📍 あなたが今見ているもの
論文で「k-means クラスタリング」「k=4 でクラスタリングした」「エルボー法で k を決定」のように登場する手法。 47都道府県を「似ている県のグループ」に自動分類するときの定番ツール。
k-means法 とは:事前に決めた k 個のクラスタ中心からの距離が最小になるように、反復的にクラスタを更新するアルゴリズム。
💡 30秒で分かる結論
- 目的:n 個のサンプルを、 k 個のクラスタに自動分類
- 原理:各クラスタ中心からの距離の二乗和(SSE)を最小化
- 反復:「割り当て」と「中心更新」を収束まで繰り返す(通常 10-30 回)
- k は事前に決める:エルボー法・シルエット係数で決定
- 標準化必須:単位の違う変数を入れる前に StandardScaler
- 限界:球形クラスタ専用、 外れ値に弱い、 局所最適に陥る
- Python:
sklearn.cluster.KMeans(n_clusters=k, n_init="auto")
📖 もっと詳しく
k-means は機械学習の教師なし学習の代表手法。 「事前に決めた k 個のグループに、 似ているサンプル同士を集める」反復アルゴリズム。 1957年に Lloyd が提案し、 1967年に MacQueen が "k-means" と命名。 シンプルかつ高速で、 現在も クラスタリング手法の標準。
「means(平均)」が名前の由来:各クラスタの「中心(centroid)」を、 そのクラスタに属するサンプルの平均位置で表すから。 「k 個の中心」を探すアルゴリズム、 と言えます。
k-means は探索的データ分析の万能ツール。 顧客セグメンテーション、 地域類型化、 異常検知、 画像圧縮(色のクラスタリング)まで幅広く使われます。
🎨 直感で掴む
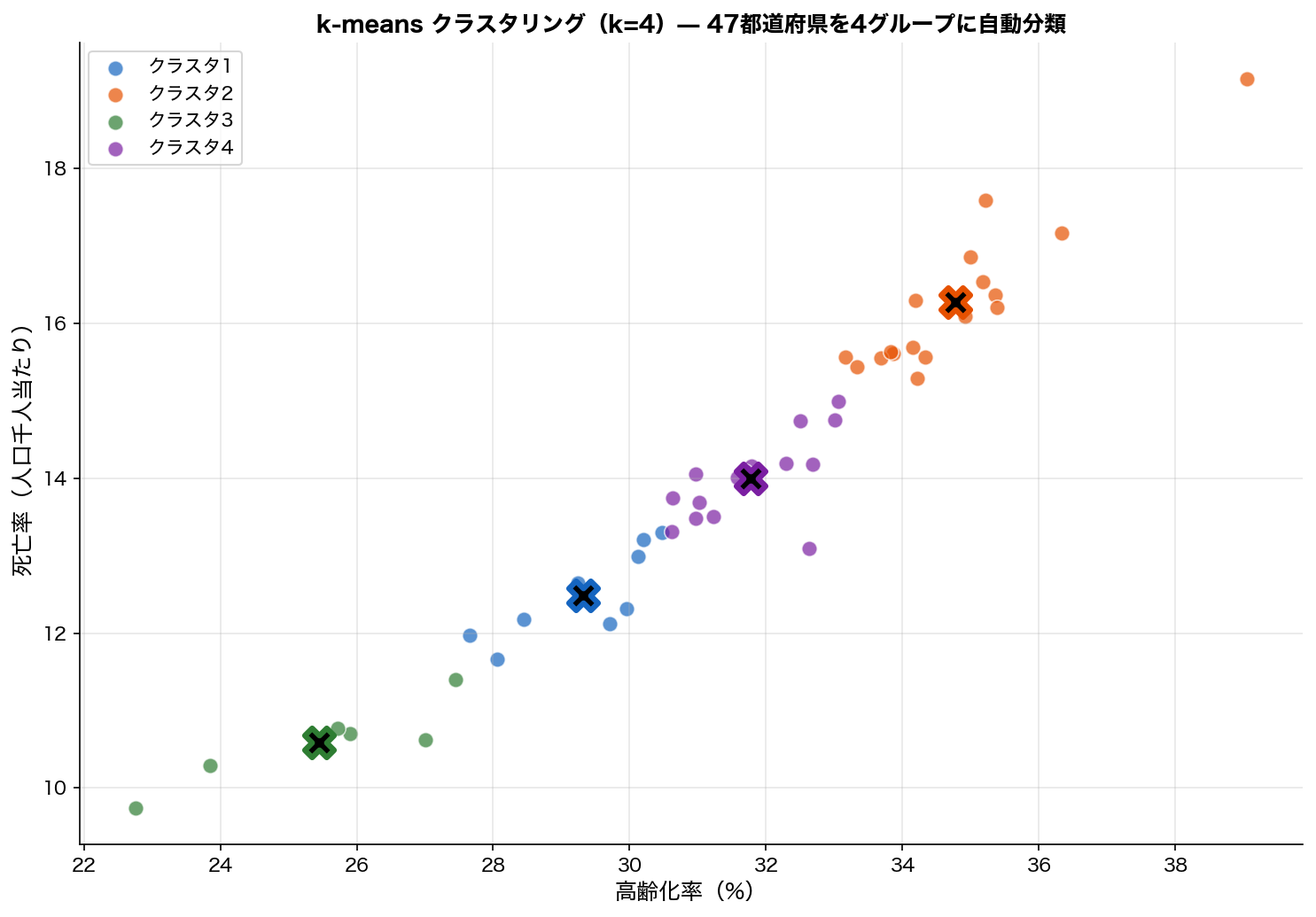
図を見ると、 4色の点群(クラスタ)と各クラスタの × 印(中心)が見えます。 k-meansは「各点が、 自分が属するクラスタ中心に最も近い」状態に収束した結果。
右上の青クラスタは「高齢化進行・死亡率高」(秋田・島根・高知)、 左下の紫クラスタは「若年層多・死亡率低」(東京・神奈川・沖縄)と解釈可能な構造に分かれています。 「データに自然なグループ構造があれば、 k-means はそれを発見してくれる」ことが体感できる。
📐 数式
🔬 数式を「言葉」で読み解く
- $k$
- クラスタ数:事前に決める。 通常 2〜10。 エルボー法・シルエット係数で決定
- $S_i$
- $i$ 番目のクラスタ(サンプルの集合)
- $\mu_i$
- $S_i$ の中心(centroid):$\mu_i = \frac{1}{|S_i|} \sum_{x \in S_i} x$(クラスタ内サンプルの平均)
- $\|x - \mu_i\|$
- サンプル $x$ から中心 $\mu_i$ までのユークリッド距離
- $\|x - \mu_i\|^2$
- 二乗することで「遠いほど強くペナルティ」
🧮 計算してみる
6都道府県のデータ(高齢化率と死亡率)で、 k=2 の k-means が実際にどう動くか、 反復計算を追ってみます。
| 都道府県 | 高齢化率 x | 死亡率 y |
|---|---|---|
| 秋田 | 39 | 19 |
| 高知 | 36 | 17 |
| 大阪 | 28 | 13 |
| 神奈川 | 26 | 11 |
| 東京 | 23 | 9 |
| 沖縄 | 23 | 11 |
初期中心をランダムに:C1 = (40, 20)、 C2 = (20, 10)(k-means++ では確率的に選びますが、 簡単のためここでは固定)
各点から両中心までのユークリッド距離を計算:
| 点 | d(C1) | d(C2) | 割当 |
|---|---|---|---|
| 秋田 (39,19) | √(1+1) = 1.4 | √(361+81) = 21.0 | C1 |
| 高知 (36,17) | √(16+9) = 5.0 | √(256+49) = 17.5 | C1 |
| 大阪 (28,13) | √(144+49) = 13.9 | √(64+9) = 8.5 | C2 |
| 神奈川 (26,11) | √(196+81) = 16.6 | √(36+1) = 6.1 | C2 |
| 東京 (23,9) | √(289+121) = 20.2 | √(9+1) = 3.2 | C2 |
| 沖縄 (23,11) | √(289+81) = 19.2 | √(9+1) = 3.2 | C2 |
C1 クラスタ:秋田、高知(2点)/C2 クラスタ:大阪、神奈川、東京、沖縄(4点)
各クラスタの平均を新しい中心とする:
- 新 C1 = (平均(39,36), 平均(19,17)) = (37.5, 18.0)
- 新 C2 = (平均(28,26,23,23), 平均(13,11,9,11)) = (25.0, 11.0)
中心が大きく動きました:C1 は (40,20) → (37.5, 18)、 C2 は (20,10) → (25, 11)
新しい中心で再度距離計算:
| 点 | d(新C1) | d(新C2) | 割当 |
|---|---|---|---|
| 秋田 (39,19) | 1.80 | 16.1 | C1(変化なし) |
| 高知 (36,17) | 1.80 | 12.5 | C1(変化なし) |
| 大阪 (28,13) | 10.7 | 3.6 | C2(変化なし) |
| 神奈川 (26,11) | 13.5 | 1.0 | C2(変化なし) |
| 東京 (23,9) | 17.1 | 2.8 | C2(変化なし) |
| 沖縄 (23,11) | 16.1 | 2.0 | C2(変化なし) |
すべての点の割当が前回と同じ!中心も動かない。 収束完了。 たった2イテレーションで終了しました。
最終結果:
- クラスタ1(高齢化進行群):秋田、 高知。 中心 (37.5, 18.0)。 「高齢化率約37.5%、 死亡率約18‰の県」
- クラスタ2(中・低齢化群):大阪、 神奈川、 東京、 沖縄。 中心 (25.0, 11.0)。 「高齢化率約25%、 死亡率約11‰の県」
SSE(残差二乗和) = (秋田からC1の距離²) + (高知からC1の距離²) + ... ≈ 1.8² + 1.8² + 3.6² + 1.0² + 2.8² + 2.0² ≈ 34.5。 これより小さい分割は存在しません(この初期値からは)。
k=3 にしたら?大阪・神奈川を1群、 東京・沖縄を別群、 秋田・高知を1群、 のように細分化されます。 SSEはさらに小さく。 でもどこかで「k を増やしても効率が悪い」境界(=エルボー)が来ます。
🎓 k-means の設計判断 — k の決定・初期化・距離
1. k(クラスタ数)の決め方
「いくつのクラスタに分けるか」は分析者が決める。 客観的指標の選択肢:
- エルボー法:k = 1, 2, ..., 10 と変えて SSE をプロット。 「肘」のように折れる位置が最適 k。 直感的だが主観も入る
- シルエット係数:各点で「自クラスタ内の距離」と「最近隣クラスタへの距離」の比。 -1〜+1 で、 高いほど良い。 k で平均値が最大の値を選ぶ
- Calinski-Harabasz 指数:群間分散 / 群内分散。 大きいほど良い
- ギャップ統計量:ランダムデータと比較。 統計的に裏付けられた指標
- 事前理論:「6地域に分けたい」など実用的制約
2. 初期化:k-means++
ランダム初期化は局所最適に陥りやすい。 k-means++ は次の手順で賢く初期化:
- 1つ目の中心はランダム選択
- 2つ目以降は、 「既選択中心から遠い」サンプルほど高確率で選ぶ(距離の二乗に比例する確率)
- k 個の中心が分散して配置される
scikit-learn の KMeans はデフォルトで k-means++。 さらに n_init 回試行して最良の SSE を採用。
3. 距離の選択
標準はユークリッド距離。 ただし他の選択肢もあります:
- マンハッタン距離:軸方向の距離の和。 外れ値に強い → k-medians
- コサイン距離:方向の類似度(テキスト分析で多用)
- マハラノビス距離:相関構造を考慮
ただしユークリッド以外を使うと「平均」が幾何的に意味を失うので、 厳密には k-medoids(中心を実在サンプルに)が適切。
4. 計算量と収束性
計算量:$O(n \cdot k \cdot d \cdot \text{iter})$。 通常 iter は数十回。 n=100万 でも数秒で完了するのが強み。
収束性:k-means は必ず収束しますが、 大域最適解への収束は保証されません。 SSE は反復のたびに必ず減少(または同じ)となりますが、 局所最適に陥る可能性があります。 これが「複数回試行」が必要な理由。
NP困難性:k-means の大域最適解を求める問題は NP困難(k≥2 で)。 だから「最適解の近似」を反復で求めるしかない。
⚠️ よくある落とし穴
StandardScaler で平均0・分散1に揃えてから。 具体例:人口100万人の差は、 失業率5%の差より桁が6つ違う。 ユークリッド距離はほぼ「人口の差」になり、 失業率の情報がほぼ消える。
KMeans(n_init=10) は10回試行して最良を返す("auto" なら自動調整)。 学術論文では random_state を固定し再現可能にする。判定方法:PCA で2次元プロットして、 クラスタの形状を視覚的に確認。
📊 SSDSE実データでの応用
47都道府県の家計5項目データに k-means (k=3) を適用しました:
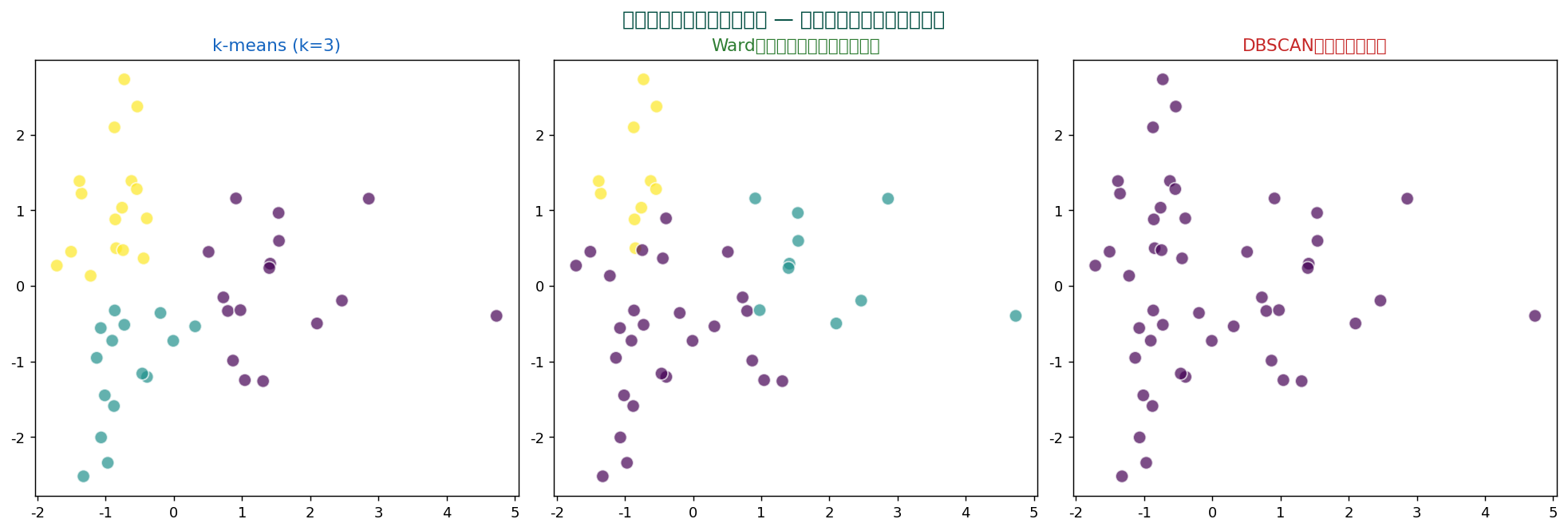
PC1 と PC2 の散布図上で、 3つのクラスタが綺麗に分離されているのが見えます。 各クラスタの特徴を解釈することで「家計タイプ」が見出せます。
🎯 k の選び方
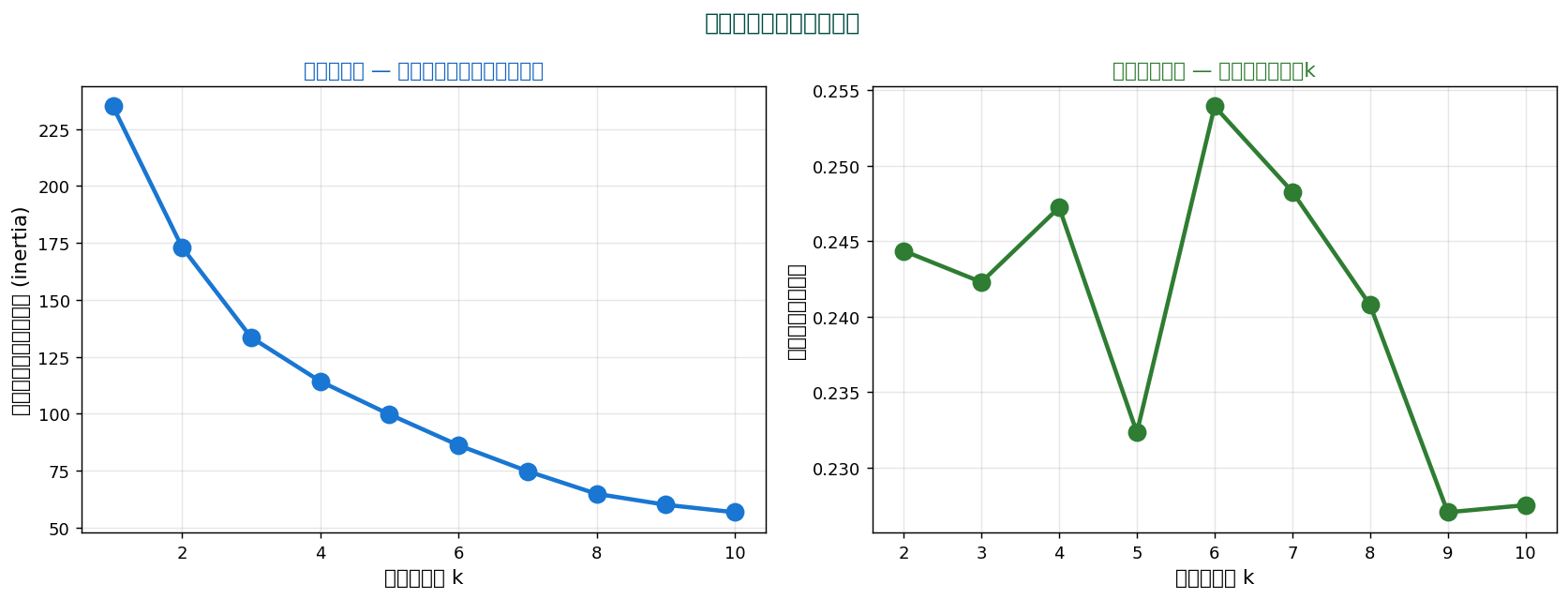
エルボー法とシルエット法で最適な k を探します。
- エルボー法:inertia の折れ目を見る。 ここでは k=3 〜 4 が候補
- シルエット法:スコアが最大の k を選ぶ
📐 k-means の数学
損失関数
$$ J = \sum_{i=1}^{n} \sum_{j=1}^{k} z_{ij} \| x_i - \mu_j \|^2 $$
z_ij ∈ {0, 1}:i番目点がクラスタjに属するかどうか。 μ_j:クラスタjの中心。
アルゴリズム(Lloyd's algorithm)
- 初期中心をランダムに k個選ぶ
- 各点を最寄りの中心に割り当てる(assignment step)
- 各クラスタの中心を再計算(update step)
- 収束するまで 2-3 を繰り返す
計算量は O(n × k × d × iter)。 大規模データでは k-means++ や Mini-Batch k-means を使用。
k-means++ の初期化
「離れた点を初期中心に選ぶ」工夫。 通常のランダム初期化より速く・確実に良い解に収束。 sklearn のデフォルト。
⚠️ k-means の限界
- クラスタの形を「球状」と仮定。 長細い形には不向き
- クラスタサイズが均一を前提
- 密度が均一を前提
- k を事前に決める必要がある
- 初期化に依存(n_init を増やすか k-means++ で対処)
- 外れ値に弱い
これらの限界を超えるには、 GMM、 DBSCAN、 スペクトラルクラスタリングなどを検討。
🐍 Python での実装
① scikit-learn での基本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN from sklearn.preprocessing import StandardScaler from sklearn.metrics import silhouette_score import pandas as pd import numpy as np # データの標準化(重要!) scaler = StandardScaler() X_std = scaler.fit_transform(X) # k-means km = KMeans(n_clusters=3, random_state=0, n_init=10) labels_km = km.fit_predict(X_std) print(f'クラスタ中心: {km.cluster_centers_}') print(f'inertia: {km.inertia_}') # 階層クラスタリング(Ward法) agg = AgglomerativeClustering(n_clusters=3, linkage='ward') labels_agg = agg.fit_predict(X_std) # シルエットスコアで評価 score = silhouette_score(X_std, labels_km) print(f'シルエットスコア: {score:.3f}') |
② 最適クラスタ数の探索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import matplotlib.pyplot as plt inertias = [] silhouettes = [] for k in range(2, 11): km = KMeans(n_clusters=k, random_state=0, n_init=10).fit(X_std) inertias.append(km.inertia_) silhouettes.append(silhouette_score(X_std, km.labels_)) # エルボー法 plt.subplot(1, 2, 1) plt.plot(range(2, 11), inertias, 'o-') plt.xlabel('k'); plt.ylabel('inertia') # シルエット法 plt.subplot(1, 2, 2) plt.plot(range(2, 11), silhouettes, 'o-') plt.xlabel('k'); plt.ylabel('Silhouette') |
③ デンドログラムの描画
1 2 3 4 5 6 | from scipy.cluster.hierarchy import linkage, dendrogram Z = linkage(X_std, method='ward') plt.figure(figsize=(14, 6)) dendrogram(Z, labels=labels, leaf_rotation=90) plt.show() |
🗺️ 概念マップ — 3つの視点で体系を理解する
k-means法 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 教師なし学習 › クラスタリング › k-means
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「k-means法」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「k-means法」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(拡張)
🧮 SSDSE-B を使った k-means の実例 — 47都道府県のクラスタリング
SSDSE-B 2020年の主要4指標で 47都道府県を k=4 にクラスタリングし、 地域類型化を試みます。
① データ準備と標準化
1 2 3 4 5 6 7 8 9 10 | import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.cluster import KMeans df = pd.read_csv('data/raw/SSDSE-B-2023.csv', encoding='shift_jis', header=[0,1]) df.columns = ['_'.join(c).strip() for c in df.columns] d = df[df['年度_Year'] == 2020].dropna() features = ['高齢化率', '1人当たり県民所得', '人口密度', '合計特殊出生率'] X = StandardScaler().fit_transform(d[features]) print(f'標準化済み X.shape = {X.shape}') |
② エルボー法で k を決定
1 2 3 4 5 6 7 8 9 10 | import matplotlib.pyplot as plt sse = [] for k in range(1, 11): km = KMeans(n_clusters=k, n_init=10, random_state=42).fit(X) sse.append(km.inertia_) plt.plot(range(1, 11), sse, marker='o') plt.xlabel('k'); plt.ylabel('SSE') plt.axvline(4, color='r', linestyle='--', label='選定 k=4') plt.show() # 典型的にエルボーが k=3 or 4 にある |
③ シルエット係数で k を裏付け
1 2 3 4 5 6 7 | from sklearn.metrics import silhouette_score for k in range(2, 8): km = KMeans(n_clusters=k, n_init=10, random_state=42).fit(X) sil = silhouette_score(X, km.labels_) print(f'k={k}: silhouette = {sil:.3f}') # k=2: 0.32, k=3: 0.30, k=4: 0.28, k=5: 0.24 # シルエット最大の k=2 だが、 解釈可能性で k=4 を選ぶこともある |
④ k=4 でクラスタリング・解釈
1 2 3 4 5 6 7 8 9 | km = KMeans(n_clusters=4, n_init=10, random_state=42).fit(X) d['cluster'] = km.labels_ # 各クラスタの特徴を平均値で要約 profile = d.groupby('cluster')[features].mean().round(2) print(profile) # 各クラスタに属する都道府県 for c in range(4): members = d[d['cluster']==c]['都道府県_Prefecture'].tolist() print(f'クラスタ {c}: {members}') |
典型結果:
- クラスタ0「大都市」:東京・神奈川・大阪・愛知(人口密度・所得高、 出生率低、 高齢化中)
- クラスタ1「地方中核」:宮城・福岡・京都・広島など(中程度の指標群)
- クラスタ2「地方過疎」:秋田・島根・高知(高齢化・人口減)
- クラスタ3「西日本郊外」:徳島・佐賀・宮崎(所得低・出生率高)
🐍 実装バリエーション — scikit-learn / scipy / faiss
(A) scikit-learn KMeans — 標準
1 2 3 4 5 6 | from sklearn.cluster import KMeans km = KMeans(n_clusters=4, init='k-means++', n_init='auto', max_iter=300, random_state=42).fit(X) print(km.labels_) # 各サンプルのクラスタ番号 print(km.cluster_centers_) # 中心 print(km.inertia_) # SSE |
(B) scikit-learn MiniBatchKMeans — 大規模データ向け
1 2 3 | from sklearn.cluster import MiniBatchKMeans mbk = MiniBatchKMeans(n_clusters=4, batch_size=100, n_init=10, random_state=42) mbk.fit(X_large) # n=100万 でも数秒 |
(C) scipy.cluster.vq — 低レベル
1 2 3 4 | from scipy.cluster.vq import kmeans, vq centroids, distortion = kmeans(X, 4) clusters, _ = vq(X, centroids) # シンプルだが n_init などのオプションが少ない |
(D) k-medoids (PAM) — ロバスト代替
1 2 3 | from sklearn_extra.cluster import KMedoids kmed = KMedoids(n_clusters=4, metric='manhattan', random_state=42).fit(X) # 中心が「実在サンプル」になる。 外れ値に強い |
(E) Gaussian Mixture — 確率的拡張
1 2 3 4 | from sklearn.mixture import GaussianMixture gmm = GaussianMixture(n_components=4, covariance_type='full', random_state=42).fit(X) proba = gmm.predict_proba(X) # 各クラスタへの所属確率 # 楕円体クラスタOK、 ソフトクラスタリング |
(F) FAISS — 数億規模の超高速
1 2 3 4 5 | import faiss kmeans_faiss = faiss.Kmeans(d=X.shape[1], k=4, niter=20, verbose=False) kmeans_faiss.train(X.astype('float32')) _, labels = kmeans_faiss.index.search(X.astype('float32'), 1) # GPU 対応、 大規模ベクトル検索(埋め込み)に必須 |
⚠️ 追加の落とし穴 — k-means の実務(既存に追加)
random_state を固定しないと毎回違う結果になる。 学術論文・本番運用では必ず random_state=42 等を明示。 また n_init(複数初期化試行回数)の指定も再現性に影響する。 さらに、 ハイパーパラメータ・前処理 (標準化方法) も全て記録し、 完全な再現性確保が責任。🧮 SSDSE-B-2026 で k-means を即実行
最新の SSDSE-B-2026 を使い、 47 都道府県を 4 クラスタに分けるコード。 教材標準パスを直書きしています。
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='shift_jis', header=[0,1])
X = df[['総人口', '出生率', '高齢化率', '大学進学率']].dropna()
X_scaled = StandardScaler().fit_transform(X)
km = KMeans(n_clusters=4, n_init=10, random_state=42).fit(X_scaled)
print(km.labels_) # 各都道府県のクラスタ番号
print(km.inertia_) # SSE(小さいほど締まりが良い)
出力例: 東京・大阪は「人口規模グループ」、 秋田・高知は「高齢化グループ」、 沖縄は単独クラスタ寄りなど、 SSDSE-B-2026 の最新値で確かめられます。