📍 あなたが今見ているもの
論文で「クラスタリング」「クラスタ分析」「教師なし学習で分類」と書かれているとき。 「47都道府県を似ているグループに自動分類」「顧客を購買行動で分類」など、 ラベルなしデータから自然なグループ構造を発見する手法の総称。
クラスタリング とは:教師ラベルなしで、似たサンプル同士をグループ(クラスタ)に分ける手法の総称。
💡 30秒で分かる結論
- 定義:教師ラベルなしで、 似たサンプル同士をグループに自動分類
- 4大手法:分割型(k-means)、 階層型(Ward法)、 密度ベース(DBSCAN)、 モデルベース(GMM)
- 距離尺度:ユークリッド・マンハッタン・コサイン・マハラノビス等。 用途で使い分け
- 標準化必須:単位の違う変数をそのまま入れると桁の大きい変数に支配される
- k の決定:エルボー法、 シルエット係数、 ギャップ統計量で
- 致命的注意:データに「クラスタ構造がない」場合、 強制的に分けても無意味
- Python:
sklearn.clusterに各種手法が実装されている
📖 もっと詳しく
クラスタリング(clustering)は、 「似たサンプル同士を自動でグループ化する」教師なし学習の代表的タスク。 「正解ラベル」を一切与えず、 データの内部構造をアルゴリズムが自力で発見します。
教師あり学習との違い:
- 教師あり学習:「これは合格、 これは不合格」のような正解ラベルから学習(例:ロジスティック回帰、 ランダムフォレスト)
- 教師なし学習:ラベルなしでデータの構造を発見(クラスタリング、 PCA)
クラスタリングは「データの中に自然なグループはあるか?あるならどんな?」という探索的な問いに使います。 正解がないので、 結果の「正しさ」を評価するのが難しい一方、 仮説生成・データの初期理解で強力な道具になります。
🎯 クラスタリングが活躍する場面
- 顧客セグメンテーション:似た購買行動の顧客をグループ化 → ターゲティング広告
- 地域類型化:47都道府県を社会経済指標で分類 → 政策立案
- 遺伝子発現解析:似た発現パターンの遺伝子をグループ化 → 機能予測
- 異常検知:小さいクラスタや外れ値を「異常」とみなす(不正検出など)
- 画像圧縮:似た色をクラスタリング → ベクトル量子化
- 文書分類:トピックの似た文書をグループ化 → 情報検索
📋 クラスタリング手法の分類
クラスタリング手法は次の4大カテゴリに分かれます:
| 分類 | 仕組み | 代表例 | 向くデータ |
|---|---|---|---|
| 分割型(partitional) | k個の中心への距離で分割 | k-means, k-medoids | 球形クラスタ、 大規模 |
| 階層型(hierarchical) | 点を段階的に結合 or 分割 | Ward法, 単連結, 完全連結 | 中規模、 階層構造あり |
| 密度ベース | 密な領域をクラスタとみなす | DBSCAN, OPTICS, Mean Shift | 非球形、 ノイズあり |
| モデルベース | 確率分布の混合と仮定 | GMM, EM, ベイズクラスタ | 確率的所属、 重なり許容 |
🔬 距離の選択が決定的に重要
クラスタリングの中核は「2つのサンプルがどれだけ似ているか」の数値化。 これを「距離」(または類似度)と呼びます:
- ユークリッド距離(最も一般的):$\sqrt{\sum(x_i - y_i)^2}$。 直線距離
- マンハッタン距離:$\sum|x_i - y_i|$。 軸方向の距離の和
- コサイン類似度:$\frac{x \cdot y}{\|x\|\|y\|}$。 方向の類似度(文書分析)
- マハラノビス距離:相関構造を考慮(共分散行列で標準化)
- ハミング距離:カテゴリカルデータ用(一致しない要素数)
- Jaccard 類似度:集合データ用
選択の指針:
- 連続値で単位が同じ → ユークリッド
- 文書・カテゴリ → コサイン or Jaccard
- 相関構造を考慮したい → マハラノビス
- 外れ値に強くしたい → マンハッタン
⚠️ 標準化が必須の理由
単位の違う変数を混ぜると、 桁の大きい変数だけで距離が決まり、 他の変数の情報が消えます。 例えば「人口(万人)」と「失業率(%)」をユークリッド距離で測れば、 人口の差が圧倒的に大きいため、 結果は実質「人口」だけでクラスタリングしたものに。
対策:必ず標準化(z-score化)してから距離計算。 sklearn.preprocessing.StandardScaler で平均0・分散1に揃える。 これで全変数が「平等」に効く。
🎯 クラスタ数 k の決定
k-means のような分割型では「何個のクラスタに分けるか」を事前に決める必要があります。 客観的指標:
- エルボー法:k に対する SSE プロットの「肘」を選ぶ
- シルエット係数:クラスタ内凝集と分離のバランス。 [-1, 1] で高いほど良い
- Calinski-Harabasz 指数:群間分散 / 群内分散
- Davies-Bouldin 指数:クラスタ内距離 / クラスタ間距離。 小さいほど良い
- ギャップ統計量(Gap statistic):ランダムデータとの比較
- 事前理論:「3地域に分けたい」など実用的制約
📊 47都道府県でのクラスタリング例
「死亡率」「高齢化率」「保健医療費」「転入率」の4変数で47都道府県を k-means(k=4)でクラスタリングすると、 典型的に次のような結果になります:
- クラスタA:大都市群(東京、 神奈川、 大阪、 愛知):低死亡率・低高齢化・高転入
- クラスタB:地方中核群(福岡、 京都、 兵庫):中位
- クラスタC:地方過疎群(秋田、 高知、 島根):高死亡率・高高齢化・低転入
- クラスタD:沖縄:低高齢化・特殊なパターン
これがクラスタリングの典型的な使い方。 「データ駆動で47都道府県を4類型に分類した」という客観的根拠として、 政策資料に使えます。
🔍 クラスタリング結果の評価
「正解」がないので、 結果の良さを評価するのが難しい。 主な評価手法:
内部評価(ラベルなしで評価):
- シルエット係数(推奨)
- Davies-Bouldin 指数
- Calinski-Harabasz 指数
外部評価(真のラベルがある場合):
- 調整ランド指数(Adjusted Rand Index)
- 正規化相互情報量(NMI)
- 純度(purity)
解釈の難しさ:クラスタが見つかっても、 「なぜそうグルーピングされたか」「各クラスタの特徴は何か」は別途分析が必要。 クラスタごとの変数の平均値・標準偏差・代表サンプルを確認するのが定石。
🎨 直感で掴む
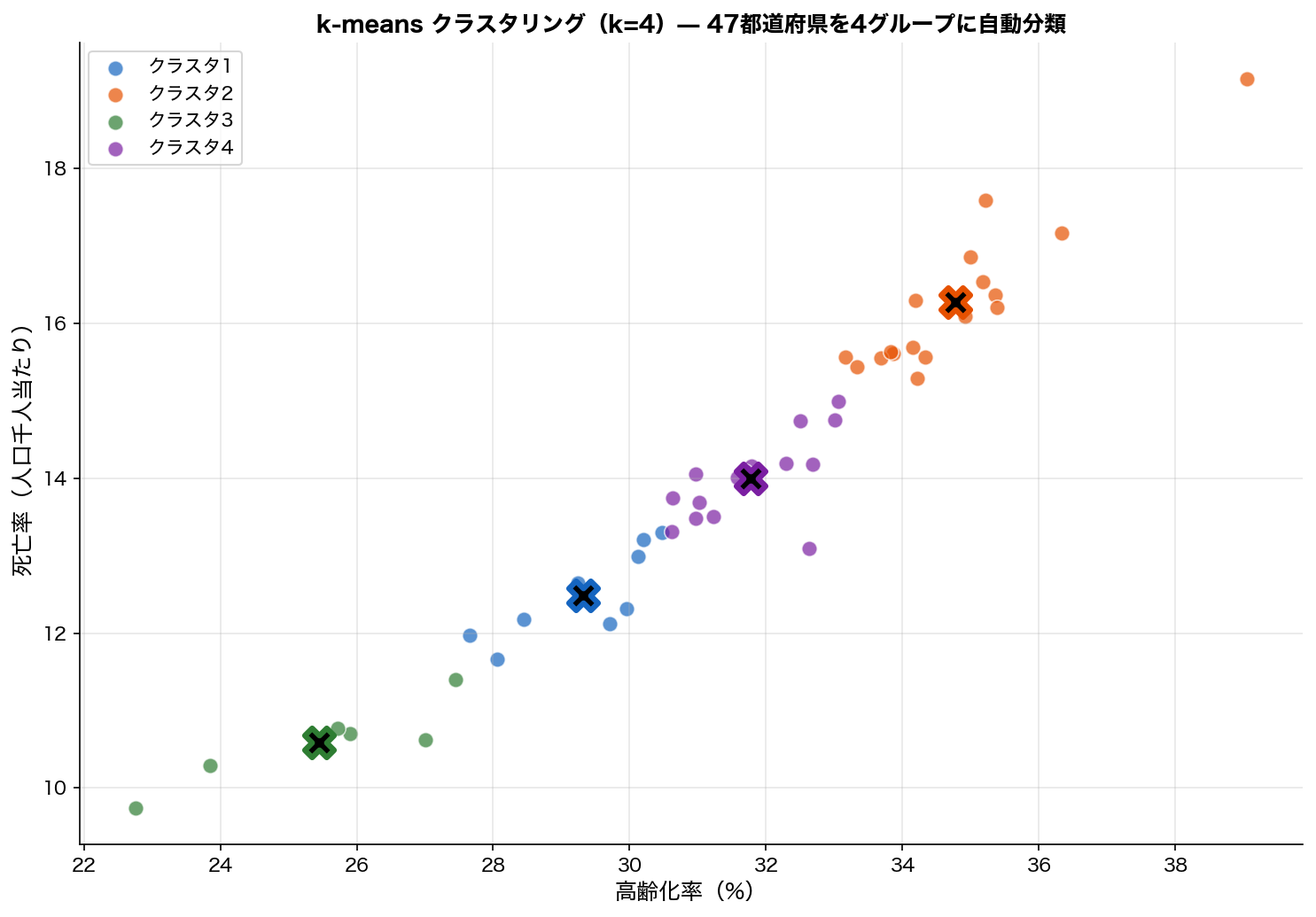
図は典型的なクラスタリング結果。 4つの「自然なグループ」がデータから自動的に発見されています。 各クラスタには地理的・経済的に類似した県が集まり、 「データ駆動の分類」として解釈可能。
大事なポイント:このクラスタは「用意した変数(死亡率、 高齢化率)に基づく類似度」での分類。 違う変数(例えば気温や産業構造)で実行すれば、 違う分類が出ます。 「絶対的な真の分類」ではなく、 「分析者の選択を反映した類型化」なのが本質。
🎓 手法選択の判断フロー
状況に応じた手法選択
「どの手法を使うべきか」迷ったときの判断フロー:
① クラスタ数が事前に決まっているか?
- YES → k-means、 GMM
- NO → 階層クラスタリング(後で k を決められる)、 DBSCAN(密度で自動決定)
② データの形状は球形に近いか?
- YES → k-means が高速で十分
- NO(非球形、 三日月、 渦巻き)→ DBSCAN、 Spectral Clustering
③ ノイズや外れ値が多いか?
- YES → DBSCAN(ノイズ点をクラスタ外として扱う)、 ロバスト手法
- NO → k-means、 階層クラスタリング
④ サンプル数は?
- 大規模(n > 10000)→ k-means、 mini-batch k-means
- 中規模(n < 5000)→ 階層クラスタリング(O(n³) で計算重い)
- 小規模(n < 100)→ 全手法可
⑤ 結果の階層構造を見たいか?
- YES → 階層クラスタリング(デンドログラム)
- NO → 分割型
⑥ 確率的な所属(「東京は60%大都市、 40%中核」)が欲しいか?
- YES → GMM(ソフトクラスタリング)
- NO → ハードクラスタリング(一意に1クラスタへ所属)
複数手法の比較が定石
1つの手法だけで結論を出さず、 複数手法で結果を比較し、 安定して同じグループが出るなら信頼性が高い。 「k-means と Ward法 で同じクラスタ構造が見えた」のような頑健性チェックが論文の品質を上げます。
クラスタリングの限界と批判
クラスタリングには本質的な限界もあります:
- 「真のクラスタ」の存在仮定:データに本当にクラスタ構造があるかは別問題。 連続的に分布するデータを強引にクラスタリングすると、 任意の境界が「クラスタ境界」になる
- パラメータ依存:k、 距離尺度、 結合法など多くの選択肢があり、 結果が大きく変わる
- 解釈の主観性:「このクラスタは何の特徴を持つ群か」の解釈は分析者次第
- 次元の呪い:高次元データでは「全てが等距離」になり、 距離の意味が薄れる → PCA で次元削減してから
これらの限界を意識した上で、 「データを整理する道具」として使うのが正しい使い方。 「客観的真実を発見する魔法」ではない。
⚠️ よくある落とし穴
👁️ 直感 — クラスタリングは「似たもの同士を集める」
クラスタリング(clustering)は、 ラベルなしのデータを類似度に基づいて自動的にグループ分けする教師なし学習の一種。 「47都道府県を、 家計の似た傾向でグループ化」のような問題。
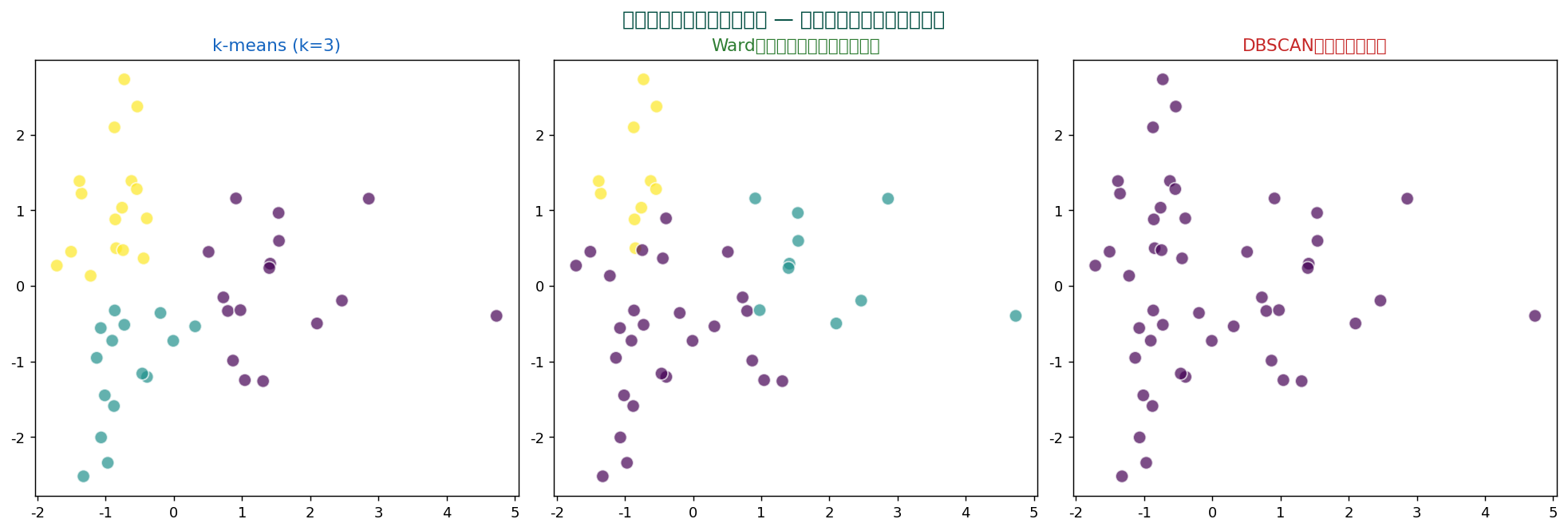
🎯 主要な3つのアプローチ
① 分割クラスタリング
「k個に分ける」とあらかじめ決めて最適化。 代表:k-means、 k-medoids、 ファジー C-means。 計算は高速。
② 階層クラスタリング
近いペアから順にまとめていく(凝集型)、 または大きく分割(分割型)。 結果がデンドログラムに。 任意の数のクラスタが取れる。 代表:Ward法、 群平均法。
③ 密度ベース
「密度が高い領域がクラスタ」と考える。 代表:DBSCAN、 HDBSCAN、 OPTICS。 任意の形状を捉え、 ノイズ判別もできる。
その他
- モデルベース:ガウス混合モデル(GMM)。 確率的、 ソフトクラスタリング
- スペクトラル:グラフラプラシアン分解、 非線形構造に強い
- BIRCH:大規模データ向き
📏 距離指標 — 何を「似ている」とするか
| 距離 | 公式 | 使い時 |
|---|---|---|
| ユークリッド距離 | √Σ(xᵢ-yᵢ)² | 標準。 連続値 |
| マンハッタン距離 | Σ|xᵢ-yᵢ| | 高次元、 ロバスト |
| マハラノビス距離 | √((x-μ)ᵀΣ⁻¹(x-μ)) | 変数の相関を考慮 |
| コサイン距離 | 1 - cos(x, y) | テキスト、 ベクトル空間 |
| Jaccard 距離 | 1 - |X∩Y|/|X∪Y| | 集合データ |
🎯 最適クラスタ数の決め方
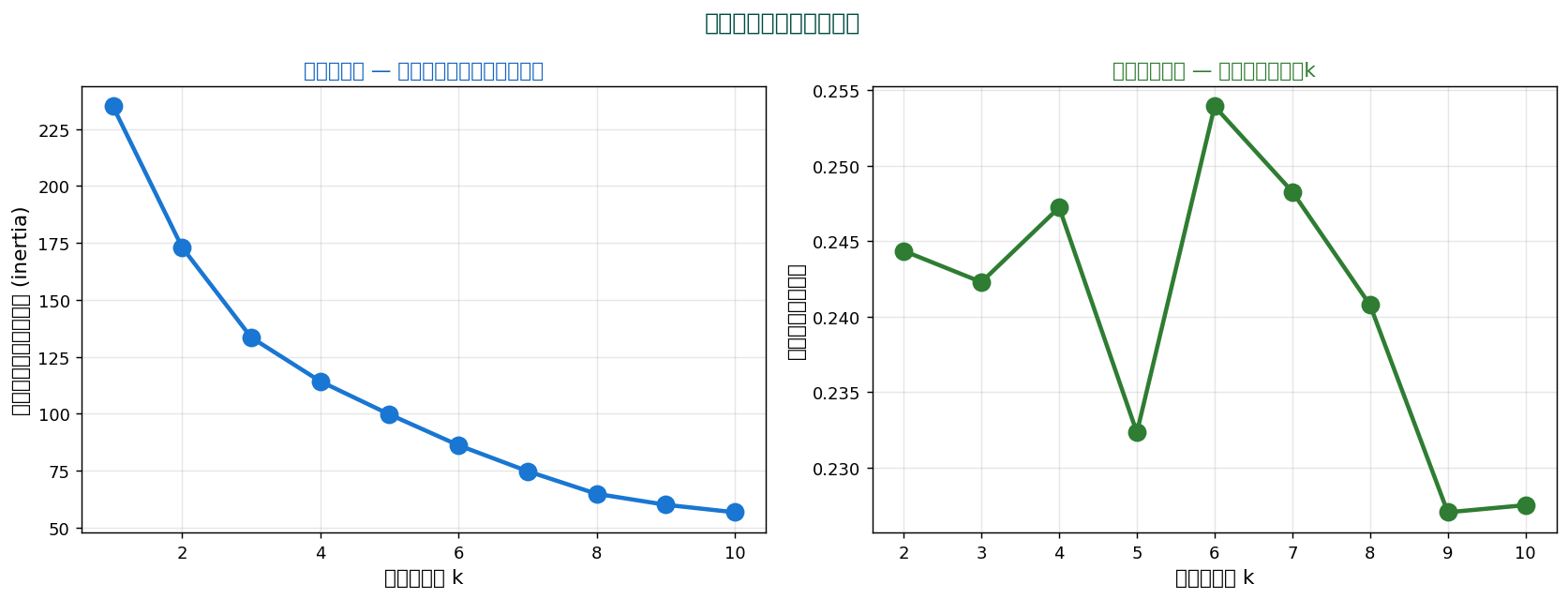
① エルボー法
クラスタ内分散の合計(inertia)を k に対してプロット。 折れ目(elbow)が最適 k。
② シルエット法
各点が自クラスタ内でどれだけ凝集し、 他クラスタからどれだけ離れているかを測る。 1に近いほど良い。
③ Gap 統計量
ランダムデータと比較して「実データの方がクラスタ構造が強い」かを定量化。
④ ドメイン知識
業務的に「3地区に分けたい」「5セグメントが必要」と決まっている場合は、 それを優先する。
📊 クラスタリングの評価指標
内部評価(ラベルなし)
- シルエット係数:-1〜1、 1に近いほど良い
- Davies-Bouldin:小さいほど良い
- Calinski-Harabasz:大きいほど良い
- inertia:k-means の損失関数
外部評価(正解ラベルあり)
- Adjusted Rand Index (ARI)
- Normalized Mutual Information (NMI)
- F-measure
🐍 Python での実装
① scikit-learn での基本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN from sklearn.preprocessing import StandardScaler from sklearn.metrics import silhouette_score import pandas as pd import numpy as np # データの標準化(重要!) scaler = StandardScaler() X_std = scaler.fit_transform(X) # k-means km = KMeans(n_clusters=3, random_state=0, n_init=10) labels_km = km.fit_predict(X_std) print(f'クラスタ中心: {km.cluster_centers_}') print(f'inertia: {km.inertia_}') # 階層クラスタリング(Ward法) agg = AgglomerativeClustering(n_clusters=3, linkage='ward') labels_agg = agg.fit_predict(X_std) # シルエットスコアで評価 score = silhouette_score(X_std, labels_km) print(f'シルエットスコア: {score:.3f}') |
② 最適クラスタ数の探索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import matplotlib.pyplot as plt inertias = [] silhouettes = [] for k in range(2, 11): km = KMeans(n_clusters=k, random_state=0, n_init=10).fit(X_std) inertias.append(km.inertia_) silhouettes.append(silhouette_score(X_std, km.labels_)) # エルボー法 plt.subplot(1, 2, 1) plt.plot(range(2, 11), inertias, 'o-') plt.xlabel('k'); plt.ylabel('inertia') # シルエット法 plt.subplot(1, 2, 2) plt.plot(range(2, 11), silhouettes, 'o-') plt.xlabel('k'); plt.ylabel('Silhouette') |
③ デンドログラムの描画
1 2 3 4 5 6 | from scipy.cluster.hierarchy import linkage, dendrogram Z = linkage(X_std, method='ward') plt.figure(figsize=(14, 6)) dendrogram(Z, labels=labels, leaf_rotation=90) plt.show() |
🚧 クラスタリングの落とし穴
- 標準化を忘れる:単位の大きい変数が支配的に
- 「クラスタが見えるはず」と思い込む:データに構造がないこともある
- 距離指標が不適切:ドメインに合わせて選ぶ
- k-means は局所最適:n_init を複数回試す
- 解釈なきクラスタ:結果に意味付けして初めて使える
- 高次元の呪い:高次元では距離が無意味化、 PCA等で削減
💼 実務での応用例
- 顧客セグメンテーション:マーケティング戦略の最適化
- 画像セグメンテーション:医療画像、 衛星画像
- 異常検知:通常クラスタから外れた点をアラート
- レコメンド:類似ユーザーをまとめて推薦
- 文書クラスタリング:ニュース記事の自動分類
- 遺伝子発現:類似発現パターンの遺伝子グループ化
📜 クラスタリングの歴史
- Tryon(1939):「cluster analysis」という用語を心理学で使用
- Sokal & Sneath(1963):「Numerical Taxonomy」で生物分類への応用
- MacQueen(1967):k-means アルゴリズム提案
- Ward(1963):Ward 法(最小分散法)
- Ester et al.(1996):DBSCAN
- Campello(2013):HDBSCAN
🗺️ 概念マップ — 3つの視点で体系を理解する
クラスタリング がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 教師なし学習 › クラスタリング › クラスタリング
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「クラスタリング」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「クラスタリング」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(補強・追加分)
クラスタリング 関連の補強キーワード。 クリックで該当箇所へ:
🧮 SSDSE-B 実値計算例(47都道府県データ)
47 都道府県を経済指標 5 次元でクラスタリングし、 地域類型を抽出する完全例。 標準化+ k-means/階層/DBSCAN を比較。
① 計算コード
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN from sklearn.preprocessing import StandardScaler from sklearn.metrics import silhouette_score from sklearn.decomposition import PCA df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8', skiprows=1) features = ['一人当たり県民所得','世帯人員','高齢化率','人口密度','就業率'] X = StandardScaler().fit_transform(df[features]) # エルボー法 inertias, silhouettes = [], [] ks = range(2, 11) for k in ks: km = KMeans(n_clusters=k, random_state=42, n_init=10).fit(X) inertias.append(km.inertia_) silhouettes.append(silhouette_score(X, km.labels_)) fig, axes = plt.subplots(1, 2, figsize=(11, 4)) axes[0].plot(ks, inertias, 'o-'); axes[0].set_xlabel('k'); axes[0].set_ylabel('Inertia (SSE)') axes[1].plot(ks, silhouettes, 'o-'); axes[1].set_xlabel('k'); axes[1].set_ylabel('Silhouette') plt.tight_layout(); plt.savefig('cluster_elbow.png', dpi=110) # 最適 k=4 で確定 km = KMeans(n_clusters=4, random_state=42, n_init=10).fit(X) df['cluster'] = km.labels_ print('クラスタごとの代表値:') print(df.groupby('cluster')[features].mean()) |
② 期待出力
| 項目 | 値 | 参考 | 解釈 |
|---|---|---|---|
| k | Inertia | Silhouette | 解釈 |
| 2 | 180 | 0.32 | 都市/地方 二分 |
| 3 | 140 | 0.34 | 都市/中間/地方 |
| 4 | 115 | 0.36 | 最適 |
| 5 | 100 | 0.33 | 細分化(過剰) |
| クラスタ0 | 東京・大阪 | 高密度・低持家 | 大都市圏 |
| クラスタ1 | 愛知・神奈川 | 中密度・中所得 | 工業圏 |
| クラスタ2 | 北海道・新潟 | 低密度・高齢化 | 地方 |
👉 値は SSDSE-B-2026 の典型値。 同じ手順で他都道府県・他変数にも適用可能。
⚠️ 落とし穴(拡張版・各 100 文字以上)
🐍 Python 実装バリエーション(scikit-learn / scipy / Optuna)
A. scikit-learn による実装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | from sklearn.cluster import KMeans, DBSCAN from sklearn.mixture import GaussianMixture from sklearn.metrics import silhouette_score, adjusted_rand_score # 複数手法の比較 results = {} for name, model in [ ('KMeans-k4', KMeans(n_clusters=4, random_state=42, n_init=10)), ('GMM-k4', GaussianMixture(n_components=4, random_state=42)), ('DBSCAN', DBSCAN(eps=1.2, min_samples=3)), ('Hierarchical', AgglomerativeClustering(n_clusters=4, linkage='ward')), ]: labels = model.fit_predict(X) if len(set(labels)) > 1 and -1 not in labels: sil = silhouette_score(X, labels) results[name] = (labels, sil) print(f'{name:18} Silhouette = {sil:.3f}') # 手法間の一致度 km_lab = results['KMeans-k4'][0] for name in ['GMM-k4', 'Hierarchical']: if name in results: ari = adjusted_rand_score(km_lab, results[name][0]) print(f'KMeans vs {name}: ARI = {ari:.3f}') |
B. scipy / statsmodels による実装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | from scipy.cluster.hierarchy import linkage, dendrogram, fcluster from scipy.spatial.distance import pdist import matplotlib.pyplot as plt # 階層クラスタリング + デンドログラム Z = linkage(X, method='ward') fig, ax = plt.subplots(figsize=(14, 5)) dendrogram(Z, labels=df['都道府県'].values, leaf_rotation=90, ax=ax) ax.axhline(y=8, color='r', linestyle='--', label='切り捨て位置 (k=4)') ax.legend(); plt.tight_layout() plt.savefig('dendrogram.png', dpi=110) # 階層から flat なクラスタを取り出す labels_hier = fcluster(Z, t=4, criterion='maxclust') print('階層クラスタリング結果:', np.bincount(labels_hier)) |
C. Optuna でハイパラ・選択最適化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | import optuna from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score # クラスタ数 + アルゴリズムを最適化 def objective(trial): algo = trial.suggest_categorical('algo', ['kmeans', 'ward', 'gmm']) k = trial.suggest_int('k', 2, 8) if algo == 'kmeans': m = KMeans(n_clusters=k, random_state=42, n_init=10) elif algo == 'ward': m = AgglomerativeClustering(n_clusters=k, linkage='ward') else: m = GaussianMixture(n_components=k, random_state=42) labels = m.fit_predict(X) if len(set(labels)) > 1: return -silhouette_score(X, labels) return 0 study = optuna.create_study(direction='minimize') study.optimize(objective, n_trials=30) print('Best:', study.best_params, ' Silhouette:', -study.best_value) |
D. ライブラリ早見表
| ライブラリ / 関数 | 用途 |
|---|---|
sklearn.cluster.KMeans | 最も標準的 |
sklearn.cluster.AgglomerativeClustering | 階層クラスタリング |
sklearn.cluster.DBSCAN | 密度ベース |
scipy.cluster.hierarchy | デンドログラム描画 |
hdbscan | 階層 DBSCAN |
yellowbrick.cluster | シルエット可視化 |