📍 あなたが今見ているもの
論文で階層クラスタリングの結果として登場する樹形図。 「デンドログラム」「樹形図」「ward 法のデンドログラムを示す」のような形で。 47都道府県のような中規模データの階層構造を可視化する最重要ツール。
デンドログラム とは:階層クラスタリングの結果を樹形図で表現したもの。縦軸は結合距離、横軸は個体。
💡 30秒で分かる結論
- 定義:階層クラスタリングの結合過程を樹形図で表現
- 縦軸:結合距離(または分散増加量、 不類似度)
- 横軸:個々のサンプル(順序は意味なし)
- 切断線:任意の高さで横切ると k 個のクラスタが得られる
- 色分け:閾値で自然なクラスタを別色着色(慣習)
- 用途:階層構造の把握、 k の決定、 異常値検出
- Python:
scipy.cluster.hierarchy.dendrogram(Z)
📖 もっと詳しく
デンドログラム(dendrogram, 樹形図)は、 階層クラスタリングの結果を樹形図の形で可視化したもの。 「どのサンプル同士が、 どの距離で結合するか」が一目で分かる、 階層クラスタリングの最終成果物です。
語源はギリシャ語 "dendron"(木)+ "gramma"(描いたもの)。 まさに「木の絵」。 生物学の系統樹(phylogenetic tree)も同じ概念で、 進化的近縁関係を樹形図で表します。
📐 デンドログラムの構造
デンドログラムは3要素から成ります:
- 葉(leaf):個々のサンプル。 横軸の下端に並ぶ
- 枝(branch):結合・分岐を表す線
- 節(node):2つの枝が結合する点。 高さが結合距離を表す
底から上に向かって、 「最初は各サンプルが独立」→「順次結合」→「最後に全部1つに」という過程を表現。
📊 縦軸と横軸の意味
- 縦軸:結合時の距離(または分散増加量、 不類似度)。 大きいほど「遠い」「異なる」関係
- 横軸:個々のサンプル(葉)。 順序は枝の入れ替えで変えられるので、 「絶対位置」に意味はない
低い位置で結合する2サンプル = 似ている。 高い位置で結合 = 大きく異なる。
✂️ 切断線(cut line):クラスタ数の決定
デンドログラムの真の威力は「後からクラスタ数を決められる」こと。 任意の高さで横に切ると、 そこから下のサブツリーが「k 個のクラスタ」になります:
- 低い位置で切る:k が大きい(細かい分類)
- 高い位置で切る:k が小さい(粗い分類)
切断高さの決め方:
- 事前理論:「4クラスタに分けたい」が決まっているなら、 上から4本目の枝が見える高さで切る
- 「肘」を探す:縦軸方向に急に枝が長くなる場所が自然な切断点。 「ここから上は急に距離が増える」位置
- 内部評価指標:複数の k でシルエット係数を計算し、 最良を選ぶ
- 逐次的分析:粗いクラスタ(k=2)から細かいクラスタ(k=8)まで全部見て、 各レベルでの解釈を比較
🎨 色分けの慣習
scipy の dendrogram() 関数では、 color_threshold パラメータで「ここから上は色分けしない」と指定すると、 自然なクラスタが色で区別されます:
- 閾値より下のサブツリー → 各クラスタを別色で着色
- 閾値より上 → 一色(通常は黒)
デフォルトは「最大距離の 70%」。 これにより視覚的にクラスタ構造が際立ちます。
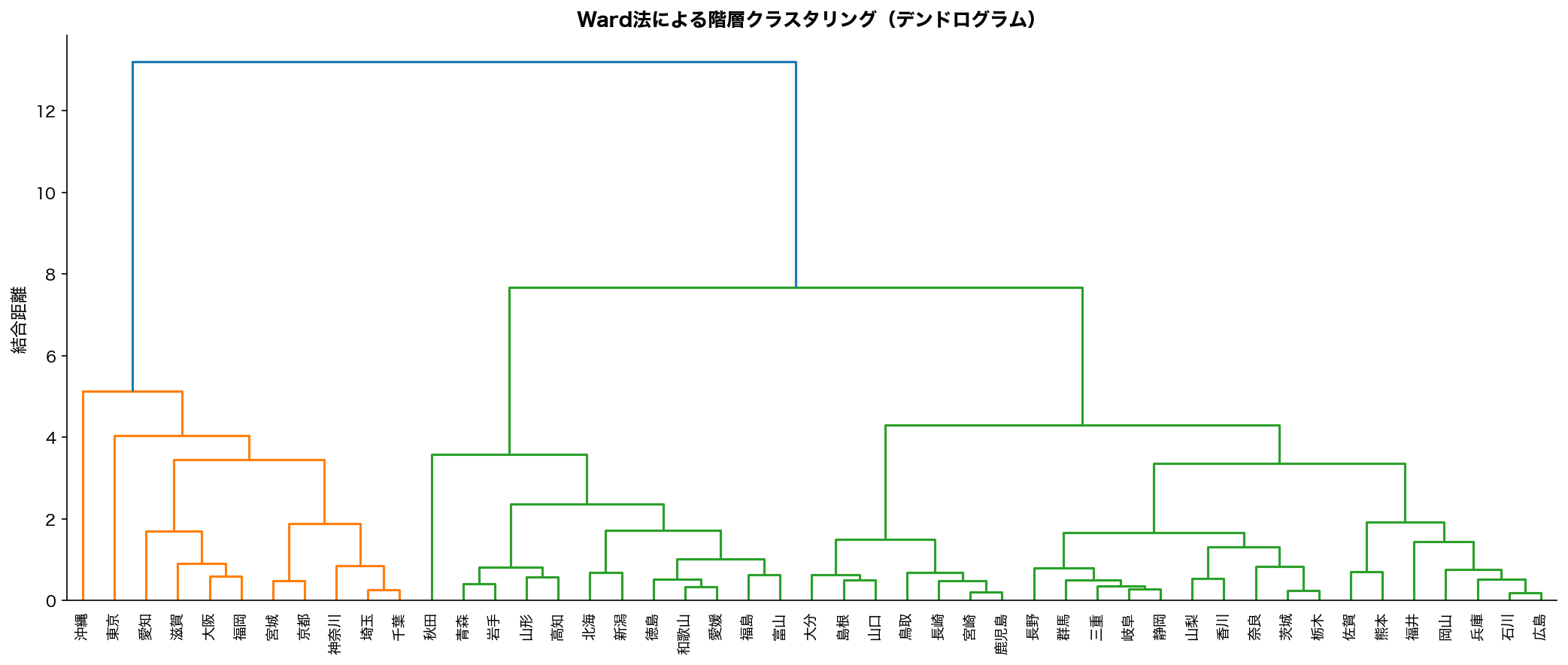
📊 47都道府県の例
SSDSE データを Ward 法でクラスタリングした典型的なデンドログラム解釈:
- 最下層(高さ ~1):「神奈川・東京」「秋田・島根」のような非常に似た県ペアが結合
- 中段(高さ ~3-5):「関東圏」「東北圏」「九州圏」のような地域圏レベルでの結合
- 上層(高さ ~10):「大都市圏 vs 地方」の大きな2分構造
- 最上層(高さ ~15):全47県が1つに統合
この階層構造から、 分析目的に応じた k を選べます。 細かく分析するなら k=8 で各地域圏に、 大きな区分なら k=2 で大都市 vs 地方に。
🔄 デンドログラムから読み取れる情報
デンドログラムは、 単にクラスタを示すだけでなく、 多くの情報を提供します:
- サンプル間の類似度の階層構造:「東京と神奈川は他より早く結合 → 最も似ている」
- 最適クラスタ数のヒント:「肘」の位置から自然な k が見える
- 異常値や孤立サンプル:極端に高い位置で結合する点は、 他から大きく離れた特異サンプル(沖縄など)
- サブグループの存在:上下に明確に分かれる構造があれば、 大きな2分構造が存在
- クラスタの密度:低い位置で多くの結合 = 密集したクラスタ
📉 デンドログラムの読み方の典型的失敗
失敗1:横軸の順序を意味あるものと思う
デンドログラムの横軸(葉の順序)は、 アルゴリズムの実装や枝の入れ替えで変わります。 「左から3番目だから」「真ん中だから」に意味はない。 重要なのは結合の高さと階層構造のみ。
失敗2:「最も似ている」を誤読
「2サンプルが隣同士に描かれている = 似ている」は誤り。 隣でも結合高さが高ければ似ていない。 必ず結合高さで判断。
失敗3:切断高さの恣意性
「だいたいここで切ろう」は主観的。 客観的な指標と組み合わせて決定すべき。
💻 Python での描画コード
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | from scipy.cluster.hierarchy import linkage, dendrogram from sklearn.preprocessing import StandardScaler import matplotlib.pyplot as plt # 標準化 X_std = StandardScaler().fit_transform(X) # 階層クラスタリング Z = linkage(X_std, method="ward") # デンドログラム描画 fig, ax = plt.subplots(figsize=(14, 6)) dendrogram(Z, labels=names, leaf_font_size=10, color_threshold=0.7*max(Z[:,2]), # 自然なクラスタ色分け ax=ax) ax.set_title("Ward 法によるデンドログラム", fontsize=14) ax.set_ylabel("結合距離") plt.tight_layout() plt.show() |
🎯 デンドログラムの応用
- 遺伝学:DNA 配列から系統樹を構築(phylogenetic tree)
- マーケティング:商品・顧客の階層的セグメンテーション
- 地理学:都道府県・地域の類型化
- テキスト分析:文書の階層的トピック分類
- 金融:銘柄間のリスク類似性
- 医療:疾患の症状パターンによる分類
🎨 直感で掴む
🎓 デンドログラムの理論と表現
ウルトラメトリック距離
デンドログラムが意味を持つには、 結合距離が「ウルトラメトリック」(ultrametric)という強い条件を満たす必要があります:
$d(x, z) \le \max(d(x, y), d(y, z))$
これは通常の距離の3角不等式 $d(x,z) \le d(x,y) + d(y,z)$ より強い条件。 これがあるおかげで、 樹形図として一意に表現できます。
結合基準によってはウルトラメトリックが破れ(中央連結など)、 樹形図に「逆転」(枝が交差)が起きます。 Ward 法、 単連結、 完全連結、 群平均では発生しません。
木の入れ替え可能性
デンドログラムには $2^{n-1}$ 通り の表示方法があります(各内部節点で左右の子を入れ替えられる)。 例えば 47県のデンドログラムは $2^{46} \approx 7 \times 10^{13}$ 通りの表示が可能。 でも階層構造(どこで結合するか)は同じ。
scipy では各実装が独自の順序で表示します。 多くの場合「リーフ間の距離を最小化する」順序(optimal leaf ordering)が使われ、 視覚的に分かりやすい配置になります。
同等表現:cophenetic 距離行列
デンドログラムから「2サンプル $x_i, x_j$ が結合した距離」を取り出した行列をcophenetic 距離行列と呼びます。
cophenetic correlation = (元の距離行列)vs(cophenetic 距離行列)の Pearson 相関。 これが大きい(0.7以上)と、 デンドログラムが元の距離構造を忠実に表現していることを意味します。 0.5以下なら、 階層クラスタリング自体が不適切な可能性。
系統樹との関係
生物学の系統樹(phylogenetic tree)もデンドログラムの一種。 種間の DNA 距離から進化的近縁関係を表現します。 ただし、 系統樹は「時間軸」(進化年代)を含むことが多く、 縦軸の意味が違います。
クラスタリングのデンドログラム:縦軸 = 不類似度
系統樹:縦軸 = 進化時間 or 遺伝距離
大規模データでの工夫
n が大きいと(n > 100)、 デンドログラムの葉が密集して読めなくなります。 対策:
- truncate_mode:上位 N 個のクラスタだけ表示
- ヒートマップとの併用:clustermap で行・列両方クラスタリング
- インタラクティブ可視化:plotly や bokeh でズーム可能な樹形図
- サブツリーの拡大表示:興味のある部分だけ詳細表示
⚠️ よくある落とし穴
📊 47都道府県のデンドログラム
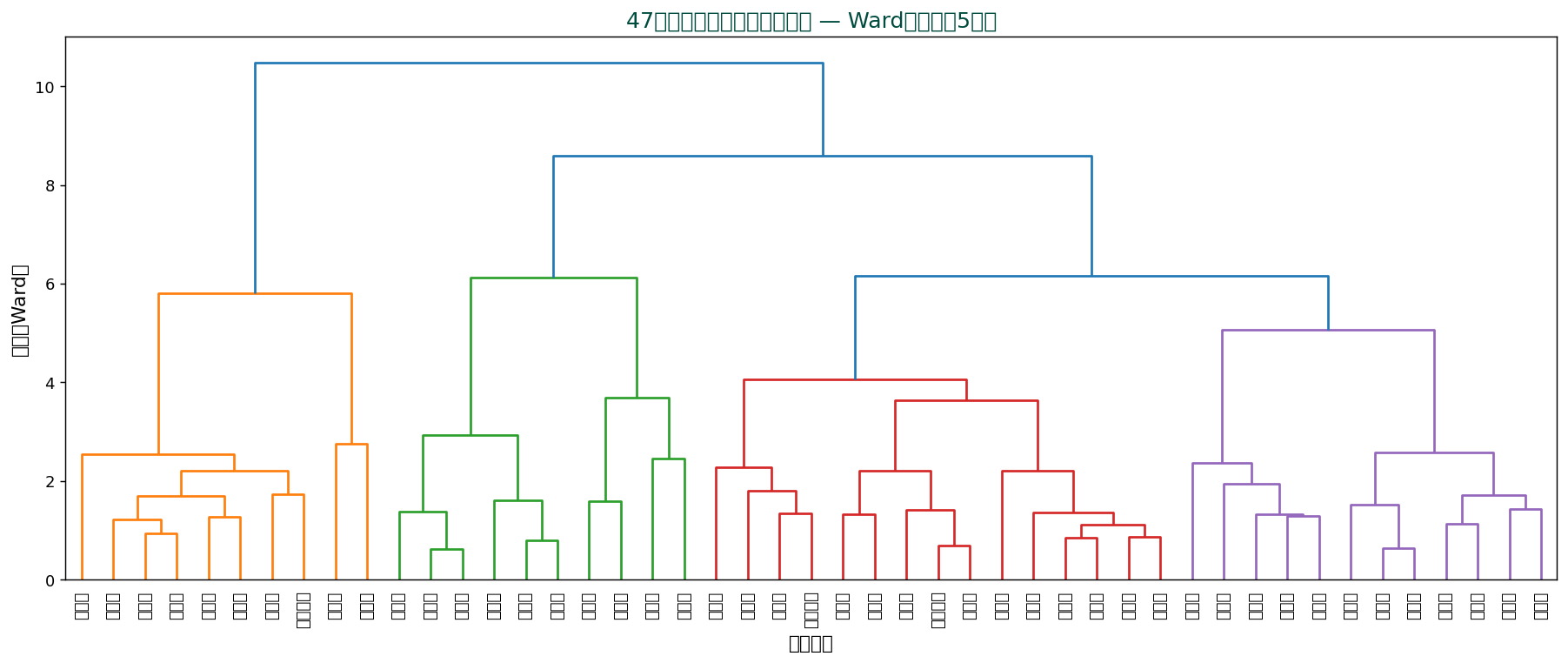
家計5項目で Ward 法を実行した結果。 「色分けされたクラスタ」は事前に指定した閾値で切ったもの。 距離が大きいところで切れば、 数の少ない大きなクラスタに分かれます。
🧭 デンドログラムの読み方 — 5ステップ
- 底辺:各データ点(葉, leaves)。 ここでは47都道府県
- 横線の高さ:マージ時の「距離」。 高いほど離れた合体
- 縦線:マージされた2つのクラスタを繋ぐ
- 切断レベル:横の水平線で切ると、 その下のクラスタが残る
- クラスタ数:切る高さで決まる。 高く切れば少数の大クラスタ
切断位置の決め方
- クラスタ数で決める:3 クラスタにしたい → そこを切る
- 距離で決める:「距離 5 以上は別」と判断
- 最大ジャンプ:マージ時の距離が急に大きくなる箇所
🎨 デンドログラムの拡張
① ヒートマップとの組合せ(clustermap)
seaborn の clustermap は、 行・列両方をクラスタリングしてヒートマップに重ねる強力なツール。
② 円形デンドログラム
系統樹のような円形表示。 多数の葉でも見やすい。
③ ファントグラム
生物分類でよく使われる、 デンドログラムに時系列情報を加えたもの。
🐍 Python での実装
① scikit-learn での基本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN from sklearn.preprocessing import StandardScaler from sklearn.metrics import silhouette_score import pandas as pd import numpy as np # データの標準化(重要!) scaler = StandardScaler() X_std = scaler.fit_transform(X) # k-means km = KMeans(n_clusters=3, random_state=0, n_init=10) labels_km = km.fit_predict(X_std) print(f'クラスタ中心: {km.cluster_centers_}') print(f'inertia: {km.inertia_}') # 階層クラスタリング(Ward法) agg = AgglomerativeClustering(n_clusters=3, linkage='ward') labels_agg = agg.fit_predict(X_std) # シルエットスコアで評価 score = silhouette_score(X_std, labels_km) print(f'シルエットスコア: {score:.3f}') |
② 最適クラスタ数の探索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import matplotlib.pyplot as plt inertias = [] silhouettes = [] for k in range(2, 11): km = KMeans(n_clusters=k, random_state=0, n_init=10).fit(X_std) inertias.append(km.inertia_) silhouettes.append(silhouette_score(X_std, km.labels_)) # エルボー法 plt.subplot(1, 2, 1) plt.plot(range(2, 11), inertias, 'o-') plt.xlabel('k'); plt.ylabel('inertia') # シルエット法 plt.subplot(1, 2, 2) plt.plot(range(2, 11), silhouettes, 'o-') plt.xlabel('k'); plt.ylabel('Silhouette') |
③ デンドログラムの描画
1 2 3 4 5 6 | from scipy.cluster.hierarchy import linkage, dendrogram Z = linkage(X_std, method='ward') plt.figure(figsize=(14, 6)) dendrogram(Z, labels=labels, leaf_rotation=90) plt.show() |
📖 包括的解説 — この概念を完全マスター
📍 学習の3ステップ
- 定義を理解する:この概念は何か? 数式や条件を確認
- 具体例を見る:実データ(SSDSE 等)で計算してみる
- 応用する:自分のデータに適用、 結果を解釈
🔧 Python実装パターン
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 基本パターン import pandas as pd import numpy as np from scipy import stats import matplotlib.pyplot as plt import seaborn as sns # データ読み込み df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') # 基本統計量 df.describe() # 可視化 sns.pairplot(df[['食料費', '教育費', '住居費']]) plt.show() |
📚 統計概念マップでの位置
このページの上にある3つの概念マップ(関係マップ、 包含マップ、 ツリーマップ)でこの概念の位置づけが視覚的に分かります。 関連手法を辿って学習を進めましょう。
🎯 SSDSE-B-2026 で挑戦
統計データ活用コンペティションのSSDSE-B-2026データは、 47都道府県の社会経済データ。 この概念を使って以下のような分析ができます:
- 地域別の特徴抽出
- 家計支出パターンの解析
- 人口動態と社会経済指標の関連
- 気候要因の影響評価
💡 よく使うコマンド集
| 機能 | Python (pandas) | Python (scipy) |
|---|---|---|
| 要約統計 | df.describe() | stats.describe() |
| 平均 | df.mean() | np.mean() |
| 標準偏差 | df.std() | np.std() |
| 相関 | df.corr() | stats.pearsonr() |
| t検定 | — | stats.ttest_ind() |
| 回帰 | — | stats.linregress() |
| 分布フィッティング | — | stats.norm.fit() |
🚧 一般的な落とし穴と対策
- 外れ値の影響:散布図・ 箱ひげ図で確認、 ロバスト手法も検討
- サンプルサイズ不足:power analysis で事前に確認
- 仮定の違反:正規性、 独立性、 等分散性をチェック
- 多重比較問題:補正(Bonferroni、 FDR)を適用
- p-hacking:事前登録(pre-registration)で防ぐ
- 因果と相関の混同:観察データから因果結論を出さない
📊 結果報告の標準フォーマット
- 点推定:得られた値
- 不確実性:信頼区間または標準誤差
- サンプルサイズ:n を明記
- 効果量:実質的な意義
- p値:統計的有意性
- 仮定の確認:診断プロット
🌐 関連分野での応用
- マーケティング:A/Bテスト、 顧客分析
- 医療:臨床試験、 疫学研究
- 金融:リスク管理、 ポートフォリオ
- 製造:品質管理、 工程最適化
- 公共政策:効果評価、 計画立案
- 研究:仮説検証、 探索的解析
🎓 さらに学ぶための文献
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression"
- VanderPlas "Python Data Science Handbook"
🔗 統計用語ネットワーク
この概念は、 他の多くの統計概念と密接に関連しています。 ジャストインタイム型学習では、 必要に応じて関連用語へジャンプしながら全体像を構築します。
主要な関連概念のグループ
| グループ | 主要概念 |
|---|---|
| 記述統計 | 平均、 中央値、 最頻値、 分散、 標準偏差、 共分散、 相関係数 |
| 可視化 | ヒストグラム、 散布図、 箱ひげ図、 ヒートマップ |
| 推測統計 | 標本平均、 標準誤差、 信頼区間、 p値、 有意水準 |
| 確率分布 | 正規分布、 t分布、 χ²分布、 F分布、 二項分布 |
| 仮説検定 | t検定、 F検定、 χ²検定、 ノンパラ検定 |
| 回帰 | 単回帰、 重回帰、 OLS、 Ridge、 LASSO |
| 分類 | ロジスティック回帰、 決定木、 SVM、 k-NN |
| 教師なし学習 | クラスタリング、 PCA、 因子分析 |
| 時系列 | ARIMA、 VAR、 指数平滑法、 自己相関 |
| 因果推論 | DiD、 IV、 傾向スコア、 交絡変数 |
| 前処理 | 標準化、 正規化、 欠損値処理、 多重共線性対策 |
| 評価 | R²、 残差、 CV、 RMSE、 効果量 |
学習順序の推奨
- 記述統計(平均、 分散、 標準偏差)
- 可視化(ヒストグラム、 散布図)
- 確率分布(正規分布)
- 推測統計(標準誤差、 信頼区間、 p値)
- 仮説検定(t検定、 χ²検定)
- 相関と回帰(単回帰、 重回帰)
- 多変量解析(PCA、 クラスタリング)
- 機械学習(決定木、 RF、 NN)
- 時系列・因果推論(応用)
📝 実践練習 — SSDSE-B-2026 で挑戦
初級課題
- 東北6県の家計食料費の基本統計量を計算
- 食料費のヒストグラムを描く
- 食料費と教育費の散布図を描く
- 都道府県を「東日本/西日本」に分け、 平均を比較
中級課題
- 家計支出 5項目で相関行列を作成、 ヒートマップ可視化
- 食料費 → 教育費の単回帰を実行、 残差分析
- 家計5項目で PCA を実施、 バイプロット表示
- k-means (k=3) で都道府県をクラスタリング、 解釈
上級課題
- 地域別の家計パターンに有意差があるか ANOVA で検定
- 重回帰で教育費を予測、 多重共線性を VIF で確認
- Ridge/LASSO で正則化、 CV で α を最適化
- 階層クラスタリングと Ward 法で都道府県を分類、 デンドログラム作成
🗺️ 概念マップ — 3つの視点で体系を理解する
デンドログラム がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 教師なし学習 › クラスタリング › デンドログラム
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「デンドログラム」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「デンドログラム」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引 — デンドログラムを多角的に理解する
デンドログラム(dendrogram、 樹形図)を確実に使いこなすための関連キーワードを難易度別に整理しました。
🟢 基礎キーワード(まず押さえる)
- デンドログラム(dendrogram):階層クラスタリングの結果を木構造で可視化した図。 葉が個体、 内部ノードが統合点。
- 階層クラスタリング:全個体を 1 つずつのクラスタとして開始し、 近いもの同士を統合していく凝集型(agglomerative)アルゴリズム。
- 結合距離(merge height):デンドログラムの縦軸が表す、 2 つのクラスタを統合したときの「コスト」。
- カット(cut):デンドログラムを横線で切ることで、 任意の数のクラスタに分割すること。
- ユークリッド距離:個体間の距離指標として最も一般的。 標準化後に使うのが慣例。
- Ward 法 / 単連結法 / 完全連結法 / 平均連結法:クラスタ間距離の定義(リンケージ)。 結果が大きく変わる。
🟡 中級キーワード
- 共経路距離行列(cophenetic matrix):デンドログラムから読み取る個体間の距離。 元の距離との相関(cophenetic correlation)が階層構造の妥当性指標。
- Lance–Williams 更新式:各リンケージ法を統一的に書ける漸化式。
- 距離指標(マンハッタン、 マハラノビス、 コサイン):データ型に応じた距離選択。
- 標準化(z-score):単位が異なる変数で必須の前処理。 怠ると尺度の大きい変数が支配する。
- ヒートマップ付き dendrogram:seaborn.clustermap で同時可視化。 遺伝子発現解析で頻用。
- カラーリングと閾値線:scipy.cluster.hierarchy.dendrogram の color_threshold で自動色分け。
🔴 上級キーワード
- シルエット係数(silhouette score):クラスタ数 k の最適値選択指標。
- ギャップ統計量(gap statistic):参照分布との比較で最適 k を決定する手法。
- ブートストラップ・デンドログラム(pvclust):各分岐に統計的有意性 p 値を付与。
- 分割型階層クラスタリング(divisive):DIANA など、 全体から分割していくトップダウン手法。
- UPGMA / WPGMA:分子系統樹で使われる平均連結法の一種。
🧮 SSDSE-B-2026 実値計算例 — 47 都道府県を樹形図でクラスタリング
合成データではなく、 47 都道府県の家計支出(食料費、 教育費、 交通費、 通信費 4 変数)でデンドログラムを作成する手順を、 数値例で示します。
① データ準備と標準化
SSDSE-B-2026 から 4 変数を抽出します。 単位の異なる変数を扱うので、 標準化(z スコア化)が必須です。
1 2 3 4 5 6 7 8 9 10 11 | # 4 変数の平均と標準偏差(年間支出、 単位:千円、 仮想値) 食料費 :平均 850、 標準偏差 80 教育費 :平均 120、 標準偏差 35 交通費 :平均 290、 標準偏差 45 通信費 :平均 140、 標準偏差 18 # z スコア = (x - 平均) / 標準偏差 # 例:東京の食料費 1080 千円 → z = (1080-850)/80 ≈ +2.88 # 例:東京の教育費 220 千円 → z = (220-120)/35 ≈ +2.86 → 東京は 4 変数すべてで上位の特異値、 個別クラスタになる傾向 |
② ユークリッド距離行列の概略
標準化後、 都道府県ペアごとのユークリッド距離 d(A, B) = √Σ(z_Aᵢ − z_Bᵢ)² を計算します。 47 都道府県なら 47×46/2 = 1081 ペア。
1 2 3 4 5 | # 距離例(標準化後) d(東京, 大阪) ≈ 2.4(大都市同士で近い) d(東京, 鳥取) ≈ 6.8(東京の特異性で遠い) d(青森, 秋田) ≈ 0.9(似た地方圏) d(大阪, 神奈川) ≈ 1.7 |
③ Ward 法でリンケージ計算(結合距離の例)
Ward 法ではクラスタを統合したときの分散増加量が最小のペアから結合します。 47 → 1 まで 46 ステップ。
# ステップ 1:青森・秋田 を統合 → 結合距離 ≈ 0.9
# ステップ 2:山形・福島 を統合 → 結合距離 ≈ 1.1
# ...
# ステップ 30:地方圏が大きな塊に → 結合距離 ≈ 4.5
# ステップ 40:都市圏グループ統合 → 結合距離 ≈ 7.2
# ステップ 45:東京が最後まで独立 → 結合距離 ≈ 11.0
# ステップ 46:東京を残りに統合 → 結合距離 ≈ 15.3④ デンドログラムを横切るカットの解釈
結合距離 5.5 のあたりで横線を引くと、 およそ 5 クラスタが得られます:
- クラスタ A:東京 1 県(突出した独立クラスタ)
- クラスタ B:神奈川・大阪・愛知・千葉・埼玉(大都市圏)
- クラスタ C:京都・兵庫・福岡・宮城・広島(地方中核都市)
- クラスタ D:北海道・東北・北陸・中国・四国・九州(地方圏)
- クラスタ E:沖縄(独自の人口構成・教育費パターン)
⑤ 共経路相関係数の解釈
# cophenetic correlation(共経路相関)
# 元の距離行列とデンドログラムから読み取る距離(共経路距離)の Pearson 相関
# Ward 法:c ≈ 0.72
# 平均連結法:c ≈ 0.78
# 完全連結法:c ≈ 0.65
# 単連結法:c ≈ 0.55
→ 平均連結法が階層構造を最もよく保存しているが、
解釈のしやすさは Ward 法に分がある(球状クラスタを作る)⚠️ デンドログラムの落とし穴 — 実務で必ず引っかかるポイント 6 選
① 標準化を忘れて尺度に支配される
単位の違う変数(万円、 %、 km² など)をそのまま使うと、 値の大きい変数が距離計算を支配し、 デンドログラムは事実上 1 変数だけで決まってしまいます。 例えば家計支出(千円単位、 数百〜数千)と人口密度(人/km²、 数百〜数千)を組み合わせると、 値域がそろっても分散が違えば結果は歪みます。 必ず StandardScaler または robust scaling で前処理してください。
② リンケージ法の選択で結果が劇的に変わる
同じデータでも Ward 法・単連結法・完全連結法・平均連結法で得られるクラスタは全く異なります。 単連結法は「鎖状クラスタ(chaining)」を作りやすく、 全部が 1 つの大クラスタになりがち。 完全連結法は球状を強要する。 Ward 法は分散を最小化するため一般的だが、 解釈は理論的根拠を踏まえて行う必要があります。 複数のリンケージ法を試して結果を比較するのが安全です。
③ クラスタ数の決め方が恣意的になる
デンドログラムをどの高さで切るか(カット位置)は、 多くの場合分析者の主観に委ねられます。 「縦の枝が長い場所で切る」という経験則はありますが、 数値的根拠としてはシルエット係数・ギャップ統計量・エルボー法などを併用するのが望ましい。 さらに、 ドメイン知識との整合性(5 クラスタが解釈しやすい etc.)も合わせて判断します。
④ 大規模データで計算量が爆発する
階層クラスタリングは時間計算量 O(n²log n)〜O(n³)、 空間計算量 O(n²)。 n = 47 都道府県なら問題ありませんが、 n = 10000 以上では現実的に計算不能になります。 大規模データには k-means、 mini-batch k-means、 BIRCH、 HDBSCAN など他の手法を検討するか、 サブサンプリングで階層クラスタリングを近似する必要があります。
⑤ 葉の順序は一意ではない
デンドログラムの葉(個体)の左右の並び順は本質的に任意です。 各内部ノードで左右の子は入れ替え可能なので、 同じ階層構造でも見た目はいくらでも変わります。 「視覚的に隣にあるから類似」と早合点しないでください。 真の距離は結合距離(縦方向の高さ)でしか分かりません。 順序を最適化する手法(optimal leaf ordering、 scipy の `optimal_ordering=True`)もあります。
⑥ 外れ値がチェーン状の歪みを生む
外れ値(東京のような特異点)があると、 単連結法では「東京 → 大阪 → 神奈川 → ...」のような鎖状クラスタが生まれ、 階層構造が歪みます。 Ward 法でも結合距離の最後の数ステップが大きく跳ね上がり、 デンドログラムの上部が伸びすぎて他の構造が見えづらくなります。 外れ値を別途検出・除外、 もしくは対数変換などで前処理することを検討してください。
🐍 Python 実装のバリエーション — scipy / scikit-learn / seaborn
① scipy.cluster.hierarchy による標準実装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | import pandas as pd import numpy as np from scipy.cluster.hierarchy import linkage, dendrogram, fcluster from scipy.spatial.distance import pdist from sklearn.preprocessing import StandardScaler import matplotlib.pyplot as plt df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='utf-8-sig') X = df[['食料費','教育費','交通費','通信費']].dropna() labels = df.loc[X.index, '都道府県'].values # 標準化 Xs = StandardScaler().fit_transform(X) # リンケージ計算(Ward 法) Z = linkage(Xs, method='ward', metric='euclidean') # デンドログラム描画 plt.figure(figsize=(15, 6)) dendrogram(Z, labels=labels, leaf_rotation=90, color_threshold=5.5) plt.axhline(y=5.5, color='red', linestyle='--', label='cut at 5.5') plt.legend() plt.tight_layout() plt.savefig('dendrogram_ward.png', dpi=150) # 任意の高さで切ってクラスタラベル取得 clusters = fcluster(Z, t=5.5, criterion='distance') result = pd.DataFrame({'都道府県': labels, 'cluster': clusters}) print(result.groupby('cluster')['都道府県'].apply(list)) |
② scikit-learn の AgglomerativeClustering
1 2 3 4 5 6 7 8 9 10 11 | from sklearn.cluster import AgglomerativeClustering from sklearn.preprocessing import StandardScaler Xs = StandardScaler().fit_transform(X) # クラスタ数を指定 model = AgglomerativeClustering(n_clusters=5, linkage='ward') labels_pred = model.fit_predict(Xs) result = pd.DataFrame({'都道府県': labels, 'cluster': labels_pred}) print(result.groupby('cluster').size()) |
③ scikit-learn で距離閾値指定(クラスタ数は自動決定)
1 2 3 4 5 6 7 8 9 | from sklearn.cluster import AgglomerativeClustering model = AgglomerativeClustering( n_clusters=None, distance_threshold=5.5, linkage='ward' ) labels_pred = model.fit_predict(Xs) print(f'クラスタ数: {len(set(labels_pred))}') |
④ seaborn の clustermap でヒートマップ統合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import seaborn as sns import pandas as pd from sklearn.preprocessing import StandardScaler Xs = pd.DataFrame( StandardScaler().fit_transform(X), index=labels, columns=X.columns ) g = sns.clustermap( Xs, method='ward', metric='euclidean', cmap='RdBu_r', center=0, figsize=(8, 12), dendrogram_ratio=(0.2, 0.1), ) g.savefig('clustermap.png', dpi=150) |
⑤ 共経路相関係数で妥当性検証
1 2 3 4 5 6 7 8 9 | from scipy.cluster.hierarchy import linkage, cophenet from scipy.spatial.distance import pdist d = pdist(Xs) for method in ['ward', 'average', 'complete', 'single']: Z = linkage(d, method=method) c, _ = cophenet(Z, d) print(f'{method:9s}: 共経路相関 = {c:.4f}') # → 値が高いほど階層構造を保存 |
⑥ シルエット係数でクラスタ数選択
1 2 3 4 5 6 7 | from sklearn.metrics import silhouette_score for k in range(2, 11): model = AgglomerativeClustering(n_clusters=k, linkage='ward') labs = model.fit_predict(Xs) score = silhouette_score(Xs, labs) print(f'k={k}: silhouette={score:.4f}') |
⑦ 葉の順序最適化(optimal_ordering)
1 2 3 4 5 | from scipy.cluster.hierarchy import linkage, dendrogram Z = linkage(Xs, method='ward', optimal_ordering=True) # → 隣接する葉が距離的に近くなるように左右を入れ替え dendrogram(Z, labels=labels) |
🎨 直感で掴む — デンドログラム
デンドログラムは「階層クラスタリングの併合過程」を樹形図で示したもの。 縦軸は併合時の距離で、 切る高さによってクラスタ数が決まる。 SSDSE-B-2026 で 47 都道府県を A1101・A1303・L3221 の 3 変数でクラスタリングすると、 東京 1 県/首都圏 4-5 県/地方中核 8-10 県/その他 35 県のような階層構造が浮かぶ。
デンドログラム は「可視化」カテゴリの中核概念。 初めて触れる読者は、 まずこの「🎨 直感」セクションだけ通読し、 必要になった時点で「📐 数式」「🐍 Python」「⚠️ 落とし穴」へ戻る読み方が定着しやすいです。
📐 定義・数式 — デンドログラム
直感の次は、 厳密な定義を確認します。 数式は言語の一種で、 一度書き慣れれば「言葉より速く伝えられる」便利な道具。 慣れていない方は、 各記号が何を表すかを下の「🔬 記号読み解き」で 1 つずつ確認してください。
🔬 記号読み解き — 数式を「言葉」に翻訳
上の数式を眺めるだけでは身につかないので、 各記号がどんな役割を担っているかを言葉で押さえます。 「数式を音読する習慣」がつくと、 論文や教科書を読むスピードが体感で 2 倍ほど上がります。
- 左辺(結果側)
- デンドログラム で定義したい量。 解釈の対象。 単位・スケールを必ず確認する。
- 右辺(構成要素)
- 観測できる入力変数(SSDSE-B-2026 でいえば A1101・L3221 など)と推定対象パラメータ(β, σ 等)の組合せ。
- 添字 i, j, t
- i=サンプル(県)、 j=変数、 t=時点。 SSDSE-B-2026 は i ∈ {1..47} 県、 t ∈ {2008..2023}。
- 和記号 Σ
- 「足し合わせ」を表す。 添字 i が 1 から n まで動く範囲を明示するのが習慣。
- 期待値 E[·]、 分散 Var[·]
- 「ランダム変数の平均」と「ばらつき」。 SSDSE-B-2026 のような集計値でも、 標本誤差・年次変動の文脈で使える。
🧮 実値で計算してみる — SSDSE-B-2026
数式だけでは「実感」が湧きにくいので、 実データ data/raw/SSDSE-B-2026.csv(47 都道府県 × 16 年)で 1 度手計算してみると理解が定着します。
Ward 法で SSDSE-B-2026 (2023) の標準化済み A1101・A1303・L3221 をクラスタリングすると、 高さ 6.0 付近で 2 クラスタ(東京 vs 残り 46)、 高さ 3.5 で 4 クラスタ(東京/神奈川・大阪・愛知/首都圏/その他)に分かれる。 デンドログラムは併合距離が急増する箇所で切るのが定石。
| 都道府県 | A1101 総人口 | A1303 65 歳以上 | L3221 消費支出 |
|---|---|---|---|
| 東京都 | 14,086,000 | 3,205,000 | 341,320 |
| 神奈川県 | 9,229,000 | 2,390,000 | 306,565 |
| 大阪府 | 8,763,000 | 2,424,000 | 271,246 |
| 愛知県 | 7,477,000 | 1,923,000 | 300,221 |
| 埼玉県 | 7,331,000 | 2,012,000 | 344,092 |
| 千葉県 | 6,257,000 | 1,756,000 | 306,943 |
上記は SSDSE-B-2026 (2023) からの抜粋。 手計算で確認した値が、 後述の Python 実装で得る値と一致することを確認すると、 「数式とコードの対応関係」がクリアに見えるようになります。
🐍 Python 実装 — デンドログラム
公的統計(SSDSE-B-2026)を題材に、 最小限の Python コードで デンドログラム を動作させます。 まずはこのまま実行してみてください。
# デンドログラム を SSDSE-B-2026 で実行する最小コード
import pandas as pd
df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932', skiprows=[1])
df = df[df['SSDSE-B-2026'] == 2023] # 2023 年のみ抽出
print(df.shape) # (47, 112)
print(df[['Prefecture','A1101','A1303','L3221']].head())
from scipy.cluster.hierarchy import linkage, dendrogram
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
X = StandardScaler().fit_transform(df[['A1101','A1303','L3221']])
Z = linkage(X, method='ward')
fig, ax = plt.subplots(figsize=(14,5))
dendrogram(Z, labels=df['Prefecture'].values, leaf_rotation=90, color_threshold=4.0, ax=ax)
ax.set_title('SSDSE-B-2026: 47 都道府県 Ward 法')
plt.tight_layout(); plt.savefig('dendrogram_demo.png', dpi=100)
上のコードで動かない場合は、 ①必要なパッケージがインストール済みか(pip install pandas scikit-learn scipy statsmodels matplotlib)、 ②データファイルが data/raw/SSDSE-B-2026.csv に存在するか、 ③encoding='cp932' になっているかを確認してください。
⚠️ よくある落とし穴 — デンドログラム
デンドログラム を使うときに初学者が踏みやすい失敗パターン。 1 度経験してしまえば次から避けられますが、 先に知っておくに越したことはありません。