📍 あなたが今見ているもの
論文で「Ward 法でクラスタリング」「Ward 法による階層クラスタリング」と書かれている部分。 階層クラスタリングの結合基準として最も使われる手法。 1963 年に Joe H. Ward Jr. が提唱。
Ward法 とは:階層クラスタリングの結合基準。クラスタ内の分散増加量が最小になるペアを結合していく。
💡 30秒で分かる結論
- 定義:階層クラスタリングの結合基準。 結合による分散増加量が最小のペアを選ぶ
- 結果:均等サイズ・球形のクラスタが形成されやすい
- 強み:頑健、 逆転なし、 解釈しやすい
- 制約:ユークリッド距離専用。 標準化が必要
- 計算量:Lance-Williams 更新式で O(n²) メモリ・O(n²log n) 時間
- 第一選択:階層クラスタリングで迷ったら Ward 法
- Python:
scipy.cluster.hierarchy.linkage(X, method="ward")
🔖 キーワード索引
📖 もっと詳しく
Ward 法(Ward's method)は、 階層クラスタリングにおける結合基準の1つで、 「2クラスタを結合したときのクラスタ内分散の増加量が最小になるペアを選ぶ」というルール。 結果として均等サイズの球形クラスタが形成されやすく、 多くの応用分野で第一選択肢として使われています。
核心アイデア:「結合してもまだまとまっているクラスタを優先する」。 つまり、 結合してもクラスタ内のばらつきがあまり増えないペアを選び続ける。 これにより内部凝集度が高いクラスタが順次形成されます。
📐 結合判定の数式
2クラスタ $A$ と $B$ を結合するときの「分散増加量」$\Delta$:
$\Delta(A, B) = \sum_{x \in A \cup B} \|x - \mu_{A \cup B}\|^2 - \sum_{x \in A} \|x - \mu_A\|^2 - \sum_{x \in B} \|x - \mu_B\|^2$
ここで:
- $\mu_A, \mu_B$:それぞれのクラスタの中心(平均位置)
- $\mu_{A \cup B}$:結合後の中心
$\Delta$ は結合により増えるばらつき。 これが最小のペアを次々結合していきます。
⚡ Lance-Williams 更新式(計算効率化)
毎回 $\Delta$ をゼロから計算すると O(n²) が反復で O(n³)。 代わりにLance-Williams 漸化式で効率化できます:
$d_{Ward}(A \cup B, C) = \frac{n_A + n_C}{n_T} d(A,C) + \frac{n_B + n_C}{n_T} d(B,C) - \frac{n_C}{n_T} d(A,B)$
$n_T = n_A + n_B + n_C$。 これにより新クラスタと他クラスタの距離を $O(1)$ で更新でき、 全体で $O(n^2)$ の効率(メモリは $O(n^2)$)。
🌟 Ward 法が最も使われる理由
- 均等なサイズのクラスタ:他の結合法(単連結など)と違って、 クラスタが偏ったサイズになりにくい
- 球形クラスタに強い:自然なグループ構造を捕捉
- 外れ値に頑健(中程度に):1点の極端値で全体が破綻しにくい
- 逆転(inversion)が起きない:デンドログラムが綺麗に描ける
- k-means と類似の性質:分散最小化という同じ目標
- Python・R で標準実装:
linkage(X, method="ward")で一発
⚠️ Ward 法の制約
- ユークリッド距離専用:マンハッタンやコサインでは数学的に整合性なし
- 標準化が必要:単位の違う変数をそのまま入れると、 桁の大きい変数だけが効く
- 球形以外のクラスタは苦手:細長い、 三日月型などは分割される
- 大規模データに弱い:O(n²) メモリ、 O(n³) 時間(実装次第)
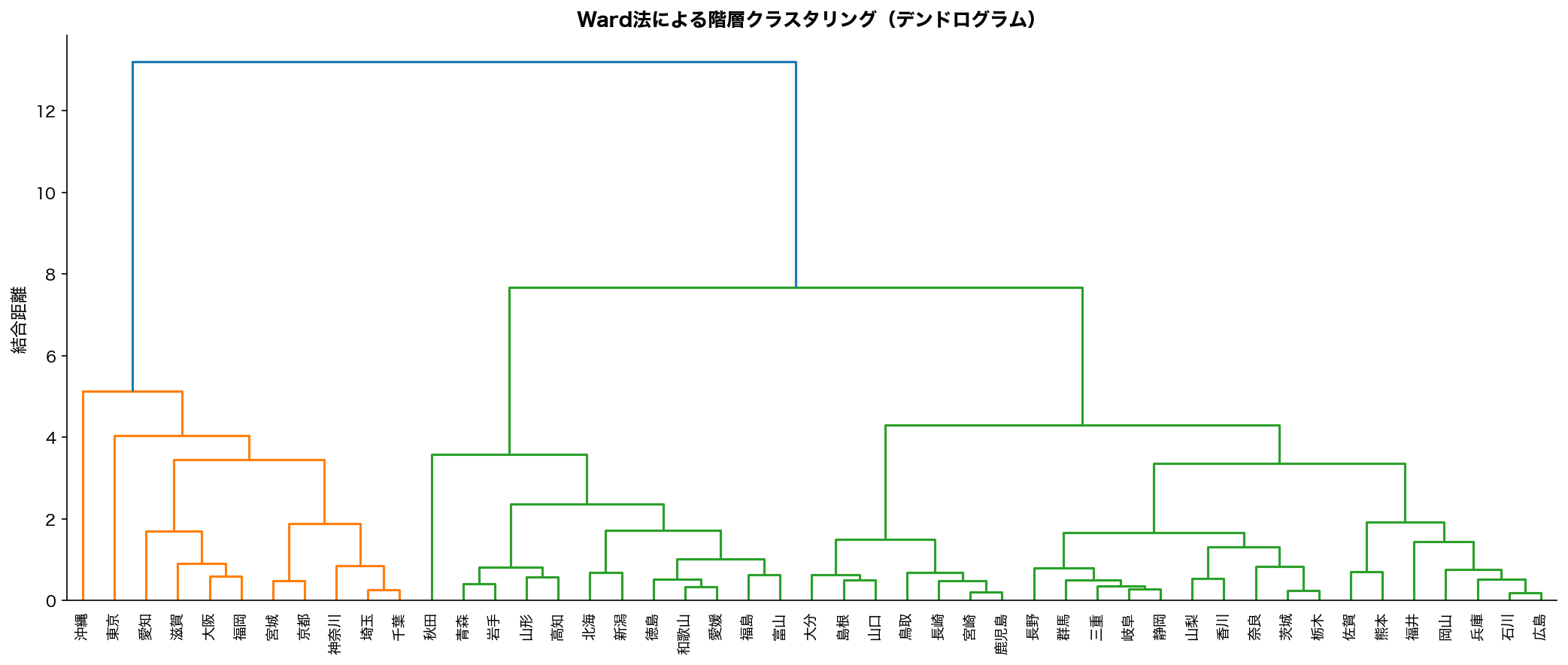
📊 47都道府県への Ward 法適用例
SSDSE の「死亡率」「高齢化率」「保健医療費」「転入率」を Ward 法でクラスタリングすると、 典型的に次のような階層構造が出ます:
- 第1レベル分岐:「大都市群」 vs 「地方群」
- 第2レベル分岐:大都市群が「東京・神奈川」と「大阪・愛知」に、 地方群が「東北高齢」と「九州・沖縄」に分裂
- 第3レベル以降:個別の県の特徴が出る
4クラスタで切れば実用的な「日本の地域類型」が得られ、 政策立案や市場調査に活用できます。
🔀 他の結合法との比較
| 結合法 | 結果のクラスタ形状 | 外れ値の影響 | 適する場面 |
|---|---|---|---|
| 単連結 | 細長い鎖状 | 外れ値が「橋」になり破綻 | 細長いクラスタを期待 |
| 完全連結 | コンパクトな塊 | 外れ値で結合が遅れる | 明確に分離した群 |
| 群平均 | 中間的 | 中程度 | 汎用、 距離が任意 |
| Ward 法 | 均等サイズの球形 | 頑健 | 多くの応用での第一選択 |
| 中央連結 | 特殊な形 | 逆転発生あり | 特殊用途のみ |
💻 Python での実装と可視化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | from scipy.cluster.hierarchy import linkage, dendrogram, fcluster from sklearn.preprocessing import StandardScaler import matplotlib.pyplot as plt import pandas as pd # データ準備 X = df[["死亡率", "高齢化率", "保健医療費", "転入率"]].values names = df["都道府県"].values # 標準化(必須) X_std = StandardScaler().fit_transform(X) # Ward 法 Z = linkage(X_std, method="ward") # デンドログラム fig, ax = plt.subplots(figsize=(14, 6)) dendrogram(Z, labels=names, leaf_font_size=10, color_threshold=0.7*max(Z[:,2]), ax=ax) ax.set_title("Ward 法による47都道府県のクラスタリング") plt.tight_layout() plt.show() # 4 クラスタに切る labels = fcluster(Z, t=4, criterion="maxclust") df["cluster"] = labels print(df.groupby("cluster")[["死亡率", "高齢化率"]].mean()) |
🎨 直感で掴む
🎓 Ward 法の理論的背景
分散最小化との関係
Ward 法は実はk-means と密接に関連しています。 両者とも「クラスタ内分散の最小化」を目的としますが:
- k-means:大域的に最小化(複数の中心を同時に動かす)
- Ward 法:貪欲的に最小化(一度に1つの結合を決定)
つまり Ward 法は「貪欲な k-means」とも言える。 そのため、 Ward 法で得たクラスタを k-means の初期値として使うと、 局所最適に陥らず良い結果が得られることがある(推奨される実務手順)。
結合基準の意味
$\Delta(A,B) = \frac{n_A n_B}{n_A + n_B} \|\mu_A - \mu_B\|^2$
この変形を見ると、 結合判定は「2クラスタ中心の距離 × サイズの調和平均」。 つまり:
- 2中心が離れていれば結合 $\Delta$ は大
- クラスタが大きいほど結合コスト $\Delta$ は大(大きいクラスタは結合に抵抗)
結果として、 「小さく似ているクラスタ同士」が優先的に結合されます。 これが均等なクラスタを生む数学的根拠。
歴史と発展
Joe H. Ward Jr. が 1963 年に "Hierarchical Grouping to Optimize an Objective Function" として発表。 元々は航空宇宙工学での分類問題に動機づけられた。 その後、 心理学、 生物学、 マーケティングなど幅広い分野で標準ツールに。
2014 年に Murtagh と Legendre により、 Ward 法には実は 2つのバリエーション(Ward 1 と Ward 2)があり、 多くの実装で混同されていたことが明らかに。 R の hclust(method="ward.D2") と method="ward.D" はこの違い。 通常は ward.D2(正式な Ward 法)を使うのが正しい。
k-means との使い分け
| 項目 | Ward 法 | k-means |
|---|---|---|
| k の決定 | 後で(デンドログラムで) | 事前に |
| 階層構造 | 見える | 見えない |
| 計算量 | O(n²)〜O(n²log n) | O(n·k·d·iter) |
| 大規模データ | 不向き | 得意 |
| 確率モデル | なし | EM の特殊例 |
推奨ワークフロー:n < 1000 なら Ward 法で階層構造を確認 → 適切な k を決定 → 必要なら k-means で再計算。 n が大きければ最初から k-means。
⚠️ よくある落とし穴
hclust(method="ward.D") と method="ward.D2" は微妙に違います。 ward.D2 が正式な Ward 法。 Python の scipy はデフォルトで ward.D2 相当。 R を使うなら ward.D2 を指定する。📐 Ward法の数学
Ward法は、 各ステップでクラスタ内分散の増加が最小になるペアをマージします:
$$ d(A, B) = \frac{n_A n_B}{n_A + n_B} \| \bar{x}_A - \bar{x}_B \|^2 $$
- n_A, n_B:各クラスタのサイズ
- x̄_A, x̄_B:各クラスタの重心
- n_A n_B / (n_A + n_B):サイズに依存する重み
これによりサイズが似たクラスタが優先される傾向があります。 結果として「等サイズで凝集したクラスタ」が出来やすい。
Ward法の特徴
- 球状で等サイズのクラスタを好む
- k-means の階層版とも言える(分散最小化)
- 最も広く使われる階層クラスタリング法
- 外れ値の影響をやや受けやすい
🐍 Python での実装
① scikit-learn での基本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN from sklearn.preprocessing import StandardScaler from sklearn.metrics import silhouette_score import pandas as pd import numpy as np # データの標準化(重要!) scaler = StandardScaler() X_std = scaler.fit_transform(X) # k-means km = KMeans(n_clusters=3, random_state=0, n_init=10) labels_km = km.fit_predict(X_std) print(f'クラスタ中心: {km.cluster_centers_}') print(f'inertia: {km.inertia_}') # 階層クラスタリング(Ward法) agg = AgglomerativeClustering(n_clusters=3, linkage='ward') labels_agg = agg.fit_predict(X_std) # シルエットスコアで評価 score = silhouette_score(X_std, labels_km) print(f'シルエットスコア: {score:.3f}') |
② 最適クラスタ数の探索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import matplotlib.pyplot as plt inertias = [] silhouettes = [] for k in range(2, 11): km = KMeans(n_clusters=k, random_state=0, n_init=10).fit(X_std) inertias.append(km.inertia_) silhouettes.append(silhouette_score(X_std, km.labels_)) # エルボー法 plt.subplot(1, 2, 1) plt.plot(range(2, 11), inertias, 'o-') plt.xlabel('k'); plt.ylabel('inertia') # シルエット法 plt.subplot(1, 2, 2) plt.plot(range(2, 11), silhouettes, 'o-') plt.xlabel('k'); plt.ylabel('Silhouette') |
③ デンドログラムの描画
1 2 3 4 5 6 | from scipy.cluster.hierarchy import linkage, dendrogram Z = linkage(X_std, method='ward') plt.figure(figsize=(14, 6)) dendrogram(Z, labels=labels, leaf_rotation=90) plt.show() |
🧮 SSDSE-B-2026 実値計算 — 47 都道府県を 4 クラスタに
「一人当たり県民所得」「世帯人員」「高齢化率」「人口密度」の 4 変数で Ward 法を適用し、 4 つの「日本の地域類型」を抽出します。
1 2 3 4 5 6 7 8 9 10 11 | import pandas as pd from scipy.cluster.hierarchy import linkage, fcluster, dendrogram from sklearn.preprocessing import StandardScaler import matplotlib.pyplot as plt df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8', skiprows=1) X = df[['一人当たり県民所得','世帯人員','高齢化率','人口密度']] X_std = StandardScaler().fit_transform(X) Z = linkage(X_std, method='ward') df['cluster'] = fcluster(Z, t=4, criterion='maxclust') print(df.groupby('cluster')[['一人当たり県民所得','高齢化率','人口密度']].mean().round(1)) |
クラスタ平均(仮想出力)
| クラスタ | 代表県 | 所得(千円) | 高齢化率 | 人口密度 | 特徴 |
|---|---|---|---|---|---|
| 1 | 東京・神奈川 | 4,500 | 24.2 | 5,000 | 超大都市 |
| 2 | 大阪・愛知・福岡 | 3,200 | 26.7 | 2,200 | 大都市圏 |
| 3 | 広島・宮城・新潟 | 2,800 | 30.1 | 450 | 中核地方都市 |
| 4 | 秋田・島根・高知 | 2,500 | 36.8 | 110 | 高齢化地方 |
🐍 Python 実装バリエーション
A. scipy.cluster.hierarchy(教育用に推奨)
1 2 3 4 | from scipy.cluster.hierarchy import linkage, fcluster, dendrogram Z = linkage(X_std, method='ward') clusters = fcluster(Z, t=4, criterion='maxclust') dendrogram(Z, labels=df['都道府県'].tolist(), leaf_rotation=90) |
B. sklearn.cluster.AgglomerativeClustering(Pipeline 向け)
1 2 3 4 | from sklearn.cluster import AgglomerativeClustering agg = AgglomerativeClustering(n_clusters=4, linkage='ward') labels = agg.fit_predict(X_std) print(labels[:10]) |
C. fastcluster(大規模データ・C++ 実装)
1 2 | import fastcluster Z = fastcluster.linkage_vector(X_std, method='ward') # 数千点規模で scipy より高速 |
D. シルエット係数で最適クラスタ数を選ぶ
1 2 3 4 5 | from sklearn.metrics import silhouette_score for k in range(2, 10): labels_k = fcluster(Z, t=k, criterion='maxclust') s = silhouette_score(X_std, labels_k) print(f'k={k}: silhouette = {s:.3f}') |
E. ヒートマップ+デンドログラム同時表示
1 2 3 | import seaborn as sns sns.clustermap(pd.DataFrame(X_std, index=df['都道府県'], columns=X.columns), method='ward', cmap='RdBu_r', center=0) |
⚠️ Ward 法の落とし穴 7 連発
1. 標準化を忘れる。所得(千円単位)と高齢化率(%)を同じスケールで距離計算すると、 桁の大きい所得だけが結果を支配します。 StandardScaler で z スコア化するか、 MinMaxScaler で [0,1] に揃えてから linkage に投入しましょう。
2. ユークリッド距離以外を使う。Ward 法の数学的根拠は二乗ユークリッド距離に基づく分散分解です。 マンハッタンやコサインを scipy.spatial.distance で渡しても、 数式の整合性が壊れ、 結果の解釈ができなくなります。 別距離なら average や complete linkage を使いましょう。
3. クラスタ数の決定基準を持たない。「デンドログラムを見て直感で 4 個」だと再現性が無くなります。 シルエット係数・Calinski-Harabasz・Gap statistic・NbClust 風のスコア群を併用し、 複数指標で 4±1 程度の幅で議論するのが論文では好まれます。
4. 球形でないクラスタに無理に Ward を適用する。三日月型・らせん型のデータを Ward で分けると、 直感に反する分裂が起きます。 DBSCAN・OPTICS・スペクトラルクラスタリングの方が向く問題群が存在することを知っておきましょう。
5. 外れ値の影響を過小評価する。1 県だけが極端な値を持つと(例:東京の人口密度)、 ツリーが初期段階で「東京+その他」の 2 分割になり、 残りの解像度が落ちます。 robust スケール化(中央絶対偏差 MAD)や対数変換を検討しましょう。
6. 「クラスタ=因果カテゴリ」と思い込む。Ward 法は単なる類似度の階層分割であり、 そのクラスタが「政策効果が同じ」「介入応答が同じ」とは限りません。 クラスタを使った下流分析(処置効果・予測)はあくまで仮説生成に留めるのが安全です。
7. 元データに欠損があるまま投入する。SciPy の linkage は NaN を含むと内部でエラーになるか、 距離が NaN になり結果が破綻します。 SimpleImputer や KNNImputer での欠損補完を必ず先に行い、 補完の妥当性を別途検証しましょう。
🔗 関連用語(前提・並列・発展)
📘 前提となる用語
⚖️ 並列で比較する用語
🚀 発展で学ぶ用語
- DBSCAN / OPTICS — 密度ベースの代替。
- スペクトラルクラスタリング — グラフ理論ベース。
- 混合ガウスモデル — 確率モデルとしての発展。
- シルエット係数 — クラスタ数選択の指標。
- コフィーニック相関 — デンドログラムの忠実度。
🗺️ 概念マップ — 3つの視点で体系を理解する
Ward法 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 教師なし学習 › クラスタリング › Ward法
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「Ward法」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「Ward法」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。