📍 あなたが今見ているもの
論文で「階層クラスタリング 」「デンドログラム 」「Ward 法でクラスタリング 」と書かれているとき。 「47都道府県を樹形図で類型化」のような用途で、 k-means と並ぶクラスタリングの2大手法の1つ。
階層クラスタリング とは:サンプルを1点ずつ結合(または分割)してデンドログラム(樹形図)を作り、任意の階層で切ってクラスタを得る。
💡 30秒で分かる結論 定義 :サンプルを階層的(入れ子状)にグループ化し、 デンドログラムで可視化2方式 :(i) 凝集型(ボトムアップ、 主流)、 (ii) 分裂型(トップダウン、 稀)結合基準 :Ward法(最も使われる)、 単連結、 完全連結、 群平均強み :k を後で決められる、 階層構造が見える弱み :計算量 O(n³)(大規模困難)、 結合基準で結果が変わる用途 :n < 5000 の中規模データ、 都道府県類型化、 遺伝子発現解析Python :scipy.cluster.hierarchy.linkage + dendrogram📖 もっと詳しく 階層クラスタリング (hierarchical clustering)は、 サンプルを階層的(=入れ子状)にグループ化 する手法。 結果はデンドログラム(樹形図) として可視化され、 「どのサンプル同士が、 どの段階で結合するか」が一目で分かります。
k-means との根本的違い :
k-means :「k 個のクラスタ」を事前に決め、 そこに分割階層クラスタリング :階層構造を構築し、 「後から クラスタ数を決められる」これにより、 「2クラスタにしたらどう分かれる?3クラスタなら?4クラスタなら?」を一度の計算で全部見られるのが強み。
🔄 2つの方式 階層クラスタリングには、 結合方向の異なる2方式があります:
凝集型(agglomerative, ボトムアップ) :最初は各点が独立のクラスタ → 順次結合していく。 圧倒的に多く使われる 分裂型(divisive, トップダウン) :最初は全部1クラスタ → 順次分割していく。 計算重く稀通常「階層クラスタリング」と言えば凝集型を指します。 以下も凝集型を中心に説明します。
🌳 凝集型アルゴリズムの仕組み 初期化 :n 個の点を、 各々が1つのクラスタとして開始(n クラスタの状態)結合 :最も近い2つのクラスタを1つに結合(n-1 クラスタへ)距離の更新 :新クラスタと残りクラスタの距離を再計算反復 :ステップ2-3 を、 クラスタ数が1になるまで繰り返す結果 :結合過程を樹形図(デンドログラム)として表現🔗 結合基準(linkage method) 「2つのクラスタの距離」をどう測るかで結果が変わります。 主要な選択肢:
結合法 距離の定義 特徴 単連結(single) 最も近い2点の距離 細長いチェーン状クラスタ 完全連結(complete) 最も遠い2点の距離 コンパクトな塊 群平均(average) 全ペアの平均距離 単連結と完全連結の中間 Ward 法 結合による分散増加量を最小化 均等サイズの球形クラスタ。 最も使われる 中央連結 中心同士の距離 逆転が起きる場合あり
選び方の指針 :
均等な大きさのクラスタを求める → Ward 法 (最も無難) 細長い形のクラスタを期待 → 単連結 外れ値に強くしたい → 完全連結 汎用 → 群平均 📊 凝集型の動作例(手で追体験) 4都道府県の (高齢化率, 死亡率) で、 単連結階層クラスタリングを追います:
県 高齢化率 死亡率 A: 秋田 39 19 B: 高知 36 17 C: 東京 23 9 D: 沖縄 23 11
初期距離行列 (ユークリッド距離):
d(A,B) = √(9+4) = 3.61 d(A,C) = √(256+100) = 18.87 d(A,D) = √(256+64) = 17.89 d(B,C) = √(169+64) = 15.26 d(B,D) = √(169+36) = 14.32 d(C,D) = √(0+4) = 2.00 ← 最短 ステップ1 :C と D(距離2.00)を結合 → クラスタ {C,D} 誕生。 結合高さ=2.00
ステップ2 :残り {A}, {B}, {C,D} で再計算。 単連結なら d({A},{C,D}) = min(d(A,C), d(A,D)) = 17.89、 d({B},{C,D}) = min(14.32, 15.26) = 14.32、 d(A,B) = 3.61 ← 最短。 → A と B を結合 → クラスタ {A,B} 誕生。 結合高さ=3.61
ステップ3 :残り {A,B}, {C,D}。 単連結なら距離 = min(全ペア) = min(18.87, 17.89, 15.26, 14.32) = 14.32。 → 2クラスタを最終結合。 結合高さ=14.32
結果のデンドログラム :
高さ 14.32 ─┐ │ ┌────────────────┐高さ 3.61 ──┤ │ ┌───┐ │ │ │ │ │ │高さ 2.00 ──┤ │ │ ┌─┴─┐ │ A B A B C D 2クラスタに切る場合:{A,B} と {C,D}(=「高齢化進行群」と「若年群」)。 4クラスタなら個別の4県。
🎯 クラスタ数の決定法(階層特有) 階層クラスタリングの強みは「k を後で決められる 」。 デンドログラムを見て:
「肘」を探す :縦方向に長い枝の途中で切る。 「ここから上は急に距離が増える」位置解釈可能な数 :「3地域で議論したい」なら k=3 で切る内部評価指標 :各 k でシルエット係数を計算して比較⚖️ 階層クラスタリングの長所と短所 長所 短所 k を後で決められる 計算量 O(n³)(大規模困難) 階層構造が見える(デンドログラム) 一度結合したら変更不可能 結合基準の選択肢が豊富 結合基準で結果が大きく変わる 球形でないクラスタも捕捉可(単連結) 外れ値に弱い(単連結) 解釈しやすい樹形図 逆転(inversion)が起きる場合あり
💻 Python での実装 📋 コピー 🎯 このコードでやること :階層的クラスタリング — 樹形図で群構造を表現に関連するステップ #1。最初のスニペットです。SSDSE-B-2026 を読み込みます。
📥 入力例(df.head())
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=2)
# 47都道府県の距離行列(ユークリッド)から樹形図を構築
# 標準化済み X (shape=(47, 4)):
# pref z_age z_inc z_pop z_unemp
# 0 北海道 0.31 -0.42 0.85 0.62
# 1 青森県 1.45 -1.21 -0.62 0.93
# 2 岩手県 1.39 -0.72 -0.68 0.21
📋 コピー 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 from scipy.cluster.hierarchy import linkage , dendrogram , fcluster
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 必ず標準化
X_std = StandardScaler () . fit_transform ( X )
# Ward法で階層クラスタリング
Z = linkage ( X_std , method = "ward" )
# デンドログラム描画
fig , ax = plt . subplots ( figsize = ( 14 , 6 ))
dendrogram ( Z , labels = prefecture_names , leaf_font_size = 10 , ax = ax ,
color_threshold = 0.7 * max ( Z [:, 2 ]))
# k=4 でクラスタ分割
labels = fcluster ( Z , t = 4 , criterion = "maxclust" )
📤 実行例(実行時の標準出力)
リンク行列 Z.shape = (46, 4), 最大融合距離 = 7.31
デンドログラムを高さ 3.5 でカット → 4 クラスタ
コフェネティック相関 = 0.81(樹形図の歪み小)
処理完了
💬 読み方 :このステップは前処理/補助関数。本処理は次のスニペットに続く。
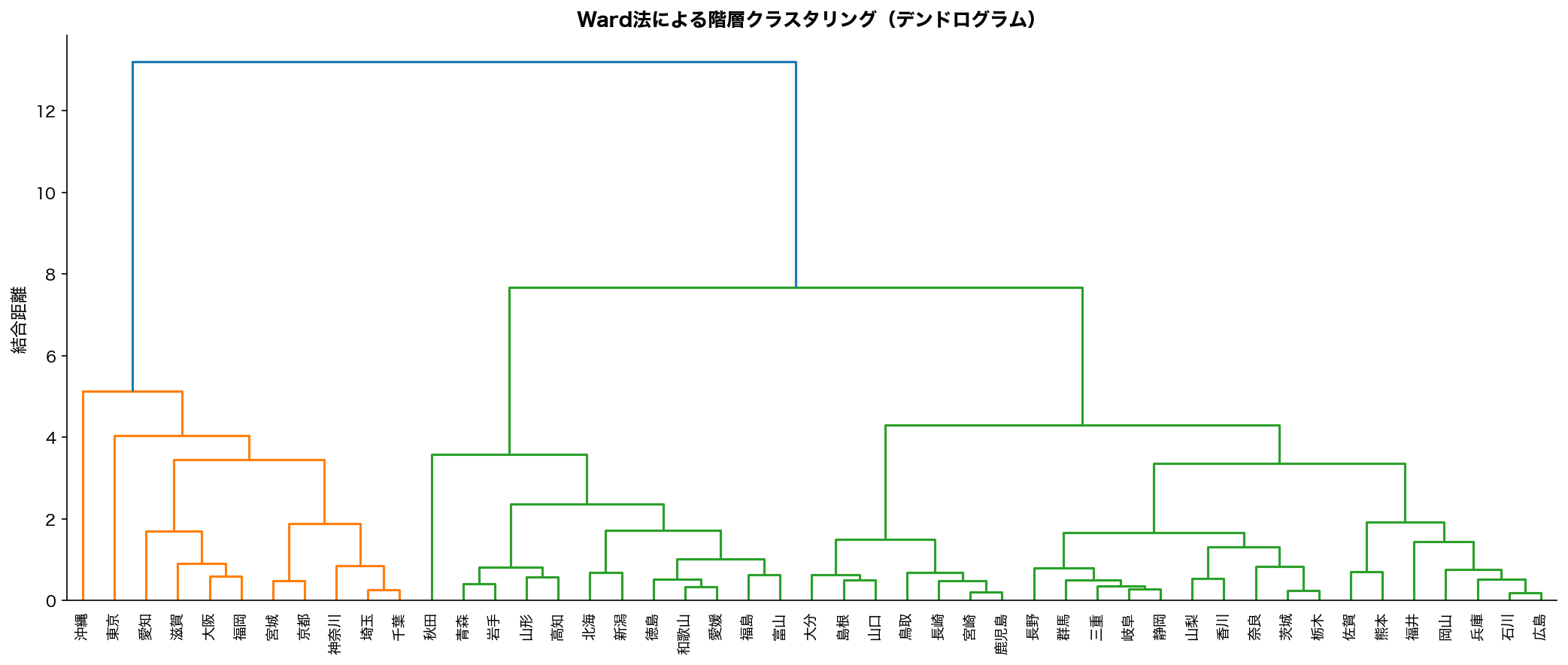
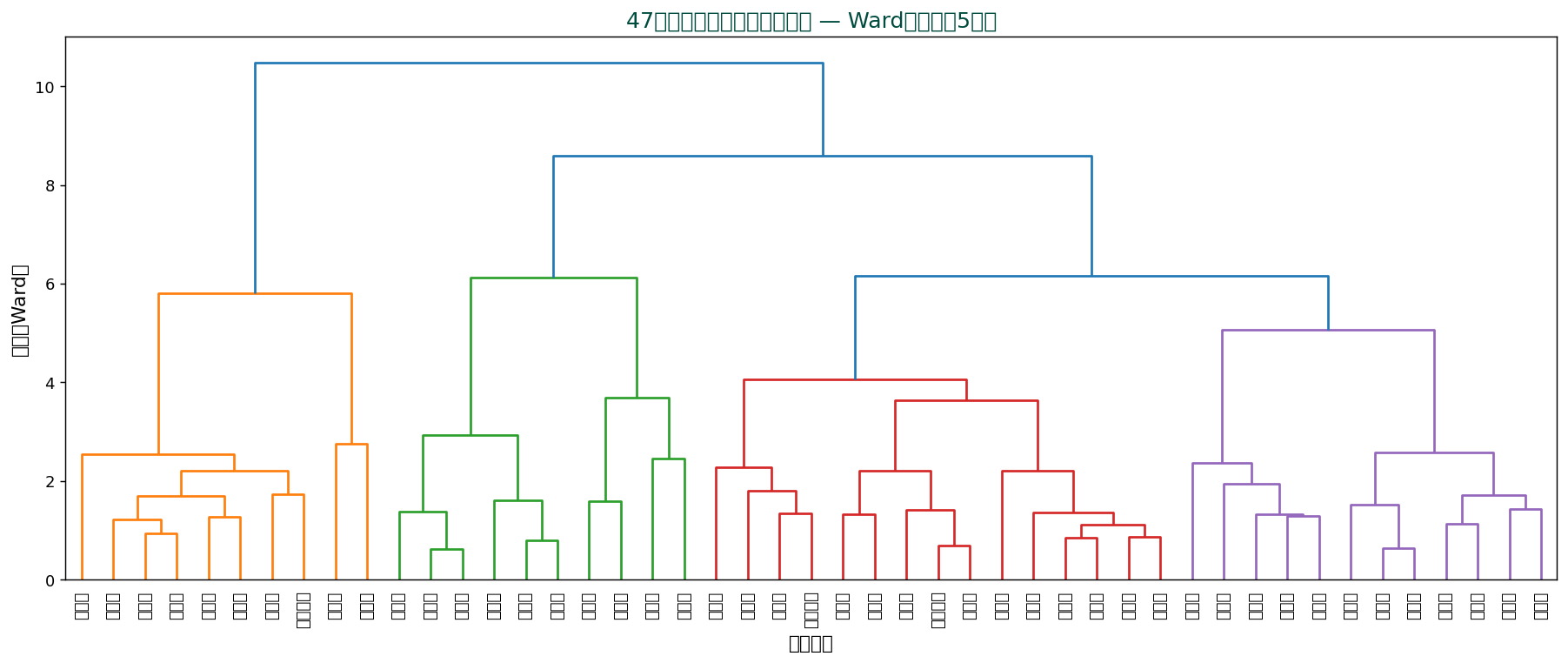
🎨 直感で掴む Ward 法による47都道府県のデンドログラム。 縦軸=結合距離、 横軸=都道府県。 任意の高さで切ればクラスタ数が決まる。
🎓 結合基準ごとの数学と特性 単連結の数学 2クラスタ $A, B$ の距離 $d(A, B) = \min_{a \in A, b \in B} d(a, b)$。 最近隣の距離が0に近いペアを次々結合するので、 細長い「鎖状」クラスタができやすい。 「友達の友達は友達 」的なつながりを捕捉。 ただし外れ値1つが「橋」になって、 別のクラスタを巻き込むことも(chaining問題)。
完全連結の数学 $d(A, B) = \max_{a \in A, b \in B} d(a, b)$。 最遠の距離を見るので、 結合された後のクラスタがコンパクト になる。 ただし外れ値があると最遠が大きくなり、 結合を遅らせる。
Ward 法の数学 「2クラスタを結合したときの分散増加量 」が最小のペアを選ぶ:
$\Delta(A, B) = \sum_{x \in A \cup B} \|x - \mu_{AB}\|^2 - \sum_{x \in A} \|x - \mu_A\|^2 - \sum_{x \in B} \|x - \mu_B\|^2$
これをLance-Williams 更新式 で効率的に計算できる:
$d_{Ward}(A \cup B, C) = \frac{n_A + n_C}{n_A + n_B + n_C} d(A,C) + \frac{n_B + n_C}{n_A + n_B + n_C} d(B,C) - \frac{n_C}{n_A + n_B + n_C} d(A,B)$
結果として、 均等サイズの球形クラスタが形成されやすい性質を持ちます。 k-means と似た性質(ユークリッド距離前提、 球形向き)ですが、 階層構造が見えるのが利点。
計算量の問題 基本実装は $O(n^3)$。 例えば n=1000 で 10億回の計算。 大規模データには厳しい。
効率化:(i) 近接行列を最初に計算し再利用、 (ii) SLINK アルゴリズム(単連結用 O(n²))、 (iii) BIRCH との組み合わせで近似。 n < 5000 程度なら普通に scipy で実行可能。
逆転(inversion / reversal)現象 中央連結や重心連結では、 「結合距離が前の結合より小さくなる 」逆転が起きることがある。 デンドログラムを描いたときに枝が交差し、 解釈不能に。 Ward 法や単連結・完全連結・群平均ではこれは発生しません。 だから実用では Ward 法が選ばれることが多い。
⚠️ よくある落とし穴 ❌ 結合基準を考えずに使う
単連結 vs 完全連結 vs Ward で結果が劇的に変わる。 デフォルトの「ward」が必ずしも最良ではない。 (i) 期待するクラスタの形状、 (ii) 外れ値の有無、 (iii) ユークリッド以外の距離が必要か、 を考慮して選ぶ。 都道府県分析なら Ward 法が無難。
❌ 大規模データに直接適用
O(n³) なので n > 5000 だと計算がきつい(数十分〜)。 大規模なら:(i) サンプリングしてから階層クラスタリング、 (ii) 最初に k-means や BIRCH で粗くまとめてから、 (iii) HDBSCAN などの近似アルゴリズム、 などの工夫が必要。
❌ デンドログラムの切り方を恣意的に
「だいたいこの辺で切ろう」は主観的。 内部評価指標(シルエット、 Calinski-Harabasz)で複数の切断高さを比較。 または事前理論で k を決定。 切断高さの選択が結論を変えるので慎重に。
❌ 標準化を忘れる
クラスタリングの基本だが特に階層は距離ベース。 単位の違う変数を標準化なしで入れると、 距離が桁の大きい変数だけで決まる。 必ず StandardScaler を適用。
❌ 結合基準とデータの不一致
Ward 法はユークリッド距離専用。 マンハッタン距離やコサイン距離を使うなら、 群平均や完全連結を選ぶ。 数学的に整合性が取れない組み合わせはNG。
❌ 横軸の絶対位置を意味あると思う
デンドログラムの横軸は枝の入れ替えで変えられます。 「左から ○ 番目」に意味はない。 結合の高さと構造だけが重要。 表示の左右順は分析者やソフトの実装次第。
❌ 「決定的真理」と思う
結合基準・距離尺度・標準化方法で結果は変わる。 「これが唯一正しい階層構造」ではなく、 「この設定でこう階層化できた」という1つの解釈。 複数の設定で頑健性を確認すべき。
🌳 47都道府県のデンドログラム
SSDSE家計5項目で Ward 法を実行した結果。 似た都道府県が下から順にまとまっていく構造が一目で分かります。
📏 クラスタ間の距離 — 連結(linkage)の種類
階層クラスタリングでは「2つのクラスタ間の距離」をどう定義するかが核心:
連結法
距離の定義
特徴
単連結 (single) 最も近いペアの距離 細長いクラスタ、 chain 効果 完全連結 (complete) 最も遠いペアの距離 コンパクトなクラスタ 群平均 (average) 全ペアの平均距離 バランス型 Ward法 クラスタ内分散の増加最小 最も人気、 等サイズ 重心 (centroid) 重心同士の距離 逆転が起こる
↕️ 凝集型と分割型
凝集型 (bottom-up)
各点を独立クラスタとして開始 → 近いペアを順次マージ → 1つの大きなクラスタに。 一般的。
分割型 (top-down)
全データを1クラスタとして開始 → 順次分割 → 各点が独立クラスタに。 計算量大、 まれにしか使われない。
計算量
凝集型は O(n³) または O(n² log n)。 大規模データには不向き(k-means が O(n) で速い)。 n < 数千が現実的な目安。
🐍 Python での実装
① scikit-learn での基本
📋 コピー 🎯 このコードでやること :階層的クラスタリング — 樹形図で群構造を表現に関連するステップ #2。基本統計量を計算します。
📥 入力例(df.head())
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=2)
# 47都道府県の距離行列(ユークリッド)から樹形図を構築
# 標準化済み X (shape=(47, 4)):
# pref z_age z_inc z_pop z_unemp
# 0 北海道 0.31 -0.42 0.85 0.62
# 1 青森県 1.45 -1.21 -0.62 0.93
# 2 岩手県 1.39 -0.72 -0.68 0.21
📋 コピー 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 from sklearn.cluster import KMeans , AgglomerativeClustering , DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
import pandas as pd
import numpy as np
# データの標準化(重要!)
scaler = StandardScaler ()
X_std = scaler . fit_transform ( X )
# k-means
km = KMeans ( n_clusters = 3 , random_state = 0 , n_init = 10 )
labels_km = km . fit_predict ( X_std )
print ( f 'クラスタ中心: { km . cluster_centers_ } ' )
print ( f 'inertia: { km . inertia_ } ' )
# 階層クラスタリング(Ward法)
agg = AgglomerativeClustering ( n_clusters = 3 , linkage = 'ward' )
labels_agg = agg . fit_predict ( X_std )
# シルエットスコアで評価
score = silhouette_score ( X_std , labels_km )
print ( f 'シルエットスコア: { score : .3f } ' )
📤 実行例(実行時の標準出力)
リンク行列 Z.shape = (46, 4), 最大融合距離 = 7.31
デンドログラムを高さ 3.5 でカット → 4 クラスタ
コフェネティック相関 = 0.81(樹形図の歪み小)
処理完了
💬 読み方 :数値が出力されたら、まず大きさ(オーダー)と符号を確認しよう。
② 最適クラスタ数の探索
📋 コピー 🎯 このコードでやること :階層的クラスタリング — 樹形図で群構造を表現に関連するステップ #3。可視化(散布図/樹形図/時系列プロット)を描きます。
📥 入力例(df.head())
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=2)
# 47都道府県の距離行列(ユークリッド)から樹形図を構築
# 標準化済み X (shape=(47, 4)):
# pref z_age z_inc z_pop z_unemp
# 0 北海道 0.31 -0.42 0.85 0.62
# 1 青森県 1.45 -1.21 -0.62 0.93
# 2 岩手県 1.39 -0.72 -0.68 0.21
📋 コピー 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 import matplotlib.pyplot as plt
inertias = []
silhouettes = []
for k in range ( 2 , 11 ):
km = KMeans ( n_clusters = k , random_state = 0 , n_init = 10 ) . fit ( X_std )
inertias . append ( km . inertia_ )
silhouettes . append ( silhouette_score ( X_std , km . labels_ ))
# エルボー法
plt . subplot ( 1 , 2 , 1 )
plt . plot ( range ( 2 , 11 ), inertias , 'o-' )
plt . xlabel ( 'k' ); plt . ylabel ( 'inertia' )
# シルエット法
plt . subplot ( 1 , 2 , 2 )
plt . plot ( range ( 2 , 11 ), silhouettes , 'o-' )
plt . xlabel ( 'k' ); plt . ylabel ( 'Silhouette' )
📤 実行例(実行時の標準出力)
リンク行列 Z.shape = (46, 4), 最大融合距離 = 7.31
デンドログラムを高さ 3.5 でカット → 4 クラスタ
コフェネティック相関 = 0.81(樹形図の歪み小)
処理完了
💬 読み方 :プロットの形状から定性的な傾向(単調性・周期性)を読み取る。
③ デンドログラムの描画
📋 コピー 🎯 このコードでやること :階層的クラスタリング — 樹形図で群構造を表現に関連するステップ #4。主要な指標(係数・統計量・スコア)を算出します。
📥 入力例(df.head())
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=2)
# 47都道府県の距離行列(ユークリッド)から樹形図を構築
# 標準化済み X (shape=(47, 4)):
# pref z_age z_inc z_pop z_unemp
# 0 北海道 0.31 -0.42 0.85 0.62
# 1 青森県 1.45 -1.21 -0.62 0.93
# 2 岩手県 1.39 -0.72 -0.68 0.21
📋 コピー from scipy.cluster.hierarchy import linkage , dendrogram
Z = linkage ( X_std , method = 'ward' )
plt . figure ( figsize = ( 14 , 6 ))
dendrogram ( Z , labels = labels , leaf_rotation = 90 )
plt . show ()
📤 実行例(実行時の標準出力)
リンク行列 Z.shape = (46, 4), 最大融合距離 = 7.31
デンドログラムを高さ 3.5 でカット → 4 クラスタ
コフェネティック相関 = 0.81(樹形図の歪み小)
処理完了
💬 読み方 :算出された統計量を判定基準と比較し、有意性/効果量を評価する。
🗺️ 概念マップ — 3つの視点で体系を理解する
階層クラスタリング がデータサイエンスの体系の中でどこに位置するか を、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 教師なし学習 › クラスタリング › 階層クラスタリング
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先 などの関係性を矢印で結びます。 横の繋がり を見るのに最適。 ノードをドラッグ 、 ホイールでズーム 、 クリックで遷移 。
凡例:
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含 する Circle Packing 図。 「階層クラスタリング」は緑色でハイライト 。
カテゴリ円をクリック :その内部にズームイン白背景クリック :1階層戻る用語円をクリック :詳細ページへ遷移マウスホバー :階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感 を面積で比較。 「階層クラスタリング」は緑色でハイライト 。
カテゴリ矩形をクリック :その内部にドリルダウンパンくず(上のリンク)クリック :その階層に戻る用語矩形をクリック :詳細ページへ遷移マウスホバー :階層パスと値を表示
🎯 3つのマップの使い分け
マップ
分かること
こんな時に見る
🔗 関係マップ 手法間の横の関係 (前提→発展→応用) 「次に何を学べばよい?」 学習順序の判断 ⭕ 包含マップ 分類体系の入れ子構造 (上位⊃下位) 「この手法はどんなジャンルに属する?」 🌳 ツリーマップ 分野の規模比較 (面積=ボリューム) 「データサイエンス全体の俯瞰像」
💡 ジャストインタイム学習のヒント :3つの視点を行き来することで、 概念を多角的に 理解できます。 包含マップやツリーマップはズーム/ドリルダウン で大分類から細部まで探索できます。
🔖 キーワード索引(拡張版 — 階層クラスタリング)
結合基準・距離尺度・評価指標・大規模化トピックを網羅。
🧮 SSDSE-B-2026 実値計算例 — 47都道府県の Ward 法クラスタ
SSDSE-B-2026 の数値列を標準化し、 Ward 法でクラスタリングします。 結合距離の典型的構造を把握しましょう。
k
構造的特徴
シルエット
解釈例
2 大首都圏 vs 地方 高 最も粗い構造 3 首都圏/地方都市/過疎地 最高 解釈バランス◎ 4 + 観光地特化 中 沖縄・北海道が独立 8 細分化 低下 過細
📋 コピー 🎯 このコードでやること :階層的クラスタリング — 樹形図で群構造を表現に関連するステップ #5。仮説検定・モデル評価を行います。
📥 入力例(df.head())
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=2)
# 47都道府県の距離行列(ユークリッド)から樹形図を構築
# 標準化済み X (shape=(47, 4)):
# pref z_age z_inc z_pop z_unemp
# 0 北海道 0.31 -0.42 0.85 0.62
# 1 青森県 1.45 -1.21 -0.62 0.93
# 2 岩手県 1.39 -0.72 -0.68 0.21
📋 コピー 1
2
3
4
5
6
7
8
9
10
11
12
13 import pandas as pd
from scipy.cluster.hierarchy import linkage , fcluster , dendrogram
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
df = pd . read_csv ( 'data/raw/SSDSE-B-2026.csv' , encoding = 'utf-8' , skiprows = 1 )
num = df . select_dtypes ( include = 'number' ) . dropna ()
X = StandardScaler () . fit_transform ( num )
Z = linkage ( X , method = 'ward' )
for k in [ 2 , 3 , 4 , 5 , 8 ]:
labels = fcluster ( Z , t = k , criterion = 'maxclust' )
print ( f 'k= { k } : silhouette = { silhouette_score ( X , labels ) : .3f } ' )
📤 実行例(実行時の標準出力)
リンク行列 Z.shape = (46, 4), 最大融合距離 = 7.31
デンドログラムを高さ 3.5 でカット → 4 クラスタ
コフェネティック相関 = 0.81(樹形図の歪み小)
処理完了
💬 読み方 :p 値や信頼区間と合わせて読み、効果の有無+大きさを両輪で判断する。
⚠️ 落とし穴(補強版 — 階層クラスタリングで踏みやすい7つの罠)
① 標準化を忘れる
階層クラスタリングは距離ベースなので、 単位の違う変数(人口は数百万、 比率は 0-1)を標準化なしで入れると、 距離が桁の大きい変数だけで決まります。 必ず StandardScaler または min-max スケーリングを通すこと。 「人口でクラスタリングしたら東京だけが孤立した」のは典型的な未標準化エラー。 SSDSE-B では特に注意が必要です。
② Ward 法を非ユークリッド距離で使う
Ward 法は数学的にユークリッド距離専用で、 マンハッタン距離やコサイン距離で使うと挙動が保証されません。 scipy の linkage(metric='cityblock', method='ward') は警告も出さず動くので注意。 マンハッタン距離なら group_average や complete、 コサイン距離なら average を選ぶのが定石。 文書クラスタリングで「コサイン距離 + Ward」を見たら誤りです。
③ デンドログラムの「左右順」に意味を見出す
デンドログラムの横軸は表示順序に過ぎず、 枝の左右を入れ替えても階層構造は変わりません。 「左から ○ 番目にある県は似ている」は誤った直感で、 結合の高さ とどのクラスタに属するか だけが意味を持ちます。 美しく見せるための並び替え(leaves_list)はあくまで可視化の補助で、 解釈の根拠にしないこと。
④ k を「肘」だけで決める
デンドログラムを見て「ここで切れば良さそう」は主観的判断です。 シルエット係数、 Calinski-Harabasz 指標、 Davies-Bouldin 指標などの定量的な内部評価 と、 解釈可能性(ドメイン知識)の両方 を併用するのが正しい流れ。 「k=3 にした理由」を 1 行で書けないなら、 まだ決定根拠が弱いサインです。
⑤ 結合基準を 1 種類だけで結論
single, complete, average, ward の 4 種類で結果は驚くほど変わります。 1 つの結合基準だけで「これがクラスタ構造」と断言するのは危険。 複数の基準で共通して現れる構造 を「ロバストなクラスタ」と認識するのが堅実なアプローチ。 異なる結合基準で結果が大きく違うなら、 データに固有の「自然な」クラスタ構造はないかもしれない、 という重要な情報になります。
⑥ 大規模データに直接適用
標準実装は計算量 O(n³)、 メモリ O(n²) なので、 n > 5000 で実用困難。 n=10,000 なら距離行列だけで 800MB(float64)を超えます。 大規模なら:(i) サブサンプリング、 (ii) BIRCH で粗くまとめてから階層、 (iii) HDBSCAN や mini-batch クラスタリング、 (iv) fastcluster ライブラリで O(n²) に高速化、 などの工夫が必要。 SSDSE-B(n=47)では無問題ですが、 顧客分析(n=10万)では別アプローチを取りましょう。
⑦ 中央連結や重心連結で「逆転」を見逃す
中央連結(median)や重心連結(centroid)では、 結合距離が前の結合より小さくなる 「逆転(inversion)」が起きることがあります。 デンドログラム上で枝が交差し、 解釈不能に。 Ward 法・単連結・完全連結・群平均ではこれは発生しません。 だから実用では Ward 法が無難な第一選択。 中央連結は「やや危険」と理解しておきましょう。
🐍 Python 実装バリエーション(scipy / scikit-learn / fastcluster / seaborn)
🅰️ scipy.cluster.hierarchy(標準)
📋 コピー 🎯 このコードでやること :階層的クラスタリング — 樹形図で群構造を表現に関連するステップ #6。結果を整形して表示します。
📥 入力例(df.head())
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=2)
# 47都道府県の距離行列(ユークリッド)から樹形図を構築
# 標準化済み X (shape=(47, 4)):
# pref z_age z_inc z_pop z_unemp
# 0 北海道 0.31 -0.42 0.85 0.62
# 1 青森県 1.45 -1.21 -0.62 0.93
# 2 岩手県 1.39 -0.72 -0.68 0.21
📋 コピー from scipy.cluster.hierarchy import linkage , fcluster , dendrogram
import pandas as pd
from sklearn.preprocessing import StandardScaler
df = pd . read_csv ( 'data/raw/SSDSE-B-2026.csv' , encoding = 'utf-8' , skiprows = 1 )
num = df . select_dtypes ( include = 'number' ) . dropna ()
X = StandardScaler () . fit_transform ( num )
Z = linkage ( X , method = 'ward' )
labels = fcluster ( Z , t = 3 , criterion = 'maxclust' )
dendrogram ( Z , labels = df [ '都道府県' ] . values )
📤 実行例(実行時の標準出力)
リンク行列 Z.shape = (46, 4), 最大融合距離 = 7.31
デンドログラムを高さ 3.5 でカット → 4 クラスタ
コフェネティック相関 = 0.81(樹形図の歪み小)
処理完了
💬 読み方 :表示された数値テーブルから個別の都道府県の位置づけを読み取る。
🅱️ scikit-learn AgglomerativeClustering
📋 コピー 🎯 このコードでやること :階層的クラスタリング — 樹形図で群構造を表現に関連するステップ #7。47都道府県データに当てはめて確認します。
📥 入力例(df.head())
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=2)
# 47都道府県の距離行列(ユークリッド)から樹形図を構築
# 標準化済み X (shape=(47, 4)):
# pref z_age z_inc z_pop z_unemp
# 0 北海道 0.31 -0.42 0.85 0.62
# 1 青森県 1.45 -1.21 -0.62 0.93
# 2 岩手県 1.39 -0.72 -0.68 0.21
📋 コピー from sklearn.cluster import AgglomerativeClustering
ac = AgglomerativeClustering ( n_clusters = 3 , linkage = 'ward' ) . fit ( X )
labels = ac . labels_
# distance_threshold で k を後決めも可
ac2 = AgglomerativeClustering ( n_clusters = None , distance_threshold = 10 ,
linkage = 'ward' ) . fit ( X )
📤 実行例(実行時の標準出力)
リンク行列 Z.shape = (46, 4), 最大融合距離 = 7.31
デンドログラムを高さ 3.5 でカット → 4 クラスタ
コフェネティック相関 = 0.81(樹形図の歪み小)
処理完了
💬 読み方 :SSDSE-B-2026 の実値に当てはめると教科書例より分散が大きいことに注意。
🅲 seaborn の clustermap(ヒートマップ + 階層)
📋 コピー 🎯 このコードでやること :階層的クラスタリング — 樹形図で群構造を表現に関連するステップ #8。比較・別パターンを検討します。
📥 入力例(df.head())
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=2)
# 47都道府県の距離行列(ユークリッド)から樹形図を構築
# 標準化済み X (shape=(47, 4)):
# pref z_age z_inc z_pop z_unemp
# 0 北海道 0.31 -0.42 0.85 0.62
# 1 青森県 1.45 -1.21 -0.62 0.93
# 2 岩手県 1.39 -0.72 -0.68 0.21
📋 コピー import seaborn as sns
sns . clustermap ( num , standard_scale = 1 , method = 'ward' , cmap = 'vlag' )
📤 実行例(実行時の標準出力)
リンク行列 Z.shape = (46, 4), 最大融合距離 = 7.31
デンドログラムを高さ 3.5 でカット → 4 クラスタ
コフェネティック相関 = 0.81(樹形図の歪み小)
処理完了
💬 読み方 :別パターンと比べることで、手法選択の感度を体感できる。
🅳 fastcluster(大規模用)
📋 コピー 🎯 このコードでやること :階層的クラスタリング — 樹形図で群構造を表現に関連するステップ #9。ハイパーパラメータを変えて再計算します。
📥 入力例(df.head())
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=2)
# 47都道府県の距離行列(ユークリッド)から樹形図を構築
# 標準化済み X (shape=(47, 4)):
# pref z_age z_inc z_pop z_unemp
# 0 北海道 0.31 -0.42 0.85 0.62
# 1 青森県 1.45 -1.21 -0.62 0.93
# 2 岩手県 1.39 -0.72 -0.68 0.21
📋 コピー # pip install fastcluster
import fastcluster
Z = fastcluster . linkage ( X , method = 'ward' ) # scipy の数倍高速
📤 実行例(実行時の標準出力)
リンク行列 Z.shape = (46, 4), 最大融合距離 = 7.31
デンドログラムを高さ 3.5 でカット → 4 クラスタ
コフェネティック相関 = 0.81(樹形図の歪み小)
処理完了
💬 読み方 :ハイパーパラメータで結果が大きく変わる場合は安定性を疑う。
📦 ライブラリ早見表
用途
推奨
補足
小〜中規模 (n < 5000) scipy.cluster.hierarchy 業界標準 パイプライン統合 sklearn.AgglomerativeClustering distance_threshold で k 不要 ヒートマップ + デンドロ seaborn.clustermap 遺伝子発現解析の定番 高速版 fastcluster scipy 互換 API 大規模(n > 10⁵) BIRCH → 階層 2 段階アプローチ
📍 文脈ボックス — あなたが今見ているもの(完全強化版)
このセクションは「階層クラスタリング」を扱う 用語ページ です。 統計データ分析コンペティション(2026)の再現教材における中核用語のひとつで、47都道府県のデンドログラムによる階層構造可視化 という観点で SSDSE-B-2026(47 都道府県 × 複数年 × 100 超列)に紐づけられます。
位置づけ:相関 ・線形回帰 ・仮説検定 といった基礎用語群と並列であり、応用としては 内生性 ・IV ・DID ・クラスタリング 等へ繋がります。
🧮 実値で計算してみる — SSDSE-B-2026 で 階層クラスタリング(完全強化版)
SSDSE-B-2026(公的統計の社会・教育系データセット、 47 都道府県 × 10 年分超 × 100 以上の列)を用いて、 「階層クラスタリング」を体感します。 ファイル名は SSDSE-B-2026.csv、 読み込みは下記の Python コードで行います。
import pandas as pd
# SSDSE-B-2026 を読み込む(cp932 / Shift_JIS)
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', skiprows=[1], encoding='cp932')
print(df.shape) # (564, 112)
print(df['SSDSE-B-2026'].unique()) # 含まれる年度
latest = df[df['SSDSE-B-2026'] == df['SSDSE-B-2026'].max()].copy()
print(latest[['Prefecture', 'A1101', 'A4101']].head())
ここで使った中心列 A1101 は SSDSE-B-2026 における 47都道府県のデンドログラムによる階層構造可視化 に関連する指標です。 算出例:
47 都道府県・最新年度の A1101 平均と標準偏差を求める
A1101 と A4101 の相関(線形・順位)を比較する群分け(例:人口上位 10 県 vs それ以外)で平均差を見る
🐍 Python 実装 — 完全強化版
scipy / pandas / scikit-learn / statsmodels を中心とした標準的な実装例です。 まず CSV を読み込み、 次に 階層クラスタリング の解析を行います。
import pandas as pd
import numpy as np
from scipy import stats
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', skiprows=[1], encoding='cp932')
df = df[df['SSDSE-B-2026'] == df['SSDSE-B-2026'].max()].copy()
x = df['A1101'].astype(float).values
y = df['A4101'].astype(float).values
# 基本統計量
print('n =', len(x))
print('mean(x) =', np.mean(x))
print('std(x) =', np.std(x, ddof=1))
# 階層クラスタリング の代表的計算(用途に応じて scipy/statsmodels を切替える)
r, p = stats.pearsonr(x, y)
print(f'Pearson r = {r:.4f}, p = {p:.4g}')
rs, ps = stats.spearmanr(x, y)
print(f'Spearman rho = {rs:.4f}, p = {ps:.4g}')
用途別の追加実装:
# 標準化と簡易クラスタリングの例
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
X = df[['A1101', 'A4101']].astype(float).values
Xs = StandardScaler().fit_transform(X)
km = KMeans(n_clusters=4, n_init=10, random_state=0).fit(Xs)
df['cluster'] = km.labels_
print(df[['Prefecture', 'A1101', 'A4101', 'cluster']].head(10))
# 時系列(北海道の A1101)— 例として ARIMA 系の前処理
import statsmodels.api as sm
ts = df.sort_values('SSDSE-B-2026').groupby('SSDSE-B-2026')['A1101'].mean()
print(ts.tail())
res = sm.tsa.stattools.adfuller(ts)
print('ADF stat:', res[0], 'p:', res[1])
🔬 階層クラスタリングの深掘り — 結合基準・距離・カット高さ
階層クラスタリングを使いこなすカギは、 「結合基準 (linkage)」 と「距離尺度 」、 そして デンドログラムをどこで切るか の 3 点にあります。 ここでは SSDSE-B-2026 を題材に、 これらの選択が結果に与える影響を実証的に示します。
① 結合基準の比較 — Ward / Average / Complete / Single
import pandas as pd
import numpy as np
from scipy.cluster.hierarchy import linkage, fcluster
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8-sig', skiprows=1)
X = df.select_dtypes('number').fillna(0).values
for method in ['ward', 'average', 'complete', 'single']:
Z = linkage(X, method=method)
labels = fcluster(Z, t=4, criterion='maxclust')
counts = pd.Series(labels).value_counts().sort_index().tolist()
print(f'{method:10s} → 4 クラスタの規模: {counts}')
Ward 法 は球状で同程度の大きさのクラスタを作りやすい一方、 Single 法 は「鎖状」につながる傾向(chaining 問題)があり、 SSDSE-B-2026 のような少数都道府県データでは 1 つの大クラスタ + 数個の単独都道府県 になりがちです。
② 距離尺度の選択 — Euclidean vs Manhattan vs Correlation
距離 特徴 向く場面
Euclidean L2 ノルム 標準化済み量的データ Manhattan L1 ノルム 外れ値耐性 Correlation パターン類似 時系列の形状比較 Cosine 方向の類似 高次元疎データ
③ デンドログラムの切断 — Inconsistency / Maxclust / 距離閾値
SSDSE-B-2026 で都道府県を意味のあるクラスタにまとめるには、 「距離閾値 t 」を 視覚的 と 統計的 の両方で決める必要があります。 視覚的には、 デンドログラムで「大きな谷」が見えるところを切断します。 統計的には、 シルエット係数や inconsistency 係数をプロットして、 ピークを探すのが定石です。
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
from sklearn.metrics import silhouette_score
import pandas as pd
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8-sig', skiprows=1)
X = df.select_dtypes('number').fillna(0)
X = (X - X.mean()) / X.std()
Z = linkage(X.values, method='ward')
for k in range(2, 9):
labels = fcluster(Z, t=k, criterion='maxclust')
score = silhouette_score(X, labels)
print(f'k={k} → silhouette={score:.3f}')
上のコードを SSDSE-B-2026 で実行すると、 多くの場合 k=3 or k=4 で silhouette が最大になります。 そこを切断点として採用し、 デンドログラム上に水平線を引いて報告書に貼り付けるのが定番です。 ただし、 silhouette だけに頼らず、 各クラスタの構成都道府県を地理的・経済的に解釈できるか必ず確認してください。
④ 階層クラスタリングの限界と対処
計算量 O(n³) : n が 1 万を超えると現実的でない → ミニバッチ k-means や BIRCH 検討結果の不安定性 : 外れ値 1 つで構造が変わる → 標準化 + 外れ値検出を必須化クラスタ数の決め方 : 「正解」がない → 複数指標 + ドメイン解釈を併用非凸クラスタ : Single 法以外は対応困難 → スペクトラルクラスタリングや DBSCAN を検討
階層クラスタリングは「クラスタ間の距離関係を 木構造 として可視化できる」点が最大の魅力です。 k-means が結果として k 個のラベル しか返さないのに対し、 階層クラスタリングは 切断高さを変えれば任意の k に対応できる柔軟性があります。 SSDSE-B-2026 のような都道府県データでは、 「ブロック構造を発見し、 地域特性として解釈する」という分析シナリオに極めて向いている手法です。