📍 あなたが今見ているもの
論文中に 「分散」として登場する用語。
分散 とは:「平均からのズレ」の2乗の平均。データの広がりを測る。標準偏差の2乗。
💡 30秒で分かる結論
- 定義:「平均からのズレ」の2乗の平均。データの広がりを測る。標準偏差の2乗。
- カテゴリ:記述統計
📖 もっと詳しく
分散(variance)は、 データの「広がり(散らばり)」を測る量です。 平均だけでは「中心」しか分からないので、 散らばりを定量化するために使います。
計算:「各データ点と平均との差」を 2乗して、 平均したもの。 2乗するのは正負を打ち消して、 散らばりだけを取り出すため。
単位の問題:元の単位の2乗(cm² など)になるため、 直感的に使いにくい。 そこで平方根を取って元の単位に戻したのが 標準偏差。 実用ではこちらの方が好まれます。
応用:(i) 回帰の R² は「分散の分解」、 (ii) ANOVA(分散分析)は「群間分散 vs 群内分散」、 (iii) PCA は「分散最大の方向」を探す。 分散は統計の中核概念です。
🎨 直感で掴む — 分散は「ばらつきの大きさ」
分散(variance)は、 データの散らばり具合を1つの数字で表す指標。 平均から各データがどれくらい離れているか、 を2乗してから平均したものです。
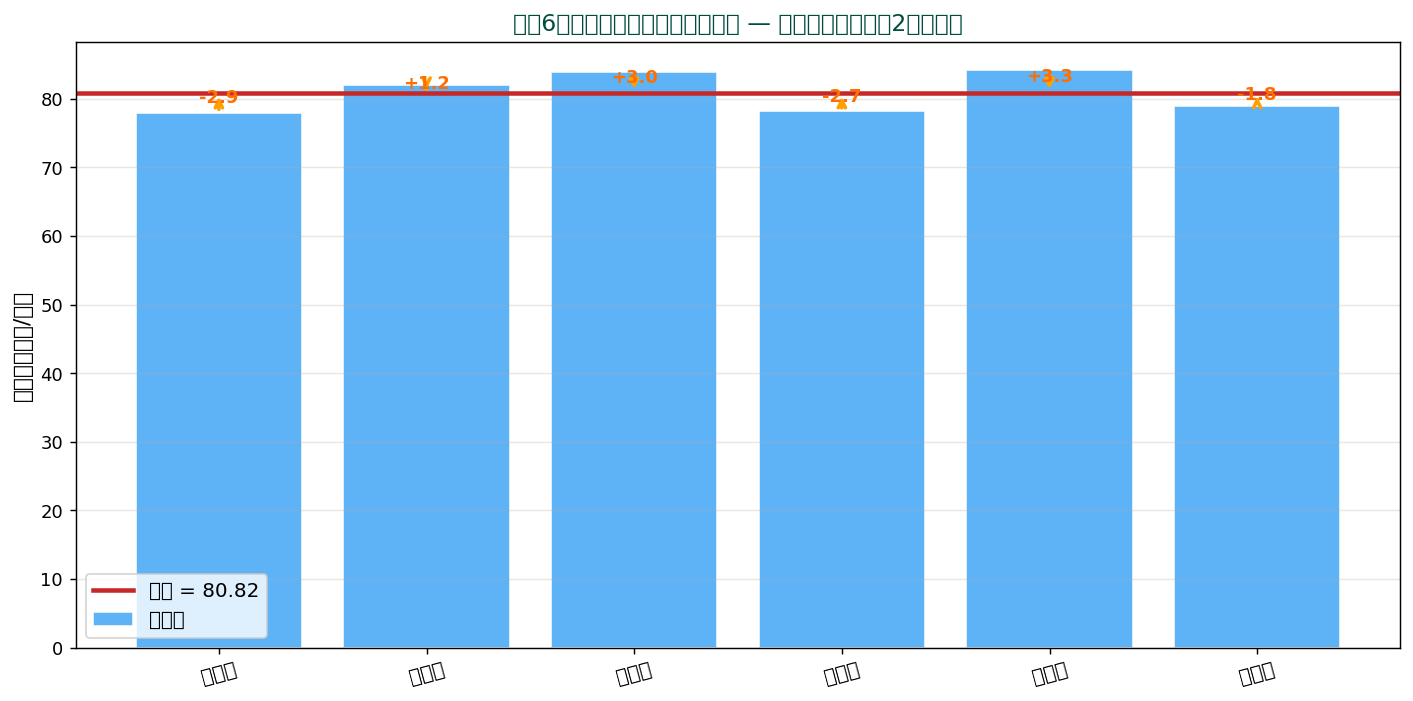
各バーが東北6県の食料費。 赤線が平均、 オレンジ矢印が各県から平均までの距離(偏差)。 この偏差を集約したのが分散です。
なぜ「2乗」するのか?
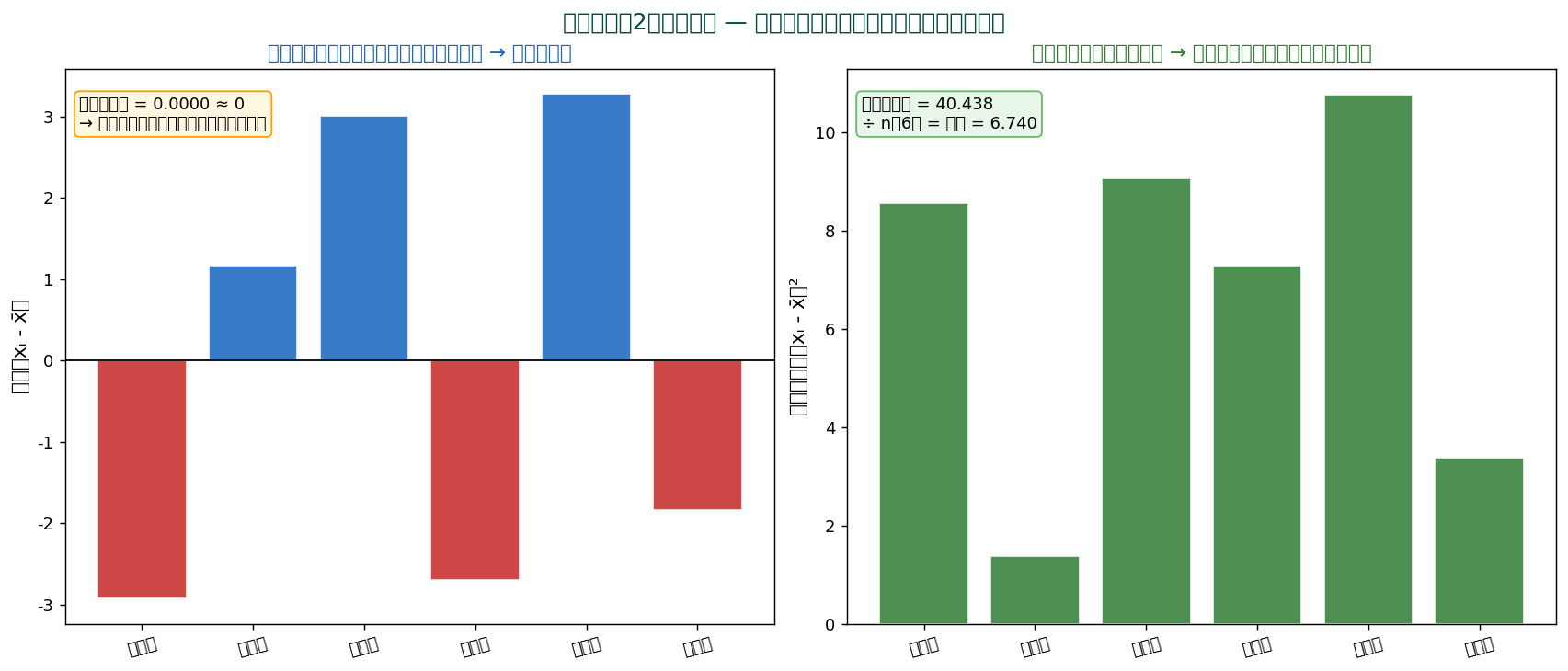
左:偏差はプラスとマイナスが混在し、 合計はゼロになります(重心の性質)。 そのままでは「ばらつき」を表せません。
右:偏差を2乗するとすべて非負になり、 「平均からの距離の大きさ」を測れます。 この平均が分散。
3つの分散レベル
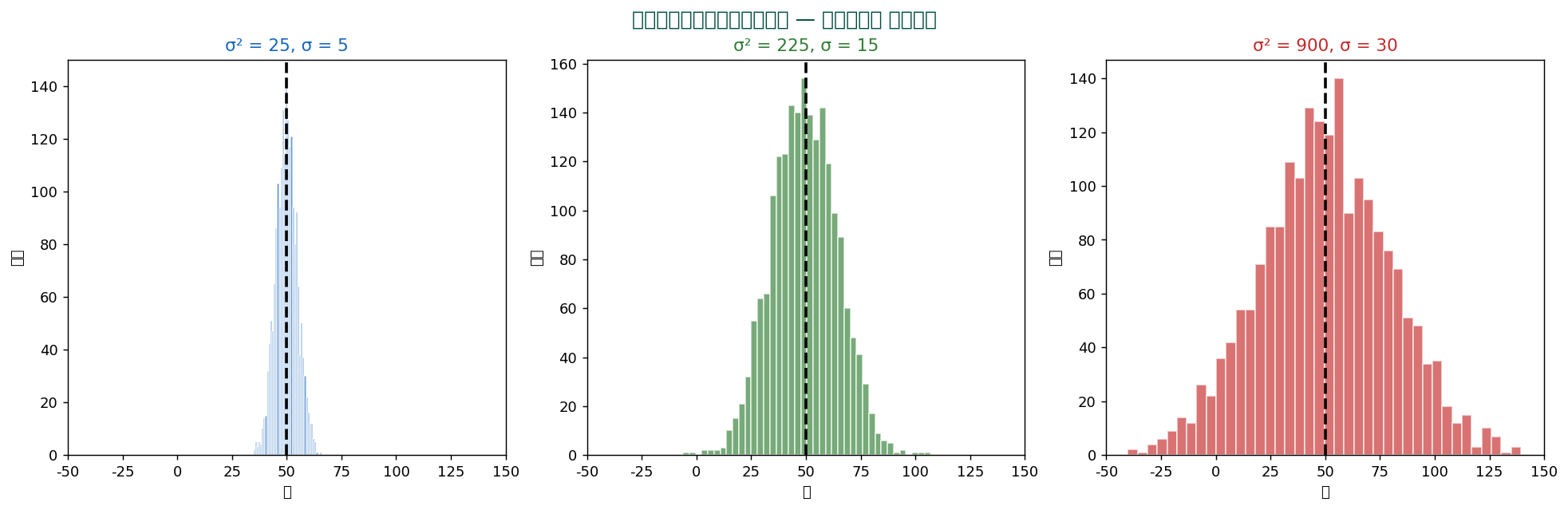
同じ平均(μ=50)でも、 分散が大きいほどデータは広がります。 分散は不確実性の大きさとも解釈できます。
💡 分散は幾何学的には「平均からの距離の2乗の平均」、 物理学的には「慣性モーメント」、 確率論的には「期待値の2次モーメント」と多角的に理解できます。
🧮 計算ステップ — 東北6県の分散を手計算
データと偏差・偏差の二乗
| 都道府県 | 食料費 xᵢ | 偏差 (xᵢ - x̄) | 偏差の二乗 (xᵢ - x̄)² |
|---|---|---|---|
| 青森県 | 77.899 | -2.925 | 8.5556 |
| 岩手県 | 81.997 | +1.173 | 1.3759 |
| 宮城県 | 83.835 | +3.011 | 9.0661 |
| 秋田県 | 78.124 | -2.700 | 7.2900 |
| 山形県 | 84.105 | +3.281 | 10.7650 |
| 福島県 | 78.984 | -1.840 | 3.3856 |
| 合計 | 484.944 | ≈ 0 | 40.4382 |
平均 x̄ = 80.824 千円。
標本分散(÷ n)
$$ s^2_n = \frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})^2 $$
計算:40.4382 ÷ 6 = 6.7397
不偏分散(÷ n-1)— 推論用
$$ s^2 = \frac{1}{n - 1} \sum_{i=1}^{n} (x_i - \bar{x})^2 $$
計算:40.4382 ÷ 5 = 8.0876
東北6県の食料費の分散は約 6.74〜8.09 (千円²)。 平方根を取れば標準偏差 ≈ 2.84 千円。
🎲 なぜ n-1 で割るのか? — Bessel補正
「ばらつきを n 個で割って平均すれば、 1個あたりのばらつきになる」が直感的。 でも統計学ではn-1 で割るのが標準。 なぜでしょうか。
標本分散はバイアスを持つ
「÷n」で計算した標本分散 s²_n は、 母集団全体の分散 σ²より小さくなる傾向があります。
$$ \mathbb{E}[s^2_n] = \frac{n - 1}{n} \sigma^2 \quad < \sigma^2 $$
つまり「÷n」だと、 平均的に母分散より (n-1)/n 倍だけ過小評価します。 これを是正するため、 (n-1)/n の逆数 n/(n-1) を掛けて補正:
$$ s^2 = \frac{n}{n-1} \cdot s^2_n = \frac{1}{n - 1} \sum (x_i - \bar{x})^2 $$
これが不偏分散。 期待値が母分散 σ² に一致する(不偏性)。
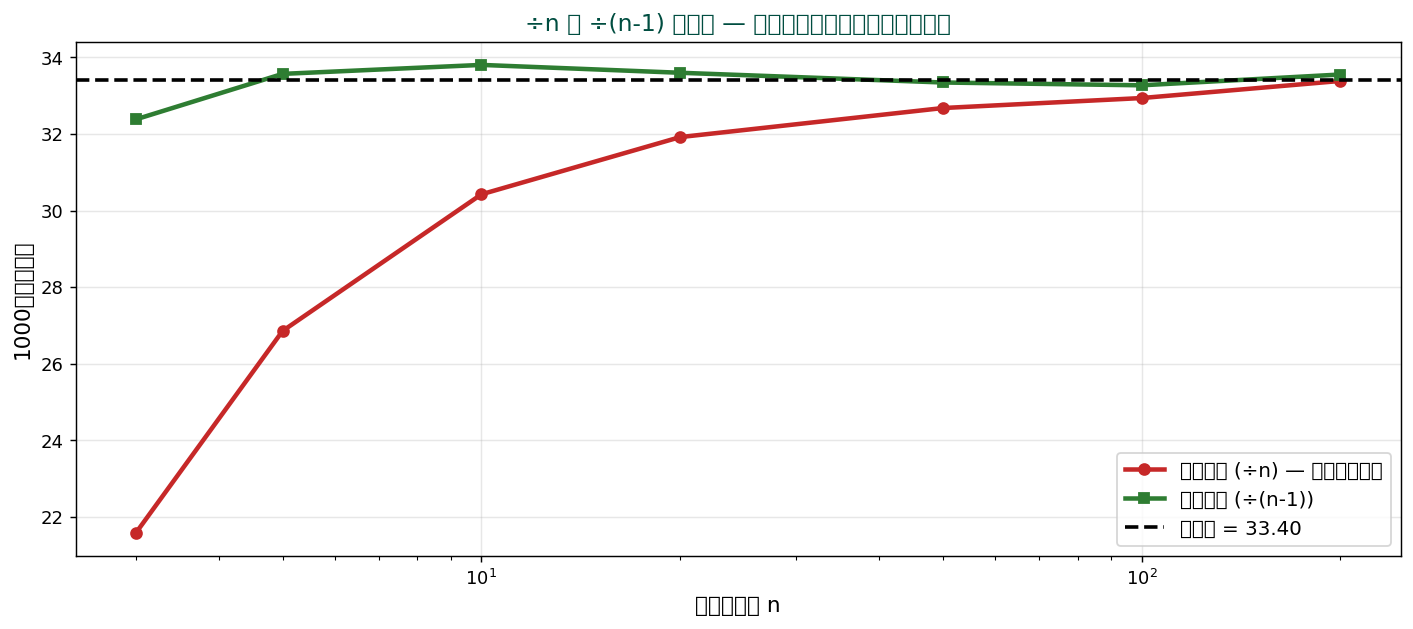
上の図は1000回のサンプリングで分散を計算した平均値。 赤線(÷n)は常に真値より下にあり、 緑線(÷(n-1))は真値に正しく一致。
直感的説明:自由度
n 個のデータがあって、 平均 x̄ を計算すると1つの「制約」ができます(偏差の合計がゼロ)。 残りの「自由に動ける情報の数」は n-1 個。 これが自由度と呼ばれる概念。
- n 個のデータ:n 個の情報
- x̄ で「平均」を1つ推定済み:1自由度消費
- 残り自由度:n − 1
自由度で割ることで、 「情報の量に合わせた平均」になります。
どちらを使うべきか?
- 標本そのものを記述したい(要約統計)→ ÷n(標本分散)
- 母集団の分散を推定したい(推論統計)→ ÷(n-1)(不偏分散)
- 機械学習では多くの場合 ÷n(最尤推定量)が使われる
- numpy のデフォルト:
np.var(x)は ÷n、ddof=1で ÷(n-1) - pandas のデフォルト:
df.var()は ÷(n-1) — 推論用
📐 数式と読み方
① 母分散(population variance)
$$ \sigma^2 = \mathbb{E}[(X - \mu)^2] = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 $$
② 不偏分散(sample variance)
$$ s^2 = \frac{1}{n - 1} \sum_{i=1}^{n} (x_i - \bar{x})^2 $$
| 記号 | 読み方 | 意味 |
|---|---|---|
| σ² | シグマの二乗 | 母分散 |
| s² | エスの二乗 | 不偏分散(標本ベース) |
| (xᵢ - x̄)² | エックスアイ マイナス エックスバー の二乗 | 偏差の二乗 |
| E[·] | 期待値 | 確率変数の重み付き平均 |
🔬 数式を言葉で読み解く — ③ 計算用の別形式
展開すると:
$$ s^2_n = \overline{x^2} - \bar{x}^2 = \frac{1}{n} \sum x_i^2 - \bar{x}^2 $$
「二乗の平均 − 平均の二乗」とも呼ばれます。 計算量が少なく、 ストリーミングデータでも使いやすい。
🔧 分散の性質 — 線形変換とどう動くか
① 定数を足しても分散は変わらない
$$ \text{Var}(X + c) = \text{Var}(X) $$
全データに同じ数を足すと、 全部が平行移動するだけで「散らばり」は変わらない。
② 定数倍すると分散はその二乗倍
$$ \text{Var}(aX) = a^2 \cdot \text{Var}(X) $$
2倍すると分散は4倍、 3倍すると分散は9倍。 ばらつきも2乗で広がる。
③ 独立な場合の和の分散
$$ \text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y) \quad (X, Y \text{ 独立}) $$
独立な変数の和の分散は、 それぞれの分散の和。 大数の法則の根拠でもあります。
④ 一般の場合(共分散項あり)
$$ \text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y) + 2 \text{Cov}(X, Y) $$
独立でない場合、 共分散の項が追加されます。 ポートフォリオ理論や分散分析の基礎。
⑤ 標本平均の分散
$$ \text{Var}(\bar{X}) = \frac{\sigma^2}{n} $$
サンプルサイズを n 倍にすると、 平均のばらつきは 1/n に減る。 これが「サンプルを多く取れば平均が安定する」の理論的根拠。
📏 標準偏差との関係
分散の平方根が標準偏差(standard deviation):
$$ \sigma = \sqrt{\sigma^2}, \quad s = \sqrt{s^2} $$
分散は単位が「元の単位の2乗」(千円² など)になるため、 解釈しにくいことがあります。 平方根を取った標準偏差は元のデータと同じ単位を持つので、 直感的。
| 統計量 | 単位 | 直感性 | 数学的扱いやすさ |
|---|---|---|---|
| 分散 σ² | 元の単位の二乗(千円²) | 低い | 高い(線形性、 加法性) |
| 標準偏差 σ | 元の単位(千円) | 高い | 低い(加法性なし) |
🎯 分散分析 (ANOVA) — 分散の分解
分散の最大の応用が分散分析(Analysis of Variance)。 全体の分散を「群間の差による分散」と「群内の偶然の分散」に分けて、 「群差は本物か?」を検定します。
分散の分解
$$ \text{総分散} = \text{群間分散} + \text{群内分散} $$
$$ \sum_i (x_i - \bar{x})^2 = \sum_g n_g (\bar{x}_g - \bar{x})^2 + \sum_g \sum_i (x_{gi} - \bar{x}_g)^2 $$
F検定量
$$ F = \frac{\text{群間分散} / df_1}{\text{群内分散} / df_2} $$
F が大きい → 群間差が大きい → 群差は有意。 t検定の多群版とも言えます。
使用例
- 東北・関東・関西の食料費に違いはあるか?
- 3種類の肥料で収穫量に差はあるか?
- 4種類の治療法で効果に差はあるか?
🤖 機械学習での分散
① バイアス-バリアンス分解
機械学習モデルの予測誤差は3つに分解されます:
$$ E[(y - \hat{f}(x))^2] = \text{Bias}^2 + \text{Variance} + \sigma^2_\epsilon $$
- Bias²:モデル予測の平均と真の関数のズレ(モデル単純すぎ)
- Variance:データセット間での予測のバラつき(モデル複雑すぎ)
- σ²_ε:ノイズ(避けられない誤差)
過学習=Variance が大(複雑モデルは学習データに敏感)、 過小学習=Bias が大。
② PCA(主成分分析)
「分散を最大化する方向」を順に見つけ、 データの主要な変動を捉える次元削減手法。 分散がそのまま「情報量」として使われる。
③ Variance Threshold(特徴選択)
分散がほぼゼロの特徴量(全データで値が同じ)は予測に寄与しないので除外する前処理。
1 2 3 | from sklearn.feature_selection import VarianceThreshold selector = VarianceThreshold(threshold=0.01) X_filtered = selector.fit_transform(X) |
④ Batch Normalization
各層の出力を「平均0、 分散1」に標準化する深層学習の必須技術。 「分散」が出てくるたびに必要なのが正規化。
🐍 Python での計算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import numpy as np import pandas as pd # numpy のデフォルトは ÷n(標本分散) arr = np.array([77.90, 82.00, 83.83, 78.12, 84.11, 78.98]) print(np.var(arr)) # 標本分散(÷n) print(np.var(arr, ddof=1)) # 不偏分散(÷(n-1)) # pandas のデフォルトは ÷(n-1)(不偏分散) s = pd.Series(arr) print(s.var()) # 不偏分散 print(s.var(ddof=0)) # 標本分散 # 行列の分散(軸指定) mat = np.random.randn(100, 5) print(np.var(mat, axis=0)) # 各列の分散 # 共分散行列(分散は対角成分) cov_mat = np.cov(mat, rowvar=False) diag = np.diag(cov_mat) # 各列の分散 |
ストリーミング計算(Welford's algorithm)
データを1個ずつ受け取る場合の安定アルゴリズム:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | class StreamingVariance: def __init__(self): self.n = 0 self.mean = 0.0 self.M2 = 0.0 def update(self, x): self.n += 1 delta = x - self.mean self.mean += delta / self.n delta2 = x - self.mean self.M2 += delta * delta2 def variance(self, unbiased=True): if self.n 2: return float('nan') return self.M2 / (self.n - 1 if unbiased else self.n) # 使用例 sv = StreamingVariance() for x in [1, 2, 3, 4, 5]: sv.update(x) print(sv.variance()) # 2.5(÷(n-1)) |
🚧 分散の落とし穴
1️⃣ ÷n か ÷(n-1) か — 文脈で判断
numpy のデフォルトと pandas のデフォルトが違う点に注意。 ddof(delta degrees of freedom)パラメータで明示的に指定するのが安全。
2️⃣ 単位の混乱
分散は元の単位の二乗。 「分散 = 500千円²」は直感的でない。 解釈するときは標準偏差(√500 ≈ 22千円)に変換すべき。
3️⃣ 外れ値の影響
2乗するため、 外れ値1個が分散を大きく押し上げます。 外れ値ありデータでは MAD(中央絶対偏差)や IQR を併用するとよい。
4️⃣ 異なる単位の変数を比較できない
身長(cm)と体重(kg)の分散を直接比較するのは無意味。 変動係数 (CV = σ/μ) で無次元化するのが標準。
5️⃣ サンプルサイズが小さいと不安定
n=5 程度では分散の推定値は大きくブレます。 信頼区間(χ²分布ベース)を計算するか、 ブートストラップで分布を見るのが安全。
📜 分散の歴史
- Gauss(1809):最小二乗法と正規分布で分散の概念を確立
- Bessel(1838):天文観測誤差の研究で「n-1で割る」補正を提案
- Karl Pearson(1894):「standard deviation」という用語を導入
- Fisher(1918):「variance」という用語を導入。 分散分析(ANOVA)を発明
- Markowitz(1952):分散を「リスク」として使ったポートフォリオ理論で経済学に応用
分散は単なる記述統計を超え、 推論・予測・最適化など現代統計学の中核に。
🗺️ 概念マップ — 3つの視点で体系を理解する
分散 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 記述統計 › ばらつき › 分散
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「分散」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「分散」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(拡張)
分散と関連する重要用語:
🧮 SSDSE-B 実値計算 — 47都道府県の主要変数で分散を計算
SSDSE-B-2026 の主要 6 変数で、 ① 標本分散、 ② 不偏分散、 ③ 標準偏差、 ④ 変動係数(CV)、 ⑤ Welford のオンライン計算 を実演する。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import numpy as np import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) df.columns = [c.strip() for c in df.columns] feats = ['総人口', '65歳以上人口', '製造品出荷額等', '現金給与総額', '完全失業率', '出生率'] print(f'{"変数":<20s}{"平均":>14s}{"σ²(母)":>14s}' f'{"s²(不偏)":>14s}{"SD":>12s}{"CV":>10s}') for f in feats: x = df[f].astype(float).values mu = x.mean() var_pop = x.var(ddof=0) var_samp = x.var(ddof=1) sd = x.std(ddof=1) cv = sd / mu print(f'{f:<20s}{mu:14.2f}{var_pop:14.2f}{var_samp:14.2f}' f'{sd:12.2f}{cv:10.3f}') |
典型的な観察例: 総人口の CV は 1.0 を超え(東京がずば抜けて大きい)、 現金給与の CV は 0.07 程度。 「ばらつきを比較する」には絶対値の分散ではなく、 単位無次元の CV を使うのが定石。 また ddof=0(母分散)と ddof=1(不偏分散)の差は n=47 では約 2.2% で実用上ほぼ無視できるが、 教科書通り「サンプルから母数を推定」する文脈では必ず ddof=1 を使う。
Welford のオンラインアルゴリズム(数値安定)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # 大規模ストリーミングや高精度計算が必要なら Welford 法 def welford(xs): n, mean, M2 = 0, 0.0, 0.0 for x in xs: n += 1 delta = x - mean mean += delta / n M2 += delta * (x - mean) return mean, M2/n, M2/(n-1) # 母分散, 不偏分散 x = df['現金給与総額'].astype(float).values mu, var_pop, var_samp = welford(x) print(f'Welford : μ={mu:.2f}, σ²={var_pop:.2f}, s²={var_samp:.2f}') print(f'numpy : μ={x.mean():.2f}, σ²={x.var(ddof=0):.2f}, ' f's²={x.var(ddof=1):.2f}') |
分散の加法性(独立確率変数の和)
1 2 3 4 5 6 7 8 9 10 11 | # 15歳未満 + 65歳以上 = 「非生産年齢人口」とすると Var の加法性は崩れる # (両者は同じ県内のサンプルなので相関がある) a = df['15歳未満人口'].astype(float) b = df['65歳以上人口'].astype(float) print(f'Var(a) = {a.var(ddof=1):.2f}') print(f'Var(b) = {b.var(ddof=1):.2f}') print(f'Var(a+b) = {(a+b).var(ddof=1):.2f}') print(f'2*Cov(a,b) = {2 * a.cov(b):.2f}') print(f'分散の加法性チェック: ' f'Var(a)+Var(b)+2Cov(a,b) = ' f'{a.var(ddof=1) + b.var(ddof=1) + 2*a.cov(b):.2f}') |
⚠️ 分散の落とし穴 — 6 つの典型ミス
① ddof=0 と ddof=1 を取り違える
numpy.var() の既定は ddof=0(母分散)、 pandas Series.var() の既定は ddof=1(不偏分散)と、 主要ライブラリでデフォルト値が違う。 これに気づかず numpy と pandas を混在させると、 nが小さいデータで結果が 5〜10% 単位でズレる。 学術論文や検定で使うのは「サンプルから母数を推定する」目的なので ddof=1(n-1 で割る)が正しい。 必ず明示する習慣をつけ、 既定任せにしない。
② 単位の二乗を忘れる
「身長(cm)」の分散は cm² であり、 元データと単位が違う。 そのため分散の絶対値は直感的に解釈しにくく、 報告は標準偏差(SD = √分散、 単位は元と同じ)で行うのが原則。 「年収のばらつきが分散 1.2 × 10⁹ 円²」と書くより「SD ≈ 35,000 円」の方がずっと意味が分かる。 査読でも SD で報告するよう要求されることが多い。
③ 外れ値で分散が劇的に膨らむ
分散は偏差を二乗するため、 外れ値 1 個で大きく動く。 47 都道府県で東京を含めると総人口の SD が 200 万人台、 外すと 100 万人台、 と大きく変わる。 ロバストな散布度として IQR(四分位範囲)、 MAD(中央絶対偏差)が代替に使える。 MAD = median(|x - median(x)|) を SD に変換するなら ×1.4826(正規分布前提)。 外れ値の処理を明示せずに分散を比較しない。
④ 加法性を「独立でない変数」にも適用する
「Var(X+Y) = Var(X) + Var(Y)」は X と Y が独立(または無相関)のときだけ成立。 相関がある場合は Var(X+Y) = Var(X) + Var(Y) + 2·Cov(X,Y) が正しい。 共分散項を忘れて足し算するとポートフォリオのリスクを誤算する。 SSDSE データでも「15歳未満人口 + 65歳以上人口」は強い負相関を持ち、 単純加算では合わない。 リスク管理・ファイナンスでは共分散項が本質。
⑤ 「分散が小さい = 推定が正確」と誤解する
分散はデータのばらつきを測るが、 推定量の精度を測るのは「標準誤差(SE = SD/√n)」。 SE = SD ではない。 サンプルサイズ n を増やせば SE は √n に反比例して下がるが、 SD(母集団の真のばらつき)は変わらない。 「分散が大きい / 小さい」と「推定が不確実 / 確実」は別概念で、 両者を混同するのは初学者の典型ミス。
⑥ スケールが違う変数同士の分散を直接比較する
「総人口の分散」と「失業率の分散」を直接比較しても意味がない(単位が違う)。 単位無次元の比較には変動係数 CV = SD/Mean を使う。 ただし平均が 0 に近い変数(収益率など)では CV が爆発するので、 z-スコア化(標準化)して比較するか、 ロバストな統計(中央値・MAD)を使う方が安全。 PCA や Lasso 等の機械学習でスケーリングが必須なのも同じ理由。
🐍 Python 実装バリエーション — numpy / pandas / scipy / statsmodels
1. numpy / pandas — 既定値の違いに注意
1 2 3 4 5 6 7 | import numpy as np import pandas as pd x = np.array([1, 2, 3, 4, 5]) print('numpy.var ddof=0:', np.var(x)) # 2.0 (母分散) print('numpy.var ddof=1:', np.var(x, ddof=1)) # 2.5 (不偏分散) print('pandas .var() :', pd.Series(x).var()) # 2.5 (既定 ddof=1) print('pandas .var(ddof=0):', pd.Series(x).var(ddof=0)) # 2.0 |
2. scipy.stats.tvar — トリム分散
1 2 3 4 5 6 7 | from scipy import stats x = df['総人口'].values # 両端 10% をトリムした分散 print('トリム分散 :', stats.tvar(x, limits=(np.percentile(x, 10), np.percentile(x, 90)))) print('MAD :', stats.median_abs_deviation(x)) print('MAD→SD換算:', stats.median_abs_deviation(x) * 1.4826) |
3. statsmodels.stats.weightstats — 重み付き分散
1 2 3 4 5 6 7 | from statsmodels.stats.weightstats import DescrStatsW # 各県を人口で重み付けした全国の重み付き分散 ds = DescrStatsW(df['現金給与総額'].values, weights=df['総人口'].values, ddof=1) print('重み付き平均:', ds.mean) print('重み付き分散:', ds.var) print('重み付き SD :', ds.std) |
4. numpy.cov — 分散共分散行列
1 2 3 4 5 | X = df[['総人口','製造品出荷額等','現金給与総額']].astype(float).values S = np.cov(X.T, ddof=1) print('分散共分散行列:'); print(S) # 相関行列は標準化版 print('相関行列 :'); print(np.corrcoef(X.T)) |
5. ブートストラップで分散の 95%CI
1 2 3 4 5 6 | from scipy.stats import bootstrap def var_unbiased(x, axis=0): return np.var(x, axis=axis, ddof=1) res = bootstrap((df['現金給与総額'].values,), var_unbiased, n_resamples=5000, confidence_level=0.95) print(f'分散の 95%CI = {res.confidence_interval}') |
6. オンライン分散(Welford 法、 大規模対応)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | class WelfordVariance: def __init__(self): self.n = 0 self.mean = 0.0 self.M2 = 0.0 def update(self, x): self.n += 1 delta = x - self.mean self.mean += delta / self.n self.M2 += delta * (x - self.mean) @property def variance(self): return self.M2 / (self.n - 1) if self.n > 1 else float('nan') w = WelfordVariance() for v in df['現金給与総額'].values: w.update(v) print(w.variance) |