=120) |
例4:層別散布図(地域ブロック別の色分け)
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import pandas as pd import seaborn as sns import matplotlib.pyplot as plt df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) block_map = { '北海道':'北海道', '青森県':'東北','岩手県':'東北','宮城県':'東北','秋田県':'東北','山形県':'東北','福島県':'東北', '茨城県':'関東','栃木県':'関東','群馬県':'関東','埼玉県':'関東','千葉県':'関東','東京都':'関東','神奈川県':'関東', } df['ブロック'] = df['都道府県'].map(block_map).fillna('その他') cols = df.select_dtypes('number').columns sns.scatterplot(data=df, x=cols[0], y=cols[1], hue='ブロック', s=80) plt.savefig('scatter_by_block.png', dpi=120, bbox_inches='tight') |
⚠️ 2変量可視化の落とし穴(補強・各 100 文字以上)
🐍 Python 実装バリエーション(matplotlib / seaborn / plotly / scipy)
1. matplotlib — 基本のスキャッタ
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 | import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) cols = df.select_dtypes('number').columns plt.scatter(df[cols[0]], df[cols[1]], s=50, alpha=0.7, edgecolor='k') plt.xlabel(cols[0]); plt.ylabel(cols[1]) plt.grid(alpha=0.3) plt.savefig('basic_scatter.png', dpi=120) |
2. seaborn — jointplot で周辺分布つき
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 | import seaborn as sns import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) cols = df.select_dtypes('number').columns sns.jointplot(data=df, x=cols[0], y=cols[1], kind='hex', height=8) |
3. scipy — gaussian_kde で 2次元密度推定
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import numpy as np import pandas as pd from scipy.stats import gaussian_kde import matplotlib.pyplot as plt df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) cols = df.select_dtypes('number').columns x = df[cols[0]].dropna().values y = df[cols[1]].dropna().values xy = np.vstack([x, y]) density = gaussian_kde(xy)(xy) plt.scatter(x, y, c=density, s=60, cmap='viridis') plt.colorbar(label='density') plt.savefig('kde_scatter.png', dpi=120, bbox_inches='tight') |
4. plotly — インタラクティブ散布図
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 | import plotly.express as px import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) cols = df.select_dtypes('number').columns fig = px.scatter(df, x=cols[0], y=cols[1], hover_name='都道府県', trendline='ols', size_max=12) fig.write_html('interactive_scatter.html') |
5. pandas — クロス集計 + ヒートマップ
data/raw/SSDSE-B-2026.csv。 列 A4101 (食料費)と A4301 (教育費)。1 2 3 4 5 6 7 8 9 10 | import pandas as pd import seaborn as sns import matplotlib.pyplot as plt df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) df['人口層'] = pd.qcut(df.select_dtypes('number').iloc[:,0], q=3, labels=['小','中','大']) df['経済層'] = pd.qcut(df.select_dtypes('number').iloc[:,1], q=3, labels=['低','中','高']) ct = pd.crosstab(df['人口層'], df['経済層']) sns.heatmap(ct, annot=True, cmap='YlOrRd', fmt='d') plt.savefig('crosstab_heatmap.png', dpi=120, bbox_inches='tight') |
🎨 直感で掴む — 2 変量の可視化
2 変量の可視化は「2 つの変数の関係を 1 枚の図にする」。 量×量=散布図、 量×質=箱ひげの群比較、 質×質=モザイクやヒートマップ。 SSDSE-B-2026 では、 A1101(人口)と L3221(消費支出)の散布図が定番で、 都市規模の大きい県ほど 1 世帯あたり支出が高めという緩い正相関が見える。
2 変量の可視化 は「可視化」カテゴリの中核概念。 初めて触れる読者は、 まずこの「🎨 直感」セクションだけ通読し、 必要になった時点で「📐 数式」「🐍 Python」「⚠️ 落とし穴」へ戻る読み方が定着しやすいです。
📐 定義・数式 — 2 変量の可視化
直感の次は、 厳密な定義を確認します。 数式は言語の一種で、 一度書き慣れれば「言葉より速く伝えられる」便利な道具。 慣れていない方は、 各記号が何を表すかを下の「🔬 記号読み解き」で 1 つずつ確認してください。
🔬 記号読み解き — 数式を「言葉」に翻訳
上の数式を眺めるだけでは身につかないので、 各記号がどんな役割を担っているかを言葉で押さえます。 「数式を音読する習慣」がつくと、 論文や教科書を読むスピードが体感で 2 倍ほど上がります。
- 左辺(結果側)
- 2 変量の可視化 で定義したい量。 解釈の対象。 単位・スケールを必ず確認する。
- 右辺(構成要素)
- 観測できる入力変数(SSDSE-B-2026 でいえば A1101・L3221 など)と推定対象パラメータ(β, σ 等)の組合せ。
- 添字 i, j, t
- i=サンプル(県)、 j=変数、 t=時点。 SSDSE-B-2026 は i ∈ {1..47} 県、 t ∈ {2008..2023}。
- 和記号 Σ
- 「足し合わせ」を表す。 添字 i が 1 から n まで動く範囲を明示するのが習慣。
- 期待値 E[·]、 分散 Var[·]
- 「ランダム変数の平均」と「ばらつき」。 SSDSE-B-2026 のような集計値でも、 標本誤差・年次変動の文脈で使える。
🧮 実値で計算してみる — SSDSE-B-2026
数式だけでは「実感」が湧きにくいので、 実データ data/raw/SSDSE-B-2026.csv(47 都道府県 × 16 年)で 1 度手計算してみると理解が定着します。
SSDSE-B-2026 (2023) で A1101 と L3221 の相関 r ≈ 0.40。 散布図に都道府県名ラベルを付けると、 東京・神奈川・愛知が右上、 鳥取・島根が左下に配置される。 「人口 → 都市規模 → 物価 → 消費」の連鎖を仮説として読み解ける。
| 都道府県 | A1101 総人口 | A1303 65 歳以上 | L3221 消費支出 |
|---|---|---|---|
| 東京都 | 14,086,000 | 3,205,000 | 341,320 |
| 神奈川県 | 9,229,000 | 2,390,000 | 306,565 |
| 大阪府 | 8,763,000 | 2,424,000 | 271,246 |
| 愛知県 | 7,477,000 | 1,923,000 | 300,221 |
| 埼玉県 | 7,331,000 | 2,012,000 | 344,092 |
| 千葉県 | 6,257,000 | 1,756,000 | 306,943 |
上記は SSDSE-B-2026 (2023) からの抜粋。 手計算で確認した値が、 後述の Python 実装で得る値と一致することを確認すると、 「数式とコードの対応関係」がクリアに見えるようになります。
🐍 Python 実装 — 2 変量の可視化
公的統計(SSDSE-B-2026)を題材に、 最小限の Python コードで 2 変量の可視化 を動作させます。 まずはこのまま実行してみてください。
# 2 変量の可視化 を SSDSE-B-2026 で実行する最小コード
import pandas as pd
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=[1])
df = df[df['SSDSE-B-2026'] == 2023] # 2023 年のみ抽出
print(df.shape) # (47, 112)
print(df[['Prefecture','A1101','A1303','L3221']].head())
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(8,6))
ax.scatter(df['A1101'], df['L3221'], alpha=0.6, color='#FF7043')
ax.set_xlabel('A1101 総人口')
ax.set_ylabel('L3221 消費支出')
ax.set_title('SSDSE-B-2026 (2023): 人口 vs 消費支出')
for i,row in df.iterrows():
if row['A1101'] > 5_000_000:
ax.annotate(row['Prefecture'], (row['A1101'], row['L3221']))
plt.savefig('bivariate_demo.png', dpi=100)
print('Pearson r:', df[['A1101','L3221']].corr().iloc[0,1])
上のコードで動かない場合は、 ①必要なパッケージがインストール済みか(pip install pandas scikit-learn scipy statsmodels matplotlib)、 ②データファイルが data/raw/SSDSE-B-2026.csv に存在するか、 ③encoding='cp932' になっているかを確認してください。
⚠️ よくある落とし穴 — 2 変量の可視化
2 変量の可視化 を使うときに初学者が踏みやすい失敗パターン。 1 度経験してしまえば次から避けられますが、 先に知っておくに越したことはありません。