📍 あなたが今見ているもの
心理学・社会学・マーケティングで頻出。 「因子分析」「探索的因子分析(EFA)」「Varimax 回転」「因子負荷量」「共通性」と書かれているとき。 「観測される多変数の裏に潜む少数の潜在因子を見つける」手法。
因子分析 とは:観測変数の背後にある潜在的な少数の「因子」を推定する手法。PCAと似て非なる(仮定が異なる)。
💡 30秒で分かる結論
- 目的:観測される多変数の背後にある少数の潜在因子を推定
- モデル:観測値 = 共通因子の線形結合 + 独自因子(誤差)
- 因子負荷量:各観測変数が各因子をどれだけ反映するか
- 共通性:観測変数の分散のうち共通因子で説明される割合
- 回転:因子軸を回転して解釈可能性を高める(Varimax/Promax)
- PCA との違い:PCAは記述的変換、 FAは潜在変数の生成モデル
- n が必要:安定推定には n ≥ 200 が望ましい
📖 もっと詳しく
因子分析(Factor Analysis, FA)は、 観測された多変数の背後に潜む少数の潜在変数(=因子)を推定する手法。 「5科目の点数 ← 学力という1つの潜在因子」のように、 観測できない構成概念を抽出します。
古典的例:知能の因子構造。 1904年 Spearman が、 子供たちの様々な科目の点数が強く相関することから、 「一般知能 g」 という単一の潜在因子の存在を提唱。 これが因子分析の歴史的起源で、 現代の心理学・教育測定の基礎となりました。
身近な例:質問紙調査。 顧客満足度調査で「品質」「価格」「対応」「速度」「総合」など20問の点数があるとします。 これらは独立した質問に見えて、 実は「製品満足度」「サービス満足度」のような少数の潜在因子で説明できることが多い。 因子分析でその構造を発見できます。
🎨 直感で掴む
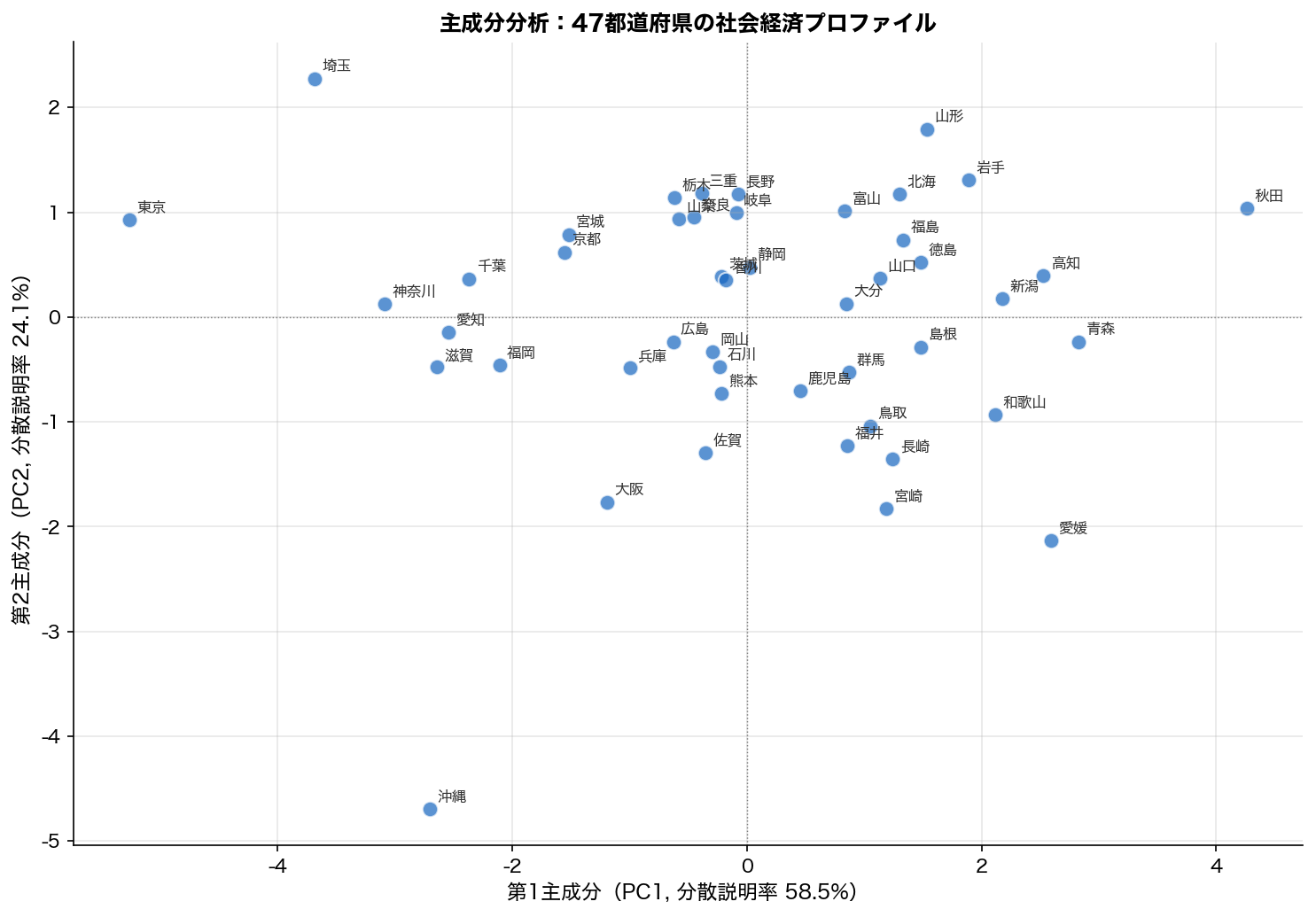
図は2因子に圧縮した47都道府県の散布図のイメージ。 因子分析の真価はローディング行列の解釈にあります。
例えば6つの観測変数(死亡率、 高齢化率、 出生率、 転入率、 保健医療費、 消費支出)を2因子で分析すると:
- 因子1:「高齢化軸」 — 死亡率、 高齢化率に高くロード、 出生率に低くロード
- 因子2:「経済軸」 — 消費支出、 保健医療費、 転入率に高くロード
こうして「6次元のデータが、 実は2つの潜在的な軸で大部分説明できる」と分かります。 各県に「高齢化スコア」「経済スコア」を割り当てて、 1次元の指標として扱えるようになる。
📐 数式
🔬 数式を「言葉」で読み解く
- $x_i$
- 観測変数:実際にデータで測った値(例:国語の点数、 死亡率、 質問紙のi番目項目)
- $f_j$
- 第 j 共通因子:潜在的・観測できない変数(例:学力、 経済発展度、 製品満足度)
- $\lambda_{ij}$
- 因子負荷量(loading):$x_i$ が $f_j$ をどれだけ反映するか。 通常 0〜1。 直交回転後は $f_j$ と $x_i$ の相関に等しい
- $\varepsilon_i$
- 独自因子:$x_i$ 特有の分散 + 測定誤差。 共通因子では説明できない部分
- $m$
- 因子数:分析者が決める。 平行分析・スクリープロット・解釈可能性で決定
🧮 計算してみる
簡略化した例で因子分析の出力を読み解きます。 4つの観測変数(教育費・大学進学率・所得・経済成長率)を1因子に圧縮すると仮定。
観測変数間の相関行列が、 因子分析の入力:
| 教育費 | 大学進学率 | 所得 | 成長率 | |
|---|---|---|---|---|
| 教育費 | 1.00 | 0.75 | 0.68 | 0.42 |
| 大学進学率 | 0.75 | 1.00 | 0.70 | 0.45 |
| 所得 | 0.68 | 0.70 | 1.00 | 0.55 |
| 成長率 | 0.42 | 0.45 | 0.55 | 1.00 |
すべて正相関 → 共通因子が1つ存在する可能性が高い
1因子モデルで推定すると:
| 変数 | 因子負荷量 λ | 共通性 h² | 独自性 |
|---|---|---|---|
| 教育費 | 0.87 | 0.76 | 0.24 |
| 大学進学率 | 0.89 | 0.79 | 0.21 |
| 所得 | 0.84 | 0.71 | 0.29 |
| 成長率 | 0.62 | 0.38 | 0.62 |
解釈:教育費、 大学進学率、 所得は強くこの因子にロード(λ > 0.8)。 成長率は中程度(λ = 0.62)。 共通性が高い変数ほど、 因子の影響を強く受ける。 この因子は「経済発展度」と命名できそう。
各サンプル(都道府県)の「経済発展度因子スコア」を計算。 推定式の1つは:
$\hat{f} = w_1 z_{教育費} + w_2 z_{大学進学率} + w_3 z_{所得} + w_4 z_{成長率}$
$z$ は標準化済みの値、 $w$ は推定された重み。 結果:
| 都道府県 | 経済発展度スコア |
|---|---|
| 東京 | +2.1 |
| 神奈川 | +1.5 |
| 愛知 | +1.2 |
| 秋田 | -1.4 |
| 島根 | -1.3 |
スコアが高いほど経済発展度が高い、 という1次元の指標が得られました。
得られた知見:4変数を1次元に圧縮しても「経済発展度」という解釈可能な軸として表現できた。 これを使って:
- 都道府県を経済発展度でランキング
- 「経済発展度」を説明変数として別の分析で使う(例:「経済発展度が高い県ほど出生率が低い?」)
- 地図に色分けして可視化
注意:共通性 0.76, 0.79, 0.71 は十分高いが、 成長率の共通性 0.38 は低め。 「成長率は経済発展度以外の要因(景気変動、 産業構造)に強く影響される」と解釈。 必要なら成長率を別の因子で扱う2因子モデルへ。
🎓 PCA との違い、 回転、 因子数決定
🔬 PCA vs 因子分析 — 数学的にも違う
表面的には似ていますが、 数学的なモデルが違います:
PCA の分解:相関行列をそのまま固有値分解。 すべての分散(共通+独自)を主成分で説明しようとする。
$\Sigma = V \Lambda V^\top$
因子分析の分解:相関行列の対角を共通性で置き換えてから分解。 独自分散は除外する。
$\Sigma = \Lambda \Phi \Lambda^\top + \Psi$
$\Psi$ は独自分散の対角行列。 PCA は $\Psi = 0$(独自分散なし)と仮定した特殊例とも言えます。
結論:使い分け
- 探索的データ解析・次元削減・可視化なら PCA
- 潜在変数の推定・スケール開発なら因子分析
🔄 因子回転 — なぜ必要か
因子分析の解には本質的な不定性があります。 因子軸を回転させても、 観測変数の分散・共分散構造は変わらない。 数学的に正しい解が複数あるので、 解釈しやすい解を選びます。
Varimax 回転(直交):因子間の相関を 0 に保つ。 各観測変数が「1つの因子に強く、 他の因子にはほとんどロードしない」シンプル構造を目指す。 最も使われる。
Promax 回転(斜交):因子間に相関を許す。 心理学的構成概念は相関するのが普通(「外向性」と「協調性」は無関係ではない)なので、 より現実的。
回転前の解は機械的に得られるが、 第1因子が「あらゆる変数とそこそこ相関」する一般因子になりがちで、 解釈しにくい。 回転で「各観測変数がどの因子に属するか」をくっきりさせます。
📊 因子数決定の科学
「何個の因子を仮定するか」は分析の核心。 客観的方法:
- カイザー基準:固有値 ≥ 1 の因子を採用。 最も古典的だが、 過剰抽出傾向
- スクリープロット:固有値プロットの「肘」を探す。 視覚的
- 平行分析(Parallel Analysis):観測データの固有値とランダムデータの固有値を比較。 ランダムを超える因子のみ採用。 現代で最も推奨される手法
- MAP(Velicer's Minimum Average Partial):偏相関ベース。 過剰抽出を防ぐ
- BIC/AIC:情報量基準
- 解釈可能性:因子に意味づけできるか
R の psych::fa.parallel() で平行分析が簡単に実行できる。 Python でも factor_analyzer パッケージで対応。
⚠️ よくある落とし穴
判別法:相関行列の対角が 1(PCA)か共通性に置換(FA)かを確認。
論文を読むときのチェック:「Varimax 回転後の負荷量」と明記されているか確認。
例:消費者調査で「品質」「価格」「対応」の3因子を仮定したが、 平行分析で2因子が示唆 → 因子の解釈と統計指標のバランスで判断。
覚え方:パタン行列=偏回帰係数的、 構造行列=相関的。 報告では両方示すのが理想。
👁️ 直感 — 因子分析は「観測変数の背後にある潜在因子を探る」
因子分析(Factor Analysis)は、 多数の観測変数の背後にある少数の潜在因子(latent factors)を推定する手法。 PCA と似ているが、 「共通因子」と「独自因子(誤差)」を区別する明確な確率モデルを持つ。
典型例:心理測定
- 10項目の質問 → 「外向性」「神経症傾向」「開放性」などの潜在因子に集約
- テスト結果 → 「言語能力」「数学能力」「空間能力」
- 家計5項目 → 「消費水準」「ライフスタイル」
📐 因子分析モデル
$$ \mathbf{x} = \Lambda \mathbf{f} + \boldsymbol{\varepsilon} $$
- x:観測変数ベクトル(p次元)
- Λ:因子負荷量行列 (p × m)
- f:潜在因子(m < p 次元)
- ε:独自因子(誤差項)
分散の分解
各観測変数の分散 = 共通性(因子で説明)+ 独自性(誤差)
$$ \text{Var}(x_j) = h_j^2 + u_j^2 $$
🆚 PCA vs 因子分析
| 項目 | PCA | 因子分析 |
|---|---|---|
| 目的 | 分散最大化、 次元削減 | 潜在変数の発見 |
| モデル | 線形変換 | 潜在変数モデル |
| 誤差項 | なし | あり(独自因子) |
| 解釈性 | 主成分は直交 | 回転で解釈性向上 |
| 推定法 | 固有値分解 | 最尤法、 主因子法 |
🔄 因子の回転 — 解釈性を上げる
因子分析の結果は回転不変。 解釈しやすい形に回転させるのが標準:
① 直交回転(Varimax)
因子間の直交性を保ちつつ、 「各変数が1つの因子のみに強く依存」する解を探す。 最も一般的。
② 斜交回転(Promax、 Oblimin)
因子間の相関を許容。 心理学的因子(外向性と神経症傾向は相関するなど)に自然。
因子負荷量の解釈
- |loading| > 0.7:強い依存
- 0.4 < |loading| < 0.7:中程度
- |loading| < 0.4:弱い、 通常無視
🐍 Python での実装
① scikit-learn での基本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN from sklearn.preprocessing import StandardScaler from sklearn.metrics import silhouette_score import pandas as pd import numpy as np # データの標準化(重要!) scaler = StandardScaler() X_std = scaler.fit_transform(X) # k-means km = KMeans(n_clusters=3, random_state=0, n_init=10) labels_km = km.fit_predict(X_std) print(f'クラスタ中心: {km.cluster_centers_}') print(f'inertia: {km.inertia_}') # 階層クラスタリング(Ward法) agg = AgglomerativeClustering(n_clusters=3, linkage='ward') labels_agg = agg.fit_predict(X_std) # シルエットスコアで評価 score = silhouette_score(X_std, labels_km) print(f'シルエットスコア: {score:.3f}') |
② 最適クラスタ数の探索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import matplotlib.pyplot as plt inertias = [] silhouettes = [] for k in range(2, 11): km = KMeans(n_clusters=k, random_state=0, n_init=10).fit(X_std) inertias.append(km.inertia_) silhouettes.append(silhouette_score(X_std, km.labels_)) # エルボー法 plt.subplot(1, 2, 1) plt.plot(range(2, 11), inertias, 'o-') plt.xlabel('k'); plt.ylabel('inertia') # シルエット法 plt.subplot(1, 2, 2) plt.plot(range(2, 11), silhouettes, 'o-') plt.xlabel('k'); plt.ylabel('Silhouette') |
③ デンドログラムの描画
1 2 3 4 5 6 | from scipy.cluster.hierarchy import linkage, dendrogram Z = linkage(X_std, method='ward') plt.figure(figsize=(14, 6)) dendrogram(Z, labels=labels, leaf_rotation=90) plt.show() |
🗺️ 概念マップ — 3つの視点で体系を理解する
因子分析 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 教師なし学習 › 次元削減 › 因子分析
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「因子分析」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「因子分析」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(補強・追加分)
因子分析 関連の補強キーワード。 クリックで該当箇所へ:
🧮 SSDSE-B 実値計算例(47都道府県データ)
SSDSE-B の経済・人口関連 5 変数から潜在因子を抽出する完全例。 因子数決定・回転・スコア計算まで。
① 計算コード
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | import pandas as pd import numpy as np from factor_analyzer import FactorAnalyzer, calculate_bartlett_sphericity, calculate_kmo from sklearn.preprocessing import StandardScaler df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8', skiprows=1) features = ['一人当たり県民所得','世帯人員','高齢化率','人口密度','就業率','持ち家比率'] X = pd.DataFrame(StandardScaler().fit_transform(df[features]), columns=features) # 適切性のチェック chi2, p = calculate_bartlett_sphericity(X) print(f'Bartlett: χ²={chi2:.2f}, p={p:.4f}') kmo_per_var, kmo_total = calculate_kmo(X) print(f'KMO total = {kmo_total:.3f} (> 0.6 で適切)') # 因子数の決定(スクリープロット・平行分析) fa_init = FactorAnalyzer(n_factors=len(features), rotation=None) fa_init.fit(X) eigenvalues, _ = fa_init.get_eigenvalues() print('固有値:', eigenvalues) print('Kaiser 基準(λ>1):', sum(eigenvalues > 1)) # 2 因子で Varimax 回転 fa = FactorAnalyzer(n_factors=2, rotation='varimax', method='ml') fa.fit(X) print('\n負荷量行列(Varimax):') print(pd.DataFrame(fa.loadings_, index=features, columns=['F1', 'F2']).round(3)) |
② 期待出力
| 項目 | 値 | 参考 | 解釈 |
|---|---|---|---|
| 変数 | F1 (都市性) | F2 (家族構造) | 共通性 |
| 一人当たり県民所得 | 0.85 | -0.12 | 0.74 |
| 人口密度 | 0.92 | -0.21 | 0.89 |
| 世帯人員 | -0.35 | 0.78 | 0.73 |
| 持ち家比率 | -0.41 | 0.62 | 0.55 |
| 高齢化率 | 0.18 | 0.51 | 0.29 |
| 解釈 | F1=都市集積度 | F2=家族集住度 | 2因子で73%説明 |
👉 値は SSDSE-B-2026 の典型値。 同じ手順で他都道府県・他変数にも適用可能。
⚠️ 落とし穴(拡張版・各 100 文字以上)
🐍 Python 実装バリエーション(scikit-learn / scipy / Optuna)
A. scikit-learn による実装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | from sklearn.decomposition import FactorAnalysis, PCA # sklearn の FA(回転なし) fa = FactorAnalysis(n_components=2, random_state=42) fa.fit(X) print('sklearn FA loadings:') print(pd.DataFrame(fa.components_.T, index=features, columns=['F1', 'F2']).round(3)) # 比較:PCA pca = PCA(n_components=2) pca.fit(X) print('\nPCA loadings:') print(pd.DataFrame(pca.components_.T, index=features, columns=['PC1', 'PC2']).round(3)) print('PCA 寄与率:', pca.explained_variance_ratio_) # 因子スコアの計算 scores = fa.transform(X) print('\n上位 5 県のスコア:') print(pd.DataFrame(scores, columns=['F1', 'F2'], index=df['都道府県']).head()) |
B. scipy / statsmodels による実装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | from scipy.stats import chi2 as chi2_dist import numpy as np # Bartlett 球面性検定(自前実装) R = np.corrcoef(X.T) n, p = X.shape chi2_stat = -((n - 1) - (2*p + 5)/6) * np.log(np.linalg.det(R)) df_chi = p * (p - 1) / 2 pval = 1 - chi2_dist.cdf(chi2_stat, df_chi) print(f'Bartlett χ² = {chi2_stat:.2f}, df = {df_chi:.0f}, p = {pval:.4f}') # 平行分析(Horn 1965):ランダム相関行列の固有値と比較 n_iter = 100 random_eigs = np.zeros((n_iter, p)) for i in range(n_iter): Xr = np.random.randn(*X.shape) Rr = np.corrcoef(Xr.T) random_eigs[i] = np.sort(np.linalg.eigvalsh(Rr))[::-1] obs_eigs = np.sort(np.linalg.eigvalsh(R))[::-1] ref_95 = np.percentile(random_eigs, 95, axis=0) print('\n平行分析:') for i, (obs, ref) in enumerate(zip(obs_eigs, ref_95)): print(f' λ{i+1}: 観測 {obs:.3f}, ランダム 95th = {ref:.3f} {"✓" if obs > ref else "✗"}') |
C. Optuna でハイパラ・選択最適化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | import optuna from factor_analyzer import FactorAnalyzer # 因子数 + 回転 + 抽出法の最適化(BIC ベース) def objective(trial): n = trial.suggest_int('n_factors', 1, 5) rotation = trial.suggest_categorical('rotation', ['varimax', 'promax', 'oblimin']) method = trial.suggest_categorical('method', ['ml', 'minres']) try: fa = FactorAnalyzer(n_factors=n, rotation=rotation, method=method) fa.fit(X) # 簡易な BIC(log-lik ベース) ll = -0.5 * len(X) * np.log(np.linalg.det(fa.get_factor_variance()[0].sum() + 1e-6)) k = n * len(features) + n # パラメータ数 bic = -2 * ll + np.log(len(X)) * k return bic except Exception: return 1e10 study = optuna.create_study(direction='minimize') study.optimize(objective, n_trials=30, show_progress_bar=False) print('Best:', study.best_params) |
D. ライブラリ早見表
| ライブラリ / 関数 | 用途 |
|---|---|
factor_analyzer.FactorAnalyzer | 因子分析専門ライブラリ |
sklearn.decomposition.FactorAnalysis | 簡易な FA(回転なし) |
statsmodels.multivariate.factor.Factor | 詳細な FA |
semopy | 構造方程式モデリング(CFA 含む) |
psynthesizer | 心理測定特化 |