📍 あなたが今見ているもの
論文で「主成分分析(PCA)」「第1主成分」「分散説明率」と書かれている部分。 多くの社会経済データのまとめ・可視化に登場。
主成分分析(PCA) とは:多次元データを「分散が最大となる軸(主成分)」へ射影して次元削減。可視化や前処理に多用。
💡 30秒で分かる結論
- 目的:高次元データを「ばらつきが最大の方向」に射影して少ない次元で情報を保つ
- 仕組み:データの共分散行列の固有ベクトルが主成分軸
- 第k主成分:直交制約のもとで k 番目にばらつきが大きい方向
- 分散説明率:各主成分が元データの分散の何%を担うか
- 用途:(i) 可視化(2D 散布図)、 (ii) 多重共線性の解消(PCR)、 (iii) ノイズ除去、 (iv) 特徴抽出
- 必須事項:標準化(z-score 化)してから PCA。 さもないと桁の大きい変数に支配される
- Python:
sklearn.decomposition.PCA(n_components=2)
🔖 キーワード索引
📖 もっと詳しく
あなたが47都道府県について、 「人口」「年齢構成」「所得」「失業率」「医療費」「教育水準」「気温」など10個の指標を持っているとします。 「どの県とどの県が似ているか」「全体としてどんなパターンがあるか」を知りたい。 でも10次元の空間は脳で想像できません。 10次元を2次元に圧縮して可視化したい──これが PCA(主成分分析)の出番です。
PCA の核心アイデア: データのばらつき(=情報量)が最も大きい方向に新しい軸(第1主成分)を立て、 次にそれと直交する中でばらつきが最大の方向に第2主成分を立て...と続けます。 元の10個の変数の代わりに、 最初の数本の主成分だけを使えば、 ほとんどの情報を保ちながら次元を減らせます。
例えば SSDSE の社会経済指標を PCA すると、 第1主成分は「都市↔︎地方」軸(東京・神奈川 vs 秋田・島根)、 第2主成分は「北方↔︎南方」軸など、 解釈可能な軸として現れることがあります。 これにより 6次元のデータを 2次元の散布図で「都道府県マップ」として描けるのです。
注意:PCA は「事前に標準化(平均0・分散1)が必須」です。 単位や桁が違う変数(人口 vs 失業率)をそのまま入れると、 桁が大きい変数だけで第1主成分が決まってしまいます。
🎨 直感で掴む
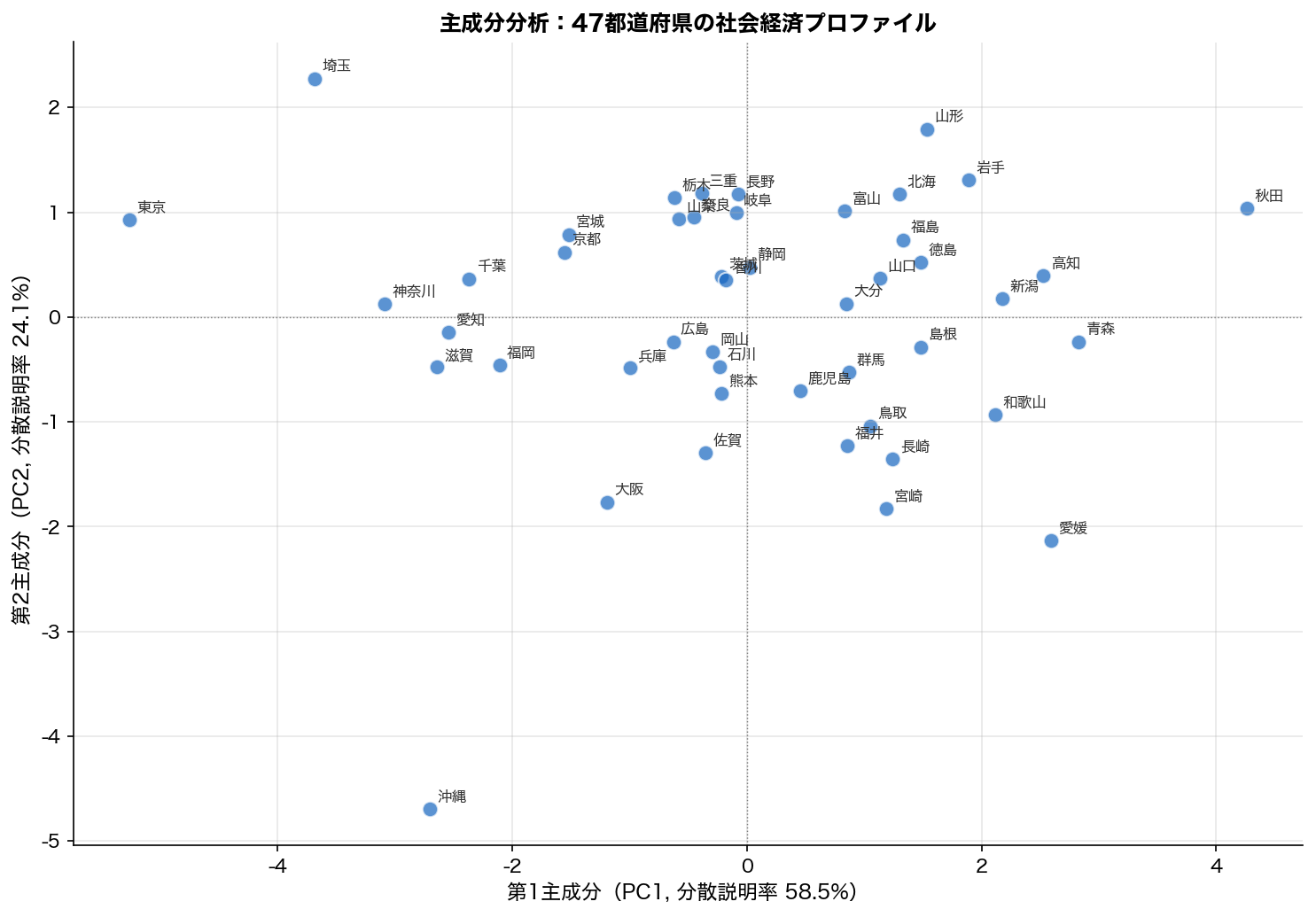
図の左上、 右下、 などにグループが見えるはずです。 これは元の6次元では分かりにくかった「都道府県の特徴の似ている度合い」を、 たった2次元で表現できているということ。 PCA がうまく機能している証拠です。
具体的に PCA が何をしているか:
- ① 標準化したデータの共分散行列(k×k 対称行列)を計算
- ② 共分散行列の固有値分解を行う:$\Sigma = V \Lambda V^\top$。 $V$ が固有ベクトル(主成分軸)、 $\Lambda$ が固有値(分散の大きさ)
- ③ 固有値が大きい順に固有ベクトルを並べ、 最初の数本(多くは2-3本)だけを使ってデータを射影
- ④ 各主成分の分散説明率 = $\lambda_k / \sum \lambda_i$。 合計で 80% 超なら「次元削減として十分」が経験則
ローディング(loading):各主成分が元のどの変数と強く関係しているかを示す係数。 ローディングを見れば「第1主成分は人口や所得が強く効いている → 都市性軸」のような解釈ができます。
📐 数式
🔬 数式を「言葉」で読み解く
- $\mathbf{X}$
- データ行列(標準化済み、 n×k)。 各行が1サンプル、 各列が1変数
- $\mathbf{w}$
- 主成分軸を表す単位ベクトル。 元の変数の線形結合の重み
- $\mathbf{w}^\top \mathbf{X}$
- データを $\mathbf{w}$ 方向に射影した値(=主成分スコア)
- $\mathrm{Var}(\cdot)$
- 射影後の分散。 これが最大になる方向を選ぶのが PCA の本質
🧮 計算してみる
2変数(高齢化率 x、 死亡率 y、 標準化済)で PCA の動きを直感的に追ってみましょう。
$\Sigma = \begin{pmatrix} 1 & 0.972 \\ 0.972 & 1 \end{pmatrix}$
固有ベクトル: $\mathbf{v}_1 = (0.707, 0.707), \mathbf{v}_2 = (0.707, -0.707)$
つまり第1主成分は「両変数を同じ重みで足した方向」(45度線方向)
たった1次元で元データの98.6%が表現できる! 2変数が強く相関していたから、 1本の軸でほぼ全てが説明できる。
🎓 PCA と他の手法の関係
PCA vs 因子分析(FA):似ているが目的が違います。 PCA は「観測変数の全分散をなるべく少ない軸で説明」、 FA は「観測変数の共通分散のみを共通因子で説明(独自分散は誤差扱い)」。 因子分析の方が「潜在変数の存在」という仮説に踏み込むので、 心理学・社会学のスケール開発で好まれます。
PCA vs SVD(特異値分解):数学的にはほぼ同じ。 SVD はより一般的な行列分解法で、 PCA は SVD の特殊例。 NumPy の np.linalg.svd でも PCA を実装できます。
PCA の限界:
- 線形変換のみ:曲面に並ぶデータは捉えられない → カーネル PCA、 t-SNE、 UMAP(非線形次元削減)
- 分散が大きい方向 ≠ 重要な方向:例えば分類問題では、 分散が小さくてもクラスを区別する軸の方が重要。 → 線形判別分析(LDA)
- 解釈が難しい:主成分は元の変数の線形結合なので、 「PC1 = 0.5×人口 + 0.3×所得 - 0.2×失業率...」のような表現になり、 物理的な意味が不明瞭になることも
PCR (Principal Component Regression):多重共線性で OLS が不安定なとき、 説明変数を PCA してから上位主成分だけで回帰する手法。 解釈は犠牲になるが安定性が向上。
⚠️ よくある落とし穴
StandardScaler で z-score 化してから PCA。👁️ 直感 — PCAは「データの広がりを最大にする方向を見つける」
主成分分析(Principal Component Analysis, PCA)は、 多次元データの「分散が最大になる方向」を新しい軸として、 元の変数を組み替える手法。 次元削減と特徴抽出の基本ツール。
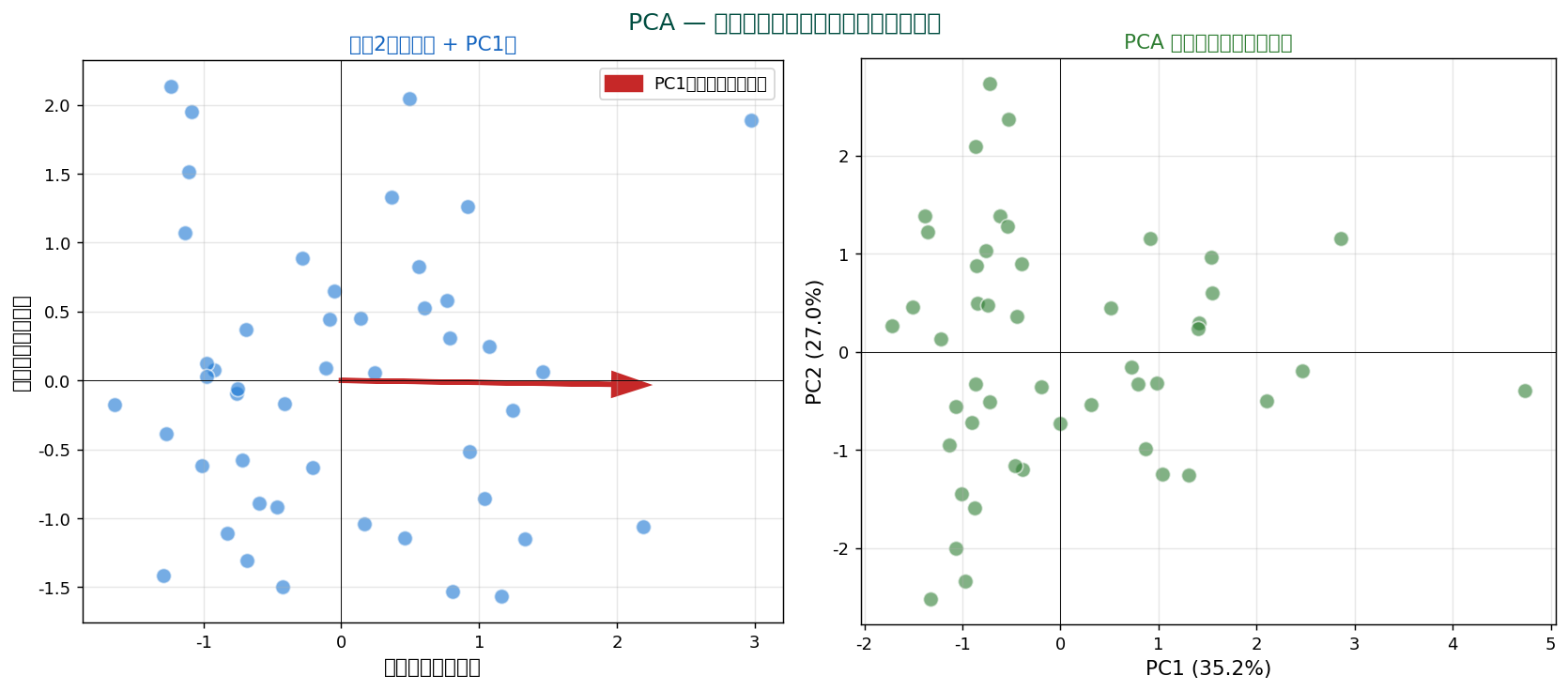
左:元の2変数(食料費と住居費)の散布図。 赤い矢印が PC1(最大分散方向)。
右:PCA 後、 データが PC1/PC2 という新しい直交軸上に再配置される。 もはや「食料費」「住居費」ではなく、 合成変数になっています。
💡 PCAは回転と考えられます。 「元の軸」を「データの最大分散方向」に回転させ、 新しい軸を作る。 情報損失を最小にしながら次元を減らせます。
🎯 PCAで何ができる?
① 次元削減
100変数のデータを、 寄与の大きい数個の主成分で要約。 ストレージ削減、 可視化、 学習高速化。
② 可視化(2次元/3次元)
高次元データを2次元/3次元に圧縮して散布図化。 クラスタや異常を視覚的に発見。
③ 多重共線性の解消
相関の強い変数群を独立な主成分に置き換える。 回帰モデルの安定化。
④ 特徴抽出
新しい「合成変数」を作り、 元の変数では見えなかった「潜在因子」を発見。
⑤ ノイズ除去
寄与の小さい成分はノイズ。 削ることでデータをスムージング。
⚙️ PCAのアルゴリズム — 3ステップ
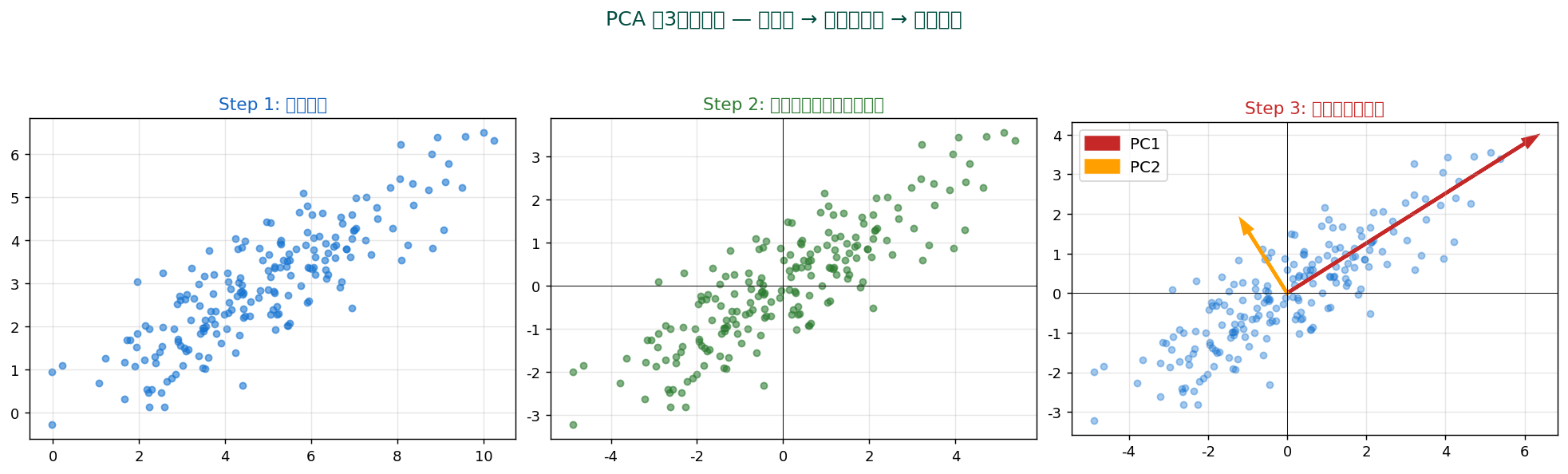
Step 1: データの中心化(標準化)
各変数から平均を引く。 場合によって標準偏差で割る(標準化):
$$ x'_i = \frac{x_i - \bar{x}}{s} $$
単位が違う変数を扱う場合は標準化必須。 単位が同じなら中心化のみでもOK。
Step 2: 共分散行列を計算
$$ \Sigma = \frac{1}{n-1} X^T X $$
p個の変数に対して p×p の対称行列。 対角成分が各変数の分散、 非対角が共分散。
Step 3: 共分散行列の固有値分解
$$ \Sigma = V \Lambda V^T $$
- V:固有ベクトル行列(主成分の方向)
- Λ:対角行列、 固有値(主成分の分散)
- 固有値の大きい順に並べる → 第1主成分、 第2主成分、 ...
Step 4: 主成分得点(projection)
$$ Z = X \cdot V $$
元データを新しい軸(主成分)に射影。 これが「主成分得点」。
実用:SVD によるPCA(より安定)
大規模データでは特異値分解(SVD)で実装するのが一般的:
$$ X = U \Sigma V^T $$
V が主成分、 ΣΣ^T/(n-1) が固有値。 sklearn の PCA は内部で SVD を使っている。
📐 数式と読み方
① 主成分得点
$$ z_{ij} = \sum_{k=1}^{p} v_{kj} \cdot x_{ik} $$
i番目のサンプルの j番目主成分得点 = 元の変数 × 固有ベクトルの重み付き和。
② 寄与率 (proportion of variance)
$$ \text{寄与率}_j = \frac{\lambda_j}{\sum_{k=1}^{p} \lambda_k} $$
各主成分が全分散のうち何%を説明するか。 固有値の比。
③ 累積寄与率
第1〜j主成分までの寄与率の合計。 通常80%や90%を超える主成分まで採用。
記号一覧
| 記号 | 読み方 | 意味 |
|---|---|---|
| X | エックス | n×p のデータ行列 |
| Σ | シグマ(大文字) | 共分散行列(p×p) |
| V | ブイ | 固有ベクトル(主成分方向) |
| λ_j | ラムダ サブ ジェイ | j番目主成分の固有値(=分散) |
| Z | ゼット | 主成分得点行列 |
🧮 SSDSE実データでの計算例
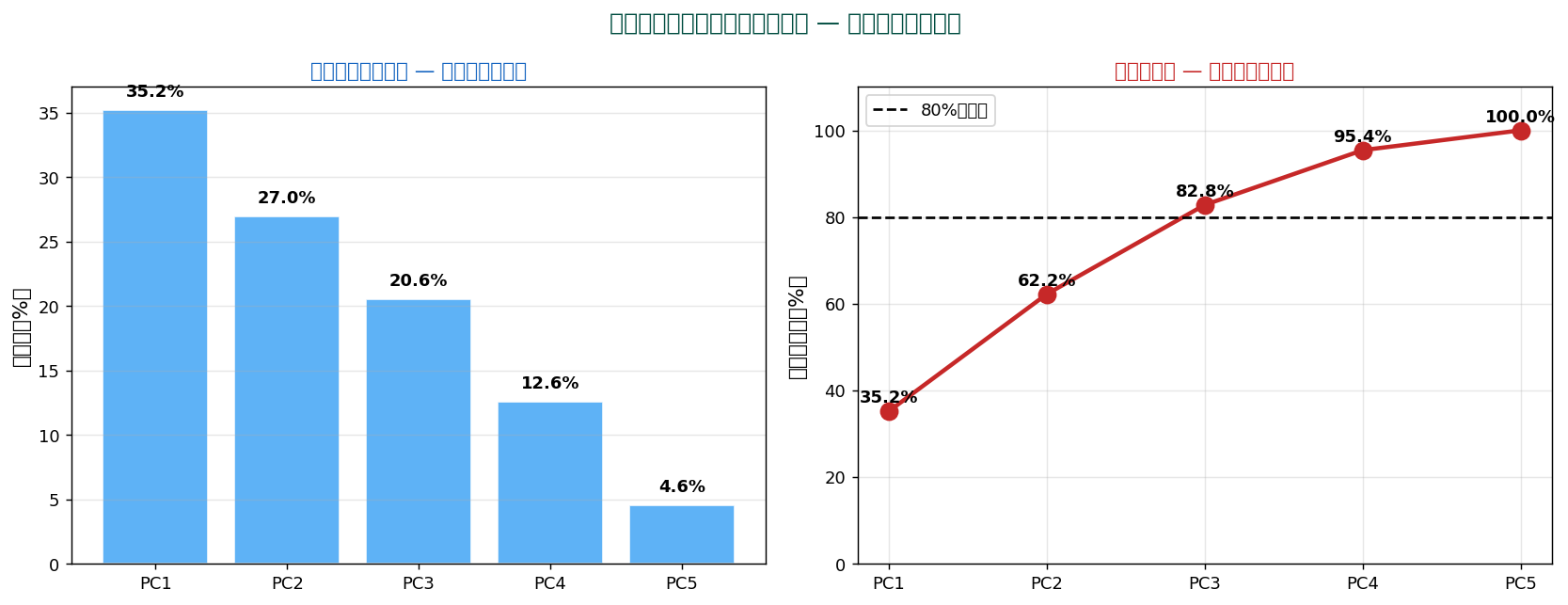
47都道府県の家計5項目(食料費、 住居費、 教育費、 光熱費、 保健医療費)で PCA を実施した結果:
各主成分の寄与率
| 主成分 | 固有値 | 寄与率 | 累積寄与率 |
|---|---|---|---|
| PC1 | 1.801 | 35.2% | 35.2% |
| PC2 | 1.379 | 27.0% | 62.2% |
| PC3 | 1.051 | 20.6% | 82.8% |
| PC4 | 0.644 | 12.6% | 95.4% |
| PC5 | 0.234 | 4.6% | 100.0% |
PC1だけで全分散の 35.2% を説明。 PC1とPC2で62.2%。 PC1 と PC2 だけで全体像がほぼ捉えられる。
🧩 主成分の意味を読み解く — 固有ベクトル(loading)
主成分は合成変数。 元の変数の重み付き和です。 重み(loading)を見ることで主成分の「意味」が分かります。
SSDSE データでの loading
| 変数 | PC1の重み | PC2の重み |
|---|---|---|
| 食料費 | +0.659 | +0.289 |
| 住居費 | -0.010 | -0.243 |
| 教育費 | +0.702 | +0.066 |
| 光熱費 | -0.151 | +0.711 |
| 保健医療費 | -0.223 | +0.590 |
主成分の解釈
PC1:符号が混在 → 支出のバランスを表す対比。 つまり PC1 のスコアが高い県は「全体的に支出が多い県」、 低い県は「節約県」と読めます。
PC2:PC1 では捉えられない別の軸。 重みの符号を見て「何 vs 何の対比」かを読み取る。
💡 主成分の解釈にはドメイン知識が必要。 重みの大きさ・符号を見て、 「この成分は何を表しているか」を仮説的に解釈し、 散布図と組み合わせて確認します。
🎨 バイプロット — 観測点と変数を同時表示
主成分得点の散布図に、 元変数の loading を矢印で重ね合わせたのがバイプロット。 「各サンプルがどの変数の影響で配置されているか」が一目で分かる強力な可視化。
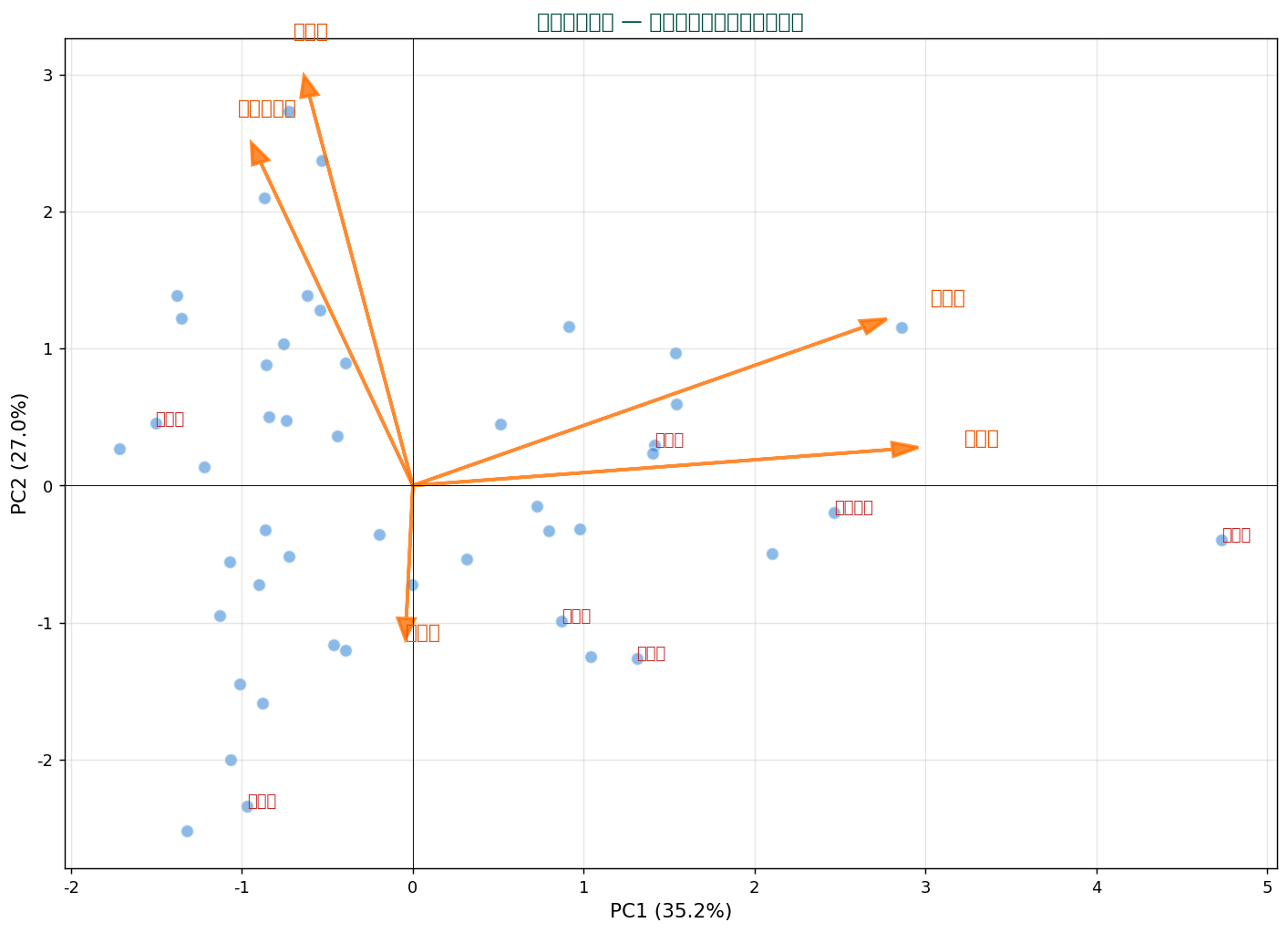
バイプロットの読み方
- 点(サンプル)の位置:主成分空間でのデータ点
- 矢印(変数)の方向:どの主成分にどれだけ影響するか
- 矢印が似た方向:変数同士が正の相関
- 矢印が反対方向:変数同士が負の相関
- 矢印が直角:変数同士が無相関
- 矢印の方向の点:その変数が大きいサンプル
🎯 主成分数の決め方 — 4つのルール
① 累積寄与率ルール
累積寄与率が80%(または90%)を超える数の主成分を採用。 もっとも一般的。
② カイザー基準
固有値が1以上の主成分を採用(標準化データの場合)。 「平均的な変数より分散が大きい主成分」を残す考え方。
③ スクリープロットの肘(elbow)
スクリープロットで「カーブが急に折れる点」を探す。 視覚的判断だが直感的。
④ 並行解析(parallel analysis)
ランダムデータの固有値分布と比較。 ランダムを超える主成分を採用。 統計的根拠あり。
🤖 機械学習での PCA の使い方
① 前処理として
高次元データで多重共線性を解消、 計算量削減。 ただし PCA は分散最大化であり、 教師あり学習の予測精度を最大化はしません。
② 可視化
クラスタリング結果を 2D で見るための定番。 t-SNE や UMAP の代替・併用。
③ ノイズ除去・データ圧縮
画像処理:固有顔(eigenfaces)で顔画像認識の前処理。 ファイルサイズ削減(JPEG の DCT に類似)。
④ 異常検知
主要な主成分で再構成した結果と元データの残差が大きいサンプルを異常と判定。
⑤ Whitening 変換
PCA で共分散行列を単位行列に変換する前処理。 PCA + 標準化のような効果で学習を加速。
非線形拡張
- Kernel PCA:カーネル法で非線形な主成分
- t-SNE / UMAP:可視化に特化した非線形手法
- Autoencoder:深層学習による非線形 PCA
🐍 Python での PCA
scikit-learn での基本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler # データの標準化(重要!) scaler = StandardScaler() X_std = scaler.fit_transform(X) # PCA 実行 pca = PCA(n_components=2) # 主成分数を指定 Z = pca.fit_transform(X_std) # 寄与率 print(f'寄与率: {pca.explained_variance_ratio_}') print(f'累積寄与率: {pca.explained_variance_ratio_.cumsum()}') # 主成分軸(固有ベクトル) print(f'主成分軸:\n{pca.components_}') # 固有値 print(f'固有値: {pca.explained_variance_}') |
累積寄与率で主成分数を自動決定
1 2 3 | pca = PCA(n_components=0.95) # 累積寄与率95%まで Z = pca.fit_transform(X_std) print(f'採用された主成分数: {pca.n_components_}') |
numpy で手作りPCA
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | import numpy as np # 1. 中心化 X_centered = X - X.mean(axis=0) # 2. 共分散行列 cov_matrix = np.cov(X_centered, rowvar=False) # 3. 固有値分解 eig_vals, eig_vecs = np.linalg.eigh(cov_matrix) # 4. 降順ソート order = np.argsort(eig_vals)[::-1] eig_vals = eig_vals[order] eig_vecs = eig_vecs[:, order] # 5. 射影 Z = X_centered @ eig_vecs # 寄与率 ratio = eig_vals / eig_vals.sum() |
SVD でPCA
バイプロットの描画
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize=(10, 8)) ax.scatter(Z[:, 0], Z[:, 1], alpha=0.5) # 変数を矢印で for i, name in enumerate(feature_names): ax.arrow(0, 0, pca.components_[0, i] * 3, pca.components_[1, i] * 3, color='red', head_width=0.05) ax.text(pca.components_[0, i] * 3.2, pca.components_[1, i] * 3.2, name) ax.set_xlabel(f'PC1 ({pca.explained_variance_ratio_[0]*100:.1f}%)') ax.set_ylabel(f'PC2 ({pca.explained_variance_ratio_[1]*100:.1f}%)') |
🚧 PCAの落とし穴
1️⃣ 標準化を忘れる
単位が違う変数(kg と cm)をそのまま PCA すると、 単位の大きい変数が支配的に。 必ず標準化してから実施。
2️⃣ 非線形関係は捉えられない
PCA は線形変換。 曲線的なパターンは見逃します。 そのときは Kernel PCA、 t-SNE、 UMAP、 Autoencoder を。
3️⃣ 解釈が困難な場合
主成分は合成変数で、 元の変数ほど直感的でないことがある。 特に loading の重みが似た値なら解釈が難しい。 回転(varimax 回転、 因子分析)を検討。
4️⃣ 外れ値に弱い
分散を最大化するため、 外れ値の影響を受けやすい。 RobustPCA や事前の外れ値除去を。
5️⃣ 主成分は予測精度を保証しない
PCA は教師なし。 「分散が大きい方向」が「目的変数の予測に有用」とは限らない。 PCR(主成分回帰)より PLS のほうが優れることも。
6️⃣ 符号の不定性
固有ベクトルは符号が反転しても同じ主成分。 異なる環境で計算すると符号が違うことが。 解釈時に注意。
📜 PCAの歴史
- Karl Pearson(1901):"On lines and planes of closest fit" で PCA を発見
- Harold Hotelling(1933):心理学への応用で PCA を再発見・体系化
- Karhunen(1947)、 Loève(1948):信号処理での Karhunen-Loève 展開
- Eckart-Young(1936):SVD と低ランク近似の関係を証明
- Sirovich & Kirby(1987):固有顔(eigenfaces)で顔認識を実用化
- Schölkopf(1998):Kernel PCA で非線形に拡張
120年以上の歴史を持ち、 現代のデータサイエンスの中核的手法として使われ続けています。
🐍 Python 実装バリエーション(sklearn / numpy / scipy / Kernel / Sparse)
A. sklearn.decomposition.PCA(標準)
1 2 3 4 5 6 7 8 9 10 11 | import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8', skiprows=1) X = df[['一人当たり県民所得','世帯人員','高齢化率','人口密度','大学進学率']] Xs = StandardScaler().fit_transform(X) pca = PCA(n_components=3).fit(Xs) print('寄与率', pca.explained_variance_ratio_) print('累積', pca.explained_variance_ratio_.cumsum()) print('ローディング\n', pd.DataFrame(pca.components_.T, index=X.columns, columns=['PC1','PC2','PC3']).round(3)) |
B. numpy.linalg.svd 直書き(教育的)
1 2 3 4 5 6 | import numpy as np Xc = Xs - Xs.mean(axis=0) U, S, Vt = np.linalg.svd(Xc, full_matrices=False) loadings = Vt.T scores = U * S # = Xc @ Vt.T print((S**2 / (S**2).sum())[:3]) |
C. scipy.linalg.eigh による固有値分解
1 2 3 4 5 | from scipy.linalg import eigh cov = np.cov(Xs, rowvar=False) eigvals, eigvecs = eigh(cov) order = np.argsort(eigvals)[::-1] print(eigvals[order]) |
D. KernelPCA(非線形多様体)
1 2 | from sklearn.decomposition import KernelPCA kpca = KernelPCA(n_components=2, kernel='rbf', gamma=0.1).fit_transform(Xs) |
E. SparsePCA / FactorAnalysis(解釈性向上)
1 2 3 4 | from sklearn.decomposition import SparsePCA, FactorAnalysis spca = SparsePCA(n_components=3, alpha=1.0, random_state=42).fit(Xs) fa = FactorAnalysis(n_components=3).fit(Xs) print(pd.DataFrame(spca.components_.T, index=X.columns).round(2)) |
F. IncrementalPCA(大規模データのストリーム処理)
1 2 3 4 | from sklearn.decomposition import IncrementalPCA ipca = IncrementalPCA(n_components=3, batch_size=10) for i in range(0, len(Xs), 10): ipca.partial_fit(Xs[i:i+10]) |
⚠️ PCA の落とし穴 7 連発
1. 標準化を忘れる。「人口(万人)」と「失業率(%)」を素のまま PCA すると、 人口の桁が圧倒的に大きいため、 第 1 主成分が「人口の方向」とほぼ一致してしまい、 他の指標が全く反映されません。 StandardScaler(z 化)または RobustScaler を必ず通しましょう。
2. 主成分の符号反転を気にしない。PCA の固有ベクトルは符号が定まらないため、 ライブラリ・乱数によって PC1 が反転することがあります。 解釈で「PC1 が大きい県」と書くなら、 必ずローディングを確認して「PC1 が高い → ◯◯ が高い」の対応を明示しましょう。
3. 累積寄与率だけで主成分数を決める。「80% を超えるまで」という閾値は経験則であり、 サンプル数や目的によって変えるべきです。 スクリープロットの肘、 カイザー基準(固有値 ≥ 1)、 並列分析(parallel analysis)、 CV 損失の最小点を併用しましょう。
4. 線形変換以外を試さない。三日月型・ドーナツ型のように非線形多様体上のデータは、 PCA では分散最大方向に「貫通」してしまい、 構造を捉えられません。 Kernel PCA・t-SNE・UMAP・Isomap などの非線形手法も比較しましょう。
5. PC スコアを使った回帰(PCR)で解釈を捨てる。多重共線性の解消には便利ですが、 「PC1 の係数が 0.3」と言われても元の変数への落とし込みが難しいです。 解釈優先なら Ridge・Lasso、 もしくは Sparse PCA を検討しましょう。
6. 外れ値で第 1 主成分を奪われる。1 県(例:東京)が他県より極端な値を持つと、 PC1 がほぼ「東京の方向」になり、 残りの分散が捉えにくくなります。 RobustPCA や、 外れ値を除いた感度分析を行いましょう。
7. テストデータで fit_transform を再実行する。訓練データで学習した PCA は、 テストには transform のみ適用しなくてはいけません。 テストで fit すると、 異なる回転行列が出てしまい予測モデルが壊れます。 sklearn Pipeline を使えば自動で正しい順序になります。
🔗 関連用語(前提・並列・発展)
📘 前提となる用語
- 共分散・相関行列 — PCA の核となる行列。
- 固有値・固有ベクトル — 主成分軸の正体。
- 標準化 — PCA の前処理の必須項目。
- 分散 — 主成分の評価基準。
- 線形代数の基礎 — 行列演算と直交変換。
⚖️ 並列で比較する用語
- 因子分析 — 共通分散だけを抽出。
- 線形判別分析 (LDA) — クラス分離が目的の次元削減。
- 独立成分分析 (ICA) — 統計的独立性で分解。
- NMF (非負値行列分解) — 非負制約の分解。
🚀 発展で学ぶ用語
- Kernel PCA — 非線形多様体に対応。
- t-SNE — 局所構造を保つ可視化。
- UMAP — 多様体学習の現代標準。
- オートエンコーダ — 非線形 PCA の深層学習版。
- Sparse PCA — ローディングをスパース化して解釈性を向上。
- Robust PCA — 外れ値耐性のある分解。
🗺️ 概念マップ — 3つの視点で体系を理解する
主成分分析(PCA) がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 教師なし学習 › 次元削減 › 主成分分析
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「主成分分析(PCA)」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「主成分分析(PCA)」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。