📍 あなたが今見ているもの
論文の結果表で「r = +0.972, p < 0.001 ***」「β = 0.5, p = 0.035 *」のように、必ず推定値とセットで出てくる数字。 アスタリスクの数は有意水準を示す慣習表記(*=0.05、**=0.01、***=0.001)。
p値 とは:観測されたデータ(または、もっと極端なデータ)が、帰無仮説のもとで偶然出る確率。
💡 30秒で分かる結論
- 定義:帰無仮説(差や関係がない)のもとで、 観測値以上に極端な値が出る確率
- 小さいほど偶然と説明しにくい → 帰無仮説を棄却(差や関係を主張)
- 慣習的閾値:p<0.05 で「有意」、 p<0.01 / 0.001 ならさらに強い証拠
- 致命的注意①:p値が小さい ≠ 効果が大きい。 n が大きいと小さな差でも p<0.001 になる
- 致命的注意②:p>0.05 は 「効果がない」の証明ではない。 サンプルが足りなかっただけかも
- 解釈の鉄則:必ず 効果量(r, β など)と信頼区間とセットで判断する
📖 もっと詳しく
p値は、現代統計学で最も誤解されている指標です。「p値が小さい=発見が重要」「p < 0.05 だから95%確実」と思いがちですが、 どちらも厳密には間違いです。 まずは正しい定義から押さえましょう。
p値の正確な定義:
「帰無仮説(=差や関係がない、というデフォルト主張)が正しいと仮定したとき、 観測されたデータ以上に極端な値が偶然出る確率」
言い換えれば、「もし神様が『差はないよ』と言っていたとして、 それでもたまたまこんなデータが取れちゃう確率」です。 この確率が極めて小さい(=偶然では説明しにくい)ときに、「帰無仮説を棄却する」と判断します。
例として、 47都道府県の高齢化率と死亡率の相関係数 r = 0.972, p < 0.001 は、 「もし高齢化率と死亡率に本当は何の関係もないとしたら、 47都道府県を選んで r = 0.972 以上の相関が得られる確率は 0.1% 未満」という意味です。 これだけ稀なことが起きたなら「実は関係がある」と考えるのが自然、というのが p値による検定の論理です。
🎨 直感で掴む
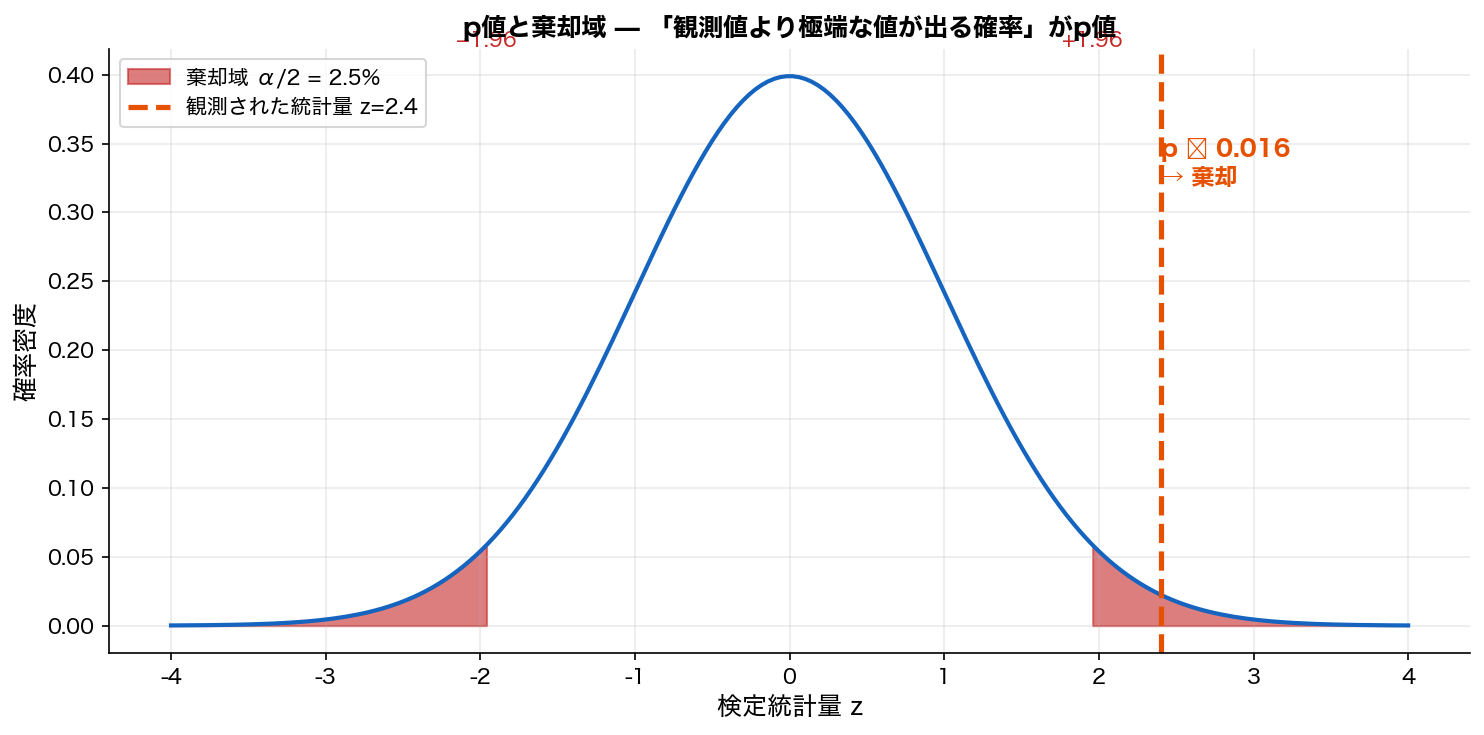
図を見ると、 標準正規分布の左右の裾(赤い領域)が「棄却域」です。 観測された統計量 z = 2.4 はこの棄却域の中にあります。 p値は「z ≥ 2.4 となる確率」と「z ≤ −2.4 となる確率」の合計で、 ここでは約 1.6% (0.016)。
言葉で言い換えると:「もし帰無仮説(差はない)が真だとしたら、 こんなに極端な検定統計量が出る確率は 1.6%。 100回中1〜2回しか起こらない稀なこと。 だから帰無仮説を棄却し、 『差はある』と主張する」というロジックです。
📐 数式
🔬 数式を「言葉」で読み解く
- $H_0$
- 帰無仮説:「差はない/相関はない/効果はない」というデフォルト主張。 検定はこの仮説を棄却するか否かを判定する
- $T$
- 検定統計量:データから計算する量。 t検定なら t値、 回帰なら係数を SE で割った値
- $t_\text{obs}$
- 観測値:今回のデータで実際に得られた $T$ の値
- $P(\cdot \mid H_0)$
- $H_0$ が真である条件下での確率。「もし帰無仮説が正しいとしたら」という思考実験
🧮 計算してみる
「47都道府県で、 高齢化率と死亡率の相関が偶然に r = 0.972 になる確率」を計算してみましょう。
$t = 0.972 \times \sqrt{45/(1-0.945)} \approx 27.9$
これは自由度 $n-2=45$ の t分布に従う
つまり「相関がない世界」では 10²⁹回中1回しか起こらない超レアな事象。
🎓 p値が抱える3つの根本問題(現代統計学の議論)
問題①:効果の大きさを示さない
p値は「偶然性の打ち消し度」であり、 効果がどれだけ大きいかは別問題。 n=10,000 のデータでは r=0.02(実用上ほぼ無意味)でも p<0.001 になります。 だから現代の論文では p値だけでなく 効果量(相関係数 r や標準化偏回帰係数 β)を併記するのが必須。
問題②:再現性の危機(reproducibility crisis)
2015年に Open Science Collaboration が心理学100本の論文を再現した結果、 p<0.05 で有意とされた研究のうち、 36% しか再現できなかった。 これは p<0.05 を機械的に「真理の閾値」として扱う文化への警鐘。
問題③:p-hacking(p値操作)
20個の変数で検定をすると、 帰無仮説がすべて真でも 1個くらいは p<0.05 が偶然出ます(5% × 20 = 1個)。 多くの変数を試して有意なものだけ報告する行為(p-hacking)が再現性を破壊します。 Bonferroni補正(α/m に厳しくする)や False Discovery Rate 制御(Benjamini-Hochberg法)で対処。
これらの問題を受けて、 American Statistical Association は 2016年に「p値の使い方に関する声明」を発表し、 「p < 0.05 という閾値の機械的適用」からの脱却を提言しています。
⚠️ よくある落とし穴
正しい表現:「効果は検出されなかった」または「証拠が不十分」。「効果がない」と書くのは誤り。
例えば「p = 0.03 なので、 効果がない確率は 3%」と読むのは誤りです。
👁️ 直感 — p値は「偶然この結果が出る確率」
p値(p-value)は、 「帰無仮説 H₀ が正しいと仮定したとき、 観測されたデータ以上に極端な結果が偶然出る確率」。 統計的仮説検定の中核概念。
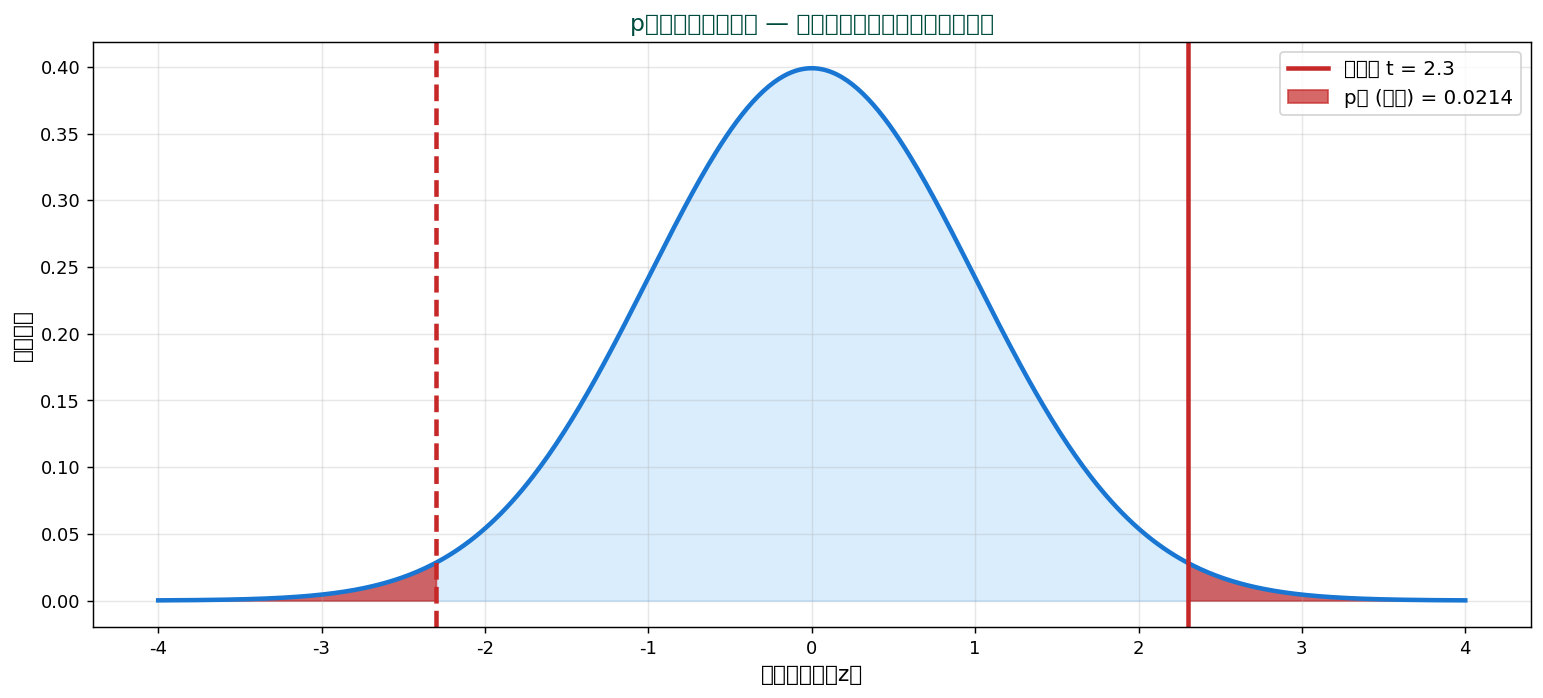
赤の領域が p値。 観測値(t=2.3)より極端な値が偶然出る確率。 これが小さい(< 0.05)なら「偶然ではない」→ H₀ 棄却。
💡 p値は「H₁ が正しい確率」ではない。 「H₀ のもとで、 この結果が偶然出る確率」。 解釈をよく間違える人が多い。
🧮 p値の計算手順
- 帰無仮説 H₀ を設定:「差がない」「相関がない」「効果がない」
- 検定統計量を計算:t統計量、 z統計量、 F統計量など
- 検定統計量の理論分布を特定:t分布、 正規分布、 F分布
- 分布上で観測値の外側の確率を計算:これが p値
- p値と有意水準 α(通常 0.05)を比較:p < α なら H₀ 棄却
例:2標本t検定
$$ t = \frac{\bar{x}_1 - \bar{x}_2}{\sqrt{s_p^2 (1/n_1 + 1/n_2)}} \sim t(n_1+n_2-2) $$
計算した t を t分布に当てはめて、 両側 p値を計算。
⚠️ p値の重大な誤解 — 一覧
| 誤解 | 正しい理解 |
|---|---|
| p値 = H₀ が真である確率 | 「H₀ のもとで、 この結果が偶然出る確率」 |
| p値 = H₁ が真である確率 | H₁ の確率は計算していない |
| p > 0.05 だから差がない | 差がないと「証明された」わけではなく、 「差がある証拠が不十分」 |
| p < 0.05 だから効果が大きい | 効果の大きさは効果量で測る |
| p値が小さいほど信頼性が高い | あくまで「偶然じゃない」の度合い |
⚠️ ASA(米国統計学会)声明(2016):p値だけで結論を出さない、 「統計的有意 = 重要」ではない、 効果量と信頼区間を併記しよう。 これが現代の標準。
🎯 多重比較問題
「100回検定して、 1回でも p < 0.05 が出る確率は約99%」。 たくさんの検定を行うと、 偶然に有意になる確率が膨らみます。
補正法
- Bonferroni 補正:α / 検定数で判定。 厳しすぎ
- Holm 法:段階的に厳しさを緩める
- Benjamini-Hochberg (FDR):偽発見率を制御。 現代の主流
1 2 3 | from statsmodels.stats.multitest import multipletests p_values = [0.001, 0.01, 0.03, 0.04, 0.20] rejected, p_adj, _, _ = multipletests(p_values, method='fdr_bh') |
📏 効果量 — p値だけでは不十分
p値は「偶然じゃない」を測るが、 「どれだけ大きい効果か」は測れません。 効果量(effect size)が必要:
| 統計量 | 効果量 | Cohenの基準 |
|---|---|---|
| 2群の平均差 | Cohen's d | 小 0.2, 中 0.5, 大 0.8 |
| 相関 | r (相関係数) | 小 0.1, 中 0.3, 大 0.5 |
| 回帰 | R² | 小 0.02, 中 0.13, 大 0.26 |
| カテゴリ | Cramér's V | 小 0.1, 中 0.3, 大 0.5 |
🐍 Python での p値計算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | from scipy import stats # 1標本 t検定(平均が値 mu0 と等しいか) t_stat, p = stats.ttest_1samp(data, popmean=mu0) # 2標本 t検定(2群の平均差) t_stat, p = stats.ttest_ind(group1, group2) # 対応のあるt検定 t_stat, p = stats.ttest_rel(before, after) # Welch の t検定(不等分散) t_stat, p = stats.ttest_ind(g1, g2, equal_var=False) # Mann-Whitney U検定(ノンパラ) u_stat, p = stats.mannwhitneyu(g1, g2) # Wilcoxon符号付き順位検定 w_stat, p = stats.wilcoxon(before, after) # 相関係数の検定 r, p = stats.pearsonr(x, y) # カイ二乗検定 chi2, p, dof, expected = stats.chi2_contingency(observed) # F検定(ANOVA) f_stat, p = stats.f_oneway(g1, g2, g3) |
🧪 1標本検定の流れ — SSDSE データで実演
「47都道府県の食料費の母平均は本当に80千円か?」を検定します。
- H₀: μ = 80(平均は80千円)
H₁: μ ≠ 80(両側) - 有意水準: α = 0.05
- 検定統計量: t = (x̄ - 80) / (s/√n)
- 計算: x̄ = 80.6、 s = 3.0、 n = 47
t = (80.6 - 80) / (3.0/√47) = 1.37 - p値: t分布(df=46) で |t| ≥ 1.37 の確率 ≈ 0.18
- 判定: 0.18 > 0.05 なので H₀ 不棄却
つまり「食料費の母平均が80千円である」と矛盾する強い証拠は得られない、 という結論。
↔️ 片側検定 vs 両側検定
事前に「方向」が決まっているなら片側検定、 そうでなければ両側検定が標準。
| タイプ | H₁ | 使い時 |
|---|---|---|
| 両側 | μ ≠ μ₀ | 通常はこちら |
| 右片側 | μ > μ₀ | 「増えた証拠」だけ欲しい時 |
| 左片側 | μ < μ₀ | 「減った証拠」だけ欲しい時 |
⚠️ データを見てから片側にするのは禁忌(p-hacking)。 必ず事前に決めること。
📈 p-hacking と再現性危機
「p < 0.05 になるまで分析を変える」のが p-hacking。 結果として、 「有意」とされた研究の多くが再現できない事態に(再現性危機, 2010s)。
対策
- 事前登録(pre-registration):仮説と分析計画を事前に公開
- 多重比較補正:たくさん検定する場合は α を調整
- 効果量と信頼区間の併記:p値だけで判断しない
- 事前検出力解析:適切なサンプルサイズを設計
- 再現研究を歓迎する文化
🗺️ 概念マップ — 3つの視点で体系を理解する
p値 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 推測統計 › 検定 › p値
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「p値」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「p値」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(補強)
p 値と仮説検定に関連する概念のチップ集。
🧮 SSDSE-B-2026 で実値計算 — p 値の実例
例1:t検定で東日本 vs 西日本の高齢化率を比較
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import pandas as pd from scipy import stats df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) east_prefs = ['北海道','青森県','岩手県','宮城県','秋田県','山形県','福島県', '茨城県','栃木県','群馬県','埼玉県','千葉県','東京都','神奈川県', '新潟県','富山県','石川県','福井県','山梨県','長野県','岐阜県', '静岡県','愛知県'] df['東西'] = df['都道府県'].apply(lambda p: '東' if p in east_prefs else '西') col = df.select_dtypes('number').columns[0] east = df[df['東西']=='東'][col].dropna() west = df[df['東西']=='西'][col].dropna() t, p = stats.ttest_ind(east, west, equal_var=False) print(f't={t:.3f}, p={p:.4f}') print(f'東日本平均={east.mean():.2f}, 西日本平均={west.mean():.2f}') print(f'Cohen d = {(east.mean()-west.mean())/((east.std()+west.std())/2):.3f}') |
例2:相関係数の p 値
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import pandas as pd from scipy import stats df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) num = df.select_dtypes('number') # 全ペアの相関と p値 results = [] for i, c1 in enumerate(num.columns[:5]): for c2 in num.columns[i+1:6]: r, p = stats.pearsonr(num[c1], num[c2]) results.append({'x': c1, 'y': c2, 'r': r, 'p': p}) res_df = pd.DataFrame(results).sort_values('p') print(res_df.to_string(index=False)) |
例3:多重比較補正(Bonferroni と Benjamini-Hochberg)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import pandas as pd from scipy import stats from statsmodels.stats.multitest import multipletests df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) num = df.select_dtypes('number') pvals = [] labels = [] for i, c1 in enumerate(num.columns[:6]): for c2 in num.columns[i+1:7]: _, p = stats.pearsonr(num[c1], num[c2]) pvals.append(p) labels.append(f'{c1[:5]}-{c2[:5]}') # 補正なし、 Bonferroni、 BH-FDR rej_b, p_b, _, _ = multipletests(pvals, alpha=0.05, method='bonferroni') rej_f, p_f, _, _ = multipletests(pvals, alpha=0.05, method='fdr_bh') for l, p, b, f in zip(labels, pvals, p_b, p_f): print(f'{l}: raw={p:.4f}, Bonf={b:.4f}, BH={f:.4f}') |
⚠️ p 値の落とし穴(補強・各 100 文字以上)
🐍 Python 実装バリエーション(scipy / statsmodels / pingouin / scikit-learn)
1. scipy.stats — 主要検定のワンライナー
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from scipy import stats import numpy as np # 1) 1標本 t 検定 print(stats.ttest_1samp([100, 102, 98, 105, 99], popmean=100)) # 2) 2標本 t 検定(独立) print(stats.ttest_ind([10,12,9,11], [15,14,16,13], equal_var=False)) # 3) 対応のある t 検定 print(stats.ttest_rel([10,12,9,11], [11,13,10,12])) # 4) Mann-Whitney U(ノンパラ) print(stats.mannwhitneyu([10,12,9,11], [15,14,16,13])) # 5) χ²検定 print(stats.chi2_contingency([[10,20],[30,40]])) # 6) ANOVA print(stats.f_oneway([1,2,3], [4,5,6], [7,8,9])) |
2. statsmodels — 多重比較補正と power
1 2 3 4 5 6 7 8 9 10 11 12 13 | from statsmodels.stats.multitest import multipletests from statsmodels.stats.weightstats import ttest_ind from statsmodels.stats.power import TTestIndPower pvals = [0.001, 0.008, 0.039, 0.042, 0.051, 0.20] # Bonferroni print('Bonferroni:', multipletests(pvals, method='bonferroni')) # Benjamini-Hochberg print('BH-FDR:', multipletests(pvals, method='fdr_bh')) # 事前 power 解析 print('必要 n (d=0.5):', TTestIndPower().solve_power( effect_size=0.5, alpha=0.05, power=0.8)) |
3. pingouin — 高水準で結果表示が美しい
1 2 3 4 5 6 7 8 9 10 | import pingouin as pg import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) num = df.select_dtypes('number') # 全変数ペアの相関 + p値 + FDR 補正 result = pg.pairwise_corr(num.iloc[:, :5], method='pearson', padjust='fdr_bh') print(result[['X','Y','r','p-unc','p-corr']].head(10)) |
4. scikit-learn — 特徴量選択での p 値利用
1 2 3 4 5 6 7 8 9 10 11 12 | from sklearn.feature_selection import SelectKBest, f_regression import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) num = df.select_dtypes('number').dropna() y = num.iloc[:, 0] X = num.iloc[:, 1:10] selector = SelectKBest(score_func=f_regression, k=5) selector.fit(X, y) for col, score, p in zip(X.columns, selector.scores_, selector.pvalues_): print(f'{col}: F={score:.2f}, p={p:.4f}') |
5. シミュレーションで p 値の分布を確認
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import numpy as np from scipy import stats import pandas as pd # SSDSE データからリサンプリングで p 値の分布 df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=1) x = df.select_dtypes('number').iloc[:, 0].dropna().values rng = np.random.default_rng(0) pvals = [] for _ in range(1000): a = rng.choice(x, 20, replace=True) b = rng.choice(x, 20, replace=True) _, p = stats.ttest_ind(a, b) pvals.append(p) # 帰無仮説下なら p は一様分布になるはず print(f'p < 0.05 の頻度: {np.mean(np.array(pvals) < 0.05):.3f} (理論値 0.05)') |