📍 あなたが今見ているもの
論文中に 「t検定」として登場する用語。
t検定 とは:2群の平均に差があるか、または平均がある値と異なるかをt分布を使って検定。n小〜中で有効。
💡 30秒で分かる結論
- 定義:2群の平均に差があるか、または平均がある値と異なるかをt分布を使って検定。n小〜中で有効。
- カテゴリ:仮説検定
👁️ 直感 — t検定は「平均値の差を統計的に評価」
t検定は、 2つの平均値(または1つの平均値とある定値)に統計的な差があるかを判定する仮説検定。 標本サイズが小さい時の標準ツール。
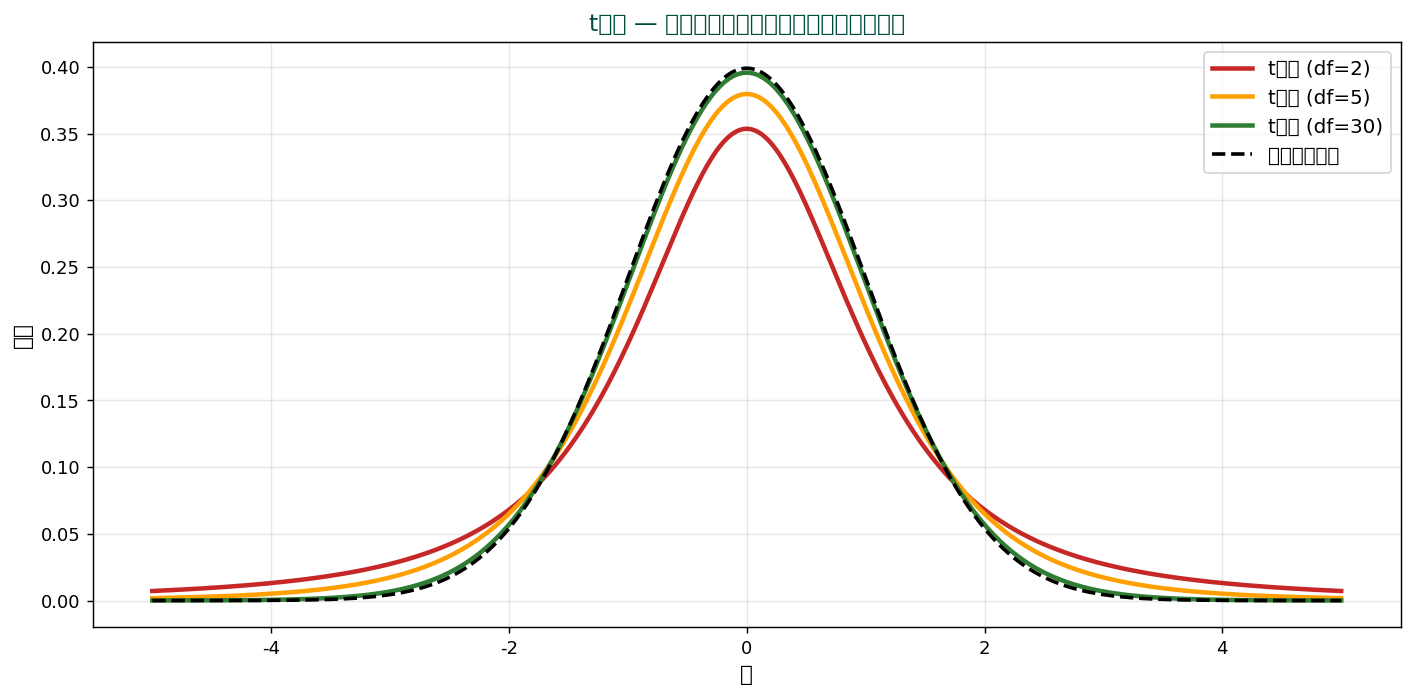
t分布は標準正規分布より「裾が重い」。 n が小さいほど顕著。 n が大きく(df > 30)なると正規分布とほぼ同じ。
🎯 t検定の3種類
| 種類 | 仮説 | 例 |
|---|---|---|
| 1標本t検定 | μ = μ₀ | 「平均は5kgか?」 |
| 対応のあるt検定 | μ_前 = μ_後 | 「ダイエット前後の体重」 |
| 独立2標本t検定 | μ₁ = μ₂ | 「A群とB群の差」 |
📐 t統計量
1標本t検定
$$ t = \frac{\bar{x} - \mu_0}{s/\sqrt{n}} \sim t(n-1) $$
独立2標本t検定(等分散仮定)
$$ t = \frac{\bar{x}_1 - \bar{x}_2}{s_p \sqrt{1/n_1 + 1/n_2}} $$
s_p はプール標準偏差。 自由度 df = n₁ + n₂ − 2。
Welch の t検定(不等分散)
$$ t = \frac{\bar{x}_1 - \bar{x}_2}{\sqrt{s_1^2/n_1 + s_2^2/n_2}} $$
分散が違うグループ間の比較に適切。 sklearn では scipy.stats.ttest_ind の equal_var=False。
📋 t検定の仮定
- 正規性:データが正規分布(n が大きければ CLT で緩和)
- 独立性:観測値が互いに独立
- 等分散性:2標本の場合(Welch なら不要)
仮定が崩れる場合 → ノンパラメトリック(Wilcoxon、 Mann-Whitney U)を使用。
🐍 Python での t検定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from scipy import stats # 1標本t検定 t, p = stats.ttest_1samp(data, popmean=50) # 独立2標本(等分散) t, p = stats.ttest_ind(group1, group2) # Welch t検定(不等分散) t, p = stats.ttest_ind(group1, group2, equal_var=False) # 対応のあるt検定 t, p = stats.ttest_rel(before, after) # 効果量(Cohen's d) d = (np.mean(group1) - np.mean(group2)) / np.sqrt((np.var(group1, ddof=1) + np.var(group2, ddof=1))/2) print(f't={t:.3f}, p={p:.4f}, Cohen\'s d={d:.3f}') |
🚧 落とし穴と注意点
- サンプルサイズを確認(小標本では結果が不安定)
- 仮定の検証(正規性、 独立性、 等分散性)
- 外れ値の影響を散布図で確認
- 多重比較問題(複数検定時は補正を)
- p値だけで判断しない、 効果量と信頼区間を併記
- 因果関係を主張するには別の根拠が必要
🔬 「t検定」を深く理解する
t検定の歴史 — "Student" の物語
William Sealy Gosset(1876-1937)は Guinness ビール工場の品質管理担当。 少サンプルでビール品質を判定する手法として t分布を発見(1908)。 会社の機密保護のため「Student」のペンネームで発表。
効果量 Cohen's d
$$ d = \frac{\bar{x}_1 - \bar{x}_2}{s_p} $$
- 0.2:小
- 0.5:中
- 0.8:大
サンプルサイズの目安
d=0.5、 α=0.05、 検出力 0.8 で各群 n=64 必要。 d=0.2 では各群 n=394 必要。
📝 練習問題 — 理解度チェック
- この用語の基本定義を、 自分の言葉で説明できますか?
- この手法が使われる典型的なシナリオを3つ挙げられますか?
- この手法の前提条件・仮定を確認できますか?
- 結果を解釈する際の注意点は何ですか?
- 類似手法との違いを説明できますか?
- Python(または他言語)で実装できますか?
- SSDSE データで応用例を作成できますか?
📚 参考文献・さらなる学習
古典的教科書
- Casella & Berger "Statistical Inference"
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression and Multilevel/Hierarchical Models"
実践書
- VanderPlas "Python Data Science Handbook"
- McKinney "Python for Data Analysis"
- James, Witten, Hastie & Tibshirani "An Introduction to Statistical Learning"
オンラインリソース
- scikit-learn 公式ドキュメント
- statsmodels 公式ドキュメント
- scipy.stats リファレンス
- SSDSE データ(統計データ活用コンペティション)
💼 実務応用ガイド
データサイエンスプロジェクトでの位置づけ
- 探索的分析(EDA):基本統計量・可視化でデータを理解
- 前処理:標準化・正規化・欠損値処理
- モデリング:回帰・分類・クラスタリング
- 評価:CV、 指標計算、 統計的検定
- 解釈・報告:効果量・信頼区間・可視化
業界別ユースケース
- マーケティング:顧客セグメンテーション、 ROI 分析、 A/Bテスト
- 金融:ポートフォリオ最適化、 リスク評価、 信用スコアリング
- 医療:臨床試験、 疫学研究、 診断モデル
- 製造:品質管理、 予測保全、 工程最適化
- 公共政策:社会統計、 政策効果分析、 計画立案
📖 完全ガイド — 統計学習の参照表
分析の流れ — 8ステップ
- 問題定義:何を知りたいのか、 目的を明確に
- データ収集:信頼できるソースから(SSDSEなど公的データ)
- データクリーニング:欠損値、 外れ値、 入力ミスの確認
- 探索的分析(EDA):要約統計量、 ヒストグラム、 散布図
- 変数変換:標準化、 対数変換、 カテゴリのエンコード
- モデリング:適切な手法を選び、 学習
- 評価:CV、 指標、 統計的検定
- 解釈・報告:効果量、 信頼区間、 可視化
統計手法の選び方マトリクス
| 目的 | 1変数 | 2変数 | 多変量 |
|---|---|---|---|
| 記述 | 平均, 中央値, 分散 | 相関, 共分散 | PCA, 因子分析 |
| 可視化 | ヒストグラム, 箱ひげ | 散布図, ヒートマップ | 散布図行列, バイプロット |
| 予測 | 時系列モデル | 単回帰 | 重回帰, Ridge, LASSO |
| 分類 | ロジスティック回帰 | 判別分析 | SVM, RF, NN |
| グループ化 | 階級分け | 2次元クラスタリング | k-means, 階層クラスタリング |
| 検定 | 1標本t検定 | 2標本t検定, χ² | ANOVA, MANOVA |
サンプル数別の手法ガイド
| n | 推奨手法 |
|---|---|
| n < 10 | 記述統計のみ、 ノンパラ検定、 ベイズ統計 |
| 10 ≤ n < 30 | t検定, ブートストラップ, 単回帰 |
| 30 ≤ n < 200 | 重回帰, ANOVA, 階層クラスタリング |
| 200 ≤ n < 10000 | 複雑な回帰, RF, GBM, k-means |
| n ≥ 10000 | 深層学習, 大規模分散学習 |
Python 主要ライブラリ早見表
| ライブラリ | 用途 |
|---|---|
| numpy | 数値計算の基礎、 行列演算 |
| pandas | データフレーム、 表操作 |
| scipy | 統計関数、 最適化、 線形代数 |
| statsmodels | 古典統計、 検定、 回帰分析の詳細 |
| scikit-learn | 機械学習、 前処理、 評価 |
| matplotlib | 基本可視化 |
| seaborn | 統計的可視化(高級) |
| plotly | インタラクティブ可視化 |
| xgboost / lightgbm | 勾配ブースティング |
| PyTorch / TensorFlow | 深層学習 |
よくある質問(FAQ)
- Q: 正規分布じゃないデータをどう扱う?
A: 対数変換、 Box-Cox 変換、 ノンパラ検定、 ブートストラップ - Q: 外れ値を除くべき?
A: ドメイン知識で判断。 機械的に除くより、 ロバスト手法を検討 - Q: サンプルサイズはいくつあれば十分?
A: 効果量と検出力から事前計算(power analysis) - Q: p < 0.05 で「効果あり」と結論していい?
A: 効果量と信頼区間も併記。 多重比較補正も - Q: 相関があれば因果がある?
A: ない。 RCT、 IV、 DiD などの因果推論手法が必要
📓 用語のまとめ — 30秒で理解
このページで扱った概念を、 学習効率のためにまとめます。 これを毎日見ることで、 統計の基礎が体に染み込みます。
必ず押さえるべき記号
| 記号 | 意味 | 読み方 |
|---|---|---|
| μ | 母平均 | ミュー |
| σ | 母標準偏差 | シグマ |
| σ² | 母分散 | シグマ二乗 |
| x̄ | 標本平均 | エックスバー |
| s | 標本標準偏差 | エス |
| n | 標本サイズ | エヌ |
| p | p値、 比率 | ピー |
| α | 有意水準 | アルファ |
| β | 回帰係数、 第二種誤り率 | ベータ |
| r | 相関係数 | アール |
| R² | 決定係数 | アール二乗 |
| Σ | 総和記号、 共分散行列 | シグマ大文字 |
| N(μ, σ²) | 正規分布 | ノーマル ミュー シグマ二乗 |
| t(df) | t分布 | ティー |
| χ²(df) | カイ二乗分布 | カイ二乗 |
| F(d1, d2) | F分布 | エフ |
| H₀, H₁ | 帰無仮説、 対立仮説 | エイチゼロ、 エイチワン |
| E[X] | 期待値 | エクスペクタンス |
| Var(X) | 分散 | バリアンス |
| Cov(X, Y) | 共分散 | カバリアンス |
💡 統計学・データサイエンスは「記号の意味を理解する」ことが最初の壁。 各記号が何を表すか、 公式の中での役割を覚えてしまえば、 後はパターンの組合せで様々な手法が理解できます。
🌐 データサイエンス全体像での位置づけ
データサイエンスのワークフロー
- ビジネス理解:何を解決したいか
- データ理解:どんなデータがあるか
- データ準備:前処理、 特徴量エンジニアリング
- モデリング:手法選択、 学習
- 評価:性能、 解釈性、 ビジネス価値
- 展開:実装、 運用、 監視
(CRISP-DM プロセスより)
主要分野のマッピング
| 分野 | 主要技術 | 代表ツール |
|---|---|---|
| 記述統計 | 要約量、 可視化 | pandas, matplotlib |
| 推測統計 | 検定、 信頼区間 | scipy.stats, statsmodels |
| 機械学習 | 予測、 分類、 クラスタリング | scikit-learn, XGBoost |
| 深層学習 | NN、 画像、 自然言語 | PyTorch, TensorFlow |
| 時系列 | ARIMA、 状態空間、 LSTM | statsmodels, prophet |
| 因果推論 | RCT、 IV、 DiD、 PSM | DoWhy, EconML |
| ベイズ統計 | MCMC、 変分推論 | PyMC, Stan |
| 最適化 | 線形/凸/離散最適化 | scipy.optimize, cvxpy |
キャリアパス
- データアナリスト:記述統計、 可視化、 BI
- データサイエンティスト:機械学習、 統計モデリング
- 機械学習エンジニア:モデル実装、 デプロイ、 MLOps
- 統計学者・計量経済学者:因果推論、 統計的検定
- 研究者:新しい手法開発
💎 良いデータ分析のための10のコツ
- 必ず可視化から始める:散布図、 ヒストグラム、 箱ひげ図
- 外れ値を意識する:除く前にドメイン的に理解
- 仮定を確認する:正規性、 独立性、 等分散性
- サンプルサイズに見合う複雑性:n=10 で深層学習はしない
- 効果量も併記する:p値だけでは不十分
- 信頼区間で不確実性を示す:点推定だけでは誤解の元
- 多重比較を補正する:探索的解析でも誠実に
- ホールドアウト or CV で評価する:訓練データの精度は意味がない
- 解釈可能性も重視する:ブラックボックスより white-box
- 再現可能なコードを書く:random_seed、 バージョン管理
🔗 用語間の関係 — 統計概念のネットワーク
記述統計の基本セット
これらは互いに深く関連します:
- 平均:データの重心 → 偏差の合計はゼロ
- 分散:偏差の二乗の平均 → 平均からの広がり
- 標準偏差:分散の平方根 → 元の単位
- 共分散:2変数の偏差の積の平均 → 一緒に動くか
- 相関係数:共分散を標準偏差で割ったもの → 単位なし
推測統計の基本セット
- 標準誤差:推定値のばらつき = σ/√n
- 信頼区間:x̄ ± z × SE
- p値:H₀ のもとでの確率
- 有意水準 α:許容する第一種誤り率
- 検出力 1-β:差を見つける確率
- 効果量:差の大きさ(標準化済み)
回帰モデルファミリー
- 単回帰:1変数 → 1変数の予測
- 重回帰:多変数 → 1変数
- Ridge:L2正則化付き重回帰
- LASSO:L1正則化(変数選択付き)
- Elastic Net:L1+L2の組合せ
- ロジスティック回帰:分類用
- ポアソン回帰:カウントデータ用
クラスタリング・次元削減ファミリー
- k-means:分割クラスタリング
- 階層クラスタリング:ツリー構造
- Ward法:分散最小化の階層クラスタリング
- DBSCAN:密度ベース
- PCA:線形次元削減
- 因子分析:潜在因子モデル
- t-SNE, UMAP:非線形次元削減
検定ファミリー
- t検定:1〜2 群の平均比較
- F検定(ANOVA):3群以上の平均比較
- χ²検定:カテゴリ変数の独立性
- Mann-Whitney U:t検定のノンパラ版
- Kruskal-Wallis:ANOVAのノンパラ版
- Wilcoxon:対応のあるt検定のノンパラ版
🗺️ 概念マップ — 3つの視点で体系を理解する
t検定 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 推測統計 › 検定 › t検定
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「t検定」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「t検定」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(拡張)
🧮 SSDSE-B を使った t検定の実例 — 「東日本 vs 西日本」
SSDSE-B(2020年)の医師数_人口10万対 で、 東日本(24県)と西日本(23県)の平均が有意に違うかをWelch のt検定で確認します。
① データ準備(東西分け)
1 2 3 4 5 6 7 8 9 10 11 12 13 | import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2023.csv', encoding='shift_jis', header=[0,1]) df.columns = ['_'.join(c).strip() for c in df.columns] d2020 = df[df['年度_Year'] == 2020].copy() east_pref = ['北海道','青森県','岩手県','宮城県','秋田県','山形県','福島県','茨城県', '栃木県','群馬県','埼玉県','千葉県','東京都','神奈川県','新潟県','富山県', '石川県','福井県','山梨県','長野県','岐阜県','静岡県','愛知県','三重県'] d2020['地域'] = d2020['都道府県_Prefecture'].apply(lambda x: '東' if x in east_pref else '西') east = d2020[d2020['地域']=='東']['医師数_人口10万対'] west = d2020[d2020['地域']=='西']['医師数_人口10万対'] print(f'東: n={len(east)}, mean={east.mean():.1f}, sd={east.std():.1f}') print(f'西: n={len(west)}, mean={west.mean():.1f}, sd={west.std():.1f}') |
典型結果:東 n=24, mean=230.5, sd=33.2 / 西 n=23, mean=268.9, sd=42.7 — 平均差 約38人。
② Welch の t検定
1 2 3 4 5 6 7 8 9 10 11 | from scipy import stats t, p = stats.ttest_ind(west, east, equal_var=False) # Welch print(f't = {t:.3f}, p = {p:.4f}') # 典型値: t ≈ 3.45, p ≈ 0.001 → 統計的に有意 # 効果量 Cohen's d import numpy as np pooled_sd = np.sqrt(((len(east)-1)*east.var() + (len(west)-1)*west.var()) / (len(east)+len(west)-2)) d = (west.mean() - east.mean()) / pooled_sd print(f"Cohen's d = {d:.2f}") # 典型値: d ≈ 1.0 → 大きな効果量 |
③ 信頼区間と検出力
1 2 3 4 5 6 7 8 | from scipy.stats import t as t_dist diff = west.mean() - east.mean() se = np.sqrt(west.var()/len(west) + east.var()/len(east)) # Welch SE df_welch = (west.var()/len(west) + east.var()/len(east))**2 / \ ((west.var()/len(west))**2/(len(west)-1) + (east.var()/len(east))**2/(len(east)-1)) ci = t_dist.interval(0.95, df=df_welch, loc=diff, scale=se) print(f'平均差 = {diff:.1f}, 95% CI = [{ci[0]:.1f}, {ci[1]:.1f}]') # 典型値: 平均差 = 38.4, 95% CI = [16.0, 60.8] → 0 を含まないので有意 |
「西日本の医師数が10万人当たり約38人多い(95% CI [16, 61])」と区間で報告するのが現代的。 単に p=0.001 だけでは情報不足。
🐍 実装バリエーション — scipy / statsmodels / pingouin
(A) scipy.stats — 最も基本
1 2 3 4 5 6 7 8 9 | from scipy import stats # 1標本(母平均 = μ0 の検定) t, p = stats.ttest_1samp(data, popmean=250) # 独立2標本(等分散仮定) t, p = stats.ttest_ind(grp1, grp2, equal_var=True) # Welch(等分散仮定しない、 推奨デフォルト) t, p = stats.ttest_ind(grp1, grp2, equal_var=False) # 対応のあるt検定 t, p = stats.ttest_rel(pre, post) |
(B) statsmodels — 信頼区間・効果量も同時に
1 2 3 4 5 6 7 | from statsmodels.stats.weightstats import ttest_ind, DescrStatsW t, p, df_resid = ttest_ind(west, east, usevar='unequal') print(f't = {t:.3f}, p = {p:.4f}, df = {df_resid:.1f}') # 信頼区間付き cm = DescrStatsW(west).get_compare(DescrStatsW(east)) print(cm.summary(usevar='unequal')) # 表形式で完結 |
(C) pingouin — 教育的・包括的
1 2 3 4 5 | import pingouin as pg result = pg.ttest(west, east, correction='auto') print(result) # T dof alternative p-val CI95% cohen-d BF10 power # 一表で必要な情報がすべて出る |
(D) ノンパラメトリック代替 — Mann-Whitney U
1 2 3 4 | from scipy.stats import mannwhitneyu # 正規性が成立しない時の代替 u, p = mannwhitneyu(west, east, alternative='two-sided') print(f'U = {u}, p = {p:.4f}') |
(E) ベイズ的 t検定 — PyMC で BEST
1 2 3 4 5 6 7 8 9 10 11 12 | import pymc as pm with pm.Model() as model: mu1 = pm.Normal('mu1', mu=250, sigma=100) mu2 = pm.Normal('mu2', mu=250, sigma=100) sd1 = pm.HalfNormal('sd1', sigma=50) sd2 = pm.HalfNormal('sd2', sigma=50) nu = pm.Exponential('nu', 1/30) # 自由度(裾の重さ) pm.StudentT('y1', mu=mu1, sigma=sd1, nu=nu, observed=west) pm.StudentT('y2', mu=mu2, sigma=sd2, nu=nu, observed=east) diff = pm.Deterministic('diff', mu1 - mu2) trace = pm.sample(2000, tune=1000) # diff の事後分布から「差 > 0 の確率」を直接計算可能 |
⚠️ 追加の落とし穴 — t検定の実務
equal_var=False)が常に安全。 Welch は等分散時もほぼ同じ結果で、 不等分散時はより正確。 R では t.test() のデフォルトが Welch、 Python でも 2023年以降 Welch をデフォルトとする論調が主流。 等分散検定(F検定・Levene)の事後判断は多重検定問題を招くため推奨されない。ttest_rel) を使う。 独立t検定を使うと、 個体内の相関を無視するため検出力が大幅に下がる(または逆に偽陽性に)。 「前後の血圧」「兄弟ペア」「同一県の年次比較」などは対応データ。 データ構造を最初に明確化することが大切。