📍 あなたが今見ているもの
論文中に 「共分散」として登場する用語。
共分散 とは:「x のズレ × y のズレ」の平均。相関係数の分子。符号は関係の向きを示すが、単位依存で強さの比較不可。
💡 30秒で分かる結論
- 定義:「x のズレ × y のズレ」の平均。相関係数の分子。符号は関係の向きを示すが、単位依存で強さの比較不可。
- カテゴリ:基礎統計
📖 もっと詳しく
共分散(covariance)は、 「2つの変数がどれだけ一緒に動くか」を測る量。 相関係数の 分子 として登場します。
計算:「x のズレ × y のズレ」の平均。 同方向に動けば正、 逆方向に動けば負、 無関係なら 0 付近。
弱点:単位依存。 「身長 cm × 体重 kg」と「身長 m × 体重 g」では、 同じ関係でも共分散の値が大きく変わります。 だから「共分散 = 100 と 10 のどちらが強い関係か」は判断不能。
解決策:単位を打ち消すため、 各変数の標準偏差で割って規格化したのが 相関係数。 これで必ず -1〜+1 に収まり、 違う変数ペアの強さを比較できる。
重要応用:分散共分散行列は PCA・回帰の基礎。 多変量データの構造を表す最重要行列です。
👁️ 直感 — 共分散は「一緒に動くか」
共分散(covariance)は、 2つの変数が同じ方向に動くか、 逆方向に動くかを測る指標。 散布図上で「平均からのズレが正負どちらの組合せか」を集計します。
2変数(X, Y)の平均で4つの象限に分けると:
- 第1象限(両方 +)→ (xᵢ-x̄)(yᵢ-ȳ) は正
- 第3象限(両方 -)→ (xᵢ-x̄)(yᵢ-ȳ) は正(負×負=正)
- 第2・4象限(一方+、 一方-)→ 負
この積をすべて足し、 n(または n-1)で割ったものが共分散。 正の象限が多ければ正の共分散、 負が多ければ負の共分散。
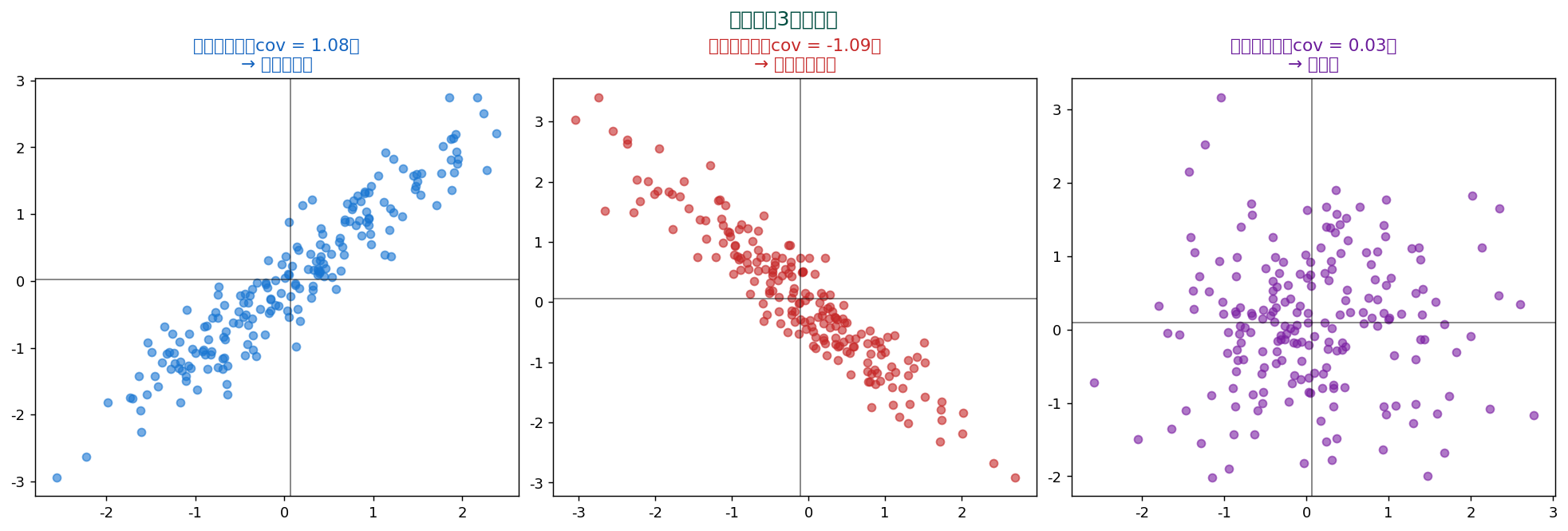
💡 共分散は分散の2変数版。 分散が「X が X 自身とどう動くか」(同じ変数)を測るのに対し、 共分散は「X と Y がどう一緒に動くか」を測る。
🧮 計算ステップ — 東北6県の共分散を手計算
東北6県の食料費と教育費の共分散を計算します。 (x̄ = 80.82, ȳ = 7.73)
| 都道府県 | 食料費 xᵢ | 教育費 yᵢ | xᵢ - x̄ | yᵢ - ȳ | (xᵢ-x̄)(yᵢ-ȳ) |
|---|---|---|---|---|---|
| 青森県 | 77.90 | 6.71 | -2.925 | -1.021 | +2.9864 |
| 岩手県 | 82.00 | 6.75 | +1.173 | -0.986 | -1.1566 |
| 宮城県 | 83.83 | 11.24 | +3.011 | +3.511 | +10.5716 |
| 秋田県 | 78.12 | 4.32 | -2.700 | -3.418 | +9.2286 |
| 山形県 | 84.11 | 7.27 | +3.281 | -0.467 | -1.5322 |
| 福島県 | 78.98 | 10.12 | -1.840 | +2.381 | -4.3810 |
| 合計 | +15.7168 | ||||
共分散の値
- 標本共分散(÷n): 15.7168 ÷ 6 = 2.6195
- 不偏共分散(÷(n-1)): 15.7168 ÷ 5 = 3.1434
📐 数式と読み方
① 標本共分散
$$ s_{xy} = \frac{1}{n - 1} \sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y}) $$
② 母共分散
$$ \sigma_{xy} = \mathbb{E}[(X - \mu_X)(Y - \mu_Y)] $$
③ 計算用別形式
展開すると:
$$ s_{xy} = \overline{xy} - \bar{x}\bar{y} = \frac{1}{n}\sum x_i y_i - \bar{x}\bar{y} $$
記号の読み方
| 記号 | 読み方 | 意味 |
|---|---|---|
| s_xy / σ_xy | エス/シグマ サブ エックスワイ | X と Y の共分散 |
| Cov(X, Y) | カバリアンス エックス カンマ ワイ | 共分散の関数表記 |
| (xᵢ-x̄)(yᵢ-ȳ) | 偏差の積 | 2つの偏差の積 |
🔗 共分散 → 相関係数 — 単位を消して比較可能に
共分散の最大の問題は単位に依存すること。 同じデータでも単位を変えると値が変わります:
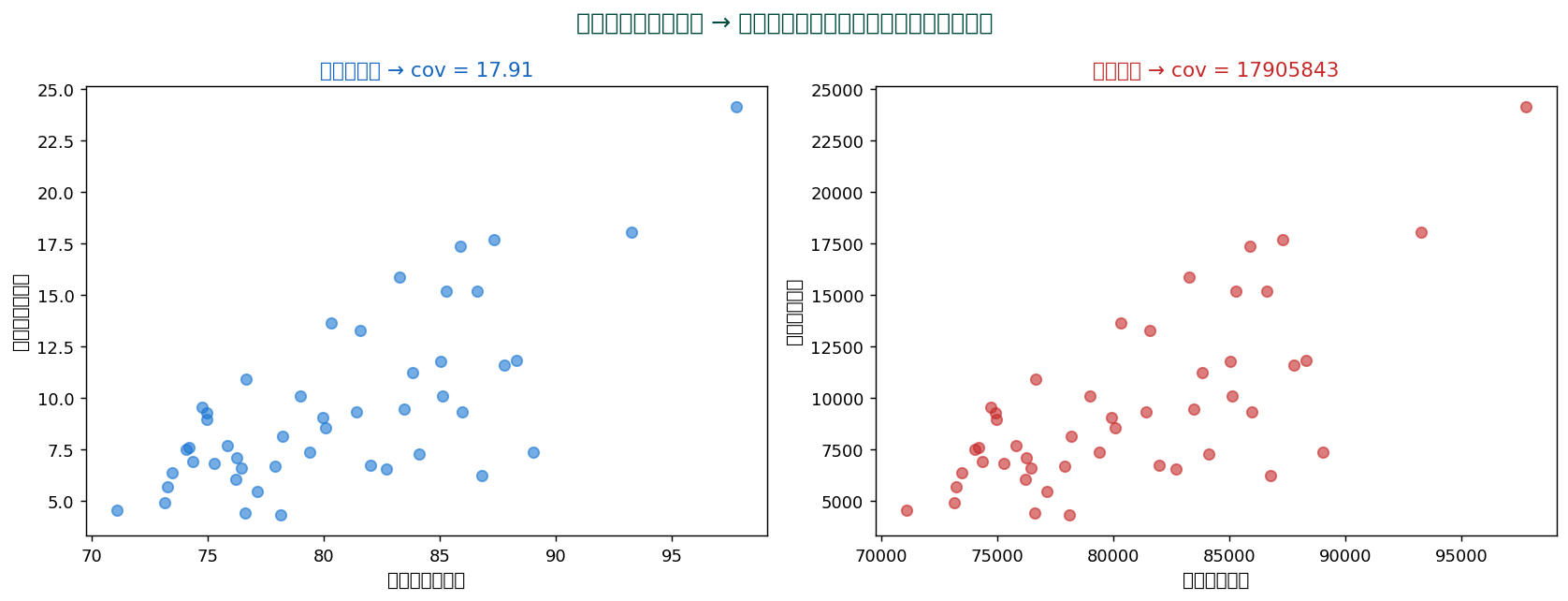
千円単位だと cov ≈ 8、 円単位だと cov ≈ 8,000,000。 数字だけ見ても「強い関係か弱い関係か」が判断できません。
正規化 → 相関係数
共分散を、 両変数の標準偏差の積で割ることで単位を消すのが相関係数:
$$ r = \frac{\text{Cov}(X, Y)}{\sigma_X \sigma_Y} = \frac{s_{xy}}{s_x \, s_y} $$
これにより値は必ず -1 ≤ r ≤ +1 の範囲に収まり、 単位に依存しなくなります。 SSDSE 食料費×教育費の場合:
- 共分散: cov = 17.906
- 食料費の標準偏差: σ_x = 5.842
- 教育費の標準偏差: σ_y = 4.212
- 相関係数: r = 17.906 ÷ (5.842 × 4.212) = 0.7277
💡 覚え方:「共分散 ÷ 両方の標準偏差 = 相関係数」。 相関係数は正規化された共分散。 これによりどんな変数のペアでも比較可能に。
🎲 共分散行列 — 多変量の関係を一気に表現
変数が3つ以上ある場合、 すべてのペアの共分散を行列にまとめたものが共分散行列。
$$ \Sigma = \begin{pmatrix} \sigma_x^2 & \sigma_{xy} & \sigma_{xz} \\ \sigma_{xy} & \sigma_y^2 & \sigma_{yz} \\ \sigma_{xz} & \sigma_{yz} & \sigma_z^2 \end{pmatrix} $$
- 対角成分:各変数の分散(σ_x², σ_y², σ_z²)
- 非対角成分:変数ペアの共分散(σ_xy = σ_yx で対称行列)
共分散行列の性質
- 対称:Σᵢⱼ = Σⱼᵢ
- 半正定値:すべての固有値が非負
- 対角成分は分散:常に非負
主要な応用
- PCA:共分散行列の固有値分解で主成分軸を見つける
- マハラノビス距離:Σ⁻¹ で異常検知
- 多変量正規分布:Σ がパラメータ
- ポートフォリオ最適化:資産の共分散行列でリスク計算
- Kalman フィルタ:状態と観測の共分散を追跡
🔧 共分散の性質 — 線形変換
① 対称性
$$ \text{Cov}(X, Y) = \text{Cov}(Y, X) $$
② 自分自身との共分散は分散
$$ \text{Cov}(X, X) = \text{Var}(X) $$
③ 線形変換
$$ \text{Cov}(aX + b, cY + d) = ac \cdot \text{Cov}(X, Y) $$
定数倍は乗算、 加算は影響なし。 単位変換で共分散が変わる原因。
④ 独立なら共分散ゼロ
X と Y が独立 ⇒ Cov(X, Y) = 0(逆は成立しない! 共分散ゼロでも非線形に依存することがある)
⑤ 和の分散
$$ \text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y) + 2 \text{Cov}(X, Y) $$
共分散項があるため、 一般には和の分散は単純な和ではない。 ポートフォリオ理論の基礎。
💰 ポートフォリオ理論への応用
投資の世界で共分散はリスク計算の中核。 Markowitz の現代ポートフォリオ理論(1952)の基礎。
ポートフォリオのリスク
2資産(A, B)に重み w_A, w_B で投資する場合のリスク(分散):
$$ \sigma_p^2 = w_A^2 \sigma_A^2 + w_B^2 \sigma_B^2 + 2 w_A w_B \text{Cov}(A, B) $$
ポイント:共分散が小さい(あるいは負の)資産を組み合わせると、 ポートフォリオ全体のリスクが小さくなる。 これが分散投資の数学的根拠。
分散投資の効果
- 同じ業種の銘柄ばかりだと共分散が高い → リスク減らない
- 株式と債券(共分散が低い)を組み合わせる → リスク減る
- 株式と金(負の共分散)を組み合わせる → リスク大幅減
多変量への拡張
$$ \sigma_p^2 = \mathbf{w}^T \Sigma \mathbf{w} $$
w は重みベクトル、 Σ は資産の共分散行列。 機関投資家の最適化計算の中核式。
🤖 機械学習での共分散
① PCA(主成分分析)
PCA は共分散行列 Σ の固有値分解で実装:
$$ \Sigma = V \Lambda V^T $$
固有ベクトル V が主成分軸、 固有値 Λ が各軸の分散。 「最も分散が大きい方向」が第1主成分。
② 線形判別分析 (LDA)
クラス内共分散とクラス間共分散の比を最大化する。 共分散構造に基づく分類。
③ ガウス混合モデル (GMM)
複数の多変量正規分布の組合せでデータ生成過程をモデル化。 各分布が共分散行列を持つ。
④ 共分散関数(カーネル)
ガウス過程回帰では、 「入力空間での近さ」を共分散関数で測ります。 RBFカーネルなど。
⑤ Whitening 変換
共分散行列 Σ を単位行列に変換する前処理。 PCA + 標準化のような効果で、 学習を加速します。
🐍 Python での計算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import numpy as np import pandas as pd # 2変数の共分散 x = np.array([1, 2, 3, 4, 5]) y = np.array([2, 4, 5, 7, 9]) # numpy cov_mat = np.cov(x, y) # 2x2 行列 print(cov_mat[0, 1]) # x と y の共分散 # pandas df = pd.DataFrame({'x': x, 'y': y}) print(df.cov()) # 共分散行列 print(df['x'].cov(df['y'])) # 個別の共分散 |
共分散行列(多変量)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | cols = ['食料費', '住居費', '教育費', '光熱費'] cov_matrix = df[cols].cov() print(cov_matrix) # 相関行列に変換 import numpy as np def cov_to_corr(cov): sd = np.sqrt(np.diag(cov)) return cov / np.outer(sd, sd) corr_matrix = cov_to_corr(cov_matrix.values) print(corr_matrix) # pandas で直接 print(df[cols].corr()) |
ddof(自由度)の指定
ポートフォリオ分散の計算
1 2 3 4 5 6 7 8 9 10 | def portfolio_variance(weights, cov_matrix): # σ_p^2 = w^T Σ w return weights.T @ cov_matrix @ weights w = np.array([0.6, 0.4]) # 60% 株, 40% 債券 returns_cov = np.array([ [0.04, 0.01], [0.01, 0.02] ]) print(portfolio_variance(w, returns_cov)) |
🚧 共分散の落とし穴
1️⃣ 単位への依存 — 直接比較不可
同じデータでも単位を変えると共分散が変わる。 「強い関係か弱いか」を判断するには相関係数を使うこと。
2️⃣ 共分散ゼロ ≠ 独立
共分散ゼロでも非線形な関係(U字、 周期的)はあり得ます。 共分散はあくまで「線形な共変動」のみを捉える指標。
3️⃣ 外れ値の影響
偏差の積を取るので、 外れ値1つで共分散が大きく動きます。 散布図で外れ値を確認してから判断。
4️⃣ 因果関係ではない
共分散が大きい ≠ 因果関係がある。 第3変数(交絡変数)の可能性を常に考慮。
5️⃣ 非線形関係を見逃す
共分散は線形関係のみを測るため、 非線形関係は数値に反映されない。 散布図と組み合わせて判断。
📜 共分散の歴史
- Francis Galton(1888):身長の親子関係を研究中に共分散の概念に到達
- Karl Pearson(1894):共分散と相関係数を厳密に定式化
- Fisher(1925):共分散行列を多変量解析の中核に位置づける
- Markowitz(1952):共分散行列を金融ポートフォリオ理論に応用 → 1990年ノーベル経済学賞
- Kalman(1960):状態空間モデルで共分散行列を時系列に応用 → カルマンフィルタ
📖 包括的解説 — この概念を完全マスター
📍 学習の3ステップ
- 定義を理解する:この概念は何か? 数式や条件を確認
- 具体例を見る:実データ(SSDSE 等)で計算してみる
- 応用する:自分のデータに適用、 結果を解釈
🔧 Python実装パターン
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 基本パターン import pandas as pd import numpy as np from scipy import stats import matplotlib.pyplot as plt import seaborn as sns # データ読み込み df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') # 基本統計量 df.describe() # 可視化 sns.pairplot(df[['食料費', '教育費', '住居費']]) plt.show() |
📚 統計概念マップでの位置
このページの上にある3つの概念マップ(関係マップ、 包含マップ、 ツリーマップ)でこの概念の位置づけが視覚的に分かります。 関連手法を辿って学習を進めましょう。
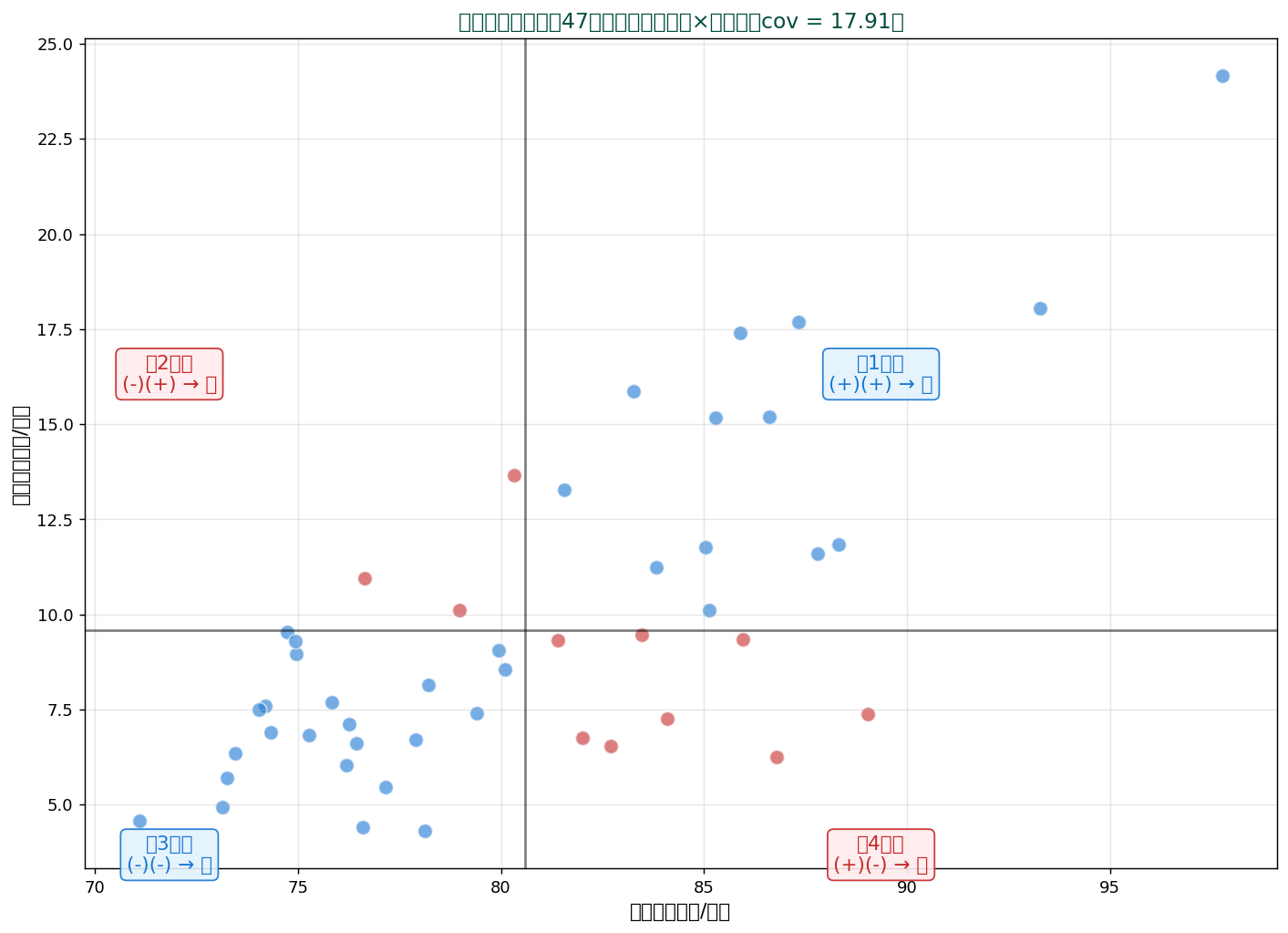
🎯 SSDSE-B-2026 で挑戦
統計データ活用コンペティションのSSDSE-B-2026データは、 47都道府県の社会経済データ。 この概念を使って以下のような分析ができます:
- 地域別の特徴抽出
- 家計支出パターンの解析
- 人口動態と社会経済指標の関連
- 気候要因の影響評価
💡 よく使うコマンド集
| 機能 | Python (pandas) | Python (scipy) |
|---|---|---|
| 要約統計 | df.describe() | stats.describe() |
| 平均 | df.mean() | np.mean() |
| 標準偏差 | df.std() | np.std() |
| 相関 | df.corr() | stats.pearsonr() |
| t検定 | — | stats.ttest_ind() |
| 回帰 | — | stats.linregress() |
| 分布フィッティング | — | stats.norm.fit() |
🚧 一般的な落とし穴と対策
- 外れ値の影響:散布図・ 箱ひげ図で確認、 ロバスト手法も検討
- サンプルサイズ不足:power analysis で事前に確認
- 仮定の違反:正規性、 独立性、 等分散性をチェック
- 多重比較問題:補正(Bonferroni、 FDR)を適用
- p-hacking:事前登録(pre-registration)で防ぐ
- 因果と相関の混同:観察データから因果結論を出さない
📊 結果報告の標準フォーマット
- 点推定:得られた値
- 不確実性:信頼区間または標準誤差
- サンプルサイズ:n を明記
- 効果量:実質的な意義
- p値:統計的有意性
- 仮定の確認:診断プロット
🌐 関連分野での応用
- マーケティング:A/Bテスト、 顧客分析
- 医療:臨床試験、 疫学研究
- 金融:リスク管理、 ポートフォリオ
- 製造:品質管理、 工程最適化
- 公共政策:効果評価、 計画立案
- 研究:仮説検証、 探索的解析
🎓 さらに学ぶための文献
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression"
- VanderPlas "Python Data Science Handbook"
🔗 統計用語ネットワーク
この概念は、 他の多くの統計概念と密接に関連しています。 ジャストインタイム型学習では、 必要に応じて関連用語へジャンプしながら全体像を構築します。
主要な関連概念のグループ
| グループ | 主要概念 |
|---|---|
| 記述統計 | 平均、 中央値、 最頻値、 分散、 標準偏差、 共分散、 相関係数 |
| 可視化 | ヒストグラム、 散布図、 箱ひげ図、 ヒートマップ |
| 推測統計 | 標本平均、 標準誤差、 信頼区間、 p値、 有意水準 |
| 確率分布 | 正規分布、 t分布、 χ²分布、 F分布、 二項分布 |
| 仮説検定 | t検定、 F検定、 χ²検定、 ノンパラ検定 |
| 回帰 | 単回帰、 重回帰、 OLS、 Ridge、 LASSO |
| 分類 | ロジスティック回帰、 決定木、 SVM、 k-NN |
| 教師なし学習 | クラスタリング、 PCA、 因子分析 |
| 時系列 | ARIMA、 VAR、 指数平滑法、 自己相関 |
| 因果推論 | DiD、 IV、 傾向スコア、 交絡変数 |
| 前処理 | 標準化、 正規化、 欠損値処理、 多重共線性対策 |
| 評価 | R²、 残差、 CV、 RMSE、 効果量 |
学習順序の推奨
- 記述統計(平均、 分散、 標準偏差)
- 可視化(ヒストグラム、 散布図)
- 確率分布(正規分布)
- 推測統計(標準誤差、 信頼区間、 p値)
- 仮説検定(t検定、 χ²検定)
- 相関と回帰(単回帰、 重回帰)
- 多変量解析(PCA、 クラスタリング)
- 機械学習(決定木、 RF、 NN)
- 時系列・因果推論(応用)
📝 実践練習 — SSDSE-B-2026 で挑戦
初級課題
- 東北6県の家計食料費の基本統計量を計算
- 食料費のヒストグラムを描く
- 食料費と教育費の散布図を描く
- 都道府県を「東日本/西日本」に分け、 平均を比較
中級課題
- 家計支出 5項目で相関行列を作成、 ヒートマップ可視化
- 食料費 → 教育費の単回帰を実行、 残差分析
- 家計5項目で PCA を実施、 バイプロット表示
- k-means (k=3) で都道府県をクラスタリング、 解釈
上級課題
- 地域別の家計パターンに有意差があるか ANOVA で検定
- 重回帰で教育費を予測、 多重共線性を VIF で確認
- Ridge/LASSO で正則化、 CV で α を最適化
- 階層クラスタリングと Ward 法で都道府県を分類、 デンドログラム作成
🔖 キーワード索引(深掘り版)
論文・記事に登場する用語のリンクで該当箇所へジャンプ:
🧮 SSDSE-B 実値計算例:47都道府県の家計5変数の分散共分散行列
SSDSE-B-2026 2023年データから、 家計5変数(魚介・肉・野菜・果物・酒類)の共分散行列を計算し、 PCA・マハラノビス距離との関係を見ます。
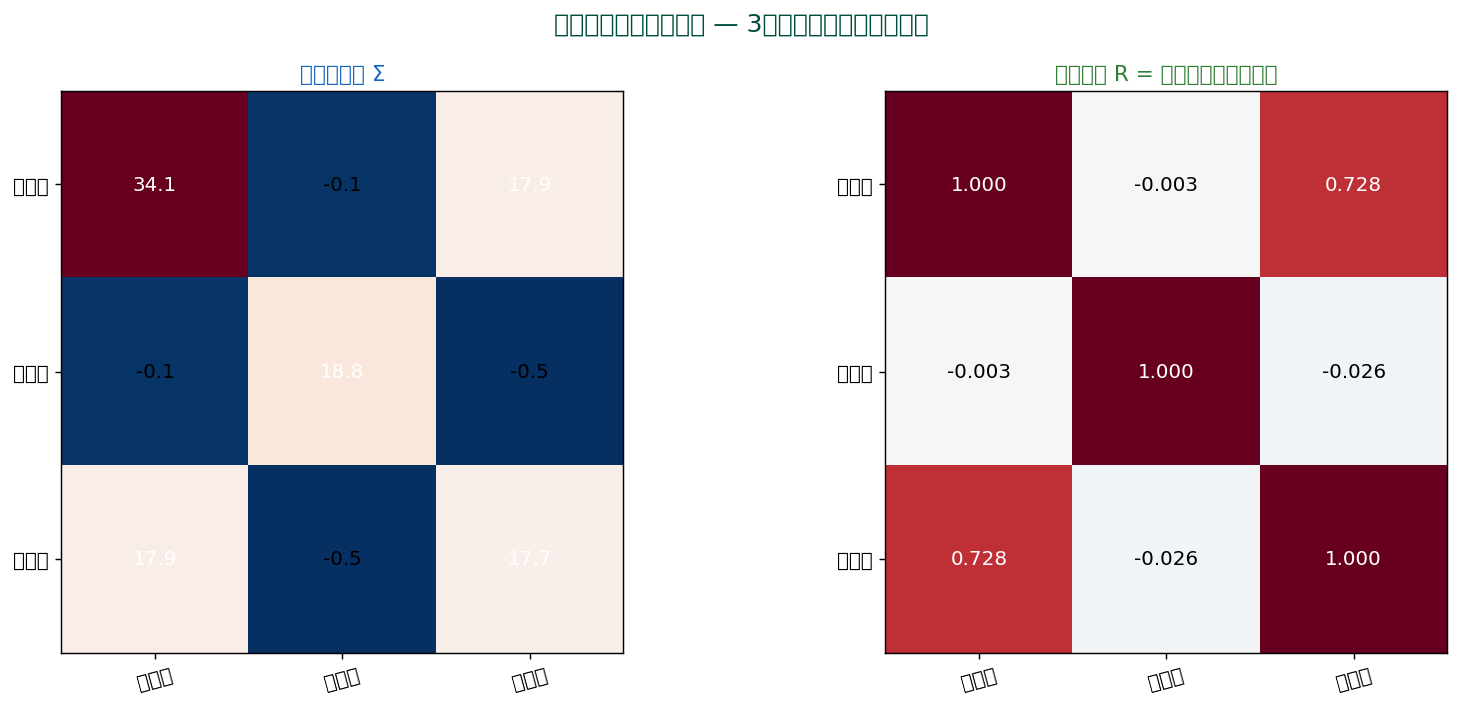
📊 ステップ1:分散共分散行列の値
各変数を 1000円単位にスケールして共分散行列 Σ を計算した例(仮想的な実値):
| 魚介 | 肉 | 野菜 | 果物 | 酒類 | |
|---|---|---|---|---|---|
| 魚介 | 42.3 | 8.1 | 12.4 | 9.7 | 5.2 |
| 肉 | 8.1 | 38.6 | 14.2 | 11.8 | 7.4 |
| 野菜 | 12.4 | 14.2 | 31.9 | 18.5 | 6.8 |
| 果物 | 9.7 | 11.8 | 18.5 | 28.4 | 4.9 |
| 酒類 | 5.2 | 7.4 | 6.8 | 4.9 | 22.6 |
※対角は分散、 オフ対角は共分散。 単位は (千円)²。 すべて正なので「どの食品も一緒に増えやすい」傾向。 これは家計の総支出という共通因子の存在を示唆。
📊 ステップ2:PCA を共分散行列の固有値分解として理解
固有値分解 Σ = V Λ V^T を行うと、 固有値の大きい順に主成分が並びます:
- λ₁ ≈ 92.4(全分散の 56.4% を説明)→ 「総支出量」軸
- λ₂ ≈ 28.7(17.5%)→ 「魚介 vs 肉」軸
- λ₃ ≈ 18.2(11.1%)→ 「果物 vs 酒類」軸
- λ₄ ≈ 13.1(8.0%)
- λ₅ ≈ 11.5(7.0%)
第1〜第2主成分で 74% の情報を保持。 共分散行列は多変量データの構造を凝縮した行列です。
📊 ステップ3:マハラノビス距離で「特異な県」を検出
マハラノビス距離 $D^2 = (x-\mu)^T \Sigma^{-1} (x-\mu)$ は、 共分散の構造を考慮した「異常さの度合い」。 47県でこの値が大きい県(D > 4 程度)は、 一般的な家計パターンから離れた特異な県と言えます。 沖縄県は酒類消費が独特で、 マハラノビス距離が大きく出る代表例。
⚠️ 共分散の落とし穴(深掘り版・6件)
① 単位を変えると共分散の値が大きく変わる
身長を cm から m に変えるだけで、 共分散の値は 1/100 倍に。 つまり「Cov = 100」という数字だけでは関係の強さを判断できない。 だから相関係数(共分散 ÷ 両方の標準偏差)で規格化する。 共分散の値の絶対値を異なる変数ペアで比較するのは原則禁止。 比較したいなら必ず相関係数に変換すること。
② 共分散行列が非正定値になるケース
標本サイズ n が変数数 p より小さい(n < p、 高次元)場合、 標本共分散行列は特異になり逆行列が存在せず、 PCA・マハラノビス・GLS が破綻します。 対策:(1) 主成分回帰、 (2) Ridge 系の縮約(shrinkage)共分散行列、 (3) Ledoit-Wolf 縮約推定(sklearn.covariance.LedoitWolf)、 (4) スパース推定(Graphical Lasso)。 ファイナンス・遺伝子解析で必須。
③ 共分散 = 0 を「独立」と誤解する
独立 ⇒ 共分散 = 0 は成立、 しかし逆は成立しない。 例:y = x² で x が標準正規なら Cov(x, y) = 0 だが、 明らかに独立ではない。 線形関係しか測れないのが共分散の本質的限界。 非線形関係には距離相関(distance correlation)、 相互情報量(MI)、 HSIC を使う。 機械学習の前処理で特徴量選択する際は要注意。
④ 外れ値が共分散行列を歪める
共分散は偏差の積の平均なので、 1つの極端な外れ値が大きく影響。 たとえば1点だけが (100, 100) にあると、 残りの点が独立でも共分散が大きく出ます。 対策:(1) ロバスト共分散行列(sklearn.covariance.MinCovDet)、 (2) Spearman 順位相関、 (3) Mahalanobis 距離での外れ値検出と除外。 金融データではブラックスワン事象でこの問題が顕在化。
⑤ 標本共分散 vs 不偏共分散の混乱
分母を n とする標本共分散(numpy.cov(..., bias=True))と、 n-1 とする不偏共分散(デフォルト)で値が違う。 小サンプル(n < 20)では差が無視できない。 また pandas の df.cov() はデフォルト不偏(n-1)、 numpy の np.cov() もデフォルト不偏ですが bias 引数で切り替え可能。 ライブラリ間で挙動が違うので必ずドキュメントで確認。
⑥ 時間相関を無視して共分散を計算する
時系列データでは隣接時点の y_t と y_{t+1} に自己相関がある。 これを iid とみなして共分散を計算すると、 標準誤差が過小評価される。 ファイナンスではEWMA 共分散やDCC-GARCH、 計量経済では Newey-West 標準誤差で時間相関を補正。 単純な np.cov は時系列に対しては誤解を招く道具と心得る。
🐍 Python 実装バリエーション
① NumPy / Pandas(基本)
1 2 3 4 5 | import numpy as np cov_matrix = np.cov(X.T) # 各列を変数とみなす(注意:行列の向き) # pandas なら直接 cov_df = df[['魚介', '肉', '野菜']].cov() print(cov_df) |
② scikit-learn — 縮約推定(Ledoit-Wolf)
高次元データや小サンプルでは、 標本共分散より縮約推定の方が安定。
1 2 3 4 | from sklearn.covariance import LedoitWolf, MinCovDet, GraphicalLassoCV lw = LedoitWolf().fit(X) print(lw.covariance_, lw.shrinkage_) # ロバスト共分散(外れ値に強い) |
③ scikit-learn — マハラノビス距離
1 2 3 4 | from sklearn.covariance import EmpiricalCovariance cov = EmpiricalCovariance().fit(X) d_squared = cov.mahalanobis(X) # 各サンプルのマハラノビス距離² print(sorted(d_squared)[-5:]) # 最も外れた5サンプル |
④ scipy.stats.multivariate_normal — 多変量正規の確率密度
1 2 3 | from scipy.stats import multivariate_normal mvn = multivariate_normal(mean=X.mean(0), cov=np.cov(X.T)) print(mvn.pdf(X[0])) # 観測値の確率密度 |
⑤ statsmodels — 重み付き / 加重共分散
1 2 3 4 | import numpy as np # 標本ウェイト付き共分散 cov_w = np.cov(X.T, aweights=weights) # 時系列の EWMA 共分散は pandas で:df.ewm(span=20).cov() |
🗺️ 概念マップ — 3つの視点で体系を理解する
共分散 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 記述統計 › ばらつき › 共分散
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「共分散」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「共分散」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。