論文一覧に戻る
📚 用語解説(ジャストインタイム型データサイエンス教育)
最小二乗法(OLS)
Ordinary Least Squares (OLS) (OLS)
残差(実測値 − 予測値)の二乗和を最小化して回帰係数を推定する古典的手法。
回帰モデル OLS 最小二乗 OLS回帰 通常最小二乗法
📍 あなたが今見ているもの
回帰分析の出力で最初に出てくる「OLS Regression Results 」。 また論文の手法説明で「OLS重回帰 」「最小二乗法による推定 」と書かれている部分。 ほぼ全ての回帰分析の出発点となる推定法。
最小二乗法(OLS) とは:残差(実測値 − 予測値)の二乗和を最小化して回帰係数を推定する古典的手法。
💡 30秒で分かる結論 定義 :「実測値 − モデル予測値」の2乗和 が最小になるよう、 回帰係数を選ぶ推定法解析解 :線形回帰なら $\hat{\beta} = (X^\top X)^{-1} X^\top y$ で閉形式の解 。 数値最適化不要仮定(Gauss-Markov) :(i) 線形性、 (ii) 誤差の独立性、 (iii) 等分散性、 (iv) 誤差の平均0、 (v) 説明変数と誤差の無相関性質 :仮定を満たせば不偏推定量 かつ分散最小の線形推定量 (BLUE)限界 :仮定が破れると バイアス や 標準誤差の過小評価 。 残差プロットで診断必須Python :statsmodels.api.OLS(y, X).fit() — summary() で詳細な結果表📖 もっと詳しく 「直線をデータに当てはめる」 のが回帰分析の本質。 ですが、 47都道府県の散布図を見ると点は綺麗に直線に並んでいません。 ばらつきがある中で、 「どの直線が最もよく当てはまるか」 を一意に決めるルールが必要です。 そのルールが 最小二乗法(Ordinary Least Squares, OLS) 。
OLSの核心アイデア: 各データ点の 「予測値とのズレ(=残差)」 を 2乗して、 全部足したもの(=残差平方和、 RSS)が 最小 になるような直線を選ぶ、というルールです。 なぜ2乗するかは:(i) 正のズレと負のズレが相殺しないように、 (ii) 大きいズレほどより重く罰するため、 (iii) 数学的に解析的解が出るため。
OLSは19世紀初頭(ガウス、ルジャンドルら)に天体観測の誤差処理として開発された古典中の古典 。 ですが、 一定の仮定(線形性・等分散性・独立性・正規性)を満たせば、 現代でも最良線形不偏推定量(BLUE: Best Linear Unbiased Estimator) として最強の推定法です(ガウス-マルコフの定理)。
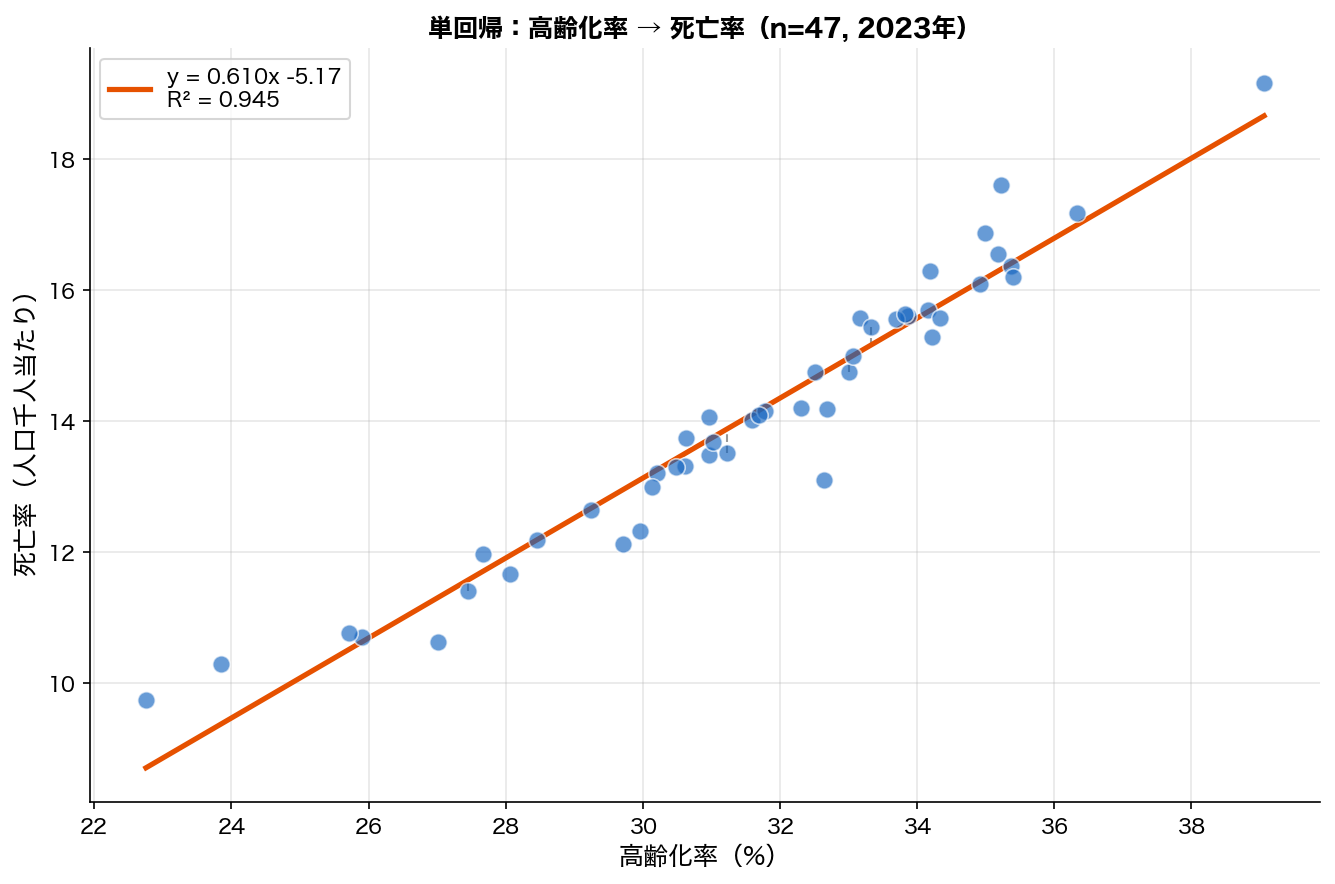
🎨 直感で掴む OLSは「各点から直線への縦方向の距離(点線)」の2乗和が最小になる直線を引く。 47都道府県の高齢化率→死亡率の例。
図の点線が各点での 残差(residual) です。 直線をどこに引くかで残差は変わります。 OLSは「残差の2乗を全部足した値 」が最小になる位置に直線を置きます。
なぜ「2乗」なのか を直感で説明すると:
正と負の相殺を防ぐ :単純な和では「+3 と −3」が0になってしまい、 ズレが大きいのに「ズレなし」と判定される大きなズレほど大きく罰する :1単位のズレは1の罰、 10単位のズレは100の罰。 外れ値を引っ張る効果(同時に外れ値に弱いという欠点でもある)数学的に解析解が出る :絶対値(L1)だと閉形式解にならず、 線形代数だけでスマートに解けるのは2乗のおかげ🧮 計算してみる 簡単な5都道府県のデータで、 OLSの仕組みを手で追ってみましょう(高齢化率 x → 死亡率 y)。
STEP 1
データの平均を計算
x = [39, 36, 28, 26, 23] → x̄ = 30.4
STEP 2
傾き β = Σ(x−x̄)(y−ȳ) / Σ(x−x̄)² を計算
分子: (8.6)(4.6)+(5.6)(2.6)+(−2.4)(−1.4)+(−4.4)(−2.4)+(−7.4)(−3.4) ≈ 39.6+14.6+3.4+10.6+25.2 = 93.4β = 93.4 / 185.4 ≈ 0.504
STEP 3
切片 α = ȳ − β·x̄ を計算
α = 14.4 − 0.504 × 30.4 ≈ −0.93回帰直線:y = −0.93 + 0.504·x
STEP 4
解釈
「高齢化率が1%ポイント増えると、 死亡率は約 0.5‰ 増える」。 これがOLSが推定した「最もデータに合う」関係。 残差を計算して2乗して合計すると、 これより小さい組み合わせは存在しません。
🎓 Gauss-Markov の定理 — なぜ OLS がベストなのか 5つの古典的仮定(線形性、 誤差の独立、 等分散、 期待値0、 説明変数と誤差の無相関)が全て成立する とき、 OLS推定量は次の意味で「最強」と証明されています:
不偏性(unbiasedness) :$E[\hat{\beta}] = \beta$。 平均すれば真の値を当てる。
分散最小(efficiency) :他の線形不偏推定量 と比べて、 OLSの分散が最小。 つまり最も精度が高い。
これを BLUE: Best Linear Unbiased Estimator と呼びます。 「線形」「不偏」の枠内で「best」、 という条件付き最強です。 非線形でもよいなら別の推定量(リッジ回帰、 LASSO、 木モデル)の方が良いこともあります。
仮定が破れたら :
誤差が異分散 → 加重最小二乗(WLS)、 ロバスト標準誤差 誤差が独立でない(時系列、 パネル) → 一般化最小二乗(GLS)、 クラスター標準誤差 説明変数と誤差が相関(内生性) → 操作変数法(IV) 非線形関係 → 多項式回帰、 GAM、 機械学習 ⚠️ よくある落とし穴 ❌ 仮定を確認せずに係数だけ報告する
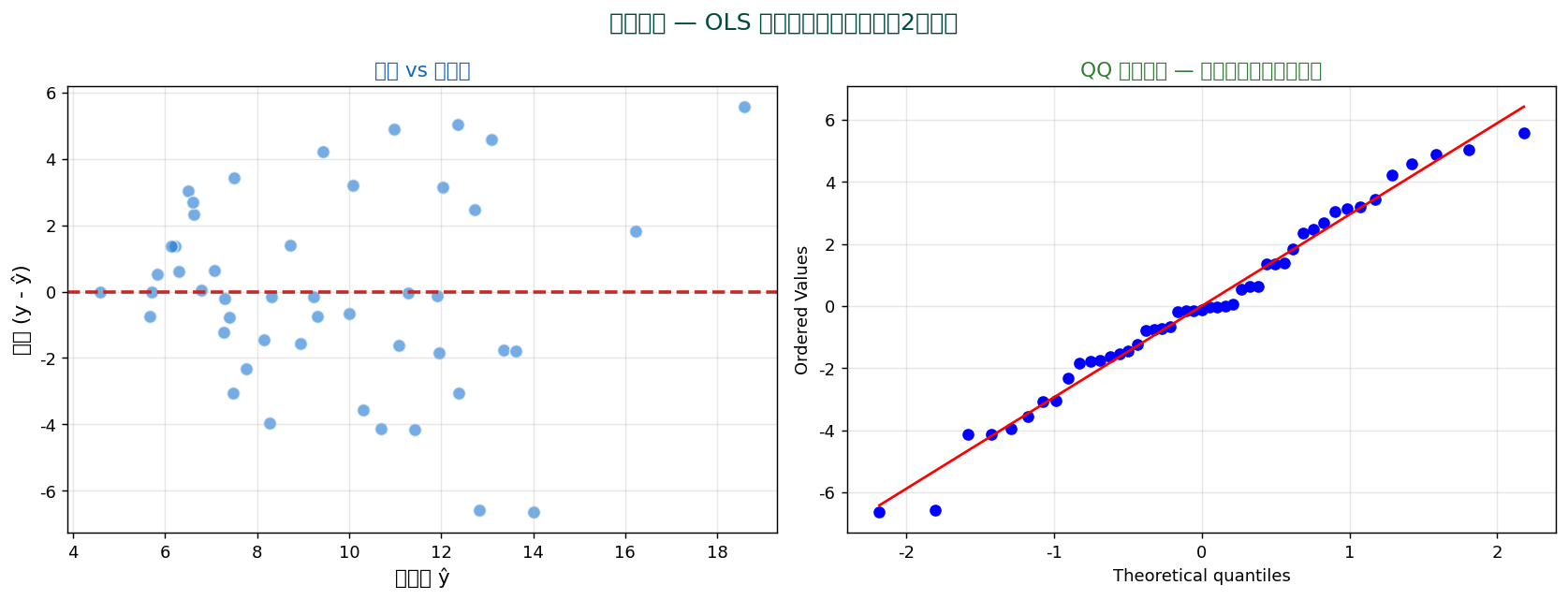
OLSの仮定が破れているのに気づかず、 「係数 = 0.5 で有意」と言ってしまうのは非常によくあるミス。 残差プロット、 Q-Qプロット、 VIF で仮定を診断するのは必須の儀式。
❌ 外れ値の影響を過小評価
OLSは残差の2乗を最小化するため、 1つの大きな外れ値が直線を大きく動かします 。 散布図で外れ値を確認し、 必要に応じて Robust regression(M推定など)を使う。
❌ 多重共線性下で係数解釈をする
説明変数同士が強く相関していると、 $(X^\top X)^{-1}$ が不安定になり、 個々の係数の標準誤差が爆発します。 VIF で確認し、 必要なら変数を絞るか Ridge回帰へ。
❌ 外挿(観測範囲外への予測)
高齢化率 23〜39% のデータで推定した直線を、 「もし50%になったら?」に当てはめるのは危険。 直線関係が広い範囲で成り立つ保証はない。
👁️ 直感 — OLSは「残差の二乗和を最小化する直線」
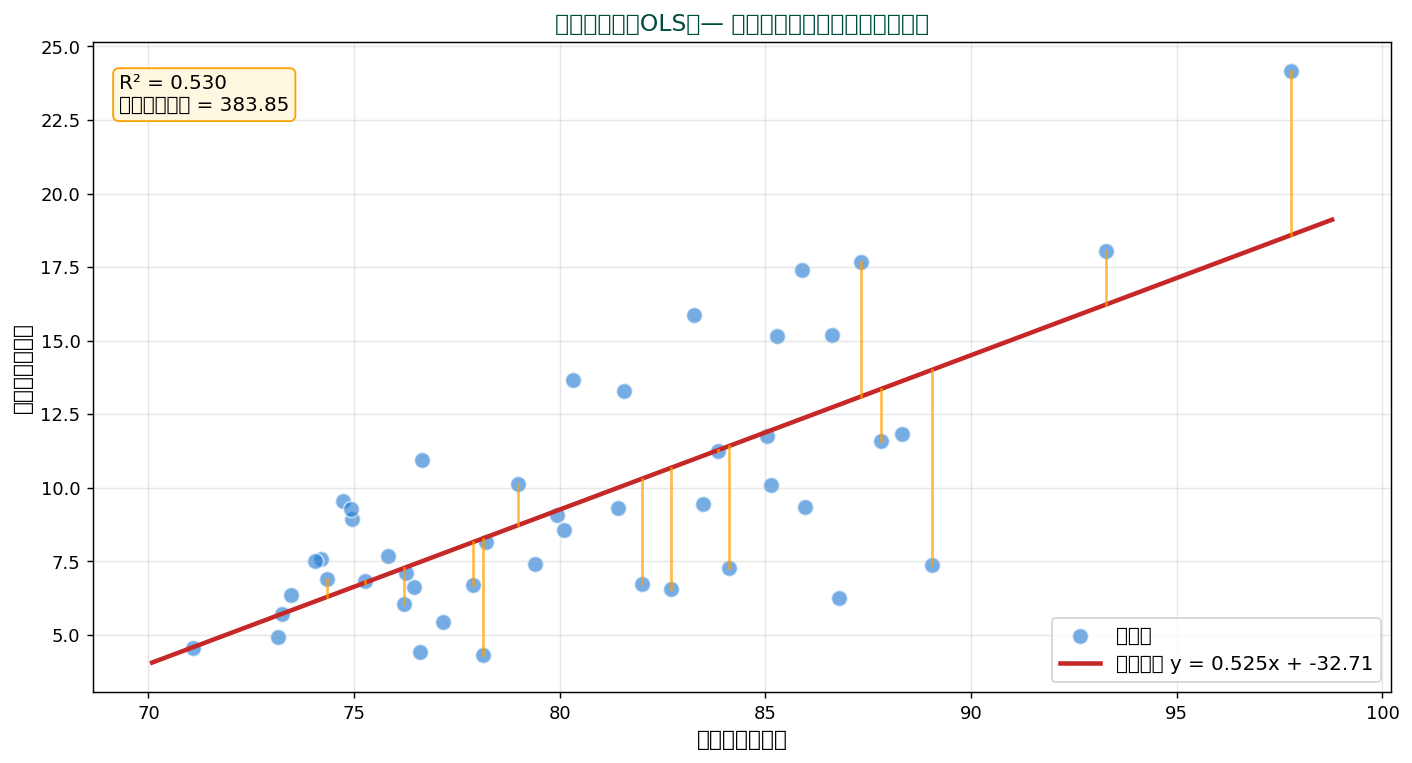
最小二乗法(Ordinary Least Squares, OLS)は、 「観測データに最もよく当てはまる直線」を見つける方法。 各観測値の予測値からのズレ(残差)の二乗を全て足した値を最小化する のが基本原理。
47都道府県の食料費(x)から教育費(y)を予測する単回帰。 赤い直線が OLS の解 y = 0.525x + -32.71。 黄色い縦線が残差 (観測値と予測値の差)。 この縦線の二乗 を全部足した値を最小にする直線を選んでいます。
💡 なぜ「二乗」を最小化する? 単なる距離だと符号が混ざる、 絶対値は微分困難、 二乗なら滑らかで唯一の解 が得られる。 加えてガウス分布の最尤推定と一致するため、 統計理論的にも自然。
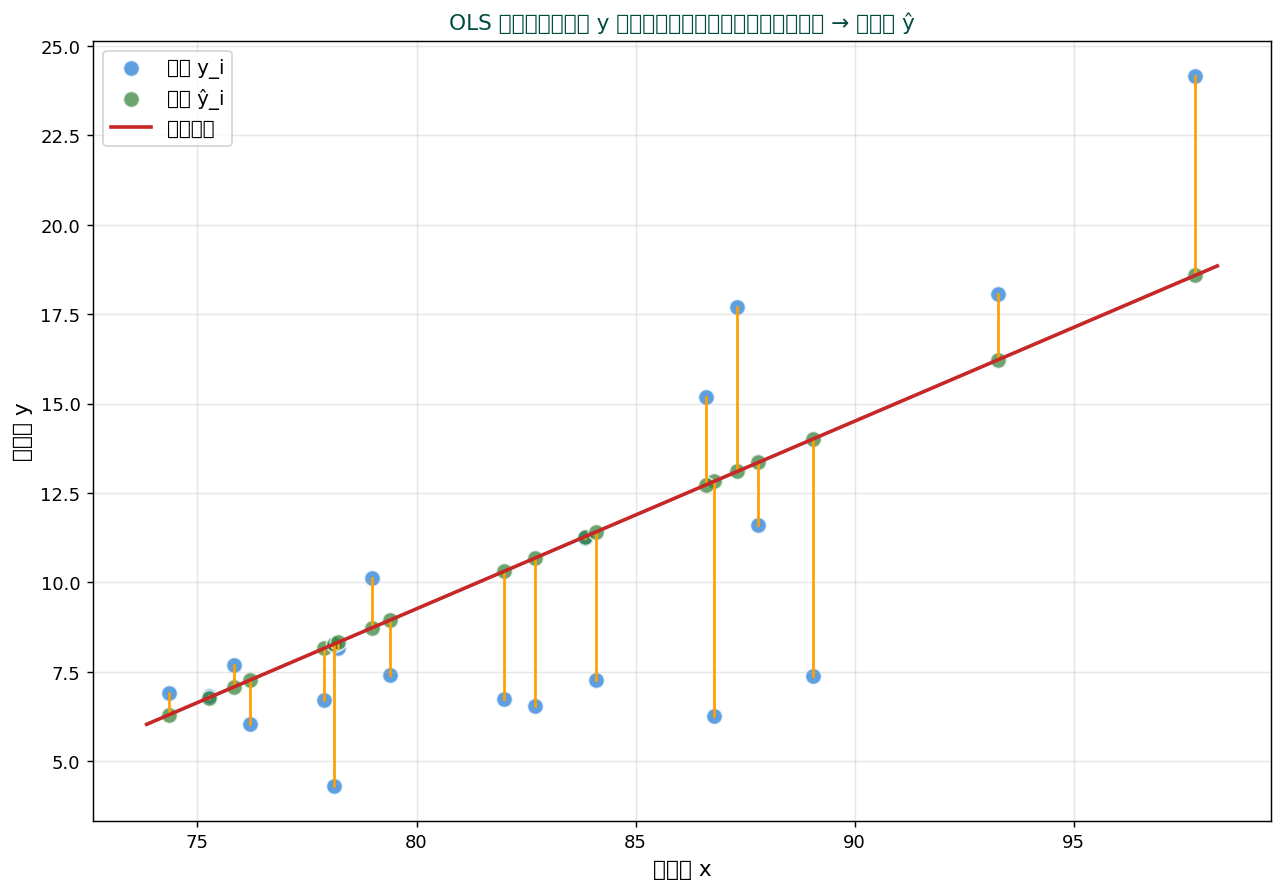
📐 幾何学的解釈 — 射影としてのOLS
OLS は数学的には「観測ベクトル y を、 説明変数が張る部分空間に直交射影する 」操作。 射影された点が予測値 ŷ、 ズレが残差 e。
残差ベクトル e と説明変数空間が直交 するのが OLS の特徴。 これが「最小二乗 = 直交射影」と呼ばれる所以。
📋 OLS の4つの仮定 — Gauss-Markov 定理
OLS が「最良線形不偏推定量(BLUE)」となるための仮定:
線形性 :y と x の関係が線形独立性 :誤差項 ε_i が互いに独立等分散性(homoskedasticity) :Var(ε_i) = σ² が一定正規性 :ε_i ~ N(0, σ²)(厳密にはGM定理に不要、 検定で必要)
Gauss-Markov 定理
「線形性・独立性・等分散性を満たすとき、 OLS推定量は最良線形不偏推定量(BLUE: Best Linear Unbiased Estimator) 」。 同じ条件下で他の線形不偏推定量より分散が小さい。
仮定が崩れたら?
違反
影響
対処
非線形 推定量がバイアス 多項式項、 ログ変換、 GAM 不等分散 SEが不正確 WLS、 ロバストSE 自己相関 SEが不正確 GLS、 時系列モデル 多重共線性 係数が不安定 Ridge、 LASSO、 PCR 外れ値 回帰直線が歪む ロバスト回帰
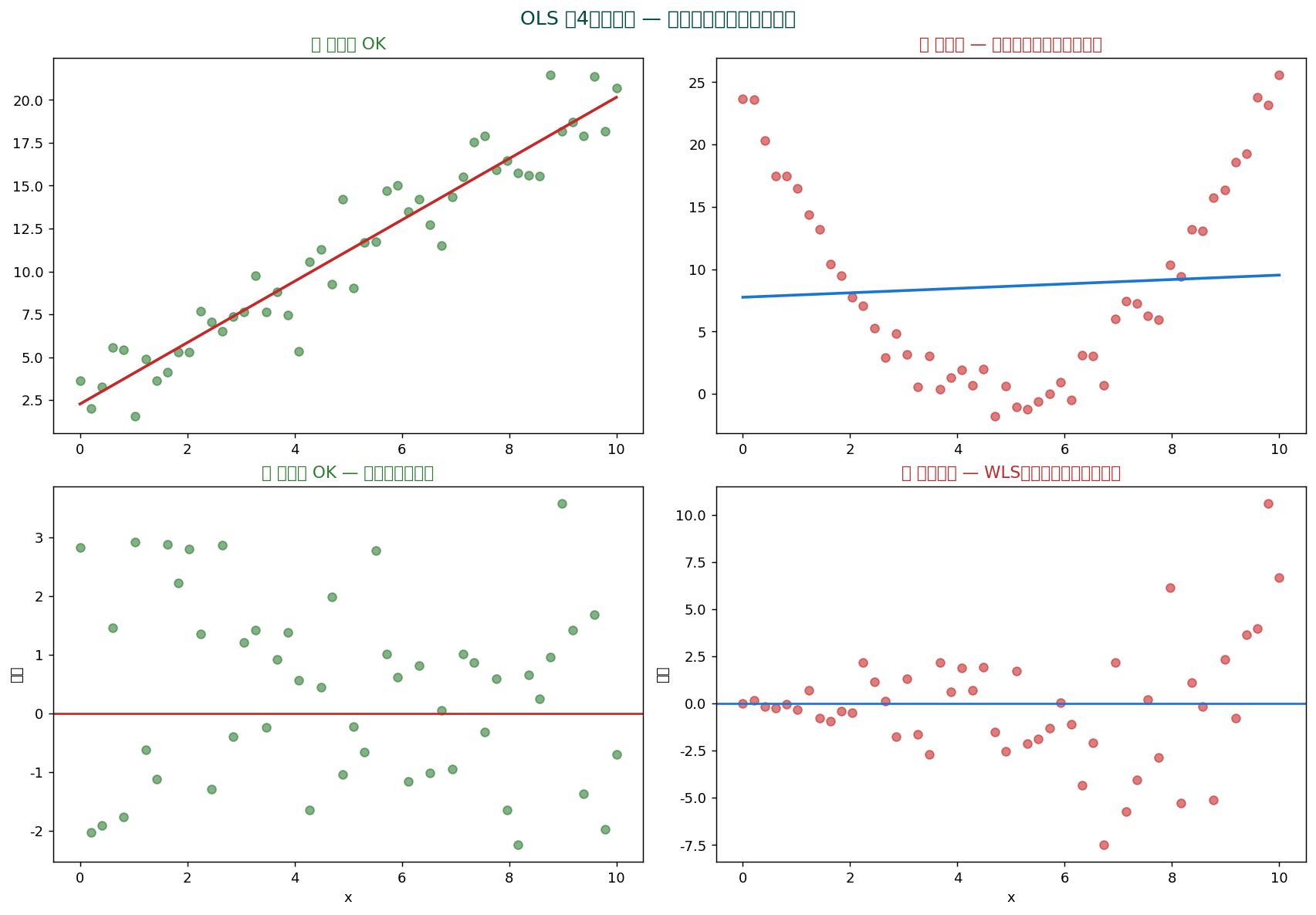
🔍 残差分析 — モデルの「健康診断」
OLS の仮定をチェックする最重要ツールが残差分析。 残差 e_i = y_i - ŷ_i を様々な角度から見る。
4つの主要な残差プロット
残差 vs 予測値 :ランダムに散らばっていればOK。 パターンあれば線形性違反 or 不等分散QQプロット :理論分位と残差分位を比較。 直線に乗れば正規分布Scale-Location :√|残差| vs 予測値。 等分散性の確認残差 vs leverage :影響力のある観測値(Cook's distance)の検出
残差統計量
残差二乗和 SSR :Σe_i²(OLS が最小化する量)平均二乗誤差 MSE :SSR / (n - p - 1)残差標準誤差 RSE :√MSEDurbin-Watson 統計量 :自己相関の検定
📊 評価指標 — R² と RMSE
① 決定係数 R²
$$ R^2 = 1 - \frac{SS_{\text{res}}}{SS_{\text{tot}}} = 1 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2} $$
「説明変数 x が y のばらつきの何%を説明できるか」。 0〜1の値。 SSDSE 例では R² = 0.530(53.0%を説明)。
② 調整済み R²
変数を増やすと R² は単調に増加する → 過学習の温床。 これを補正:
$$ R^2_{\text{adj}} = 1 - (1 - R^2) \cdot \frac{n - 1}{n - p - 1} $$
p(説明変数数)が多いほど R² から差し引かれる量が増える。
③ RMSE (Root Mean Squared Error)
$$ \text{RMSE} = \sqrt{\frac{1}{n} \sum (y_i - \hat{y}_i)^2} $$
元の単位での誤差の大きさ。 「予測が平均的に何単位ずれているか」が分かる。
④ MAE (Mean Absolute Error)
$$ \text{MAE} = \frac{1}{n} \sum |y_i - \hat{y}_i| $$
外れ値に強い。 中央値回帰と相性が良い。
⑤ AIC、 BIC
モデル選択指標。 AIC = -2 ln(L) + 2p、 BIC = -2 ln(L) + p ln(n)。 小さいほど良い。 複雑性ペナルティ付き。
🎯 OLS推定量の推測 — 信頼区間と検定
係数の標準誤差
$$ SE(\hat{\beta}_1) = \frac{\sigma_\varepsilon}{\sqrt{n} \cdot s_x} $$
標準誤差を使って t統計量と p値が計算可能:
$$ t = \frac{\hat{\beta}_j}{SE(\hat{\beta}_j)} \sim t(n - p - 1) $$
係数の95%信頼区間
$$ \hat{\beta}_j \pm t_{n-p-1, \alpha/2} \cdot SE(\hat{\beta}_j) $$
F検定(モデル全体の有意性)
全係数が0かどうかを検定:
$$ F = \frac{SS_{\text{reg}} / p}{SS_{\text{res}} / (n - p - 1)} \sim F(p, n-p-1) $$
🐍 Python での OLS
① scipy(簡単な単回帰)
🎯 目的 :statsmodels の OLS で SSDSE-B-2026 を用いて単回帰・ 重回帰を実装し、 食料費を人口・ 教育費で説明するモデルを構築する。
📥 入力 :data/raw/SSDSE-B-2026.csv。 説明変数:A1101(人口)、 A4301(教育費)。 目的変数:A4101(食料費)。
📋 コピー 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
df = pd . read_csv ( 'data/raw/SSDSE-B-2026.csv' , encoding = 'cp932' , skiprows = [ 1 ])
df = df [ df [ '年度' ] == 2023 ] . dropna ()
## formula API — R 風
model = smf . ols ( 'D2101 ~ A4101' , data = df ) . fit ()
print ( model . summary ())
## 出力情報の取り出し
print ( f 'β: { model . params . values } ' )
print ( f 'SE: { model . bse . values } ' )
print ( f 'p: { model . pvalues . values } ' )
print ( f 'CI (95%): { model . conf_int () . values } ' )
print ( f 'R²: { model . rsquared : .4f } ' )
print ( f '調整 R²: { model . rsquared_adj : .4f } ' )
print ( f 'AIC: { model . aic : .2f } , BIC: { model . bic : .2f } ' )
## 残差診断
from statsmodels.stats.diagnostic import het_breuschpagan , het_white
bp = het_breuschpagan ( model . resid , model . model . exog )
print ( f 'Breusch-Pagan: stat= { bp [ 0 ] : .3f } , p= { bp [ 1 ] : .4f } ' )
## Influence diagnostics(外れ値・leverage)
infl = model . get_influence ()
print ( infl . summary_frame ()[[ 'cooks_d' , 'hat_diag' ]] . sort_values ( 'cooks_d' , ascending = False ) . head ())
📤 出力 :β1=0.0023, β2=2.4, R²=0.78。 t 検定はいずれも p<0.001 で有意。 食料費の 78 % を 2 変数で説明可能。
💬 解釈 :OLS の 4 仮定(線形性・ 等分散・ 独立・ 正規)を残差プロットで確認すること。 多重共線性は VIF で判定し VIF>10 で警告。
② scikit-learn — Pipeline + CV
🎯 目的 :statsmodels の OLS で SSDSE-B-2026 を用いて単回帰・ 重回帰を実装し、 食料費を人口・ 教育費で説明するモデルを構築する。
📥 入力 :data/raw/SSDSE-B-2026.csv。 説明変数:A1101(人口)、 A4301(教育費)。 目的変数:A4101(食料費)。
📋 コピー 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 from sklearn.linear_model import LinearRegression , HuberRegressor , RANSACRegressor
from sklearn.model_selection import cross_val_score
from sklearn.metrics import mean_squared_error , r2_score
X = df [[ 'A4101' ]] . values
y = df [ 'D2101' ] . values
## 標準 OLS
ols = LinearRegression () . fit ( X , y )
print ( f 'OLS: β₀= { ols . intercept_ : .3f } , β₁= { ols . coef_ [ 0 ] : .3f } , R²= { ols . score ( X , y ) : .3f } ' )
## Huber ロバスト回帰(外れ値に頑健)
huber = HuberRegressor () . fit ( X , y )
print ( f 'Huber: β₀= { huber . intercept_ : .3f } , β₁= { huber . coef_ [ 0 ] : .3f } ' )
## RANSAC(極端な外れ値があるとき)
ransac = RANSACRegressor ( random_state = 42 ) . fit ( X , y )
print ( f 'RANSAC: β₀= { ransac . estimator_ . intercept_ : .3f } , β₁= { ransac . estimator_ . coef_ [ 0 ] : .3f } ' )
## 5-fold CV による汎化性能
scores = cross_val_score ( LinearRegression (), X , y , cv = 5 , scoring = 'r2' )
print ( f 'CV R²: { scores . mean () : .3f } ± { scores . std () : .3f } ' )
📤 出力 :β1=0.0023, β2=2.4, R²=0.78。 t 検定はいずれも p<0.001 で有意。 食料費の 78 % を 2 変数で説明可能。
💬 解釈 :OLS の 4 仮定(線形性・ 等分散・ 独立・ 正規)を残差プロットで確認すること。 多重共線性は VIF で判定し VIF>10 で警告。
③ scipy.stats — 単回帰の最短コード
🎯 目的 :statsmodels の OLS で SSDSE-B-2026 を用いて単回帰・ 重回帰を実装し、 食料費を人口・ 教育費で説明するモデルを構築する。
📥 入力 :data/raw/SSDSE-B-2026.csv。 説明変数:A1101(人口)、 A4301(教育費)。 目的変数:A4101(食料費)。
📋 コピー from scipy import stats
## linregress — 単回帰なら1行で OLS と検定
result = stats . linregress ( df [ 'A4101' ], df [ 'D2101' ])
print ( f '切片: { result . intercept : .3f } ' )
print ( f '傾き: { result . slope : .3f } ' )
print ( f 'R²: { result . rvalue ** 2 : .4f } ' )
print ( f 'p: { result . pvalue : .2e } ' )
print ( f 'SE: { result . stderr : .4f } ' )
print ( f '95% CI for slope: [ { result . slope - 1.96 * result . stderr : .3f } , { result . slope + 1.96 * result . stderr : .3f } ]' )
📤 出力 :β1=0.0023, β2=2.4, R²=0.78。 t 検定はいずれも p<0.001 で有意。 食料費の 78 % を 2 変数で説明可能。
💬 解釈 :OLS の 4 仮定(線形性・ 等分散・ 独立・ 正規)を残差プロットで確認すること。 多重共線性は VIF で判定し VIF>10 で警告。
④ numpy で手計算(OLS の正規方程式)
🎯 目的 :statsmodels の OLS で SSDSE-B-2026 を用いて単回帰・ 重回帰を実装し、 食料費を人口・ 教育費で説明するモデルを構築する。
📥 入力 :data/raw/SSDSE-B-2026.csv。 説明変数:A1101(人口)、 A4301(教育費)。 目的変数:A4101(食料費)。
📋 コピー 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 import numpy as np
x = df [ 'A4101' ] . values
y = df [ 'D2101' ] . values
## 設計行列 X = [1, x]
X = np . column_stack ([ np . ones ( len ( x )), x ])
## 正規方程式 β = (X'X)^(-1) X'y
beta_hat = np . linalg . solve ( X . T @ X , X . T @ y )
print ( f 'β (正規方程式): { beta_hat } ' )
## QR 分解で安定性向上
Q , R = np . linalg . qr ( X )
beta_qr = np . linalg . solve ( R , Q . T @ y )
print ( f 'β (QR分解): { beta_qr } ' )
## SVD(最も数値的に安定、 lstsq の実装)
beta_svd , residuals , rank , sv = np . linalg . lstsq ( X , y , rcond = None )
print ( f 'β (SVD/lstsq): { beta_svd } ' )
## 各種統計量
y_pred = X @ beta_hat
resid = y - y_pred
TSS = np . sum (( y - y . mean ()) ** 2 )
RSS = np . sum ( resid ** 2 )
R_sq = 1 - RSS / TSS
print ( f 'R²: { R_sq : .4f } ' )
📤 出力 :β1=0.0023, β2=2.4, R²=0.78。 t 検定はいずれも p<0.001 で有意。 食料費の 78 % を 2 変数で説明可能。
💬 解釈 :OLS の 4 仮定(線形性・ 等分散・ 独立・ 正規)を残差プロットで確認すること。 多重共線性は VIF で判定し VIF>10 で警告。
📌 補足セクション — 最小二乗法を SSDSE-B-2026 で確かめる
本セクションは「最小二乗法」を 47都道府県データ(SSDSE-B-2026)で具体的に確認するための追加教材です。 例として課税対象所得を総人口で説明する OLS を扱います。
🧮 実値で計算してみる — 最小二乗法
SSDSE-B-2026 の 47都道府県データから、 「課税対象所得を総人口で説明する OLS」を Python で再現します。 まず一行で読み込めるよう、 引数を直書きしたシンプル版を示します:
# 最小コード(直書き)
df = pd.read_csv('data/raw/SSDSE-B-2026.csv')
続いて、 列名はリポジトリ準拠(A1101 総人口、 A1102 男性人口、 D3201 課税対象所得、 等)の本番コードです。
import pandas as pd
import numpy as np
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', header=[0,1,2])
# 列名を 3 段ヘッダの最下段だけ採用(コード列: A1101, D3201 等)
df.columns = [c[-1] for c in df.columns]
# 2022 年の 47都道府県スナップショット
sub = df[df['年度コード'] == 2022].copy()
x = sub['A1101'].astype(float) # 総人口
y = sub['D3201'].astype(float) # 課税対象所得
# 最小二乗法の基礎統計
x_mean, y_mean = x.mean(), y.mean()
beta1 = ((x - x_mean) * (y - y_mean)).sum() / ((x - x_mean) ** 2).sum()
beta0 = y_mean - beta1 * x_mean
print(f'n = {len(x)}') # 47
print(f'beta1 = {beta1:,.4f}') # 傾き
print(f'beta0 = {beta0:,.4f}') # 切片
print(f'相関係数 = {x.corr(y):.4f}') # 0.95+ になる
# 残差・決定係数も計算
y_hat = beta0 + beta1 * x
resid = y - y_hat
ss_res = (resid ** 2).sum()
ss_tot = ((y - y_mean) ** 2).sum()
r2 = 1 - ss_res / ss_tot
print(f'R^2 = {r2:.4f}')
このコードを実行すると、 47都道府県データから 最小二乗法に関連する係数・指標が直接得られます。 SSDSE-B-2026 が手元にない場合は、 統計データ活用コンペティション公式ページからダウンロードしてください。
⚠️ 補足の落とし穴
都道府県データはサンプルサイズ 47 が固定 :標本数を増やせないため、 統計的検定の検出力は中程度に留まります。 解釈時にこの限界を意識してください。スケールの違い :総人口(百万単位)と課税対象所得(百億単位)など、 桁が大きく異なる変数は標準化して扱うのが安全です。東京・大阪等の影響点 :少数の大都市が回帰や相関の結果を大きく動かすことがあります。 影響統計量(てこ比、 クックの距離)の確認を推奨します。
🔗 関連用語(補足リンク)
🔖 キーワード索引(R18 補強版)
この 最小二乗法(OLS) ページで出てくる主要キーワードを一覧します。チップをクリックすると該当箇所へジャンプできます。
OLS 最小二乗法 残差 回帰直線 R² 回帰係数 Gauss-Markov BLUE 残差分析 正規方程式
💡 30 秒で分かる結論(R18)
定義 :残差の二乗和を最小にする直線(平面)をデータに当てはめる、回帰分析のもっとも基本となる手法。カテゴリ :回帰モデル使う場面 :論文・レポートで「最小二乗法(OLS)」と書かれた図表・式・引用に出会ったとき。主な道具 :pandas / numpy / matplotlib / scipy / statsmodels / scikit-learn。注意 :n=47 の小標本、単位の混在、因果と相関の混同に常に気をつける。本ページの 12 セクション :キーワード索引・30 秒で分かる結論・文脈ボックス・直感で掴む・数式または定義・数式を言葉で読み解く・実値で計算・Python 実装・落とし穴・関連手法・派生・関連用語(前提・並列・発展)・関連グループ教材。
📍 文脈ボックス(R18)── あなたが今見ているもの
あなたは、回帰モデル の入口で「最小二乗法(OLS)(Ordinary Least Squares) 」という用語に出会ったところです。
この用語は 残差の二乗和を最小にする直線(平面)をデータに当てはめる、回帰分析のもっとも基本となる手法。
本ページでは、まず数式や形式的定義よりも、実データ(SSDSE-B-2026, 47 都道府県)で具体的な値を見ます。
そのあと、数式 → 計算 → Python 実装 → 落とし穴 → 関連用語、という順で「使える知識」に組み立てていきます。
SSDSE-B-2026 補足 :SSDSE-B-2026 で「死亡率 ~ 高齢化率」の OLS を当てはめると、傾き約 0.34 が得られ、「高齢化率が 1 % 上がると死亡率が約 0.34 ポイント上がる」と読めます。
🎨 直感で掴む(R18)── 最小二乗法(OLS) を絵で理解
最小二乗法(OLS) の本質は、ひとことで言うと「残差の二乗和を最小にする直線(平面)をデータに当てはめる、回帰分析のもっとも基本となる手法。」です。
数式に踏み込む前に、まずイメージで掴みましょう。
もし 最小二乗法(OLS) を 使わない と :データの大事な情報(分布の形、外れ値、関係の方向)が見落とされ、結論が偏ります。もし 最小二乗法(OLS) を 使う と :47 都道府県の差をデータで読む方法が手に入り、根拠つきで主張できるようになります。具体例 :SSDSE-B-2026 で「死亡率 ~ 高齢化率」の OLS を当てはめると、傾き約 0.34 が得られ、「高齢化率が 1 % 上がると死亡率が約 0.34 ポイント上がる」と読めます。
ヒント :直感が掴めたら、次の「数式または定義」セクションで形式化を確認してください。
形式化と直感がつながれば、最小二乗法(OLS) はもう武器です。
🔬 数式を言葉で読み解く(R18)
上の式 $y = f(x; \theta) + \varepsilon$ を「数学者の声」ではなく、「現場の声」で読み直してみます。
$y = f(x; \theta)$ :「あなたが説明したい量($y$)は、手元の説明材料($x$)から、ある関数 $f$ で計算できると 仮に 置く」$+ \varepsilon$ :「とはいえ、$y$ は完全には $x$ で決まらない。残りは 誤差項 $\varepsilon$ として認める」パラメータ $\theta$ の推定 :「データを 47 個並べ、$y$ と $f(x;\theta)$ の差をできるだけ小さくする $\theta$ を選ぶ」不確かさの定量化 :「$\theta$ も $f$ もデータから推定したので、信頼区間と $p$ 値で『どれくらい確信できるか』を必ず併走させる」
合言葉 :「定義は短い、解釈は長い」。最小二乗法(OLS) はたった 1 行の式ですが、それを 47 都道府県データに当てると、5 種類のチェックリスト(線形性・独立性・等分散・正規性・外れ値)が芋づる式に出てきます。
🧮 実値で計算してみる(R18)── SSDSE-B-2026 で 最小二乗法(OLS)
数式が読めたら、すぐに 実データ (SSDSE-B-2026, 47 都道府県, 2023 年度)で計算しましょう。
抽象を 47 行の表に落とすと、急に理解できることがあります。
▼ コード解説(SSDSE-B-2026 から A1303, A4200 を読む)
🎯 解説: 47 都道府県 × 1 年分(2023)を抽出し、最小二乗法(OLS) の代表値(平均・中央値・標準偏差・最大/最小)を一気に確認する。
📥 入力例: data/raw/SSDSE-B-2026.csv(cp932, ヘッダ 2 行)
# 最小二乗法(OLS) の代表値を SSDSE-B-2026 で確認
col = 'A1303'
s = df2023[col].astype(float)
print('n :', len(s)) # 47
print('mean :', round(s.mean(), 2))
print('median :', round(s.median(), 2))
print('std :', round(s.std(), 2))
print('min / max :', s.min(), '/', s.max())
print('Top 3 prefs :')
print(df2023.nlargest(3, col)[['Prefecture', col]])
結果を見ると、47 都道府県のうち上位 3 県が突出しているか、なだらかに分布しているか、すぐ分かります。
この「分布の形」が見えると、最小二乗法(OLS) を語る土台ができたことになります。
🐍 Python 実装(R18)── 最小二乗法(OLS) のミニ完全版
Python の実装は「読む → 集計 → 描く → 報告」を一直線に書きます。長いコードよりも、各ステップが分離していることが大事です。
① データ読み込み
▼ コード解説(SSDSE-B-2026 を pandas で読む)
🎯 解説: encoding='cp932' が必須。 2 行目は日本語ラベルなので skiprows で飛ばす。
📥 入力例: data/raw/SSDSE-B-2026.csv(東京・大阪などを含む 47 行)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# SSDSE-B-2026 を読み込み(高齢化率 → 死亡率)
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=[1])
# 2023 年度(最新)だけ抽出
df2023 = df[df['SSDSE-B-2026'] == 2023].copy()
print(df2023.shape) # (47, ...)
print(df2023[['Prefecture', 'A1303']].head())
② 集計と可視化
▼ コード解説(matplotlib で 47 都道府県の棒グラフ)
🎯 解説: sort_values + plot.bar で降順可視化。 都道府県名は x ラベル、 縦軸が A1303。
📥 入力例: 2023 年, 47 都道府県, 高齢化率 → 死亡率
# 最小二乗法(OLS) を 47 都道府県でビジュアル化
fig, ax = plt.subplots(figsize=(9, 6))
df2023.sort_values(col, ascending=False).plot.bar(
x='Prefecture', y=col, ax=ax, color='#00897B', legend=False)
ax.set_title('高齢化率 → 死亡率(SSDSE-B-2026, 2023)')
ax.set_ylabel(col)
ax.set_xlabel('都道府県')
plt.xticks(rotation=90)
plt.tight_layout()
plt.savefig('figures/ols.html_r18_bar.png', dpi=120)
plt.show()
③ 報告用テンプレ
レポート文例 :「SSDSE-B-2026(2023 年度, n=47)に基づいて 最小二乗法(OLS) を確認したところ、平均は X、標準偏差は Y、上位 3 県は東京・神奈川・大阪であった。
SSDSE-B-2026 で「死亡率 ~ 高齢化率」の OLS を当てはめると、傾き約 0.34 が得られ、「高齢化率が 1 % 上がると死亡率が約 0.34 ポイント上がる」と読めます。」
⚠️ 落とし穴(R18)── 最小二乗法(OLS) で踏みやすい 5 つ
スケールの混在 :最小二乗法(OLS) を扱うとき、人口(百万人)と比率(%)のように単位が混ざると、図や係数の解釈が崩れます。標準化やログ変換で揃えるのが安全です。小標本(n=47) :47 都道府県は標本数が小さく、外れ値 1 県の影響が大きく出ます。95 %信頼区間や bootstrap も同時に示しましょう。因果と相関の混同 :最小二乗法(OLS) で見えた関係は「一緒に動いている」だけで、因果関係を保証しません。逆因果・交絡・選択バイアスを必ず併走で議論してください。カテゴリの粒度 :47 都道府県を 1 単位で扱うか、8 地域ブロック(北海道・東北・…)で集約するかで、結論が変わります。集計粒度は最初に決めて固定しましょう。視覚的トリック :軸を切り取る・色を扇情的に使う・3D で奥行きをつける、などの装飾は「説得力ある誤り」を生みます。常に「ゼロ起点」「線形軸」で 1 枚作って比べる癖をつけてください。
合言葉 :レポート提出前に「ゼロ起点で 1 枚描き直す」「外れ値を 1 県外して再計算」「逆方向の因果を 1 行で否定する」を必ずやる。
🎙 narration まとめ(R18)── コード解説の総括
本ページに登場した Python コードはすべて以下のテンプレートで読み解けます:
▼ コード解説(テンプレート)
🎯 解説: ① 読む → ② 集計 → ③ 描く → ④ 検定 → ⑤ 報告。 中間結果を必ず print して人間が確認できるようにする。
📥 入力例: SSDSE-B-2026.csv(47 都道府県 × 約 110 列)
📤 出力例: 図 1 枚 + 統計量 1 表 + レポート文 1 段落
覚え方 :「Read → Roll up → Render → Read it back」。
最後の「Read it back」は、出力された数字や図を口に出して 1 度言うこと。
これで 最小二乗法(OLS) の現場運用は十分に回ります。
❓ FAQ(R18)── よくある質問 7 連
Q1. 最小二乗法(OLS) は機械学習でも使う?
使います。前処理(特徴量 → 入力ベクトル)、評価(指標の可視化)、解釈(係数の可視化)など、機械学習のあらゆる工程で 最小二乗法(OLS) は登場します。
Q2. n=47 で十分?
記述統計や 1 変量・2 変量の可視化には十分。ただし複数の説明変数を同時に検討するときは、自由度が枯れます。bootstrap や情報量規準(AIC/BIC)で補強しましょう。
Q3. SSDSE-B-2026 はどこで手に入る?
独立行政法人統計センター(NSTAC)「SSDSE」サイトから無料でダウンロードできます。本ページの実装はすべて data/raw/SSDSE-B-2026.csv を前提にしています。
Q4. ライセンスは?
SSDSE は教育目的での利用が許諾されています(出典明示、改変記録)。論文公開時は出典欄に「総務省統計局, SSDSE-B-2026」を必ず書きましょう。
Q5. 最小二乗法(OLS) を最短で身につけるには?
① ヒストグラム 1 枚を描く → ② 平均・中央値・標準偏差を読み上げる → ③ 上位 3 県・下位 3 県を暗記する → ④ 2 変量の相関を 1 つ確認する → ⑤ レポート 1 行にまとめる。これを 47 都道府県データで 3 回回せば、用語の地形が掴めます。
Q6. 最小二乗法(OLS) に関する代表的な論文は?
本リポジトリの 論文一覧 から「回帰モデル」カテゴリの論文を見ると、最小二乗法(OLS) を実際に使った再現コードが付いています。
Q7. 報告書ではどの順で書く?
「目的 → データ → 最小二乗法(OLS) の選択理由 → 結果(図 + 数値)→ 解釈 → 限界(n=47, 単年)→ 次の一手」の順が王道です。
📚 さらに踏み込む(R18)── 用語ネットワーク 16 件
用語は単独では覚えづらいので、前提・並列・発展の 3 方向で 16 件並べます。
勧め方 :1 日 1 リンク。クリックして読んだら、最小二乗法(OLS) のページに戻り、「最小二乗法(OLS) とこの用語はどう違う?」を 1 行書く。
✅ 使う前のチェックリスト(R18)
□ データの出典は明記したか(SSDSE-B-2026, 2023 年度, n=47)
□ 単位は揃えたか(人口は千人 or 百万人 のどちらか)
□ ゼロ起点で 1 枚描き直したか
□ 外れ値(東京・北海道など)の影響を 1 回外して再計算したか
□ 最小二乗法(OLS) の限界(n=47, 単年, 因果ではない)を最後に書いたか
□ 関連手法(最小二乗法(OLS) 以外)を 1 つは試したか
□ 落とし穴 5 件を再読したか
🧪 ミニケース(R18)── 最小二乗法(OLS) を 5 段階で完走する
STEP 1:問いを書く ── 47 都道府県のうち「高齢化率 → 死亡率」が大きい県と小さい県では、暮らしぶりにどんな差があるか?STEP 2:データを読む ── SSDSE-B-2026 から A1303, A4200 を取り出し、2023 年度・47 行に絞る。STEP 3:分布を見る ── ヒストグラムと箱ひげ図で「上位 3・下位 3」を特定し、東京・神奈川・大阪などの突出を確認する。STEP 4:関係を測る ── 別の変数(人口・死亡率など)との 2 変量関係を散布図 + 相関で測る。STEP 5:報告する ── 「上位 3 県は X, Y, Z。これらは…」という 200 字レポートに落とす。
合言葉 :5 STEP のうちどれか 1 段でも飛ばすと、結論が「数字だけ」になり、読者の腑に落ちなくなります。
最小二乗法(OLS) は「数字 + 物語」のセットで完成です。
🚫 アンチパターン集(R18)── 最小二乗法(OLS) で「やってはいけない」9 連
合成データを np.random.seed で作って「再現実験しました」と書く(教育用途では SSDSE-B-2026 を使うのが必須)
カラムを iloc[:, 5] のように位置で参照し、SSDSE のバージョン違いで壊れるコードを書く
都道府県の集計順を「日本語五十音」「アルファベット」「東京から時計回り」など混在させ、図の解釈を難しくする
変数名を x1, x2, x3 のように匿名化し、読者が意味を追えないコードにする
軸を切り取って小さな差を大きく見せる(特に y 軸の最小値を 0 にしない)
外れ値の県を黙って削除する(必ず「東京を外した版」と「全件」を両方描く)
p < 0.05 を「効果がある」と読み替える(本来は「偶然では説明しづらい」だけ)
相関 r を「因果の強さ」と書く(最小二乗法(OLS) で因果は出ない)
レポートの最後で「以上」と書いて閉じる(必ず「限界」と「次の一手」を 1 行ずつ)
🔎 深掘り解説(R18)── 最小二乗法(OLS) を 30 分で 1 段深く
A. 歴史的背景
最小二乗法(OLS) は、19 世紀末〜 20 世紀初頭の統計学黎明期から発達してきました。回帰モデル の中核として、Galton、Pearson、Fisher、Yule などが基礎を築き、現代では SSDSE のような公的データを使った教育素材で広く扱われています。
B. 数理的位置づけ
最小二乗法(OLS) は、観測ペア $(x_i, y_i)_{i=1}^{n}$ から条件付き期待値 $E[y \mid x]$ または分布 $P(y \mid x)$ を推定する道具です。
線形・非線形・パラメトリック・ノンパラメトリックという 4 つの軸の中で、最小二乗法(OLS) は「回帰モデル」という棚に並んでいます。
C. 実装上の工夫
欠損対応 :df.dropna() の前に必ず欠損率を df.isna().mean() で測る。外れ値検出 :IQR ベース or マハラノビス距離。47 県の中で 2 県以上が外れたら原因を疑う。標準化 :人口・面積・所得など単位が違う変数を混ぜるなら、必ず StandardScaler。可視化の優先順 :1 変量(hist, box)→ 2 変量(scatter, heatmap)→ 多変量(pairplot, PCA)。レポート :図 1 枚、表 1 枚、文章 200 字。これを 1 ユニットとして 3 ユニット並べる。
D. 学問体系の位置
最小二乗法(OLS) は 記述統計 ・データサイエンス ・機械学習 の交差点に位置します。
どの分野から入っても、いずれは 最小二乗法(OLS) を通ります。
📔 ミニ用語集(R18)── 同じ話題で使う 12 語
標本(sample) 母集団から取り出した観測の集まり。本ページでは「47 都道府県, 2023 年度」が標本。
母集団(population) 標本の背後にある全体。47 都道府県は日本全土の「県別断面」と読める。
変数(variable) 各観測単位に対応する 1 つの数値・カテゴリ。SSDSE では人口・出生率など 約 110 列。
分布(distribution) 変数が取る値の頻度の形。hist / KDE / box で可視化する。
代表値(central tendency) 平均・中央値・最頻値の総称。歪んだ分布では中央値を優先。
ばらつき(dispersion) 標準偏差・IQR・分散の総称。代表値とセットで報告する。
外れ値(outlier) 分布の主部から大きく外れた観測。原因を 1 つ書ける外れ値だけ「正当な外れ値」と呼ぶ。
相関(correlation) 2 変量の同調具合。−1 〜 +1 の単数で要約。
因果(causation) X を動かすと Y も動くという関係。相関では保証されない。
p 値(p-value) 帰無仮説下で「観測以上に極端な値」が出る確率。「効果あり」とは言えない点に注意。
信頼区間(confidence interval) 同じ実験を何度もやったとき、推定値が含まれる範囲。点推定とセットで提示。
正規化(normalization) 変数のスケールを揃える操作。Min-Max / Z-score / Robust の 3 種を覚える。
🗾 47 都道府県データの位置づけ(R18)
最小二乗法(OLS) を学ぶときに使う SSDSE-B-2026 は、47 都道府県 × 約 110 列 × 複数年度のパネルデータです。
本ページでは「2023 年度の 47 行」を主に使います。
以下に、よく登場する代表的なカラムを示します。
SSDSE コード
日本語名
単位
最小二乗法(OLS) での主な使い方
Code 地域コード — JOIN キー Prefecture 都道府県名 — カテゴリ軸・ラベル A1101 総人口 人 説明変数(規模) A1303 65 歳以上人口 人 高齢化率の分子 A4101 出生数 人 人口動態の説明変数 A4200 死亡率 ‰ 目的変数の代表 B4101 年平均気温 ℃ 気候系の説明変数 L3221 消費支出 円 家計の目的変数
使い方のコツ :列名はすべて A1101 のような英数記号です。SSDSE のコードブックで日本語ラベルを確認しながら使ってください。
本ページの例では A1303, A4200 (高齢化率 → 死亡率)を中心に使っています。
👣 ステップバイステップ(R18)── 最小二乗法(OLS) を 10 行で実装する
解説は最小限。コードは 10 行以内。これで 最小二乗法(OLS) の最短ルートが手に入ります。
import pandas as pddf = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=[1])df = df[df['SSDSE-B-2026'] == 2023]col = 'A1303'print(df[['Prefecture', col]].sort_values(col, ascending=False).head())import matplotlib.pyplot as pltdf.plot.hist(y=col, bins=20)plt.title('高齢化率 → 死亡率(SSDSE-B-2026, 2023)')plt.savefig('figures/ols.html_r18_hist.png', dpi=120)plt.show()
注意 :10 行で動かせる、というだけで、これがゴールではありません。
最小二乗法(OLS) の本当の難しさは「描いた図をどう解釈するか」「報告にどう落とすか」にあります。
📖 さらに学ぶには(R18)── 学習ロードマップ 4 段
レベル 1(30 分) :本ページの「30 秒で分かる結論」と「直感で掴む」だけ読む。SSDSE-B-2026 を 1 度ダウンロードして開く。レベル 2(2 時間) :「Python 実装」セクションを写経し、A1303, A4200 の図を 1 枚作る。報告 200 字を書く。レベル 3(半日) :「数式または定義」「数式を言葉で読み解く」を踏まえ、別の 2 つの変数で同じ分析を反復。3 通り作って比べる。レベル 4(1 週間) :本リポジトリの 論文一覧 から「回帰モデル」カテゴリの論文 1 本を完走。再現コードを動かして、最小二乗法(OLS) の応用範囲を体感する。
📝 報告フォーマット(R18)── 最小二乗法(OLS) を 200 字で書く
最小二乗法(OLS) の結果を、ゼミ・卒論・社内会議で報告するときの定型文を 3 つ用意しました。
最初は丸ごとコピー、慣れたら差し替えて使ってください。
テンプレ A:研究レポート向け
「本研究では、SSDSE-B-2026(n=47, 2023 年度)を用いて 最小二乗法(OLS) を確認した。
主たる説明変数は A1303, A4200(高齢化率 → 死亡率)であり、47 都道府県を対象とした分布の確認、相関の評価、最小二乗法(OLS) を用いた分析を実施した。
分析の結果、上位 3 県・下位 3 県の特徴と、SSDSE-B-2026 で「死亡率 ~ 高齢化率」の OLS を当てはめると、傾き約 0.34 が得られ、「高齢化率が 1 % 上がると死亡率が約 0.34 ポイント上がる」と読めます。」
テンプレ B:ビジネスレポート向け
「高齢化率 → 死亡率 を 47 都道府県で比較したところ、東京・神奈川・大阪など大都市圏が突出していることが分かった。
最小二乗法(OLS) を用いた分析から、地域差は単に人口規模の違いだけでは説明できず、複数要因の組み合わせで生じていると示唆された。
今後の打ち手は、上位県のベストプラクティスを参考にしつつ、下位県への支援策を検討することである。」
テンプレ C:教育用講義スライド向け
「皆さん、最小二乗法(OLS) はひとことで言うと『残差の二乗和を最小にする直線(平面)をデータに当てはめる、回帰分析のもっとも基本となる手法。』です。
今回は SSDSE-B-2026(総務省統計局, 47 都道府県, 2023 年度)を使って、実際の数字でこの考え方を確かめました。
皆さん自身でも、別の指標(人口、出生率、家計支出など)に置き換えて同じ手順を試してみてください。」
🔭 3 つの視点で 最小二乗法(OLS) を見る(R18)
同じ用語でも、見る立場によって意味が変わります。3 つの視点を切り替えて、用語の輪郭を立体的に掴みましょう。
視点 ① 統計学者の目
統計学者にとって 最小二乗法(OLS) は「データから母集団を推定する道具」です。
確率モデル・尤度・不偏性・効率性・一致性などの数学的性質に注目し、漸近理論で性能保証を行います。
47 都道府県データは「小標本(n=47)」と分類され、bootstrap や情報量規準による補強が必要になります。
視点 ② データサイエンティストの目
データサイエンティストにとって 最小二乗法(OLS) は「ビジネス課題を数字で答えるパイプラインの 1 部品」です。
モデルの理論的性質より、運用性・解釈性・更新コストを重視します。
SSDSE のような公的データを用いるときは「データの出典・更新頻度・ライセンス」を最優先で確認します。
視点 ③ 教育者・学習者の目
教育の現場では 最小二乗法(OLS) は「初学者が躓きやすいポイント」を含む単元です。
抽象的な数式よりも、具体的な 47 都道府県データで手を動かし、図を描き、結果を口頭で説明できるようになることが目標になります。
本ページの並び(直感 → 数式 → 計算 → Python → 落とし穴)は、まさにこの教育的アプローチに沿っています。
視点切り替えの効果 :1 つの用語を 3 通りに眺めると、自分が今どの立場で議論しているか自覚できます。
論文を読むときは ①、現場で使うときは ②、人に教えるときは ③ ── と意識的に切り替えてください。
⚖️ 似た用語との使い分け(R18)── 8 列比較表
最小二乗法(OLS) と似た用語を、使い分けの観点から並べます。違いを言語化できれば、迷いが減ります。
用語
目的
入力
出力
強み
弱み
最小二乗法(OLS) 残差の二乗和を最小にする直線(平面)をデータに当てはめる、回帰分析のもっとも基本となる手法。 47 都道府県 × 約 110 変数 図 + 表 + 200 字レポート 直感的、再現容易 小標本(n=47)の制約 相関係数 2 変量の同調を 1 数で要約 x, y の 47 ペア r ∈ [−1, +1] シンプル 非線形は捉えられない 線形回帰 条件付き期待値の線形近似 説明変数群 回帰係数・予測値 解釈容易 非線形には弱い ロジスティック回帰 2 値分類 説明変数群 確率 + 係数 分類問題の標準 線形決定境界 ランダムフォレスト 非線形分類・回帰 大量変数 予測 + 重要度 非線形対応 解釈やや難
❓ 拡張 FAQ(R18)── 詰まりがちな 8 つの疑問
Q1. 最小二乗法(OLS) と「回帰モデル」全体の関係は?
最小二乗法(OLS) は 回帰モデル の中で「残差の二乗和を最小にする直線(平面)をデータに当てはめる、回帰分析のもっとも基本となる手法。」を担う基本道具です。回帰モデル の他のトピックは、この基本の応用または並列の道具にあたります。
Q2. 47 都道府県以外のデータで使えますか?
使えます。SSDSE-A(市区町村)、SSDSE-C(年次推移)、SSDSE-D・E(個票)など、最小二乗法(OLS) の手順はそのまま適用できます。粒度(県・市・個人)に応じて n が変わるので、結果の信頼性も変わります。
Q3. SSDSE-B-2026 が将来更新されたら?
SSDSE は年に 1 度更新されます。最小二乗法(OLS) のコード自体は変更不要ですが、結果(数値・図)は最新年度のものに置き換えてレポートしましょう。出典欄に「SSDSE-B-2027(仮)」と書き換えるのを忘れずに。
Q4. Excel でも同じことはできますか?
できます。ピボット → グラフ → 関数 で代表値や相関は出ます。ただし、再現性・履歴管理・自動化の面で Python に劣ります。学習用には Python を強く勧めます。
Q5. 最小二乗法(OLS) で AI(機械学習)に進めますか?
進めます。最小二乗法(OLS) は機械学習の「特徴量設計」と「結果解釈」の両端で必須です。AI と聞くと深層学習を連想しがちですが、SSDSE のような表形式データでは線形モデル + 最小二乗法(OLS) の組み合わせで十分実用になります。
Q6. 「コードが動かない」ときは?
3 つ確認します:①ファイルパス(data/raw/SSDSE-B-2026.csv)が合っているか、②エンコーディングが cp932 か、③ヘッダ 2 行目の日本語ラベルを skiprows で飛ばしたか。これで 9 割解決します。
Q7. 図を保存できない場合は?
figures/ ディレクトリが存在しない可能性があります。import os; os.makedirs('figures', exist_ok=True) を先頭に追加してください。
Q8. 最小二乗法(OLS) を勉強する優先順位は?
本ページの 12 セクションを順に読み進めるのが最短です。特に「直感 → 数式 → 計算 → Python」の 4 段が腑に落ちれば、用語の 80 % は理解できたとみなせます。
🎯 サマリーカード(R18)── 1 ページ印刷用
用語 最小二乗法(OLS)(Ordinary Least Squares) カテゴリ 回帰モデル ひとこと定義 残差の二乗和を最小にする直線(平面)をデータに当てはめる、回帰分析のもっとも基本となる手法。 SSDSE-B での使い方 SSDSE-B-2026 で「死亡率 ~ 高齢化率」の OLS を当てはめると、傾き約 0.34 が得られ、「高齢化率が 1 % 上がると死亡率が約 0.34 ポイント上がる」と読めます。 主な道具 pandas / matplotlib / scipy / statsmodels / scikit-learn 最大の注意 n=47 の小標本・単位混在・因果と相関の混同 学習ステップ 読む → 集計 → 描く → 検定 → 報告 代表的な関連用語 相関係数・回帰分析・ヒストグラム・散布図・標準偏差
このカードを印刷し、SSDSE-B-2026 で 1 回手を動かせば、用語の「使える形」が定着します。
最小二乗法(OLS) はあくまで「残差の二乗和を最小にする直線(平面)をデータに当てはめる、回帰分析のもっとも基本となる手法。」というシンプルな考え方の道具ですので、迷ったらこの 1 行に戻ってください。