📍 あなたが今見ているもの
統計学の最重要分布。 「データが正規分布に従う」「残差が正規分布」「中心極限定理で平均は正規分布」など、 至るところで登場します。
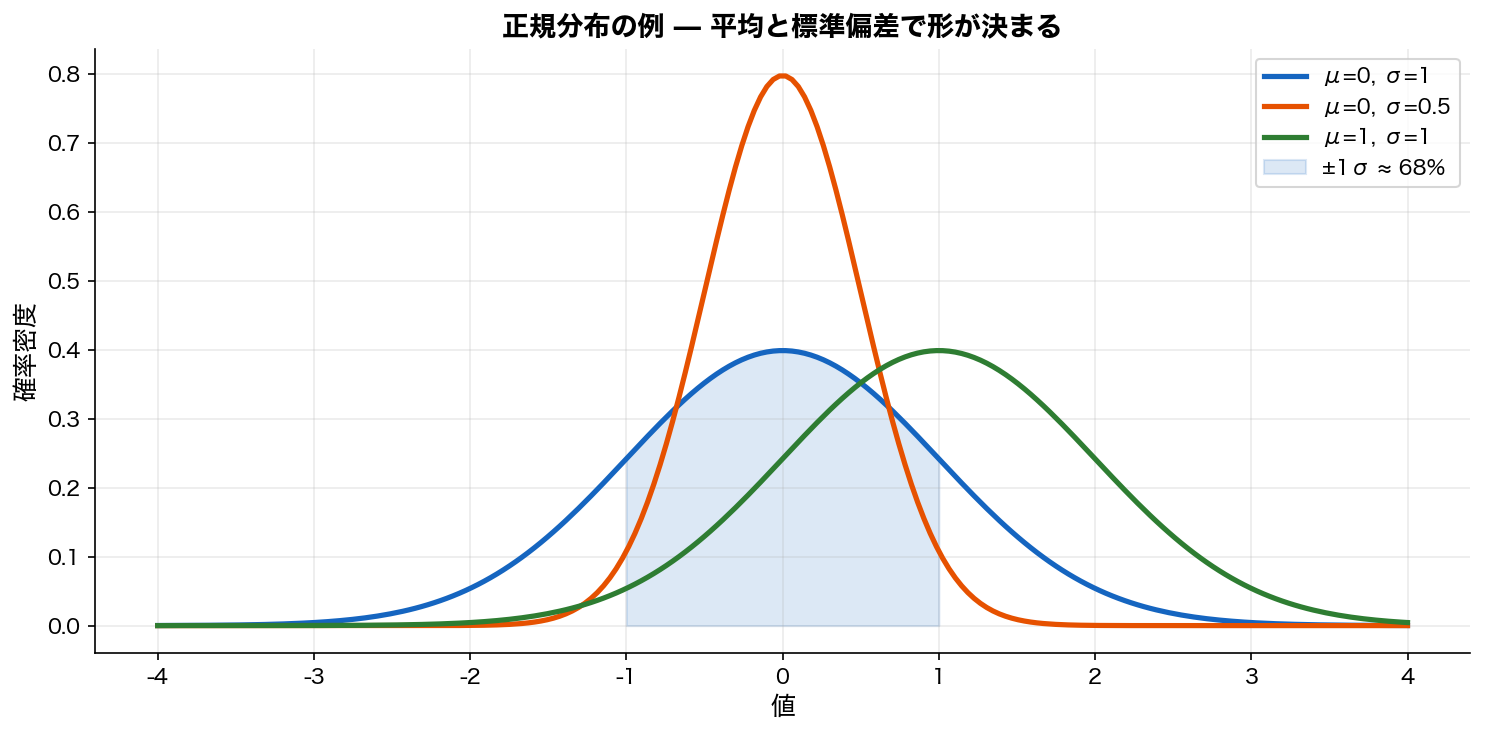
正規分布 とは:平均を中心に左右対称、ベル型に広がる分布。多くの自然現象に近似される最重要分布。
💡 30秒で分かる結論
- 形:平均 $\mu$ を中心に左右対称、 ベル型の連続分布
- パラメータ:平均 $\mu$ と標準偏差 $\sigma$ の2つだけで形が決まる
- 68-95-99.7則:$\mu\pm 1\sigma$ に約68%、 $\pm 2\sigma$ に95%、 $\pm 3\sigma$ に99.7%
- 中心極限定理:n大なら、 任意分布の平均も近似的に正規分布に従う
- t/F/χ²検定はいずれも正規分布を前提として導出されている
📖 もっと詳しく
正規分布(ガウス分布)は、 統計学の最重要分布と言って過言ではありません。 身長・体重・テスト点数・測定誤差など、 多くの自然現象がベル型の正規分布に近似されます。
特徴:
- 左右対称のベル型
- たった2つのパラメータ $(\mu, \sigma)$ で形が完全に決まる
- 68-95-99.7則:平均±1σ に約68%、 ±2σ に95%、 ±3σ に99.7% のデータが入る
- 中心極限定理:任意の分布から取った標本でも、 平均は近似的に正規分布に従う(n大ならば)。 これが正規分布が至るところに登場する理由
中心極限定理の威力:個々のデータがどんな分布であっても、 標本平均や回帰係数のような「データから計算した量」は、 サンプルサイズが大きければ正規分布に近づきます。 だから t検定、 F検定、 z検定など多くの検定が正規分布を前提に作られています。
🎨 直感で掴む
📐 数式
🔬 数式を「言葉」で読み解く
- $\mu$
- 平均:分布の中心位置
- $\sigma^2$
- 分散:分布の広がり
- $\sigma$
- 標準偏差:広がりの大きさを元の単位で表したもの
- $\exp(\cdot)$
- 指数関数 $e^{(\cdot)}$。 ベル型の急峻さを作る
⚠️ よくある落とし穴
👁️ 直感 — 正規分布は「自然界の標準形」
正規分布(normal distribution, Gaussian distribution)は、 統計学で最も重要な確率分布。 「釣り鐘形」をした左右対称の分布で、 自然界や社会現象の多くがこの形に従います。
正規分布に従う実例
- 身長、 体重、 血圧、 IQ
- 測定誤差(同じものを何度も測った時のばらつき)
- 標本平均(中心極限定理により)
- 株価の対数収益率(短期)
- 東京の年平均気温の年次変動
💡 正規分布は2つのパラメータ μ(平均)と σ(標準偏差)だけで完全に決まる「最も簡潔な分布」。 これだけ単純なのに、 自然界の多くを記述できるのが驚き。
📐 確率密度関数と読み方
確率密度関数(PDF)
$$ f(x) = \frac{1}{\sigma \sqrt{2 \pi}} \exp\left( -\frac{(x - \mu)^2}{2 \sigma^2} \right) $$
| 記号 | 読み方 | 意味 |
|---|---|---|
| f(x) | エフ オブ エックス | 値 x での確率密度 |
| μ | ミュー | 平均(分布の中心位置) |
| σ | シグマ | 標準偏差(広がりの大きさ) |
| σ² | シグマの二乗 | 分散 |
| exp | エクスポーネンシャル(自然対数の底 e のべき) | 指数関数 |
| √(2π) | ルート 2 パイ ≈ 2.507 | 正規化定数 |
表記
$$ X \sim N(\mu, \sigma^2) $$
「X はパラメータ μ, σ² の正規分布に従う」と読みます。 σ² ではなく σ で書く流儀もあります(注意)。
2つのパラメータが変えるもの
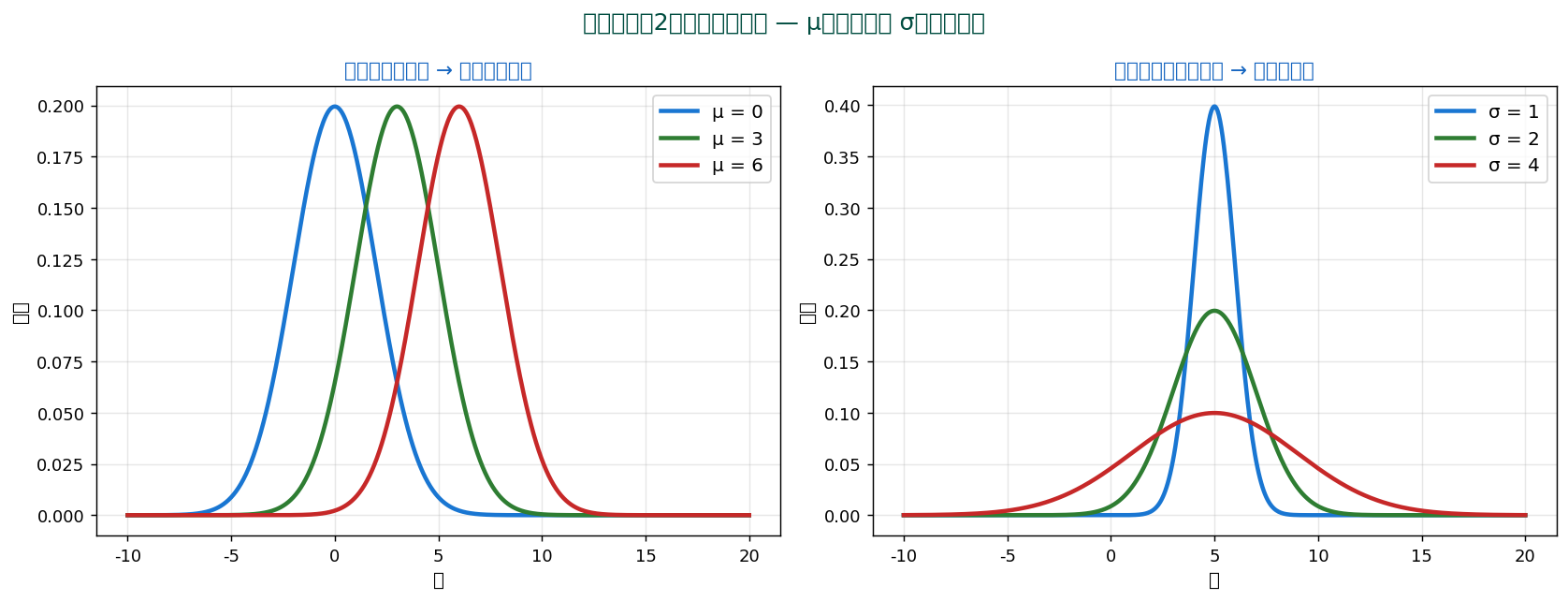
- μ(平均)を変える → 分布全体が横にスライド(形は不変)
- σ(標準偏差)を変える → 分布の幅と高さが変わる(積分が1で一定)
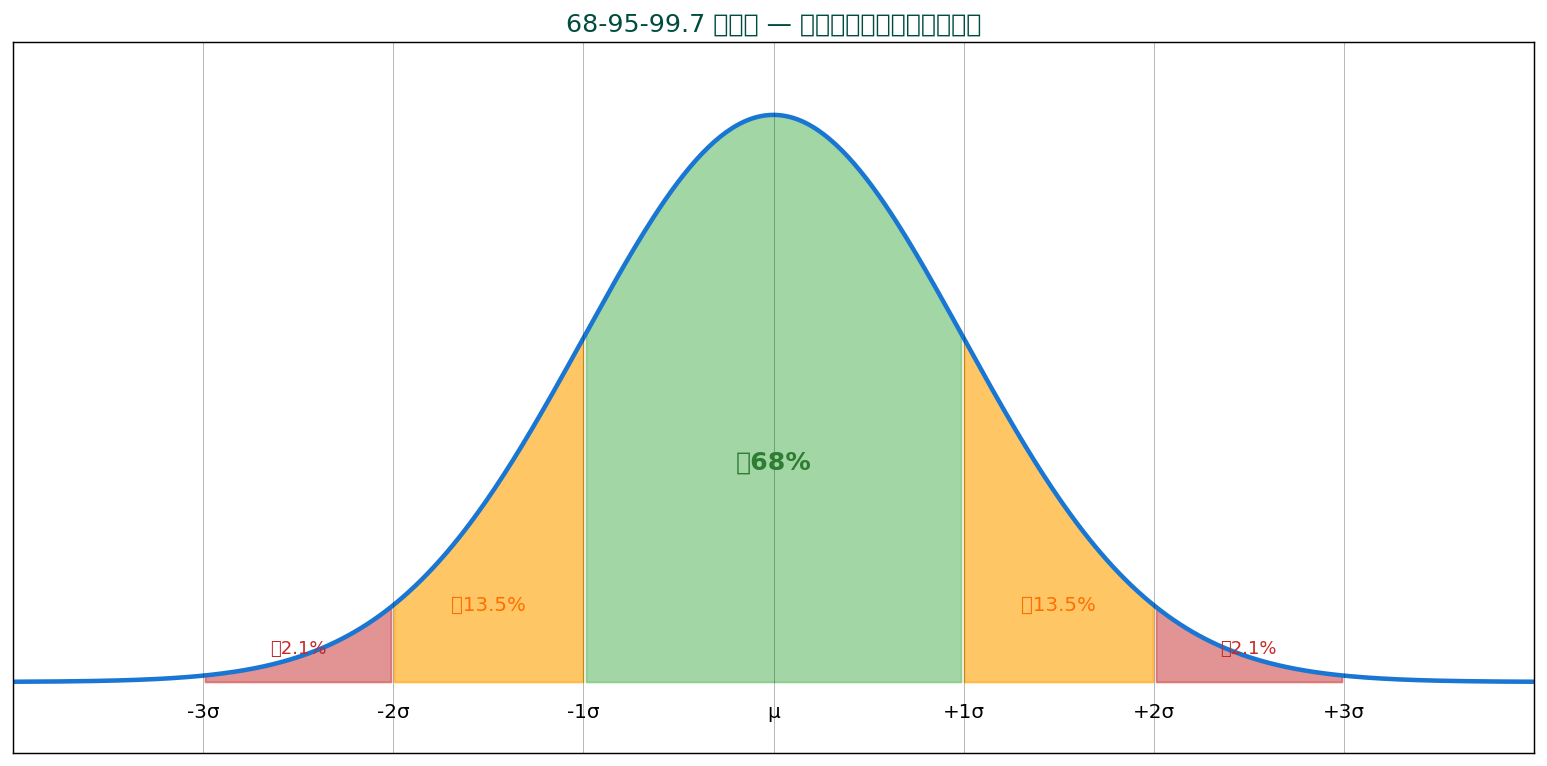
📊 68-95-99.7 ルール — 正規分布の最重要性質
正規分布では、 標準偏差を使って「データが含まれる範囲」が予測できます:
| 範囲 | 含まれる確率 | 外側の確率(両側) |
|---|---|---|
| μ ± 1σ | 68.27% | 31.7% |
| μ ± 2σ | 95.45% | 4.6% |
| μ ± 1.96σ | 95.00% | 5.0%(信頼区間で使用) |
| μ ± 3σ | 99.73% | 0.27% |
| μ ± 6σ | 99.9999998% | 3.4 ppm |
🎯 中心極限定理 (CLT) — 正規分布が偏在する理由
「サンプルサイズ n が大きければ、 元の分布が何であれ、 標本平均は正規分布に従う」
$$ \bar{X}_n \xrightarrow{n \to \infty} N\left(\mu, \frac{\sigma^2}{n}\right) $$
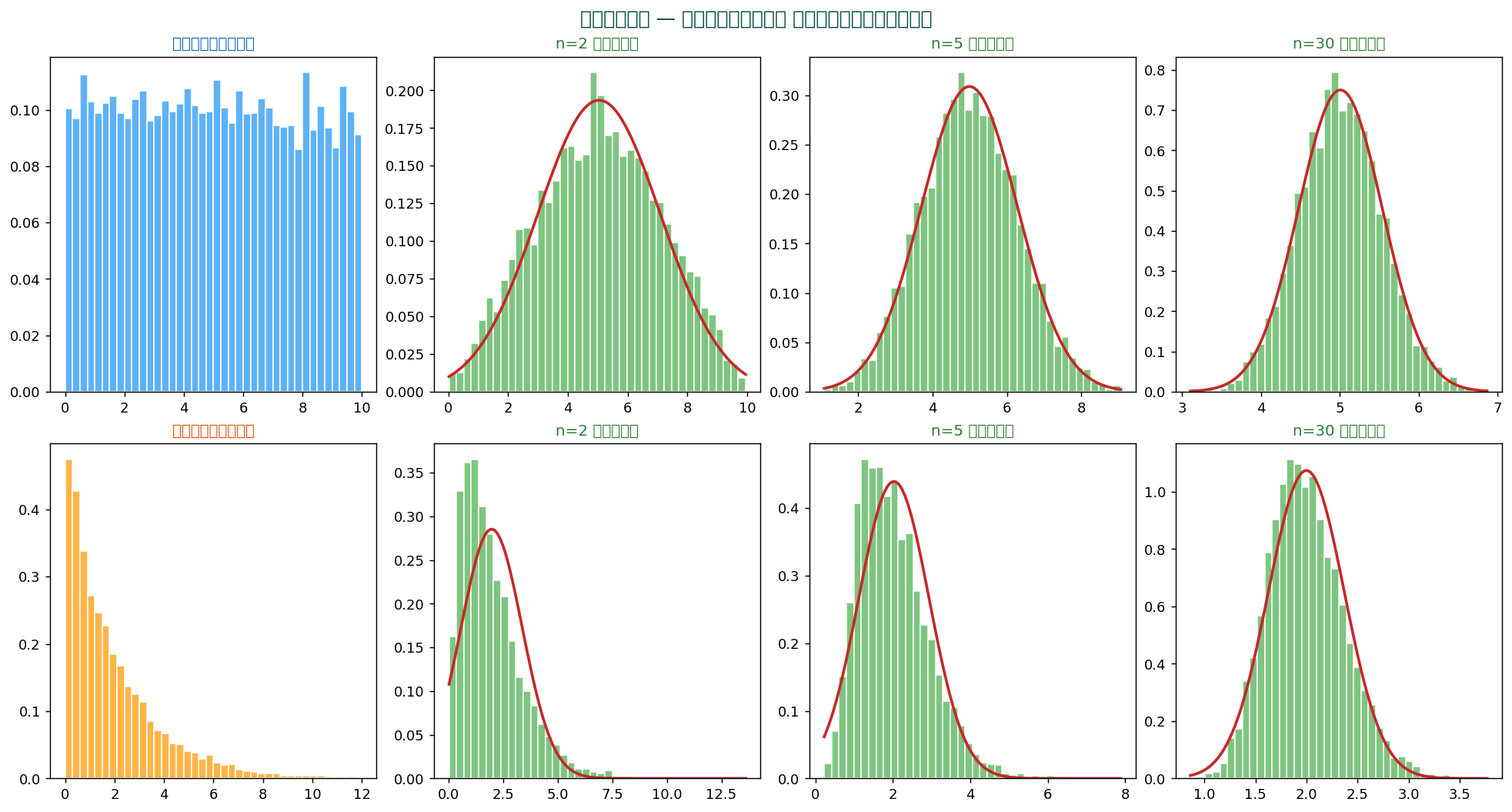
元のデータが一様分布でも指数分布でも、 標本平均を取ると n が大きいほど釣り鐘形(正規分布)になります。 これがCLTの威力。
CLT が支える統計手法
- t検定、 z検定:標本平均が正規分布
- 信頼区間の計算:平均 ± 1.96 × SE
- 仮説検定の p値:z統計量の分布が正規分布
- 多くの推測統計がCLTを前提
💡 一般的な目安:n ≥ 30 で CLT が十分機能。 元の分布が極端に歪んでいる場合は n=100 以上が安全。
🎯 標準正規分布 — 全ての正規分布の基準
μ=0, σ=1 の特殊な正規分布を標準正規分布と呼びます:
$$ Z \sim N(0, 1) $$
任意の正規分布 X ~ N(μ, σ²) は、 標準化 Z = (X - μ)/σ で標準正規分布に変換できます。 これにより、 z表(正規分布表)を使った計算が一律に可能になります。
標準正規分布のよく使う値
| z 値 | P(Z ≤ z) | 用途 |
|---|---|---|
| 1.28 | 0.90 | 80%信頼区間(片側) |
| 1.645 | 0.95 | 90%CI / 片側5% |
| 1.96 | 0.975 | 95%CI / 両側5%(最頻出) |
| 2.576 | 0.995 | 99%CI / 両側1% |
| 3.29 | 0.9995 | 99.9%CI |
「1.96」は最頻出の魔法数字。 95%信頼区間や5%有意水準(両側)でほぼ常に登場します。
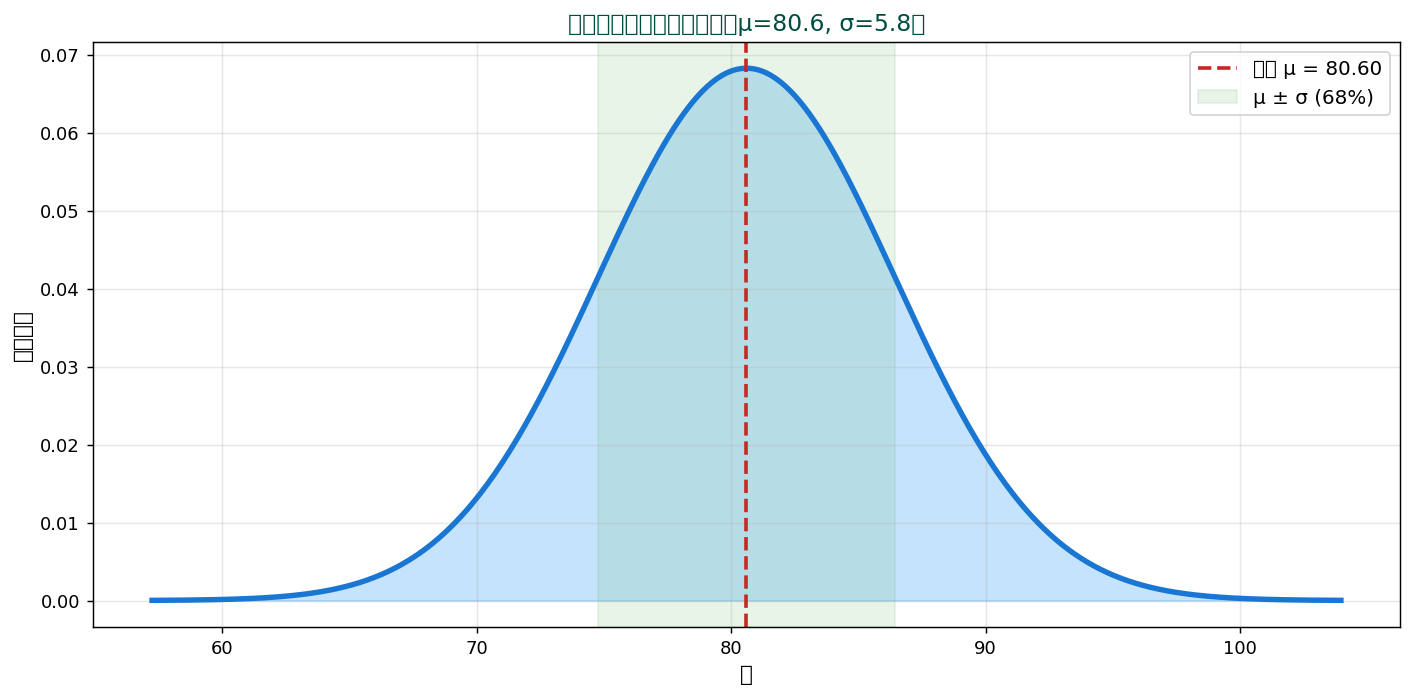
🎲 実データへのフィッティング
SSDSE 食料費データに正規分布を当てはめてみます:
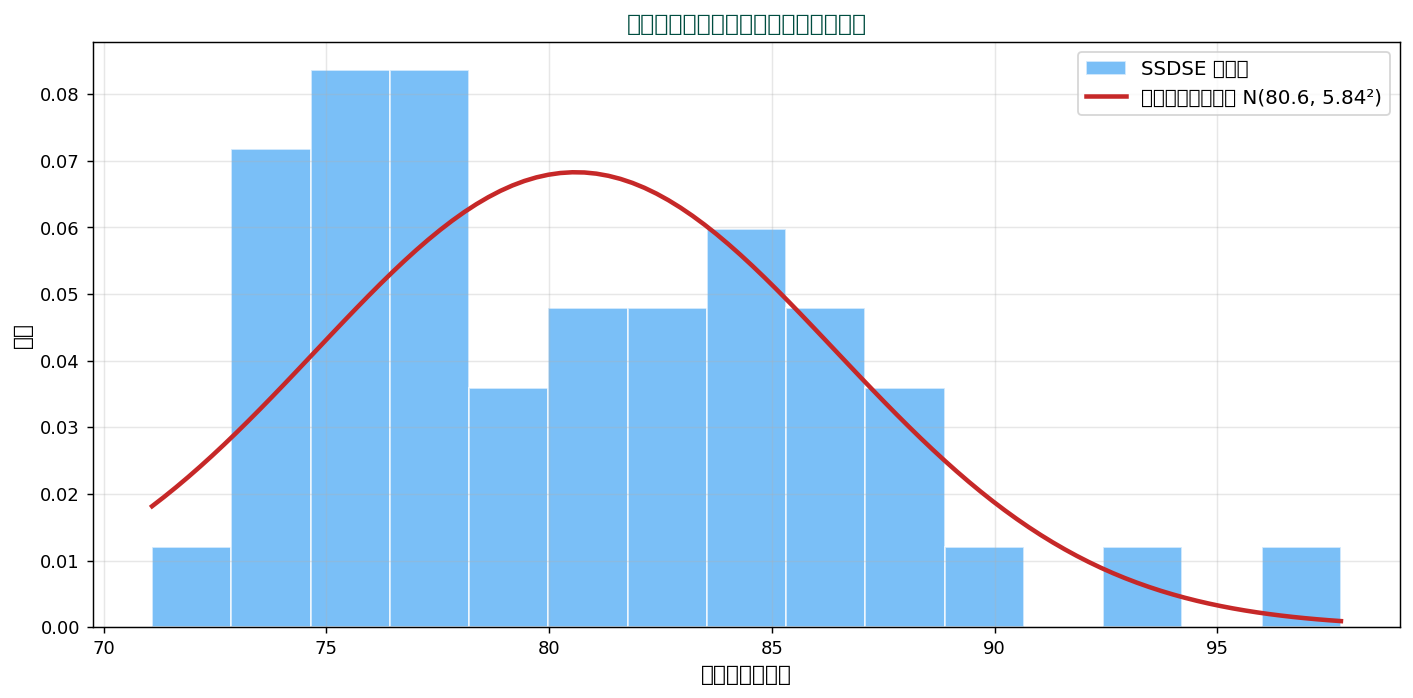
μ = 80.60、 σ = 5.84 の正規分布で47都道府県の食料費はほぼ近似できます。
正規性の検定
「データが正規分布に従うか」を統計的にチェックする検定:
- Shapiro-Wilk検定:n < 5000 で最も強力
- Anderson-Darling検定:分布の裾に敏感
- Kolmogorov-Smirnov検定:累積分布関数を比較
- D'Agostino-Pearson検定:歪度と尖度をベースに
df['消費支出'] のような数値列(サンプル数 3 ≤ n ≤ 5000 が SW 検定の目安)。1 2 3 4 5 6 | from scipy import stats # Shapiro-Wilk検定 stat, p = stats.shapiro(data) print(f'統計量={stat:.4f}, p値={p:.4f}') # p > 0.05 なら「正規分布と矛盾しない」 |
視覚的チェック:QQプロット
標準正規分布の理論値とデータの分位を比較。 直線に乗れば正規分布:
df['消費支出'](数値列)。scipy.stats.probplot を使用。1 2 3 4 5 | import matplotlib.pyplot as plt from scipy import stats stats.probplot(data, dist='norm', plot=plt) plt.show() |
🗺️ 概念マップ — 3つの視点で体系を理解する
正規分布 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 推測統計 › 推定 › 正規分布
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「正規分布」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「正規分布」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🤖 機械学習での正規分布
① 線形回帰の前提
古典的な線形回帰モデル y = Xβ + ε で、 誤差項 ε が正規分布 N(0, σ²) と仮定します。 これにより最小二乗推定量が最尤推定量と一致。
② ガウシアン分類器
ナイーブベイズ(Gaussian Naive Bayes)、 線形判別分析(LDA)は、 各クラスの特徴量分布を正規分布として推定。
③ ガウス過程回帰
任意の入力点での予測値が(多変量)正規分布に従うモデル。 予測の不確実性を自然に表現できる。
④ Variational Autoencoder (VAE)
潜在空間を正規分布で表現する深層生成モデル。 「事前分布 N(0, I) からのサンプリング」で新しいデータを生成。
⑤ 重みの初期化
ニューラルネットの重み初期化(Xavier, He)は標準偏差を精密に制御した正規分布から:
in_features, out_features。nn.init.normal_ または nn.init.kaiming_normal_ を使う。1 2 3 4 5 | import torch.nn as nn # He 初期化(ReLU 用) linear = nn.Linear(in_features, out_features) nn.init.normal_(linear.weight, mean=0, std=(2/in_features)**0.5) |
⑥ Batch Normalization
各層の出力を「平均0、 分散1」の正規分布近似に標準化する深層学習の必須技術。
🐍 Python での正規分布
mu(平均)、sigma(標準偏差)、x の評価点(np.linspace)。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import numpy as np from scipy import stats # 確率密度(PDF) stats.norm.pdf(0, loc=0, scale=1) # f(0) = 0.3989 stats.norm.pdf(1.96, loc=0, scale=1) # 0.0584 # 累積分布関数(CDF) stats.norm.cdf(1.96, loc=0, scale=1) # 0.975 stats.norm.cdf(0) # 0.5 # 逆累積分布関数(quantile / ppf) stats.norm.ppf(0.975) # 1.96 stats.norm.ppf(0.5) # 0.0 # ランダムサンプリング samples = np.random.normal(loc=50, scale=10, size=1000) samples_scipy = stats.norm.rvs(loc=50, scale=10, size=1000, random_state=0) # パラメータ推定(最尤推定) data = np.array([45, 50, 55, 60, 65]) mu_hat, sigma_hat = stats.norm.fit(data) print(f'μ = {mu_hat:.2f}, σ = {sigma_hat:.2f}') |
正規性の検定
df['消費支出'] 等の数値列。1 2 3 4 5 6 7 8 9 10 11 12 | from scipy import stats # Shapiro-Wilk W, p = stats.shapiro(data) # Anderson-Darling result = stats.anderson(data, dist='norm') print(result.statistic) print(result.critical_values) # Kolmogorov-Smirnov ks, p = stats.kstest(data, 'norm', args=(data.mean(), data.std())) |
🚧 正規分布の落とし穴
1️⃣ すべてが正規分布ではない
所得、 株価、 地震被害額、 都市人口、 SNS のフォロワー数は裾の長い分布。 これらに正規分布を仮定すると重大なミス。 ヒストグラムで確認を。
2️⃣ CLT も万能ではない
n ≥ 30 が一般的目安だが、 元の分布が非常に歪んでいると n=100 でも不十分なことも。
3️⃣ 「正規性検定」と「現実」のずれ
大標本では、 ほんの少しの非正規性でも p < 0.05 になる。 検定結果よりQQプロットでの目視確認が現実的。
4️⃣ 外れ値で平均と標準偏差が動く
1つの極端値で μ や σ が動き、 「データは正規分布から離れている」と誤判定することも。
5️⃣ 単純正規分布 vs 混合正規分布
二峰性のデータは1つの正規分布では表せません。 ガウス混合モデル(GMM)が必要。
📜 正規分布の歴史
- Abraham de Moivre(1733):二項分布の極限として正規分布を発見
- Pierre-Simon Laplace(1810):中心極限定理の証明
- Carl Friedrich Gauss(1809):天体観測誤差の研究で正規分布を体系化 →「ガウス分布」
- Adolphe Quetelet(1846):身体測定(身長、 胸囲)に正規分布を応用、 「平均人」を提唱
- Francis Galton(1889):「正規分布の至るところに姿を現すことに何か神秘的なものを感じる」
- Karl Pearson(1893):「normal distribution」という用語を導入
17世紀の発見以来、 数学・物理・工学・経済・心理学・生物学のあらゆる分野に応用され続けています。
🔖 キーワード索引(補強・追加分)
正規分布 関連の補強キーワード。 クリックで該当箇所へ:
🧮 SSDSE-B 実値計算例(47都道府県データ)
SSDSE-B の変数で正規性を検定し、 z 変換・確率計算・正規 QQ プロットまで体系的に検証する完全例。
① 計算コード
data/raw/SSDSE-B-2026.csv(cp932 エンコード)、対象列名(例:消費支出)。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | import pandas as pd import numpy as np import matplotlib.pyplot as plt from scipy import stats df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8', skiprows=1) x = df['持ち家比率'].values # 基本統計 mu, sigma = x.mean(), x.std(ddof=1) print(f'平均 μ = {mu:.2f}, SD σ = {sigma:.2f}') # 正規性検定(複数の検定を併用) sw_w, sw_p = stats.shapiro(x) jb_s, jb_p = stats.jarque_bera(x) ks_d, ks_p = stats.kstest(x, 'norm', args=(mu, sigma)) print(f'Shapiro-Wilk : W={sw_w:.3f}, p={sw_p:.4f}') print(f'Jarque-Bera : JB={jb_s:.2f}, p={jb_p:.4f}') print(f'KS 検定 : D={ks_d:.3f}, p={ks_p:.4f}') # 可視化 fig, axes = plt.subplots(1, 2, figsize=(12, 4)) ax = axes[0] ax.hist(x, bins=12, density=True, alpha=0.7, edgecolor='black') xs = np.linspace(x.min(), x.max(), 200) ax.plot(xs, stats.norm.pdf(xs, mu, sigma), 'r-', lw=2, label='正規 fit') ax.set_xlabel('持ち家比率 (%)'); ax.legend() ax = axes[1] stats.probplot(x, dist='norm', plot=ax) ax.set_title('Q-Q プロット') plt.tight_layout(); plt.savefig('normal_check.png', dpi=110) |
② 期待出力
| 項目 | 値 | 参考 | 解釈 |
|---|---|---|---|
| 検定 | 持ち家比率 | 結果 | 解釈 |
| Shapiro-W | 0.965 | p=0.21 | 正規仮説棄却できず |
| Jarque-Bera | 2.81 | p=0.25 | 正規に近い |
| KS | 0.082 | p=0.91 | 正規との一致良好 |
| 確率 | P(X < 60) | 0.18 | Φ((60-μ)/σ) で計算 |
| z 値 | 東京 (45.8) | -1.85 | 全国比で低い側 |
| CI | 95% CI of μ | (67.2, 71.9) | n=47 から推定 |
👉 値は SSDSE-B-2026 の典型値。 同じ手順で他都道府県・他変数にも適用可能。
⚠️ 落とし穴(拡張版・各 100 文字以上)
🐍 Python 実装バリエーション(scikit-learn / scipy / Optuna)
A. scikit-learn による実装
X(1 次元または多次元の数値列)、n_components=2。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | from sklearn.mixture import GaussianMixture from sklearn.preprocessing import StandardScaler, QuantileTransformer import numpy as np # 正規でないデータを「正規化」する変換 qt = QuantileTransformer(output_distribution='normal', random_state=42) x_norm = qt.fit_transform(df[['一人当たり県民所得']]).ravel() print(f'変換前 歪度: {stats.skew(df["一人当たり県民所得"]):+.2f}') print(f'変換後 歪度: {stats.skew(x_norm):+.2f}') # 混合ガウスで「実は 2 つの正規の合成」を検出 gmm = GaussianMixture(n_components=2, random_state=42) gmm.fit(df[['一人当たり県民所得']]) print('成分 1:', gmm.means_[0], gmm.covariances_[0]) print('成分 2:', gmm.means_[1], gmm.covariances_[1]) print('重み:', gmm.weights_) |
B. scipy / statsmodels による実装
mu, sigma, 観測値 x。norm.cdf(x, mu, sigma) で確率を計算。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | from scipy import stats import numpy as np x = df['持ち家比率'].values mu, sigma = x.mean(), x.std(ddof=1) # 各種確率計算 print(f'P(X < 60) = {stats.norm.cdf(60, mu, sigma):.4f}') print(f'P(60 < X < 75) = {stats.norm.cdf(75, mu, sigma) - stats.norm.cdf(60, mu, sigma):.4f}') print(f'P(X > 80) = {1 - stats.norm.cdf(80, mu, sigma):.4f}') # 分位点 for q in [0.025, 0.25, 0.5, 0.75, 0.975]: print(f' {int(q*100)}%-tile (正規) = {stats.norm.ppf(q, mu, sigma):.2f}') # 信頼区間(平均の) n = len(x) ci_low = mu - stats.t.ppf(0.975, n-1) * sigma / np.sqrt(n) ci_high = mu + stats.t.ppf(0.975, n-1) * sigma / np.sqrt(n) print(f'\n95% CI of μ: ({ci_low:.2f}, {ci_high:.2f})') # 尤度比検定の例:正規 vs t 分布 ll_norm = np.sum(stats.norm.logpdf(x, mu, sigma)) ll_t = np.sum(stats.t.logpdf(x, df=5, loc=mu, scale=sigma)) print(f'\nlog-Lik 正規 = {ll_norm:.2f}') print(f'log-Lik t(5) = {ll_t:.2f}') print('差が大きいほど分布選択が重要') |
C. Optuna でハイパラ・選択最適化
X(観測データ)、Optuna study とトライアル数。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | import optuna from scipy import stats # 正規分布の MLE 推定 + 分布族の選択 def objective(trial): dist = trial.suggest_categorical('dist', ['norm', 'lognorm', 't', 'gamma']) x = df['一人当たり県民所得'].values if dist == 'norm': params = stats.norm.fit(x) ll = np.sum(stats.norm.logpdf(x, *params)) k = 2 elif dist == 'lognorm': params = stats.lognorm.fit(x) ll = np.sum(stats.lognorm.logpdf(x, *params)) k = 3 elif dist == 't': params = stats.t.fit(x) ll = np.sum(stats.t.logpdf(x, *params)) k = 3 else: # gamma params = stats.gamma.fit(x) ll = np.sum(stats.gamma.logpdf(x, *params)) k = 3 # AIC return -2 * ll + 2 * k study = optuna.create_study(direction='minimize') study.optimize(objective, n_trials=10) print('Best distribution:', study.best_params, ' AIC:', study.best_value) |
D. ライブラリ早見表
| ライブラリ / 関数 | 用途 |
|---|---|
scipy.stats.norm | PDF・CDF・乱数生成 |
scipy.stats.shapiro, jarque_bera, normaltest | 正規性検定 |
scipy.stats.probplot | Q-Q プロット |
scipy.stats.kstest | Kolmogorov-Smirnov 検定 |
scipy.stats.anderson | Anderson-Darling 検定 |
statsmodels.stats.diagnostic.kstest_normal | Lilliefors 検定 |
🔬 モーメント母関数と特性関数 — 「全モーメントの貯金箱」
正規分布 $\mathcal{N}(\mu, \sigma^2)$ のモーメント母関数 (MGF) は
$$M_X(t) = \mathbb{E}[e^{tX}] = \exp\!\left(\mu t + \tfrac{1}{2}\sigma^2 t^2\right)$$
この MGF を $t$ で微分して $t=0$ を代入すれば、 全モーメントが取り出せます。 1 次:$\mathbb{E}[X] = \mu$、 2 次:$\mathbb{E}[X^2] = \mu^2 + \sigma^2$、 3 次中心モーメント=0(左右対称)、 4 次中心モーメント=$3\sigma^4$(尖度=3 が正規分布の指標)。 SSDSE-B-2026 の年齢別人口比のような「ほぼ正規」とされる量も、 4 次モーメントの 3 からのズレで「真の正規からの距離」を測れます。
特性関数 $\varphi_X(t) = \mathbb{E}[e^{itX}] = \exp(i\mu t - \tfrac{1}{2}\sigma^2 t^2)$ は MGF と違って必ず存在し、 中心極限定理の証明で本質的役割を果たします。 $n$ 個の i.i.d. 確率変数の和の特性関数は $\varphi(t)^n$ で、 これが $n \to \infty$ で正規分布の特性関数に収束する――これが CLT の標準証明です。
📐 多変量正規分布の幾何学
$p$ 次元の多変量正規分布 $\mathcal{N}_p(\boldsymbol\mu, \Sigma)$ の密度関数は
$$f(\boldsymbol x) = \frac{1}{(2\pi)^{p/2} |\Sigma|^{1/2}} \exp\!\left(-\tfrac{1}{2}(\boldsymbol x - \boldsymbol\mu)^\top \Sigma^{-1} (\boldsymbol x - \boldsymbol\mu)\right)$$
等高線は $\Sigma$ の固有ベクトル方向を軸とする楕円。 主軸の長さは固有値の平方根に比例します。 SSDSE-B-2026 の「総人口・労働力人口・就業者数」を多変量正規でモデル化すると、 $\Sigma$ の最大固有値は「人口総量軸」に対応し、 47 都道府県は概ねこの軸上に並びます(離散的だが連続近似が有効)。
条件付き分布の閉形式公式も極めて重要。 $\boldsymbol X = (\boldsymbol X_1, \boldsymbol X_2)$ で分割し、 $\Sigma$ も $\Sigma_{11}, \Sigma_{12}, \Sigma_{22}$ にブロック分割すると、
$$\boldsymbol X_1 \mid \boldsymbol X_2 = \boldsymbol x_2 \sim \mathcal{N}\!\left(\boldsymbol\mu_1 + \Sigma_{12} \Sigma_{22}^{-1} (\boldsymbol x_2 - \boldsymbol\mu_2),\ \Sigma_{11} - \Sigma_{12} \Sigma_{22}^{-1} \Sigma_{21}\right)$$
これは カルマンフィルタ、 ガウス過程回帰、 ベイズ線形回帰の心臓部。 「条件付けも正規」「条件付き期待値は線形」「条件付き分散は新情報に依らず一定」という三つの性質がアルゴリズムを閉じた形に保ちます。
📊 正規性検定 — 「本当に正規ですか?」
| 検定 | 特徴 | $n$ 適用 | SSDSE で使うとき |
|---|---|---|---|
| Shapiro-Wilk | 小標本で最も強力 | $n \le 5000$ | 47 都道府県($n=47$)に最適 |
| Kolmogorov-Smirnov | 理論分布との最大距離 | 全範囲 | $\mu, \sigma$ 推定時は Lilliefors 補正必要 |
| Anderson-Darling | 裾の差に敏感 | 全範囲 | 外れ値検出と組合せ有用 |
| Jarque-Bera | 歪度・尖度ベース | $n$ 大 | 大規模センサスデータに |
| D'Agostino's K² | 歪度・尖度の Z 値合成 | $n \ge 20$ | SSDSE-B にちょうど良い |
| Q-Q プロット | 視覚的・検定不要 | 常時併用 | 必ず描く・最重要 |
import pandas as pd from scipy import stats df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=1) pop_log = np.log(df.iloc[:, 3]) # Shapiro-Wilk(n=47 で最強) W, p = stats.shapiro(pop_log) print(f'Shapiro-Wilk: W={W:.4f}, p={p:.4f}') # Anderson-Darling A2 = stats.anderson(pop_log, dist='norm') print(f'AD: A²={A2.statistic:.4f}, critical at 5%={A2.critical_values[2]}') # Q-Q プロット(最も信頼すべき判定) import matplotlib.pyplot as plt stats.probplot(pop_log, dist='norm', plot=plt) plt.title('Q-Q plot: log(人口)'); plt.show()
🌀 中心極限定理の精密版 — Berry-Esseen 不等式
通常の CLT は「$n \to \infty$ で正規分布に収束」と言うだけですが、 収束の速さを定量化するのが Berry-Esseen の定理:
$$\sup_x \left| F_n(x) - \Phi(x) \right| \le \frac{C \cdot \rho}{\sigma^3 \sqrt{n}}, \quad C \le 0.4748, \rho = \mathbb{E}|X - \mu|^3$$
「ズレは $O(1/\sqrt{n})$」、 つまり $n = 100$ なら最大誤差は約 0.05、 $n = 10000$ なら約 0.005。 SSDSE-B-2026 の 47 都道府県平均を計算するとき、 $n=47$ なら最大誤差 0.07 程度――「ほぼ正規」だが厳密な確率計算には注意が必要、 という肌感覚を持てます。
さらに $X_i$ が独立でも同分布でなくてよい「Lindeberg-Feller の CLT」、 弱従属でも成り立つ「マルチンゲール CLT」など、 CLT には豊富な拡張があり、 統計学の基礎理論を支えています。
⚠️ 正規分布の追加的な落とし穴(10 個)
- 「データが多ければ正規」と思う:CLT は「標本平均が正規」と言うだけ。 個々のデータが正規分布する保証はない。
- 裾が重い分布で SD を使う:t 分布や Cauchy 分布に近いデータで SD を計算すると、 外れ値で SD が無意味に大きく。
- p 値だけで正規性を判定:$n$ 大で僅かなズレでも有意になる。 Q-Q プロットの目視を併用。
- 有界データを正規で扱う:失業率 (0-100%) のような有界量は厳密には正規でない。 ロジット変換が定石。
- 離散データを連続正規で近似:人数のような整数値も、 平均が大きければ正規近似可能。 ただし「人数 = 0」付近では危険。
- ゼロ過剰な分布:「ある産業の雇用者数」のように 0 が多発する変数は、 正規分布ではなく Tweedie や Hurdle モデルが適切。
- 多変量で周辺正規 ≠ 同時正規:各変数が正規でも組み合わせが正規とは限らない(コピュラの問題)。
- 歪度を見ずに分散だけで議論:人口データは右に長い裾を持つので、 中央値と平均が乖離する。
- 標準正規での近似誤差:99.7% ルールは「3σ 内に 99.73%」だが、 4σ・5σ の現実的確率は極めて低く、 ファイナンスではブラックスワンの源。
- 3σ ルールの誤用:「3σ 外=外れ値」は正規前提。 非正規データに適用すると正常値まで切り捨てる。
💼 実務応用 — 正規分布が支える 8 分野
- 品質管理:管理図 (X̄-R chart) は「平均が正規に従う」前提。 6σ 品質管理は不良率 3.4 ppm を意味する。
- ファイナンス:Black-Scholes モデルは対数収益率が正規。 ただし実データは裾が重い(GARCH や t 分布で補正)。
- 誤差解析:物理測定では複数の独立誤差が足し合わさるため、 CLT で正規近似が正当化される。
- 機械学習:線形回帰の残差は正規仮定、 Gaussian Naive Bayes、 VAE の潜在変数、 ガウス過程など。
- 医療統計:身長・血圧・コレステロール値などは概ね正規。 「平均±2SD」が基準値範囲の基本。
- 心理学:IQ は定義上正規(平均 100, SD 15)に標準化されている。
- 気象:日次気温は概ね正規だが、 極端気温(heat wave)は裾の議論が必要。
- 製造業:寸法公差設計は正規分布の Cpk 指標で評価される。
🏛 正規分布の歴史 — 200 年の旅路
- 1733 年:de Moivre が二項分布の正規近似を発見(その後 100 年忘れ去られる)。
- 1809 年:Gauss が天文学の誤差解析で正規分布を「再発見」、 「ガウス分布」の名の起源に。
- 1810 年:Laplace が中心極限定理の原型を証明。
- 1835 年:Quetelet が社会統計(身長・犯罪率)に正規分布を初応用、 「平均人」概念を提唱。
- 1894 年:Pearson が「正規分布」(normal distribution) の名前を定着させる。
- 1920 年代:Fisher が最尤推定・分散分析を体系化、 正規分布を統計学の中心に。
- 1940 年代:Wiener が確率過程(ブラウン運動)の理論を完成、 連続時間版正規分布が物理・金融に浸透。
- 1970 年代:Tukey ら が「ロバスト統計」を提唱、 「正規分布信仰」への警鐘を鳴らす。
- 2000 年代:機械学習でガウス過程・正規化フローが復権、 正規分布は今も最重要分布の一つ。