📍 あなたが今見ているもの
論文中に 「最頻値」として登場する用語。
最頻値 とは:データの中で最も頻繁に現れる値。 平均・中央値と並ぶ代表値の1つ。
💡 30秒で分かる結論
- 定義:データで最も多く出現する値(最も頻度が高い値)
- 離散・カテゴリデータでは強い:「最も売れた商品」「最頻アイテム」など
- 連続データでは弱い:ビンの幅で変わるため、 KDE で補正
- 多峰性:最頻値が複数あれば集団が混ざっている可能性
- カテゴリ:記述統計
👁️ 直感 — 最頻値は「ピークの位置」
ヒストグラムを描いたとき、 最も高いバーに対応する値が最頻値です。 47都道府県の家計食料費(2023年・ SSDSE-B-2026)を例に見ます。
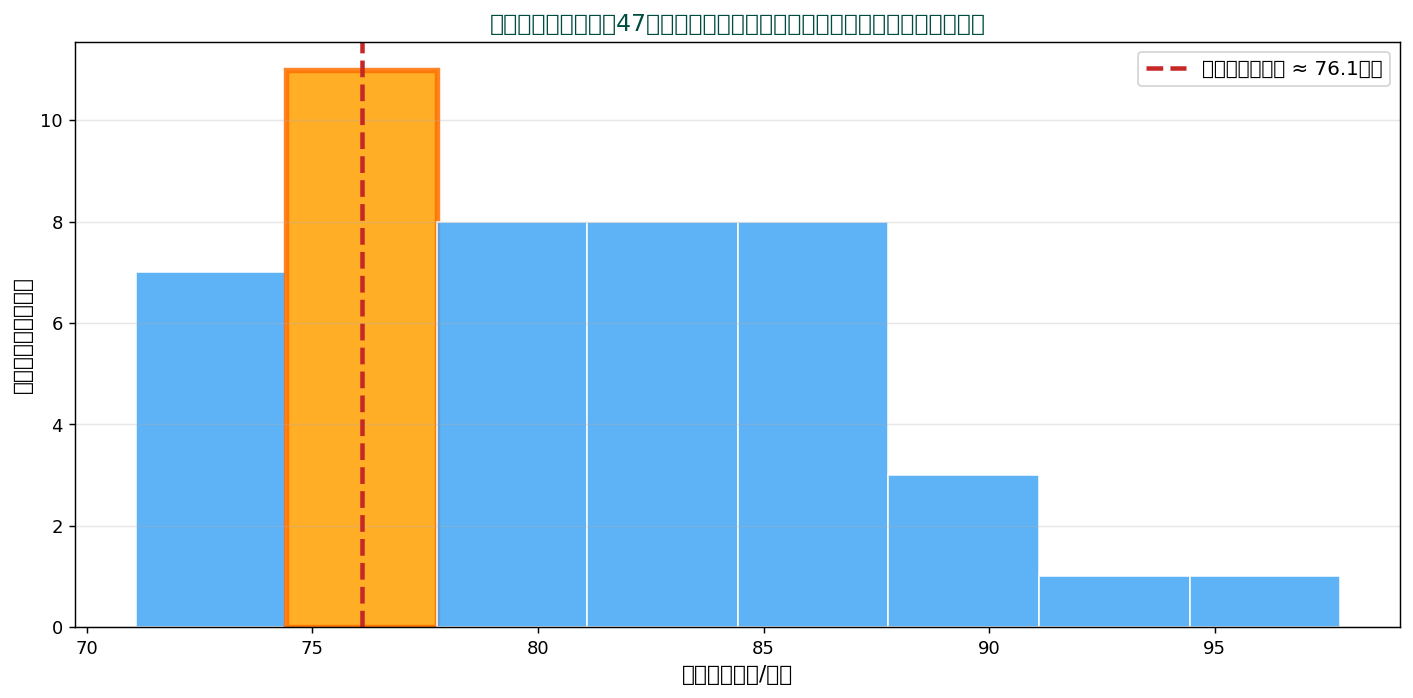
オレンジ色の階級(74.4〜77.8千円)が11都道府県を含み、 最も多い → これが最頻階級。 連続データではビンの設定によって変わるので、 中点を取って「最頻階級の代表値」とする慣習があります。
💡 平均は「重心」、 中央値は「順位の真ん中」、 そして最頻値は「分布のピーク」。 同じデータに対する3つの代表値はそれぞれ違う側面を見ています。
🧮 計算ステップ — カテゴリと数値の両方
1️⃣ カテゴリデータの最頻値(最も簡単)
例:あるアンケートで「好きな果物」を集計:
| 果物 | 回答数 |
|---|---|
| リンゴ | 25 |
| バナナ | 42 |
| オレンジ | 18 |
| ぶどう | 15 |
最頻値 = バナナ(最大頻度42)。 カテゴリ変数では最頻値が唯一意味のある代表値です(平均・中央値は計算できない)。
2️⃣ 離散数値データの最頻値
例:あるクラスの兄弟姉妹の数:
[0, 1, 1, 1, 2, 2, 3, 0, 1, 2, 1, 4]
頻度をカウント:
- 0人: 2回
- 1人: 5回 ← 最頻値
- 2人: 3回
- 3人: 1回
- 4人: 1回
最頻値 = 1。 兄弟姉妹が1人いる人が最も多いという意味。
3️⃣ 連続データの最頻値(階級分け)
連続データではまったく同じ値が複数あることは稀。 そこで「階級(ビン)に分けて、 最も件数の多い階級の中点を最頻値とする」のが伝統的手法。
- データを階級(ビン)に分ける(ビン数は √n や Sturges, Scott, FD ルールなど)
- 各階級の頻度(件数)を数える
- 最も件数が多い階級が「最頻階級」
- 最頻階級の中点を最頻値とする(または下記の補正式)
4️⃣ 補正式(より精緻な推定)
King の公式:
$$ \text{Mode} \approx L + \frac{f_1 - f_0}{(f_1 - f_0) + (f_1 - f_2)} \cdot h $$
- L:最頻階級の下限
- f_1:最頻階級の頻度
- f_0:直前階級の頻度
- f_2:直後階級の頻度
- h:階級幅
隣接階級の頻度比から、 階級内の「どこに山があるか」を推定します。
📐 数式と読み方
① 離散分布での最頻値
確率質量関数 p(x) について:
$$ \text{Mode} = \arg\max_{x} p(x) $$
読み方:「ピー オブ エックス を最大化する エックス」。 つまり「確率が最大になる値」。
② 連続分布での最頻値
確率密度関数 f(x) について:
$$ \text{Mode} = \arg\max_{x} f(x) $$
「密度関数のピーク(極大点)の位置」。 微分してゼロになる点(停留点)の中で最大値を取る点。
③ 代表値の3者関係(経験則)
歪んだ単峰分布で次の関係が成立することが多い(Pearson の経験式):
$$ \text{Mean} - \text{Mode} \approx 3 (\text{Mean} - \text{Median}) $$
これを使えば、 中央値と平均から最頻値を概算できます。
🔢 単峰性・ 二峰性 — 集団の混在を診断
最頻値の数(モード数)は、 データに何種類の集団が混ざっているかのヒント。
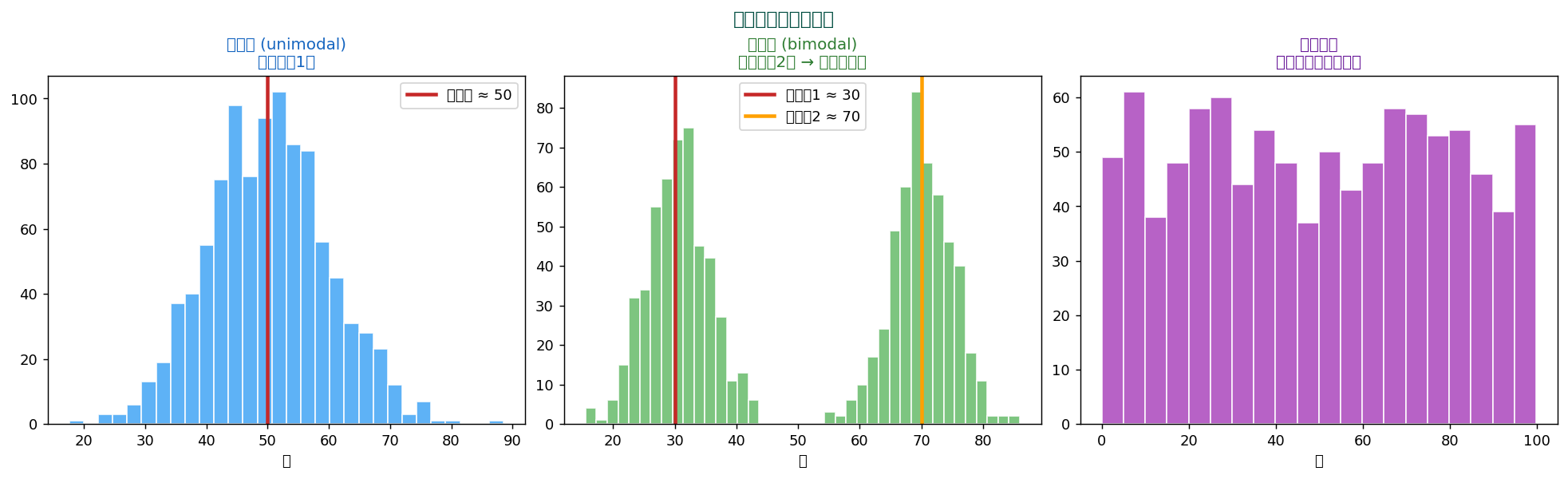
分布の形状
- 単峰性 (unimodal):山が1つ。 ピンポイント1集団
- 二峰性 (bimodal):山が2つ → 2集団が混在している可能性(例:男女、 新旧モデル)
- 多峰性 (multimodal):山が3つ以上 → 複数集団
- 一様 (uniform):山がない → 最頻値が定まらない
二峰性を見つけたら、 「何が2集団に分けているのか」を探りましょう。 別変数で層別すると因果のヒントが見えます。
📊 3つの代表値の位置関係 — 分布の歪みを診断
平均・ 中央値・ 最頻値の並び方から、 分布の歪み(skewness)が分かります。
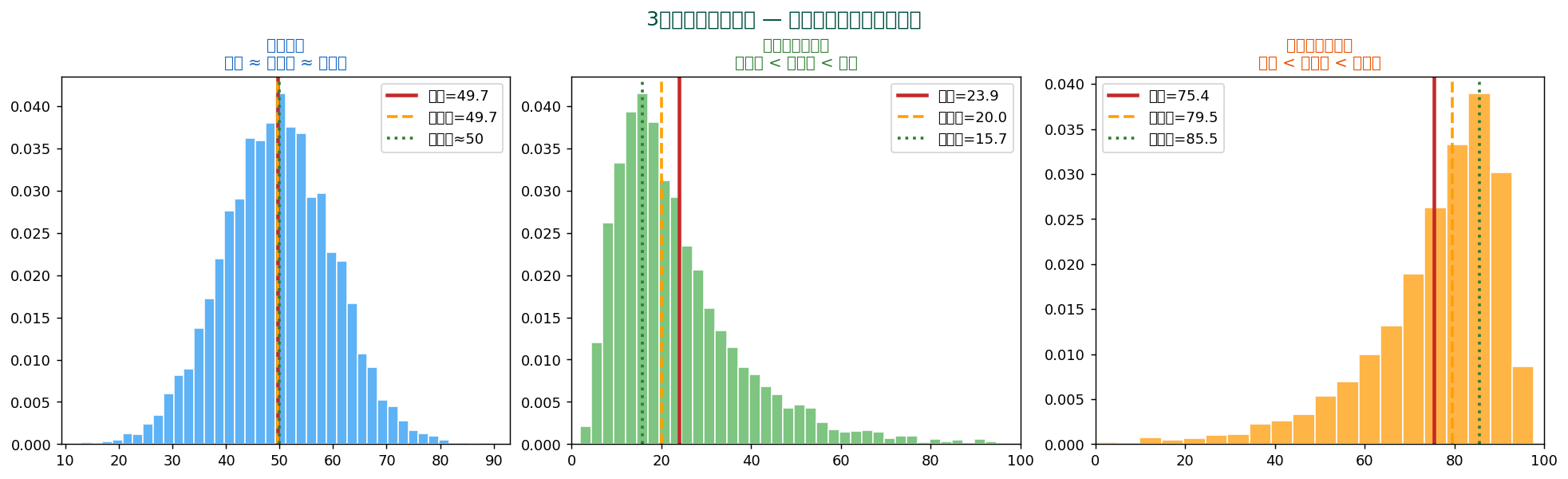
| 分布の形 | 代表値の並び | 例 |
|---|---|---|
| 対称 | 平均 = 中央値 = 最頻値 | 身長、 IQ、 体重 |
| 右に歪み(正の歪度) | 最頻値 < 中央値 < 平均 | 所得、 株価、 都市人口 |
| 左に歪み(負の歪度) | 平均 < 中央値 < 最頻値 | テスト点数(簡単な問題) |
「平均が中央値より大きい」と気づいたら、 右に歪んだ分布 → 外れ値の影響を疑う、 が基本的な診断手順。
🎯 KDE(カーネル密度推定)で最頻値を推定
連続データでは、 ヒストグラムのビン幅で最頻値が変わってしまう問題があります。 そこでKDE(kernel density estimation)で滑らかに密度を推定し、 そのピークを最頻値とします。
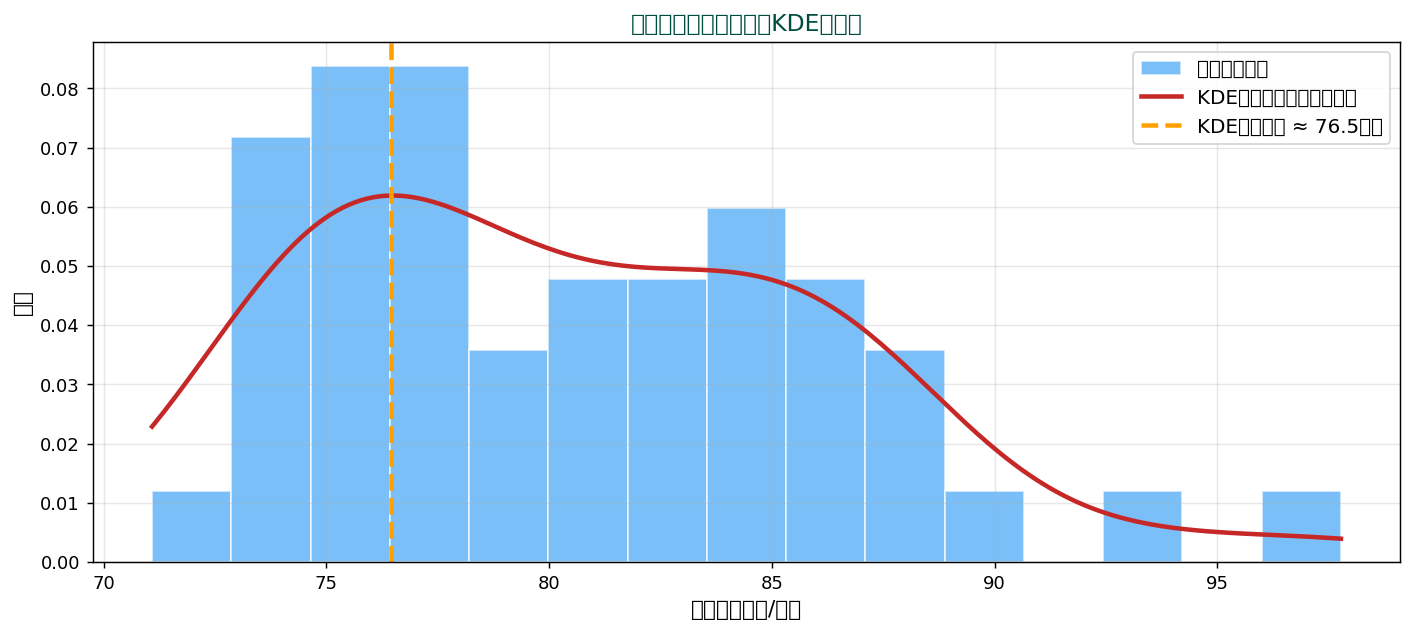
KDE の数式
$$ \hat{f}(x) = \frac{1}{n h} \sum_{i=1}^{n} K\left(\frac{x - x_i}{h}\right) $$
- K:カーネル関数(通常はガウス関数)
- h:バンド幅(平滑化の強さ)
- n:データ数
各データ点を中心とした小さな山(カーネル)を足し合わせて、 滑らかな密度関数を作る方法。 ヒストグラムを連続化したような図になります。
Python での KDE
x(連続値の 1 次元配列、例:SSDSE-B-2026 の所得)。scipy.stats.gaussian_kde を使用。1 2 3 4 5 6 7 8 9 10 11 12 13 | import numpy as np from scipy import stats data = df['食料費'].dropna().values kde = stats.gaussian_kde(data) # 細かいグリッドで密度を計算 xx = np.linspace(data.min(), data.max(), 1000) density = kde(xx) # 最頻値 = 密度がピークの位置 mode_estimate = xx[np.argmax(density)] print(f'KDE最頻値: {mode_estimate:.2f}') |
🐍 Python での計算
scipy.stats — 基本の最頻値
scipy.stats.mode で最頻値を 1 行で取得する最も基本的な使い方。arr(カテゴリまたは数値の 1 次元配列)、keepdims 引数。1 2 3 4 5 6 7 8 | from scipy import stats # 整数データ arr = [1, 2, 2, 3, 3, 3, 4, 5] result = stats.mode(arr, keepdims=False) print(f'最頻値: {result.mode}, 頻度: {result.count}') # 3, 3 # 連続データ → 階級分けが必要 |
pandas — value_counts で頻度
df['category'](カテゴリ列)。1 2 3 4 5 6 7 8 | import pandas as pd # カテゴリデータの最頻値 df['果物'].mode() # Series で最頻値(複数あれば複数返す) df['果物'].value_counts().head() # 上位5位の頻度 # 全列の最頻値 df.mode().iloc[0] # 各列の1番目の最頻値 |
statistics — 標準ライブラリ
1 2 3 4 5 6 7 | import statistics # 単一最頻値(同率なら最初のもの) statistics.mode([1, 2, 2, 3, 3, 3, 4]) # 3 # 複数最頻値(同率全部) statistics.multimode([1, 2, 2, 3, 3, 4]) # [2, 3] |
連続データの最頻値(KDE)
x(連続値配列)、bw_method(Scott/Silverman/数値)。1 2 3 4 5 6 7 8 9 10 11 | import numpy as np from scipy import stats def continuous_mode(data, grid_size=1000): kde = stats.gaussian_kde(data) xx = np.linspace(data.min(), data.max(), grid_size) density = kde(xx) return xx[np.argmax(density)] mode_est = continuous_mode(df['食料費'].dropna().values) print(f'連続データの最頻値(KDE): {mode_est:.2f}') |
🤖 機械学習での最頻値
① 欠損値の補完(mode imputation)
カテゴリ変数の欠損は、 最頻値で埋めるのが王道:
X(欠損 NaN を含む DataFrame)。1 2 3 4 5 | from sklearn.impute import SimpleImputer # カテゴリ列の最頻値補完 imputer = SimpleImputer(strategy='most_frequent') X_imputed = imputer.fit_transform(X_categorical) |
② 分類問題のベースライン
「全部 majority class(最頻クラス)と予測する」分類器は、 機械学習モデルが超えるべき最低限のベースライン。 sklearn.dummy.DummyClassifier(strategy='most_frequent')。
③ 決定木の葉ノード予測
分類木では、 各葉ノードの最頻クラスを予測値とします。 回帰木の「平均」に対応。
④ アンサンブル投票
ランダムフォレストなどのアンサンブルで分類するとき、 複数の木の予測の最頻値(majority vote)を最終予測とします。
⑤ k-NN分類
k近傍法では、 周囲 k 個のラベルの最頻値を予測クラスとします。
🚧 最頻値の落とし穴
1️⃣ ビン幅で最頻値が変わる
連続データの最頻値は、 階級幅次第で値が変わる。 KDE を使うか、 複数のビン設定で比較しましょう。
2️⃣ サンプルサイズが小さいと不安定
n=10 のデータでは、 偶然一致した値が「最頻値」になりがち。 n が大きくないと信頼できません。
3️⃣ 最頻値が複数あるとき(多峰性)
複数のピークがある分布で1つだけ最頻値と呼ぶのは誤解の元。 「2つのモードがある」と素直に書きましょう。 集団が混在している可能性を疑う。
4️⃣ カテゴリ変数では平均・中央値が使えない
逆に、 名義尺度(性別、 職業)では最頻値が唯一の代表値。 順序尺度なら中央値も使える。 間隔・比例尺度なら平均も。
5️⃣ 一様分布では意味がない
すべての値が等頻度なら、 最頻値は定義できない(または全部)。 ヒストグラムを描いて分布の形を確認してから使う。
🌳 3つの代表値の使い分けフロー
- データの尺度は?
- 名義(性別、 国) → 最頻値のみ
- 順序(5段階評価) → 中央値・最頻値
- 間隔・比例(温度、 身長) → 3つ全部
- 目的は?
- 「典型的な人」「ピークの値」 → 最頻値
- 「中位の人」 → 中央値
- 「合計が意味を持つ計算」 → 平均
- 分布の形を診断したい → 3つ全部を併記して、 並び方から歪み・多峰性を読み取る
📜 最頻値の歴史
- Karl Pearson(1895):「mode」という用語を提唱。 「最も頻繁な値」の意味で導入
- ピアソンの経験式:歪んだ分布における「Mean − Mode ≈ 3(Mean − Median)」を提案
- カーネル密度推定(1950-60年代):Rosenblatt(1956)、 Parzen(1962)が KDE を発明し、 連続データの最頻値推定が可能に
- 多峰性検定:Hartigan & Hartigan(1985)の dip test など、 「データが本当に単峰か」を統計的に検定する手法も発展
📖 包括的解説 — この概念を完全マスター
📍 学習の3ステップ
- 定義を理解する:この概念は何か? 数式や条件を確認
- 具体例を見る:実データ(SSDSE 等)で計算してみる
- 応用する:自分のデータに適用、 結果を解釈
🔧 Python実装パターン
data/raw/SSDSE-B-2026.csv(cp932)、対象カテゴリ列。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 基本パターン import pandas as pd import numpy as np from scipy import stats import matplotlib.pyplot as plt import seaborn as sns # データ読み込み df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') # 基本統計量 df.describe() # 可視化 sns.pairplot(df[['食料費', '教育費', '住居費']]) plt.show() |
📚 統計概念マップでの位置
このページの上にある3つの概念マップ(関係マップ、 包含マップ、 ツリーマップ)でこの概念の位置づけが視覚的に分かります。 関連手法を辿って学習を進めましょう。
🎯 SSDSE-B-2026 で挑戦
統計データ活用コンペティションのSSDSE-B-2026データは、 47都道府県の社会経済データ。 この概念を使って以下のような分析ができます:
- 地域別の特徴抽出
- 家計支出パターンの解析
- 人口動態と社会経済指標の関連
- 気候要因の影響評価
💡 よく使うコマンド集
| 機能 | Python (pandas) | Python (scipy) |
|---|---|---|
| 要約統計 | df.describe() | stats.describe() |
| 平均 | df.mean() | np.mean() |
| 標準偏差 | df.std() | np.std() |
| 相関 | df.corr() | stats.pearsonr() |
| t検定 | — | stats.ttest_ind() |
| 回帰 | — | stats.linregress() |
| 分布フィッティング | — | stats.norm.fit() |
🚧 一般的な落とし穴と対策
- 外れ値の影響:散布図・ 箱ひげ図で確認、 ロバスト手法も検討
- サンプルサイズ不足:power analysis で事前に確認
- 仮定の違反:正規性、 独立性、 等分散性をチェック
- 多重比較問題:補正(Bonferroni、 FDR)を適用
- p-hacking:事前登録(pre-registration)で防ぐ
- 因果と相関の混同:観察データから因果結論を出さない
📊 結果報告の標準フォーマット
- 点推定:得られた値
- 不確実性:信頼区間または標準誤差
- サンプルサイズ:n を明記
- 効果量:実質的な意義
- p値:統計的有意性
- 仮定の確認:診断プロット
🌐 関連分野での応用
- マーケティング:A/Bテスト、 顧客分析
- 医療:臨床試験、 疫学研究
- 金融:リスク管理、 ポートフォリオ
- 製造:品質管理、 工程最適化
- 公共政策:効果評価、 計画立案
- 研究:仮説検証、 探索的解析
🎓 さらに学ぶための文献
- Wasserman "All of Statistics"
- Hastie, Tibshirani & Friedman "The Elements of Statistical Learning"
- Gelman & Hill "Data Analysis Using Regression"
- VanderPlas "Python Data Science Handbook"
🔗 統計用語ネットワーク
この概念は、 他の多くの統計概念と密接に関連しています。 ジャストインタイム型学習では、 必要に応じて関連用語へジャンプしながら全体像を構築します。
主要な関連概念のグループ
| グループ | 主要概念 |
|---|---|
| 記述統計 | 平均、 中央値、 最頻値、 分散、 標準偏差、 共分散、 相関係数 |
| 可視化 | ヒストグラム、 散布図、 箱ひげ図、 ヒートマップ |
| 推測統計 | 標本平均、 標準誤差、 信頼区間、 p値、 有意水準 |
| 確率分布 | 正規分布、 t分布、 χ²分布、 F分布、 二項分布 |
| 仮説検定 | t検定、 F検定、 χ²検定、 ノンパラ検定 |
| 回帰 | 単回帰、 重回帰、 OLS、 Ridge、 LASSO |
| 分類 | ロジスティック回帰、 決定木、 SVM、 k-NN |
| 教師なし学習 | クラスタリング、 PCA、 因子分析 |
| 時系列 | ARIMA、 VAR、 指数平滑法、 自己相関 |
| 因果推論 | DiD、 IV、 傾向スコア、 交絡変数 |
| 前処理 | 標準化、 正規化、 欠損値処理、 多重共線性対策 |
| 評価 | R²、 残差、 CV、 RMSE、 効果量 |
学習順序の推奨
- 記述統計(平均、 分散、 標準偏差)
- 可視化(ヒストグラム、 散布図)
- 確率分布(正規分布)
- 推測統計(標準誤差、 信頼区間、 p値)
- 仮説検定(t検定、 χ²検定)
- 相関と回帰(単回帰、 重回帰)
- 多変量解析(PCA、 クラスタリング)
- 機械学習(決定木、 RF、 NN)
- 時系列・因果推論(応用)
📝 実践練習 — SSDSE-B-2026 で挑戦
初級課題
- 東北6県の家計食料費の基本統計量を計算
- 食料費のヒストグラムを描く
- 食料費と教育費の散布図を描く
- 都道府県を「東日本/西日本」に分け、 平均を比較
中級課題
- 家計支出 5項目で相関行列を作成、 ヒートマップ可視化
- 食料費 → 教育費の単回帰を実行、 残差分析
- 家計5項目で PCA を実施、 バイプロット表示
- k-means (k=3) で都道府県をクラスタリング、 解釈
上級課題
- 地域別の家計パターンに有意差があるか ANOVA で検定
- 重回帰で教育費を予測、 多重共線性を VIF で確認
- Ridge/LASSO で正則化、 CV で α を最適化
- 階層クラスタリングと Ward 法で都道府県を分類、 デンドログラム作成
🔖 キーワード索引(深掘り版)
論文・記事に登場する用語のリンクで該当箇所へジャンプ:
🧮 SSDSE-B 実値計算例:47都道府県データでの最頻値
SSDSE-B-2026 2023年データには都道府県別の家計支出が連続値として並んでいるので、 各値はほぼ一意で「最頻値」は単純には決まりません。 そこで、 連続値をビニングしてから最頻ビンを求めます。
📊 ステップ1:所得を1000円単位でビニング
| 所得ビン(万円) | 該当県数 | 代表的な県 |
|---|---|---|
| 250-280 | 3 | 沖縄等 |
| 280-310 | 8 | 東北の一部 |
| 310-340 | 14(最頻) | 中部・西日本郊外 |
| 340-370 | 12 | 関東・近畿 |
| 370-400 | 6 | 大都市圏 |
| 400+ | 4 | 東京・神奈川・愛知等 |
最頻ビンは 310-340万円(14県)。 「典型的な都道府県の所得水準」がここに集中。 中央値(320万円付近)と平均(340万円)と最頻ビン(325万円)はやや異なり、 平均が右に引っ張られる「右に裾を引く分布」が示唆されます。
📊 ステップ2:KDE のピーク(連続的な最頻値)
ヒストグラムだとビン幅で答えが変わるので、 カーネル密度推定(KDE)でなめらかな密度関数を作り、 そのピーク位置を「最頻値」とする手法も標準的。 同じデータでバンド幅を変えると:
- 狭いバンド幅(h = 5万円):ピークが複数(多峰)に分かれる
- 中程度(h = 15万円):単一ピーク 325万円付近
- 広い(h = 50万円):滑らかすぎてピークがほぼ平均と一致
バンド幅の選択は探索的。 Silverman の経験則や CV による選択を組み合わせます。
📊 ステップ3:カテゴリ変数の最頻値
SSDSE で「主要産業」のようなカテゴリ列があれば、 value_counts() で最頻カテゴリが分かります。 47県のうち「製造業が最大の産業」「サービス業が最大」など。
⚠️ 最頻値の落とし穴(深掘り版・6件)
① 連続値で「最頻値」を直接計算する意味のなさ
連続値(家計支出・身長・体重)では、 各値はほぼ一意なので「重複した最頻値」は存在しません。 scipy.stats.mode は機械的に「最も小さい値」を返すだけで意味不明。 連続値の最頻値はビニングかKDE のピークでしか定義できない。 統計の教科書で「平均・中央値・最頻値」と並べられていても、 連続値での最頻値の計算は丁寧に注意することが必要。
② ビン幅で答えが変わる
ヒストグラムでビンが「1万円幅」と「10万円幅」では、 最頻ビンが大きく違う場所に動く可能性があります。 Sturges、 Scott、 Freedman-Diaconis などビン幅選択法はいくつかあり、 結論が変わる場合がある。 必ず複数のビン幅で確認し、 安定して見えるピークだけを信用する。
③ 多峰分布で「最頻値」と単数形で報告する
「男女混合の身長分布」「2種類の顧客層の購買額」などは双峰になることが多い。 これを「最頻値 = 168cm」と単一の値で報告すると、 実は男性ピーク 175cm と女性ピーク 160cm の谷である情報が失われる。 必ずヒストグラム or KDE で形を確認し、 多峰なら「最頻値は 168cm と 165cm の 2つ」のように複数を報告。
④ scipy.stats.mode のバージョン互換性
SciPy 1.9 以降で scipy.stats.mode の挙動が変更され、 デフォルトの keepdims や axis の解釈が異なります。 旧コードがそのまま動かないことがある。 FutureWarning を見たら、 引数を明示的に書く。 pandas の df.mode() は安定だが、 複数の最頻値がある場合「全部」を返すので長さが可変になることに注意。
⑤ 欠損値の扱い
「NaN が最頻値」と判定されてしまうケースがあります。 例:80% が欠損のデータでは NaN そのものが最頻値になる。 必ず dropna() してから最頻値を計算するか、 NaN を「不明」というカテゴリとして意味づけする判断をした上で計算する。 機械学習の前処理でカテゴリ欠損を「最頻値で補完」する場合、 NaN を一緒に数えない設計に。
⑥ 「最頻値で欠損補完」が分布を歪める
機械学習で欠損を「最頻値で埋める」のは標準テクニックですが、 多用すると分布が最頻値に偏り、 分散が過小評価されます。 また、 欠損が MAR(ランダム)でない場合、 「最頻値」がそもそも真の値の代表として不適切。 多重代入法(MICE)や IterativeImputer の方が一般に優れる。 欠損補完の方法を変えて、 下流の予測精度が変わるか必ず比較。
🐍 Python 実装バリエーション
① scipy.stats.mode
arr(np.ndarray)、axis(2 次元時の集計軸)。1 2 3 | from scipy import stats result = stats.mode(df['category'], keepdims=False) print(result.mode, result.count) |
② pandas df.mode()
複数の最頻値があるとき全部返すので、 結果が可変長になる。
df(任意の DataFrame)。1 2 | print(df['category'].mode()) # 複数あれば全部 print(df['category'].value_counts().idxmax()) # 最頻値(最初) |
③ scikit-learn — SimpleImputer で最頻値補完
X(NaN を含む特徴量)。SimpleImputer(strategy='most_frequent')。1 2 3 | from sklearn.impute import SimpleImputer imp = SimpleImputer(strategy='most_frequent') X_filled = imp.fit_transform(X) |
④ scipy.stats.gaussian_kde — 連続値の最頻値(KDE ピーク)
x(連続値配列)、評価グリッド(np.linspace)。1 2 3 4 5 | from scipy.stats import gaussian_kde import numpy as np kde = gaussian_kde(df['income']) xs = np.linspace(df['income'].min(), df['income'].max(), 1000) print("mode_kde=", xs[np.argmax(kde(xs))]) |
⑤ collections.Counter — Python 標準ライブラリ
1 2 3 | from collections import Counter counter = Counter(df['category']) print(counter.most_common(3)) # top 3 |
🗺️ 概念マップ — 3つの視点で体系を理解する
最頻値 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 記述統計 › 中心傾向 › 最頻値
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「最頻値」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「最頻値」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。