📍 あなたが今見ているもの
論文の冒頭で「n = 47(47都道府県)」と書かれる数字。 ほぼ全ての統計量の信頼性を左右する基本要素。
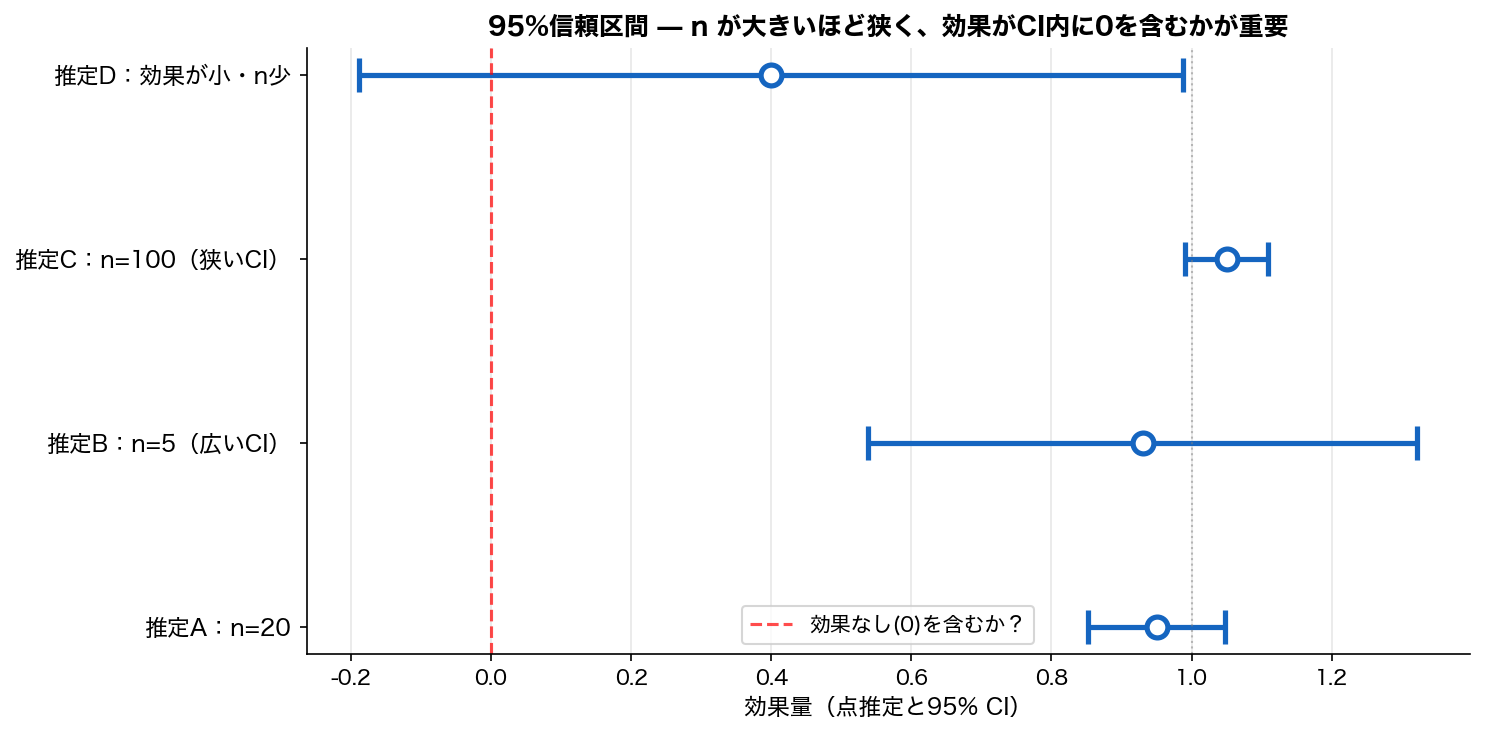
サンプルサイズ とは:観測したデータの個数。nが大きいほど統計量の精度が上がり、小さな効果でも有意になりやすい。
💡 30秒で分かる結論
- 定義:観測したデータ点(個体)の数
- 影響:n大 → 推定の精度↑、 検定の検出力↑
- $\sqrt{n}$ 則:標準誤差は $1/\sqrt{n}$ で減る。 n を4倍で初めて精度2倍
- 限界:n が極端に大(n > 10000)だと、 実用上無視できる差でも p<0.001 になる
- n=47(都道府県データ)は中規模。 重回帰の説明変数は4-5個までが目安
📖 もっと詳しく
サンプルサイズ n は 「データの個数」 です。 47都道府県データなら n=47、 1000人のアンケートなら n=1000。 単純な数字ですが、 n は分析結果の精度・検出力・解釈の全てを支配する重要パラメータです。
n の効果:n が大きいほど、 (i) 推定値のばらつき(標準誤差)が小さくなる、 (ii) 信頼区間が狭くなる、 (iii) 検定の検出力(小さな効果も発見できる確率)が上がる。 $\sqrt{n}$ 則:標準誤差は $1/\sqrt{n}$ で減るので、 精度を2倍にしたければ n を4倍にする必要がある。
n が小さすぎる弊害:(i) 検定の検出力不足で「効果あり」を見逃す、 (ii) 推定値が不安定で再現できない、 (iii) 外れ値の影響を受けやすい。
n が大きすぎる弊害:(i) 実用上無視できる小さな差でも p<0.001 になり、 「有意」が氾濫する、 (ii) 計算コストが上がる。
都道府県データ n=47 は中規模。 重回帰では n ≥ 10×(説明変数の数) が経験則なので、 n=47 だと説明変数は4〜5個までが目安。 多変量分析(PCA、 クラスタリング)も実行可能だが、 結果の安定性に注意。
🎨 直感で掴む
📐 数式
⚠️ よくある落とし穴
statsmodels.stats.power。✅ 実務チェックリスト — 推測統計を使う前に
1. データの確認
- サンプルサイズ n は十分か?(n < 30 なら t分布、 非正規性に注意)
- 独立同分布の仮定は妥当か?(時系列、 クラスター構造に注意)
- 外れ値の影響を確認したか?(box plot で)
- 正規性は確認したか?(QQプロット、 Shapiro-Wilk検定)
- 欠損値の扱いは適切か?
2. 検定・推定の設計
- 仮説(H₀、 H₁)は事前に定義したか?
- 片側 vs 両側を選択しているか?
- 有意水準 α は事前に設定したか?
- 多重比較の補正は必要か?
- サンプルサイズの事前計算(power analysis)したか?
3. 結果の報告
- 点推定 + 信頼区間を併記しているか?
- p値だけでなく効果量も報告したか?
- サンプルサイズを明記したか?
- 仮定の確認結果を述べたか?
- 「統計的有意 = 実質的に重要」と混同していないか?
4. 解釈の注意
- 「相関 ≠ 因果」を意識
- シンプソンのパラドックスを警戒
- 探索的分析と確認的分析を区別
- 結果を再現できるか
📚 推測統計を学ぶための重要文献
- Fisher (1925) "Statistical Methods for Research Workers" — 古典中の古典
- Neyman & Pearson (1933) — 仮説検定の理論的基礎
- Cohen (1988) "Statistical Power Analysis" — 効果量とサンプルサイズの教科書
- ASA Statement (2016) — p値の正しい使い方
- Gelman & Hill (2007) "Data Analysis Using Regression and Multilevel/Hierarchical Models"
- Wasserman (2004) "All of Statistics" — 現代統計学の総括
🆚 推測統計の主要用語 — 一目で分かる対比表
| 用語 | 記号 | 何を測る? | 公式 |
|---|---|---|---|
| 標準偏差 | σ, s | データ1個のばらつき | √(Σ(x-x̄)²/(n-1)) |
| 標準誤差 | SE | 推定値のばらつき | σ/√n |
| 信頼区間 | CI | 真値の入る範囲 | x̄ ± z·SE |
| p値 | p | 偶然この結果が出る確率 | P(|T| ≥ |t_obs| | H₀) |
| 有意水準 | α | Type I 誤り許容率 | 通常 0.05 |
| 検出力 | 1-β | 真の差を検出する確率 | 1 - Pr(Type II error) |
| 効果量 | d, r, R² | 差の大きさ | Cohen's d = (μ₁-μ₂)/σ |
| サンプルサイズ | n | 標本数 | power analysisで決定 |
🧪 A/Bテストのサンプル設計 — 完全ガイド
必要なパラメータ
- ベースライン率 p₁:現在のコンバージョン率(例:5%)
- 最小検出可能効果(MDE):検出したい改善幅(例:+10%相対 → 5.5%)
- 有意水準 α:通常 0.05
- 検出力:通常 0.80(または 0.90)
- 片側 vs 両側:通常両側
計算例
p₁ = 5%、 MDE = +20%相対(p₂ = 6%)、 α = 0.05、 検出力 = 0.80:
- 各群必要サンプル:約 12,000人
- 合計:約 24,000人のトラフィック
テスト期間の決定
1日あたりのアクセス数 D 、 必要サンプル N の場合、 期間 = N/D 日。 ただし最低でも 1-2 週は曜日効果を均すため。
逐次検定(ベイジアン A/B)
古典的な「事前に N を決める」方式とは別に、 ベイズ統計では「データを見ながら判断」できる手法も発展中。 Optimizely や Google Optimize で採用。
🤖 機械学習でのサンプルサイズ
① 学習曲線(learning curve)で診断
サンプルを徐々に増やして学習し、 訓練・検証スコアの推移を可視化。 「データ追加でモデルが伸びる余地があるか」を判断:
1 2 3 4 5 6 7 8 9 | from sklearn.model_selection import learning_curve import matplotlib.pyplot as plt train_sizes, train_scores, val_scores = learning_curve( estimator, X, y, train_sizes=np.linspace(0.1, 1.0, 10), cv=5, scoring='accuracy') plt.plot(train_sizes, train_scores.mean(axis=1), label='Train') plt.plot(train_sizes, val_scores.mean(axis=1), label='Validation') |
検証スコアがプラトーに達していれば、 さらにサンプルを増やす効果は薄い。
② 経験則 — 特徴量数の比
- 線形モデル:n ≥ 10〜20 × 特徴量数
- 決定木 / RF / XGB:n ≥ 数百以上、 特徴量数の影響は小
- 深層学習:n ≥ 数万〜数百万
- 転移学習:事前学習済みモデルなら数百でも実用可能
③ クラス不均衡データ
マイナークラスのサンプル数こそ重要。 「2クラス分類で1%しかないクラス」を学習するには、 そのクラスだけで最低数百は欲しい。
④ アクティブラーニング
「次にラベル付けすべきサンプル」を選ぶ手法。 同じ精度をより少ないサンプルで達成。 医療画像など、 ラベル付けコストが高い場面で有効。
🆘 サンプルが少ない時の対処
- ブートストラップ:少ない標本から多数の擬似標本を作る
- ベイズ統計:事前情報で n の不足を補う
- ノンパラメトリック検定:分布仮定が緩く、 小標本でも使える
- 正則化:Ridge, LASSO で過学習を防ぐ
- クロスバリデーション:限られたデータを最大活用
- データ拡張(augmentation):画像・音声で人工的に増やす
- 転移学習:他タスクのモデルから知識を借りる
⚠️ ただし「サンプルが少ない」は本質的な限界。 どんなテクニックを使っても、 n が極端に少なければ強い結論は出せない。 結果の不確実性を明示すべき。
🗺️ 概念マップ — 3つの視点で体系を理解する
サンプルサイズ がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 推測統計 › 推定 › 標本サイズ
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「サンプルサイズ」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「サンプルサイズ」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(補強)
サンプルサイズと検出力に関する主要概念チップ集。
🧮 SSDSE-B-2026 で実値計算 — サンプルサイズの考察
SSDSE-B-2026 は 47都道府県 = n=47 の典型的な「小〜中規模パネル」。 サンプルサイズに関連する具体計算を実行します。
例1:47都道府県の平均値の標準誤差
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from statsmodels.stats.power import TTestIndPower analysis = TTestIndPower() # 必要なサンプルサイズを計算 n_required = analysis.solve_power( effect_size=0.5, # 中程度の効果量(Cohen's d) alpha=0.05, power=0.80, ratio=1.0 # 2群が同じサイズ ) print(f'各群に必要なサンプルサイズ: {n_required:.0f}') # 与えられたnでの検出力 power = analysis.solve_power( effect_size=0.3, n_obs=50, alpha=0.05) print(f'検出力: {power:.3f}') |
📚 サンプルサイズの経験則
| 分析の種類 | 最低 n | 推奨 n |
|---|---|---|
| 単回帰 | 30 | 100+ |
| 重回帰(説明変数 k) | 10k + 10 | 20k + 50 |
| 因子分析 | 100 | 200-300 |
| クラスタリング | 2^k × 10 | 数百 |
| 機械学習(教師あり) | 10 × 特徴数 | 数千〜数万 |
🚧 サンプルサイズの落とし穴
1️⃣ 検出力不足
n が小さいと、 真に差があっても見つけられない(false negative)。 研究設計時に必ず power analysis を。
2️⃣ 過剰なサンプル
大きすぎる n は意味のない小さな差も「有意」に。 効果量で実用的意義を判断。
3️⃣ コストとのトレードオフ
サンプルが大きいほど精度は上がるが、 コストも増える。 √n でしか改善しないため、 設計時に慎重に。
4️⃣ 多重比較
多くの検定を行う場合、 必要な n は劇的に増えます(補正後の α が小さくなるため)。