📍 あなたが今見ているもの
論文で「α = 0.05」「有意水準5%で検定」と書かれる数字。 p値の判定基準。
有意水準 とは:「これより小さいp値なら帰無仮説を棄却する」と事前に決める閾値。慣習的に 0.05, 0.01, 0.001。
💡 30秒で分かる結論
- 定義:「これより小さい p値なら帰無仮説を棄却する」と事前に決める閾値
- 慣習:α = 0.05 が最頻出。 厳しくするなら 0.01、医学・遺伝学では 0.001 や 5×10⁻⁸ も
- 意味:第1種過誤(誤って棄却する確率)の上限
- α を小さくすると false positive↓ だが true effect も見逃しやすくなる(power↓)
- 結果を見てから α を動かすのは 厳密には禁止(事前に決める)
📖 もっと詳しく
有意水準 α は、 検定の「合否ライン」です。 「p値が α より小さければ、 偶然とは考えにくいので帰無仮説を棄却する」というルール。 慣習的に α = 0.05(5%)が最も使われますが、 厳しい検証では 0.01 や 0.001 も。
α は事前に決めるのが厳密な手順。 結果を見てから「3%なら有意」と動かすのは p-hacking の温床。
α の意味:「本当は帰無仮説が正しいのに、 誤って棄却してしまう確率」の上限(第1種の過誤)。 α を小さくすると false positive は減るが、 本物の効果も見逃しやすくなる(第2種過誤の増加)。
🎨 直感で掴む
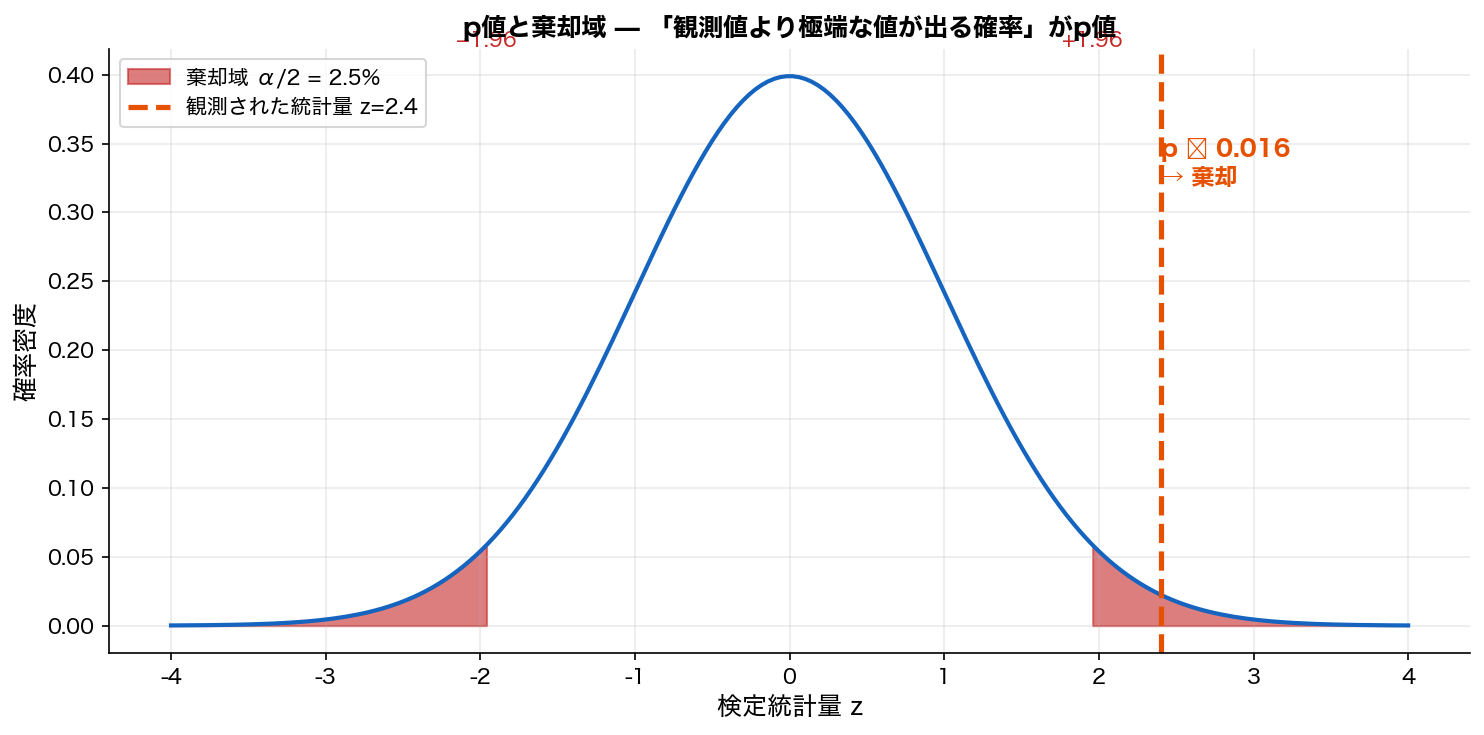
📐 数式
⚠️ よくある落とし穴
✅ 実務チェックリスト — 推測統計を使う前に
1. データの確認
- サンプルサイズ n は十分か?(n < 30 なら t分布、 非正規性に注意)
- 独立同分布の仮定は妥当か?(時系列、 クラスター構造に注意)
- 外れ値の影響を確認したか?(box plot で)
- 正規性は確認したか?(QQプロット、 Shapiro-Wilk検定)
- 欠損値の扱いは適切か?
2. 検定・推定の設計
- 仮説(H₀、 H₁)は事前に定義したか?
- 片側 vs 両側を選択しているか?
- 有意水準 α は事前に設定したか?
- 多重比較の補正は必要か?
- サンプルサイズの事前計算(power analysis)したか?
3. 結果の報告
- 点推定 + 信頼区間を併記しているか?
- p値だけでなく効果量も報告したか?
- サンプルサイズを明記したか?
- 仮定の確認結果を述べたか?
- 「統計的有意 = 実質的に重要」と混同していないか?
4. 解釈の注意
- 「相関 ≠ 因果」を意識
- シンプソンのパラドックスを警戒
- 探索的分析と確認的分析を区別
- 結果を再現できるか
📚 推測統計を学ぶための重要文献
- Fisher (1925) "Statistical Methods for Research Workers" — 古典中の古典
- Neyman & Pearson (1933) — 仮説検定の理論的基礎
- Cohen (1988) "Statistical Power Analysis" — 効果量とサンプルサイズの教科書
- ASA Statement (2016) — p値の正しい使い方
- Gelman & Hill (2007) "Data Analysis Using Regression and Multilevel/Hierarchical Models"
- Wasserman (2004) "All of Statistics" — 現代統計学の総括
🆚 推測統計の主要用語 — 一目で分かる対比表
| 用語 | 記号 | 何を測る? | 公式 |
|---|---|---|---|
| 標準偏差 | σ, s | データ1個のばらつき | √(Σ(x-x̄)²/(n-1)) |
| 標準誤差 | SE | 推定値のばらつき | σ/√n |
| 信頼区間 | CI | 真値の入る範囲 | x̄ ± z·SE |
| p値 | p | 偶然この結果が出る確率 | P(|T| ≥ |t_obs| | H₀) |
| 有意水準 | α | Type I 誤り許容率 | 通常 0.05 |
| 検出力 | 1-β | 真の差を検出する確率 | 1 - Pr(Type II error) |
| 効果量 | d, r, R² | 差の大きさ | Cohen's d = (μ₁-μ₂)/σ |
| サンプルサイズ | n | 標本数 | power analysisで決定 |
🎲 Bayes Factor — p値の代替
頻度主義の p値に対する、 ベイズ統計の対案。 「H₁ が H₀ より何倍ありそうか」を直接示します。
$$ BF_{10} = \frac{P(\text{data} | H_1)}{P(\text{data} | H_0)} $$
| BF₁₀ | 解釈 |
|---|---|
| 1〜3 | 弱い証拠 |
| 3〜10 | 中程度の証拠 |
| 10〜30 | 強い証拠 |
| >100 | 決定的証拠 |
p < 0.05 は BF ≈ 3 程度しか意味しないという議論があり、 BF を併記する研究が増えています。
🔗 有意水準と信頼区間 — 双対関係
α と CI は厳密に対応します:
- α = 0.05 → 95% CI
- α = 0.01 → 99% CI
- α = 0.10 → 90% CI
「H₀: μ = μ₀ を α 水準で棄却」 ⇔ 「(1-α)·100% CI が μ₀ を含まない」
つまり、 CI を計算するだけで、 すべての値に対する仮説検定の結果が一気に分かります。
近代統計の流れ
「有意水準で判定」より「CI を示す」方向へ。 効果量と組み合わせて、 統計的・実質的の両方を判断するのが推奨。
🌍 学問分野ごとの有意水準
| 分野 | 標準的な α | 理由 |
|---|---|---|
| 心理学・社会学 | 0.05 | 慣習 |
| 医薬品試験(FDA) | 0.05 両側 | 承認基準 |
| 高エネルギー物理 | 5σ ≈ 3×10⁻⁷ | 膨大な仮説検定があるため |
| GWAS | 5×10⁻⁸ | 100万SNPの多重比較 |
| 経済学 | 0.05〜0.10 | サンプル取得困難 |
| 産業の品質管理 | 6σ | 致命的欠陥防止 |
🚧 有意水準の落とし穴
1️⃣ 慣習的な0.05 への盲信
0.05 はあくまで慣習で、 数学的・統計学的根拠はありません。 Fisher は柔軟に使うことを意図していました。 文脈に応じて変えるべき。
2️⃣ p < 0.05 vs p = 0.06
0.049 と 0.051 はほぼ同じ証拠の強さ。 機械的に「有意/非有意」と分けるのは過度な単純化。
3️⃣ p値で効果の重要性は分からない
巨大データでは小さな効果でも p < 0.05 に。 効果量と組み合わせて評価を。
4️⃣ 多重比較の補正忘れ
10個の検定を α = 0.05 で行うと、 偶然に有意になる確率は約40%。 必ず補正を。
5️⃣ 検出力不足の研究
n が小さいと、 真の効果を見逃す(Type II 誤り)。 「有意ではない」が「効果がない」とは限らない。
6️⃣ 事後の有意水準変更
結果を見てから α を変えるのは禁忌。 必ず事前に決定。
📜 有意水準の歴史
- Fisher (1925): 「Statistical Methods for Research Workers」で 0.05 を「便利な区切り」として紹介
- Neyman & Pearson (1933): 有意水準と検出力を体系化
- Cohen (1988): 効果量の重要性を強調、 検出力解析の体系化
- Ioannidis (2005): 「ほとんどの発表された研究は誤り」論文で再現性危機を予言
- ASA Statement (2016): 「p < 0.05 = 有意」の機械的判定を批判
- Benjamin et al. (2018): α = 0.005 への厳格化を提案
- Amrhein et al. (2019): Nature で「統計的有意」廃止を提案
「0.05 の慣習」が見直され続ける現代統計学の混乱と発展。
💼 実務での有意水準 — 業界別の使い方
① 医療臨床試験
新薬承認には、 通常 α = 0.05 両側で「プラセボより有意に効果がある」を示す必要。 効果量と CI も併記。 安全性検定は α = 0.01 などより厳しく。
② A/B テスト(マーケティング)
α = 0.05 が標準。 ただし「あれもこれも有意」になりがちなため、 効果量(lift)も重視。 Type I より Type II(機会損失)を気にする傾向。
③ 物理学(粒子発見)
5σ ルール: 5 標準偏差を超える信号でないと「発見」とは認めない(p ≈ 3×10⁻⁷)。 ヒッグス粒子の発見(2012年)でも 5σ。
④ 心理学・教育学
従来 α = 0.05 が慣習。 再現性危機を受けて、 事前登録(pre-registration)が急速に普及。
⑤ 機械学習
従来は仮説検定をあまり使わなかったが、 近年は「複数モデルの比較」に McNemar 検定や CV スコアの t検定が使われる。
🎯 有意水準のまとめ
💡 有意水準 α は「許容するTypeI誤り率」。 通常 0.05 を採用するが、 これは便宜的な慣習で、 分野や目的により変えるべき。 検出力 1-β、 効果量、 信頼区間と合わせて使うのが現代統計の標準。 p < α だけで判断する時代は終わりつつある。
🐍 Python での有意水準と検定
① 基本的な検定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | from scipy import stats # 1標本 t検定 t, p = stats.ttest_1samp(data, popmean=0) alpha = 0.05 if p alpha: print(f"棄却: p={p:.4f} {alpha}") else: print(f"不棄却: p={p:.4f} ≥ α={alpha}") # 2標本 t検定(独立) t, p = stats.ttest_ind(group1, group2) # 対応のあるt検定 t, p = stats.ttest_rel(before, after) # Welch t検定(不等分散) t, p = stats.ttest_ind(g1, g2, equal_var=False) |
② 多重比較補正
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | from statsmodels.stats.multitest import multipletests p_values = [0.001, 0.01, 0.03, 0.04, 0.10, 0.20] # Bonferroni reject, p_adj, _, _ = multipletests(p_values, alpha=0.05, method='bonferroni') # Benjamini-Hochberg (FDR) reject, p_adj, _, _ = multipletests(p_values, alpha=0.05, method='fdr_bh') # Holm reject, p_adj, _, _ = multipletests(p_values, alpha=0.05, method='holm') for p_orig, p_a, rej in zip(p_values, p_adj, reject): print(f'p={p_orig:.3f} → 補正後 p={p_a:.3f}, 棄却={rej}') |
③ 検出力解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | from statsmodels.stats.power import TTestIndPower analyzer = TTestIndPower() # 検出可能な効果量を計算 effect = analyzer.solve_power(nobs1=50, alpha=0.05, power=0.80) print(f'検出可能な最小効果量: {effect:.3f}') # 必要なサンプルサイズ n = analyzer.solve_power(effect_size=0.3, alpha=0.05, power=0.80) print(f'必要n(各群): {n:.0f}') # 与えられた条件での検出力 power = analyzer.solve_power(effect_size=0.5, nobs1=30, alpha=0.05) print(f'検出力: {power:.3f}') |
🗺️ 概念マップ — 3つの視点で体系を理解する
有意水準 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 推測統計 › 検定 › 有意水準
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「有意水準」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「有意水準」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引 — 拡張版
有意水準(significance level)に関する用語を、 誤り種類・補正・代替論 別に索引化します。
| カテゴリ | キーワード(日本語) | キーワード(英語) |
|---|---|---|
| 基本概念 | 有意水準、 α、 棄却域、 臨界値、 片側/両側 | significance level, alpha, critical region, one/two-sided |
| 誤り種類 | 第一種の誤り、 第二種の誤り、 検出力(1−β)、 偽陽性率 | Type I, Type II, power, false positive rate |
| 多重比較補正 | Bonferroni補正、 Holm法、 BH法(FDR)、 Šidák、 Hochberg | Bonferroni, Holm, BH, FDR, Šidák |
| 関連指標 | p値、 信頼区間、 効果量、 ベイズファクター | p-value, CI, effect size, Bayes factor |
| 代替論 | 事前登録、 再現性、 信頼性、 p-hacking、 HARKing | preregistration, replication, p-hacking, HARKing |
| 実装関数 | scipy.stats、 statsmodels、 pingouin、 multipletests | scipy.stats, statsmodels, pingouin, multipletests |
🧮 SSDSE-B で有意水準を学ぶ — 実値計算例
SSDSE-B から「都道府県別の平均所得」を使い、 全国平均との差をt検定で評価します。
① 例:北海道の平均所得は全国平均と異なるか
H₀(帰無仮説):北海道の母平均 = 全国平均(μ₀ = 304万円)
H₁(対立仮説):北海道の母平均 ≠ 全国平均
標本平均 x̄ = 290、 SD = 35、 n = 10 とすると
t = (290 − 304) / (35 / √10) = −1.265
自由度 9、 両側p値 ≈ 0.237
α = 0.05 で 棄却できない(差は確認できない)
② 有意水準による判定の変化
| α | 臨界値 t (df=9) | 判定 | 第一種の誤り率 |
|---|---|---|---|
| 0.01 | ±3.25 | 不棄却 | 1% |
| 0.05 | ±2.26 | 不棄却 | 5% |
| 0.10 | ±1.83 | 不棄却 | 10% |
③ 多重比較の例(47都道府県を全国平均と比較)
47回の検定を α=0.05 で行うと、 偶然有意になる回数の期待値は 47×0.05 ≈ 2.35回。
Bonferroni 補正後の有意水準 = 0.05/47 ≈ 0.00106
BH法(FDR=5%):p値を昇順に並べ、 p₍ₖ₎ ≤ k/47 × 0.05 となる最大 k までを有意とする。
⚠️ 有意水準の落とし穴 — 拡張版(実務で本当に困る5+件)
- α=0.05 は絶対的な基準ではない:0.05 は Fisher が便宜的に提案した値で、 学問分野や状況によって 0.01、 0.001、 5σ(粒子物理学)など使い分けるべき。 創薬や安全工学では 0.01 以下、 探索的研究では 0.10 で柔軟に。 「p<0.05」が「真実」を意味するわけではない。 American Statistical Association は2016年に「単純な閾値判定からの脱却」を提言している。
- 多重検定問題(multiple testing):同じデータで多数の検定を行うと、 偶然有意なものが必ず混じる。 例えば100個の独立検定で α=0.05 なら、 5個は偶然有意に。 Bonferroni(α/m)、 Holm法、 BH法(FDR制御)などの補正を必須に。 オミックスやA/Bテストで特に注意。
- p-hacking(p値操作):データを取り続けて有意になるまで検定を繰り返す、 サブグループを試して有意なものだけ報告する、 共変量を選んで有意になる組合せを探す。 これらは 第一種の誤り率を大幅に膨らませる。 事前登録(preregistration)や解析計画書を予め策定することで防ぐ。
- 大標本での「常に有意」問題:n が十分大きいと、 実質的に意味のない小さな差でも有意になる(p値は標本サイズに依存)。 必ず効果量(Cohen's d、 r、 odds比など)と信頼区間を併記する。 「統計的有意 ≠ 実質的に重要」を常に意識。
- p>0.05 を「差がない」と誤解:p>0.05 は 「H₀ を棄却するに足る証拠がない」 だけで、 「H₀ が正しい」「差がない」とは言えない。 検出力不足(n が小さい)の可能性もある。 「証拠なし」と「不在の証拠」の区別を。 等価性検定(TOST)が「差がない」ことを示すには有用。
- 片側検定 vs 両側検定の選択:方向性が事前に確定している場合のみ片側検定を使う。 結果を見てから片側に変えると α が実質倍になる。 デフォルトは両側、 片側を使うなら事前にプロトコルに明記する。
- 群間検定の独立性違反:同じ被験者で複数回測定したデータに通常のt検定を使うと、 独立性仮定が破れて p値が小さく出すぎる。 対応のあるt検定や混合効果モデルを使う。
🐍 Python 実装バリエーション — scipy / statsmodels / pingouin / 多重補正
① scipy.stats(基本のt検定)
1 2 3 4 5 6 7 8 9 10 11 | import pandas as pd from scipy.stats import ttest_1samp, t df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) sample = df[df['都道府県'] == '北海道']['平均所得'] # 仮定の系列 stat, p = ttest_1samp(sample, popmean=304) alpha = 0.05 crit = t.ppf(1 - alpha/2, df=len(sample)-1) print(f't={stat:.3f}, p={p:.4f}, 臨界値=±{crit:.3f}') print('棄却' if abs(stat) > crit else '不棄却') |
② statsmodels(信頼区間・効果量つき)
1 2 3 4 5 6 | from statsmodels.stats.weightstats import DescrStatsW desc = DescrStatsW(sample) print('mean:', desc.mean) print('95% CI:', desc.tconfint_mean(alpha=0.05)) print('t統計量, p値:', desc.ttest_mean(value=304)) |
③ pingouin(効果量・ベイズも自動)
1 2 3 | import pingouin as pg res = pg.ttest(sample, 304, alternative='two-sided') print(res) # T, dof, p-val, CI95%, cohen-d, BF10, power |
④ 多重比較補正
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from statsmodels.stats.multitest import multipletests from scipy.stats import ttest_1samp import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2024.csv', encoding='shift_jis', skiprows=1) pvals = [] for pref, g in df.groupby('都道府県'): _, p = ttest_1samp(g['平均所得'], 304) pvals.append(p) # Bonferroni 補正 rej_b, padj_b, _, _ = multipletests(pvals, alpha=0.05, method='bonferroni') # BH法 (FDR) rej_bh, padj_bh, _, _ = multipletests(pvals, alpha=0.05, method='fdr_bh') # Holm法 rej_h, padj_h, _, _ = multipletests(pvals, alpha=0.05, method='holm') print('Bonferroni 棄却数:', rej_b.sum()) print('BH (FDR) 棄却数 :', rej_bh.sum()) print('Holm 棄却数 :', rej_h.sum()) |
⑤ 検出力分析(事前のサンプルサイズ計算)
1 2 3 4 5 6 | from statsmodels.stats.power import TTestPower # α=0.05, 検出力=0.8, 効果量 d=0.5 → 必要n analysis = TTestPower() n = analysis.solve_power(effect_size=0.5, alpha=0.05, power=0.8) print(f'必要サンプルサイズ: {n:.1f}') |
⑥ 等価性検定(TOST:差がないことの主張)
1 2 3 4 | from statsmodels.stats.weightstats import ttost_ind # 2群が「実質的に同じ」と主張するための片側2回検定 p, _, _ = ttost_ind(group1, group2, low=-5, upp=5) print('TOST p値:', p) # p<0.05 で「等価」 |
