📍 あなたが今見ているもの
論文中に 「中央値」として登場する用語。
中央値 とは:データを大小に並べたときの真ん中の値。外れ値に強い「ロバストな中心」。
💡 30秒で分かる結論
- 定義:データを大小に並べたときの真ん中の値。外れ値に強い「ロバストな中心」。
- カテゴリ:記述統計
📖 もっと詳しく
中央値(median)は、 データを大小順に並べたときちょうど真ん中の値。 47都道府県データなら、 24番目(または 23-24番目の平均)の値です。
強み:外れ値に強い。 1つの極端な値が混ざっても、 中央値はびくともしません。 「ロバストな中心」と呼ばれます。
使い場面:(i) 所得・支出・地価など歪んだ分布、 (ii) 外れ値が多いデータ、 (iii) 順位データ(順序尺度)。 「日本の平均年収」より「日本の中央値年収」の方が現実を反映することが多い。
箱ひげ図の中央線が中央値。 第2四分位(Q2)、 50%パーセンタイルとも同じ概念。 df.median() で計算。
🎨 直感で掴む — 中央値は「並べて真ん中」
中央値(median)は、 データを小さい順に並べた時の真ん中の値。 平均が「重心」だったのに対し、 中央値は「順位の中心」を表します。 47都道府県の住居費(2023年・ SSDSE-B-2026)を例に見ましょう。
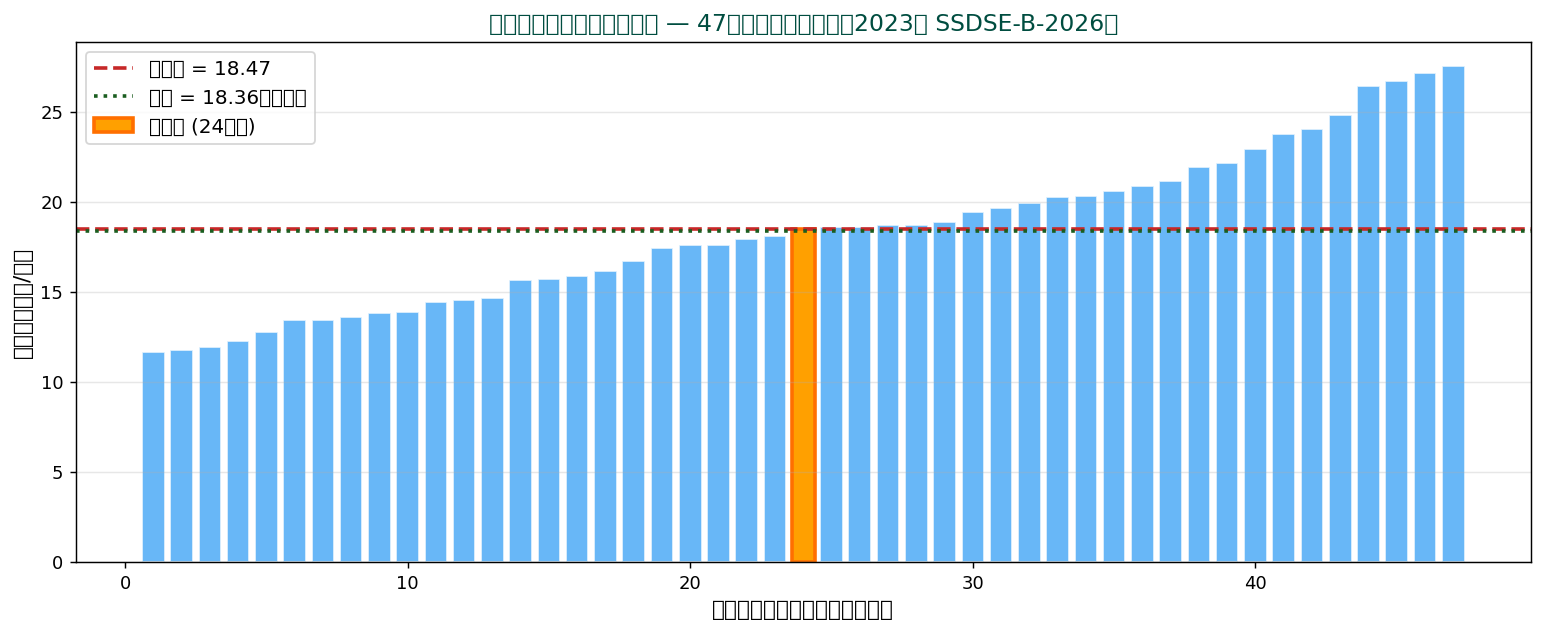
各バーが1つの都道府県の住居費。 オレンジ色の24番目がちょうど中央 → これが中央値 18.47千円です。 赤い点線が平均(18.36千円)。 平均は住居費が高い少数の県(東京、 神奈川など)に引っ張られて高めに出ています。
💡 中央値は順序統計量と呼ばれる量の代表。 「データの値そのもの」ではなく「並び順での位置」を見るため、 外れ値や極端な値の影響を受けにくい性質があります。
🧮 計算ステップ — 7点抽出データで手計算
47都道府県データから等間隔で7県を抜き出して、 中央値を手で計算してみましょう。
1️⃣ 元のデータ(無秩序)
都道府県と住居費(千円/月):
- 神奈川県:11.64
- 福井県:13.60
- 鹿児島県:22.96
- 島根県:15.88
- 長崎県:19.93
- 佐賀県:18.47
- 沖縄県:27.52
2️⃣ 小さい順に並べ替える
| 順位 | 都道府県 | 住居費 |
|---|---|---|
| 1 | 神奈川県 | 11.64 |
| 2 | 福井県 | 13.60 |
| 3 | 島根県 | 15.88 |
| 4 | 佐賀県 | 18.47 |
| 5 | 長崎県 | 19.93 |
| 6 | 鹿児島県 | 22.96 |
| 7 | 沖縄県 | 27.52 |
3️⃣ 真ん中(4番目)が中央値
n = 7(奇数)なので、 真ん中はちょうど (n+1)/2 = 4番目。
中央値 = 18.47 千円
4️⃣ もし n が偶数だったら?
n=6(例:上の表から最後を除く)の場合、 真ん中が「ない」。 そこで 3番目と4番目の平均を取ります:
- 3番目: 15.88
- 4番目: 18.47
- 中央値 = (15.88 + 18.47) / 2 = 17.174 千円
📐 数式と読み方ガイド
① 中央値の定義(数式)
データを並べたものを x_{(1)} ≤ x_{(2)} ≤ ... ≤ x_{(n)} とすると:
$$ \text{median}(x) = \begin{cases} x_{((n+1)/2)} & (n \text{ 奇数}) \\ \frac{x_{(n/2)} + x_{(n/2 + 1)}}{2} & (n \text{ 偶数}) \end{cases} $$
| 記号 | 読み方 | 意味 |
|---|---|---|
| x_{(i)} | エックス カッコ アイ | 並べた時の i 番目の値(順序統計量) |
| n | エヌ | データ数 |
| (n+1)/2 | エヌ プラス いち わる に | 真ん中の位置(n奇数の場合) |
🔬 数式を言葉で読み解く — ② 連続分布での中央値
連続的な確率分布の場合、 累積分布関数 F の0.5 になる点:
$$ F(\text{median}) = 0.5 \quad \Leftrightarrow \quad P(X \le \text{median}) = 0.5 $$
「中央値以下の確率は50%、 以上の確率も50%」という最も基本的な性質。
③ 中央値の最小化問題
中央値はL1 損失を最小化する点として定義できます:
$$ \text{median}(x) = \arg\min_m \sum_i |x_i - m| $$
絶対値の和を最小化する m が中央値です。 これは平均が「二乗和」を最小化するのと対をなします。
④ 平均との対比
| 性質 | 平均 | 中央値 |
|---|---|---|
| 最小化する損失 | L2(二乗和) | L1(絶対値和) |
| 線形性 | ✅ ある | ❌ ない |
| 外れ値耐性 | 弱い | 強い(崩壊点50%) |
| 計算量 | O(n) | O(n log n)(ソート)または O(n)(quickselect) |
| 微分可能性 | ✅ 可能 | ❌ 不可能(不連続) |
🛡️ 外れ値耐性 — 中央値の最大の強み
中央値が最も活躍するのは外れ値や歪んだ分布のとき。 平均との違いを実感する例を見ましょう。
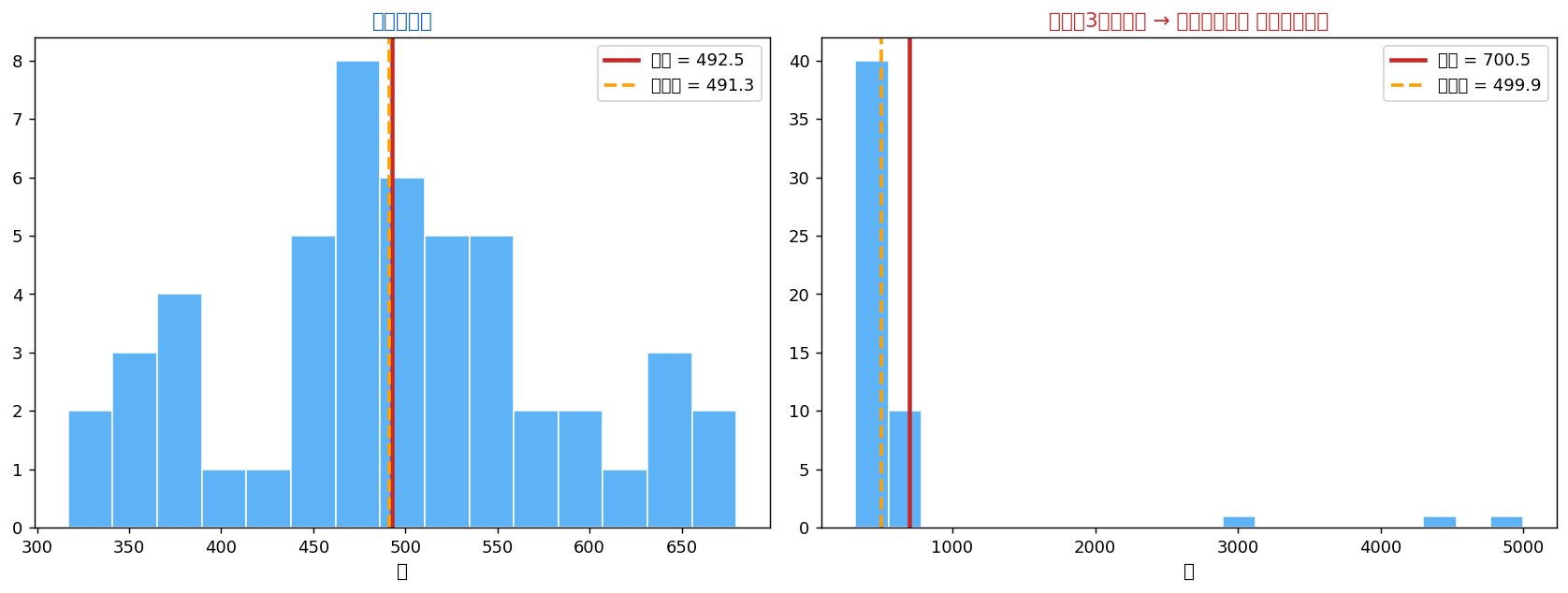
左は正規分布のデータ。 平均と中央値はほぼ一致。
右は同じデータに外れ値(3000, 4500, 5000)を3つ追加。 平均は劇的に上昇するのに、 中央値はほとんど動かない。
崩壊点(breakdown point)
「データの何%まで汚染しても推定値が壊れないか」を表す指標:
- 平均:0%(1点でも極端な値があれば任意に動く)
- 中央値:50%(理論的最大値)
- トリム平均(α=20%):20%
中央値の50%崩壊点は、 ロバスト統計量として理論的最高。 半分以上のデータが「正常」なら推定値は壊れない。
歪んだ分布での違い
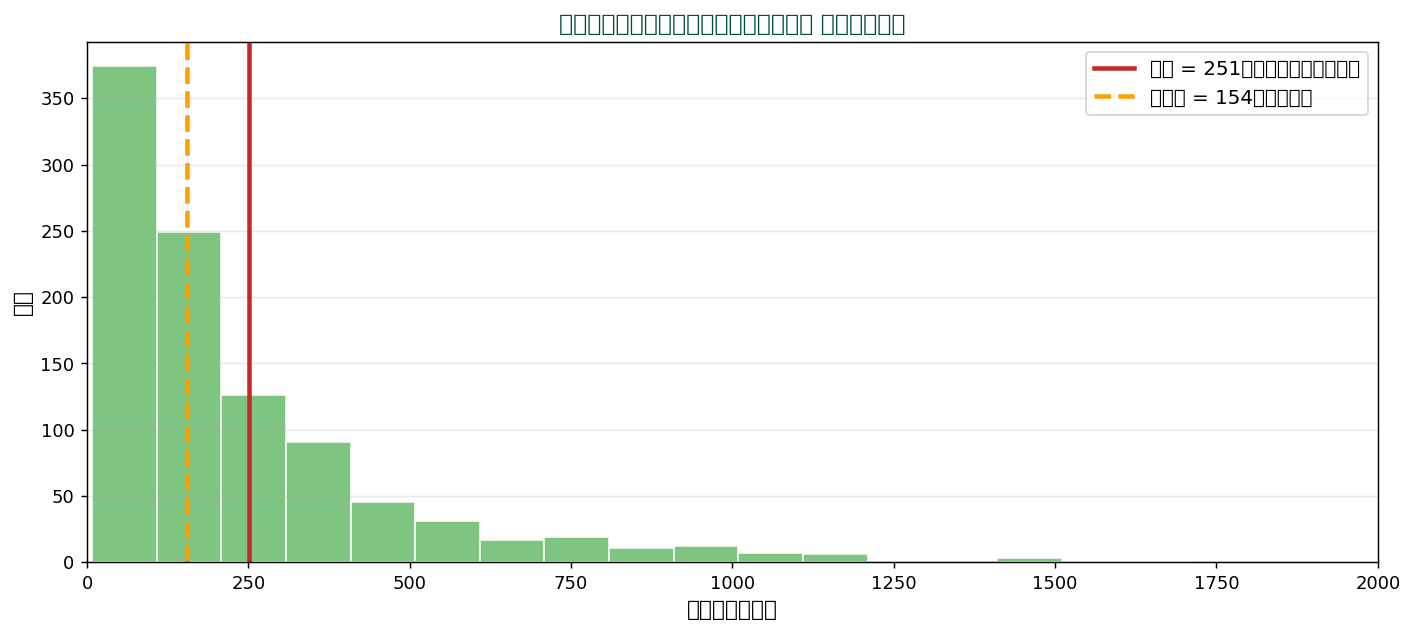
所得分布、 株価変動、 都市人口、 地震被害額など、 多くの実データは右に裾の長い分布(対数正規、 Pareto等)。 平均は裾に引っ張られて「典型的でない」値になり、 中央値の方が「典型的な人」を表します。 「平均年収」より「中央値年収」を見るべき理由。
📏 中央絶対偏差 (MAD) — 中央値ベースのばらつき指標
平均にはペアとして「標準偏差」がありましたが、 中央値のロバスト版が MAD (Median Absolute Deviation)。
$$ \text{MAD} = \text{median}(|x_i - \text{median}(x)|) $$
計算手順
- データの中央値を計算 → m
- 各データ点について |x_i - m| を計算(中央値からの絶対距離)
- その絶対距離の中央値を取る → MAD
標準偏差は外れ値に弱い(2乗するから極端値が支配的)ですが、 MAD は50%崩壊点を持つロバスト指標。 正規分布の場合、 σ ≈ 1.4826 × MAD という換算式があります。
Python での計算
1 2 3 4 5 6 7 8 9 10 11 12 | import numpy as np from scipy import stats data = np.array([1, 2, 3, 4, 5, 6, 7, 100]) # 外れ値あり median = np.median(data) mad = np.median(np.abs(data - median)) print(f'中央値: {median}') print(f'MAD: {mad}') # scipy には組み込み関数がある mad_scipy = stats.median_abs_deviation(data) mad_scaled = stats.median_abs_deviation(data, scale='normal') # 正規分布換算 |
📦 四分位と箱ひげ図 — 中央値の自然な拡張
中央値はデータの50%点。 これを25%、 75%にも拡張したのが四分位(quartile)。 そして四分位を可視化した最強のグラフが箱ひげ図。
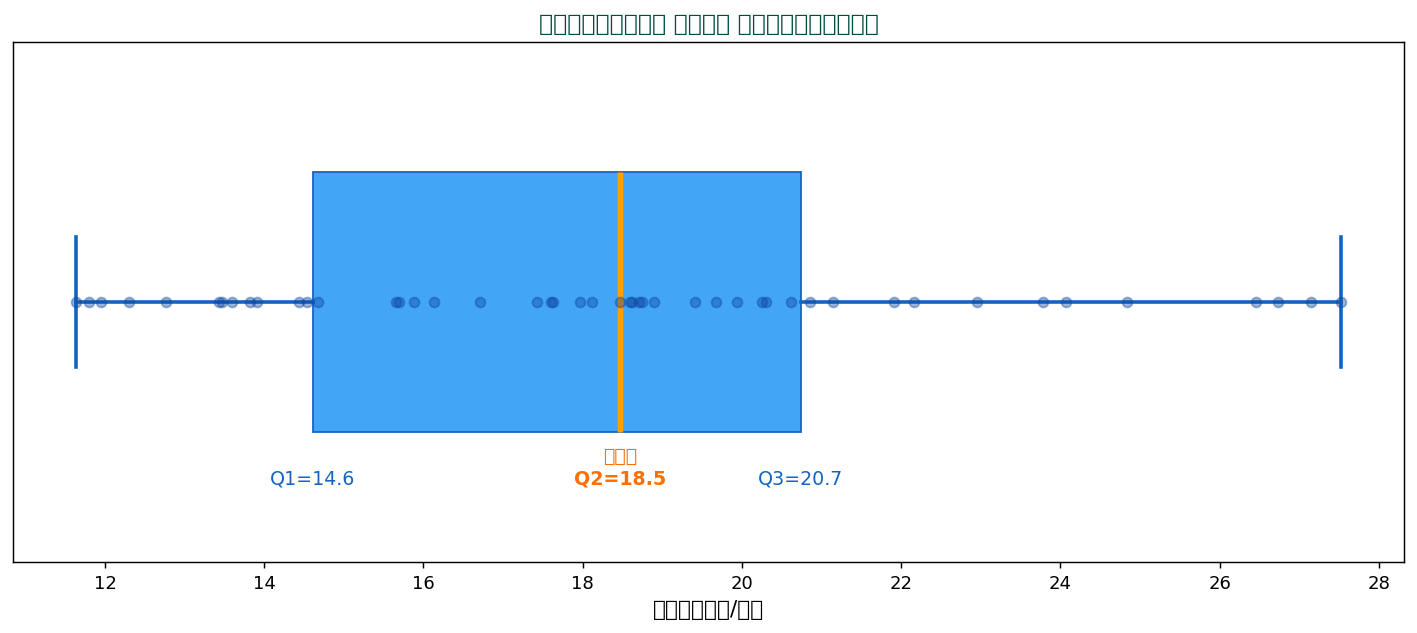
四分位の定義
- Q1(第1四分位):小さい方から25%地点 = 14.61 千円
- Q2(第2四分位 = 中央値):50%地点 = 18.47 千円
- Q3(第3四分位):75%地点 = 20.74 千円
- IQR(四分位範囲):Q3 - Q1 = 6.13 千円(中央50%の幅)
箱ひげ図の読み方
- 箱:Q1からQ3まで(中央50%のデータ)
- 箱の中の太線:中央値(Q2)
- ひげ(whisker):通常 Q1 - 1.5×IQR から Q3 + 1.5×IQR の範囲
- 点(outlier):ひげの外側のデータ点 → 外れ値の候補
💡 箱ひげ図1枚で 中央値・四分位・データの散らばり・歪み・外れ値 全てが分かります。 探索的データ分析(EDA)の基本ツール。
⚙️ 中央値計算アルゴリズム
① ソートしてから取る(O(n log n))
最も単純:全データをソートして、 真ん中を取り出す。 numpy/pandas のデフォルト実装。
1 2 3 4 5 6 7 | def median_sort(arr): sorted_arr = sorted(arr) # O(n log n) n = len(sorted_arr) if n % 2 == 1: return sorted_arr[n // 2] else: return (sorted_arr[n // 2 - 1] + sorted_arr[n // 2]) / 2 |
② QuickSelect — O(n) 平均時間
クイックソートと同じ分割を、 必要な位置だけ続ける。 全部ソートしないので線形時間で中央値が求まる。
1 2 3 4 5 6 | import numpy as np # numpy の partition は内部で QuickSelect 系のアルゴリズム arr = np.random.randn(10**6) k = len(arr) // 2 np.partition(arr, k)[k] # O(n) で k 番目の値 |
③ ストリーミングデータ — オンライン中央値
データが1個ずつ来る場合、 ヒープを2つ(max-heap と min-heap)使うと O(log n) で更新可能。 IoT センサーや金融取引の中央値追跡で使われます。
🤖 機械学習での中央値
① 中央値回帰 (Quantile Regression)
通常の線形回帰は平均(期待値)を予測しますが、 中央値を予測する回帰もあります。 外れ値に強いロバスト回帰の代表。 損失関数は L1(絶対値):
$$ L(\beta) = \sum_i |y_i - x_i^T \beta| $$
機械学習ライブラリ:sklearn.linear_model.QuantileRegressor、 statsmodels.regression.quantile_regression。
② 決定木の損失関数
決定木の回帰版で、 各葉ノードの「中央値」を予測値とする方法もあります(デフォルトは平均だが、 中央値ベースの方がロバスト)。
③ 欠損値の補完
欠損値を埋める時、 SimpleImputer(strategy='median') で中央値補完。 外れ値の影響を受けないので、 平均補完より安全。
1 2 3 | from sklearn.impute import SimpleImputer imputer = SimpleImputer(strategy='median') X_imputed = imputer.fit_transform(X) |
④ Robust Scaling
標準化(標準偏差で割る)の代わりに、 中央値と IQR を使うスケーリング。 外れ値の影響を受けない前処理:
$$ x_{\text{scaled}} = \frac{x - \text{median}(x)}{\text{IQR}(x)} $$
1 2 3 | from sklearn.preprocessing import RobustScaler scaler = RobustScaler() X_scaled = scaler.fit_transform(X) |
🐍 Python での計算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | import pandas as pd import numpy as np from scipy import stats # pandas df = pd.read_csv('data/raw/SSDSE-B-2026.csv', encoding='cp932') median_housing = df['住居費'].median() print(f'住居費の中央値: {median_housing:.2f}') # numpy arr = np.array([1, 3, 5, 7, 9, 11]) print(np.median(arr)) # 6.0(4と8の平均) # 軸指定 mat = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) print(np.median(mat, axis=0)) # [4, 5, 6] - 列ごと print(np.median(mat, axis=1)) # [2, 5, 8] - 行ごと # 欠損値を無視 arr_nan = np.array([1, 2, np.nan, 4]) print(np.nanmedian(arr_nan)) # 2.0 # 四分位 q1, q2, q3 = np.percentile(df['住居費'], [25, 50, 75]) print(f'Q1={q1:.2f}, Median={q2:.2f}, Q3={q3:.2f}') # pandas describe(要約) print(df['住居費'].describe()) # count/mean/std/min/25%/50%/75%/max |
箱ひげ図の描画
1 2 3 4 5 6 7 8 9 10 11 | import seaborn as sns import matplotlib.pyplot as plt # 1変数の箱ひげ図 sns.boxplot(y=df['住居費']) # カテゴリ別の箱ひげ図 sns.boxplot(x='地域', y='住居費', data=df) # violin plot(分布の形も見える進化版) sns.violinplot(x='地域', y='住居費', data=df, inner='quartile') |
🌳 平均 vs 中央値 — 使い分けフロー
- 分布の形をヒストグラムで確認
- 対称・正規分布に近い → 平均が最適
- 歪んでいる、 裾が長い → 中央値が安全
- 外れ値の存在
- なし → 平均
- あり、 真のデータと判断 → 中央値(または変換後の平均)
- あり、 ノイズと判断 → 外れ値除去後の平均
- 目的別
- 合計が意味を持つ(売上、 給料総額)→ 平均(× n = 合計)
- 「典型的な値」→ 中央値
- 不確実性評価 → 平均 + 信頼区間 or 中央値 + IQR
💡 報告では両方を併記するのが最も誠実。 「平均500万円、 中央値450万円」と書けば、 分布の歪みも示唆できる。
📜 中央値の歴史
- Edward Wright(1599):航海術の本で「複数の方位観測の中央値」を提案。 文献上の中央値の最古の使用例
- Boscovich(1755):天文観測で最初に中央値ベースの推定を試みる
- Laplace(1774):「中央値が L1 損失を最小化する」を証明
- Galton(1869):「median」という用語を初めて使用
- Tukey(1977):箱ひげ図を発明し、 中央値を視覚化の中心に据える
平均よりも歴史は若いですが、 「外れ値に強い代表値」として近代統計の発展に欠かせない概念に。
🗺️ 概念マップ — 3つの視点で体系を理解する
中央値 がデータサイエンスの体系の中でどこに位置するかを、 3つの異なる視点で可視化します。 同じ情報でも見方を変えると気付きが変わります。
📍 体系階層のパス
🌐 統計・データサイエンス › 記述統計 › 中心傾向 › 中央値
① 🔗 関係マップ — 「他の手法とどう繋がっているか」
中心の概念から放射状に、 前提・兄弟・発展形・応用先などの関係性を矢印で結びます。 横の繋がりを見るのに最適。 ノードをドラッグ、 ホイールでズーム、 クリックで遷移。
② ⭕ 包含マップ — 「どのカテゴリに含まれているか」
大きな円が小さな円を包含する Circle Packing 図。 「中央値」は緑色でハイライト。
- カテゴリ円をクリック:その内部にズームイン
- 白背景クリック:1階層戻る
- 用語円をクリック:詳細ページへ遷移
- マウスホバー:階層パス表示
③ 🌳 ツリーマップ — 「面積で見るボリューム比較」
長方形を入れ子に分割した Treemap 図。 各分野の規模感を面積で比較。 「中央値」は緑色でハイライト。
- カテゴリ矩形をクリック:その内部にドリルダウン
- パンくず(上のリンク)クリック:その階層に戻る
- 用語矩形をクリック:詳細ページへ遷移
- マウスホバー:階層パスと値を表示
🎯 3つのマップの使い分け
| マップ | 分かること | こんな時に見る |
|---|---|---|
| 🔗 関係マップ | 手法間の横の関係(前提→発展→応用) | 「次に何を学べばよい?」 学習順序の判断 |
| ⭕ 包含マップ | 分類体系の入れ子構造(上位⊃下位) | 「この手法はどんなジャンルに属する?」 |
| 🌳 ツリーマップ | 分野の規模比較(面積=ボリューム) | 「データサイエンス全体の俯瞰像」 |
💡 ジャストインタイム学習のヒント:3つの視点を行き来することで、 概念を多角的に理解できます。 包含マップやツリーマップはズーム/ドリルダウンで大分類から細部まで探索できます。
🔖 キーワード索引(拡張)
🧮 SSDSE-B を使った中央値の実例 — 県民所得
SSDSE-B(2020年)の「1人当たり県民所得」で平均と中央値を比較し、 中央値の有用性を確認します。
① 平均 vs 中央値の比較
1 2 3 4 5 6 7 8 9 10 11 | import pandas as pd df = pd.read_csv('data/raw/SSDSE-B-2023.csv', encoding='shift_jis', header=[0,1]) df.columns = ['_'.join(c).strip() for c in df.columns] income = df[df['年度_Year'] == 2020]['1人当たり県民所得'].dropna() print(f'n = {len(income)}') print(f'平均 = {income.mean():.1f}') print(f'中央値 = {income.median():.1f}') print(f'最大値 = {income.max():.1f}(東京)') print(f'最小値 = {income.min():.1f}(沖縄など)') print(f'歪度 = {income.skew():.3f}') |
典型結果:平均 = 312 万円、 中央値 = 290 万円。 平均 > 中央値 で右に歪んだ分布(東京の所得が高い)。 「日本人の所得」を語るなら中央値の方が実態を反映する。
② 外れ値の影響シミュレーション
1 2 3 4 5 6 7 | import numpy as np # 仮に「東京の所得が突然3倍になった」と仮定 income_extreme = income.copy() income_extreme[income_extreme.idxmax()] *= 3 print(f'平均 (元) = {income.mean():.1f} → (変動後) {income_extreme.mean():.1f}({(income_extreme.mean()-income.mean()):.1f} 変動)') print(f'中央値(元) = {income.median():.1f} → (変動後) {income_extreme.median():.1f}({(income_extreme.median()-income.median()):.1f} 変動)') # 平均は約16万円変動、 中央値は1円も動かない → ロバスト性の真髄 |
③ 四分位・MAD で頑健な散布度
1 2 3 4 5 6 7 | q1, q3 = income.quantile([0.25, 0.75]) iqr = q3 - q1 mad = (income - income.median()).abs().median() # 中央絶対偏差 print(f'Q1 = {q1:.1f}, Q3 = {q3:.1f}, IQR = {iqr:.1f}') print(f'MAD = {mad:.1f}') print(f'SD (比較) = {income.std():.1f}') # 散布度の頑健指標:MAD・IQR < SD < 分散 の順にロバスト性が低下 |
🐍 実装バリエーション — pandas / numpy / scipy / statsmodels
(A) pandas / numpy — 基本
1 2 3 4 5 6 7 | import pandas as pd import numpy as np s = pd.Series([1, 2, 3, 100]) print(s.median()) # 2.5 print(np.median(s)) # 2.5 print(np.percentile(s, 50)) # 2.5(中央値 = 50%パーセンタイル) print(np.quantile(s, 0.5)) # 2.5 |
(B) scipy.stats — トリム平均・幾何平均など
1 2 3 4 5 6 | from scipy import stats data = [1, 2, 3, 4, 100] print(stats.tmean(data, limits=(2, 50))) # 切断平均(範囲内のみ) print(stats.trim_mean(data, 0.1)) # 上下10%トリム print(stats.gmean(data)) # 幾何平均(対数正規分布向け) print(stats.hmean(data)) # 調和平均(比率の集約向け) |
(C) statsmodels — 分位点回帰
1 2 3 4 5 | import statsmodels.formula.api as smf # 「中央値」を目的とした回帰(外れ値に強い) mod = smf.quantreg('y ~ x1 + x2', data=df).fit(q=0.5) print(mod.summary()) # 通常の OLS(平均回帰)の頑健代替。 q=0.25, 0.75 で他分位点も推定可 |
(D) scikit-learn — Huber 回帰(ロバスト)
1 2 3 | from sklearn.linear_model import HuberRegressor hr = HuberRegressor(epsilon=1.35).fit(X, y) # 中央値ベースではないが、 外れ値に強い線形回帰 |
(E) scipy.stats による中央値検定(Mood's median test)
1 2 3 4 | from scipy.stats import median_test stat, p, m, table = median_test(group1, group2) print(f'統計量 = {stat:.3f}, p = {p:.4f}') # 2群の中央値が等しいかを検定(χ²ベース) |
⚠️ 追加の落とし穴 — 中央値の実務
interpolation='linear' で線形補間、 statsmodels や R では他の補間法もある。 報告時には「中央値(線形補間)」のように方法を明示する。scipy.stats.bootstrap や sklearn.utils.resample。 中央値を点推定でだけ報告するのは不十分。 「中央値 280 万(95% CI [260, 295])」のように区間も併記。